
Heterogeneous Graph Neural Network with Multi-View Contrastive Learning for Cross-Lingual Text Classification


Abstract
1. Introduction
- Theoretical advances: The proposed framework introduces an innovative approach that captures both syntactic and semantic knowledge by constructing a heterogeneous graph, where documents and words are interconnected through multiple edge types. The integration of multi-view contrastive learning facilitates the alignment of cross-lingual features, thereby advancing the theoretical understanding of structured representation learning.
- Practical implications: Accurate classification of text across multiple languages provides significant real-world benefits. Enhanced text analysis enabled by the proposed framework facilitates more effective evaluation of customer feedback, targeted advertising, and refined product recommendation systems. Consequently, these advancements contribute to global market research and public policy development by ensuring that diverse linguistic perspectives are integrated into decision-making processes.
- Empirical performance: Extensive experiments demonstrate that the proposed approach substantially outperforms state-of-the-art methods. Notably, a 2.20% improvement in accuracy on the XGLUE dataset confirms the effectiveness of the framework in facilitating knowledge transfer from high-resource to low-resource languages.
2. Related Work
2.1. Linear Transformation Methods
2.2. Pre-Trained Methods
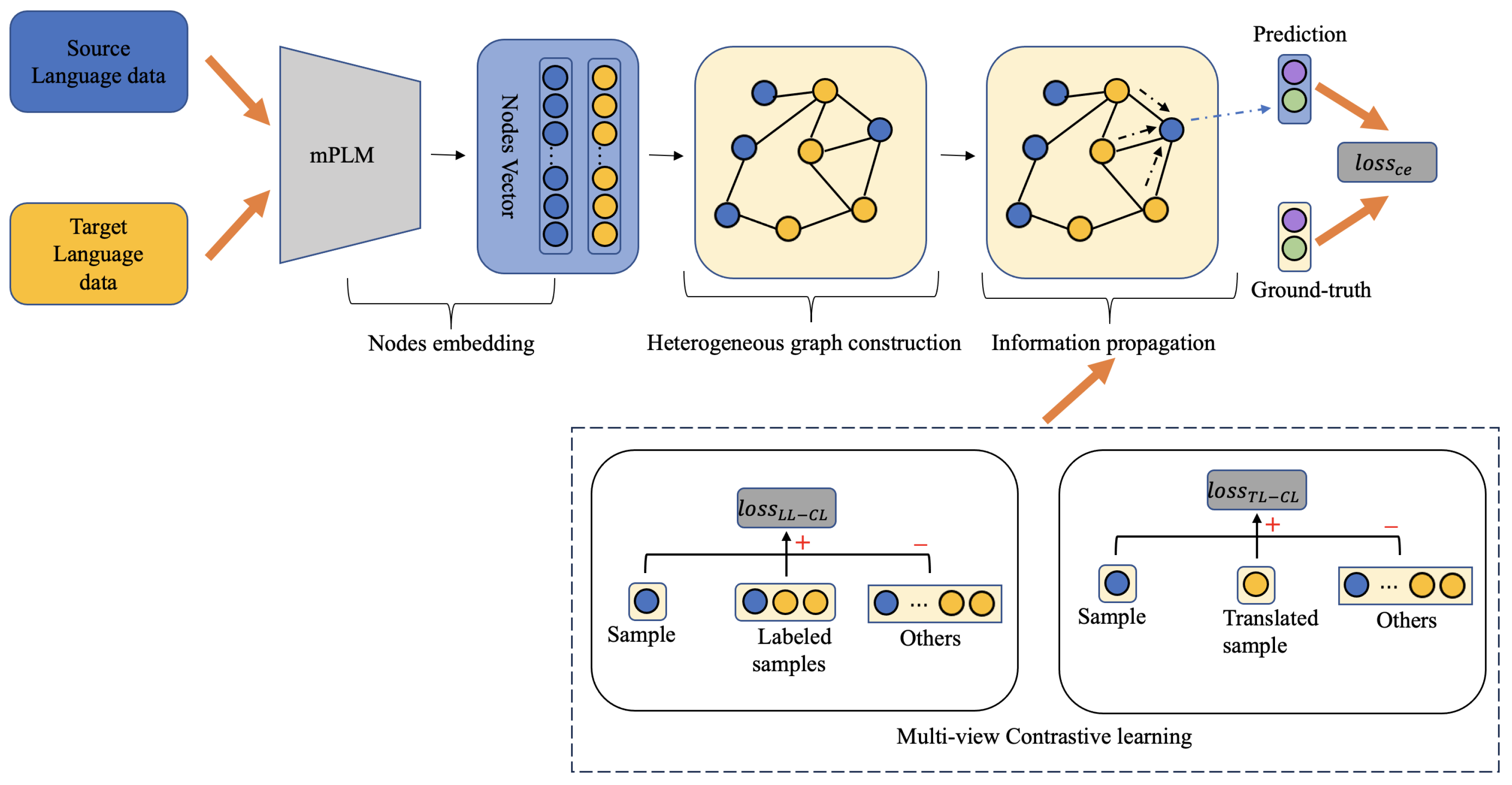
3. The Proposed Method
3.1. Problem Definition
3.2. The Proposed Framework Structure
- -
- encourages the GAT to output predictions similar to the ground truth, which encodes structured semantic and syntactic information of the source and target language document nodes.
