
Fast Fourier Asymmetric Context Aggregation Network: A Controllable Photo-Realistic Clothing Image Synthesis Method Using Asymmetric Context Aggregation Mechanism

Abstract
1. Introduction
- We propose a novel clothing image synthesis method guided by design sketches and texture patches, enabling precise control over both the structural appearance and texture style of the clothing. Our method provides innovative and practical solutions for scenarios such as personalized clothing design and rapid prototyping.
- We design a new content inference module, the Fast Fourier Channel Dual Residual Block (FF-CDRB), which utilizes the global receptive field characteristics of Fast Fourier Convolution (FFC). This module improves the network’s ability to capture contextual information and perform accurate content inference while also improving the efficiency of parameter computation. By integrating the FF-CDRB, the model demonstrates its capability to generate high-quality images with optimized parameter utilization, ensuring both accuracy and computational efficiency.
- We propose a novel Asymmetric Context Aggregation Mechanism (ACAM), which constructs global context by effectively leveraging heterogeneous features with distinct information representation characteristics from different scales and stages. This approach addresses the limitations of the existing methods in context modeling. The ACAM significantly improves both the perceptual and pixel-level quality of generated images while also enhancing the model’s robustness to variations in texture patch size. To the best of our knowledge, the ACAM is an innovative method for context information interaction, providing potentially valuable references for the research community.
- Extensive experiments were conducted on our self-constructed dataset, SKFashion, as well as two public datasets, VITON-HD and Fashion-Gen, to validate the effectiveness of the FCAN. The experimental results show that those images generated by the FCAN outperform advanced baseline methods in terms of both perceptual and pixel-level quality. Moreover, the FCAN demonstrates greater robustness to variations in texture patch conditions compared to the other methods, making it more suitable for meeting practical application requirements.
