
WDS-YOLO: A Marine Benthos Detection Model Fusing Wavelet Convolution and Deformable Attention


Abstract
1. Introduction
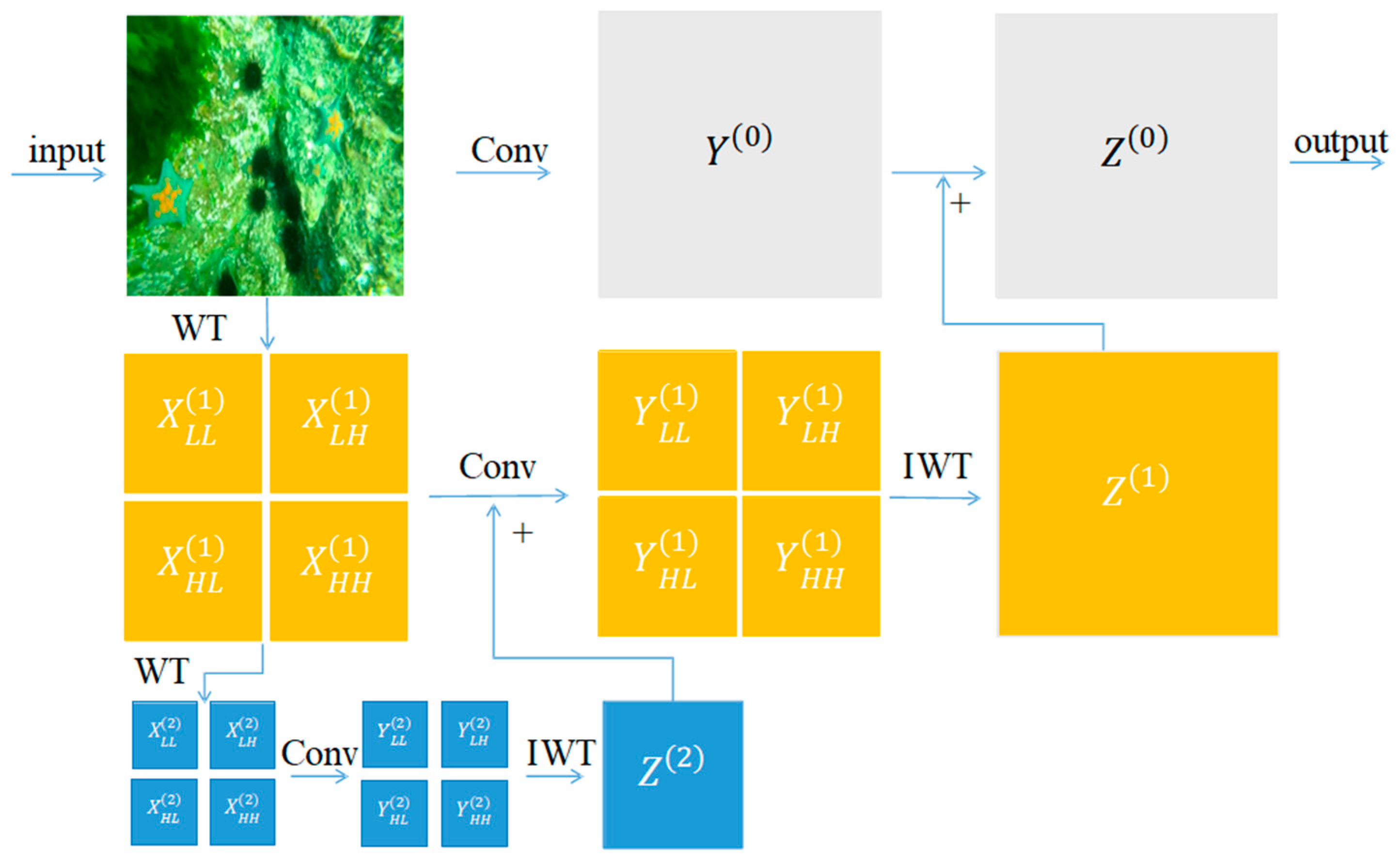
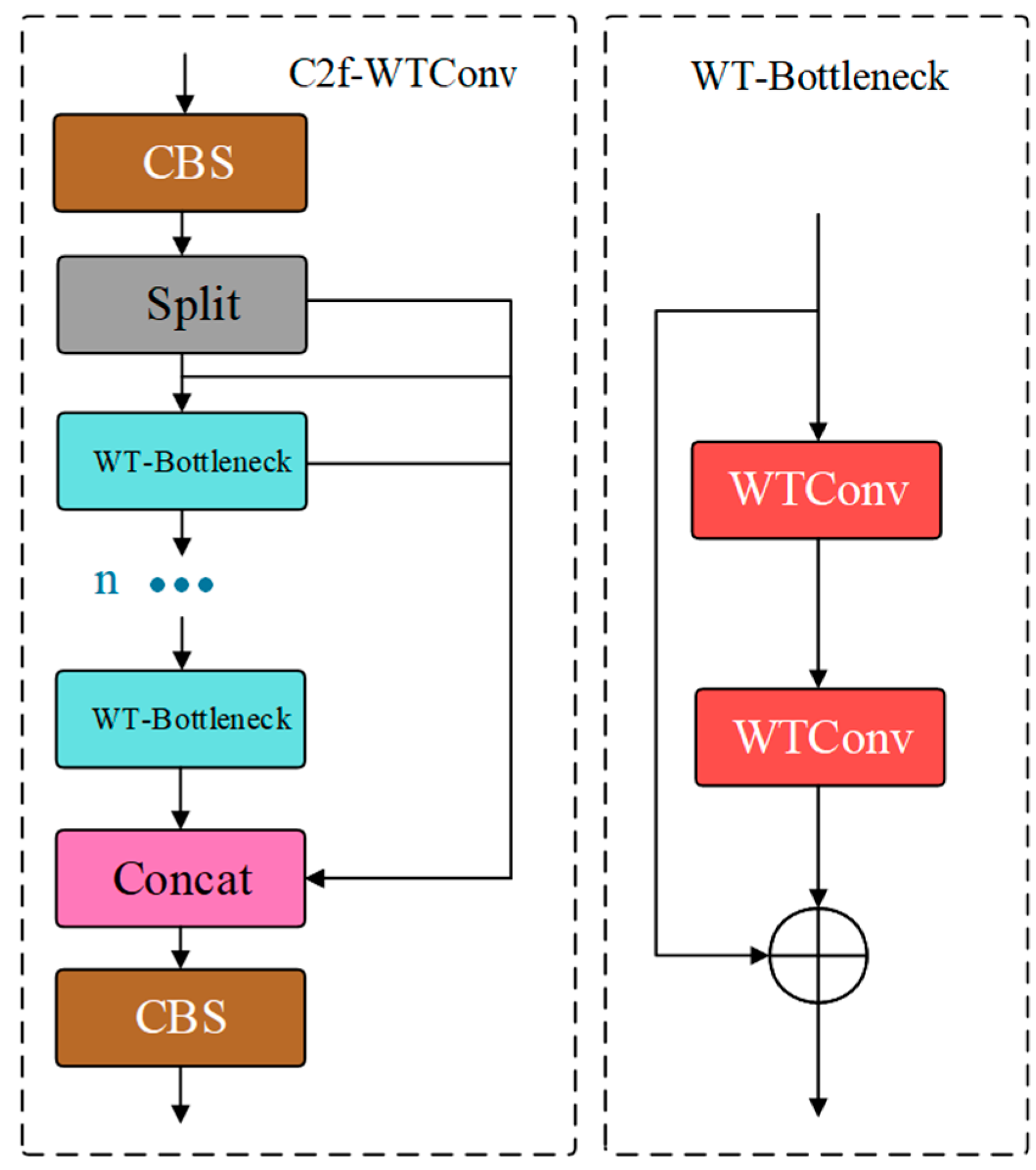
- WTConv was used to expand the receptive field, enhancing the model’s ability to extract and represent features in complex underwater environments. This capability is critical for robotic systems to accurately locate partially buried scallops and starfish in sandy substrates, contributing to enhanced fishing efficiency.
- A Deformable Attention-based Spatial Pyramid Pooling Fast (DASPPF) module was designed, which dynamically adjusts the network’s attention to objects, reducing interference from complex backgrounds in detection tasks. This module minimizes false positives caused by overlapping objects, supporting more accurate harvesting operations.
- To address the issue of small object feature information being easily lost in deep network layers, the SF-PAFPN feature fusion module was designed. It enhances the model’s ability to fuse small object features without significantly increasing the computational load, thereby improving the detection capability for smaller marine benthos objects. This improvement has the potential to optimize resource utilization and support more efficient harvesting practices.
