
Temporal Enhancement of Top-N Recommendation on Heterogeneous Graphs


Abstract
1. Introduction
- (1)
- We propose a system for the temporal enhancement of top-N recommendations on HINs called TMRec. It can improve the performance of recommender systems by learning the temporal relations of nodes and meta-paths.
- (2)
- We adopt the architectures of LSTM and RSA for embedding the learning of users and items, which can highlight the temporal relations and interactions among users or items. This can also enhance the ability to learn heterogeneous information from these nodes.
- (3)
- We use DPSA with max pooling and L2-normalization to learn the interactions among users and items in meta-paths. Additionally, collaborative attention is introduced to obtain the interactions of meta-paths, users, and items.
- (4)
- Extensive experiments are conducted on four public datasets of recommender systems. The results demonstrate that the performance of the proposed TMRec model is largely improved compared with other SOTA models.
2. Related Work
2.1. Recommender Systems
2.2. Heterogeneous Information Networks and Network Embedding
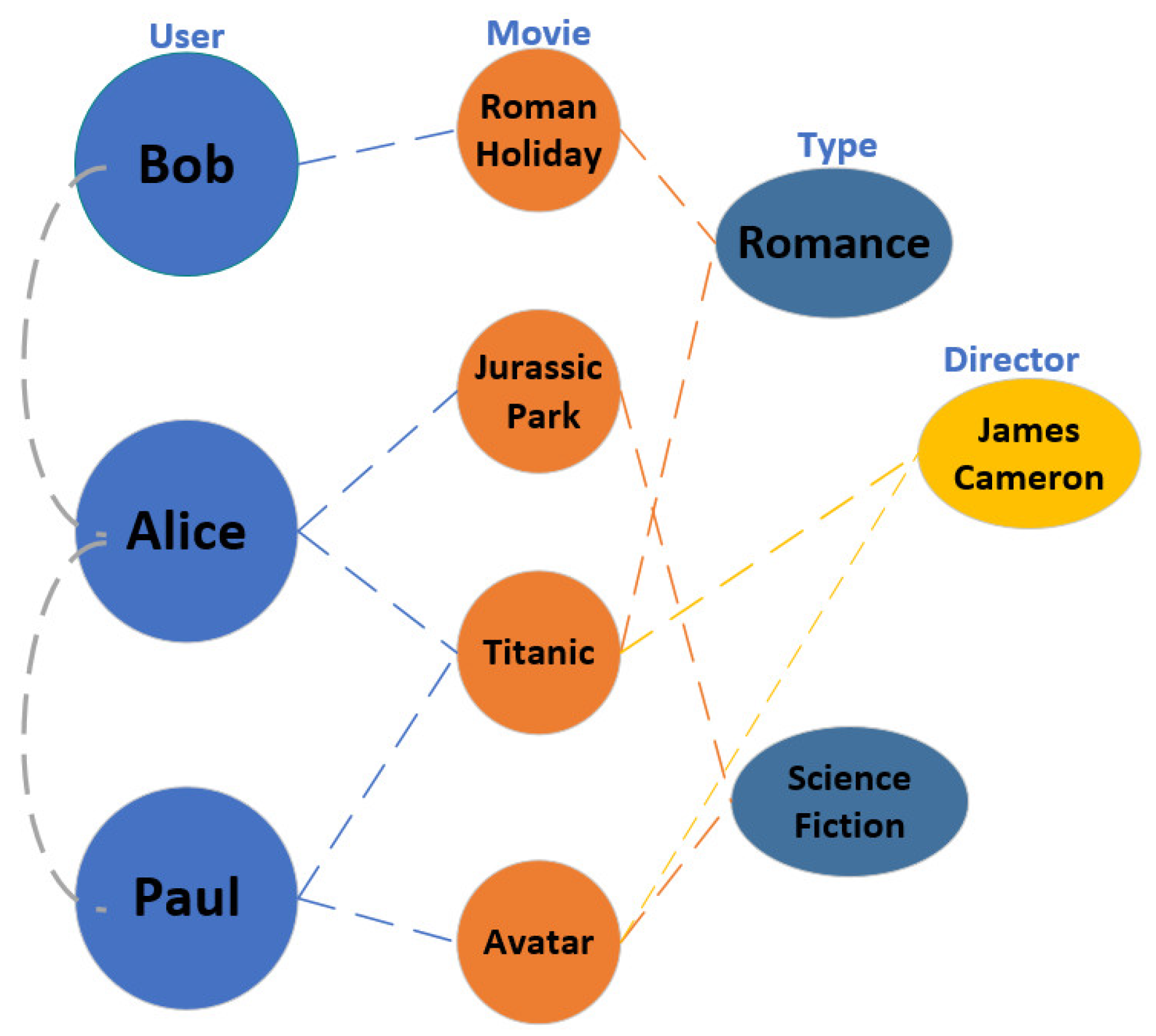
3. Preliminaries
4. The Proposed Model
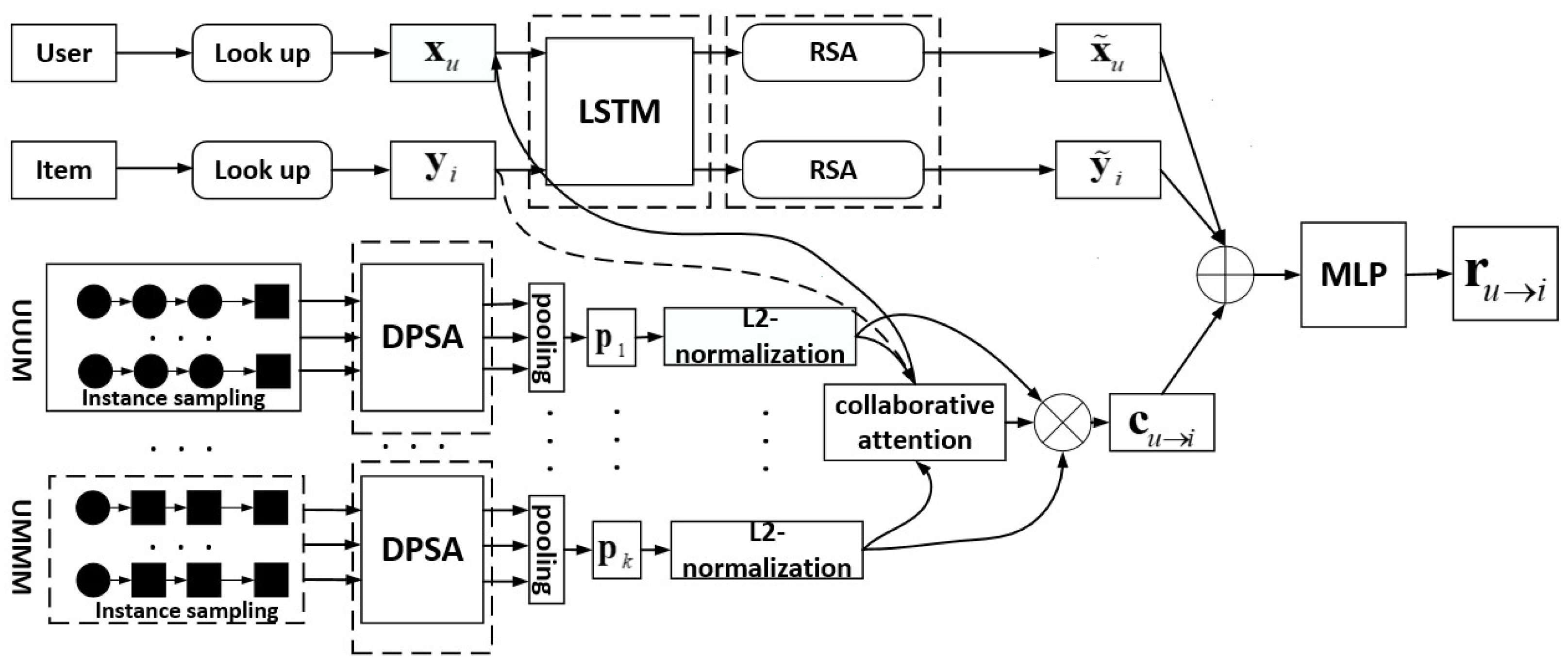
4.1. Overall Framework