2. Related Work
2.1. Image Generation Models
2.2. Fashion Clothing Image Synthesis
2.3. Fast Fourier Convolution
3. Proposed Method
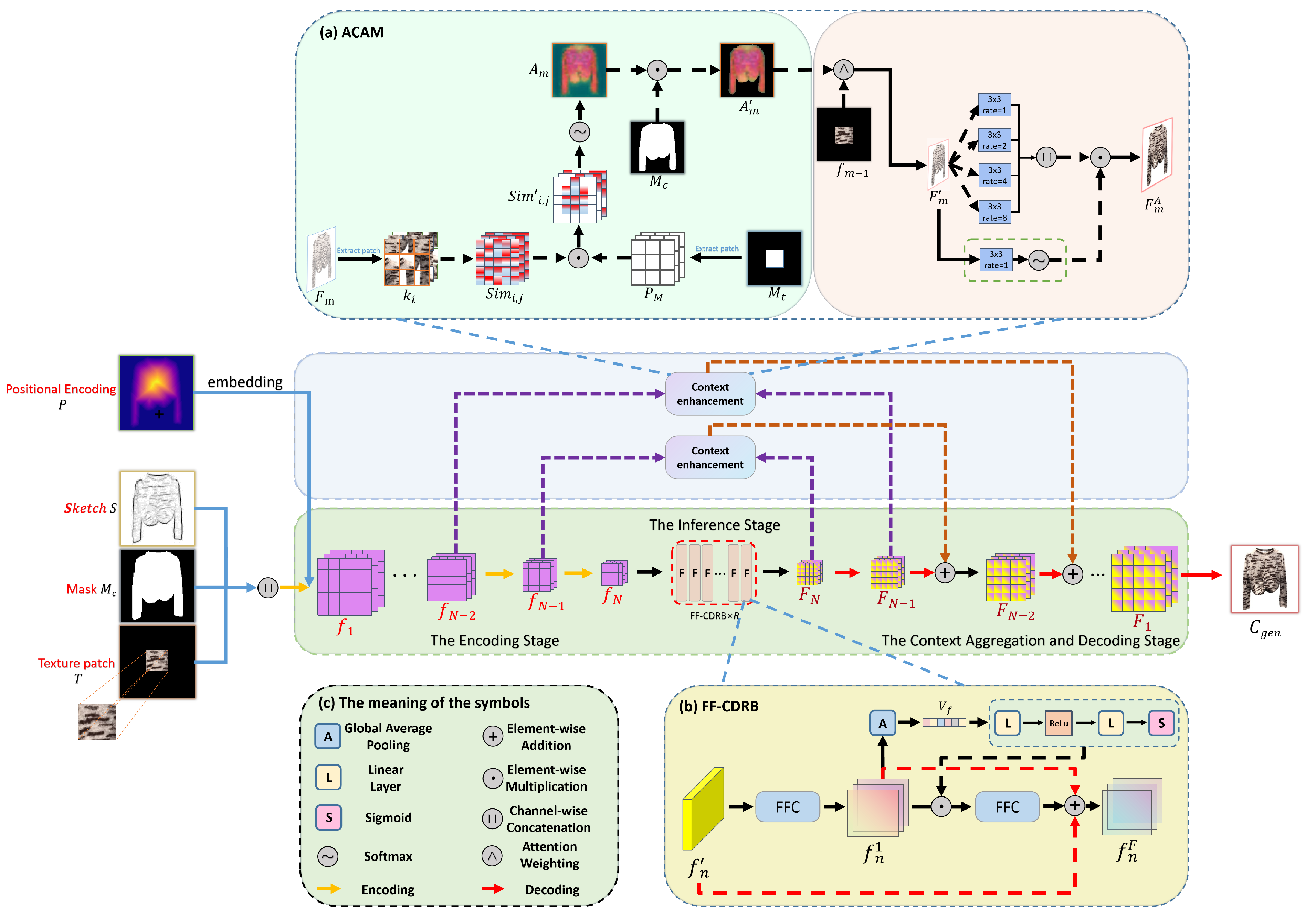
3.1. Overview
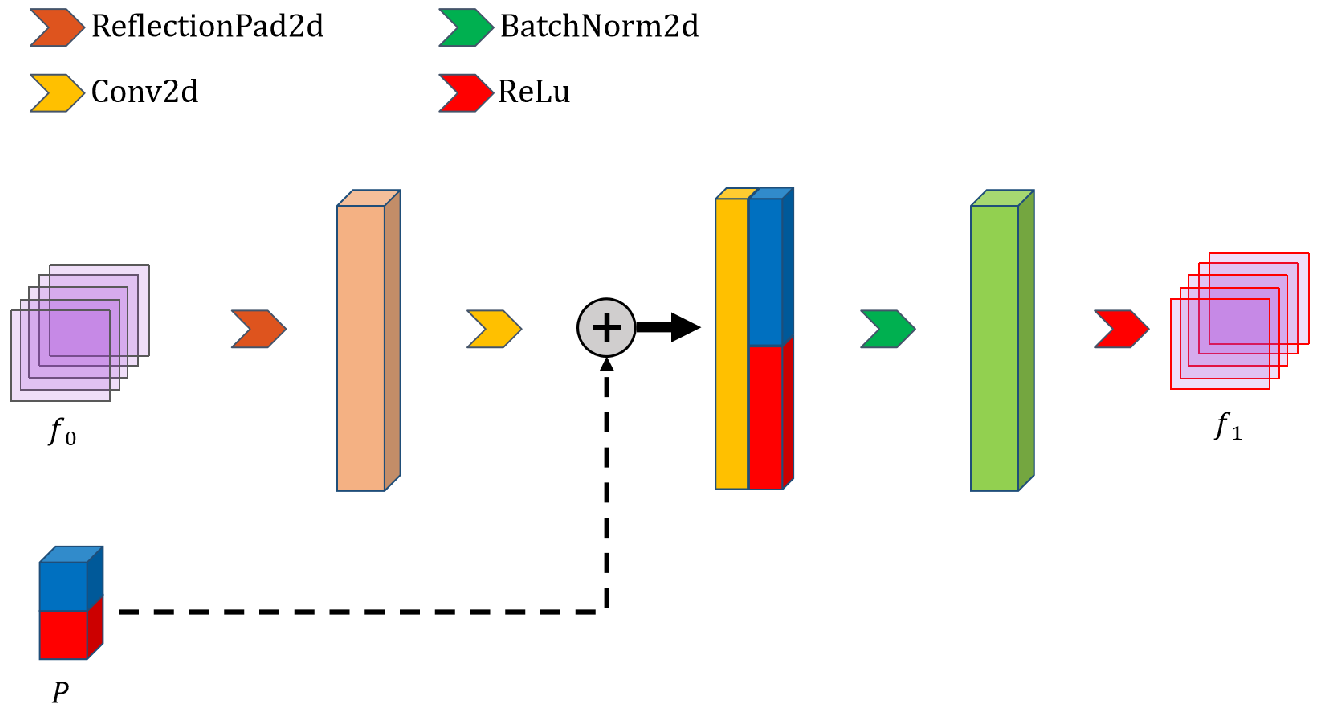
3.2. The Encoding Stage
3.3. The Content Inference Stage
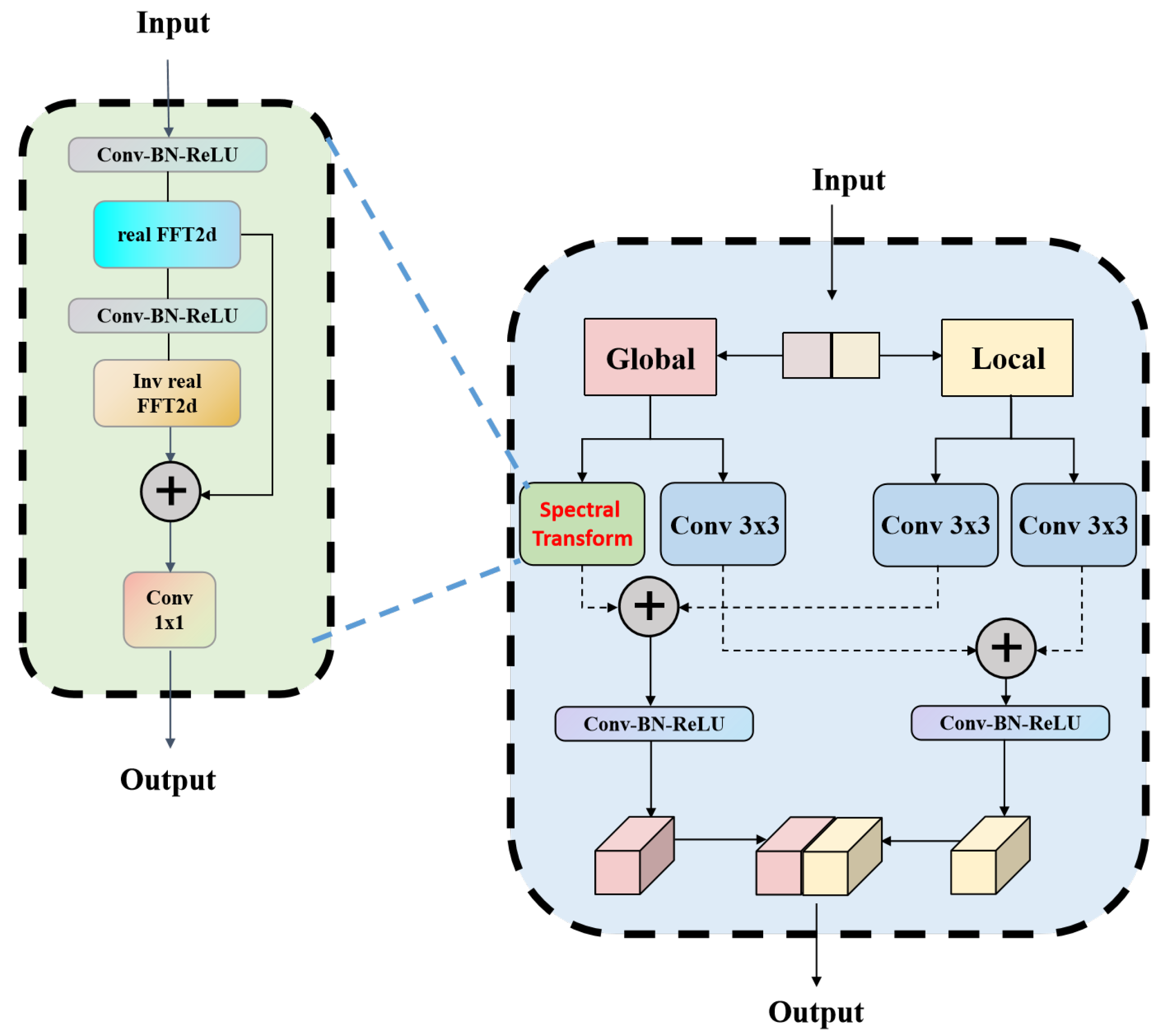
Fast Fourier Channel Dual Residual Block
- Apply real FFT to input features:where , and C represent the height, width, and number of channels of the tensor, respectively, and × represents multiplication, indicating that the dimensions of height, width, and channels are multiplied together to define the size of the feature map. and represent a real-valued tensor with spatial dimensions and a complex tensor with spatial dimensions , respectively. FFT represents the real-valued Fourier transform, and a detailed explanation and derivation of FFT can be found in [64].
- Concatenates real and imaginary parts:where ComplexToReal represents the concatenation of the real and imaginary parts of the input tensor.
- Apply convolution operations in the frequency domain:where Conv represents the convolution operation.
- Apply inverse transform to recover a spatial structure:where RealToComplex represents the conversion of a real-valued tensor into a complex-valued tensor for the application of the inverse transform. InverseRealFFT represents the application of the inverse real-valued FFT to restore the tensor to its real-valued form. Similarly, the detailed process of the inverse transform can be found in [64].
- Apply global average pooling to compress into a vector to capture global information:where represents the result of compressing the features using global average pooling.
- Map the features of through a learnable fully connected layer, and finally apply the Sigmoid function to obtain the adaptive weight vector :where represents a learnable fully connected layer used to capture feature information in the compressed vector, while represents the sigmoid function, which normalizes the final result into the weight vector w.
