
Reinforcement Learning-Based Intent Classification of Chinese Questions About Respiratory Diseases


Abstract
1. Introduction
- : The patient clearly states what kind of disease they are suffering from and asks about effective treatments (intervention measures).
- : The patient asks what disease they are suffering from or distinguishes the name of the specific disease from which they are suffering from.
- : The patient asks about the disease burden or adverse reactions that a certain disease or drug may cause.
- : The patient asks about the cause of a certain disease.
- : The main body of the patients are a specific group of people, asking about behaviors, diet, or other matters that require attention for a certain disease or drug.
2. Related Work
2.1. Keywords in Classification Tasks
2.2. Application of Reinforcement Learning in NLP Tasks
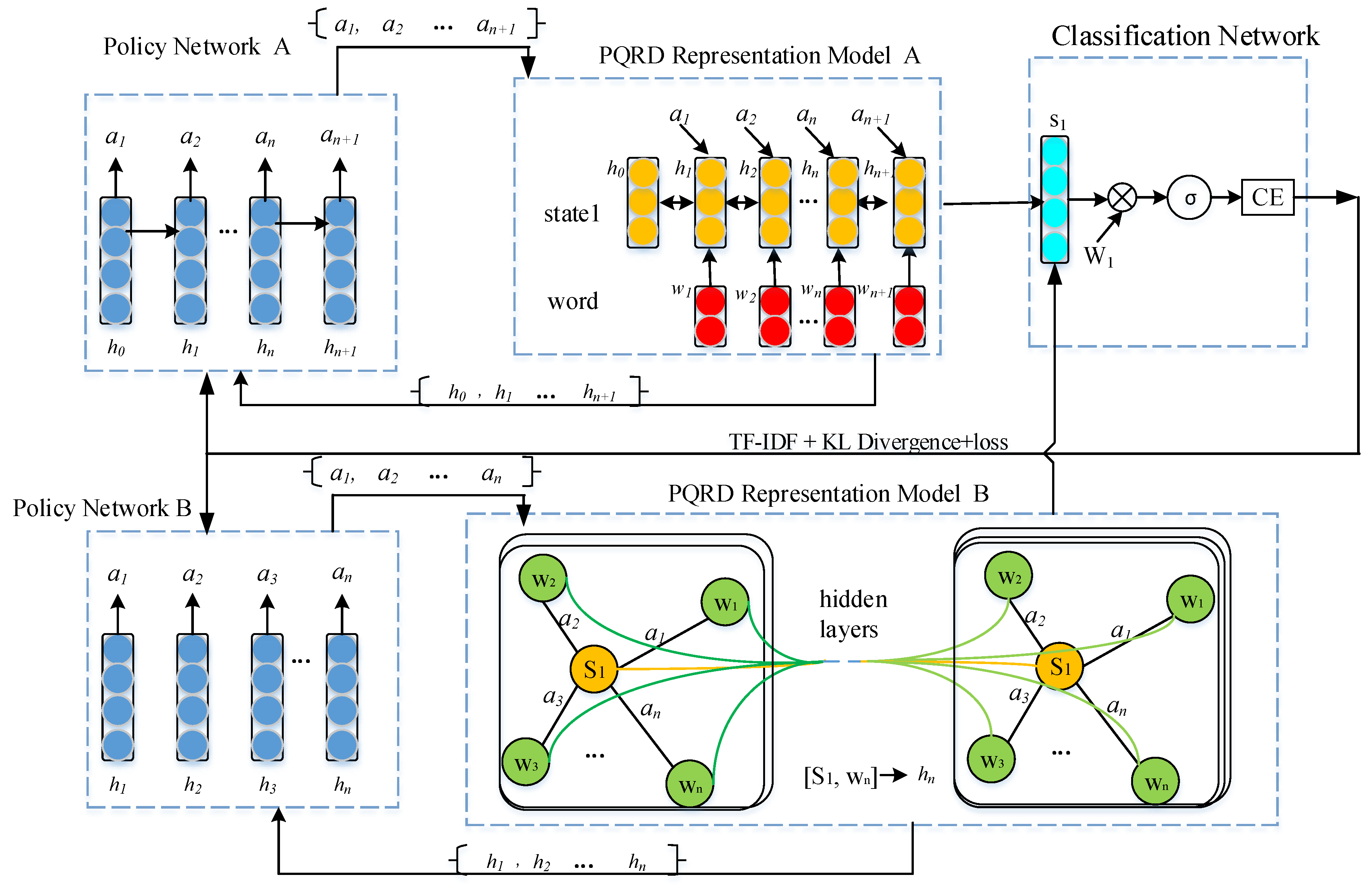
3. Methodology
3.1. Policy Network (PNet)
3.1.1. State
3.1.2. Action
3.1.3. Reward
3.2. CQRD Representation Model
3.2.1. Keyword-Driven LSTM
3.2.2. Keyword-Driven GCN
3.3. Classification Network (CNet)
4. Experiments
4.1. Tasks and Datasets
4.1.1. Intention Classification of Chinese Questions on Respiratory Diseases (IC-CQRD) Dataset
4.1.2. Chinese Medical Intention Dataset (CMID)
4.2. Hyperparameters and Training Detail
4.3. Chinese Questions on Respiratory Diseases (CQRD) Datasets Preprocessing
4.4. Classification Results
- Composition Function-Based CQRD Representation: Since the composition function constructs CQRD representations by directly deriving word vectors from the problem text, it is not feasible to directly integrate keyword information into the representation. To address this, a one-hot vector representing the category is constructed and concatenated with the problem representation vector, thereby embedding keyword information into the representation.