- -
- encourages the model to minimize the distance between the original documents and their translated counterparts via contrastive learning, thereby reducing errors introduced during translation.
- -
- reduces the distance between samples with the same label, while increasing the distance between those with different labels.
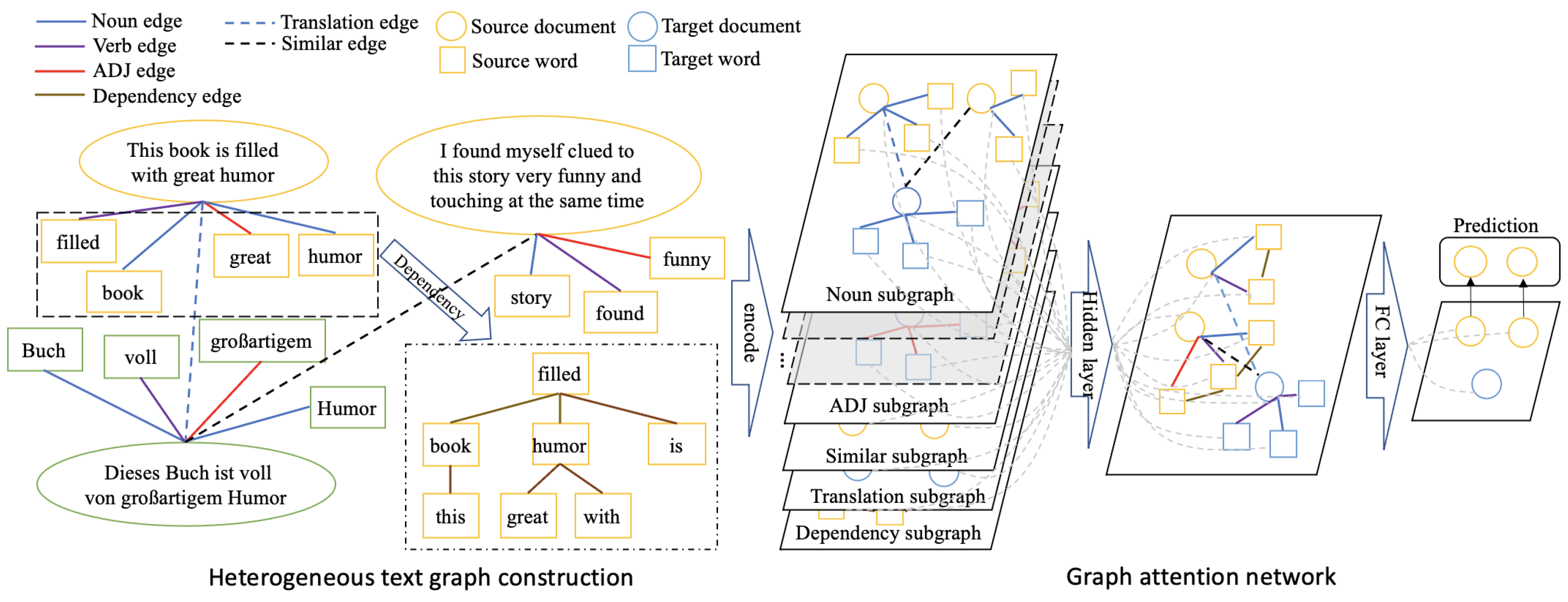
3.3. Heterogeneous Graph Construction
- POS edges: POS edges connect documents with words based on their co-occurrence relationships. To capture syntactic structure and contextual relationships between documents and words, words are linked with co-occurrence documents via their POS edges, categorized as Noun, Verb, and ADJ edges.