- Use the channel-adaptive weights to adjust the response levels of the local and global branch features in , ultimately obtaining the feature representation with adaptive weight adjustments:
3.4. The Context Aggregation and Decoding Stage
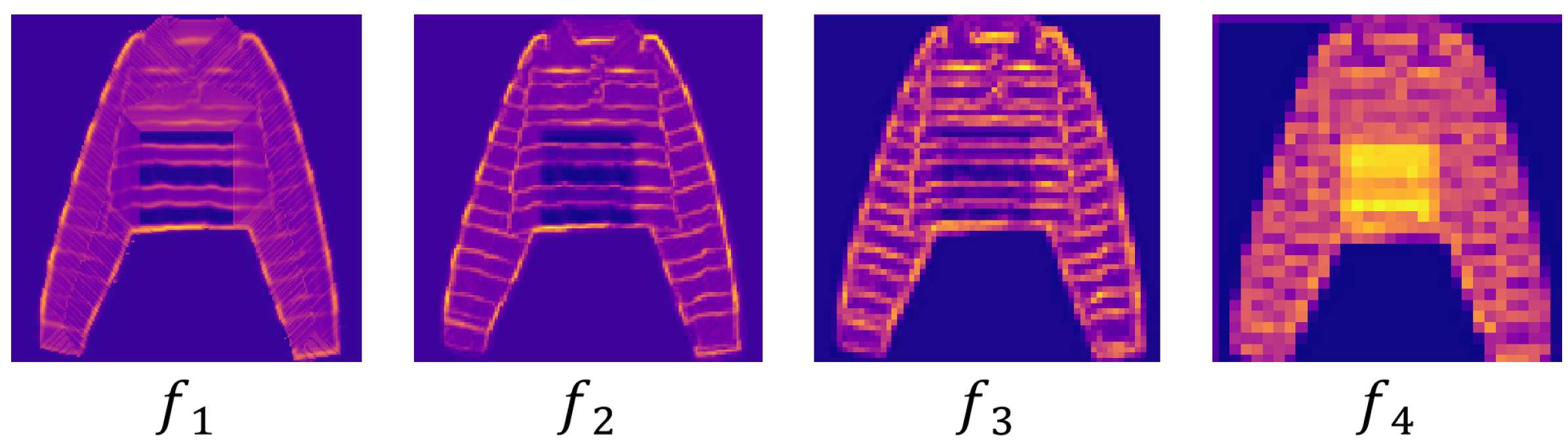
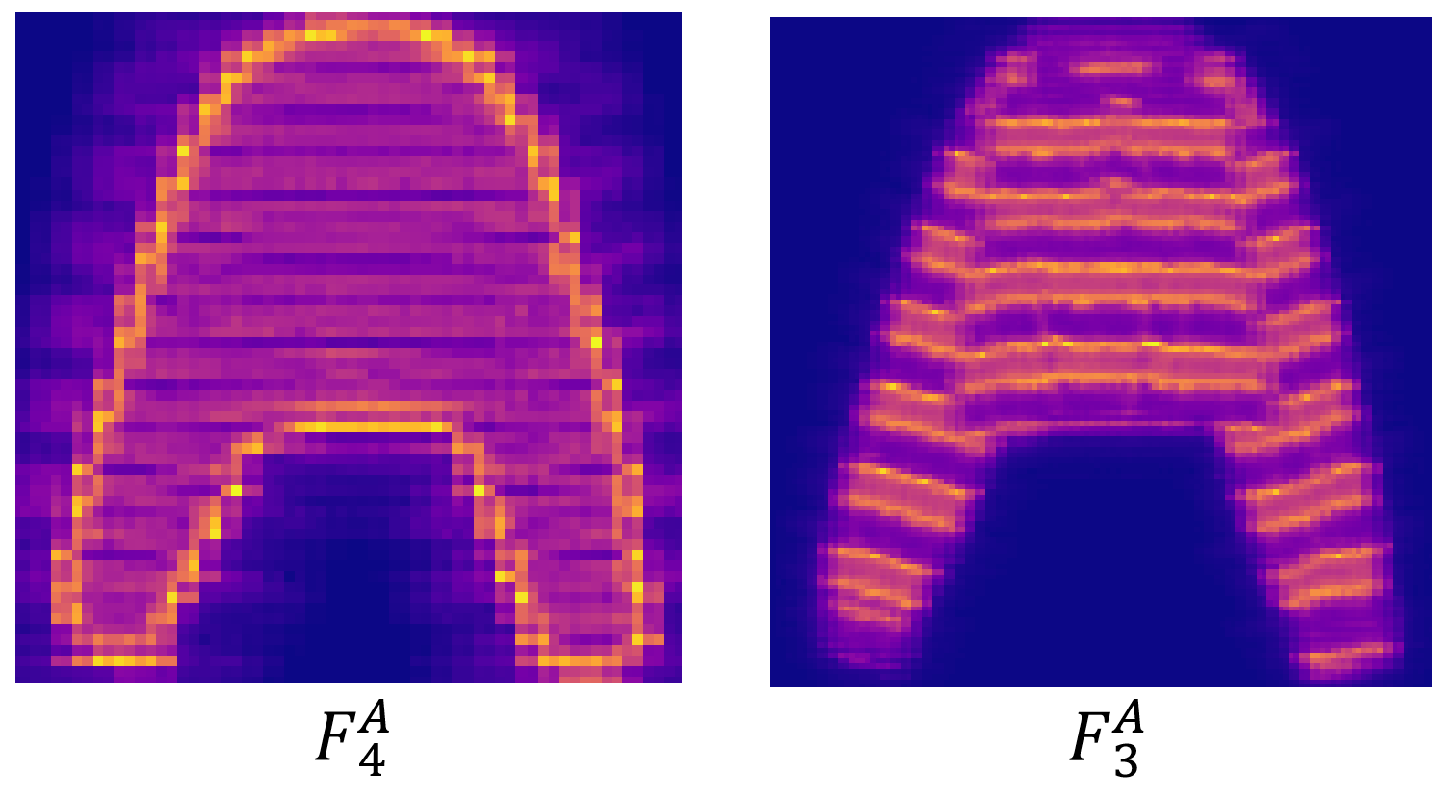
Asymmetric Context Aggregation Mechanism
| Algorithm 1 Algorithm of the FCAN |
| Input: Sketch S, Clothing Mask , and Texture Patch T Output: Synthesized Clothing Image
|
3.5. Loss Functions
4. Experiments
4.1. Dataset
- SKFashion: The SKFashion dataset consists of 20,421 paired design sketches and fashion images, each with a resolution of 256 × 256 pixels. It covers dozens of fashion categories, including long sleeves, short sleeves, dresses, shorts, skirts, padded coats, jackets, and vests. Figure 9 presents a selection of image pairs from SKFashion. Following the setup in [56], we divided the SKFashion dataset into a training set containing 17,396 image pairs and a test set comprising 3025 image pairs.
- VITON-HD: The VITON-HD dataset includes images of various upper-body clothing categories and is widely used in fashion image generation tasks such as virtual try-on. We standardized the resolution of the clothing images in VITON-HD to 192 × 256 pixels and utilized the garment structure edge maps extracted using DexiNed (Dense Extreme Inception Network for Edge Detection) [73] as design sketches. We divided the dataset into a training set comprising 10,309 sketch–clothing image pairs and a test set with 1010 pairs. Figure 10 illustrates a selection of image pairs from the VITON-HD dataset.
- Fashion-Gen: The Fashion-Gen is a large-scale multimodal dataset designed for fashion-related tasks and is widely used in multimodal fashion image generation. We extracted clothing images from Fashion-Gen using [74] and generated corresponding design sketches by applying DexiNed to obtain structural edge maps of the garments. Following the setup in [53,56,57], we randomly sampled 10,282 sketch–clothing image pairs as the training set and 800 pairs as the test set. Figure 11 showcases a selection of image pairs from the Fashion-Gen dataset.
4.2. Evaluation Metrics
- Fréchet Inception Distance (FID): FID [75] is an objective metric widely used to evaluate the quality of images generated by generative models. It measures the distance between the distributions of generated and real images using a pre-trained Inception network, quantifying the perceptual similarity between them. By considering both the global feature distribution and perceptual similarity, FID effectively assesses the overall quality of generated images, aligning closely with human visual perception. We use FID to evaluate the overall diversity and global perceptual quality of the generated images. The calculation of FID is as follows:where and represent the mean vector and covariance matrix of the generated image features, respectively, while and represent the mean vector and covariance matrix of the real image features, respectively. represents the square of the Euclidean norm of the difference between two mean vectors. Tr represents the trace of a matrix.
- Structural Similarity (SSIM): SSIM [76] is an evaluation metric used to measure the similarity of two images. SSIM focuses on the brightness, contrast, and structure of the image. We use SSIM to evaluate the quality of the generated image in terms of local structure and so on. SSIM is calculated as follows:where x and y represent the real image and the generated image, respectively. denotes the mean pixel value, represents the standard deviation of grayscale intensity, and are constant coefficients, and is defined as
- Learned Perceptual Image Patch Similarity (LPIPS): LPIPS [77] is a metric used to evaluate the perceptual similarity between two images. It assesses image quality by directly extracting features from a pre-trained neural network, making it more aligned with human visual perception. LPIPS places greater emphasis on local perceptual similarity, and we employ it to evaluate the local perceptual quality of generated images. The calculation of LPIPS is as follows:where and represent the normalized corresponding features, and is the scaling weight vector.
- Peak Signal-to-Noise Ratio (PSNR): PSNR is a pixel-level image quality metric that is sensitive to the random noise in the image. We use PSNR to evaluate the pixel-level quality of the generated image. The calculation formula of PSNR iswhere represents the maximum pixel value of the image, and is the average value of the RGB three-channel mean square error of the real image and the generated image.
