1. Introduction
As important industrial equipment, storage tanks are widely used in the petrochemical, chemical, energy, and other fields [
1]. According to a survey, in 2021, Huizhou, Qingdao, Shanghai, Zhoushan, Tianjin, Yantai, and other large ports had about 31,000 oil, gas, and chemical storage tanks of various types, with a total tank capacity of more than 300 million cubic meters; 320,000 mobile transport tanks and other various types of transit tanks, raw material tanks, media tanks, inter-plant tanks are numerous [
2]. However, most of the storage tanks store large amounts of dangerous explosive and volatile chemicals, and their operation involves a number of potential risks such as leakage, explosion, and fire, which may pose a serious threat to the industry’s reputation, assets, and the environment, as well as a serious hazard to the safety of personnel and the environment [
3]. Historical data show that leakage accidents are one of the most common accidents in the process industry, accounting for approximately 17.98% of the total number of accidents [
4]. For example, accidents such as the storage tank fire at the ITC tank farm in Houston on 18 March 2019 and the toluene storage tank fire at Sinopec Dalian Petrochemical Company on 2 June 2013 demonstrated the serious consequences and property losses of such accidents. Therefore, conducting effective quantitative analyses of dynamic accident probabilities is crucial for the safe management of storage tanks [
5].
Fault tree analysis (FTA) is a deductive analysis method widely used in probabilistic analysis to qualitatively identify the critical and root causes of unexpected events in system failures and quantitatively assess the likelihood of accidents [
6]. In the traditional FTA approach, the failure probabilities of basic events are exact values. However, because of insufficient data, performing an exact calculation of the BEs’ failure probabilities in quantitative accident probability analyses is difficult to achieve [
7,
8]. In the absence of a precise value for the probability of failure, it is common to approximate the probability and justify using ‘likelihood’ rather than ‘probability’ [
9]. In order to solve this limitation, scholars combine FTA with other technologies. For example, Lin and Wang [
10] combined FST with expert judgment to evaluate the failure probability of BEs in a robotic drilling system. Liang and Wang [
7] proposed a fuzzy fault tree analysis method based on failure possibility. They combined fuzzy set theory with FTA to better deal with the inaccuracy in fault probability assessment.
In view of the dynamic nature of the causes of hazardous chemical tank leakage accidents with temporal correlation, it is difficult to provide reliable results using traditional static probabilistic analysis methods. To cope with the time-series correlation in accident risk analysis, dynamic probabilistic analysis methods have been widely used in risk assessment [
11,
12,
13]. In 2002, Čepin and Mavko [
14] proposed the dynamic fault tree (DFT) method, which is a modified classical FT that takes into account the time dependence of system failure. To address the dynamics of accident probability, Badreddine and Amor [
15] proposed the Bayesian network (BN) method. The method is a probabilistic inference technique for uncertainty reasoning and has been shown to be a practical approach for modeling and probability calculating of dynamic risk with uncertainty [
16].
In view of the lack of risk data, the traditional expert evaluation method relies too much on the subjective evaluation of experts, which has great uncertainty. BN-based models assume that the state of each node (variable) is independent of each other [
17]. Determining conditional probability tables may face difficulties when BN is applied to variables with unknown or nonlinear dependencies. When dealing with noisy or large-scale data, BN may face computational complexity or even incompatibility. Compared to the traditional BN method, Fuzzy DFT can better handle the uncertainty dependencies and fuzzy information present in the system [
18], which makes it more robust in practical applications, especially in the context of storage tank accidents [
19]. Additionally, although Markov Chains (MC) and Monte Carlo simulation perform well in simulating system state transitions, they require significant computational resources and are often unable to meet real-time risk assessment needs, particularly when dealing with high-dimensional data [
20,
21].
In contrast, ANNs, with their powerful nonlinear modeling capabilities, can effectively capture complex system behaviors and long-range dependencies, thus demonstrating higher accuracy in risk assessment tasks [
22,
23,
24]. Compared to BN, neural networks do not need to assume that the variables are independent of each other when building the model. The neural network model has a data-driven feature that enables it to deal with unknown nonlinear dependencies more easily. In addition, neural networks can learn and optimize the model automatically and perform particularly well when dealing with large-scale or imprecise data, leading to reliable results. Currently, other subject areas have begun to apply neural networks for accident risk research. For example, Qiao et al. [
25] developed a comprehensive accident analysis model that organically integrated the Human Factors Analysis and Classification System (HFACS) and ANN to accurately quantify the failure probabilities caused by human factors in maritime accidents, providing a new perspective and method for maritime accident risk assessment. Sarbayev et al. [
17] innovatively adopted the technical approach of mapping fault tree (FT) to ANN and successfully applied it to the probability analysis of process systems. This method effectively overcame the shortcomings of traditional fault trees in dealing with system complexity and complex calculation processes, significantly improving the accuracy and efficiency of probability analysis for process systems. Lin et al. [
26] proposed a probability analysis method for mining systems based on FST and machine learning, skillfully solving the key problem of data uncertainty in probabilistic risk analysis and providing more reliable technical support for risk assessment in the mining industry. However, the current research status of dynamic probability analysis still has certain limitations. Most research methods often only focus on local factors and fail to comprehensively consider and properly address all aspects involved in accident probability analysis from a global perspective. Especially in the important field of probability analysis of storage tank leakage accidents, research on probability analysis using neural networks is relatively scarce.