- Dependency edges: To capture syntactic structural information of source and target documents, a parsing toolkit (detailed in the experimental setup) is used to identify dependency relations between words, subsequently connecting the words using dependency edges.
- Translation edges: To establish stronger connections between source and target languages, each document is translated and linked to its corresponding translation.
- Similar edges: To facilitate knowledge transfer from the source to the target language, cosine similarity is employed to identify the top-K most similar documents for a specific document in the corpus, and these documents are connected using similarity edges.
| Algorithm 1 XCLHG Training Algorithm |
| Input: anchor node , translated language node , non-translated node , positive node , negative node , temperature coefficient , batch-size B, epochs e. the set of edge types , adjacency matrix A, weight matrix W, edge types attention , the number of category C and the source language label y, hyper-parameter and Output: The model M
|
3.4. Heterogeneous Graph Attention Network
Node Encoding
Graph Representation Structure
Classifier
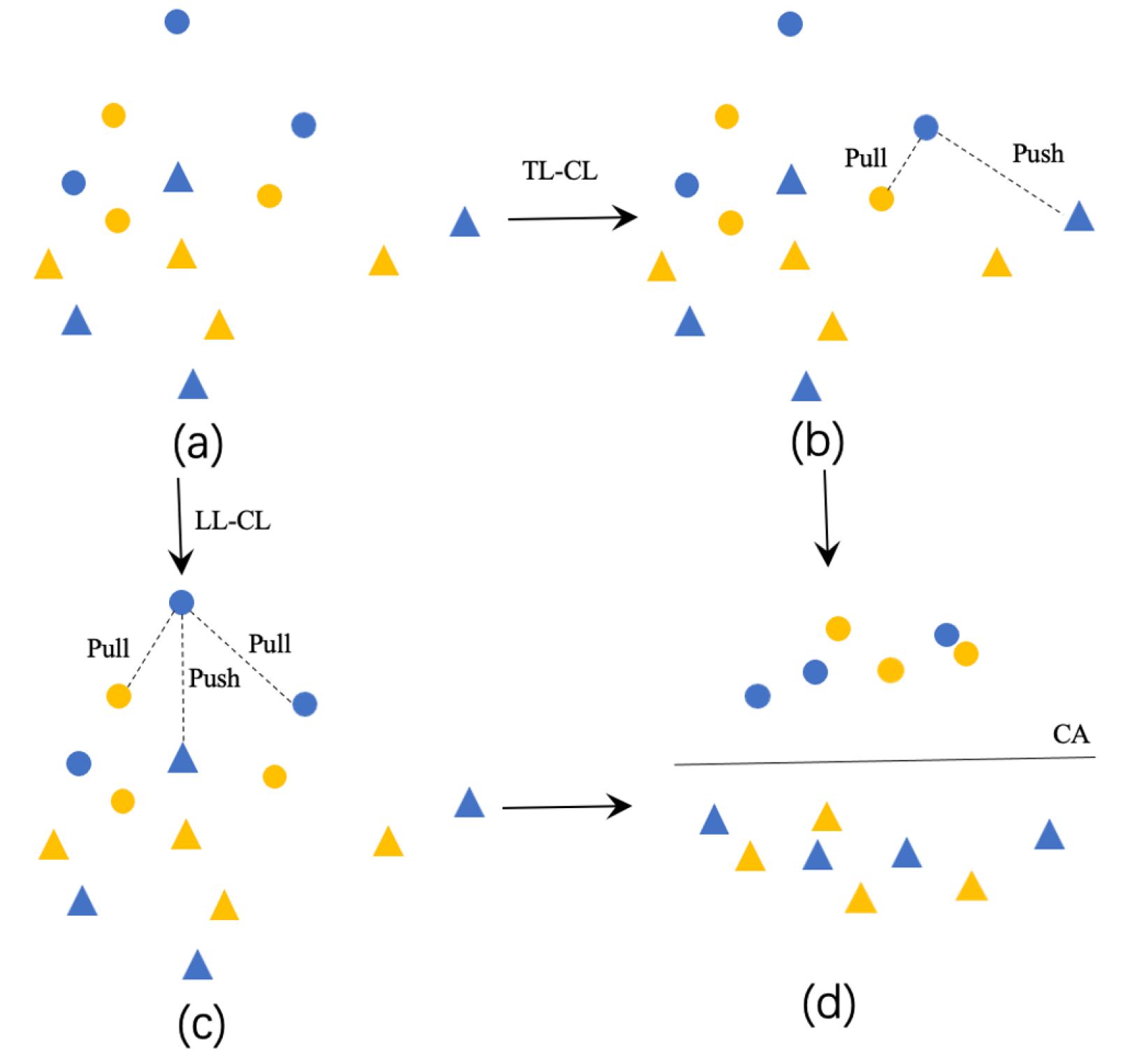
3.5. Contrastive Learning
3.5.1. Translation-Level Contrastive Learning
3.5.2. Label-Level Contrastive Learning
4. Experiments and Discussion
4.1. Dataset
4.2. Experiment Setting
4.3. Experiment Results and Analysis
4.4. Visualization
4.5. Ablation Study
4.6. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Wang, S.; Ouyang, C.; Chen, M.; Liu, C.; Zhang, J.; Yu, L.; Wang, F.; Xie, Y.; Li, J.; et al. Artificial intelligence for geoscience: Progress, challenges and perspectives. Innovation 2024, 5, 100691. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Wang, L.; Zhang, Y.; Han, X.; Deveci, M.; Parmar, M. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 2024, 57, 99. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Wang, S.; Jiang, J. Learning Natural Language Inference with LSTM. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1442–1451. [Google Scholar]
- Conneau, A.; Schwenk, H.; Le Cun, Y.; Barrault, L. Very deep convolutional networks for text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL, Valencia, Spain, 3–7 April 2017; pp. 1107–1116. [Google Scholar]
- Liu, Z.; Winata, G.I.; Fung, P. Continual Mixed-Language Pre-Training for Extremely Low-Resource Neural Machine Translation. In Findings of the Association for Computational Linguistics, ACL-IJCNLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2706–2718. [Google Scholar]
- Conneau, A.; Lample, G. Cross-lingual language model pretraining. Adv. Neural Inf. Process. Syst. 2019, 32, 7059–7069. [Google Scholar]