- TOPIQ: TOPIQ is a deep-learning-based image quality assessment method that utilizes multi-scale features and cross-scale attention mechanisms to evaluate image quality. By simulating the characteristics of the human visual system, TOPIQ leverages high-level semantic information to guide the network’s focus on semantically important local distortion regions, thereby assessing image quality. TOPIQ includes both Full-Reference (FR) and No-Reference (NR) forms. In this paper, we use them to evaluate the perceptual quality of the generated images. The specific details of TOPIQ can be found in [78].
4.3. Baseline Methods
4.4. Implementation Details
4.5. Comparison with Existing Approaches
4.5.1. Quantitative Comparison
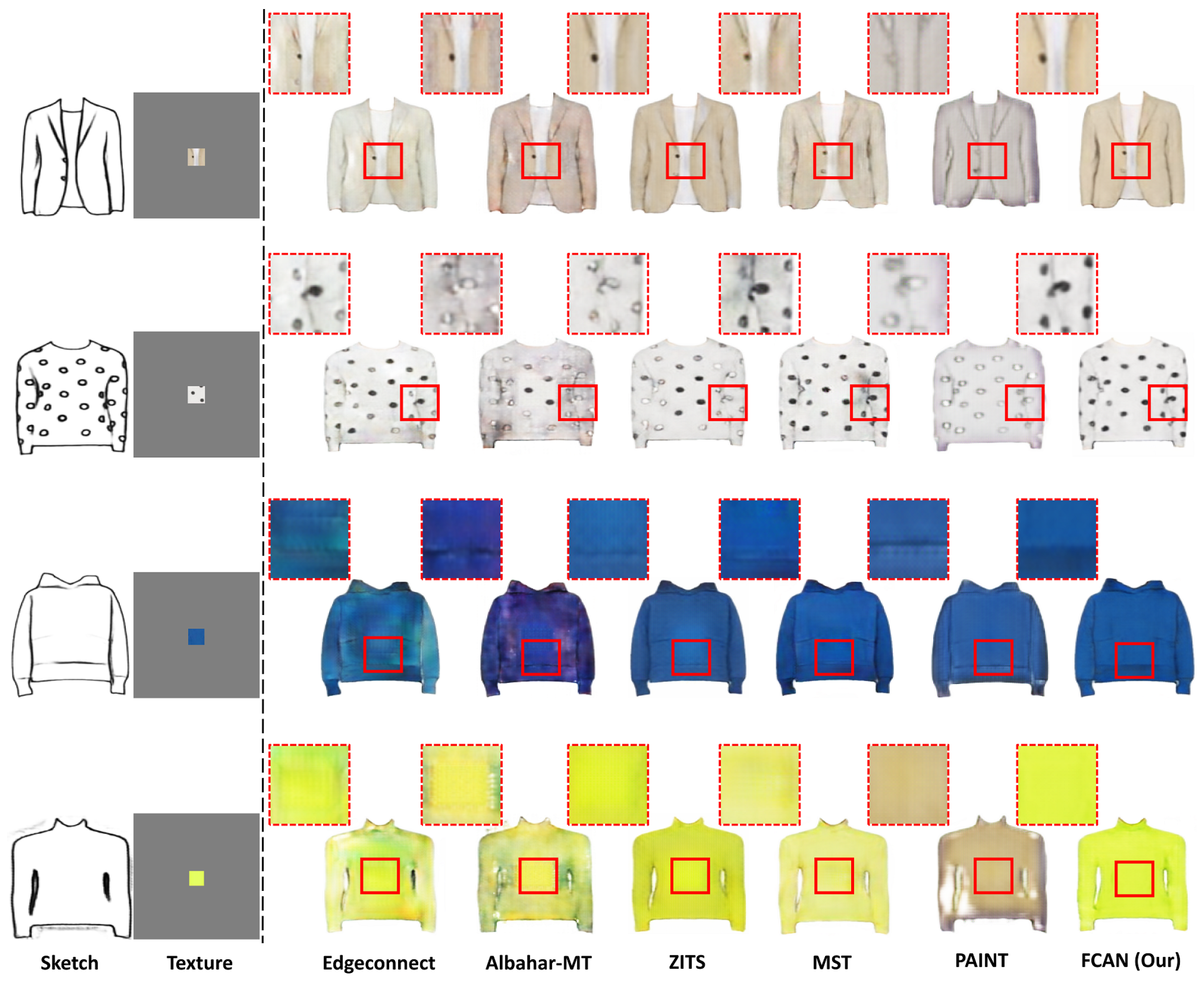
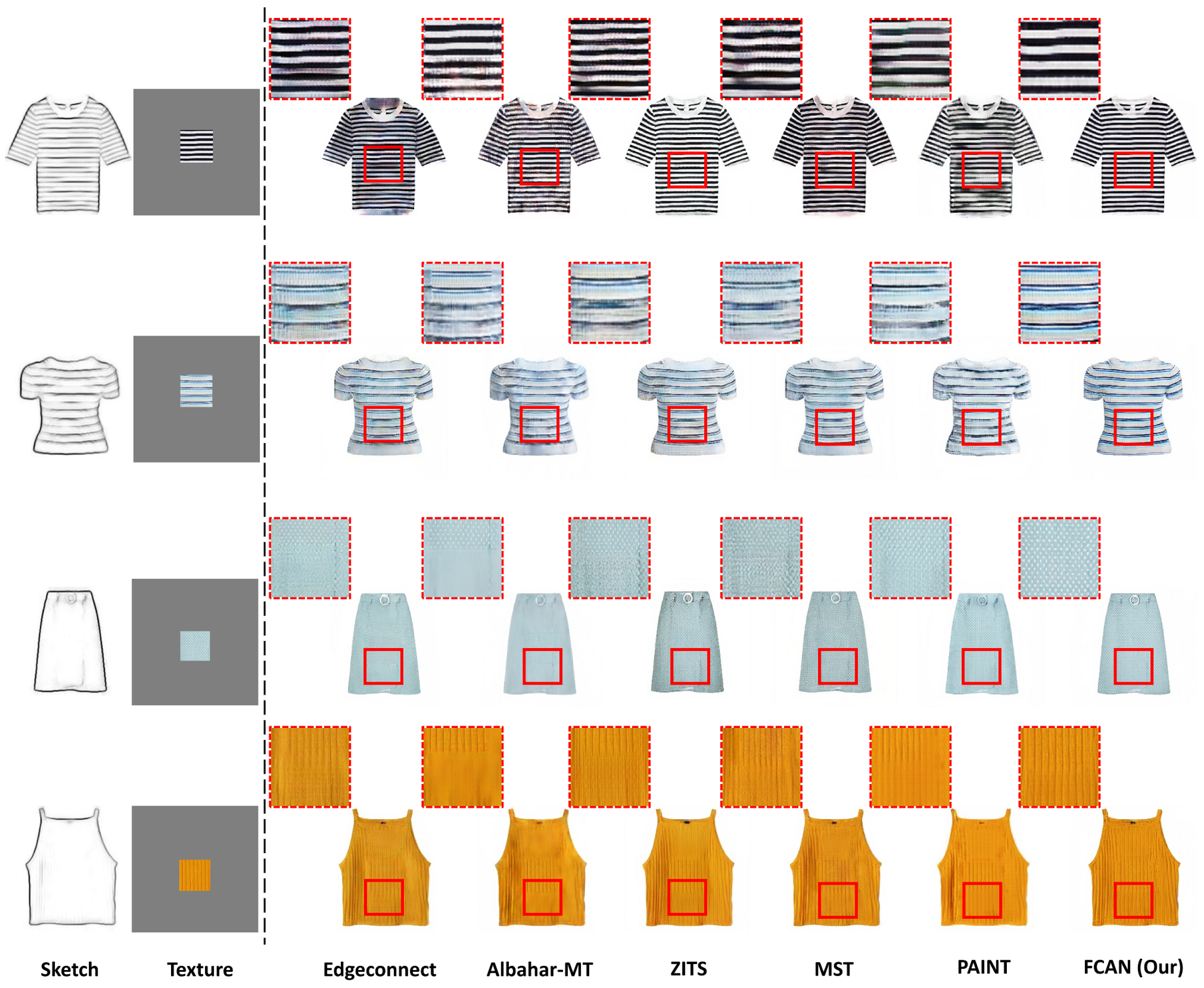
4.5.2. Qualitative Comparison
4.5.3. Ablation Studies
4.5.4. Time Performance
5. Conclusions
6. Discussion
- Optimizing the acquisition process of sketch and texture data to enhance the practical value of the method;
- Improving its synthesis performance under more extreme guidance conditions to further broaden its applicability;
- Improving time efficiency without sacrificing performance or while enhancing performance;
- Exploring cross-applications with related tasks such as virtual try-on, clothing retrieval, and recommendation systems to expand its use cases.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A





References
- Guo, Z.; Zhu, Z.; Li, Y.; Chen, S.C.H.; Wang, G. AI Assisted Fashion Design: A Review. IEEE Access 2023, 11, 88403–88415. [Google Scholar] [CrossRef]
- Oh, J.; Ha, K.J.; Jo, Y.H. A Predictive Model of Seasonal Clothing Demand with Weather Factors. Asia-Pac. J. Atmos. Sci. 2022, 58, 667–678. [Google Scholar] [CrossRef]
- Linlin, L.; Haijun, Z.; Qun, L.; Jianghong, M.; Zhao, Z. Collocated Clothing Synthesis with GANs Aided by Textual Information: A Multi-Modal Framework. ACM Trans. Multimedia Comput. Commun 2024, 20, 25. [Google Scholar]
- Lampe, A.; Stopar, J.; Jain, D.K.; Omachi, S.; Peer, P.; Štruc, V. DiCTI: Diffusion-based Clothing Designer via Text-guided Input. In Proceedings of the 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), Istanbul, Turkiye, 27–31 May 2024; pp. 1–9. [Google Scholar]
- Zhengwentai, S.; Yanghong, Z.; Honghong, H.; Mok, P.Y. DiCTI: SGDiff: A Style Guided Diffusion Model for Fashion Synthesis. In Proceedings of the 31st ACM International Conference on Multimedia (MM ’23), Association for Computing Machinery, New York, NY, USA, 29 October–3 November 2023; pp. 8433–8442. [Google Scholar]
- Cao, S.; Chai, W.; Hao, S.; Zhang, Y.; Chen, H.; Wang, G. DiffFashion: Reference-Based Fashion Design With Structure-Aware Transfer by Diffusion Models. IEEE Trans. Multimed. 2024, 26, 3962–3975. [Google Scholar] [CrossRef]
- Kim, B.-K.; Kim, G.; Lee, S.-Y. Style-controlled synthesis of clothing segments for fashion image manipulation. IEEE Trans. Multimed. 2020, 22, 298–310. [Google Scholar] [CrossRef]
- Jiang, S.; Li, J.; Fu, Y. Deep Learning for Fashion Style Generation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4538–4550. [Google Scholar] [CrossRef]
- Di, W.; Zhiwang, Y.; Nan, M.; Jianan, J.; Yuetian, W.; Guixiang, Z.; Hanhui, D.; Yi, L. StyleMe: Towards Intelligent Fashion Generation with Designer Style. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 23–28 April 2023; pp. 1–16. [Google Scholar]
- Dong, M.; Zhou, D.; Ma, J.; Zhang, H. Towards Intelligent Design: A Self-Driven Framework for Collocated Clothing Synthesis Leveraging Fashion Styles and Textures. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 3725–3729. [Google Scholar]
- Han, Y.; Haijun, Z.; Jianyang, S.; Jianghong, M.; Xiaofei, X. Toward Intelligent Fashion Design: A Texture and Shape Disentangled Generative Adversarial Network. ACM Trans. Multimed. Comput. Commun. 2023, 19, 23. [Google Scholar]
- Jianan, J.; Di, W.; Hanhui, D.; Yidan, L.; Wenyi, T.; Xiang, L.; Can, L.; Zhanpeng, J.; Wenlei, Z. Tangquan, Q. 2024. HAIGEN: Towards Human-AI Collaboration for Facilitating Creativity and Style Generation in Fashion Design. ACM Interact. Mob. Wearable Ubiquitous Technol. 2024, 8, 27. [Google Scholar]
- Han, Y.; Haijun, Z.; Xiangyu, M.; Jicong, F.; Zhao, Z. FashionDiff: A Controllable Diffusion Model Using Pairwise Fashion Elements for Intelligent Design. In Proceedings of the 31st ACM International Conference on Multimedia (MM ’23), Association for Computing Machinery, New York, NY, USA, 29 October–3 November 2023; pp. 1401–1411. [Google Scholar]
- Xian, W.; Sangkloy, P.; Agrawal, V.; Raj, A.; Lu, J.; Fang, C.; Hays, J. Texturegan: Controlling deep image synthesis with texture patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8456–8465. [Google Scholar]
- Zhou, Y.; Chen, K.; Xiao, R.; Huang, H. Neural texture synthesis with guided correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 18095–18104. [Google Scholar]