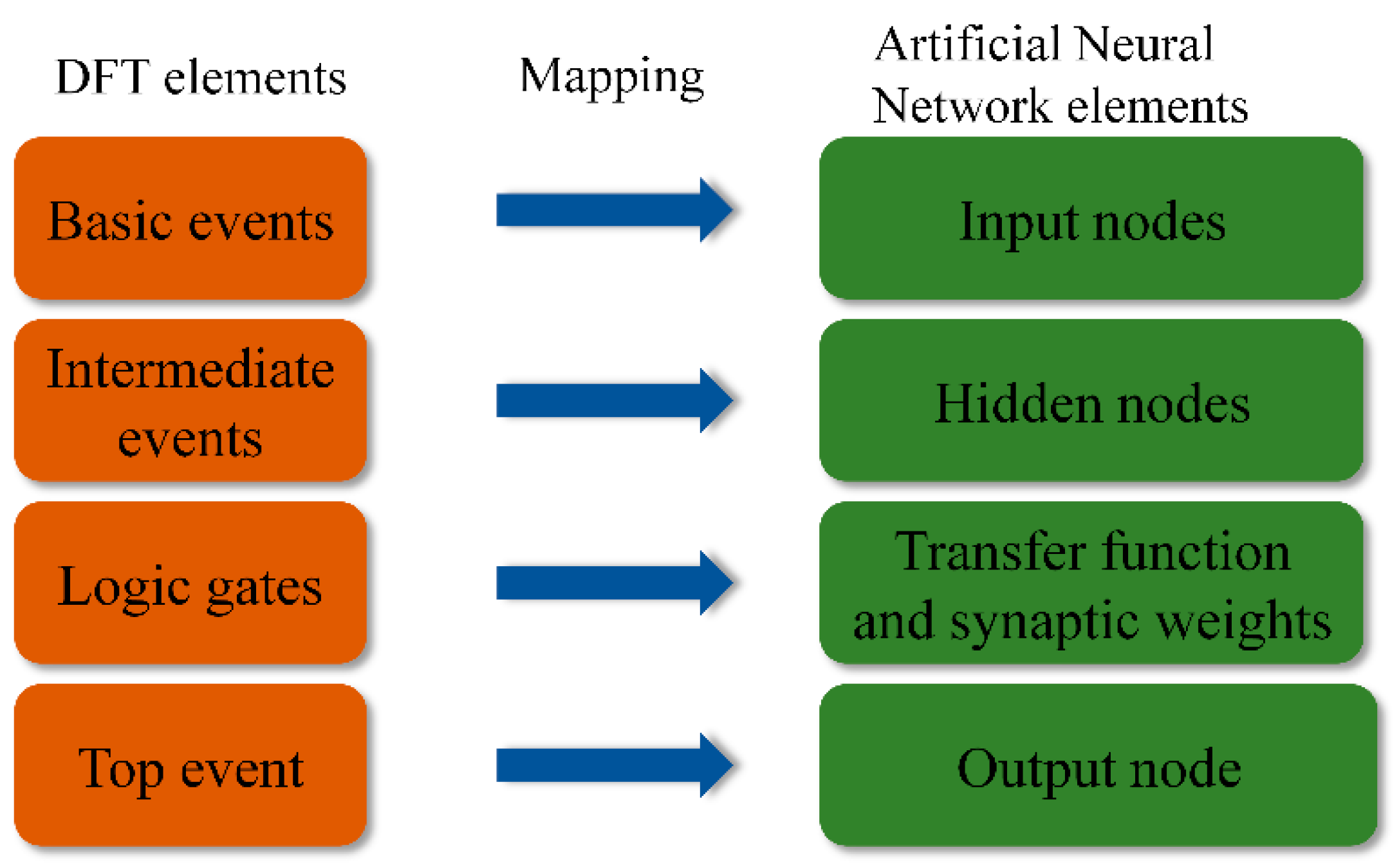
This study proposes a probability analysis method for accident risk based on Fuzzy DFT and neural network technologies. Unlike traditional methods, which often face the issue of data scarcity, the proposed method calculates the failure probabilities of BEs using FST and introduces the Bootstrap algorithm to augment risk data, creating a more comprehensive dataset for probabilistic risk analysis. This not only alleviates the problem of insufficient data in the quantitative analysis of storage tank accidents but also reduces reliance on experts’ subjective judgments through a data-driven approach. In terms of accident scenario analysis, traditional FT methods may overlook the dynamic nature of accident development. However, the method proposed in this paper utilizes DFT to comprehensively capture these dynamic features, enabling a more accurate reflection of risk state changes. In terms of model construction, the ANN model for storage tank risk analysis, based on the structure and principles of Fuzzy DFT, can better account for dependencies between events compared to traditional models, thereby simplifying the calculation process and significantly improving computational efficiency and accuracy. Additionally, the development of an LSTM model for tank accidents is another key advantage. Unlike traditional static models, this LSTM model can quickly predict the dynamic changes in the failure probability of the top event (TE) over time, providing a real-time analytical tool for storage tank safety management.
In terms of implementation, the method uses widely available software tools. Data processing and model construction are primarily carried out in the Python 3.7 programming environment. Libraries such as pandas and numpy are used for data processing, scikit-learn for data preprocessing, including normalization and data splitting, while deep learning frameworks like PyTorch 1.13 or Keras 2.11 are employed to construct and train the ANN and LSTM models. These tools have user-friendly interfaces and powerful functionalities, ensuring the smooth implementation of the proposed method and making it easy to use and apply in practical scenarios. Overall, this new method represents a significant advancement in storage tank accident probability analysis, providing the industry with a more reliable and efficient solution.
In this study,
Section 2 systematically introduces the method for constructing a quantitative probability calculation model based on Fuzzy DFT and neural networks, including the construction of the DFT, fuzzy calculation of failure probabilities for storage tank accident factors, data acquisition preprocessing, and the development of a hazardous chemical storage tank leakage accident model based on neural networks.
Section 3 conducts a case analysis using a storage tank leakage accident as an example, covering the introduction of the accident case, specific application of the proposed method, including the construction of the dynamic fault tree for the tank leakage accident, determination of fuzzy failure probabilities for basic events, risk data augmentation, hyperparameter tuning, and data processing and parameter setting for the ANN and LSTM models.
Section 4 presents a discussion of the results, which not only verifies the proposed quantitative probability calculation method based on Fuzzy DFT and neural networks for storage tanks but also provides an in-depth analysis of the impact of different parameters on the performance of the ANN model, model performance evaluation based on data updates, independence of basic events, input variable sensitivity, and the temporal development of the failure probability of hazardous chemical storage tank leakage accidents.
Section 5 summarizes the research conclusions and synthesizes the overall work.
4. Results and Discussion
4.1. Validating the Quantitative Calculation Method for Storage Tank Probability Based on Fuzzy DFT and Neural Network
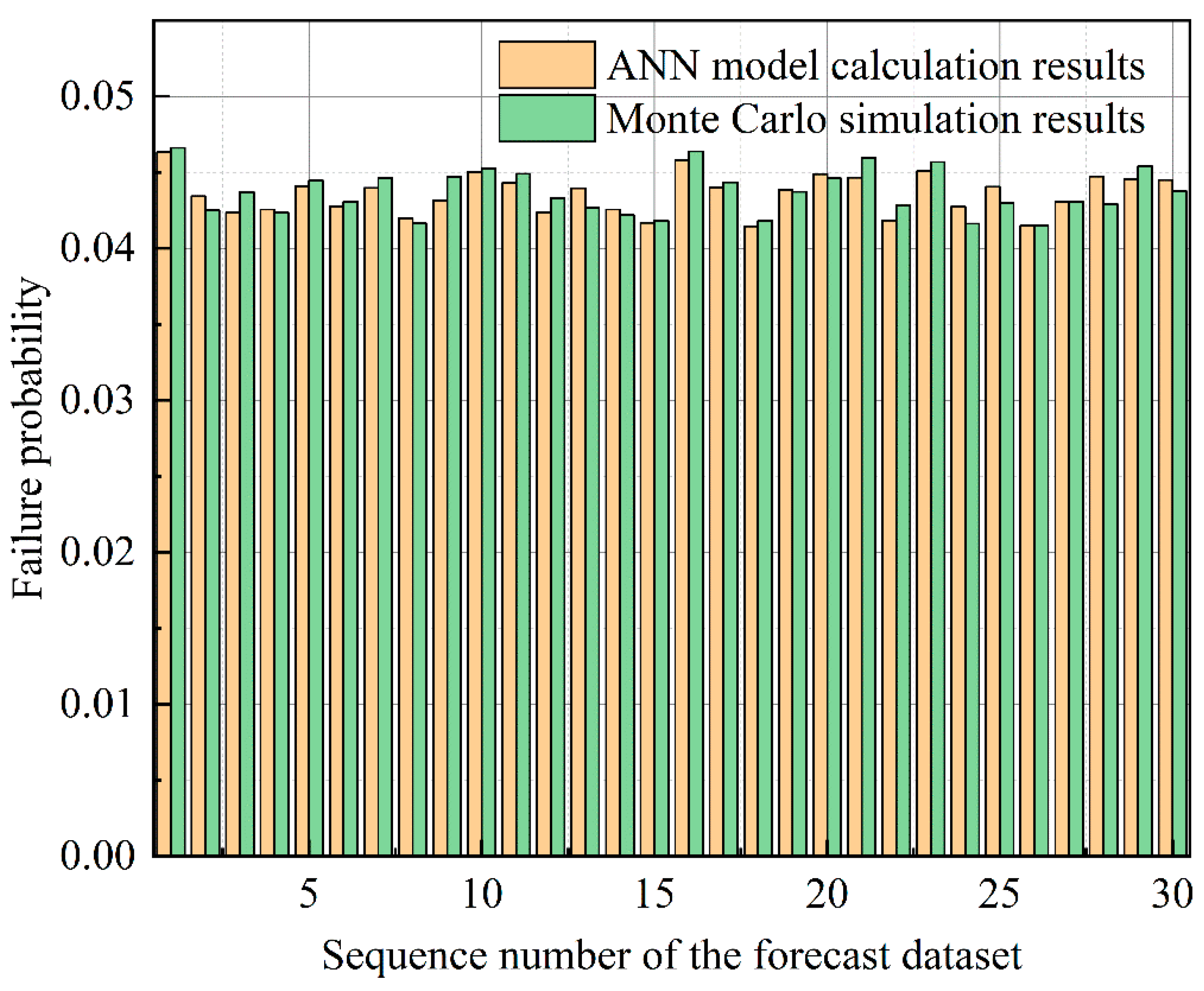
In order to validate the feasibility of the developed ANN model, a series of model tests were conducted on the trained ANN model using 30 sets of BEs failure rate data from different scenarios as a test dataset, aiming to simulate the computational process of DFT. The results of the proposed method in this paper were compared with those of the traditional Monte Carlo simulation method, and the results are shown in
Figure 7. The green curve in the figure represents the failure probability of the top DFT events obtained from the Monte Carlo simulation, while the orange curve represents the prediction results of the constructed ANN model. The prediction results between the two methods exhibit significant consistency, and the results obtained by the proposed method align with the findings of Sarbayev et al. [
17] and Yan et al. [
18]. This provides strong evidence to demonstrate the effectiveness and accuracy of the proposed method. In addition, through an estimation of the computation time, we found that using the ANN model significantly improves computational efficiency when handling large amounts of failure data. For example, in this study, when 1000 sets of data were used for computation, the ANN model completed the calculation in just 2 min, while the Monte Carlo model took approximately 2 h. This demonstrates that the ANN model significantly enhances computational efficiency when processing large-scale data, greatly saving computation time.
