
Wavelet Decomposition Prediction for Digital Predistortion of Wideband Power Amplifiers


Abstract
1. Introduction
- We propose a WD-enhanced dual-stage RNN for WDP-based DPD, where the dual-stage RNN captures long-term dependencies in the input while the WD module provides multi-resolution analysis, improving both PA modeling accuracy and DPD effectiveness.
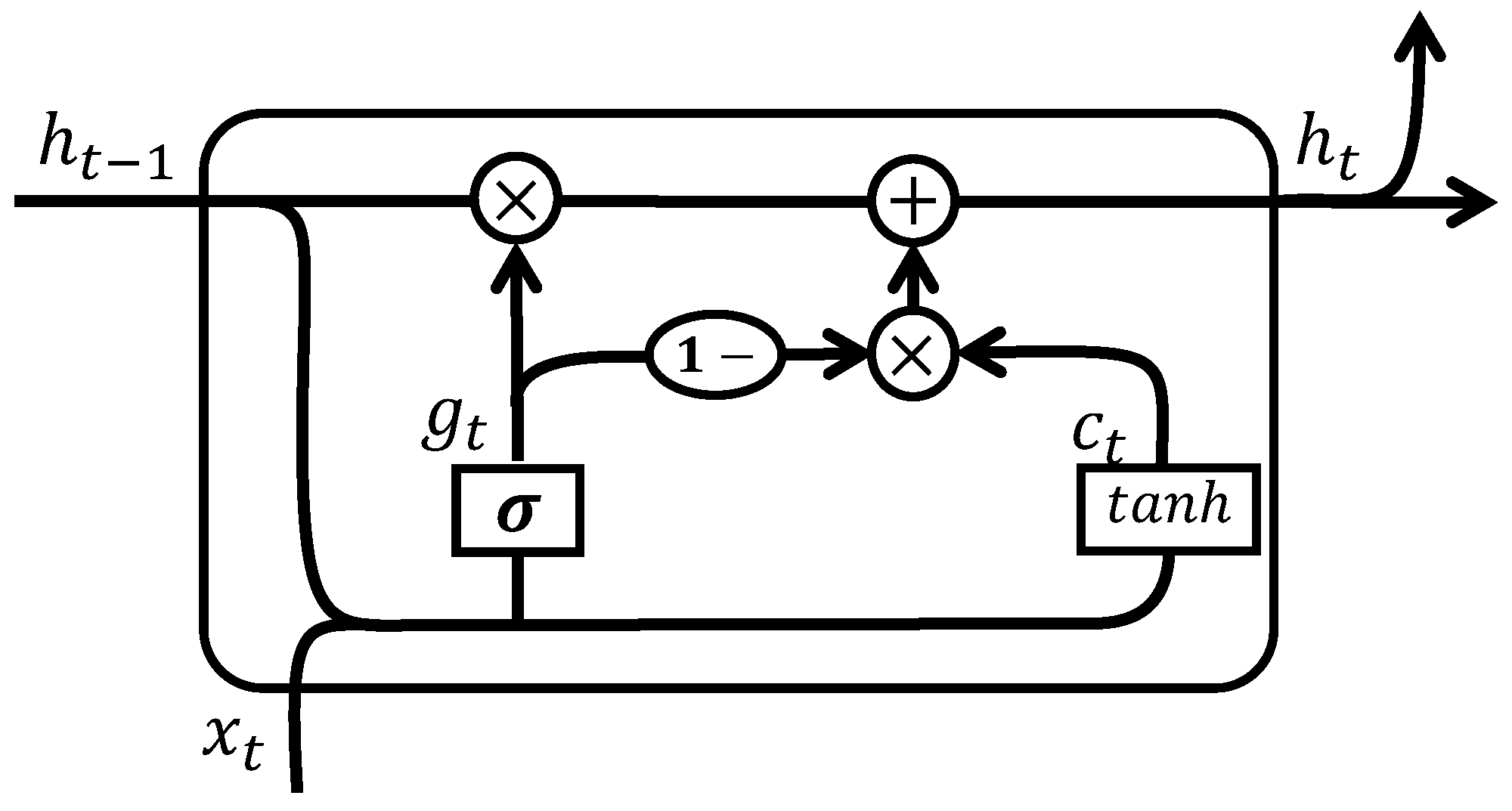
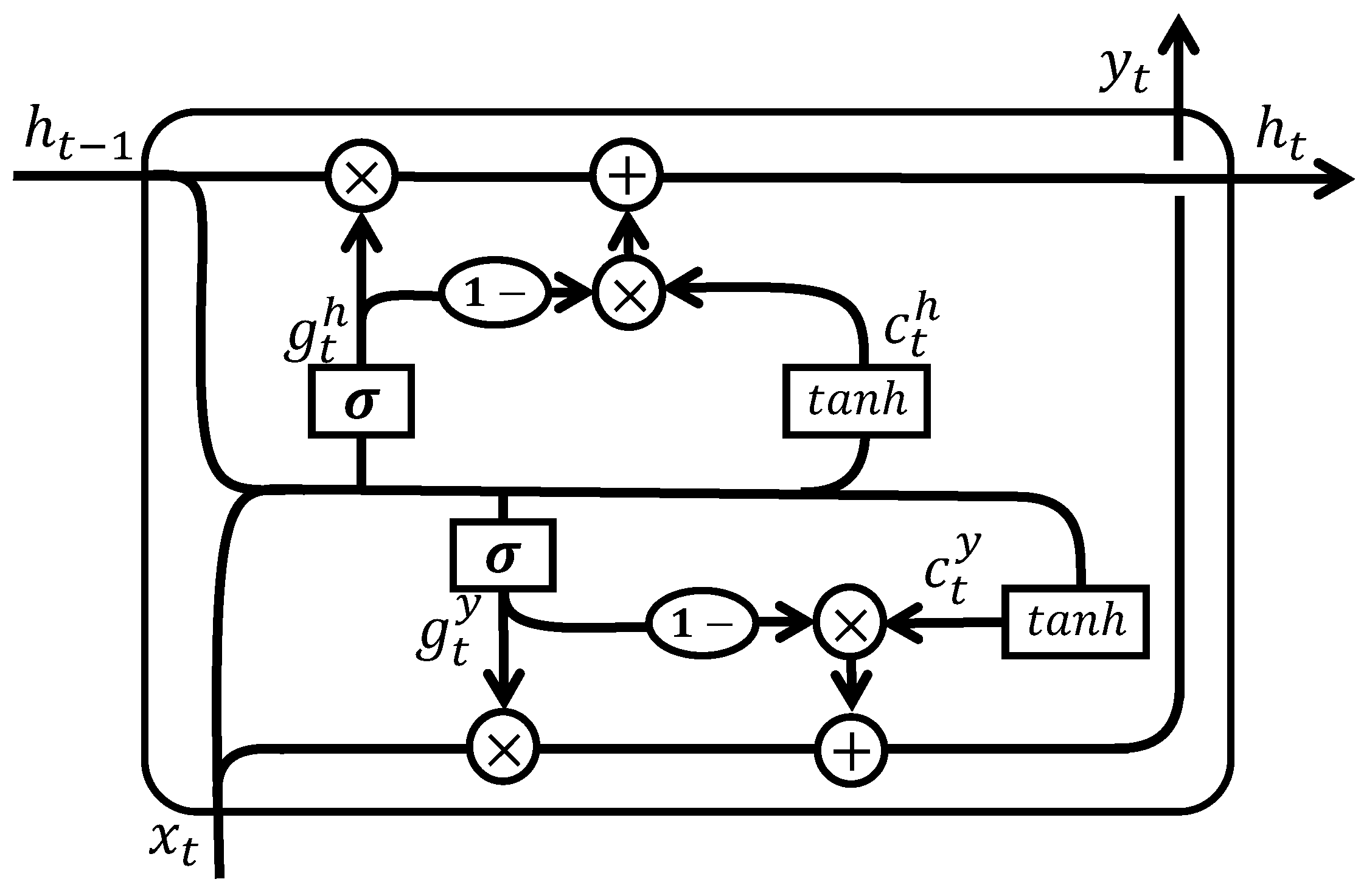
- Our approach integrates a dual-stage RNN composed of a UGRNN and an IRNN, both of which extend the vanilla RNN with a lightweight gating mechanism. Specifically, the UGRNN is employed for PA nonlinear modeling, while the IRNN is used in the DPD stage, ensuring that each stage leverages the most suitable RNN variant.
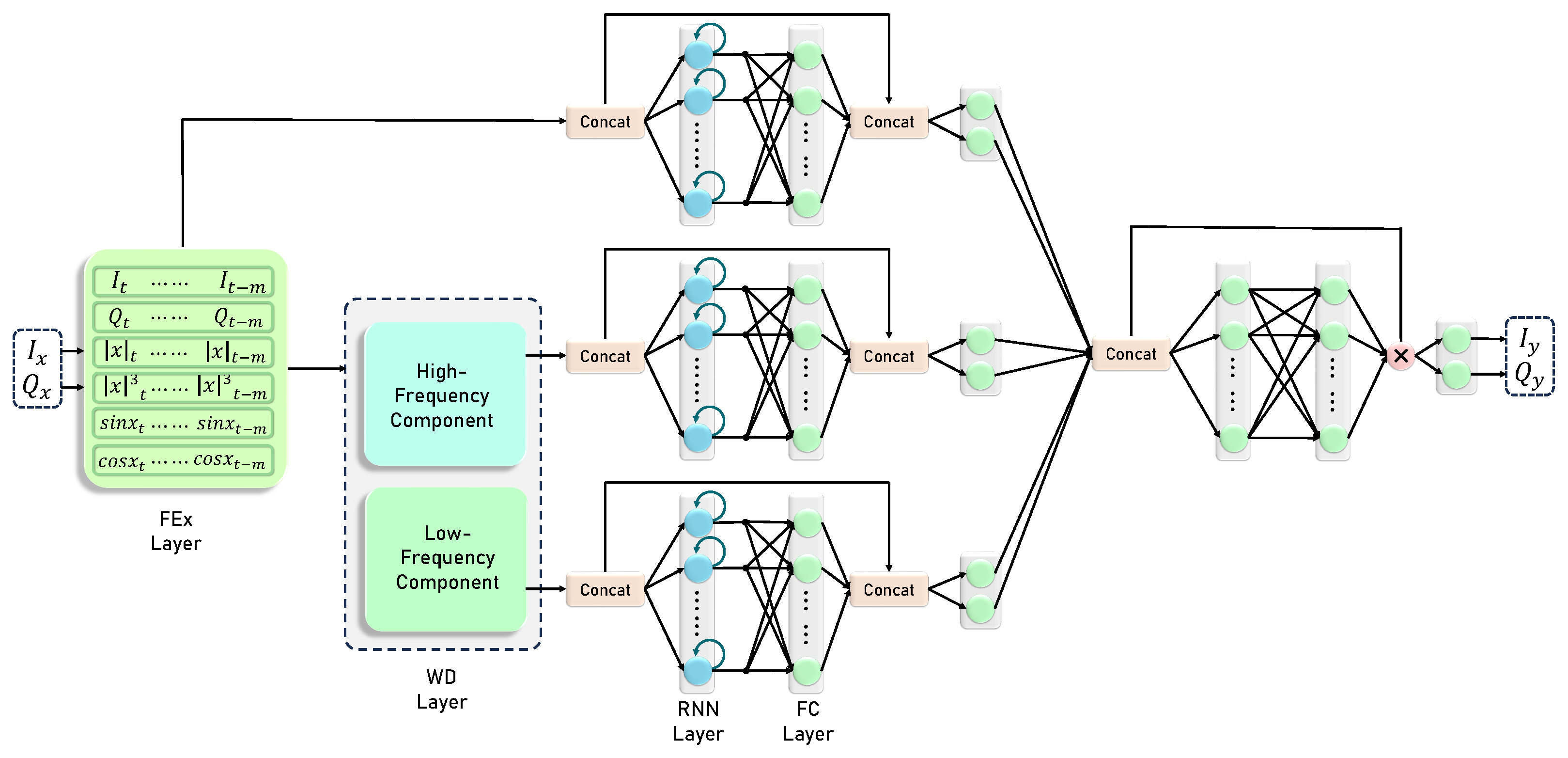
- We develop a learnable WD module that leverages WD’s frequency learning capability to decompose signals into higher-frequency components, facilitating more effective analysis of distorted signals.
- We perform extensive simulations on the open-source dataset “OpenDPD”, demonstrating substantial improvements over state-of-the-art WDP-based methods, including a dB reduction in the NMSE, ACPR gains of dBc, and a dB improvement in the EVM.
2. System Model and Problem Description
2.1. System Model
2.2. Problem Formulation
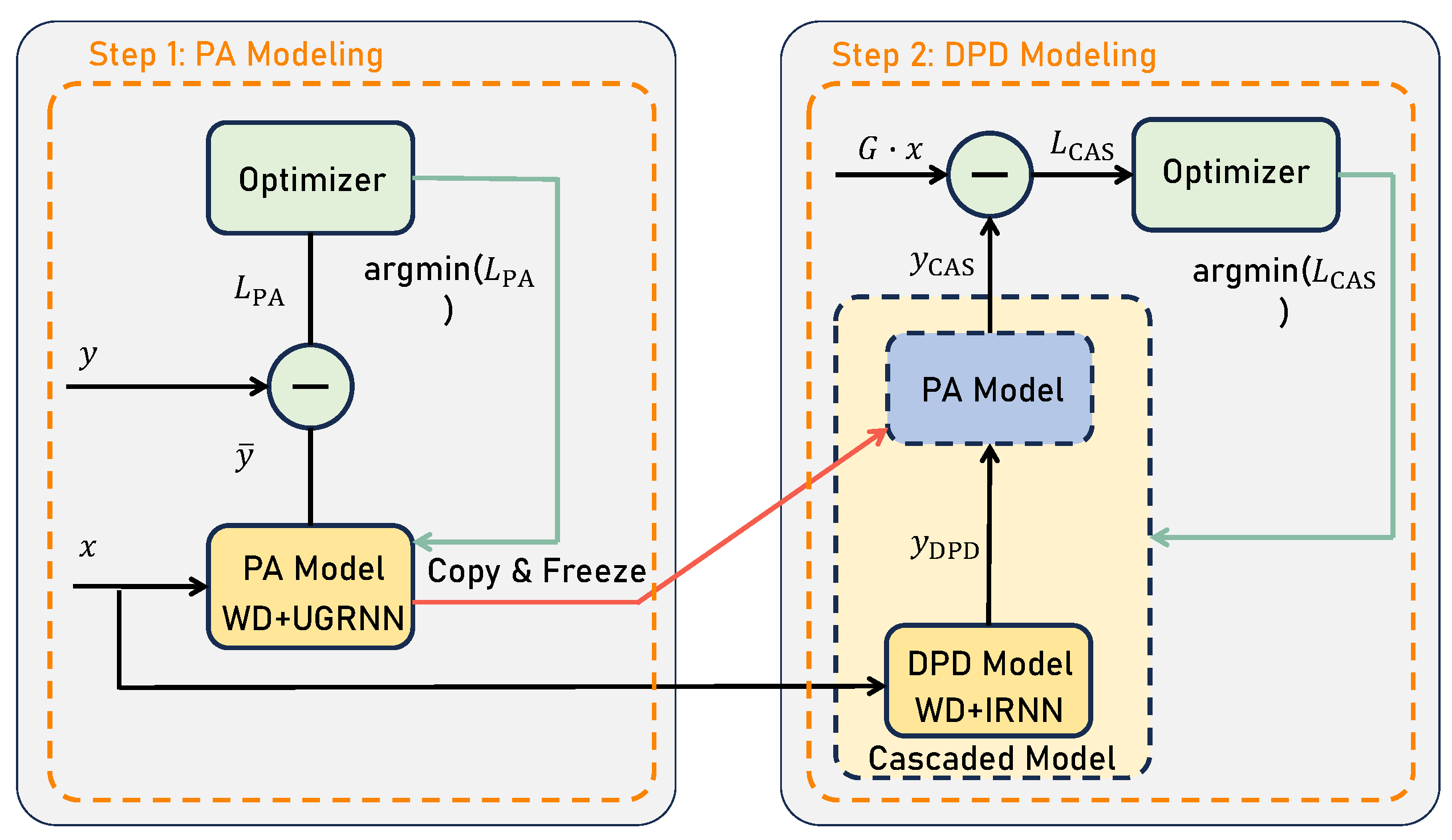
3. The Proposed WDP Architecture
| Algorithm 1 The detailed procedures of the proposed WDP method. |