- Phillips, A.; Lang, J.; Mould, D. Diverse non-homogeneous texture synthesis from a single exemplar. Comput. Graph. 2024, 124, 104099. [Google Scholar] [CrossRef]
- Houdard, A.; Leclaire, A.; Papadakis, N.; Rabin, J. A Generative Model for Texture Synthesis based on Optimal Transport Between Feature Distributions. J. Math. Imaging Vis. 2023, 65, 4–28. [Google Scholar] [CrossRef]
- Chi, L.; Jiang, B.; Mu, Y. Fast fourier convolution. Adv. Neural Inf. Process. Syst. 2023, 33, 4479–4488. [Google Scholar]
- Chen, Z.; Zhang, Y. CA-GAN: The synthesis of Chinese art paintings using generative adversarial networks. Vis. Comput. 2024, 40, 5451–5463. [Google Scholar] [CrossRef]
- Xue, A. End-to-end chinese landscape painting creation using generative adversarial networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 3863–3871. [Google Scholar]
- Wang, Q.; Guo, C.; Dai, H.N.; Li, P. Stroke-GAN Painter: Learning to paint artworks using stroke-style generative adversarial networks. Comput. Vis. Media 2023, 9, 787–806. [Google Scholar] [CrossRef]
- Gao, X.; Tian, Y.; Qi, Z. RPD-GAN: Learning to draw realistic paintings with generative adversarial network. IEEE Trans. Image Process. 2020, 29, 8706–8720. [Google Scholar] [CrossRef]
- Way, D.L.; Lo, C.H.; Wei, Y.H.; Shih, Z.C. TwinGAN: Twin generative adversarial network for Chinese landscape painting style transfer. IEEE Access 2023, 11, 60844–60852. [Google Scholar] [CrossRef]
- Abedi, M.; Hempel, L.; Sadeghi, S.; Kirsten, T. GAN-based approaches for generating structured data in the medical domain. Appl. Sci. 2022, 12, 7075. [Google Scholar] [CrossRef]
- Yan, S.; Wang, C.; Chen, W.; Lyu, J. Swin transformer-based GAN for multi-modal medical image translation. Front. Oncol. 2022, 12, 942511. [Google Scholar] [CrossRef]
- Sun, L.; Chen, J.; Xu, Y.; Gong, M.; Yu, K.; Batmanghelich, K. Hierarchical amortized GAN for 3D high resolution medical image synthesis. IEEE J. Biomed. Health Inform. 2022, 26, 3966–3975. [Google Scholar] [CrossRef]
- Aljohani, A.; Alharbe, N. Generating synthetic images for healthcare with novel deep pix2pix gan. Electronics 2022, 11, 3470. [Google Scholar] [CrossRef]
- Alrashedy, H.H.N.; Almansour, A.F.; Ibrahim, D.M.; Hammoudeh, M.A.A. BrainGAN: Brain MRI image generation and classification framework using GAN architectures and CNN models. Sensors 2022, 22, 4297. [Google Scholar] [CrossRef]
- Jiaxi, H.; Guixiong, L. An Improved Generative Adversarial Network-Based and U-Shaped Transformer Method for Glass Curtain Crack Deblurring Using UAVs. Sensors 2024, 24, 7713. [Google Scholar] [CrossRef]
- Jiangyan, W.; Guanghui, Z.; Yugang, F. LM-CycleGAN: Improving Underwater Image Quality Through Learned Perceptual Image Patch Similarity and Multi-Scale Adaptive Fusion Attention. Sensors 2024, 24, 7425. [Google Scholar] [CrossRef]
- Shaojie, G.; Xiaogang, W.; Jiayi, Z.; Zewei, L. A Fast Specular Highlight Removal Method for Smooth Liquor Bottle Surface Combined with U2-Net and LaMa Model. Sensors 2024, 22, 9834. [Google Scholar]
- Bingnan, Y.; Zhaozhao, Y.; Huizhu, S.; Conghui, W. ADE-CycleGAN: A Detail Enhanced Image Dehazing CycleGAN Network. Sensors 2023, 23, 3294. [Google Scholar] [CrossRef]
- Zhao, B.; Othmane, A.; Jonguk, L.; Daihee, P.; Yongwha, C. GAN-Based Video Denoising with Attention Mechanism for Field-Applicable Pig Detection System. Sensors 2022, 22, 3917. [Google Scholar] [CrossRef] [PubMed]
- Zhu, S.; Urtasun, R.; Fidler, S.; Lin, D.; Change Loy, C. Be your own prada: Fashion synthesis with structural coherence. In Proceedings of the IEEE International Conference On Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1680–1688. [Google Scholar]
- Ghasemi, P.; Yuan, C.; Marion, T.; Moghaddam, M. DCG-GAN: Design concept generation with generative adversarial networks. Des. Sci. 2024, 10, e14. [Google Scholar] [CrossRef]
- Cao, S.; Chai, W.; Hao, S.; Wang, G. Image reference-guided fashion design with structure-aware transfer by diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 3524–3528. [Google Scholar]
- De Souza, V.L.T.; Marques, B.A.D.; Batagelo, H.C.; Gois, J.P. A review on generative adversarial networks for image generation. Comput. Graph. 2023, 114, 13–25. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montréal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4217–4228. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2223–2232. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul, S.S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 10684–10695. [Google Scholar]
- Xu, Y.; Zhao, Y.; Xiao, Z.; Hou, T. Ufogen: You forward once large scale text-to-image generation via diffusion gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 8196–8206. [Google Scholar]