In order to assess the performance of the ANN model more comprehensively, the average difference value and the maximum difference value between the predicted results of the two models were calculated. The results show that the average difference value between the results calculated by the two methods is 6.61 × 10−4 and the maximum difference value is 1.82 × 10−3. These small difference values further confirm the high accuracy of the ANN model in predicting the probability of failure of the top event.
4.2. Analysis of the Effect of Different Parameters on the Performance of ANN Models
In order to comprehensively assess the role of different numbers of hidden neurons on the accuracy of model prediction, this study conducted a comprehensive comparative analysis of a series of training datasets of different sizes.
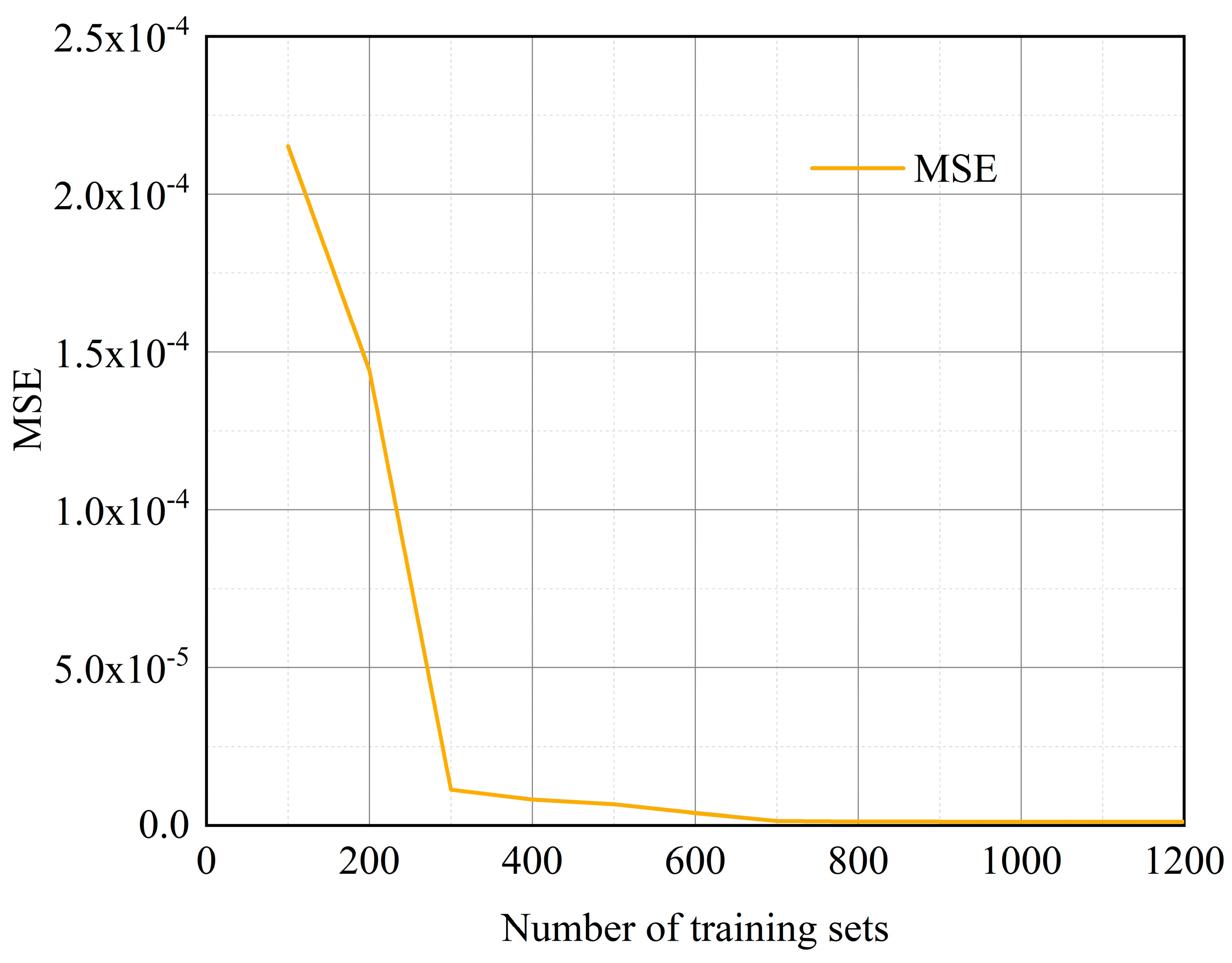
Figure 8 indicates that as the size of the training dataset expands, the failure probability predicted by the ANN model gradually approximates the actual observed value, and the model prediction is more reliable. This phenomenon verifies that sufficient data can increase the ability to improve the generalization of the ANN model.
The increase in dataset size also inevitably leads to an increase in computational resources and time, so the balance between computational cost and model performance needs to be considered in model design. Weighing the model performance and practical requirements, the training dataset containing 800 samples is selected for this study. With this dataset size, the MSE of the test set is reduced to 1.23 × 10−6, a result that not only proves the high accuracy of the model prediction but also shows the reasonableness of the model prediction results.
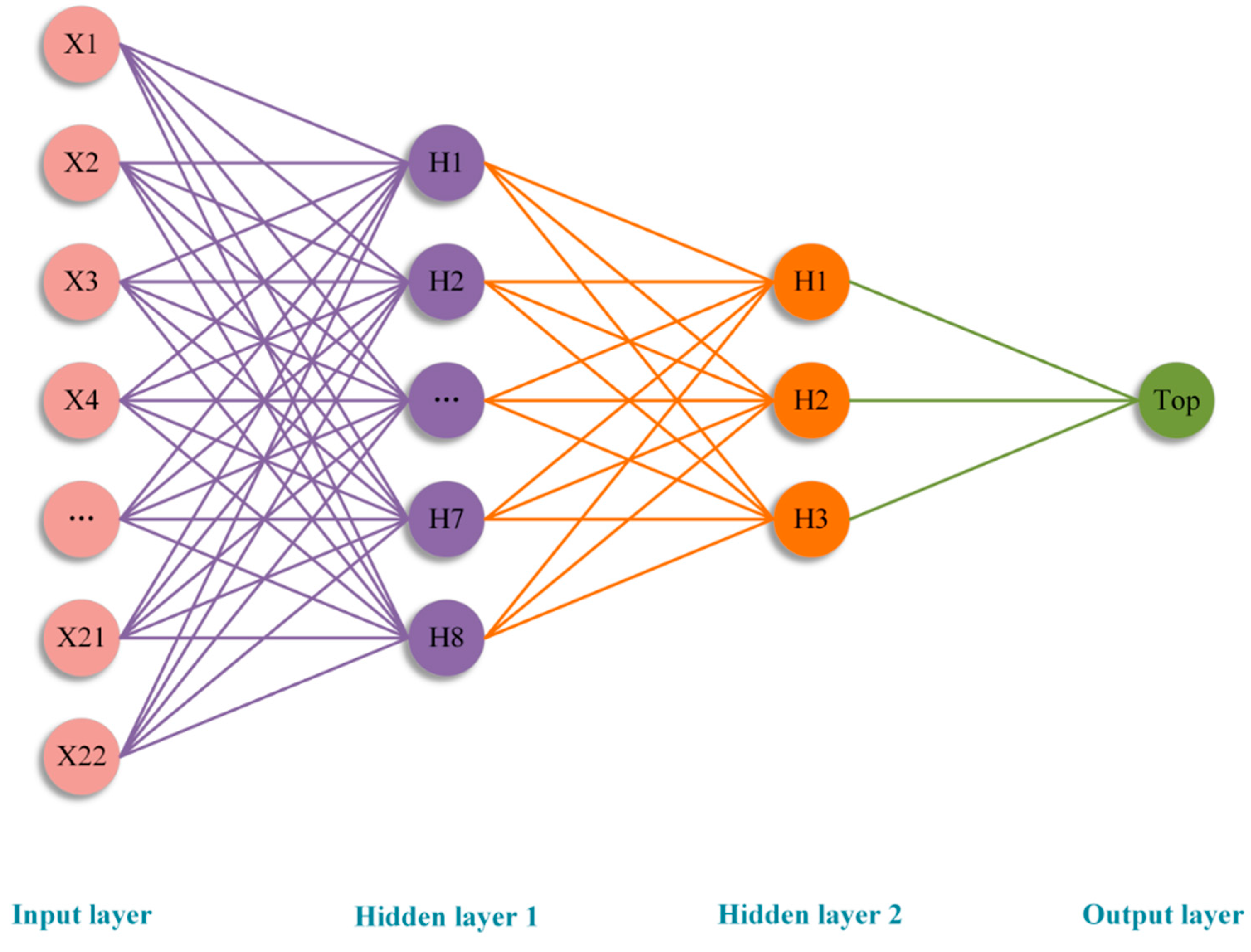
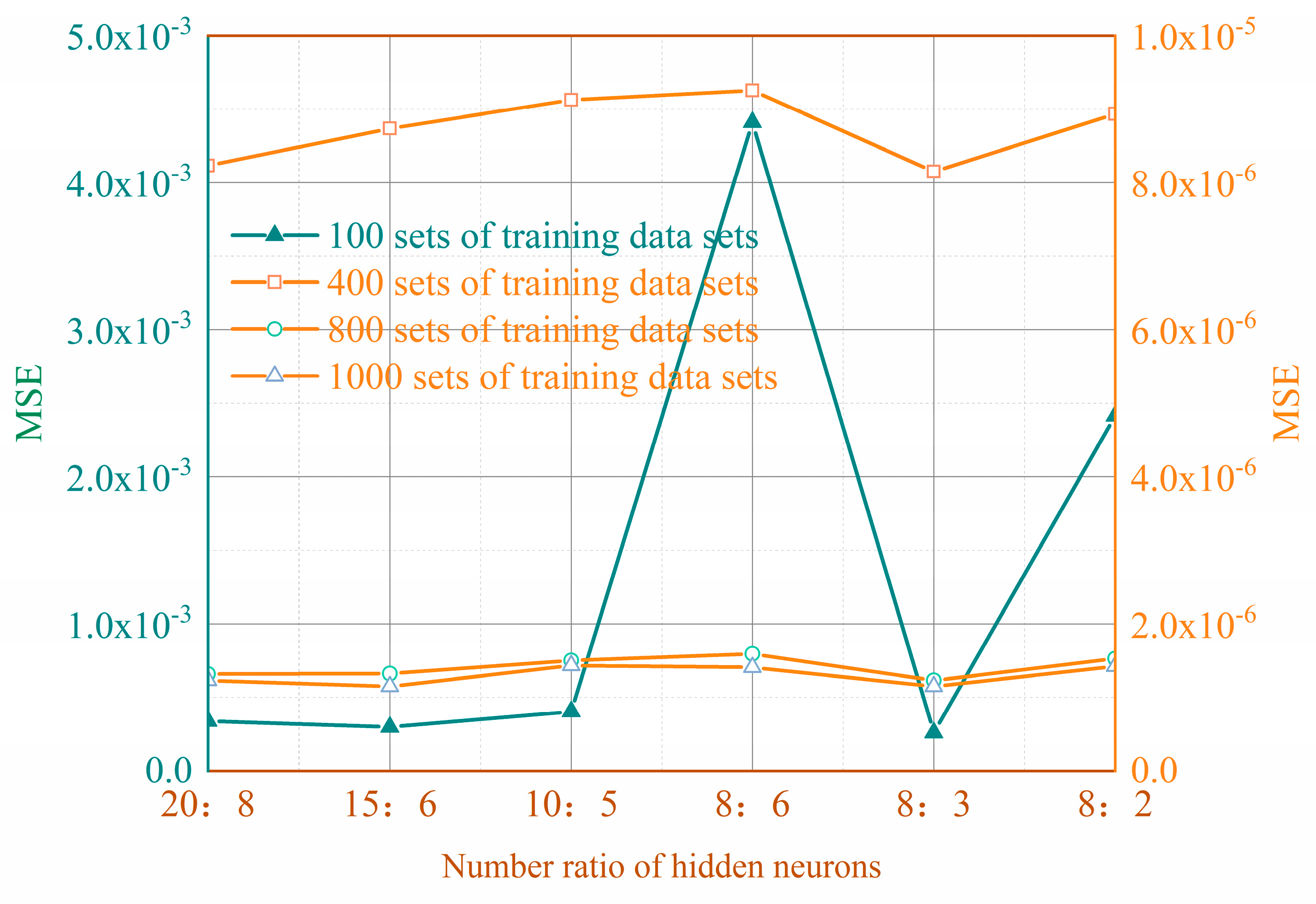
For training datasets of different sizes, choosing the right number of hidden layer neurons is crucial to obtain the best fitting effect. As shown in
Figure 9, by comparing the model performance under different configurations, it is found that the appropriate number of hidden neurons can significantly improve the predictive ability of the model and effectively avoid the overfitting problem. In particular, when the number of first hidden layer neurons is set to 8 and the number of second hidden layer neurons is set to 3, the model exhibits the best fitting effect, which is consistent with the rule of thumb presented in
Section 2.4.1.