2. Related Works
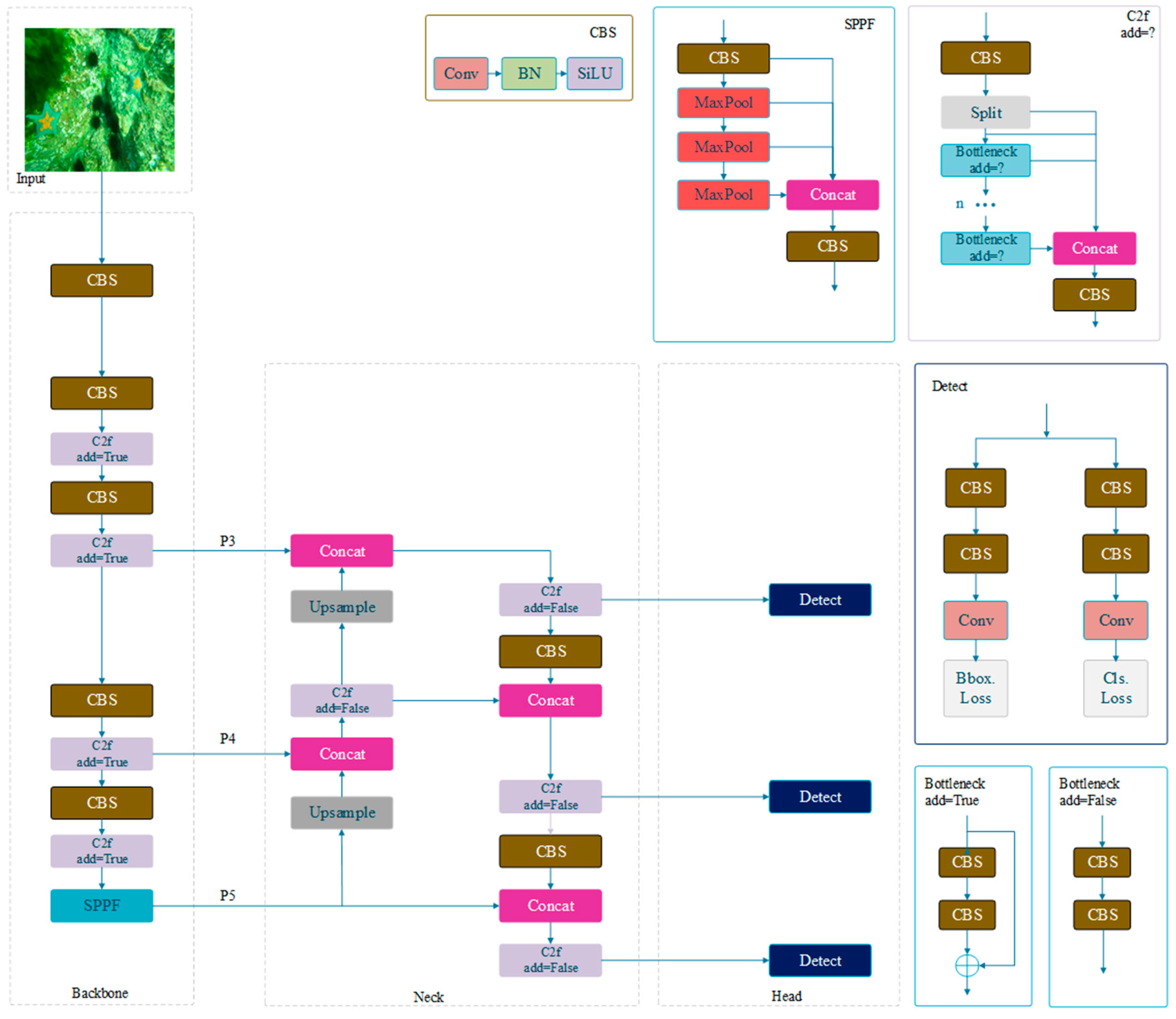
2.1. YOLOv8 Object Detection Network
2.2. Attention Mechanism
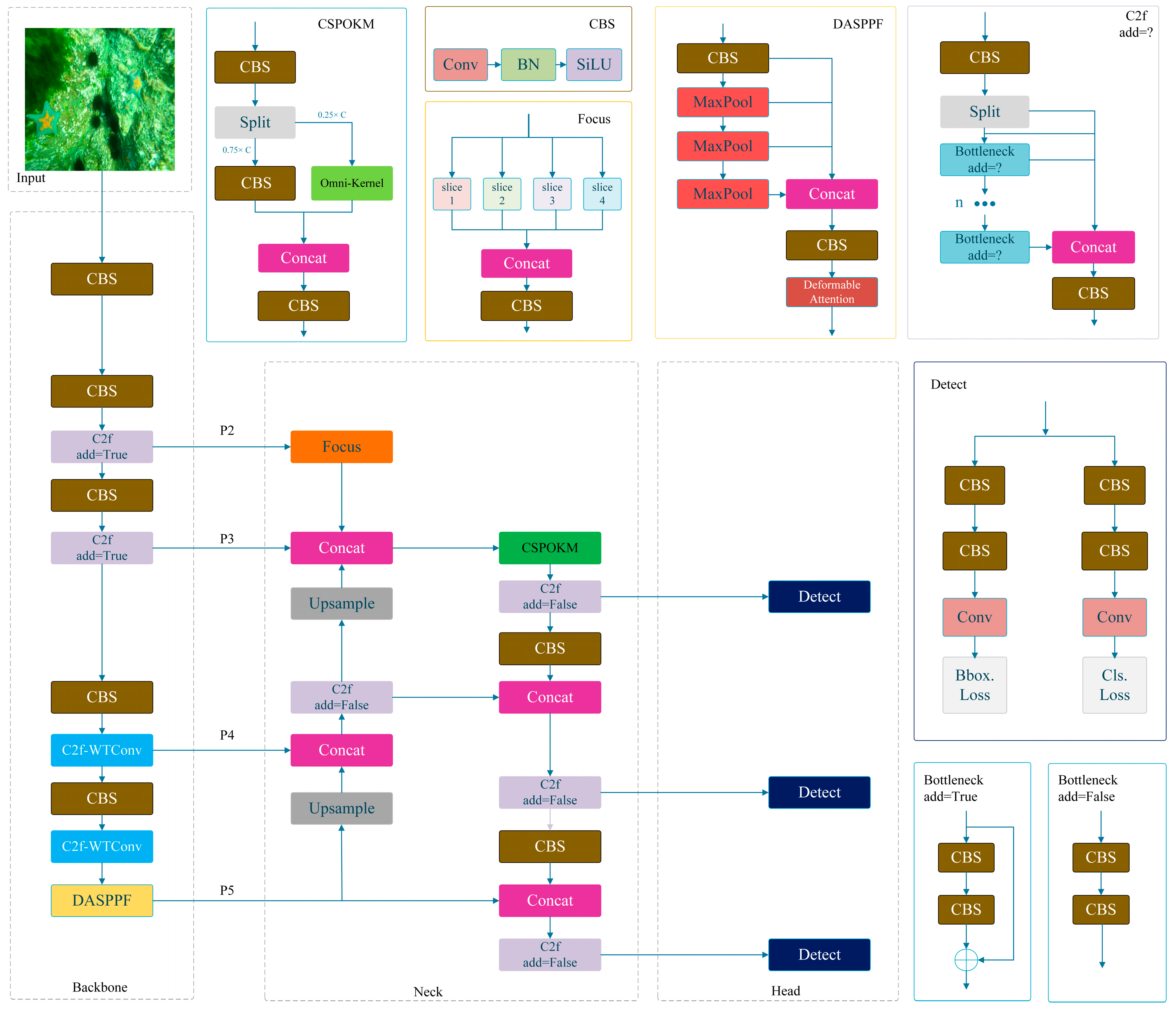
3. Methods
3.1. Feature Extraction Module: C2f-WTConv
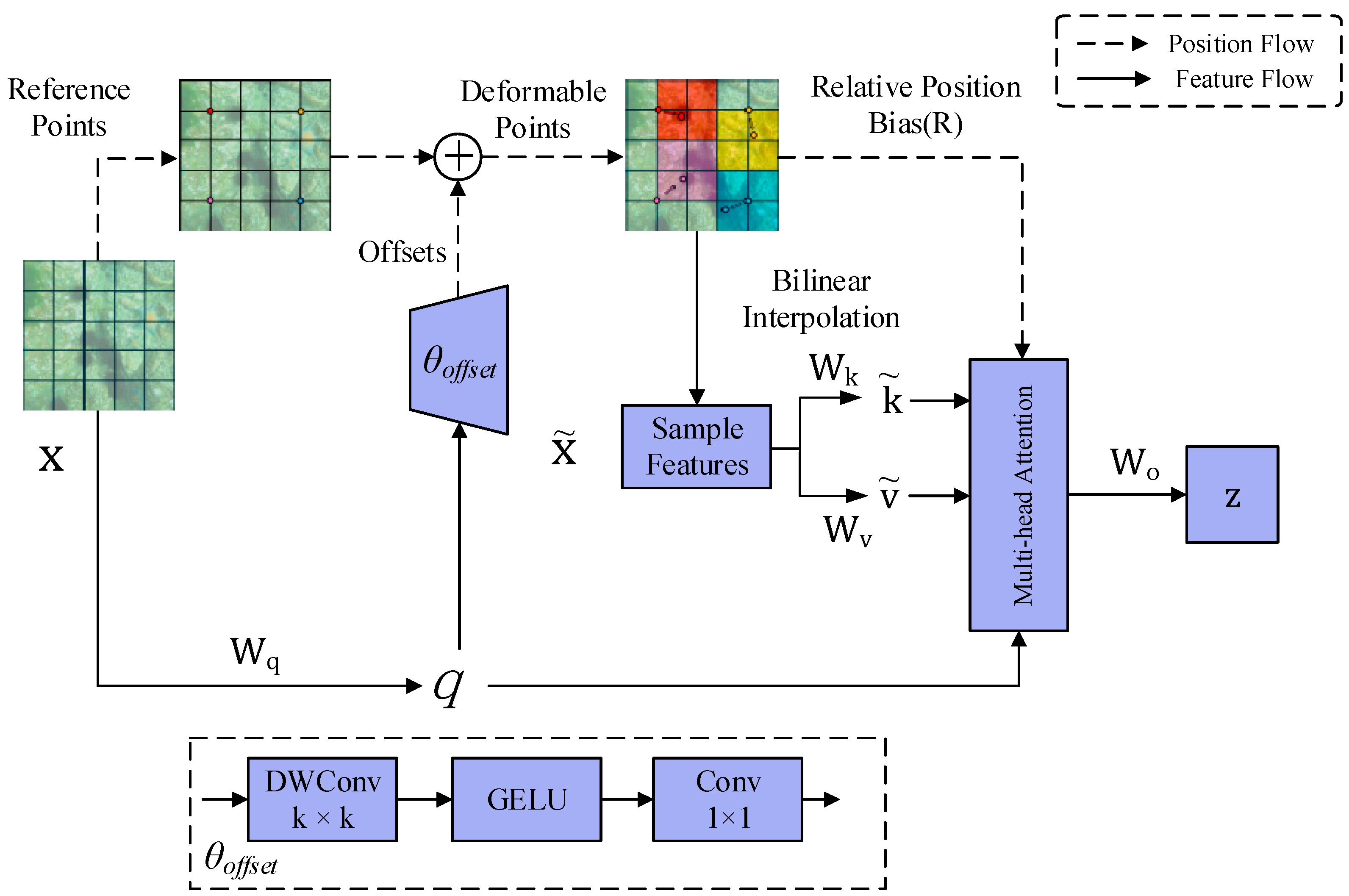
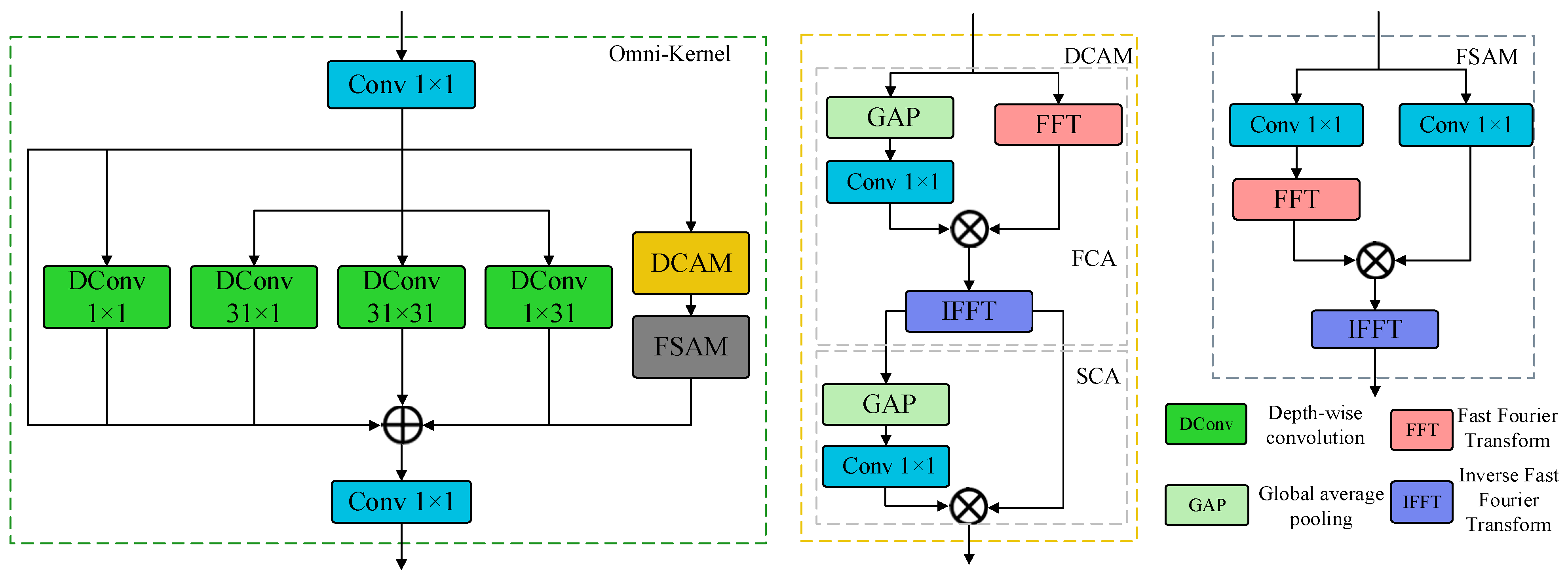
3.2. Deformable Attention-Integrated Spatial Pyramid Pooling Fast (DASPPF) Module
3.3. Enhanced Neck Structure: SF-PAFPN
4. Experiments
4.1. Experiment Setup
4.1.1. Experimental Dataset
4.1.2. Experiment Environment
4.2. Experiment Results
4.2.1. Ablation Experiment
4.2.2. Comparative Experiment
4.2.3. Generalization Experiment
4.2.4. Visual Comparison of Detection Results
4.2.5. Sub-Experiments of Improvement Points
- Sub-experiment 1: Comparison of various attention modules
- Sub-experiment 2: Comparison of small object detection methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| R-CNN | Region with CNN Features |
| RT-DETR | Real-Time Detection Transformer |
| YOLO | You Only Look Once |
| NMS | Non-Maximum Suppression |
| FPN | Feature Pyramid Network |
| DCP | Deformable Convolution Pyramid |
| DASPPF | Deformable Attention-based Spatial Pyramid Pooling Fast |
| SE | Squeeze-and-Excitation |
| CA | Coordinate Attention |
| ECA | Efficient Channel Attention |
| CBAM | Convolutional Block Attention Module |
| EMA | Efficient Multi-Scale Attention |
| BRA | Bilinear Routing Attention |
| WTConv | Wavelet Convolution |
| URPC | Underwater Robot Professional Contest |
References
- Yu, G.; Cai, R.; Su, J.P.; Hou, M.; Deng, R. U-YOLOv7: A network for underwater organism detection. Ecol. Inform. 2023, 75, 102108. [Google Scholar]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar]
- Huang, H.; Tang, Q.; Li, J.; Zhang, W.; Bao, X.; Zhu, H.; Wang, G. A review on underwater autonomous environmental perception and target grasp, the challenge of robotic organism capture. Ocean. Eng. 2020, 195, 106644. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar]
- Cai, Z.W.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2024; pp. 16965–16974. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision 2016, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.K.; Lyu, S.C.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ultralytics: Yolov5. [EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 2 November 2024).
- Chen, Z.; Zhang, F.; Liu, H.; Wang, L.X.; Zhang, Q.; Guo, L.L. Real-time detection algorithm of helmet and reflective vest based on improved YOLOv5. J. Real-Time Image Process. 2023, 20, 4. [Google Scholar]
- Wu, D.L.; Jiang, S.; Zhao, E.L.; Liu, Y.L.; Zhu, H.C.; Wang, W.W.; Wang, R.Y. Detection of Camellia oleifera fruit in complex scenes by using YOLOv7 and data augmentation. Appl. Sci. 2022, 12, 11318. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Yan, R.; Wen, X.; Li, D.; Jiang, H.B.; Jiang, N.; Feng, L.; Duan, X.L.; et al. An attention mechanism-improved YOLOv7 object detection algorithm for hemp duck count estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Li, B.; Chen, Y.; Xu, H.; Fei, Z. Fast vehicle detection algorithm on lightweight YOLOv7-tiny. arXiv 2023, arXiv:2304.06002. [Google Scholar]
- Kulyukin, V.A.; Kulyukin, A.V. Accuracy vs. energy: An assessment of bee object inference in videos from on-hive video loggers with YOLOv3, YOLOv4-Tiny, and YOLOv7-Tiny. Sensors 2023, 23, 6791. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Z.; Tong, L.; Jiang, Z.; Wang, S.; Dong, J.; Zhou, H.Y. Underwater object detection using Invert Multi-Class Adaboost with deep learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lin, W.; Zhong, J.; Liu, S.; Li, T.; Li, G. Roimix: Proposal-fusion among multiple images for underwater object detection. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2588–2592. [Google Scholar]
