1. Introduction
1.1. Introduction of KG Inference Technology
As the key link in a complex product lifecycle, the assembly process comprises a series of characteristics such as high complexity, repeatability, standardization, and quality requirements. With the continuous development of intelligent manufacturing, a great deal of knowledge regarding the assembly process lacks unified expression and organization methods, which promoted the development of assembly process knowledge graph (KG) construction technology [
1]. In the assembly process KG construction, due to the fine granularity and high interaction of the assembly process, there are often issues concerning missing entities/relations and incorrect knowledge, leading to the research regarding KG inference tasks, including knowledge judgment, entity, and relation completion. Therefore, KG inference technology for KG construction has received significant attention and has become a hot research domain [
2]. Due to the fact that KG utilizes the triplet form of head entity, relation, and tail entity (
h,
r,
t) to express and store knowledge, current studies regarding KG inference for KG construction includes knowledge judgment [
3], entity completion, relation completion [
4], etc. Most existing KG inference models are oriented to the general domain and are expressed in triplet form (
h,
r,
t); these can be divided into three categories: logical rules-based inference models, embedded learning-based inference models, and deep learning-based inference models.
The logical rules-based inference model uses the inter-entity paths automatically obtained by the machine to fit the rules. The principle is to treat some paths as approximate rules, using these to further serve as a feature training learning model to judge whether there is a specified relation between entities [
5]. Typical representatives of this model type include rule inference based on a global structure, such as the path sorting algorithm (PRA) [
6] and the incomplete knowledge-based association rule mining algorithm (AMIE) [
7], and rule inference based on a local structure, such as the local feature extraction algorithm (SFE) [
8] and the hierarchical random walk inference algorithm (HiRi) [
9]. The inference model based on logical rules exhibits high interpretability and high inference accuracy when the rules are accurate, but the problem lies in the lack of more effective methods to mine complex rules, and the method is not easy to extend.
The main idea behind the embedded learning-based inference model is to design algorithms to project entities and relations into low-dimensional continuous vector space, learning the distributed semantic embedded of entities or relations [
10]. Typical representatives include translation distance-based embedded learning models, such as TransE with its variants [
11,
12], and semantic matching based embedded learning models, such as DistMult [
13] and ComplEx. The embedded learning inference model displays the advantage of high computational efficiency, alleviating data sparsity and realizing multi-source heterogeneous information fusion, but its prediction results are probabilistic and lack interpretability.
The deep learning-based inference model uses the powerful feature extraction ability of a neural network to map the feature distribution to another feature space to obtain corresponding feature representation, realizing complex semantic modeling for KG inference [
14]. Typical representatives include Conv E [
15], Path-RNN [
16], reinforcement learning-based methods [
17], etc. They exhibit innate advantages for complex problem inference, but are limited by the defects of deep learning itself and a lack of reliable interpretability of the results.
In addition, some scholars also try to mix different inference models to achieve complementary advantages. For example, the hybrid PRA algorithm proposed by Gardner [
18] combined the hybrid inference of embedded learning to sample the hidden features of the relation and embed them into the embedded learning model by converting them into feature vectors. Wei [
19] took the embedded learning model as a candidate set from prior screening and then analyzed the data using the data-driven inference algorithm of the Markov logic network. Lan [
20] proposed a novel method that injects rules and learns representations iteratively to take full advantage of rules and embedded learning model, employing an iterative method to continuously improve KGEs and remove incorrect rule conclusions. The current hybrid inference methods are mainly oriented towards general and triplet indicator graph data sets. Although the inference accuracy and interpretability are improved, the direct application of these methods to general domain KG inference is often ineffective.
1.2. Related Work
In the manufacturing domain, including assembly, encompassing processes like assembly, machining, and additive manufacturing, the existing KG inference methods are predominantly oriented towards applications such as knowledge recommendation [
21], process decision [
22], fault diagnosis [
23], quality prediction [
24], and others [
25]. However, there is a scarcity of studies regarding tasks such as knowledge completion and knowledge judgment oriented toward KG construction. For example, Ren [
26] proposed an attention-based graph embedded model (ABGE) for discovering and supplementing tacit missing relations in KGs to obtain a complete industrial KG. For additive manufacturing process, Haruna et al. [
27] adopted bidirectional entity/relation encoder based on BERT model to convert extracted relations and entities into vectors to support additive process knowledge inference. Du et al. [
28] proposed a manufacturing knowledge-oriented relation extraction model (MKREM), which uses the Bi-LSTM layer for word embedded to improve robustness, and uses the simplified Graph Convolutional network (SGC) layer to quickly mine entity information and complete relation information. Jiang et al. [
29] proposed a product innovation design method based on the tacit knowledge relation completion in the patent KG, which generates new relations and outputs novel knowledge by constructing an implicit relation completion model based on entity similarity. Yang et al. propose [
30] propose a time-varying KG (TVGN) based on knowledge embedment, and a time-varying KG (time-varying KG), which enables the context vector and global spatial semantic information to perceive and understand the environment in real time and update the environment.