4.3. Evaluating the Performance of the Model Based on Data Updates
In practical quantitative analyses of storage tank accident probabilities, the emergence of new data may lead to changes in the structure of the DFT, such as the addition of new BEs. In this case, traditional computational methods face a complex recalculation process. In contrast, the ANN-based method proposed in this paper demonstrates remarkable adaptability and efficiency, which can quickly respond to the structural changes in the DFT and provide fast prediction results.
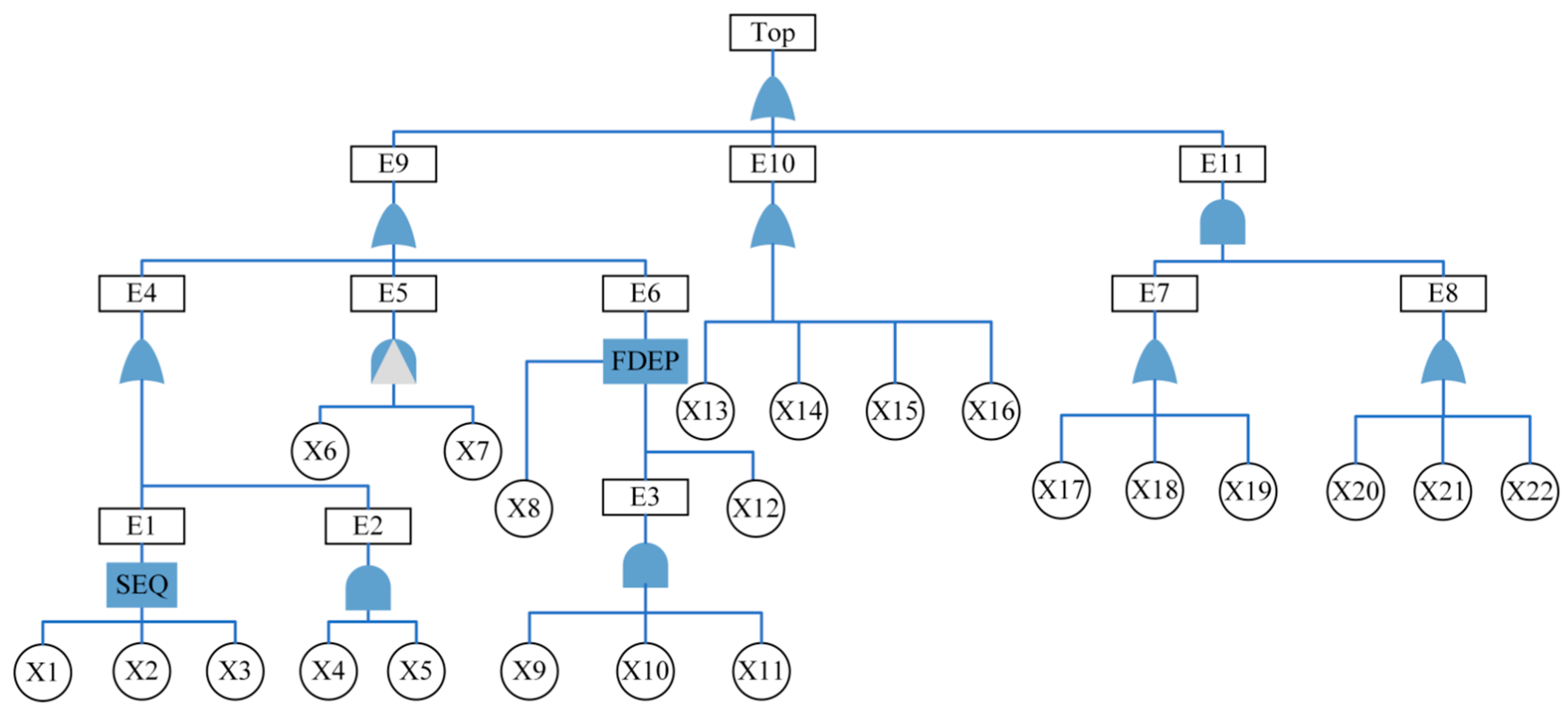
By deeply analyzing the data in
Table 6, the ranking of the 22 BEs in terms of their degree of influence on TE occurrence was obtained, and the results are displayed in
Table 9. Assuming that only 21 events were included in the initial incident analysis (removing the least influential event X13), in this case, the MSE of the prediction set obtained by applying the Fuzzy DFT-ANN model proposed in this paper is 1.96 × 10
−6. However, the MSE of the prediction set is significantly reduced to 1.23 × 10
−6 when the model is extended to include all 22 BEs. The result not only highlights that the new data play a key role in improving the model prediction accuracy, which can enhance the accuracy of the calculation, but it also confirms the high efficiency and adaptability of the proposed ANN model for storage tank accidents in the quantitative calculation of accident probability.
The findings in this section show that ANN models can be optimized continuously to provide more accurate probability predictions as new data are continuously integrated. This data-driven approach to model optimization provides an effective tool for dynamic risk management, especially in scenarios that require rapid response to system changes and timely updating of risk assessment results.
4.4. Analysis of Independence Between BEs
In this section, the effect of independence between basic events on the quantitative analysis of storage tank probability is analyzed, and the prediction results of the constructed ANN model are compared with the TE failure probability derived from the traditional DFT calculation method. The comparison results show that the average error of the failure probability of the top event predicted by the ANN model is 2.14%. Compared with the 3.44% of the traditional DFT method, the performance of the ANN model is improved by 38%. This performance enhancement may be attributed to the unknown dependencies between BEs in DFT, which are often ignored in traditional methods. The advantage of the ANN model is its ability to capture and account for these interdependencies between input variables, thus outperforming the traditional fault tree computation methods in terms of prediction accuracy. Furthermore, this property of ANN models is particularly important when performing probabilistic calculations for complex systems. Since real-world systems often involve multiple interdependent variables, ANN models can model these complex interactions more accurately, providing a more accurate tool for probabilistic failure calculations.
This section analyzes the impact of the independence between basic events on the quantitative probability analysis of storage tanks and compares the predicted results of the constructed artificial neural network (ANN) model with the failure probabilities obtained using the traditional DFT calculation method. The results of the output set of the test dataset, as shown in
Figure 7, are used to calculate the average error of the top event for both models using the following formula and to make a comparison [
17].
where
T is the calculated average error,
is the sum of the top event results for the two models’ test datasets, consisting of 30 datasets, with the denominator being the failure probability of the top event, 0.04255.
By substituting both datasets into the formula and comparing the results, it was found that the average error of the top event failure probability predicted by the ANN model is 2.14%. Compared to 3.44% for the traditional DFT method, the ANN model’s performance improved by 38%. This improvement in performance may be due to the unknown dependencies between basic events in the model design, which are often overlooked in traditional methods. The advantage of the ANN model is that it can capture and explain the interdependencies between input variables, making it superior to traditional fault tree calculation methods in terms of prediction accuracy. Additionally, this characteristic of the ANN model is especially important when performing probabilistic calculations for complex systems. Since real-world systems typically involve multiple interdependent variables, the ANN model can more accurately simulate these complex interactions, providing a more accurate tool for probabilistic failure calculations.