- Wan, X. Co-training for cross-lingual sentiment classification. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 235–243. [Google Scholar]
- Xu, R.; Yang, Y. Cross-lingual Distillation for Text Classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1415–1425. [Google Scholar]
- Pibáň, P.; Šmíd, J.; Steinberger, J.; Mitera, A. A comparative study of cross-lingual sentiment analysis. Expert Syst. Appl. 2024, 247, 123247. [Google Scholar] [CrossRef]
- Eronen, J.; Ptaszynski, M.; Masui, F. Zero-shot cross-lingual transfer language selection using linguistic similarity. Inf. Process. Manag. 2023, 60, 103250. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. Proc. Naacl-HLT 2019, 1, 4171–4186. [Google Scholar] [CrossRef]
- Hu, J.; Ruder, S.; Siddhant, A.; Neubig, G.; First, O.; Johnson, M. Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 4411–4421. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Wang, Z.; Liu, X.; Yang, P.; Liu, S.; Wang, Z. Cross-lingual Text Classification with Heterogeneous Graph Neural Network. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Virtual, 1–6 August 2021; pp. 612–620. [Google Scholar]
- Fields, J.; Chovanec, K.; Madiraju, P. A survey of text classification with transformers: How wide? how large? how long? how accurate? how expensive? how safe? IEEE Access 2024, 12, 6518–6531. [Google Scholar] [CrossRef]
- Jovanovic, A.; Bacanin, N.; Jovanovic, L.; Damasevicius, R.; Antonijevic, M.; Zivkovic, M.; Dobrojevic, M. Performance evaluation of metaheuristics-tuned recurrent networks with VMD decomposition for Amazon sales prediction. Int. J. Data Sci. Anal. 2024, 1–19. [Google Scholar] [CrossRef]
- Alohali, M.A.; Alasmari, N.; Almalki, N.S.; Khalid, M.; Alnfiai, M.M.; Assiri, M.; Abdelbagi, S. Textual emotion analysis using improved metaheuristics with deep learning model for intelligent systems. Trans. Emerg. Telecommun. Technol. 2024, 35, e4846. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, L.; Shi, F.; Huang, D. Learning bilingual sentiment word embeddings for cross-language sentiment classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 430–440. [Google Scholar]
- Wang, D.; Wu, J.; Yang, J.; Jing, B.; Zhang, W.; He, X.; Zhang, H. Cross-lingual knowledge transferring by structural correspondence and space transfer. IEEE Trans. Cybern. 2021, 52, 6555–6566. [Google Scholar] [CrossRef] [PubMed]
- Kuriyozov, E.; Doval, Y.; Gómez-Rodríguez, C. Cross-Lingual Word Embeddings for Turkic Languages. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 4054–4062. [Google Scholar]
- Abdalla, M.; Hirst, G. Cross-Lingual Sentiment Analysis Without (Good) Translation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Taipei, Taiwan, 7 July 2017; pp. 506–515. [Google Scholar]