- Sauer, A.; Schwarz, K.; Geiger, A. Stylegan-xl: Scaling stylegan to large diverse datasets. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 8–11 August 2022; pp. 1–10. [Google Scholar]
- Kang, M.; Zhu, J.Y.; Zhang, R.; Park, J.; Shechtman, E.; Paris, S.; Park, T. Scaling up gans for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10124–10134. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Esser, P.; Kulal, S.; Blattmann, A.; Entezari, R.; Müller, J.; Saini, H.; Rombach, R. Scaling rectified flow transformers for high-resolution image synthesis. arXiv 2024, arXiv:2403.03206. [Google Scholar]
- Cui, Y.R.; Liu, Q.; Gao, C.Y.; Su, Z. FashionGAN: Display your fashion design using conditional generative adversarial nets. Comput. Graph. Forum 2018, 37, 109–119. [Google Scholar] [CrossRef]
- Lee, J.; Lee, M.; Kim, Y. MT-VTON: Multilevel transformation-based virtual try-on for enhancing realism of clothing. Appl. Sci. 2023, 13, 11724. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sutskever, I. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Gu, X.; Huang, J.; Wong, Y.; Yu, J.; Fan, J.; Peng, P.; Kankanhalli, M.S. PAINT: Photo-realistic fashion design synthesis. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 20, 1–23. [Google Scholar] [CrossRef]
- Liang, X.; Mo, H.; Gao, C. Controllable Garment Image Synthesis Integrated with Frequency Domain Features. Comput. Graph. Forum 2023, 42, e14938. [Google Scholar] [CrossRef]
- Chu, T.; Chen, J.; Sun, J.; Lian, S.; Wang, Z.; Zuo, Z.; Lu, D. Rethinking fast fourier convolution in image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Vancouver Convention Center, Vancouver, BC, Canada, 18–22 June 2023; pp. 23195–23205. [Google Scholar]
- Zhou, H.; Dong, W.; Liu, Y.; Chen, J. Breaking through the haze: An advanced non-homogeneous dehazing method based on fast fourier convolution and convnext. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Vancouver Convention Center, Vancouver, BC, Canada, 18–22 June 2023; pp. 1895–1904. [Google Scholar]
- Quattrini, F.; Pippi, V.; Cascianelli, S.; Cucchiara, R. Volumetric fast fourier convolution for detecting ink on the carbonized herculaneum papyri. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2006 October 2023; pp. 1726–1734. [Google Scholar]
- Dong, Q.; Cao, C.; Fu, Y. Incremental transformer structure enhanced image inpainting with masking positional encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11358–11368. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Roman, S.; Logacheva, E.; Anton, M.; Anastasia, R.; Arsenii, A.; Aleksei, S.; Naejin, K.; Harshith, G.; Kiwoong, P.; Victor, L. Resolution-Robust Large Mask Inpainting With Fourier Convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2149–2159. [Google Scholar]
- Nussbaumer, H.J. The Fast Fourier Transform. In Fast Fourier Transform and Convolution Algorithms; Nussbaumer, H.J., Ed.; Springer Series in Information Sciences; Springer: Berlin/Heidelberg, Germany, 1982; Volume 2. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Simonyan, K. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Lei, H.; Chen, S.; Wang, M.; He, X.; Jia, W.; Li, S. A New Algorithm for Sketch-Based Fashion Image Retrieval Based on Cross-Domain Transformation. Wirel. Commun. Mob. Comput. 2021, 5577735. [Google Scholar] [CrossRef]
- Choi, S.; Park, S.; Lee, M.; Choo, J. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 14131–14140. [Google Scholar]
- Rostamzadeh, N.; Hosseini, S.; Boquet, T.; Stokowiec, W.; Zhang, Y.; Jauvin, C.; Pal, C. Fashion-gen: The generative fashion dataset and challenge. arXiv 2018, arXiv:1806.08317. [Google Scholar]
- Soria, X.; Sappa, A.; Humanante, P.; Akbarinia, A. Dense extreme inception network for edge detection. Pattern Recognit. 2023, 139, 109461. [Google Scholar] [CrossRef]
- Yilun, C.; Zhicheng, W.; Yuxiang, P.; Zhiqiang, Z.; Gang, Y.; Jian, S. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6629–6640. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Chaofeng, C.; Jiadi, M.; Jingwen, H.; Haoning, W.; Liang, L.; Wenxiu, S.; Qiong, Y.; Weisi, L. TOPIQ: A Top-Down Approach From Semantics to Distortions for Image Quality Assessment. IEEE Trans. Image Process. 2024, 33, 2404–2418. [Google Scholar]
- Cao, C.; Fu, Y. Learning a sketch tensor space for image inpainting of man-made scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), On-line form, 11–17 October 2021; pp. 14509–14518. [Google Scholar]
- AlBahar, B.; Huang, J.B. Guided image-to-image translation with bi-directional feature transformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9016–9025. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Texture Patch Size | Method | FID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | TOPIQ-FR↑ | TOPIQ-NR↑ |
|---|---|---|---|---|---|---|---|
| Standard | PAINT [56] | 9.03 | 22.46 | 0.10410 | 0.803 | 0.549 | 0.610 |
| MST [79] | 5.93 | 24.21 | 0.06438 | 0.833 | 0.693 | 0.646 | |