Require:
 [Testing procedure]:
|
3.1. PA Nonlinear Modeling by WDP
3.2. DPD by WDP
4. Experimental Results and Discussions
4.1. Experimental Setup
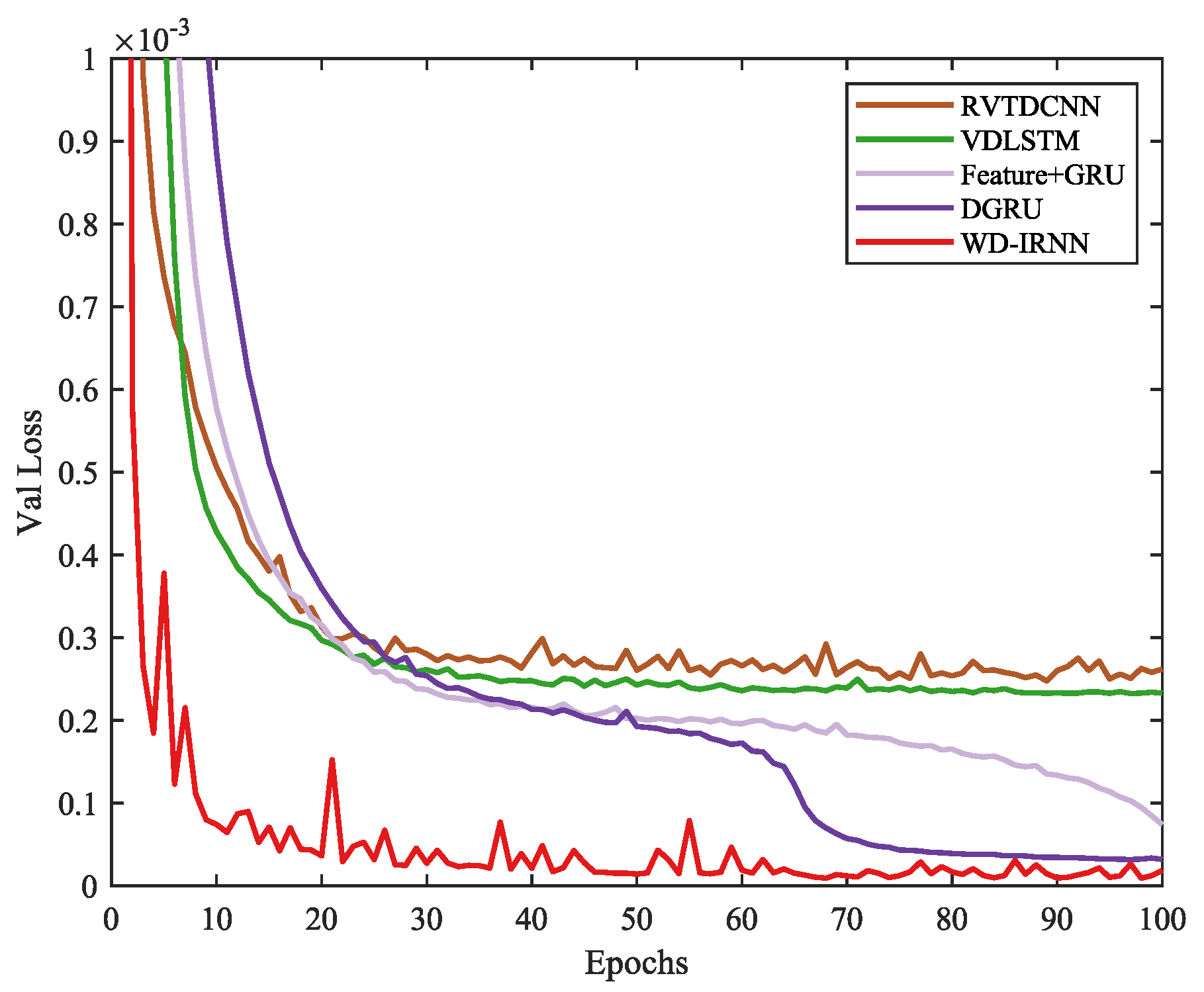
4.2. Analysis of PA Nonlinear Modeling
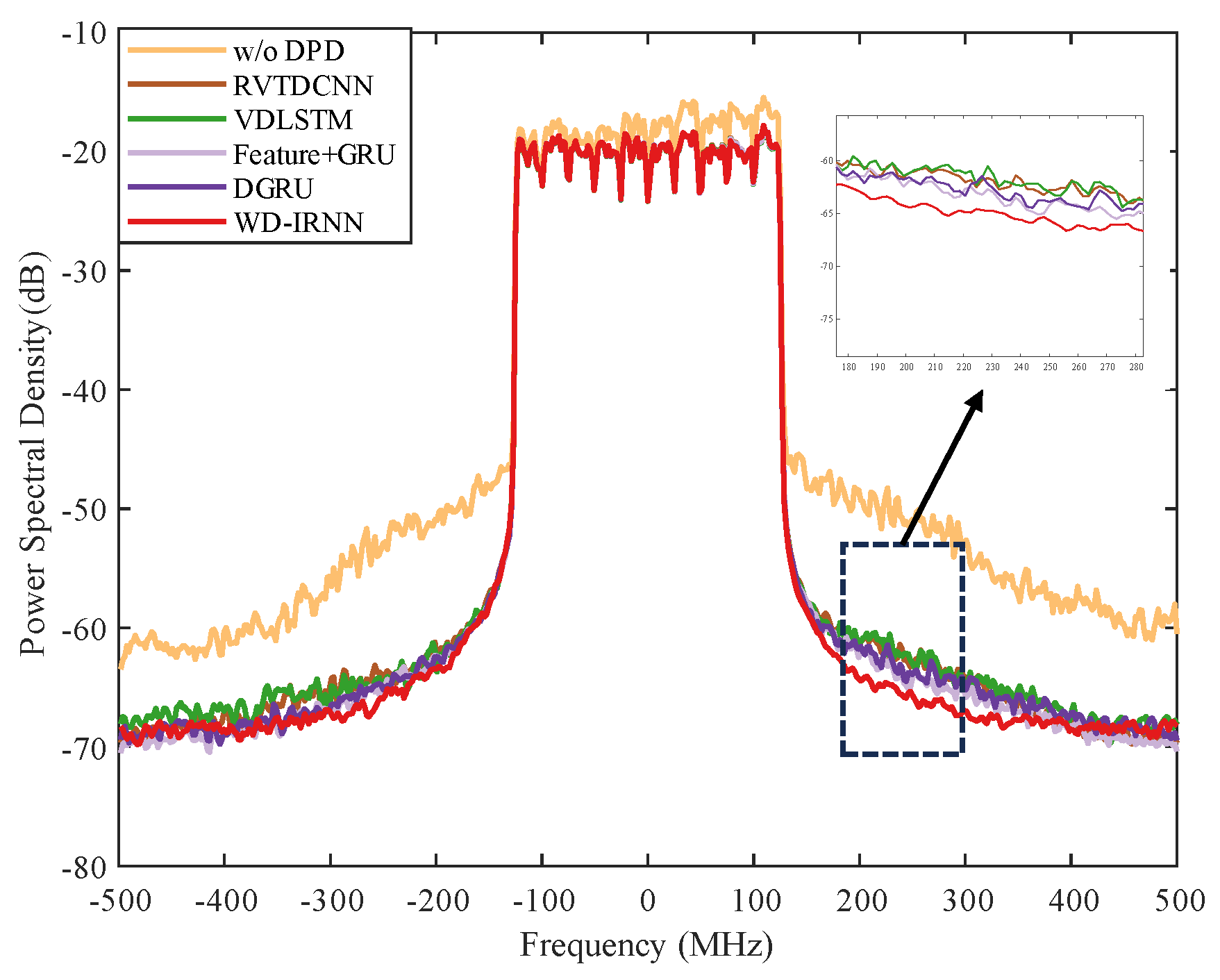
4.3. Analysis of DPD Modeling
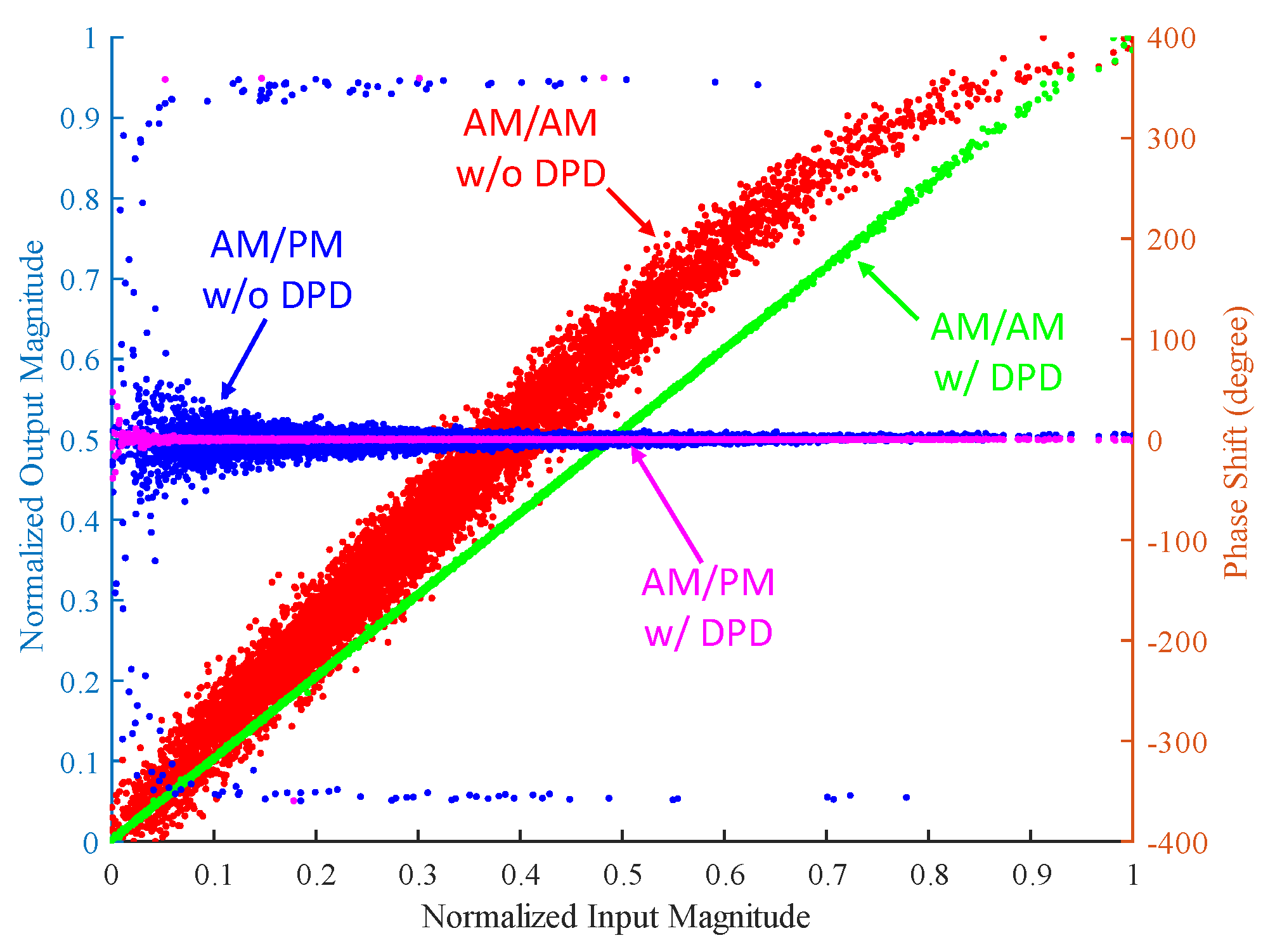
4.4. Visual Interpretation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Q.; Jiang, C.; Yang, G.; Han, R.; Liu, F. Multi-Output Recurrent Neural Network Behavioral Model for Digital Predistortion of RF Power Amplifiers. IEEE Microw. Wirel. Technol. Lett. 2023, 33, 1067–1070. [Google Scholar] [CrossRef]
- Aguila-Torres, D.S.; Galaviz-Aguilar, J.A.; Cárdenas-Valdez, J.R. Reliable Comparison for Power Amplifiers Nonlinear Behavioral Modeling Based on Regression Trees and Random Forest. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022. [Google Scholar]
- He, Z.; Tong, F. Residual RNN Models with Pruning for Digital Predistortion of RF Power Amplifiers. IEEE Trans. Veh. Technol. 2022, 71, 9735–9750. [Google Scholar] [CrossRef]
- Omar, M.S.; Qi, J.; Ma, X. Mitigating Clipping Distortion in Multicarrier Transmissions Using Tensor-Train Deep Neural Networks. IEEE Trans. Wirel. Commun. 2023, 22, 2127–2138. [Google Scholar] [CrossRef]
- Lopez-Bueno, D.; Wang, T.; Gilabert, P.L.; Montoro, G. Amping Up, Saving Power: Digital Predistortion Linearization Strategies for Power Amplifiers under Wideband 4G/5G Burst-Like Waveform Operation. IEEE Microw. Mag. 2015, 17, 79–87. [Google Scholar] [CrossRef]
- He, Z. Time-Delay/Advance Neural Networks Based Digital Predistorters: Enabling High Efficiency and High Throughput Transmitter. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, UK, 26–29 March 2023. [Google Scholar]
- Younes, M. An Accurate Complexity-Reduced “PLUME” Model for Behavioral Modeling and Digital Predistortion of RF Power Amplifiers. IEEE Trans. Ind. Electron. 2011, 58, 1397–1405. [Google Scholar] [CrossRef]
- Chen, W.; Liu, X.; Chu, J.; Wu, H.; Feng, Z.; Ghannouchi, F.M. A Low Complexity Moving Average Nested GMP Model for Digital Predistortion of Broadband Power Amplifiers. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 2070–2083. [Google Scholar] [CrossRef]
- Zhu, A. Decomposed Vector Rotation-Based Behavioral Modeling for Digital Predistortion of RF Power Amplifiers. IEEE Trans. Microw. Theory Tech. 2015, 63, 737–744. [Google Scholar] [CrossRef]
- Wang, D.; Aziz, M.; Helaoui, M.; Ghannouchi, F.M. Augmented Real-Valued Time-Delay Neural Network for Compensation of Distortions and Impairments in Wireless Transmitters. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 242–254. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Liu, F.; Zhu, A. Vector Decomposition Based Time-Delay Neural Network Behavioral Model for Digital Predistortion of RF Power Amplifiers. IEEE Access 2019, 7, 91559–91568. [Google Scholar] [CrossRef]