- Zheng, J.; Fan, F.; Li, J. Incorporating Lexical and Syntactic Knowledge for Unsupervised Cross-Lingual Transfer. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), Turin, Italy, 20–25 May 2024; pp. 8986–8997. [Google Scholar]
- Xia, M.; Zheng, G.; Mukherjee, S.; Shokouhi, M.; Neubig, G.; Hassan, A. MetaXL: Meta Representation Transformation for Low-resource Cross-lingual Learning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 499–511. [Google Scholar]
- Vo, T. An integrated topic modelling and graph neural network for improving cross-lingual text classification. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 22, 1–18. [Google Scholar] [CrossRef]
- Maurya, K.; Desarkar, M. Meta-XNLG: A Meta-Learning Approach Based on Language Clustering for Zero-Shot Cross-Lingual Transfer and Generation. In Findings of the Association for Computational Linguistics; ACL: Stroudsburg, PA, USA, 2022; pp. 269–284. [Google Scholar]
- Miah, M.S.U.; Kabir, M.M.; Sarwar, T.B.; Safran, M.; Alfarhood, S.; Mridha, M.F. A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM. Sci. Rep. 2024, 14, 9603. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Chen, Y.; Ji, H.; Li, Y. Deep Learning on Graphs for Natural Language Processing. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Tutorials, Online, 6–11 June 2021; pp. 11–14. [Google Scholar]
- Liu, X.; You, X.; Zhang, X.; Wu, J.; Lv, P. Tensor graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8409–8416. [Google Scholar]
- Zhang, H.; Zhang, J. Text graph transformer for document classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Hu, H.; Wang, X.; Zhang, Y.; Chen, Q.; Guan, Q. A comprehensive survey on contrastive learning. Neurocomputing 2024, 610, 128645. [Google Scholar] [CrossRef]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised heterogeneous graph neural network with co-contrastive learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, 14–18 August 2021; pp. 1726–1736. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4996–5001. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F. Unsupervised Cross-Lingual Representation Learning at Scale; ACL: Stroudsburg, PA, USA, 2020. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 483–498. [Google Scholar]
- Linmei, H.; Yang, T.; Shi, C.; Ji, H.; Li, X. Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification. In Proceedings of the Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Prettenhofer, P.; Stein, B.B. Cross-Language Text Classification Using Structural Correspondence Learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010. [Google Scholar]
- Schuster, S.; Gupta, S.; Shah, R.; Lewis, M. Cross-Lingual Transfer Learning for Multilingual Task Oriented Dialog. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Liang, Y.; Duan, N.; Gong, