
LSOD-YOLOv8: Enhancing YOLOv8n with New Detection Head and Lightweight Module for Efficient Cigarette Detection



Abstract
1. Introduction
2. Theory and Methods
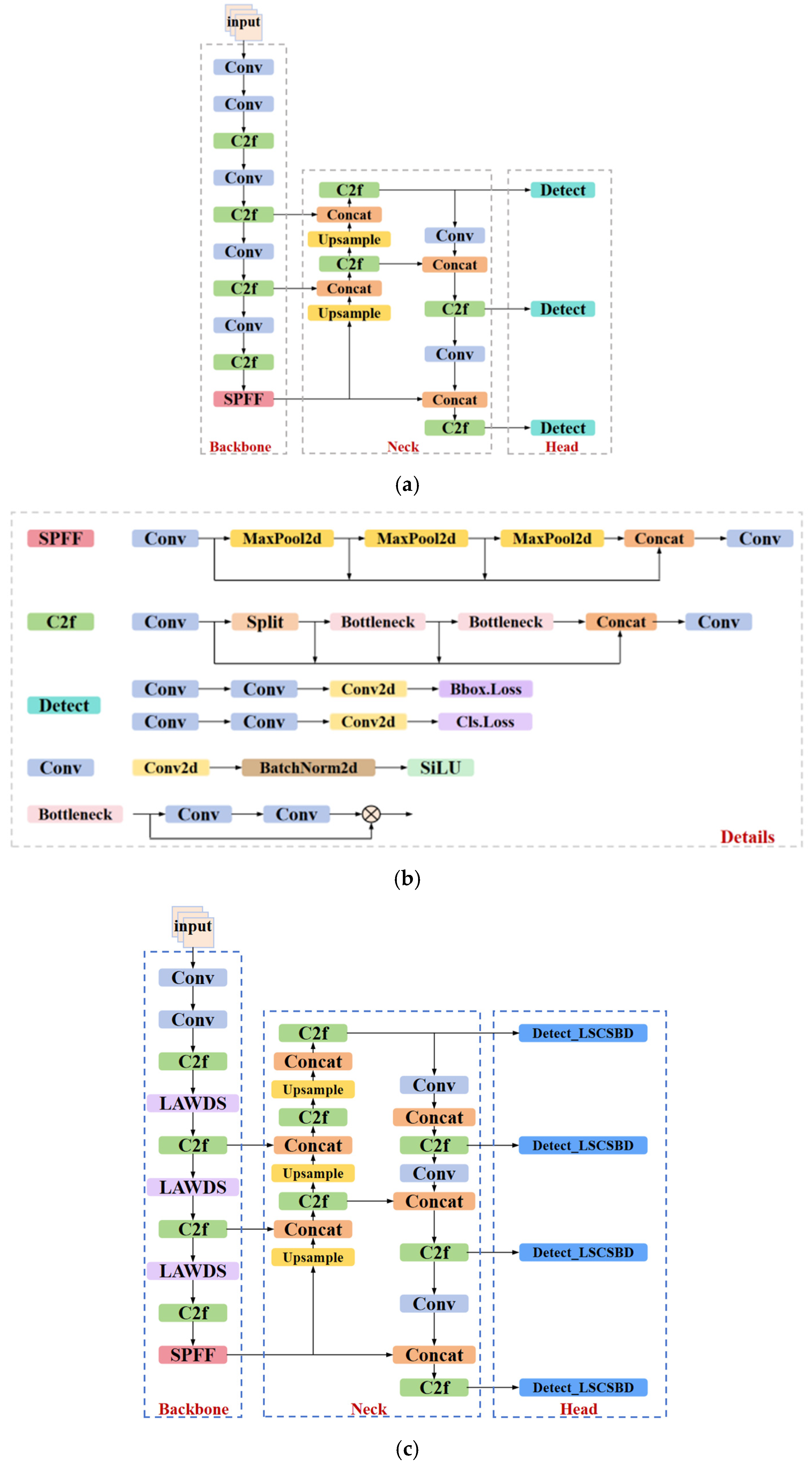
2.1. Baseline
2.2. Model Improvements
2.2.1. LAWDS
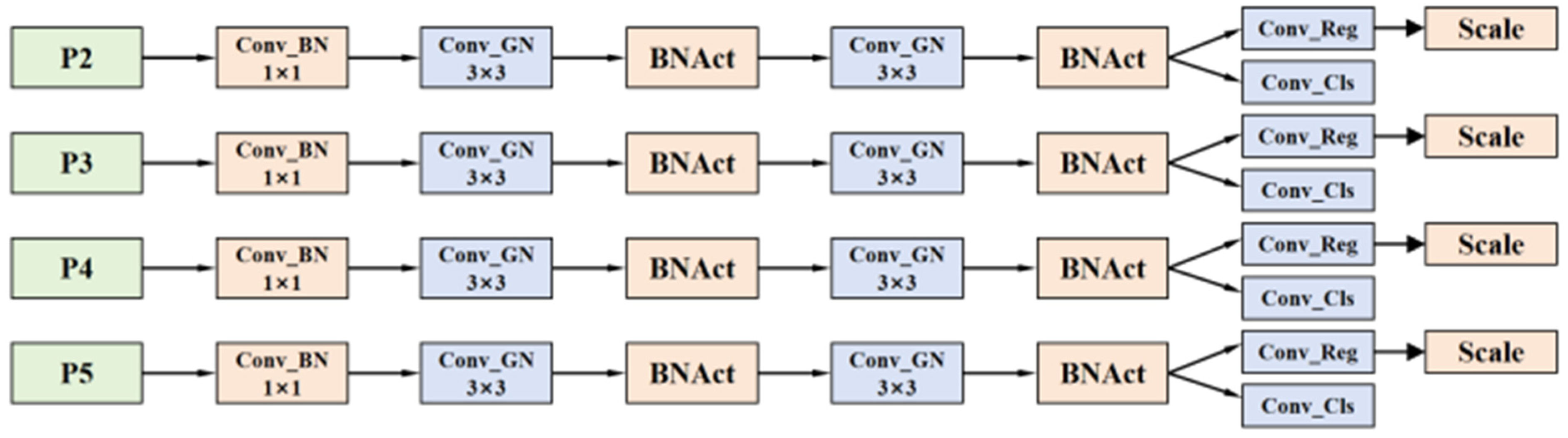
2.2.2. P2-LSCSBD
2.2.3. WIMIoU
3. Experimental Preparation
3.1. Experimental Dataset
3.2. Indicators for Experimental Evaluation
3.3. Experimental Environment
4. Experimental Results and Analysis
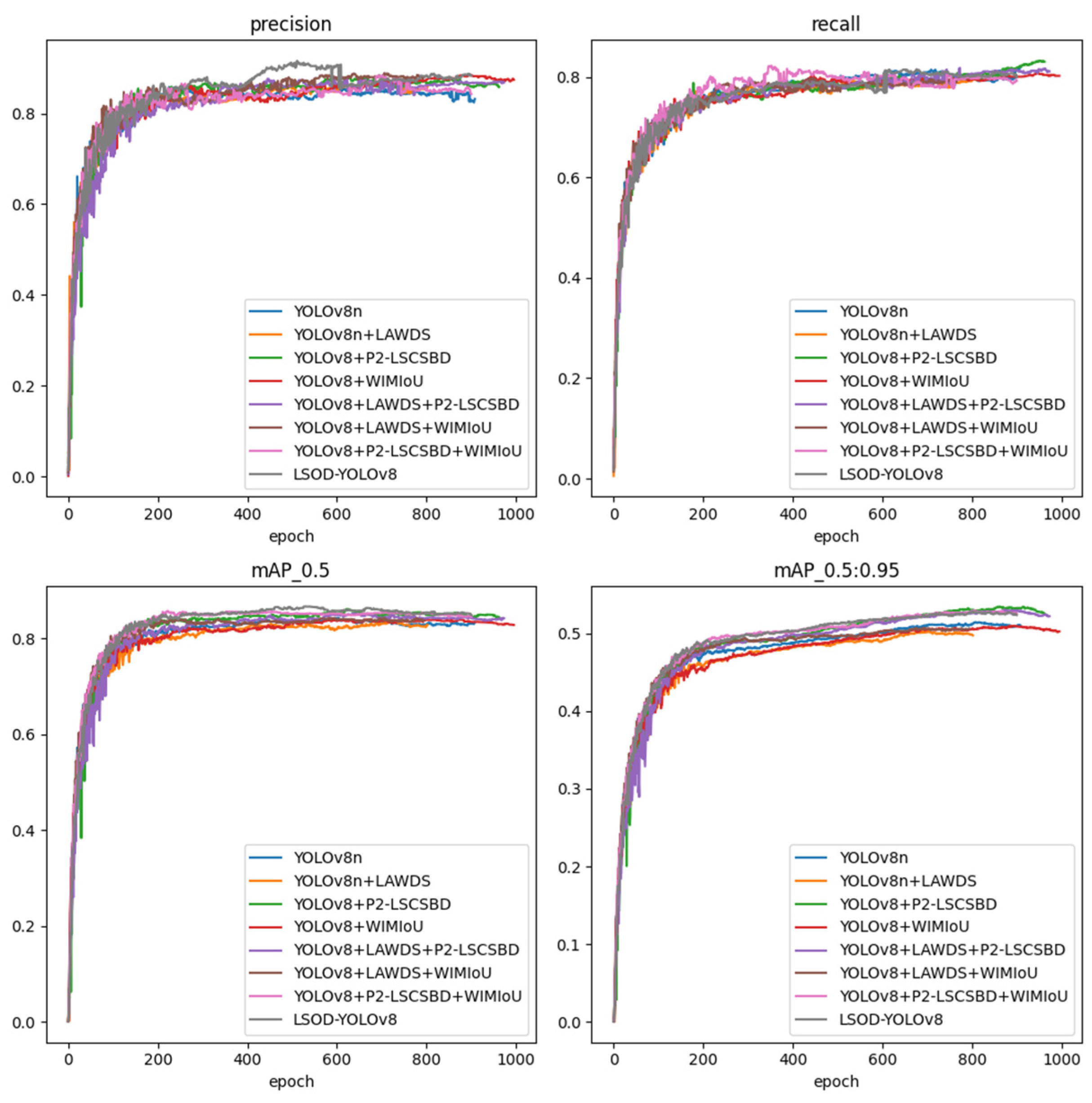
4.1. Experimental Validation of LAWDS Module
4.2. Comparative Experiment of Different Detection Models
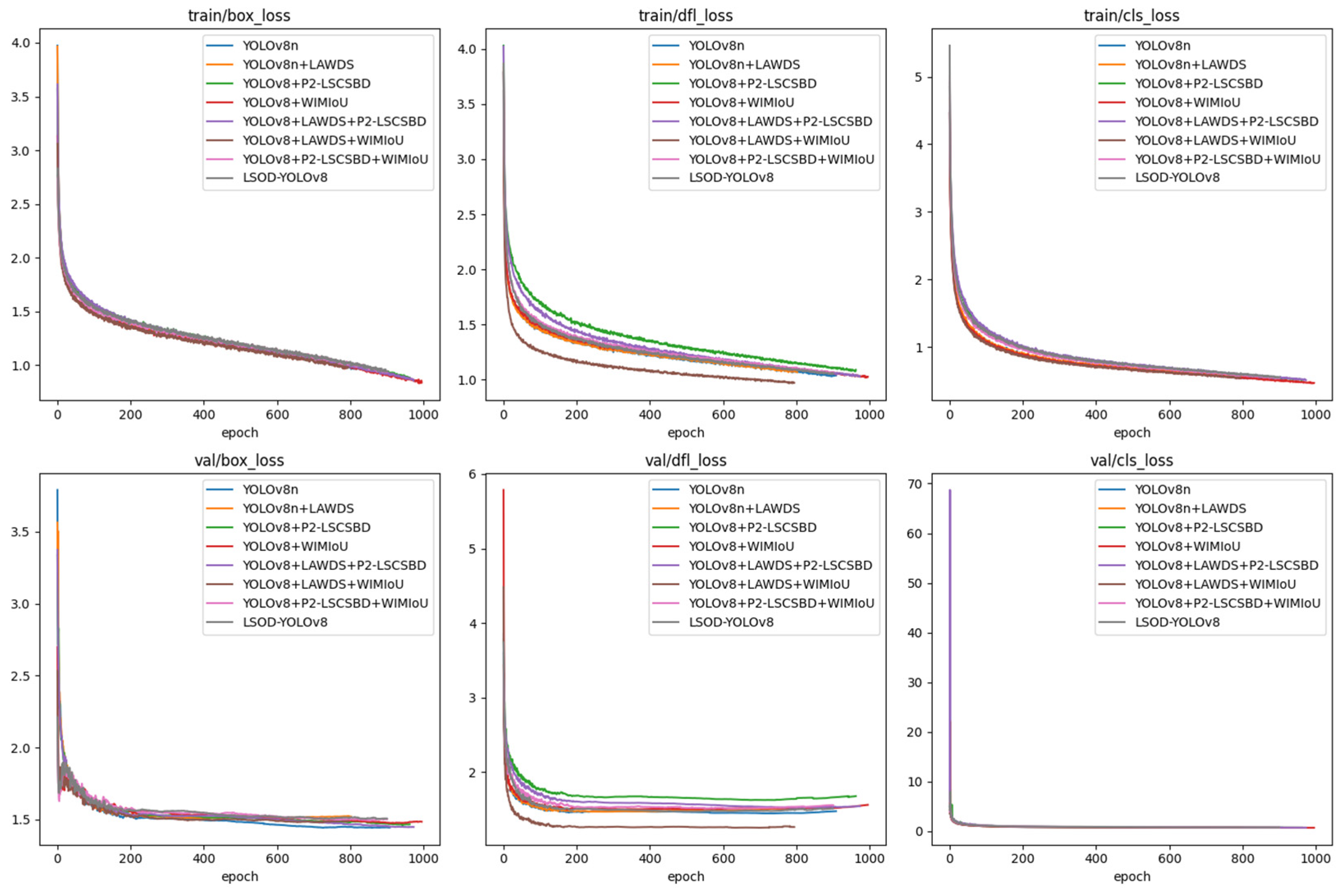
4.3. Ablation Experimental
4.4. LSOD-YOLOv8 Robustness Experiment
4.5. Comparison of Model Performance Across Different Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Malburg, L.; Rieder, M.P.; Seiger, R.; Klein, P.; Bergmann, R. Object detection for smart factory processes by machine learning. Procedia Comput. Sci. 2021, 184, 581–588. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, L.; Tan, Z.; Wang, H.; Wang, K. Multi-Head attention fusion networks for multi-modal speech emotion recognition. Comput. Ind. Eng. 2022, 168, 108078. [Google Scholar] [CrossRef]
- Sharma, A.; Singh, P.K. Applicability of UAVs in detecting and monitoring burning residue of paddy crops with IoT integration: A step towards greener environment. Comput. Ind. Eng. 2023, 184, 109524. [Google Scholar]
- Dhayne, H.; Kilany, R.; Haque, R.; Taher, Y. EMR2vec: Bridging the gap between patient data and clinical trial. Comput. Ind. Eng. 2021, 156, 107236. [Google Scholar] [PubMed]
- Liu, Y.; Wang, B.; Xu, X.; Xu, J. A new paradigm in cigarette smoke detection: Rapid identification technique based on ATR-FTIR spectroscopy and GhostNet-α. Microchem. J. 2024, 205, 111173. [Google Scholar]
- Zhu, B.; Wang, J.; Liu, S.; Dong, M.; Jia, Y.; Tian, L.; Su, C. RFMonitor: Monitoring smoking behavior of minors using COTS RFID devices. Comput. Commun. 2022, 185, 55–65. [Google Scholar]
- Imtiaz, M.H.; Ramos-garcia, R.I.; Wattal, S.; Tiffany, S.; Sazonov, E. Wearable sensors for monitoring of cigarette smoking in free-living: A systematic review. Sensors 2019, 19, 4678. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Ran, T.; Xiao, W.; Yuan, L.; Zhao, J.; He, L.; Mei, J. GD-YOLO: An improved convolutional neural network architecture for real-time detection of smoking and phone use behaviors. Digit. Signal Process. 2024, 151, 104554. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 18–20 November 2024; pp. 529–545. [Google Scholar]
- Yue, S.; Zhang, Z.; Shi, Y.; Cai, Y. WGS-YOLO: A real-time object detector based on YOLO framework for autonomous driving. Comput. Vis. Image Underst. 2024, 249, 104200. [Google Scholar]
- Xiao, D.; Wang, H.; Liu, Y.; Li, W.; Li, H. DHSW-YOLO: A duck flock daily behavior recognition model adaptable to bright and dark conditions. Comput. Electron. Agric. 2024, 225, 109281. [Google Scholar]
- Wang, Z.; Zhang, S.; Chen, Y.; Xia, Y.; Wang, H.; Jin, R.; Wang, C.; Fan, Z.; Wang, Y.; Wang, B. Detection of small foreign objects in Pu-erh sun-dried green tea: An enhanced YOLOv8 neural network model based on deep learning. Food Control 2025, 168, 110890. [Google Scholar]
- Guo, C.; Ren, K.; Chen, Q. YOLO-SGF: Lightweight network for object detection in complex infrared images based on improved YOLOv8. Infrared Phys. Technol. 2024, 142, 105539. [Google Scholar] [CrossRef]
- Niu, W.; Lei, X.; Li, H.; Wu, H.; Hu, F.; Wen, X.; Zheng, D.; Song, H. YOLOv8-ECFS: A lightweight model for weed species detection in soybean fields. Crop Prot. 2024, 184, 106847. [Google Scholar] [CrossRef]
- Yang, S.; Wang, W.; Gao, S.; Deng, Z. Strawberry ripeness detection based on YOLOv8 algorithm fused with LW-Swin Transformer. Comput. Electron. Agric. 2023, 215, 108360. [Google Scholar]
- Zhu, L.; Zhang, J.; Zhang, Q.; Hu, H. CDD-YOLOv8: A small defect detection and classification algorithm for cigarette packages. In Proceedings of the 2023 IEEE 13th International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Qinhuangdao, China,, 11–14 July 2023; pp. 716–721. [Google Scholar]
- Cui, S.; Zhang, Y.; Cao, F.; Qu, T.; Sun, X. Improved YOLOv8 track foreign object detection based on lightweight convolution and information enhancement. In Proceedings of the 2024 14th Asian Control Conference (ASCC), Dalian, China, 5–8 July 2024; pp. 1260–1265. [Google Scholar]
- Wang, Y.; Pan, F.; Li, Z.; Xin, X.; Li, W. CoT-YOLOv8: Improved YOLOv8 for aerial images small target detection. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 4943–4948. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 214–230. [Google Scholar]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z. An improved faster R-CNN for small object detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.-I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Liu, H.-I.; Tseng, Y.-W.; Chang, K.-C.; Wang, P.-J.; Shuai, H.-H.; Cheng, W.-H. A denoising FPN with transformer R-CNN for tiny object detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704415. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | Configuration Information |
|---|---|
| System | Windows 10 |
| GPUs | NVIDIA GeForce RTX 4070 |
| CPU | 13th Gen intel(R) Core (TM) i5-13490F 2.50 GHz |
| Language | Python 3.9 |
| GPU calculate platform | CUDA 12.1 |
| Deep learning framework | Pytorch 2.2.0 |
| P | R | mAP50 | mAP50-95 | Parameters | Layers | Detection Speed (s) | GFLOPs | |
|---|---|---|---|---|---|---|---|---|
| yolov8n | 0.849 | 0.803 | 0.829 | 0.513 | 3,011,043 | 225 | 0.55 | 8.2 |
| yolov8-LAWDS (all) | 0.866 | 0.784 | 0.837 | 0.516 | 2,681,123 | 260 | 0.576 | 8.1 |
| yolov8-LAWDS (neck) | 0.871 | 0.782 | 0.831 | 0.516 | 2,959,331 | 239 | 0.54 | 8.3 |
| yolov8-LAWDS (backbone) | 0.866 | 0.796 | 0.836 | 0.506 | 2,732,835 | 246 | 0.492 | 8 |
| P | R | mAP50 | mAP50-95 | Parameters | Detection Speed (s) | |
|---|---|---|---|---|---|---|
| YOLOv5n | 0.84 | 0.792 | 0.805 | 0.437 | 2,508,659 | 0.69 |
| YOLOv8n | 0.849 | 0.803 | 0.829 | 0.513 | 3,011,043 | 0.55 |
| YOLOv10n | 0.858 | 0.803 | 0.842 | 0.524 | 2,707,430 | 0.67 |
| LSOD-YOLOv8 | 0.868 | 0.805 | 0.857 | 0.535 | 2,141,477 | 0.64 |
| Model Structure | Evaluation Index | |||||||
|---|---|---|---|---|---|---|---|---|
| LAWDS | P2-LSCSBD | WIMIoU | P | R | mAP50 | mAP50-95 | Parameters | Detection Speed (s) |
| 0.849 | 0.803 | 0.829 | 0.513 | 3,011,043 | 0.55 | |||
| √ | 0.866 | 0.796 | 0.836 | 0.506 | 2,732,835 | 0.492 | ||
| √ | 0.867 | 0.799 | 0.848 | 0.538 | 2,926,692 | 0.508 | ||
| √ | 0.877 | 0.799 | 0.841 | 0.516 | 3,011,043 | 0.55 | ||
| √ | √ | 0.856 | 0.798 | 0.851 | 0.526 | 2,141,477 | 0.64 | |
| √ | √ | 0.869 | 0.81 | 0.847 | 0.513 | 2,367,460 | 0.408 | |
| √ | √ | 0.851 | 0.82 | 0.856 | 0.535 | 2,419,685 | 0.512 | |
| √ | √ | √ | 0.868 | 0.805 | 0.857 | 0.535 | 2,141,477 | 0.64 |
| Dataset | P | R | mAP50 | mAP50-95 | |
|---|---|---|---|---|---|
| YOLOv8n | cigarette | 0.849 | 0.803 | 0.829 | 0.513 |
| LSOD-YOLOv8 | cigarette | 0.868 | 0.805 | 0.857 | 0.535 |
| YOLOv8n | fire | 0.543 | 0.607 | 0.519 | 0.251 |
| LSOD-YOLOv8 | fire | 0.706 | 0.543 | 0.603 | 0.31 |
| YOLOv8n | waste | 0.985 | 0.987 | 0.994 | 0.873 |
| LSOD-YOLOv8 | waste | 0.996 | 0.991 | 0.995 | 0.911 |
| YOLOv8n | coco | 0.734 | 0.687 | 0.71 | 0.539 |
| LSOD-YOLOv8 | coco | 0.759 | 0.694 | 0.753 | 0.578 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Ouyang, H.; Miao, X. LSOD-YOLOv8: Enhancing YOLOv8n with New Detection Head and Lightweight Module for Efficient Cigarette Detection. Appl. Sci. 2025, 15, 3961. https://doi.org/10.3390/app15073961
Huang Y, Ouyang H, Miao X. LSOD-YOLOv8: Enhancing YOLOv8n with New Detection Head and Lightweight Module for Efficient Cigarette Detection. Applied Sciences. 2025; 15(7):3961. https://doi.org/10.3390/app15073961
Chicago/Turabian StyleHuang, Yijie, Huimin Ouyang, and Xiaodong Miao. 2025. "LSOD-YOLOv8: Enhancing YOLOv8n with New Detection Head and Lightweight Module for Efficient Cigarette Detection" Applied Sciences 15, no. 7: 3961. https://doi.org/10.3390/app15073961
APA StyleHuang, Y., Ouyang, H., & Miao, X. (2025). LSOD-YOLOv8: Enhancing YOLOv8n with New Detection Head and Lightweight Module for Efficient Cigarette Detection. Applied Sciences, 15(7), 3961. https://doi.org/10.3390/app15073961