- Kobal, T.; Li, Y.; Wang, X.; Zhu, A. Digital Predistortion of RF Power Amplifiers with Phase-Gated Recurrent Neural Networks. IEEE Trans. Microw. Theory Tech. 2022, 70, 3291–3299. [Google Scholar] [CrossRef]
- Jiang, C.; Li, H.; Qiao, W.; Yang, G.; Liu, Q.; Wang, G.; Liu, F. Block-Oriented Time-Delay Neural Network Behavioral Model for Digital Predistortion of RF Power Amplifiers. IEEE Trans. Microw. Theory Tech. 2022, 70, 1461–1473. [Google Scholar] [CrossRef]
- Wu, Y.; Li, A.; Beikmirza, M.; Singh, G.D.; Chen, Q.; de Vreede, L.C.N.; Alavi, M.; Gao, C. MP-DPD: Low-Complexity Mixed-Precision Neural Networks for Energy-Efficient Digital Predistortion of Wideband Power Amplifiers. IEEE Microw. Wirel. Technol. Lett. 2024, 34, 817–820. [Google Scholar]
- Paaso, H.; Mammela, A. Comparison of Direct Learning and Indirect Learning Predistortion Architectures. In Proceedings of the 2008 IEEE International Symposium on Wireless Communication Systems, Reykjavik, Iceland, 21–24 October 2008. [Google Scholar]
- Landin, P.N.; Mayer, A.E.; Eriksson, T. MILA—A Noise Mitigation Technique for RF Power Amplifier Linearization. In Proceedings of the 2014 IEEE 11th International Multi-Conference on Systems, Signals & Devices (SSD14), Barcelona, Spain, 11–14 February 2014. [Google Scholar]