| Albahar-MT [80] | 9.38 | 24.22 | 0.10733 | 0.839 | 0.521 | 0.545 | |
| EdgeConnect [81] | 5.55 | 24.67 | 0.06632 | 0.842 | 0.694 | 0.650 | |
| ZITS [61] | 5.30 | 24.78 | 0.06426 | 0.854 | 0.689 | 0.625 | |
| FCAN (Our) | 4.07 | 24.82 | 0.05556 | 0.848 | 0.732 | 0.646 | |
| Medium | PAINT [56] | 10.25 | 22.23 | 0.10131 | 0.797 | 0.514 | 0.599 |
| MST [79] | 6.57 | 23.70 | 0.07012 | 0.821 | 0.615 | 0.645 | |
| Albahar-MT [80] | 12.31 | 23.15 | 0.12341 | 0.821 | 0.504 | 0.519 | |
| EdgeConnect [81] | 6.44 | 24.22 | 0.07434 | 0.831 | 0.668 | 0.640 | |
| ZITS [61] | 6.11 | 24.24 | 0.07195 | 0.840 | 0.670 | 0.618 | |
| FCAN (Our) | 4.74 | 24.36 | 0.06182 | 0.833 | 0.714 | 0.642 | |
| Small | PAINT [56] | 14.33 | 21.97 | 0.15231 | 0.788 | 0.442 | 0.545 |
| MST [79] | 8.80 | 22.17 | 0.08973 | 0.798 | 0.597 | 0.628 | |
| Albahar-MT [80] | 14.65 | 22.52 | 0.14950 | 0.811 | 0.431 | 0.534 | |
| EdgeConnect [81] | 7.47 | 23.59 | 0.08842 | 0.814 | 0.601 | 0.647 | |
| ZITS [61] | 6.89 | 23.73 | 0.07922 | 0.830 | 0.651 | 0.614 | |
| FCAN (Our) | 5.53 | 23.95 | 0.06906 | 0.821 | 0.693 | 0.638 |
| Texture Patch Size | FID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | TOPIQ-FR↑ | TOPIQ-NR↑ | |
|---|---|---|---|---|---|---|---|
| Standard | PAINT [56] | 16.93 | 25.15 | 0.08113 | 0.864 | 0.623 | 0.667 |
| MST [79] | 10.99 | 28.24 | 0.04570 | 0.893 | 0.749 | 0.671 | |
| Albahar-MT [80] | 15.99 | 26.48 | 0.07617 | 0.870 | 0.570 | 0.635 | |
| EdgeConnect [81] | 11.51 | 28.03 | 0.04795 | 0.892 | 0.739 | 0.672 | |
| ZITS [61] | 10.36 | 27.58 | 0.04703 | 0.899 | 0.919 | 0.671 | |
| FCAN (Our) | 9.38 | 28.64 | 0.03886 | 0.907 | 0.917 | 0.681 | |
| Medium | PAINT [56] | 20.19 | 23.81 | 0.09090 | 0.830 | 0.587 | 0.665 |
| MST [79] | 14.17 | 26.01 | 0.06412 | 0.844 | 0.721 | 0.663 | |
| Albahar-MT [80] | 18.48 | 24.28 | 0.10190 | 0.842 | 0.515 | 0.619 | |
| EdgeConnect [81] | 14.45 | 25.83 | 0.05732 | 0.870 | 0.678 | 0.667 | |
| ZITS [61] | 12.27 | 26.77 | 0.05401 | 0.886 | 0.901 | 0.664 | |
| FCAN (Our) | 11.19 | 27.94 | 0.04549 | 0.893 | 0.914 | 0.671 | |
| Small | PAINT [56] | 30.28 | 22.98 | 0.10920 | 0.806 | 0.502 | 0.643 |
| MST [79] | 28.00 | 20.55 | 0.13210 | 0.782 | 0.459 | 0.630 | |
| Albahar-MT [80] | 41.62 | 22.93 | 0.13670 | 0.809 | 0.447 | 0.595 | |
| EdgeConnect [81] | 38.62 | 17.80 | 0.13970 | 0.778 | 0.455 | 0.628 | |
| ZITS [61] | 15.41 | 25.76 | 0.06361 | 0.865 | 0.897 | 0.658 | |
| FCAN (Our) | 14.32 | 26.92 | 0.05478 | 0.877 | 0.901 | 0.662 |
| Texture Patch Size | FID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | TOPIQ-FR↑ | TOPIQ-NR↑ | |
|---|---|---|---|---|---|---|---|
| Standard | PAINT [56] | 23.10 | 29.08 | 0.04544 | 0.942 | 0.655 | 0.493 |
| MST [79] | 13.61 | 33.35 | 0.02118 | 0.962 | 0.789 | 0.529 | |
| Albahar-MT [80] | 22.96 | 30.33 | 0.02118 | 0.962 | 0.652 | 0.492 | |
| EdgeConnect [81] | 13.84 | 33.29 | 0.02244 | 0.962 | 0.778 | 0.531 | |
| ZITS [61] | 13.80 | 32.91 | 0.02143 | 0.963 | 0.784 | 0.527 | |
| FCAN (Our) | 12.73 | 33.41 | 0.02040 | 0.962 | 0.794 | 0.528 | |
| Medium | PAINT [56] | 27.73 | 27.50 | 0.05539 | 0.927 | 0.594 | 0.491 |
| MST [79] | 16.78 | 32.07 | 0.02597 | 0.953 | 0.744 | 0.526 | |
| Albahar-MT [80] | 32.70 | 28.44 | 0.05120 | 0.931 | 0.573 | 0.484 | |
| EdgeConnect [81] | 18.50 | 30.77 | 0.03073 | 0.948 | 0.697 | 0.524 | |
| ZITS [61] | 17.93 | 31.81 | 0.02639 | 0.954 | 0.743 | 0.524 | |
| FCAN (Our) | 16.53 | 32.05 | 0.02630 | 0.954 | 0.742 | 0.525 | |
| Small | PAINT [56] | 37.28 | 24.98 | 0.07366 | 0.907 | 0.526 | 0.466 |
| MST [79] | 27.63 | 27.05 | 0.07061 | 0.923 | 0.535 | 0.478 | |
| Albahar-MT [80] | 45.37 | 26.60 | 0.06243 | 0.916 | 0.500 | 0.485 | |
| EdgeConnect [81] | 35.38 | 26.40 | 0.05133 | 0.924 | 0.551 | 0.503 | |
| ZITS [61] | 21.92 | 30.71 | 0.03310 | 0.940 | 0.706 | 0.523 | |
| FCAN (Our) | 20.68 | 30.75 | 0.03302 | 0.943 | 0.710 | 0.528 |
| Methods | Parameters |
|---|---|
| PAINT [56] | 83.56 M ⇑ 202% |
| MST [79] | 54.93 M ⇑ 98.5% |
| Albahar-MT [80] | 57.29 M ⇑ 107.0% |
| EdgeConnect [81] | 53.59 M ⇑ 93.7% |
| ZITS [61] | 56.59 M ⇑ 104.5% |
| FCAN (Our) | 27.67 M |
| Texture Patch Size | FID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | TOPIQ-FR↑ | TOPIQ-NR↑ | |
|---|---|---|---|---|---|---|---|
| Standard | w/o Dual residual | 4.53 | 24.79 | 0.05639 | 0.852 | 0.726 | 0.642 |
| w/o ACAM | 5.22 | 25.03 | 0.06739 | 0.844 | 0.698 | 0.616 | |
| w/o Gating | 4.37 | 24.64 | 0.05821 | 0.838 | 0.723 | 0.642 | |
| ResNet+ACAM | 4.64 | 24.48 | 0.05440 | 0.826 | 0.712 | 0.633 | |
| Skip Connection | 4.89 | 24.96 | 0.06357 | 0.853 | 0.722 | 0.648 | |
| FCAN (Our) | 4.07 | 24.82 | 0.05556 | 0.848 | 0.732 | 0.646 | |
| Medium | w/o Dual residual | 5.16 | 24.28 | 0.06242 | 0.827 | 0.701 | 0.632 |
| w/o ACAM | 6.04 | 24.22 | 0.07446 | 0.828 | 0.671 | 0.612 | |
| w/o Gating | 5.31 | 23.84 | 0.06412 | 0.818 | 0.711 | 0.636 | |