From the analysis of KG inference studies regarding KG construction in the manufacturing domain, although researchers have incorporated diverse information to accurately express manufacturing knowledge, this added information remains unaccounted in KG inference for KG construction. In view of this, this paper proposes a KG inference method integrating logical rules and embedded learning for KG construction tasks such as knowledge judgment, entity and relation completion, which is used to solve the problem that domain KG lacks effective inference methods, and this method can be extended to KG inference tasks in other domains. The theoretical framework of the proposed approach is based on quintuple form to express assembly process knowledge and consider all information in quintuple to realize complete construction of assembly process KG.
The organization of this paper is as follows.
Section 2 introduces the KG inference method framework integrating logical rules and embedded learning. The proposed methodology is explained in
Section 3. The experiment to verify proposed method is carried out in
Section 4. At the end, conclusions and future work are highlighted.
2. KG Inference Method Framework Integrating Logical Rules and Embedded Learning
Assembly process KG construction refers to the process of transforming heterogeneous assembly process data into a structured KG. This process can be decomposed into two types of tasks: natural language processing tasks and knowledge inference tasks. Therein, knowledge inference tasks consist of knowledge judgment, entity completion and relation completion, which are significantly crucial for assembly process KG construction. In the process of assembly process KG construction, in addition to the entity and relation semantic information, entity type information is an important factor to reflect the difference between entities and mapping relation. Therefore, assembly process KG inference considering entity type is an effective way to improve the accuracy of assembly process KG inference and fast construction of assembly process KG.
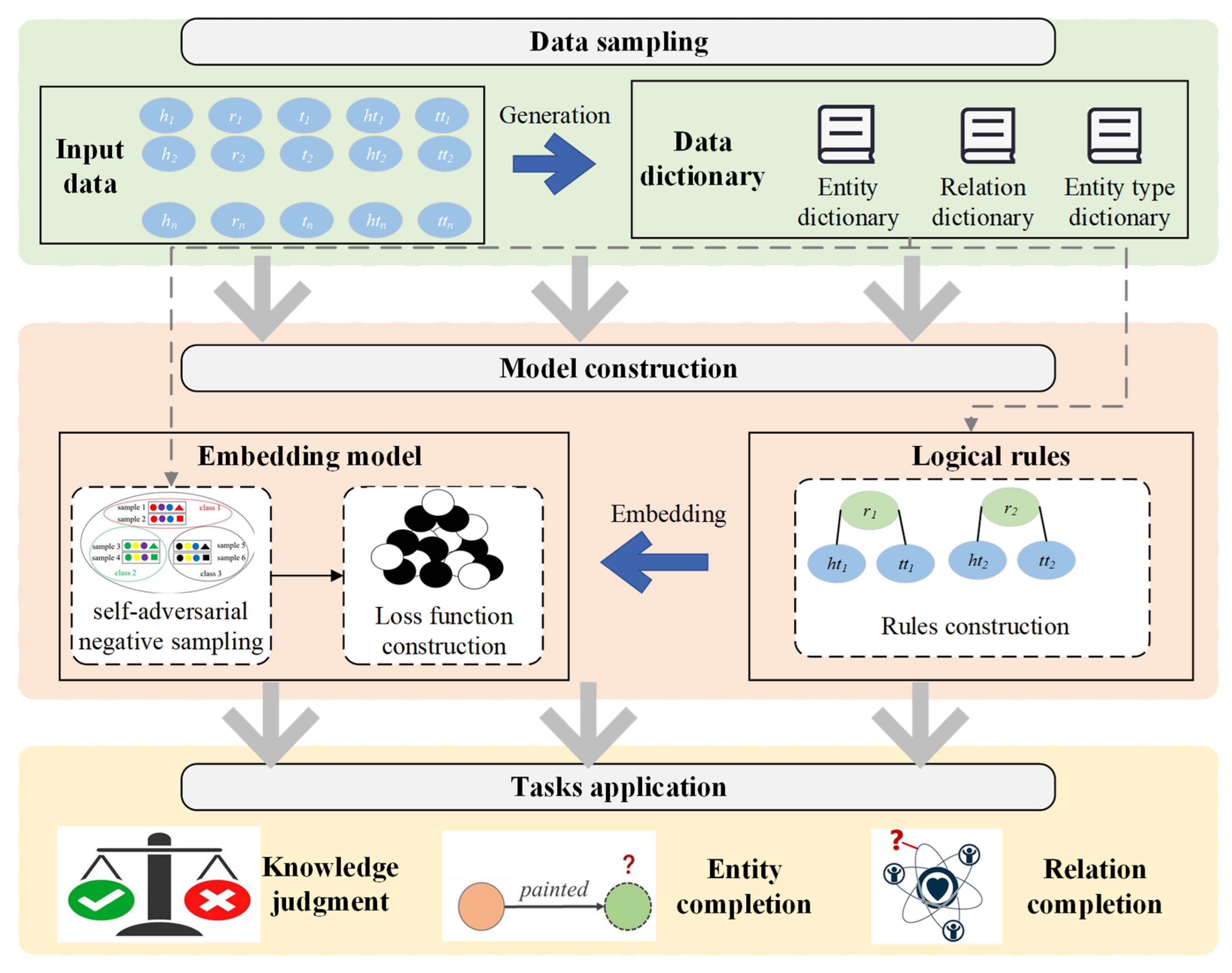
In this paper, proposed KG inference method for KG construction, whose framework is shown in
Figure 1, comprehensively considers the semantic information of entity, relation and entity type. The method framework is divided into three layers: data sampling layer, model construction layer and tasks application layer.