- Abi Hussein, M.; Bohara, V.A.; Venard, O. On the System Level Convergence of ILA and DLA for Digital Predistortion. In Proceedings of the 2012 International Symposium on Wireless Communication Systems (ISWCS), Paris, France, 28–31 August 2012. [Google Scholar]
- Mengozzi, M.; Gibiino, G.P.; Angelotti, A.M.; Florian, C.; Santarelli, A. GaN power amplifier digital predistortion by multi-objective optimization for maximum RF output power. Electronics 2021, 10, 244. [Google Scholar] [CrossRef]
- Wang, X.; Li, Y.; Yin, H.; Yu, C.; Yu, Z.; Hong, W.; Zhu, A. Digital Predistortion of 5G Multiuser MIMO Transmitters Using Low-Dimensional Feature-Based Model Generation. IEEE Trans. Microw. Theory Tech. 2021, 70, 1509–1520. [Google Scholar] [CrossRef]
- Mengozzi, M.; Gibiino, G.P.; Angelotti, A.M.; Florian, C.; Santarelli, A. Beam-dependent active array linearization by global feature-based machine learning. IEEE Microw. Wirel. Compon. Lett. 2023, 33, 895–898. [Google Scholar] [CrossRef]
- Zhou, D.; DeBrunner, V.E. Novel Adaptive Nonlinear Predistorters Based on The Direct Learning Algorithm. IEEE Trans. Signal Process. 2007, 55, 120–133. [Google Scholar]
- Yu, Z.; Zhu, E. A Comparative Study of Learning Architecture for Digital Predistortion. In Proceedings of the 2015 Asia-Pacific Microwave Conference (APMC), Nanjing, China, 6–9 December 2015. [Google Scholar]
- Wang, Z.; Chen, W.; Su, G.; Ghannouchi, F.M.; Feng, Z.; Liu, Y. Low Computational Complexity Digital Predistortion Based on Direct Learning With Covariance Matrix. IEEE Trans. Microw. Theory Tech. 2017, 65, 4274–4284. [Google Scholar]
- Tarver, C.; Jiang, L.; Sefidi, A.; Cavallaro, J.R. Neural network DPD via backpropagation through a neural network model of the PA. In Proceedings of the 2019 53rd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 3–6 November 2019. [Google Scholar]
- Javid-Hosseini, S.H.; Ghazanfarianpoor, P.; Nayyeri, V.; Colantonio, P. A Unified Neural Network-Based Approach to Nonlinear Modeling and Digital Predistortion of RF Power Amplifier. IEEE Trans. Microw. Theory Tech. 2024, 72, 5031–5038. [Google Scholar]
- Ghazanfarianpoor, P.; Javid-Hosseini, S.H.; Abbasnezhad, F.; Arian, A.; Nayyeri, V.; Colantonio, P. A Neural Network-Based Pre-Distorter for Linearization of RF Power Amplifiers. In Proceedings of the 2023 22nd Mediterranean Microwave Symposium (MMS), Sousse, Tunisia, 30 October–1 November 2023. [Google Scholar]
- Wu, Y.; Singh, G.D.; Beikmirza, M.; de Vreede, L.C.N.; Alavi, M.; Gao, C. OpenDPD: An Open-Source End-to-End Learning & Benchmarking Framework for Wideband Power Amplifier Modeling and Digital Pre-Distortion. In Proceedings of the 2024 IEEE International Symposium on Circuits and Systems (ISCAS), Singapore, 19–22 May 2024. [Google Scholar]
- Wan, R.; Mei, S.; Wang, J.; Liu, M.; Yang, F. Multivariate Temporal Convolutional Network: A Deep Neural Networks Approach for Multivariate Time Series Forecasting. Electronics 2019, 8, 876. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Z.; Li, J.; Wu, J. Multilevel Wavelet Decomposition Network for Interpretable Time Series Analysis. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Collins, J.; Sohl-Dickstein, J.; Sussillo, D. Capacity and Trainability in Recurrent Neural Networks. Available online: https://arxiv.org/abs/1611.09913 (accessed on 29 November 2016).
- Li, H.; Zhang, Y.; Li, G.; Liu, F. Vector Decomposed Long Short-Term Memory Model for Behavioral Modeling and Digital Predistortion for Wideband RF Power Amplifiers. IEEE Access 2020, 8, 63780–63789. [Google Scholar]
- Hu, X.; Liu, Z.; Yu, X.; Zhao, Y.; Chen, W.; Hu, B.; Du, X.; Li, X.; Helaoui, M.; Wang, W.; et al. Convolutional Neural Network for Behavioral Modeling and Predistortion of Wideband Power Amplifiers. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3923–3937. [Google Scholar] [PubMed]
- Zhang, Q.; Jiang, C.; Yang, G.; Han, R.; Liu, F. Block-Oriented Recurrent Neural Network for Digital Predistortion of RF Power Amplifiers. IEEE Trans. Microw. Theory Tech. 2024, 72, 3875–3885. [Google Scholar]
- Chani-Cahuana, J.; Landin, P.N.; Fager, C.; Eriksson, T. Iterative Learning Control for RF Power Amplifier Linearization. IEEE Trans. Microw. Theory Tech. 2016, 64, 2779–2789. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Setting |
|---|---|
| Python | 3.9.19 |
| Pytorch | 1.12.0 |
| Training epochs | 100 |
| Batch size | 64 |
| Memory depth | 24 |
| Frame length | 50 |
| Optimizer for model | Adamw (learning rate = 0.001) |
| Platform | NVIDIA GeForce GTX 2080Ti GPU |
| Modeling Methods | NMSE (dB) |
|---|---|
| RVTDCNN [32] | |
| VDLSTM [31] | |
| Feature+GRU [27] | |
| DGRU [27] | |
| UGRNN [30] | |
| WDP (Ours) |
| DPD Methods | NMSE (dB) | SIM-ACPR (dBc, L/R) | SIM-EVM (dB) |
|---|---|---|---|
| RVTDCNN [32] | −44.49 ± 0.95/−44.10 ± 0.83 | ||
| VDLSTM [31] | −45.92 ± 0.23/−45.37 ± 0.79 | ||
| Feature+GRU [27] | −40.92 ± 3.96 | −49.34 ± 0.52/−47.11 ± 0.82 | |
| DGRU [27] | −49.14 ± 0.64/−46.06 ± 0.89 | ||
| IRNN [30] | −47.85 ± 1.12/−46.81 ± 0.99 | ||
| WDP (Ours) | −52.71 ± 0.78/−51.93 ± 0.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, S.; You, J. Wavelet Decomposition Prediction for Digital Predistortion of Wideband Power Amplifiers. Appl. Sci. 2025, 15, 3599. https://doi.org/10.3390/app15073599
Peng S, You J. Wavelet Decomposition Prediction for Digital Predistortion of Wideband Power Amplifiers. Applied Sciences. 2025; 15(7):3599. https://doi.org/10.3390/app15073599
Chicago/Turabian StylePeng, Shaocheng, and Jing You. 2025. "Wavelet Decomposition Prediction for Digital Predistortion of Wideband Power Amplifiers" Applied Sciences 15, no. 7: 3599. https://doi.org/10.3390/app15073599
APA StylePeng, S., & You, J. (2025). Wavelet Decomposition Prediction for Digital Predistortion of Wideband Power Amplifiers. Applied Sciences, 15(7), 3599. https://doi.org/10.3390/app15073599