- CQRD Representation Based on CNN and S-LSTM Models: In this approach, keyword information is incorporated in a semi-generalized manner. Specifically, category labels are appended to each keyword in the CQRD text, treating these labels as independent words that participate in the generation of CQRD representations. This enhances the influence of keywords during the representation generation process.
- CQRD Representation Based on Bi-LSTM and LSTM Models: In this method, different weights are assigned to keywords and non-keywords within the problem text, forming a weight vector. By leveraging an attention mechanism, the hidden state sequences generated by the Bi-LSTM and LSTM models are weighted and summed to produce the final CQRD representation. This approach ensures that keywords contribute more significantly to the representation than non-keywords.
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IC-CQRD | Intention Classification of Chinese Questions on Respiratory Diseases; |
| CQRD | Chinese Questions on Respiratory Diseases; |
| KD-LSTM | Keyword-driven LSTM; |
| KD-GCN | Keyword-driven GCN; |
| RL | Reinforcement Learning; |
| HT | How to Treat; |
| WD | What Disease; |
| WWH | What Will Happen; |
| WHY | Why; |
| PRE | Precautions; |
| GDA | Grammar-based Data Augmentation; |
| DrN | Drug Names; |
| SN | Symptom Names; |
| DiN | Disease Names; |
| PNet | Policy Network; |
| CQRD_RM | CQRD Representation Model; |
| CNet | Classification Network. |
References
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for effificient text classifification. In Proceedings of the ECACL 2017, Valencia, Spain, 3–7 April 2017; Short Papers. pp. 427–431. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved Semantic Representations from Tree-Structured Long Short-Term Memory Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1556–1566. [Google Scholar]
- Bao, X.; Jiang, X.; Wang, Z.; Zhang, Y.; Zhou, G. Opinion Tree Parsing for Aspect-based Sentiment Analysis. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 7971–7984. [Google Scholar]
- Yuan, S.; Nie, E.; Färber, M.; Schmid, H.; Schuetze, H. GNNavi: Navigating the Information Flow in Large Language Models by Graph Neural Network. In Findings of the Association for Computational Linguistics: ACL 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 3987–4001. [Google Scholar]
- Liang, Y.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.d. A structured self-attentive sentence embedding. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Zhang, N.; Jia, Q.; Yin, K.; Dong, L.; Gao, F.; Hua, N. Conceptualized Representation Learning for Chinese Biomedical Text Mining. arXiv 2020, arXiv:2008.10813. [Google Scholar]
- Wang, Q.; Dai, S.; Xu, B.; Lyu, Y.; Zhu, Y.; Wu, H.; Wang, H. Building Chinese Biomedical Language Models via Multi-Level Text Discrimination. arXiv 2021, arXiv:2110.07244. [Google Scholar]
- Chuang, Y.; Dangovski, R.; Luo, H.; Zhang, Y.; Chang, S.; Soljacic, M.; Li, S.; Yih, S.; Kim, Y.; Glass, J. Diffcse: Difference-Based Contrastive Learning for Sentence Embeddings. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 10–15 July 2022; pp. 4207–4218. [Google Scholar]
- Wang, Y.; Chi, T.; Zhang, R.; Yang, Y. PESCO: Prompt-enhanced Self Contrastive Learning for Zero-shot Text Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 14897–14911. [Google Scholar]
- Yu, M.; Shen, J.; Zhang, C.; Han, J. Weakly-Supervised Neural Text Classification. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 983–992. [Google Scholar]
- Lu, Z.; Ding, J.; Xu, Y.; Liu, Y.; Zhou, S. Weakly-supervised Text Classification Based on Keyword Graph. In Proceedings of the EMNLP 2021, Virtual, 16–20 November 2021; pp. 2803–2813. [Google Scholar]
- Yogatama, D.; Blunsom, P.; Dyer, C.; Grefenstette, E.; Ling, W. Learning to Compose Words into Sentences with Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, T.; Huang, M.; Zhao, L. Learning Structured Representation for Text Classification via Reinforcement Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6053–6060. [Google Scholar]
- Aytuğ, O.; Korukoğlu, S.; Bulut, H. Ensemble of Keyword Extraction Methods and Classifiers in Text Classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- El-Ghawi, Y.; Marzouk, A.; Khamis, A. LexiconLadies at FIGNEWS 2024 Shared Task: Identifying Keywords for Bias Annotation Guidelines of Facebook News Headlines on the Israel-Palestine 2023 War. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; pp. 561–566. [Google Scholar]
- Hu, F.; Li, L.; Zhang, Z.L.; Wang, J.Y.; Xu, X.F. Emphasizing Essential Words for Sentiment Classification based on Recurrent Neural Networks. J. Comput. Sci. Technol. 2017, 32, 785–795. [Google Scholar]
- Mekala, D.; Shang, J. Contextualized Weak Supervision for Text Classification. In Proceedings of the ACL 2020, Online, 5–10 July 2020; pp. 323–333. [Google Scholar]
- Meng, Y.; Zhang, Y.; Huang, J.; Xiong, C.; Ji, H.; Zhang, C.; Han, J. Text Classification Using Label Names Only: A Language Model Self-Training Approach. In Proceedings of the EMNLP 2020, Online, 16–20 November 2020; pp. 9006–9017. [Google Scholar]
- Rrv, A.; Tyagi, N.; Uddin, M.N.; Varshney, N.; Baral, C. Chaos with Keywords: Exposing Large Language Models Sycophancy to Misleading Keywords and Evaluating Defense Strategies. In Findings of the Association for Computational Linguistics: ACL 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 12717–12733. [Google Scholar]
- Kim, J.; Yeonju, K.; Ro, Y.M. What if…?: Thinking Counterfactual Keywords Helps to Mitigate Hallucination in Large Multi-modal Models. In Findings of the Association for Computational Linguistics: EMNLP 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 10672–10689. [Google Scholar]
- Pasini, T.; Scozzafava, F.; Scarlini, B. CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multiple Languages. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4008–4018. [Google Scholar]
- Karthik, N.; Kulkarni, T.; Regina, B. Language Understanding for Text-based Games using Deep Reinforcement Learning. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1–11. [Google Scholar]
- Tang, P.; Gao, J.; Zhang, L.; Zhiyong, W. Efficient and Interpretable Compressive Text Summarisation with Unsupervised Dual-Agent Reinforcement Learning. In Proceedings of the Fourth Workshop on Simple and Efficient Natural Language Processing (SustaiNLP), Toronto, ON, Canada, 13 July 2023; pp. 227–238. [Google Scholar]
- Wang, W.Y.; Li, J.; He, X. Deep Reinforcement Learning for NLP. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics-Tutorial Abstracts, Melbourne, Australia, 15–20 July 2018; pp. 19–21. [Google Scholar]
- Asaf, Y.; Leshem, C.; Lior, F.; Omri, A. Reinforcement Learning with Large Action Spaces for Neural Machine Translation. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 4544–4556. [Google Scholar]
- Huang, W.; Liang, J.; Li, Z.; Xiao, Y.; Ji, C. Adaptive Ordered Information Extraction with Deep Reinforcement Learning. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 13664–13678. [Google Scholar]
- Wang, L.; Bo, Z.; Yunyu, L.; Can, Q.; Wei, C.; Wenchao, Y.; Xuchao, Z.; Haifeng, C.; Yun, F. Aspect-based Sentiment Classification via Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 1391–1396. [Google Scholar]
- Hyun, D.; Wang, X.; Park, C.; Xie, X.; Yu, H. Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization. In Proceedings of the EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2939–2951. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Neural Inf. Process. Syst. 2000, 12, 1057–1063. [Google Scholar]
- Chen, N.; Su, X.; Liu, T.; Hao, Q.; Wei, M. A Benchmark Dataset and Case Study for Chinese Medical Question Intent Classification. BMC Med. Inform. Decis. Mak. 2020, 20, 125. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Ruslan, R.S.; Geoffrey, E.H. Modeling Documents with Deep Boltzmann Machines. arXiv 2013, arXiv:1309.6865. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 74–80. [Google Scholar]
- Baidu’s Knowledge-Enhanced Large Language Model Built on Full AI Stack Technology. 2023. Available online: http://research.baidu.com/Blog/index-view?id=183 (accessed on 24 March 2023).

{kind=link}
| Model | Not Used Keywords | Used Keywords |
|---|---|---|
| Mean vector | 81.26 | 87.36 |
| CNN | 85.86 | 87.24 |
| LSTM | 86.90 | 89.77 |
| S-LSTM | 87.59 | 89.31 |
| Bi-LSTM | 89.43 * | 91.03 * |
| Model | CQRD_28000 | CQRD_8000 | CMID |
|---|---|---|---|
| Mean vector | 82.96 | 81.26 | 75.3 |
| BERT | 94.67 | 86.32 | 81.65 |
| MC-BERT | 94.47 | 88.67 | 83.15 |
| BERT-ehealth | 94.82 | 89.14 | 82.85 |
| ERNIE-Bot | 90.33 | 89.12 | 83.15 |
| GCN_Tf-Idf | 88.94 | 84.37 | 81.35 |
| GCN | 91.76 | 88.12 | 82.55 |
| LSTM | 94.15 | 86.9 | 81.9 |
| Bi-LSTM | 94.28 | 89.43 | 82.9 |
| Bi-LSTM + attention | 94.44 | 90.11 | 83.4 |
| KD-GCN | 94.88 | 90.13 | 83.65 |
| KD-LSTM_weight | 95.0 * | 90.92 * | 84.45 * |
| KD-LSTM_vec | 94.94 | 91.84 | 84.8 |
| Model | Test0 (×100) | Test1 (×100) | Test2 (×100) | Test3 (×100) | Test4 (×100) |
|---|---|---|---|---|---|
| SVM | 82.78 | 82.8 | 83.55 | 82.26 | 82.63 |
| GCN_Tf-Idf | 87.85 | 88.41 | 89.14 | 89.07 | 88.86 |
| GCN | 91.65 | 92.54 | 93.44 | 92.56 | 93.41 |
| LSTM | 93.77 | 93.56 | 94.69 | 93.46 | 94.26 |
| Bi-LSTM | 93.86 | 93.94 | 94.49 | 93.84 | 94.53 |
| BERT | 94.69 | 93.83 | 94.71 | 94.13 | 94.64 |
| MC-BERT | 94.38 | 93.96 | 94.36 | 94.33 | 94.58 |
| BERT-ehealth | 94.44 | 93.61 | 94.85 | 94.06 | 94.77 |
| KD-GCN | 94.43 | 94.72 * | 94.83 | 93.94 | 94.73 |
| KD-LSTM_weight | 94.65 | 94.63 | 95.64 * | 94.69 * | 95.17 |
| KD-LSTM_vec | 94.86 * | 94.29 | 95.17 | 94.47 | 95.43 * |
| Model | HT | WD | WWH | WHY | PRE | p-Value |
|---|---|---|---|---|---|---|
| LSTM | 97.65 * | 83.49 | 92.87 | 81.25 | 85.75 | 0.1140 |
| Bi-LSTM | 97.02 | 86.34 | 93.63 | 81.25 | 87.75 | |
| BERT | 96.97 | 88.29 | 94.63 | 80.42 | 89.16 | 0.2396 |
| ERNIE-Bot | 93.02 | 82.34 | 89.63 | 80.69 | 95.44 * | 0.7096 |
| KD-LSTM_weight | 96.63 | 90.89 | 95.22 * | 84.6 * | 90.03 | 0.01989 |
| KD-LSTM_vec | 96.78 | 91.46 * | 94.50 | 84.17 | 89.17 | 0.07270 |
| KD-GCN | 96.93 | 90.22 | 94.55 | 82.71 | 88.96 | 0.07092 |
| Model | Precision | Recall | F-Score |
|---|---|---|---|
| TF-IDF | 85.33 | 77.58 | 81.27 |
| ERNIE-Bot | 87.32 | 89.91 | 88.60 |
| WF-RF | 87.19 | 90.22 | 88.68 |
| KD-LSTM_weight | 95.12 | 95.63 * | 95.37 |
| KD-LSTM_vec | 95.67 * | 95.23 | 95.45 * |
| KD-GCN | 94.69 | 95.17 | 94.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Huang, D.; Lin, X. Reinforcement Learning-Based Intent Classification of Chinese Questions About Respiratory Diseases. Appl. Sci. 2025, 15, 3983. https://doi.org/10.3390/app15073983
Wu H, Huang D, Lin X. Reinforcement Learning-Based Intent Classification of Chinese Questions About Respiratory Diseases. Applied Sciences. 2025; 15(7):3983. https://doi.org/10.3390/app15073983
Chicago/Turabian StyleWu, Hao, Degen Huang, and Xiaohui Lin. 2025. "Reinforcement Learning-Based Intent Classification of Chinese Questions About Respiratory Diseases" Applied Sciences 15, no. 7: 3983. https://doi.org/10.3390/app15073983
APA StyleWu, H., Huang, D., & Lin, X. (2025). Reinforcement Learning-Based Intent Classification of Chinese Questions About Respiratory Diseases. Applied Sciences, 15(7), 3983. https://doi.org/10.3390/app15073983