1. Introduction
The rapid advancement of ICT (information and communication technologies), including AI (Artificial Intelligence), IoT (Internet of Things), and telecommunications, has led to an exponential increase in data generation and utilization [
1,
2]. Ensuring robust data security is essential, particularly for sensitive information such as financial records, medical data, and digital multimedia content, which are vulnerable to piracy, copyright infringement, and data breaches [
3,
4]. As data size and complexity grow, efficient computational methods and strong encryption algorithms have become indispensable [
5,
6].
The surge in big data has introduced challenges in maintaining data confidentiality and integrity during storage, transmission, and processing [
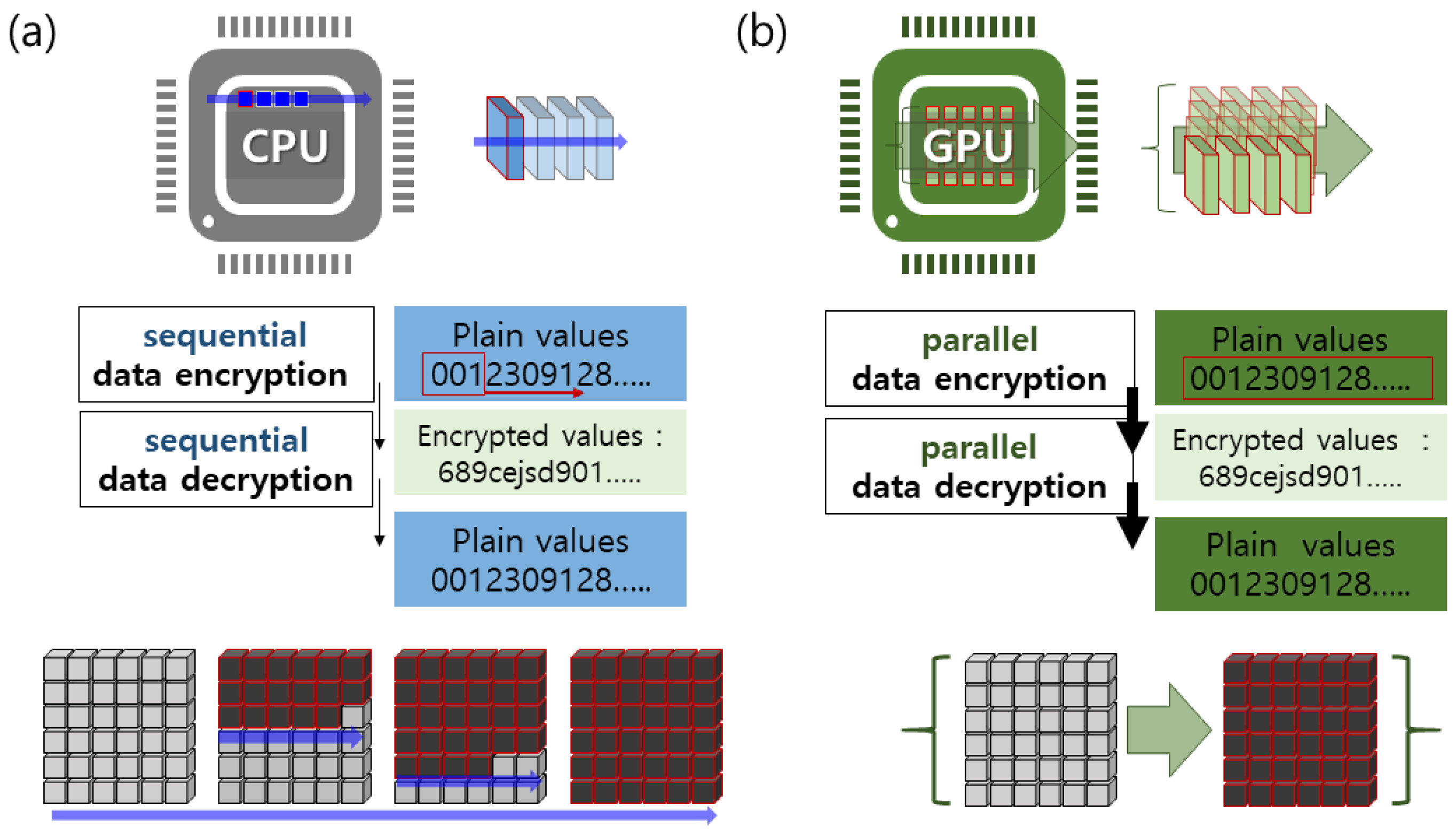
7]. Traditional CPU (Central Processing Unit)-based encryption methods, though reliable, often struggle with the computational demands of large-scale operations, leading to performance bottlenecks [
8,
9]. Parallel computing solutions, particularly GPUs (Graphics Processing Units), have emerged as effective tools due to their high throughput and parallel processing capabilities [
10].
GPUs, initially designed for graphics rendering, have evolved into versatile parallel processors capable of handling complex mathematical operations, making them suitable for cryptographic tasks [
2,
11,
12]. GPU acceleration enhances encryption and decryption processes and supports real-time data security applications in cloud computing, multimedia streaming, and secure communications [
13,
14,
15].