In the data sampling layer, several data dictionaries and logical rules are constructed according to KG information. Subsequently, the vectorization of entity, relation and entity type is realized according to these data dictionaries and word2vec model. In the model construction layer, embedded learning model is constructed based on the vectorization above, and the logic rules of vectorization are embedded in the embedded learning model to guide the training direction. In the tasks application layer, the optimized model is trained for different KG inference tasks. For knowledge judgment task, the optimized model is trained while considering the constraint of logic rules. For entity completion task, the optimized model is trained using positive and negative samples generated by entity and entity type replacement. For relation completion task, the optimized model is also trained with positive and negative samples, which are generated by relation replacement.
Classical KG adopts the entity, relation and fact approach, and a fact is represented by a triplet <
head entity,
relation,
tail entity>. Aiming at the problem that the triplet form cannot effectively express entity type information required for assembly process KG inference, this paper introduces entity type information including head entity type and tail entity type. In that, a fact in assembly process KG could be represented by three triplets:
where
represents some fact of assembly process KG. To circumvent the problem of increased computational complexity caused by multiple triplets, this paper constructs a quintuple containing entity, relation and entity type to express assembly process knowledge, which is defined as follows:
where
h is the head entity,
r is the relation,
t is the tail entity,
ht is the head entity type, and
tt is the tail entity type. In this paper, problem models are constructed for KG inference tasks such as knowledge judgment, entity and relation completion.
The knowledge judgment task in assembly process KG inference is to determine whether a quintuple is true. For example, determine whether the quintuple
<borehole,
next operation,
repair,
operation,
operation> is true, that is, whether there is a sequential relation between ‘borehole’ step and ‘repair’ step. In this regard, a knowledge decision problem model is constructed:
where,
is the input quintuple,
is the output quintuple,
and
refer to the output result after entity completion and relation completion, respectively.
The entity completion task in assembly process KG inference is to complete the missing head/tail entity and its entity type in the quintuple. For example, for an incomplete quintuple
<finishing surface,
use tools,
mask1,
operation,
mask2>, that is, what tooling is needed for the ‘finishing surface’ process, the completed quintuple is
<finishing surface,
use tools,
roughness sample/sandpaper,
operation,
process equipment resources>. In this regard, the entity completion problem model is constructed:
where,
and
are the head entity and type of the head entity after completion, and
and
are the tail entity and type of the tail entity after completion, respectively.
The relation completion task in assembly process KG inference is to complete the missing relation in the quintuple. For example, for the incomplete assembly quintuple
<paint protection,
mask,
air compressor,
operation,
process equipment resources>, that is, the relation between the process and process equipment resources is inferred, and the relation on the completion is “use equipment”. In this regard, a relation completion problem model is constructed:
where,
indicates the relation after completion.
3. Methodology
In this section, the algorithms flow is first presented. It consists of three key parts: negative sample generation, embedded learning model construction and logical rules embedded. Subsequently, these three parts are explained in detail.