| ResNet+ACAM | 5.35 | 24.08 | 0.06672 | 0.817 | 0.694 | 0.632 | |
| Skip Connection | 5.71 | 24.55 | 0.07246 | 0.840 | 0.704 | 0.642 | |
| FCAN (Our) | 4.74 | 24.36 | 0.06182 | 0.833 | 0.714 | 0.642 | |
| Small | w/o Dual residual | 5.85 | 23.80 | 0.06914 | 0.824 | 0.683 | 0.635 |
| w/o ACAM | 7.77 | 22.53 | 0.08909 | 0.821 | 0.653 | 0.618 | |
| w/o Gating | 6.41 | 23.35 | 0.07371 | 0.811 | 0.683 | 0.635 | |
| ResNet+ACAM | 6.14 | 23.69 | 0.07238 | 0.814 | 0.675 | 0.640 | |
| Skip Connection | 7.15 | 23.52 | 0.08672 | 0.827 | 0.673 | 0.628 | |
| FCAN (Our) | 5.53 | 23.95 | 0.06906 | 0.821 | 0.693 | 0.638 |
| Texture Patch Size | FID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | TOPIQ-FR↑ | TOPIQ-NR↑ | |
|---|---|---|---|---|---|---|---|
| Standard | w/o Dual residual | 10.07 | 28.66 | 0.04531 | 0.898 | 0.910 | 0.680 |
| w/o ACAM | 11.48 | 27.84 | 0.04917 | 0.895 | 0.889 | 0.650 | |
| w/o Gating | 10.21 | 28.73 | 0.04238 | 0.902 | 0.907 | 0.671 | |
| ResNet+ACAM | 10.27 | 28.65 | 0.04311 | 0.901 | 0.914 | 0.684 | |
| Skip Connection | 10.40 | 28.74 | 0.04201 | 0.905 | 0.911 | 0.674 | |
| FCAN (Our) | 9.38 | 28.64 | 0.03886 | 0.907 | 0.917 | 0.681 | |
| Medium | w/o Dual residual | 11.71 | 27.81 | 0.04737 | 0.892 | 0.900 | 0.663 |
| w/o ACAM | 14.15 | 26.74 | 0.05820 | 0.879 | 0.877 | 0.644 | |
| w/o Gating | 11.86 | 27.84 | 0.04836 | 0.891 | 0.902 | 0.659 | |
| ResNet+ACAM | 12.11 | 27.87 | 0.04821 | 0.884 | 0.910 | 0.672 | |
| Skip Connection | 14.09 | 26.78 | 0.05521 | 0.886 | 0.887 | 0.652 | |
| FCAN (Our) | 11.19 | 27.94 | 0.04549 | 0.893 | 0.914 | 0.671 | |
| Small | w/o Dual residual | 14.82 | 27.01 | 0.05679 | 0.864 | 0.891 | 0.651 |
| w/o ACAM | 28.97 | 22.86 | 0.10223 | 0.830 | 0.834 | 0.613 | |
| w/o Gating | 15.36 | 27.16 | 0.05841 | 0.876 | 0.889 | 0.649 | |
| ResNet+ACAM | 14.76 | 27.58 | 0.05431 | 0.883 | 0.904 | 0.659 | |
| Skip Connection | 24.92 | 23.26 | 0.09333 | 0.848 | 0.840 | 0.602 | |
| FCAN (Our) | 14.32 | 26.92 | 0.05478 | 0.877 | 0.901 | 0.662 |
| Texture Patch Size | FID↓ | PSNR↑ | LPIPS↓ | SSIM↑ | TOPIQ-FR↑ | TOPIQ-NR↑ | |
|---|---|---|---|---|---|---|---|
| Standard | w/o Dual residual | 13.37 | 33.45 | 0.02205 | 0.961 | 0.784 | 0.521 |
| w/o ACAM | 13.75 | 33.49 | 0.02291 | 0.960 | 0.758 | 0.494 | |
| w/o Gating | 13.27 | 33.05 | 0.02154 | 0.960 | 0.790 | 0.526 | |
| ResNet+ACAM | 13.14 | 33.18 | 0.02176 | 0.960 | 0.779 | 0.533 | |
| Skip Connection | 14.16 | 33.83 | 0.02268 | 0.964 | 0.754 | 0.501 | |
| FCAN (Our) | 12.73 | 33.41 | 0.02040 | 0.962 | 0.794 | 0.528 | |
| Medium | w/o Dual residual | 17.00 | 32.89 | 0.02646 | 0.951 | 0.737 | 0.524 |
| w/o ACAM | 17.94 | 31.98 | 0.02849 | 0.952 | 0.712 | 0.501 | |
| w/o Gating | 17.21 | 32.40 | 0.02746 | 0.952 | 0.732 | 0.522 | |
| ResNet+ACAM | 17.42 | 31.34 | 0.02994 | 0.943 | 0.732 | 0.523 | |
| Skip Connection | 19.00 | 32.02 | 0.02947 | 0.953 | 0.722 | 0.514 | |
| FCAN (Our) | 16.53 | 32.05 | 0.02630 | 0.954 | 0.742 | 0.525 | |
| Small | w/o Dual residual | 21.12 | 30.80 | 0.03362 | 0.942 | 0.706 | 0.524 |
| w/o ACAM | 22.75 | 29.42 | 0.03960 | 0.932 | 0.694 | 0.516 | |
| w/o Gating | 21.48 | 30.50 | 0.03462 | 0.932 | 0.701 | 0.521 | |
| ResNet+ACAM | 21.04 | 30.27 | 0.03580 | 0.930 | 0.711 | 0.520 | |
| Skip Connection | 24.36 | 29.89 | 0.03829 | 0.941 | 0.700 | 0.517 | |
| FCAN (Our) | 20.68 | 30.75 | 0.03302 | 0.943 | 0.710 | 0.528 |
| Methods | Parameters |
|---|---|
| w/o Dual residual | 23.41 M ⇓ 15.4% |
| w/o ACAM | 23.60 M ⇓ 14.7% |
| w/o Gating | 22.83 M ⇓ 17.5% |
| ResNet+ACAM | 35.78 ⇑ 29.3% |
| Skip Connection | 23.60 M ⇓ 14.7% |
| FCAN | 27.67 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, H.; Hu, Y.; Wang, M.; Ding, M.; Li, Z.; Luo, G. Fast Fourier Asymmetric Context Aggregation Network: A Controllable Photo-Realistic Clothing Image Synthesis Method Using Asymmetric Context Aggregation Mechanism. Appl. Sci. 2025, 15, 3534. https://doi.org/10.3390/app15073534
Lei H, Hu Y, Wang M, Ding M, Li Z, Luo G. Fast Fourier Asymmetric Context Aggregation Network: A Controllable Photo-Realistic Clothing Image Synthesis Method Using Asymmetric Context Aggregation Mechanism. Applied Sciences. 2025; 15(7):3534. https://doi.org/10.3390/app15073534
Chicago/Turabian StyleLei, Haopeng, Ying Hu, Mingwen Wang, Meihai Ding, Zhen Li, and Guoliang Luo. 2025. "Fast Fourier Asymmetric Context Aggregation Network: A Controllable Photo-Realistic Clothing Image Synthesis Method Using Asymmetric Context Aggregation Mechanism" Applied Sciences 15, no. 7: 3534. https://doi.org/10.3390/app15073534
APA StyleLei, H., Hu, Y., Wang, M., Ding, M., Li, Z., & Luo, G. (2025). Fast Fourier Asymmetric Context Aggregation Network: A Controllable Photo-Realistic Clothing Image Synthesis Method Using Asymmetric Context Aggregation Mechanism. Applied Sciences, 15(7), 3534. https://doi.org/10.3390/app15073534