- Xu, F.; Wang, H.; Peng, J.; Fu, X. Scale-aware feature pyramid architecture for marine object detection. Neural Comput. Appl. 2021, 33, 3637–3653. [Google Scholar]
- Qi, S.; Du, J.; Wu, M.; Yi, H.; Tang, L.; Qian, T.; Wang, X. Underwater small target detection based on deformable convolutional pyramid. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 2784–2788. [Google Scholar]
- Liu, Y.; Wang, S. A quantitative detection algorithm based on improved Faster R-CNN for marine benthos. Ecol. Inform. 2021, 61, 101228. [Google Scholar]
- Fu, X.; Liu, Y.; Liu, Y. A case study of utilizing YOLOT based quantitative detection algorithm for marine benthos. Ecol. Inform. 2022, 70, 101603. [Google Scholar]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on YOLO v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Liu, P.; Qian, W.; Wang, Y. YWnet: A convolutional block attention-based fusion deep learning method for complex underwater small target detection. Ecol. Inform. 2024, 79, 102401. [Google Scholar]
- Wen, G.; Li, S.; Liu, F.C.; Luo, X.; Er, M.; Mahmud, M.; Wu, T. YOLOv5s-CA: A modified YOLOv5s network with coordinate attention for underwater target detection. Sensors 2023, 23, 3367. [Google Scholar] [CrossRef]
- Zhang, L.; Fan, J.; Qiu, Y.; Jiang, Z.; Hu, Q.; Xing, B.W.; Xu, J.X. Marine zoobenthos recognition algorithm based on improved lightweight YOLOv5. Ecol. Inform. 2024, 80, 102467. [Google Scholar]
- Yi, W.; Wang, B. Research on underwater small target detection algorithm based on improved YOLOv7. IEEE Access 2023, 11, 66818–66827. [Google Scholar]