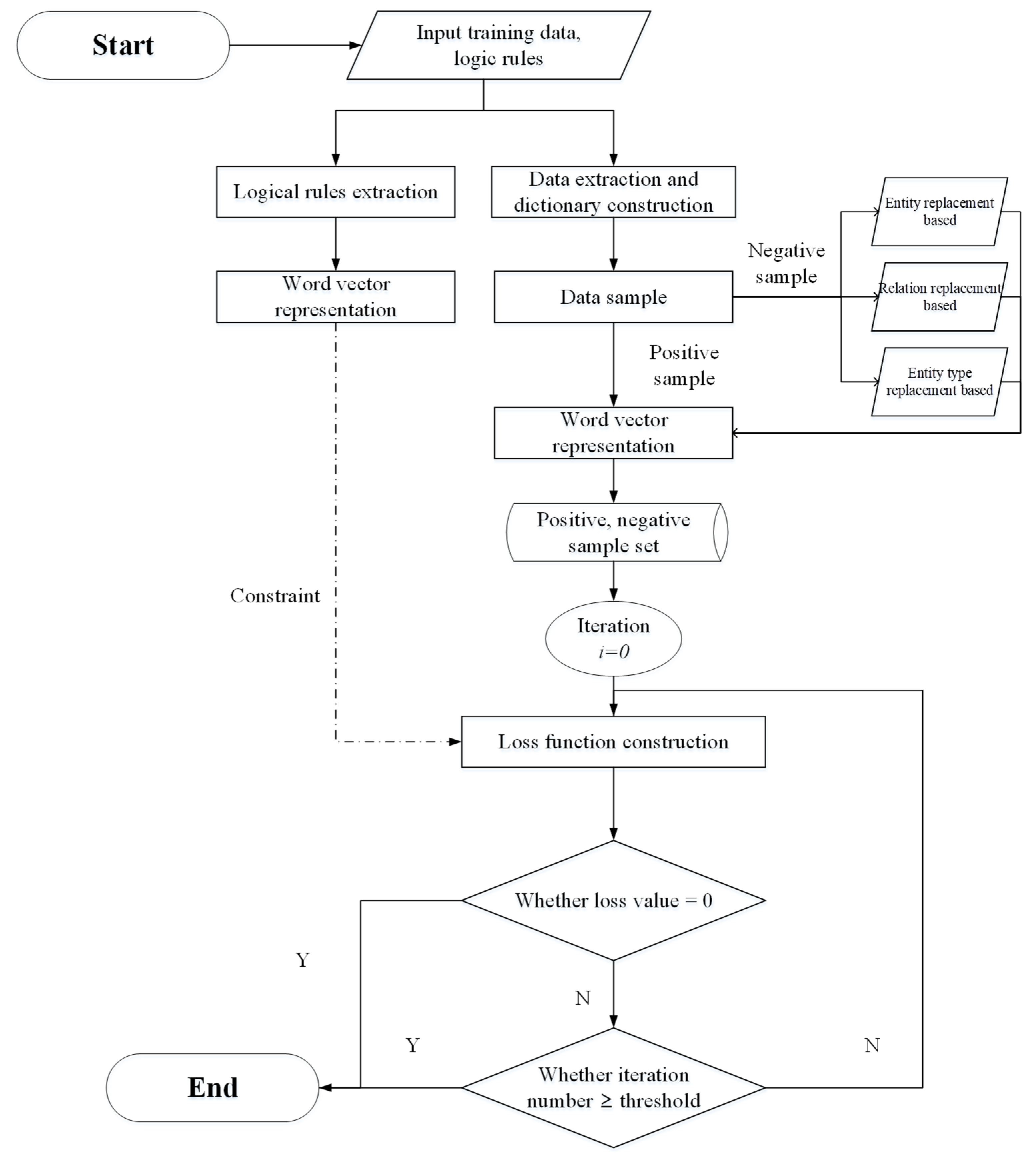
3.1. Assembly Process KG Inference Method Flow
In this paper, corresponding algorithms are designed for the KG inference tasks of knowledge decision, entity and relation completion respectively. The knowledge decision task is based on logical rules based on entity type. The entity and relation completion task includes steps such as data processing, self-adversarial sample generation, model training and evaluation. The algorithm flow is illustrated in
Figure 2.
This assembly process KG inference algorithm mainly includes the following steps:
The information in the quintuple dataset including head entity, tail entity, relation, head entity type and tail entity type respectively are extracted, and the information in the logical rule dataset including head entity type, relation and tail entity type respectively are extracted. Based on the constructed data dictionaries, word vectorization of the information above is carried out.
- 2.
Negative sample generation:
For different tasks such as entity completion, relation completion and knowledge judgment, a self-adversarial negative sample generation method considering entity type is proposed, and the accuracy of negative sample generation is improved by constructing entity dictionary, relation dictionary, and entity type dictionary. Specifically, negative sample generation for entity completion task is realized based on entity dictionary and entity type dictionary while negative sample generation for relation completion task is realized based on relation dictionary. Negative sample generation for knowledge judgment is realized according to logical rules. This novel self-adversarial negative sampling technique is proposed for efficiently and effectively training the embedded learning model.
- 3.
Construction of embedded learning model:
Based on vectorized entity, relation and entity type information, entity and relation modeling and association expression are carried out in vector space according to different representation learning models. Then loss function is constructed according to generated positive and negative samples.
- 4.
Logical rule embedded:
Logical rules are vectorized based on the constructed data dictionaries. Then the vectorized logical rules are embedded into the model training process as knowledge constraints so as to guarantee the accuracy of positive and negative samples generation. Also, logical rules are introduced into loss function for knowledge judgment task.
- 5.
Improved model training and evaluation:
Improved model is trained and its performance is evaluated for different assembly process KG completion tasks.
Compared with the original embedded learning model, this paper improves the positive and negative sample generation, model training and logical rules embedded. The additional logical rules embedded module is used for negative sample determination and result determination, without increasing the algorithm complexity or reducing the algorithm’s computational efficiency.
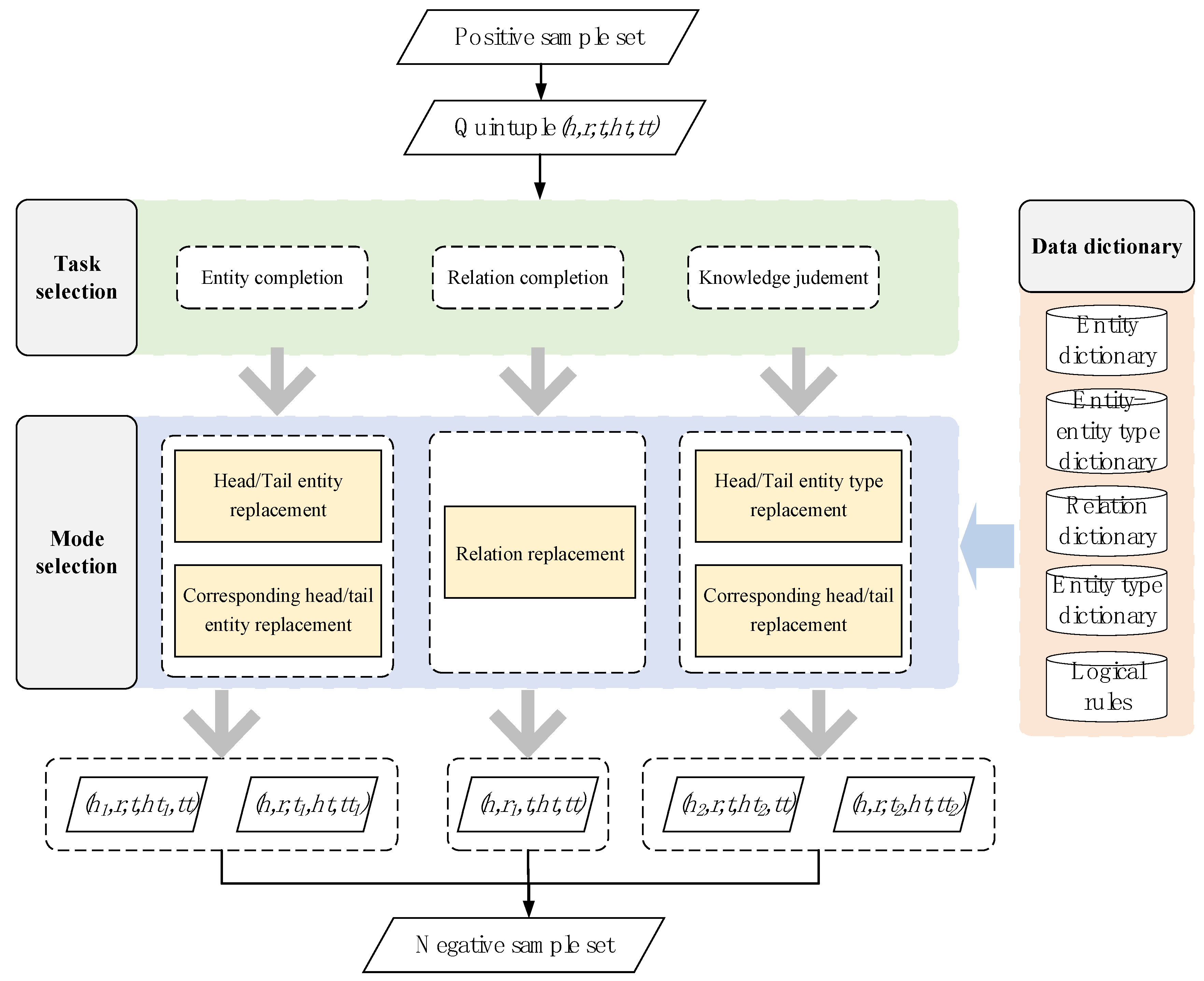
3.2. Self-Adversarial Negative Sampling Method Considering Entity Type
Negative samples serve as non-target or contrast samples to help the model more accurately identify positive samples. By introducing negative samples, the model can learn the nuances in the data, thereby improving the task accuracy and robustness such as classification and recommendation, which has a significant impact on the training and performance improvement of the model. Currently, remarkable results have been achieved in the domains of KG embedding and word embedding. Considering the low efficiency of existing negative sampling methods, this paper proposes a self- adversarial negative sampling method considering entity type information based on the self- adversarial negative sampling proposed by RotatE model, and takes logical rules as constraints to ensure the effectiveness of negative sampling.
Specifically, the negative sampling method includes two parts: negative sample generation and negative sample collection. The negative sample generation methods are divided into three types: entity replacement based, relation replacement based and entity type replacement based negative sample generation. Among them, entity replacement based and entity type replacement based negative sample generation are used for entity completion task, while relation replacement based negative sample generation is used for relation completion task.
The flow of the negative sample generation method is shown in
Figure 3 below. For example, for the entity replacement based negative sample generation method, the training data set is constructed including entity dictionary, entity type dictionary, entity-entity type dictionary, and quintuple dictionary. For each five-tuple in quintuple dictionary, random head entity replacement (h -> h′ or t -> t′) is performed based on the constructed entity dictionary. Simultaneously, the entity type is replaced based on the constructed entity-entity type dictionary to ensure that the entity-entity type is correct, which is convenient for the subsequent model training based on logical rules. The replaced quintuple is filtered by the quintuple dictionary to ensure that the replaced quintuple is a negative sample. In this process, the function of the quintuple dictionary is to ensure that the generated sample is negative. The purpose of the entity dictionary and the entity-entity type dictionary is to ensure that when an entity is replaced, its entity type is replaced accordingly. For the negative sample generation based on entity replacement and entity type replacement, in essence, the two parts of entity and entity type are replaced. The reason is that the essence of the model training process based on embedded learning is to express and train the relation between
<head entity,
relation,
tail entity> in vector space, and entity type does not participate in it. Therefore, the negative samples generated by simply replacing the entity type are still positive samples in essence, and only the samples generated after replacing the entity or relation can participate in the model training process as negative samples.
Negative sampling loss usually samples negative triplets uniformly, but this approach leads to inefficiencies. Therefore, based on generated negative samples, a self-adversarial sampling strategy is adopted to sample entities and relations in the negative samples. Specifically, the negative quintuple is extracted from the following distribution according to the current embedded model:
where, α is the sampling probability and
fr() is the scoring function of the embedded model.
This probability is treated as the weight of the negative sample and introduced into the loss function representing the learning model
3.3. Embedded Learning Model Construction
Knowledge embedded learning represents entities and relations as low-dimensional real value vectors to efficiently compute the entities, relations and complex semantic associations among them, while KG utilizes triplets (head entity, relation, tail entity), where nodes represent entities and edges represent relations. Building embedded learning model consists of the following steps:
- (1)
Utilizing Continuous vector Spaces to represent entities and relations, and relations are often regarded as operations in vector Spaces;
- (2)
Defining a score function or loss function to measure the rationality of knowledge;
- (3)
Learning the entities and relations embedded by maximizing the rationality of global observation knowledge.
The difference between different embedded learning models lies in the setting of score functions and the associations expression between entities and relation. In this paper, three mature embedded learning models including RotatE, DistMult and ComplEx are taken as verification objects for the proposed method. The DistMult model assumes that the relation is symmetric, which reduces the computational complexity and is suitable for large-scale KG completion and construction. ComplEx model introduced complex-valued vectors, and the triplet score was calculated by the complex-valued dot product. The real part of the complex-valued vector was symmetric and the imaginary part was asymmetric, so that it could be used to model the symmetric/antisymmetric relation. The RotatE model is based on the idea of complex valued vectors, modeling relations as rotations in complex vector space, so as to effectively model and infer various complex relation modes such as symmetry/antisymmetry, synthesis and inversion. For example, the DistMult model calculates the product of elements between entities and relational vectors as a score or distance function, expressed as:
The ComplEx model takes the conjugation of the inner product of the entity and the relational complex vector as the scoring function:
RotatE model defines relations as rotations in complex vector space, which focuses on the complex relation completion task. According to the existing literature, three types of relation patterns are very important and widely spread in KGs: symmetry, inversion and composition. The RotatE model calculates the product difference between the two elements as a scoring function:
By defining each relation as a rotation in the complex vector spaces, RotatE can model and infer all the three types of relation patterns introduced above.
Loss function is the core of model training, which measures the difference between the predicted value and the actual value so as to guide the algorithm optimization direction. In this paper, knowledge constraints based on logical rules are introduced to guide the model to deduce the optimal result. Taking RotatE model as an example, adding a penalty term on the basis of its existing loss function, the loss function obtained is as follows:
where σ is the sigmoid activation function,
and
are the distance functions in the positive and negative samples, respectively, γ is the fixed deviation, and P is the constant of the penalty term embedded based on logical rules, usually a larger value.
3.4. Logical Rules Embedded
The logical rules in this paper are derived from the ontology model used to guide the construction of assembly process KG, which is expressed in the triplet form of <
head entity type, relation,
tail entity type>:
The ontology model for assembly process KG construction in this paper is constructed in a top-down manner, which consist of layers of knowledge case, operation and step for assembly process specification. operation layer and step layer are associated with assembly resource. The ontology model guides the construction of KG, thus ensuring the correctness of logical rules.
Regarding the mapping of logical rules to vector spaces, it is crucial to note that the differentiation among embedded learning models primarily lies in their approaches to characterizing the mapping relations between entities and relations, while typically overlooking entity type information. Consequently, the vectorized logical rules are integrated into the model’s loss function as knowledge constraints. Specifically, during model training, if the inferred result
<ht,
r,
tt> derived from
<h,
r,
t,
ht,
tt> (all represented in vector form) is absent from the knowledge constraint set established based on logical rules, a substantial penalty term is generated. This penalty mechanism serves to regulate and optimize the direction of model training. The underlying logic can be formalized as follows:
where
is logical rules-based dictionary.
In addition to guiding the direction of model training, logical rules can also be used in negative sample generation. Regardless of the negative sample generation process based on entity replacement, relation replacement, and entity type replacement, as long as the replaced quintuple (head entity type, relation, and tail entity type) does not exist in the knowledge constraint set, the constructed sample could be guaranteed to be negative, that is:
In the equation above, represents the negative sample set. Negative sample filtering based on logical rules could avoid the problem that a few positive samples in the negative sample will affect the model training and the final model performance.
4. Experiment Verification
In this paper, a data set for validating the proposed method is constructed based on the process specifications of aircraft assembly, reducer assembly and valve assembly. This dataset describes the information and relations contained in the assembly processes of different products, including process steps, operation steps, resources, reference standards, components, and their interconnections. The dataset consists of two parts: a triplet-based dataset for the pre-improved presentation learning model, and a quintuple-based dataset for the post-improved presentation learning model. Examples of the two and their differences are shown in
Figure 4.
Part (a) of the figure above is a dataset based on triplet format <head entity, relation, tail entity> where head and tail entity information is expressed using identity document, and part (b) is a dataset based on quintuple format <head entity, relation, tail entity, head entity type, tail entity type>, the only difference between them is that part (b) adds the head and tail entity type information.
The data set constructed for assembly process domain in this paper is divided into three parts: training set, verification set and test set, and the ratio is 8:1:1, which ensures that the model has enough data for parameter learning during training, as well as enough data for verifying model performance and adjusting hyperparameters, as well as finally testing the generalization ability of the model. The dataset, which derived from the assembly process knowledge of complex aviation products, contains a total of 3824 quintuples, 1174 entities, 7 relations, and 9 entity types. Therein, 7 types of relations include ‘has_subleaf, has_step, has_operation, use_process_equip, next_operation, next_step and use_device’, and 6 types of entity types include ‘know_type, process_case, operation, step, equipment_resource, device_resource’, which describe the whole assembly process specifications. Given that the sources of knowledge cover a variety of assembly processes and the information of processes, work steps, resources, parts, etc., the data set is sufficient to prove the validity of the proposed method. In the constructed dataset, entity information is processed by replacing it with unique identifiers (UUIDs), which are then associated and mapped using a constructed entity dictionary. This approach avoids the direct use of word vectors for entities, which can lead to significant differences between word vectors due to excessively long texts. Additionally, the completed entities can retrieve their corresponding textual information through the entity dictionary.
The embedded learning model used in the verification part includes RotatE, DistMult and ComplEx. Parameters set during the experiment are shown in the following
Table 1.
4.1. Entity Completion Task
In this paper, the evaluation indicators of entity completion tasks are used, including MRR (Mean Reciprocal Ranking), HITS@1 (The average proportion of the first quintuple), HITS@3 (The average proportion of the top three quintuple) and HITS@10 (The average proportion of the top ten quintuple).
It can be seen from the results in
Table 2 that compared with the original embedded learning model, the improved model considering entity type information has obvious improvement in each evaluation index. Among them, MRR, HITS@1 and HITS@3 have higher improvement, indicating that the improved model can deduce the optimal result more accurately. HITS@10 index has a small increase and its values are all high before improvement, indicating that the existing embedded learning model can deduce correct results when the candidate range is large enough. It reflects that existing mature embedded learning model can effectively handle the entity completion task of assembly process KG, but the effect is not optimal.
In the table above, the bolded value indicates that its model performs better in this index.
4.2. Relation Completion Task
In this paper, the evaluation indicators of relation completion tasks are also used, including MRR, HITS@1, HITS@3 and HITS@10.
It can be seen from the results in
Table 3 that compared with the original representation learning model, the improved model considering the entity type information has a significant improvement in each evaluation index, and the conclusion is similar to the conclusion of the entity completion task. It should be noted that because the built data set does not indicate complex relation patterns such as symmetric/antisymmetric relation and synthetic relation, the RotatE model has excellent performance in relation completion, but its advantages are not fully manifested.
In the table above, the bolded value indicates that its model performs better in this index.
4.3. Knowledge Judgment Task
In this paper, the evaluation indicators of knowledge judgment tasks are used including confidence level, recall rate and F1 value.
The constructed logical rules are used as knowledge constraints for the first step of knowledge judgment, and then the second step of knowledge judgment is based on the constructed quintuple dictionary. The quintuple confidence level of KG constructed in this paper is used to measure the true degree or reliability of the knowledge expressed by the quintuple, and its range is [0, 1]. The closer it is to 0, the greater the probability that the quintuple is wrong, while the closer it is to 1, the greater the probability that the quintuple is correct. The recall rate is defined as the proportion of <head entity type, relation, tail entity type> in the correct knowledge to the total number of logical rules. The F1 value is the harmonic mean of confidence and recall rate.
In the
Table 4, the bolded value indicates that its model performs better in this index. Compared with the original embedded learning model, the improved model considering the entity type information has obvious improvement in each evaluation index, and the conclusion is similar to the conclusion of the entity/relation completion task.
4.4. Discussion
Although different initial embedded learning models have different effects on different KG inference tasks, the proposed method can improve the processing ability of different embedded learning models, and the degree of improvement is related to the representation learning model and task. At the same time, since the experimental data set does not contain complex relations and there are not many types of relations and entities, it can only show that the proposed method can improve the task handling capacity of the representation learning model, but cannot show which embedded learning model is optimal.
5. Conclusions and Future Work
Classical KG inference methods that only consider entity and relation semantic information cannot handle the KG inference task in assembly domain effectively. Considering entity type information, this paper proposes an assembly process KG inference method integrating logical rules and embedded learning. Based on ontology model, logical rules containing entity type information are constructed and embedded into existing embedded learning models as knowledge constraints. Furthermore, existing embedded learning model is improved from the stages of data processing and model training considering entity type, which realizes the effective processing of the assembly process KG inference tasks such as entity and relation completion and knowledge judgment. The proposed method not only guarantees the integrity and correctness of the assembly process KG, but also helps to improve assembly efficiency, support intelligent decision making, promote knowledge sharing and inheritance, and even process innovation. From the comparative experimental results, it is evident that although different initial embedded learning models exhibit varying effectiveness for different KG inference tasks, the proposed method enhances the processing capabilities of these embedded learning models. The extent of improvement is dependent on both the embedded learning model and the specific task. In addition, since the introduction of logic rules does not increase the complexity of the algorithm, this method also maintains a high level of computational efficiency.
There are also some limitations in this study. The comparative experiments in this paper focus on various assembly process specifications. However, the scope of assembly process knowledge is not limited to these specifications. Other aspects, such as standard norms, connection method selection, and assembly principles, are derived not from these specifications but from other manuals, rule tables, or even empirical knowledge. Therefore, the construction of a comprehensive assembly process knowledge graph requires a broader range of objects and corresponding methods to achieve.
Future research could focus on these directions: More complex logical rule representations, such as introducing higher-order logic or fuzzy logic, to better capture complex relations and uncertainties in assembly process procedures; Multi-modal data (such as images, text, and sensor data) can be completed by KG to improve the accuracy and practicality of inference; For dynamic assembly process scenarios, incremental learning and online learning methods can be studied, so that the model can be updated and adapted to new knowledge in real time. These directions will promote the application of KG inference technology in assembly process procedures and provide more powerful support for intelligent manufacturing.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}