4.5. Sensitivity Analysis of Input Variables
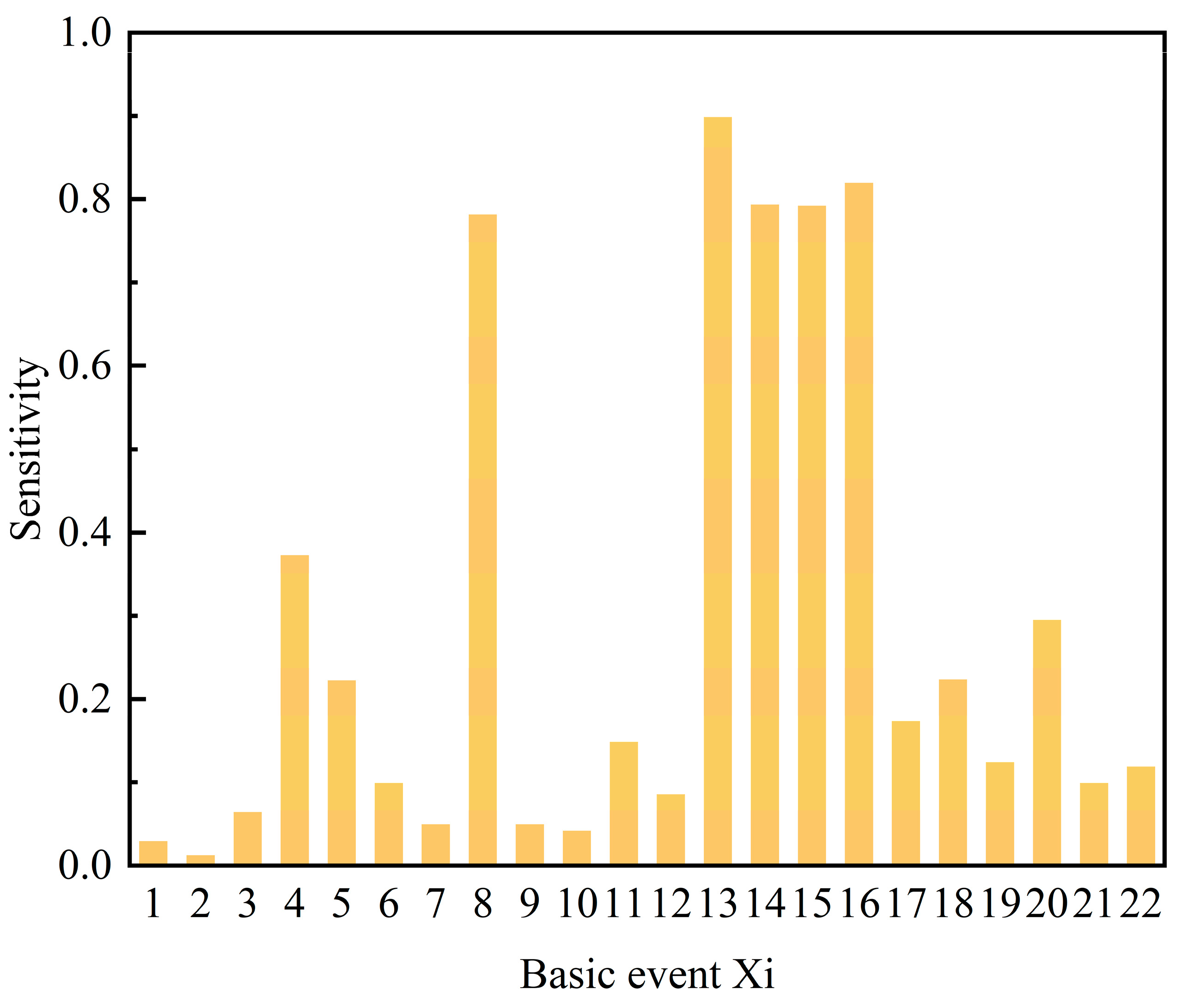
Sensitivity analyses were used to assess the impact of different incident factors on the probability of failure in a leaking vinyl chloride storage tank incident. The extent to which different factors influence system risk is revealed by quantifying how minor changes in input variables can lead to significant changes in output results. In order to perform this analysis, a method based on changes in model input variables is proposed. Using Equation (11), the corresponding degree of change in the output values with minor changes in the model input values is calculated. As shown in
Figure 10, the results of the sensitivity analysis clearly demonstrate the extent to which each factor influences the risk of storage tank leakage.
where
CRITi is the critical importance of input variable
i, i.e., the extent to which input variable
i affects the final output,
P(
TOP) is the probability of system failure, and
P(
i) is the probability of component
i failure.
The results of the sensitivity analysis highlighted the key factors affecting the risk of leakage from vinyl chloride storage tanks, with X4, X8, X13, X14, X15, and X16 identified as having a significant impact on the risk. These findings are essential for the development of targeted safety management measures. In particular, enhanced inspection and maintenance of gas storage tanks, management and maintenance of gas transmission equipment, and consideration of natural conditions were shown to be effective strategies for improving the safety performance of storage tanks.
It is noteworthy that these results are consistent with the risk factors identified in the accident investigation report, thus providing empirical support for the model proposed in this paper and further confirming the validity of the adopted methodology. The sensitivity analysis not only reveals the specific impact of each factor on the risk of storage tank leakage but also provides a scientific basis for risk management and decision-making.
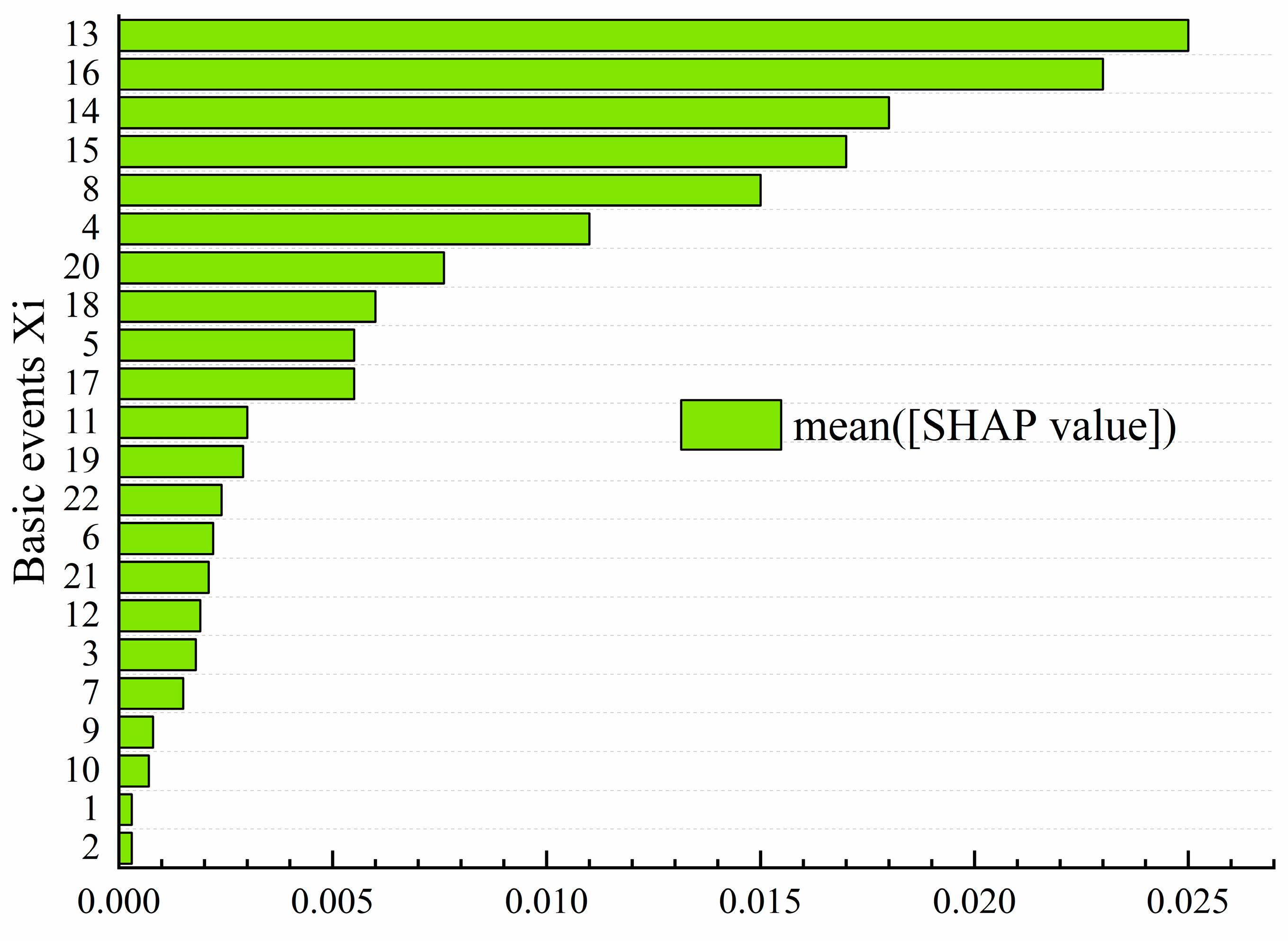
In addition, the study performed SHAP analysis on the model’s inputs to further demonstrate its interpretability. The results are shown in
Figure 11, where the
X-axis represents the average SHAP values corresponding to each basic event, and the
Y-axis lists the different basic event numbers. This bar chart illustrates the contribution of each basic event to the model’s prediction results. From the chart, it can be observed that basic events 13, 16, 14, and 15 have relatively high SHAP values, indicating that these basic events significantly influence the model’s predictions. These basic events may play a crucial role in the occurrence of accidents, and therefore, higher weights were assigned to these features during the model training process. This is consistent with the results of the sensitivity analysis, which shows that these features have a considerable impact on the model’s output, further validating their importance in the prediction process. Based on the results of the SHAP analysis, it is now clearer how the model makes predictions, especially how it relies on these key features. This interpretability enhances our trust in the model’s behavior and provides valuable insights for future optimization and adjustments. For example, features with greater contributions could be further optimized in terms of data preprocessing and feature selection, which would improve the model’s prediction accuracy.
4.6. Analysis of the Time-Efficient Development of the Failure Probability in Hazardous Chemical Storage Tank Leakage Accidents
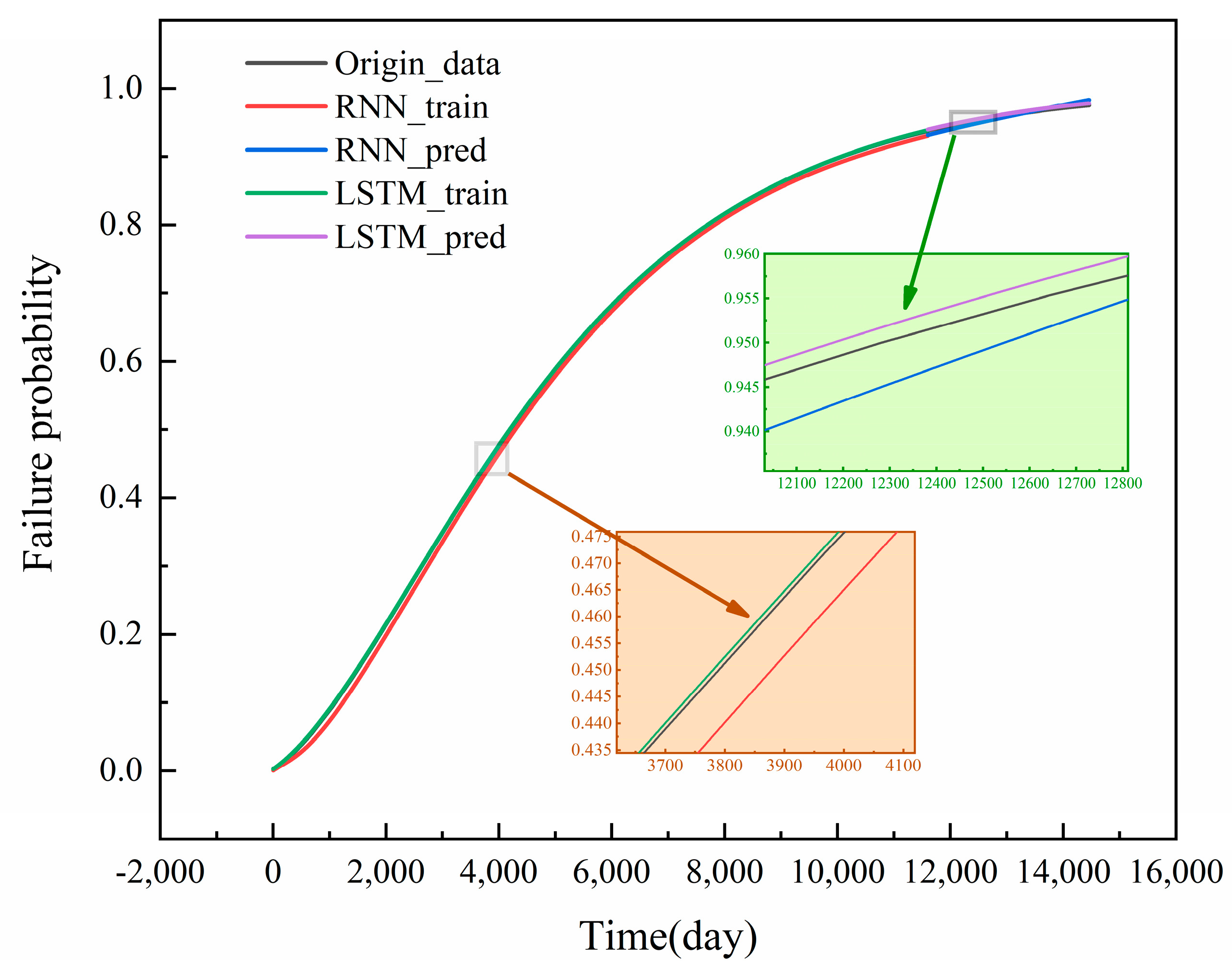
In order to effectively assess the dynamic evolution of the failure probability of hazardous chemical storage tank leakage accidents, an LSTM network model of storage tank DFT is constructed to further model and predict the DFT. When constructing the LSTM model, in the face of the incompleteness of historical data, the equipment degradation model is introduced to estimate the time-series variation of the failure probability of the BEs, and the failure probability of the TE is calculated by the corresponding calculation method of the DFT. To construct the LSTM model dataset, a total of 14,400 datasets are computed and counted, of which 80% is used to construct the training set, and the remaining 20% is used for the test set. In order to verify the applicability and superiority of the proposed model, the corresponding DFT time-series solution model is developed based on the traditional recurrent neural network (RNN) method. The time-series failure probabilities obtained from the Hidden Markov Chain are processed according to the data preprocessing method proposed earlier. The processed time-series dataset is then input into the previously constructed LSTM and RNN models to observe the differences between the output values of the two models and the true values. As shown in
Figure 12, it can be seen that the LSTM model has a better performance in capturing the time-series variation.