- Zhang, J.; Zhang, J.; Zhou, K.; Zhang, Y.; Chen, H.; Yan, X. An improved YOLOv5-based underwater object-detection framework. Sensors 2023, 23, 3693. [Google Scholar]
- Liu, K.; Peng, L.; Tang, S. Underwater object detection using TC-YOLO with attention mechanisms. Sensors 2023, 23, 2567. [Google Scholar] [CrossRef]
- Wang, J.; Li, Q.; Fang, Z.; Zhou, X.; Tang, Z.; Han, Y.; Ma, Z. YOLOv6-ESG: A lightweight seafood detection method. J. Mar. Sci. Eng. 2023, 11, 1623. [Google Scholar] [CrossRef]
- Liu, K.; Sun, Q.; Sun, D.; Peng, L.; Yang, M.; Wang, N. Underwater target detection based on improved YOLOv7. J. Mar. Sci. Eng. 2023, 11, 677. [Google Scholar] [CrossRef]
- Zhou, H.; Kong, M.; Yuan, H.; Pan, Y.; Wang, X.; Chen, R.; Lu, W.; Wang, R.Z.; Yang, Q.H. Real-time underwater object detection technology for complex underwater environments based on deep learning. Ecol. Inform. 2024, 82, 102680. [Google Scholar] [CrossRef]
- Guo, A.; Sun, K.; Zhang, Z. A lightweight YOLOv8 integrating FasterNet for real-time underwater object detection. J. Real-Time Image Process. 2024, 21, 49. [Google Scholar] [CrossRef]
- Qu, S.; Cui, C.; Duan, J.; Lu, Y.; Pang, Z. Underwater small target detection under YOLOv8-LA model. Sci. Rep. 2024, 14, 16108. [Google Scholar] [CrossRef] [PubMed]
- Pan, W.; Chen, J.; Lv, B.; Peng, L. Optimization and Application of Improved YOLOv9s-UI for Underwater Object Detection. Appl. Sci. 2024, 14, 7162. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, W.; Du, X.; Yan, Z. Underwater small target detection based on YOLOX combined with MobileViT and double coordinate attention. J. Mar. Sci. Eng. 2023, 11, 1178. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; pp. 363–380. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, B. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Zhai, X.; Huang, Z.; Li, T.; Liu, H.; Wang, S. YOLO-Drone: An Optimized YOLOv8 Network for Tiny UAV Object Detection. Electronics 2023, 12, 3664. [Google Scholar] [CrossRef]