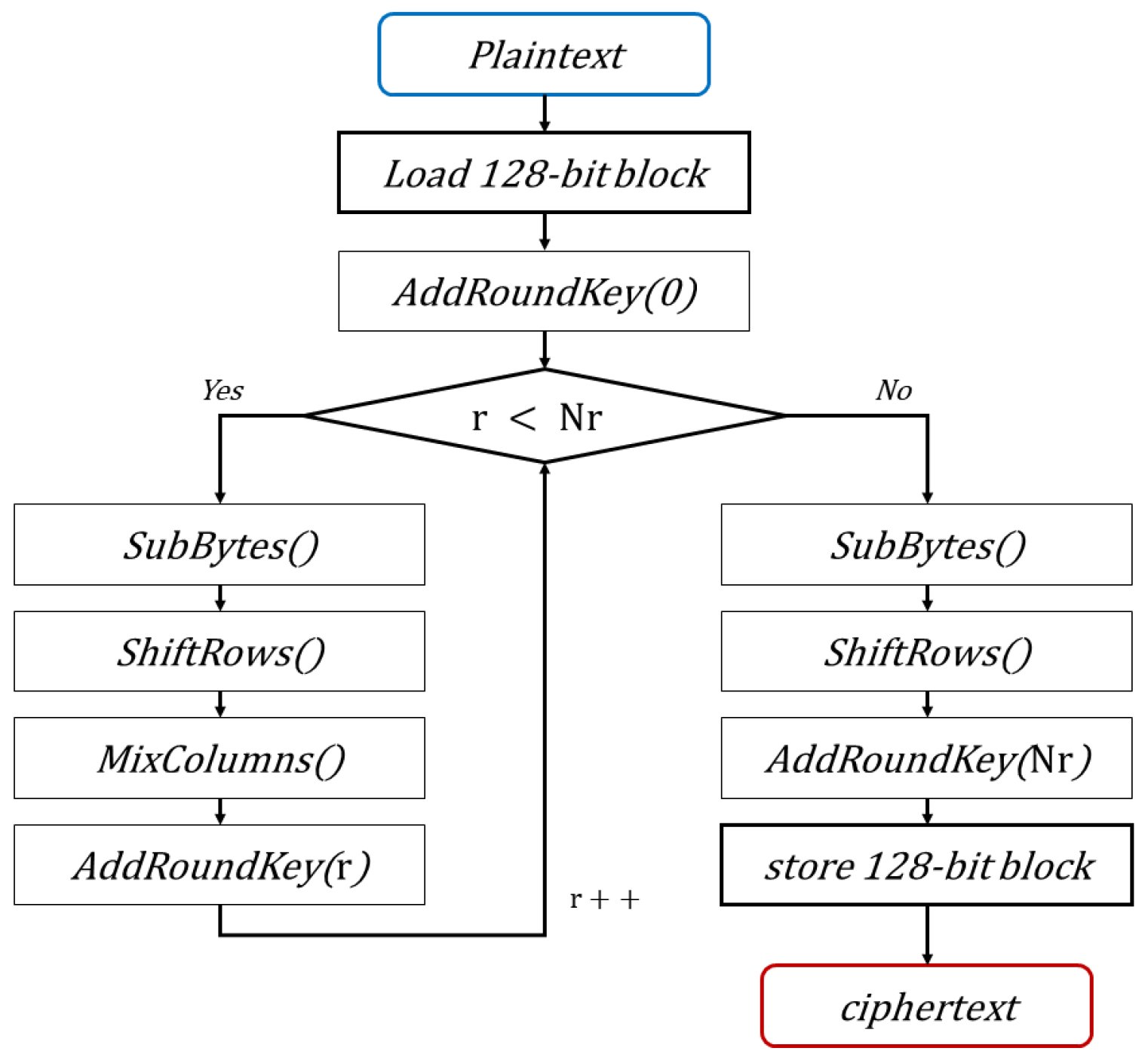
AES (Advanced Encryption Standard) [
9,
10], standardized by NIST (National Institute of Standards and Technology), remains a cornerstone of symmetric encryption for its balance of security, performance, and adaptability [
16]. AES-128 is widely used for its efficiency and strong security [
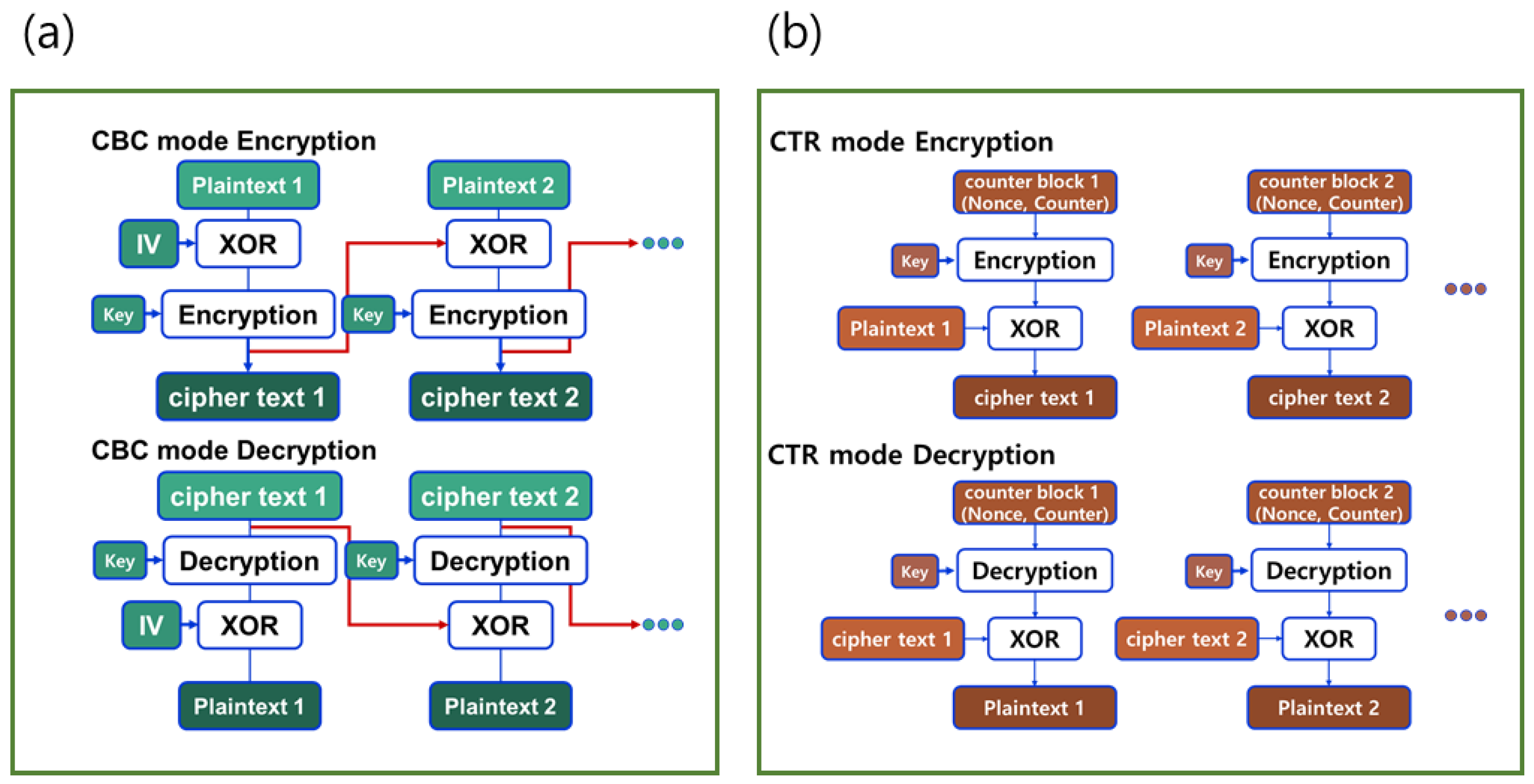
17]. However, the sequential nature of CBC (Cipher Block Chaining) mode poses challenges for parallel encryption, whereas CTR (Counter Mode) mode’s inherent parallelism is well suited for GPU acceleration [
18].
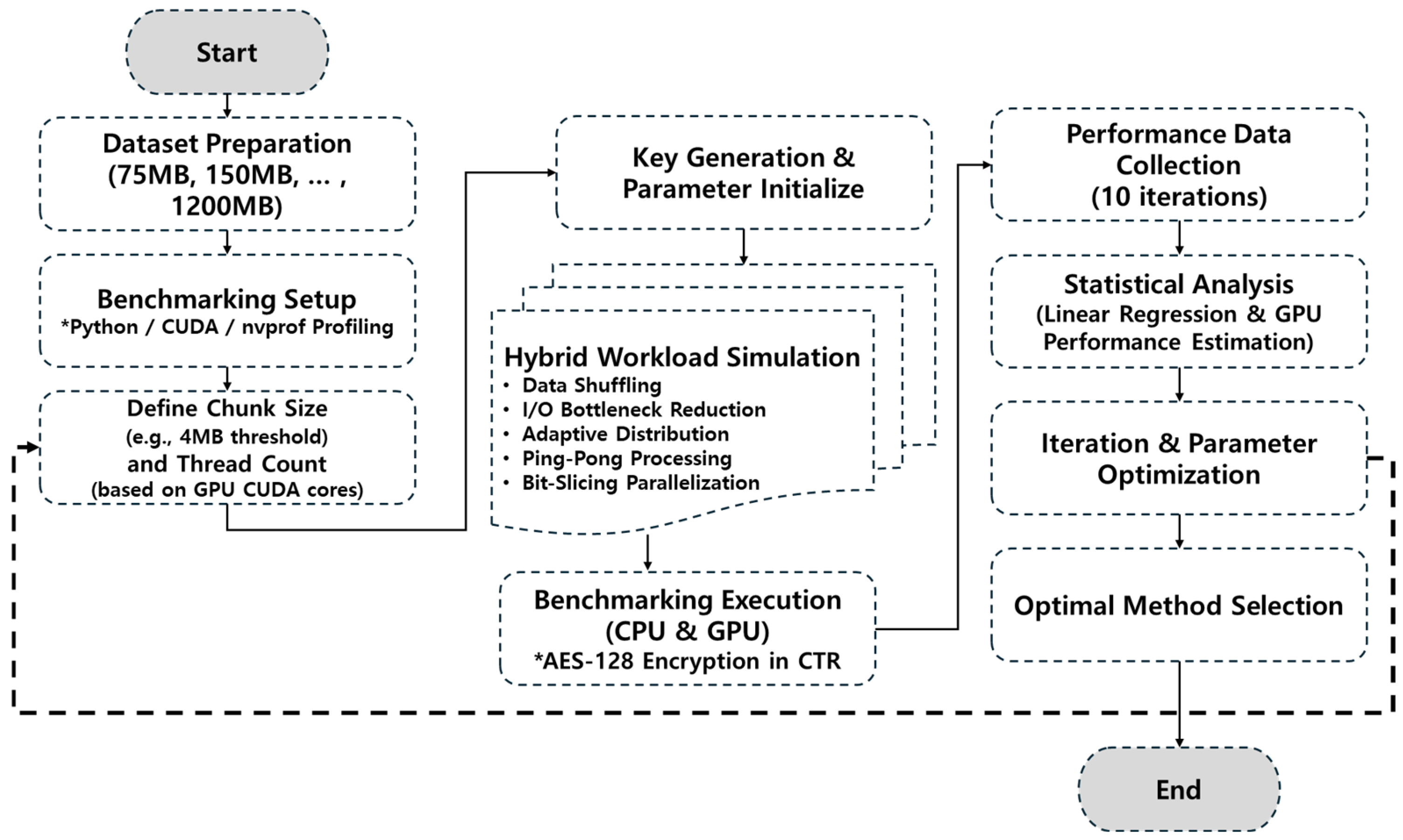
This study benchmarks AES encryption in CBC and CTR modes across multiple CPU and GPU models, comparing their encryption performance. It emphasizes the benefits of GPU acceleration and presents a hybrid CPU–GPU workflow that optimizes performance and resource utilization based on data size and operational requirements. The growing demand for scalable and efficient encryption solutions in data-intensive applications underscores the significance of this study. By harnessing the parallelism of GPUs and the flexibility of CPUs, the proposed hybrid approach balances speed and resource efficiency, making it suitable for modern encryption needs. Experiments applied AES encryption in CBC and CTR modes across different CPU and GPU hardware models, analyzing performance under varying data sizes. Performance data and mathematical models were used to calculate encryption times, GPU resource utilization, and cost-performance metrics. Results demonstrated that GPUs significantly accelerate large-scale data encryption, while the hybrid CPU–GPU approach enhances performance for specific workloads. This study highlights the importance of hardware selection for cryptographic tasks and illustrates the effectiveness of integrating theoretical models with performance analysis. Practical applications of the proposed hybrid workflow include cloud computing, data centers, and real-time processing systems, with detailed background on GPU architecture, encryption challenges, and prior research on parallel cryptographic processing to provide a comprehensive context. The existing CPU-only encryption methods face limitations in processing large-scale data efficiently, while GPU-only methods can suffer from suboptimal resource utilization and I/O bottlenecks. This study aims to bridge this gap by proposing and evaluating a hybrid CPU–GPU encryption workflow.
The objective of this study is to benchmark AES encryption performance across various CPU and GPU hardware models, highlighting the computational benefits provided by GPU acceleration. Additionally, we propose an optimized hybrid CPU–GPU workflow designed to balance workload distribution efficiently, tailored to specific data sizes and operational scenarios. To achieve this, we first formulate the research problem and identify key computational bottlenecks in AES encryption (
Section 2.1). We then analyze CPU and GPU architectures (
Section 2.2) and describe the AES-128 algorithm, emphasizing CBC and CTR modes suitable for parallel computing (
Section 2.3). Next, we introduce our proposed conceptual hybrid CPU–GPU workflow and the structured experimental approach adopted for its evaluation (
Section 2.4). Subsequently, we present detailed descriptions of five hybrid encryption methods—data shuffling, I/O bottleneck reduction, adaptive workload distribution, ping-pong processing, and bit-slicing parallelization (
Section 2.5). Computational models and analyses applied to quantitatively evaluate performance improvements, resource utilization, and energy efficiency are detailed in (
Section 2.6). Finally, we describe the experimental environment, hardware specifications, and software tools employed to ensure reproducibility and validation of our results (
Section 2.7). The outcomes of our comprehensive evaluations demonstrate the effectiveness of the hybrid CPU–GPU encryption methods, offering valuable insights and practical guidelines for efficient large-scale data encryption.
4. Discussion
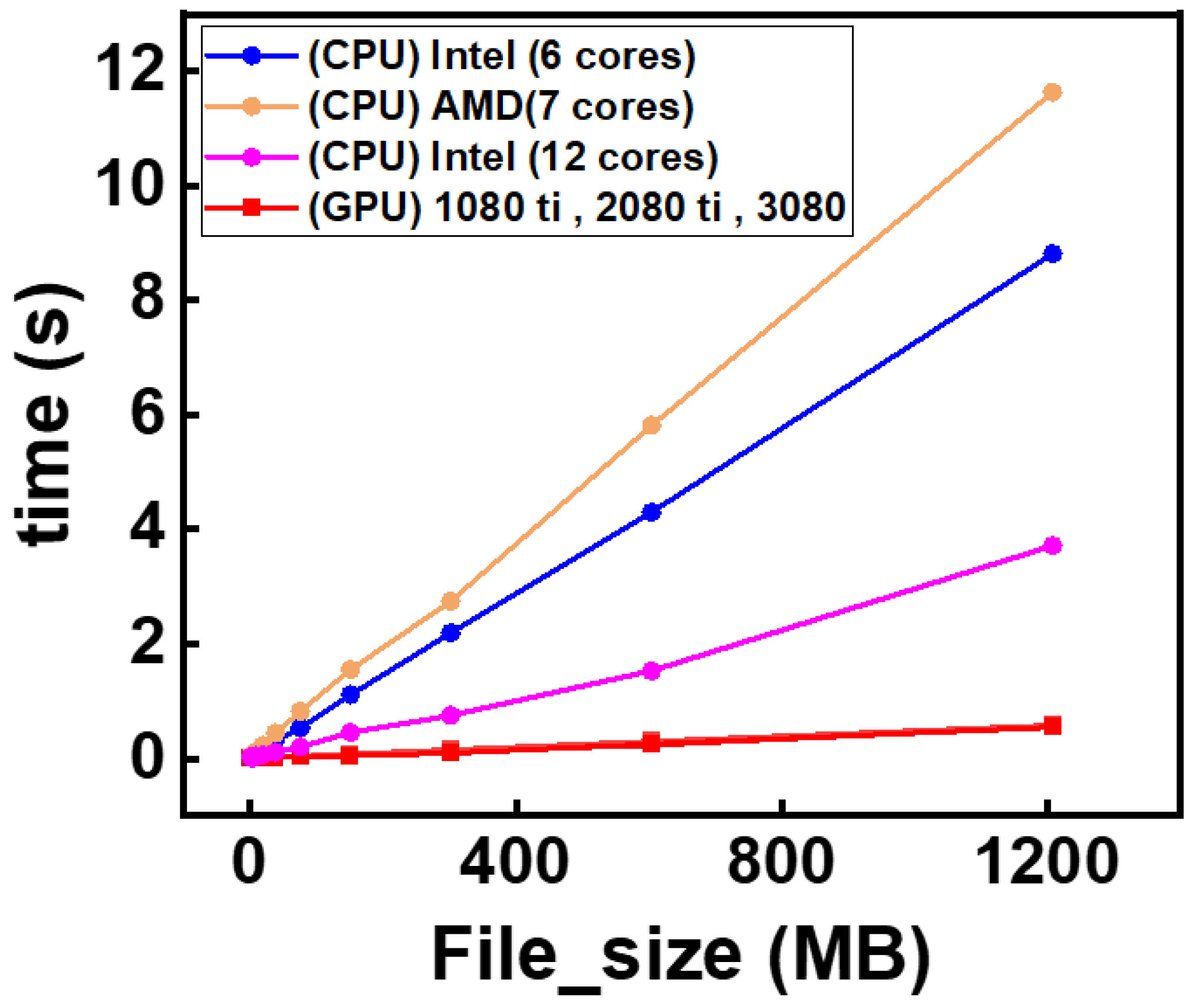
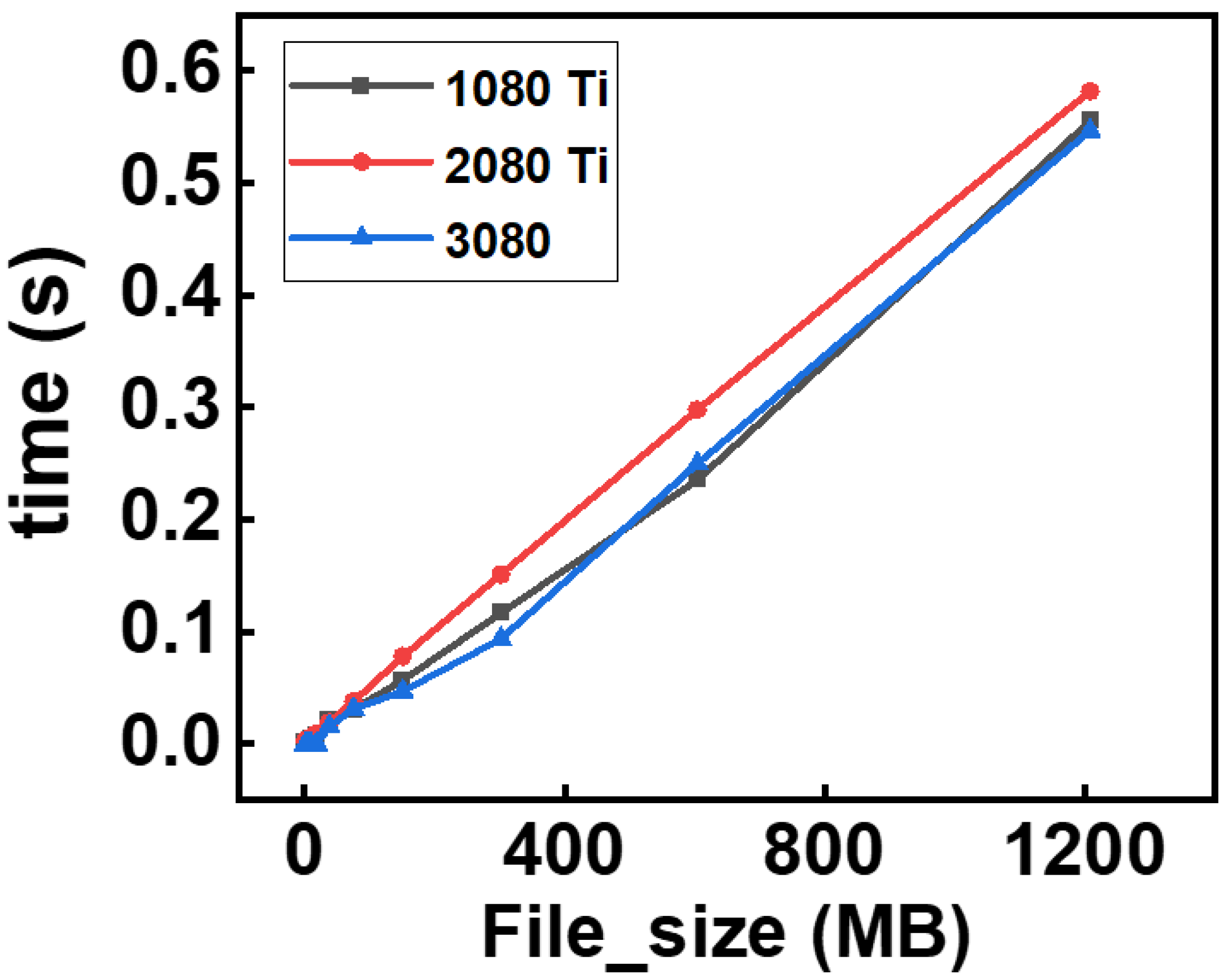
The results presented in this study highlight the significant performance advantages of GPU-based AES encryption over traditional CPU-based methods, particularly when handling large datasets. As demonstrated in
Figure 6 and
Figure 7, GPU acceleration substantially reduces encryption times, making it a viable solution for data-intensive applications such as cloud computing and real-time processing. This aligns with previous studies that emphasized the benefits of GPU parallelism for cryptographic operations, but our study extends these findings by integrating a hybrid CPU–GPU approach tailored for optimal workload distribution [
25,
26,
27].
The AES-CTR mode’s inherent parallelism facilitated efficient GPU utilization, while the CBC mode, though challenging due to its sequential dependency, benefited from our proposed hybrid methods. The bit-slicing parallelization method showed the highest performance improvement (35–40%), consistent with the theoretical advantages of bit-level parallelism highlighted. The adaptive workload distribution method, providing 15–25% improvement, reinforces the importance of dynamic task allocation in heterogeneous computing environments [
19,
28].
Our results also illustrate that while hardware advancements (such as increased CUDA cores and memory bandwidth in the RTX 3080) contribute to performance gains, the architectural differences among GPUs have a lesser impact than the employed encryption strategies. This finding is supported by prior research and underscores the importance of algorithmic optimization alongside hardware selection [
28,
29,
30]. Although our analysis identifies the number of CUDA cores and memory bandwidth as key contributors to GPU performance improvements, a deeper exploration into the interactions between GPU hardware architecture (such as warp scheduling, shared memory utilization, and cache hierarchies) and AES encryption algorithms would provide further insight. Profiling kernel execution patterns, analyzing memory access behaviors, and assessing cache hit/miss rates would provide valuable insights into optimizing encryption performance. Future studies should conduct in-depth profiling using GPU performance monitoring tools (e.g., NVIDIA Nsight and nvprof) to precisely quantify these interactions and further enhance the optimization of AES implementations on modern GPU architectures. Detailed profiling analysis, such as the examination of kernel execution patterns, shared memory access, and cache hit rates, should be conducted in future work to precisely quantify how these architectural features affect cryptographic performance. Such analyses would enhance understanding of the critical factors that optimize GPU-based encryption workflows and allow further optimization of AES implementations.
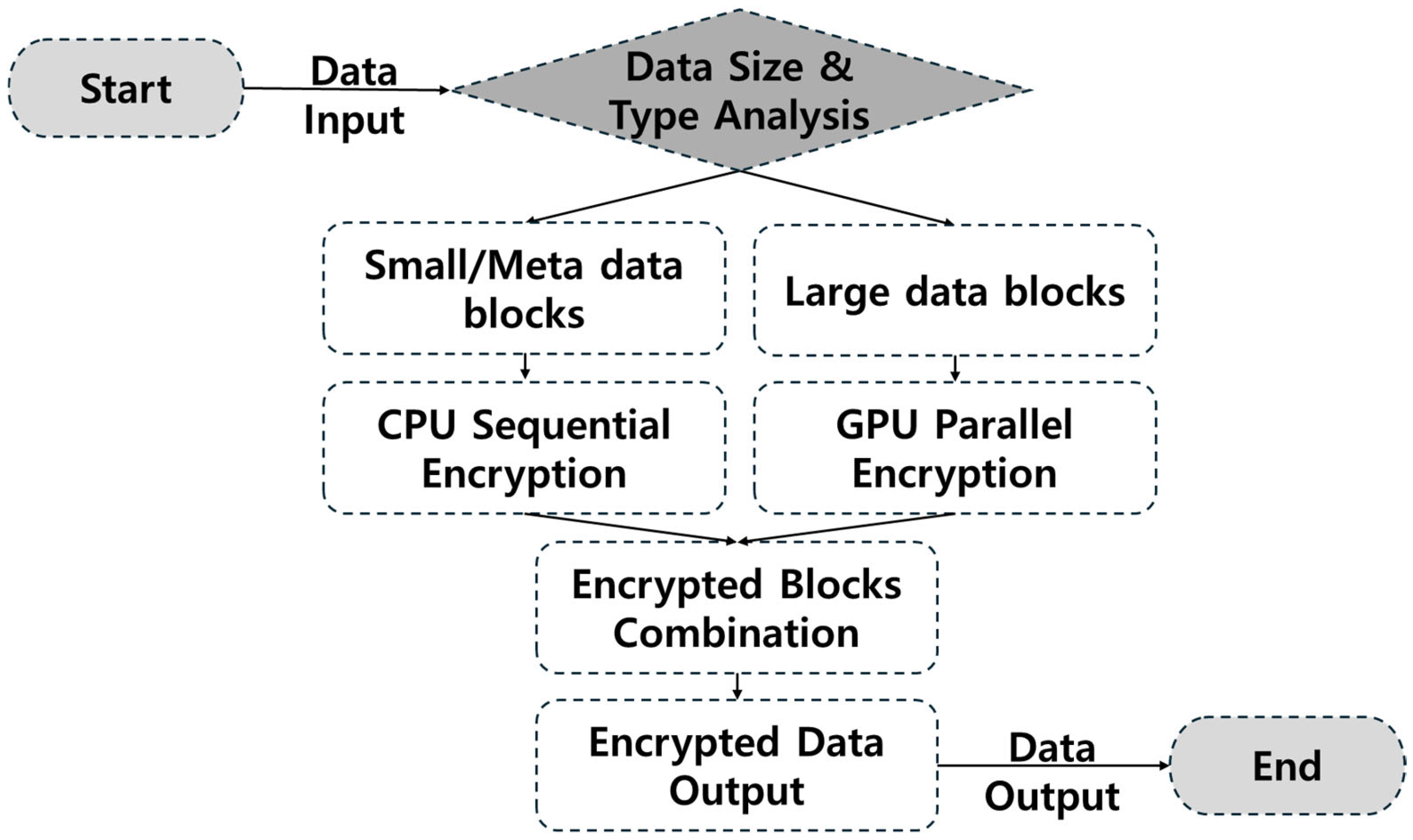
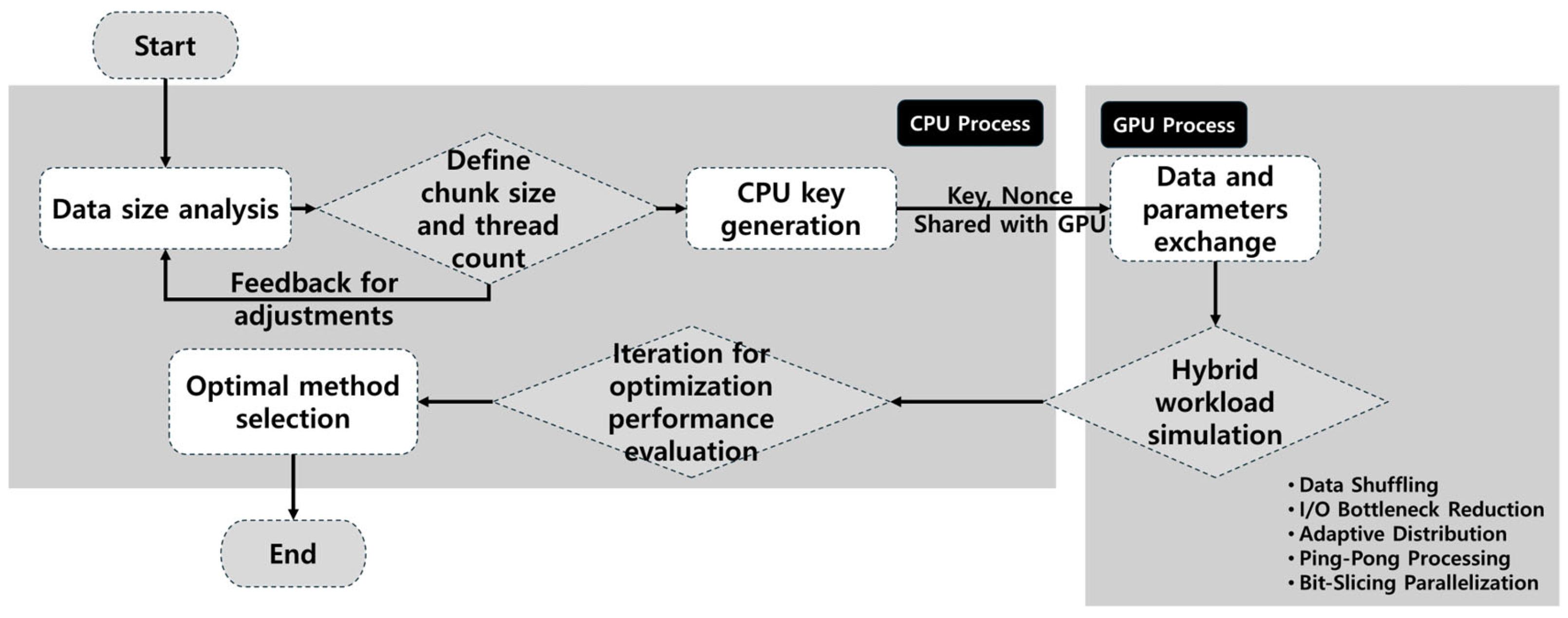
The hybrid CPU–GPU workflow, detailed in
Figure 8, offers a balanced approach by leveraging the strengths of both CPUs (for sequential tasks and control operations) and GPUs (for parallel data processing). This synergy not only enhances performance but also optimizes resource utilization, making it particularly suitable for large-scale data encryption in distributed systems and cloud environments.
Furthermore, our study introduces practical techniques to address common bottlenecks in GPU-based encryption, such as I/O data transfer latency. The proposed I/O bottleneck reduction method achieved a 20% improvement by minimizing GPU idle time through CPU pre-encryption, echoing similar strategies in recent works.
The implications of these findings are far-reaching. In an era where data security is paramount, our proposed hybrid encryption methods offer scalable solutions that can be integrated into the existing security infrastructures, enhancing both performance and security. Future research could explore adaptive hybrid models that dynamically adjust encryption strategies based on real-time performance metrics, further improving efficiency.
Additionally, integrating advanced GPU optimization techniques, such as tensor cores for cryptographic computations, presents an exciting avenue for future exploration. Investigating the impact of varying encryption key sizes (AES-192 and AES-256) on hybrid workflows could also provide valuable insights, as would applying similar hybrid strategies to other cryptographic algorithms like RSA or ECC.
5. Conclusions
This study conducted a detailed evaluation of AES-128 encryption performance across a range of CPU and GPU hardware platforms, with a focus on designing and validating an optimized hybrid CPU–GPU encryption framework. By analyzing both the serial (CBC) and parallel (CTR) modes, we identified key performance bottlenecks such as I/O latency and workload imbalance. To address these, we proposed five enhancement strategies: data shuffling, I/O bottleneck reduction, adaptive workload distribution, ping-pong processing, and bit-slicing parallelization.
The experimental results demonstrated that the hybrid methods notably improved encryption throughput across different file sizes and hardware setups. In particular, bit-slicing parallelization achieved the highest performance gains on large datasets, while adaptive workload distribution consistently reduced execution time variance. These findings confirm the effectiveness of combining CPU–GPU collaboration with tailored optimization techniques for high-performance cryptographic computing.
Despite these improvements, certain limitations remain. The study focused primarily on NVIDIA GPU architectures, and the results may vary when applied to AMD or Intel GPU platforms. Additionally, the research was limited to AES-128 encryption, while different key lengths (AES-192 and AES-256) could exhibit varied performance characteristics. Furthermore, operating system and driver variations were not explored, which could impact real-world encryption speeds.
Future research should address these limitations by extending hybrid CPU–GPU optimization techniques to heterogeneous GPU architectures and investigating performance implications for different AES key lengths. Additionally, real-time adaptive encryption models should be developed to dynamically allocate tasks based on system workload and power efficiency. The integration of emerging GPU architectures, such as those optimized for AI acceleration, into cryptographic frameworks presents another promising avenue for exploration.
The proposed hybrid encryption strategies pave the way for more scalable, efficient, and hardware-optimized data security solutions, contributing significantly to the broader field of high-performance cryptographic computing.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}