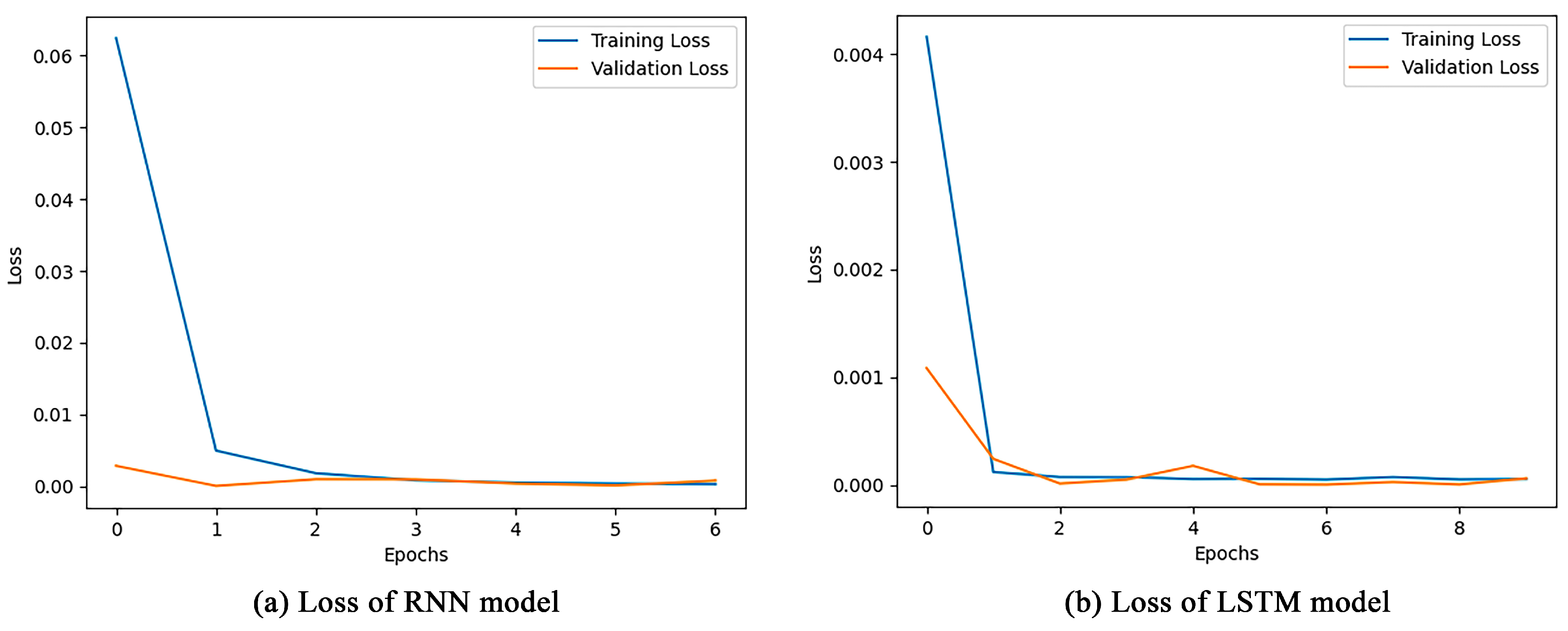
The model training results show that the traditional RNN model has a training loss of 2.1473 × 10
−4, whereas the training loss of the constructed LSTM model for storage tank accidents is only 5.0337 × 10
−5, as shown in
Figure 13. This significant improvement confirms the superiority of the LSTM model in dealing with DFT time-series prediction. The lower training loss achieved by the LSTM model is attributed to its unique gating mechanism, which allows the model to capture the long-term dependencies in the time series more efficiently while avoiding the gradient vanishing or explosion problems that are commonly found in the traditional RNN models. In addition, the LSTM model for storage tank accidents not only performs well during the training process but also shows great accuracy and reliability in predicting the future trend of risk probability evolution and is able to more accurately predict the change in the probability of failure of storage tank leakage accidents. Considering the model training loss, prediction accuracy, and model complexity together, this LSTM model proves its potential as an effective probabilistic analysis tool. It provides a new analytical approach to hazardous chemical storage tank safety management and can play an important role in risk assessment and preventive measure development.




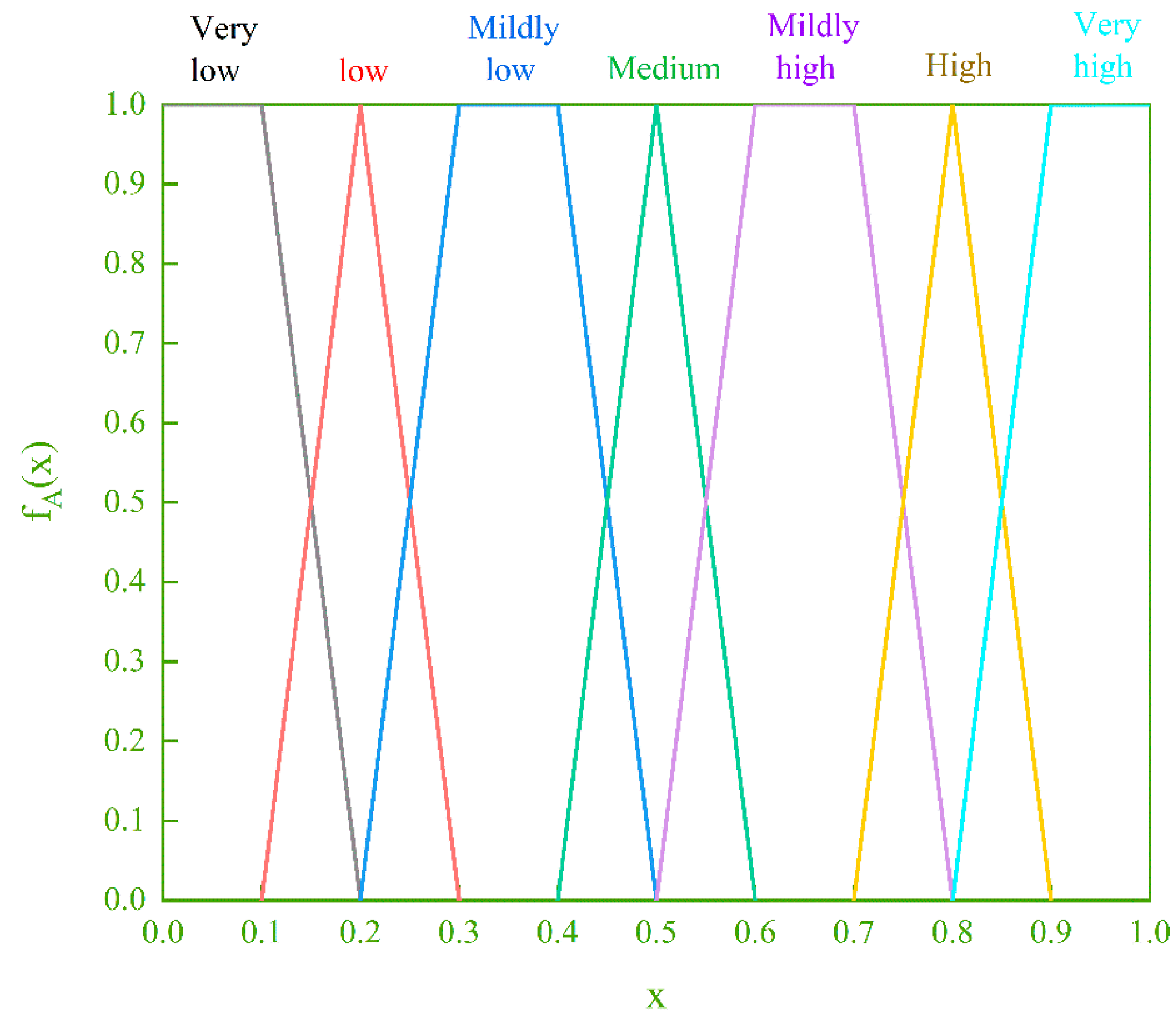


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}