- Cui, Y.; Ren, W.; Knoll, A. Omni-Kernel Network for Image Restoration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 1426–1434. [Google Scholar]
- Han, Y.; Chen, L.; Luo, Y.; Ai, H.; Hong, Z.; Ma, Z.; Zhang, Y. Underwater Holothurian Target-Detection Algorithm Based on Improved CenterNet and Scene Feature Fusion. Sensors 2022, 22, 7204. [Google Scholar] [CrossRef] [PubMed]
- Fu, C.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Luo, Z. Rethinking General Underwater Object Detection: Datasets, Challenges, and Solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase | Total Instances | Holothurian | Echinus | Starfish | Scallop |
|---|---|---|---|---|---|
| Training | 40,107 | 4502 | 20,356 | 6473 | 8776 |
| Validation | 5660 | 619 | 2780 | 947 | 1314 |
| Test | 11,645 | 1250 | 5488 | 1844 | 3063 |
| WTConv | DASPPF | SF-PAFPN | P/% | R/% | mAP@50/% | Params/M | FPS/(f·s−1) |
|---|---|---|---|---|---|---|---|
| 81.5 | 77.8 | 83.5 | 3.0 | 114.1 | |||
| √ | 82.4 | 76.0 | 83.7 | 2.6 | 118.3 | ||
| √ | 83.6 | 77.2 | 84.3 | 3.2 | 113.1 | ||
| √ | 83.2 | 78.1 | 84.7 | 3.3 | 109.5 | ||
| √ | √ | 82.6 | 77.2 | 84.6 | 3.5 | 107.1 | |
| √ | √ | 82.7 | 77.9 | 84.9 | 2.9 | 105.5 | |
| √ | √ | √ | 83.8 | 78.6 | 85.6 | 3.2 | 104.5 |
| Method | mAP@50/% | Params/M | FLOPs/G |
|---|---|---|---|
| Faster R-CNN | 78.6 | 41.4 | 239.3 |
| Cascade R-CNN | 80.0 | 69.2 | 119.0 |
| SSD | 75.1 | 26.3 | 63.4 |
| ATSS | 80.7 | 32.1 | 80.5 |
| YOLOv3 | 78.3 | 61.6 | 66.5 |
| YOLOv5s | 83.9 | 9.1 | 23.8 |
| YOLOv7-tiny | 84.6 | 6.0 | 13.2 |
| YOLOv8n | 83.5 | 3.0 | 8.1 |
| YOLOv9-t | 83.9 | 2.7 | 11.1 |
| YOLOv10n | 82.8 | 2.7 | 8.2 |
| YOLO11n | 80.0 | 2.6 | 6.3 |
| RT-DETR | 83.8 | 19.9 | 57.0 |