4.2. User and Item Embeddings
4.3. Meta-Path Embedding
4.3.1. Sampling of High-Quality Path Instances
4.3.2. Single Meta-Path Embedding
4.3.3. Meta-Path Aggregation
4.4. Embedding Fusion
5. Experiments
5.1. Datasets and Metrics
5.2. Implementation Details
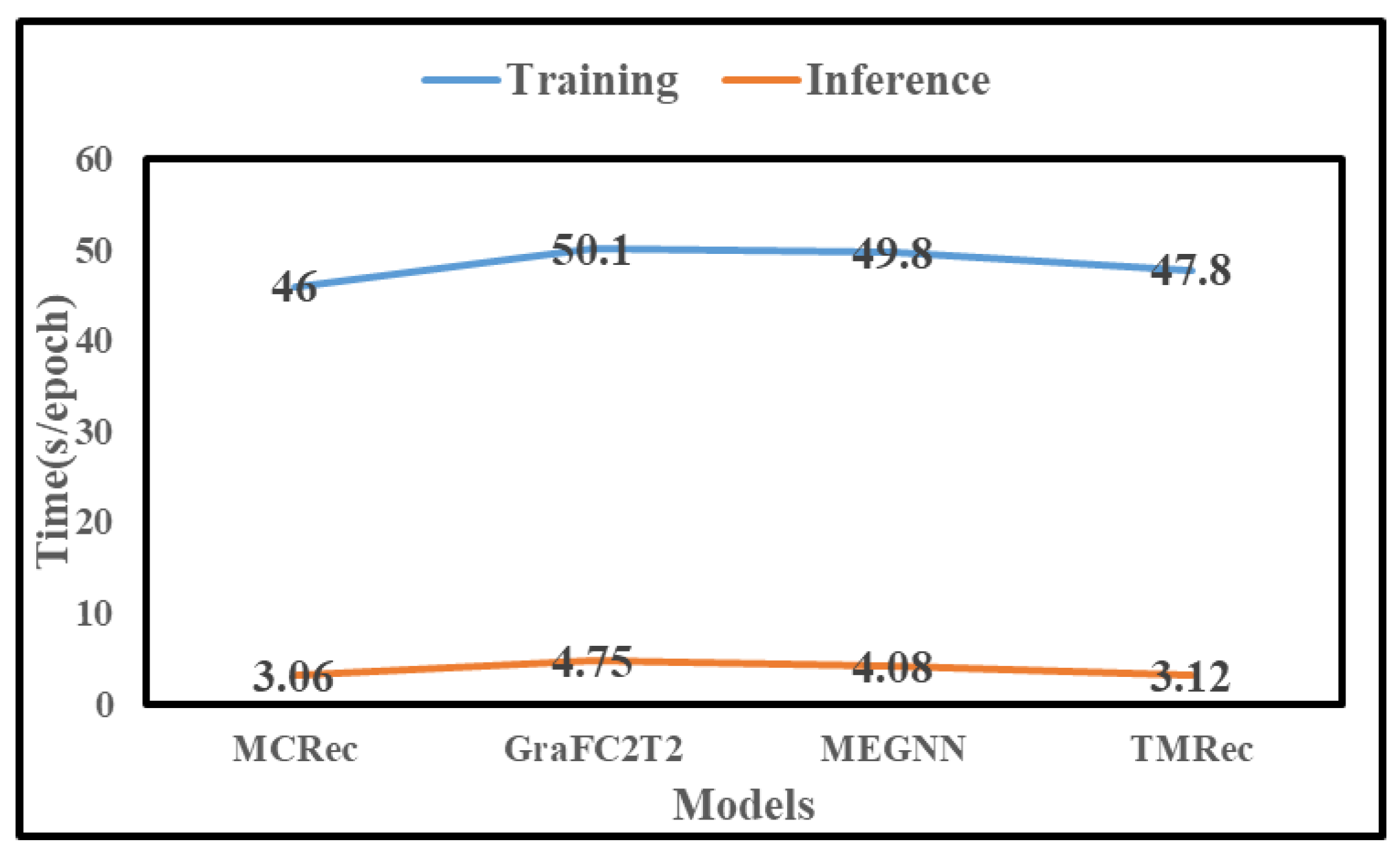
5.3. Experimental Results Analysis
- (1)
- ItemKNN [2]: It is a classical method of collaborative filtering using previous items as the reference. For example, if one wants to predict ’s rating on movie , one first needs to keep a list of k movies that has watched and evaluated and then give a prediction of the rating of by according to the historical ratings.
- (2)
- BPR [3]: It is a commonly used recommendation model in current recommender systems. Unlike other methods based on a user scoring matrix, it mainly adopts the users’ implicit feedback (such as clicks and favorites) to sort items through the maximum posterior probability obtained by the Bayesian analysis of problems and then generates recommendations.
- (3)
- MF [24]: It is proposed to solve the shortcomings of CF, which has a weak ability to process sparse matrices. It optimizes the MF model with the cross-entropy loss.
- (4)
- NCF [25]: It is a variant of the traditional collaborative filtering model. Since the previous inner product of collaborative filtering is too simple to perform well, it utilizes an MLP to replace this operation, combining neural networks and collaborative filtering.
- (5)
- HAN [13]: It adopts a hierarchical structure of the attention mechanism, including node-level and semantic-level attention. The former is used to distinguish the importance of nodes in a meta-path, while the latter is utilized to learn how much each meta-path contributes to the generation of the final embedding.
- (6)
- MCRec [16]: It is the first method to explicitly express meta-paths, which are combined with the user and item embeddings for recommendation. It also introduces the co-attention mechanism to mutually enhance the representations of meta-paths, users, and items.
- (7)
- GraFC2T2 [17]: It is a general graph-based framework that combines some side information for top-N recommendation. It encodes content-based features, and temporal and trust information into a complex graph and uses personalized PageRank on this graph to provide recommendations.
- (8)
- MEGNN [44]: It is capable of discovering and extracting the most expressive meta-paths and avoids manually defining multiple meta-paths. It also uses a heterogeneous convolution module to generate trainable heterogeneous graph structures.
- (1)
- The proposed TMRec consistently outperforms all baselines on the three datasets. The results show the effectiveness of TMRec in top-N recommendation tasks; the model considers the temporal relations of nodes of different kinds and the mutual influence of nodes of the same type in user and item embedding learning.
- (2)
- It can be clearly seen that when comparing the two different types of methods, HIN-based methods perform better than CF-based methods in general. As HIN-based methods can catch richer semantic information, they are particularly useful in addressing cold-start problems in recommendation. Therefore, they have been more widely used in recommendation tasks, especially when there are many different types of nodes and links in a dataset.
- (3)
- TMRec outperforms HAN, MCRec, and MEGNN among the HIN-based methods. HAN utilizes a hierarchical attention mechanism at the node and semantic levels, while MCRec employs a co-attention mechanism for the user, item, and meta-path embeddings. In addition, MEGNN considers the selection of meta-paths without considering the explicit expression of the meta-paths. In contrast, the proposed TMRec model uses co-attention in meta-path embedding learning and self-attention in user and item embedding learning. From the above results, we can find that the co-attention mechanism is more suitable for paths composed of different types of nodes, while the self-attention mechanism is more useful for paths composed of nodes of the same type. In addition, although GraFC2T2 considers the temporal information among different entities, its ability to capture heterogeneous information is limited. Therefore, the proposed TMRec achieves better performance than GraFC2T2 because of important components such as LSTM, RSA, and DPSA.
- (4)
- We can see from Table 2 that Prec@10, Recall@10, and NDCG@10 are increased by 0.0406, 0.0395, and 0.0448, respectively, compared with the average values of the comparison models on the LastFM dataset and by 0.0359, 0.0323, and 0.0412, respectively, on the Movielens dataset. These experimental results demonstrate that the proposed TMRec has better performance in these scenarios. In contrast to these two datasets, Prec@10, Recall@10 and NDCG@10 are increased by 0.0359, 0.0323, and 0.0412, respectively, compared with the average values of the comparison models on the Yelp dataset. Although TMRec’s advantage over the other models is relatively lower on the Yelp dataset, it still exhibits better recommendation performance.
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Ma, W.; Zhang, M. A survey on the fairness of recommender systems. ACM Trans. Inf. Syst. 2023, 41, 52. [Google Scholar]
- Kabul, M.S.; Setiawan, E.B. Recommender System with User-Based and Item-Based Collaborative Filtering on Twitter using K-Nearest Neighbors Classification. J. Comput. Syst. Inform. 2022, 3, 478–484. [Google Scholar] [CrossRef]
- Paul, A.; Wu, Z.; Liu, K.; Gong, S. Robust multi-objective visual bayesian personalized ranking for multimedia recommendation. Appl. Intell. 2022, 52, 3499–3510. [Google Scholar]
- He, Z.; Hui, B.; Zhang, S.; Xiao, C.; Zhong, T.; Zhou, F. Exploring indirect entity relations for knowledge graph enhanced recommender system. Expert Syst. Appl. 2023, 213, 11898. [Google Scholar]
- Qu, Y.; Fang, B.; Zhang, W.; Tang, R.; Niu, M.; Guo, H.; Yu, Y.; He, X. Product-based neural networks for user response prediction over multi-field categorical data. ACM Trans. Inf. Syst. 2018, 37, 5. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Gori, M.; Pucci, A.; Roma, V.; Passerini, A.; Frasconi, P. Itemrank: A random-walk based scoring algorithm for recommender engines. In Proceedings of the International Joint Conferences on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 2766–2771. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Li, Y.; King, I.; Lyu, M.R. Recommender systems with social regularization. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Lu, Y.; Dong, R.; Smyth, B. Coevolutionary recommendation model: Mutual learning between ratings and reviews. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 773–782. [Google Scholar]
- Yu, F.; Cui, L.; Guo, W.; Lu, X.; Li, Q.; Lu, H. A category-aware deep model for successive POI recommendation on sparse check-in data. In Proceedings of the Web Conference 2020, Virtual, 20–24 April 2020; pp. 1264–1274. [Google Scholar]
- Liu, J.; Song, L.; Wang, G.; Shang, X. Meta-HGT: Metapath-aware HyperGraph Transformer for heterogeneous information network embedding. Neural Netw. 2023, 157, 65–76. [Google Scholar]
- Han, Z.; Jin, X.; Xing, H.; Yang, W.; Xiong, H. An effective heterogeneous information network representation learning framework. Future Gener. Comput. Syst. 2023, 148, 66–78. [Google Scholar]
- Wang, X.; Bo, D.; Shi, C.; Fan, S. A survey on heterogeneous graph embedding: Methods, techniques, applications and sources. IEEE Trans. Big Data 2022, 9, 415–436. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Cui, P.; Yu, P.; Ye, Y. Heterogeneous graph attention network. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Chen, J.; Gong, Z.; Li, Y.; Zhang, H.; Yu, H.; Zhu, J.; Fan, G.; Wu, X.-M.; Wu, K. Meta-path based neighbors for behavioral target generalization in sequential recommendation. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1658–1667. [Google Scholar]
- Hu, B.; Shi, C.; Zhao, W.X.; Yu, P.S. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1531–1540. [Google Scholar]
- Nzeko’o, A.; Tchuente, M.; Latapy, M. A general graph-based framework for top-N recommendation using content, temporal and trust information. J. Interdiscip. Methodol. Issues Sci. 2019, 5, 5553. [Google Scholar]
- Xu, E.; Zhao, K.; Yu, Z.; Zhang, Y. Limits of predictability in top-N recommendation. Inf. Process. Manag. 2024, 61, 103731. [Google Scholar]
- Duan, J.; Zhang, P.F.; Qiu, R.; Huang, Z. Long short-term enhanced memory for sequential recommendation. World Wide Web 2023, 26, 561–583. [Google Scholar] [CrossRef]
- Wu, W.; Liu, S.; Xia, Y.; Zhang, Y. Dual residual attention network for image denoising. Pattern Recognit. 2024, 149, 110291. [Google Scholar] [CrossRef]
- Chen, M.; Ma, T.; Zhou, X. CoCNN: Co-occurrence CNN for recommendation. Expert Syst. Appl. 2022, 195, 116595. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Yu, P.S. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Koren, Y.; Rendle, S.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: New York, NY, USA, 2021; pp. 91–142. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Wu, L.; Sun, P.; Fu, Y.; Hong, R.; Wang, X.; Wang, M. A neural influence diffusion model for social recommendation. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 235–244. [Google Scholar]
- Yin, H.; Sun, Y.; Cui, B.; Hu, Z.; Chen, L. LCARS: A location-content-aware recommender system. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 221–229. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. Proc. AAAI Conf. Artif. Intell. 2016, 30, 144–150. [Google Scholar] [CrossRef]
- Jin, J.; Qin, J.; Fang, Y.; Du, K.; Zhang, W.; Yu, Y.; Zhang, Z.; Smola, A.J. An efficient neighborhood-based interaction model for recommendation on heterogeneous graph. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual, 23–27 August 2020; pp. 75–84. [Google Scholar]
- Ji, M.; Sun, Y.; Danilevsky, M.; Han, J.; Gao, J. Graph regularized transductive classification on heterogeneous information networks. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010; pp. 570–586. [Google Scholar]
- Sun, Y.; Aggarwal, C.C.; Han, J. Relation Strength-Aware Clustering of Heterogeneous Information Networks with Incomplete Attributes. 2012. Available online: https://arxiv.org/abs/1201.6563 (accessed on 9 February 2025).
- Chen, H.; Yin, H.; Wang, W.; Wang, H.; Nguyen, Q.V.H.; Li, X. PME: Projected metric embedding on heterogeneous networks for link prediction. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1177–1186. [Google Scholar]
- Chen, T.; Sun, Y. Task-guided and path-augmented heterogeneous network embedding for author identification. In Proceedings of the ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 295–304. [Google Scholar]
- Zhou, S.; Bu, J.; Wang, X.; Chen, J.; Wang, C. HAHE: Hierarchical Attentive Heterogeneous Information Network Embedding. 2019. Available online: https://arxiv.org/abs/1902.01475 (accessed on 9 February 2025).
- Li, J.; Wu, L.; Hong, R.; Hou, J. Random walk based distributed representation learning and prediction on social networking services. Inf. Sci. 2021, 549, 328–346. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Fu, T.; Lee, W.C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Xu, L.; Wei, X.; Cao, J.; Yu, P.S. Embedding of embedding (EOE) joint embedding for coupled heterogeneous networks. In Proceedings of the ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 741–749. [Google Scholar]
- Zhao, J.; Wang, X.; Shi, C.; Hu, B.; Song, G.; Ye, Y. Heterogeneous graph structure learning for graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 4697–4705. [Google Scholar]
- Liu, J.; Shi, C.; Hu, B.; Chen, K.; Zheng, Z.; Yu, Y. Personalized ranking recommendation via integrating multiple feedbacks. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2017; pp. 131–143. [Google Scholar]