| WDS-YOLO | 85.6 | 3.2 | 11.4 |
| Method | mAP@50/% | Params/M | FLOPs/G |
|---|---|---|---|
| Faster R-CNN | 75.2 | 41.4 | 239.3 |
| YOLOv7-tiny | 81.5 | 6.0 | 13.2 |
| YOLOv8n | 83.8 | 3.0 | 8.1 |
| WDS-YOLO | 84.9 | 3.2 | 11.4 |
| Module | P/% | R/% | mAP@50/% | mAP@50:95/% | Params/M | FLOPs/G |
|---|---|---|---|---|---|---|
| SPPF | 81.5 | 77.8 | 83.5 | 48.9 | 3.0 | 8.1 |
| SPPF + SimAM | 82.4 | 76.4 | 83.6 | 48.8 | 3.0 | 8.1 |
| SPPF + SE | 82.1 | 75.8 | 83.3 | 48.5 | 3.0 | 8.1 |
| SPPF + CBAM | 83.4 | 75.7 | 83.5 | 48.8 | 3.0 | 8.1 |
| SPPF + CA | 82.5 | 76.4 | 83.4 | 48.8 | 3.0 | 8.1 |
| SPPF + EMA | 82.4 | 76.4 | 83.6 | 48.8 | 3.0 | 8.1 |
| SPPF + ECA | 80.4 | 77.9 | 83.9 | 48.9 | 3.0 | 8.1 |
| SPPF + BRA | 80.7 | 77.8 | 83.6 | 48.8 | 3.2 | 8.3 |
| SPPF + DA | 83.6 | 77.2 | 84.3 | 49.4 | 3.2 | 8.3 |
| Module | P/% | R/% | mAP@50/% | mAP@50:95/% | FLOPs/G |
|---|---|---|---|---|---|
| P2 | 81.1 | 77.6 | 83.6 | 49.2 | 12.2 |
| SF-PAFPN | 83.2 | 78.1 | 84.7 | 49.5 | 11.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, J.; Chen, M. WDS-YOLO: A Marine Benthos Detection Model Fusing Wavelet Convolution and Deformable Attention. Appl. Sci. 2025, 15, 3537. https://doi.org/10.3390/app15073537
Qian J, Chen M. WDS-YOLO: A Marine Benthos Detection Model Fusing Wavelet Convolution and Deformable Attention. Applied Sciences. 2025; 15(7):3537. https://doi.org/10.3390/app15073537
Chicago/Turabian StyleQian, Jiahui, and Ming Chen. 2025. "WDS-YOLO: A Marine Benthos Detection Model Fusing Wavelet Convolution and Deformable Attention" Applied Sciences 15, no. 7: 3537. https://doi.org/10.3390/app15073537
APA StyleQian, J., & Chen, M. (2025). WDS-YOLO: A Marine Benthos Detection Model Fusing Wavelet Convolution and Deformable Attention. Applied Sciences, 15(7), 3537. https://doi.org/10.3390/app15073537