- Chen, T.; Zhang, W.; Lu, Q.; Chen, K.; Zheng, Z.; Yu, Y. SVDFeature: A toolkit for feature-based collaborative filtering. J. Mach. Learn. Res. 2012, 13, 3619–3622. [Google Scholar]
- Yan, S.; Wang, H.; Li, Y.; Zheng, Y.; Han, L. Attention-aware metapath-based network embedding for HIN based recommendation. Expert Syst. Appl. 2021, 174, 11460. [Google Scholar]
- Chang, Y.; Chen, C.; Hu, W.; Zheng, Z.; Zhou, X.; Chen, S. Megnn: Meta-path extracted graph neural network for heterogeneous graph representation learning. Knowl.-Based Syst. 2022, 235, 107611. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| User’s embedding after lookup layer | |
| Item’s embedding after lookup layer | |
| Low-dimensional representations of users | |
| Low-dimensional representations of items | |
| Improved user’s embedding after LSTM module | |
| Final user’s embedding after self-attention mechanism | |
| Final item’s embedding after self-attention mechanism | |
| Embedding of path instance p | |
| Initial embedding of meta-path | |
| Embedding of meta-path after L2-normalization | |
| Final embedding of meta-path after co-attention mechanism module | |
| Embedding of final fusion |
| Model | Movielens | LastFM | Yelp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Prec@10 | Recall@10 | NDCG@10 | Prec@10 | Recall@10 | NDCG@10 | Prec@10 | Recall@10 | NDCG@10 | |
| ItemKNN | 0.2578 | 0.1536 | 0.5692 | 0.4160 | 0.4513 | 0.7981 | 0.1386 | 0.5421 | 0.5378 |
| BPR | 0.3011 | 0.1946 | 0.6459 | 0.4129 | 0.4492 | 0.8099 | 0.1403 | 0.5651 | 0.5531 |
| MF | 0.3247 | 0.2053 | 0.6511 | 0.4364 | 0.4634 | 0.7921 | 0.1481 | 0.5991 | 0.6011 |
| NCF | 0.3256 | 0.2165 | 0.6682 | 0.454 | 0.4678 | 0.8104 | 0.1490 | 0.6001 | 0.6007 |
| HAN | 0.3356 | 0.2155 | 0.6845 | 0.4720 | 0.4978 | 0.8421 | 0.1602 | 0.6123 | 0.6134 |
| MCRec | 0.3415 | 0.2213 | 0.6876 | 0.4770 | 0.5028 | 0.8491 | 0.1674 | 0.6312 | 0.6300 |
| GraFC2T2 | 0.3400 | 0.2181 | 0.6866 | 0.4764 | 0.4991 | 0.8433 | 0.1652 | 0.6212 | 0.6274 |
| MEGNN | 0.3410 | 0.2214 | 0.6861 | 0.4773 | 0.5018 | 0.8490 | 0.1670 | 0.6305 | 0.6305 |
| TMRec | 0.3568 | 0.2381 | 0.7011 | 0.4933 | 0.5186 | 0.8691 | 0.1851 | 0.6497 | 0.6485 |
| Model | TMRec | TMRec-DPSA | TMRec-LSTM | TMRec-RSA | |
|---|---|---|---|---|---|
| Movielens | Prec@10 | 0.3568 | 0.3527 | 0.3561 | 0.3564 |
| Recall@10 | 0.2381 | 0.2338 | 0.2354 | 0.2355 | |
| NDCG@10 | 0.7011 | 0.6995 | 0.7002 | 0.7007 | |
| LastFM | Prec@10 | 0.4933 | 0.4869 | 0.4912 | 0.4917 |
| Recall@10 | 0.5186 | 0.5149 | 0.5173 | 0.5177 | |
| NDCG@10 | 0.8681 | 0.8642 | 0.8630 | 0.8639 | |
| Yelp | Prec@10 | 0.1851 | 0.1805 | 0.1823 | 0.1827 |
| Recall@10 | 0.6497 | 0.6436 | 0.6471 | 0.6475 | |
| NDCG@10 | 0.6485 | 0.6442 | 0.6453 | 0.6458 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, F.; Lin, J. Temporal Enhancement of Top-N Recommendation on Heterogeneous Graphs. Appl. Sci. 2025, 15, 3929. https://doi.org/10.3390/app15073929
Hu F, Lin J. Temporal Enhancement of Top-N Recommendation on Heterogeneous Graphs. Applied Sciences. 2025; 15(7):3929. https://doi.org/10.3390/app15073929
Chicago/Turabian StyleHu, Feng, and Jun Lin. 2025. "Temporal Enhancement of Top-N Recommendation on Heterogeneous Graphs" Applied Sciences 15, no. 7: 3929. https://doi.org/10.3390/app15073929
APA StyleHu, F., & Lin, J. (2025). Temporal Enhancement of Top-N Recommendation on Heterogeneous Graphs. Applied Sciences, 15(7), 3929. https://doi.org/10.3390/app15073929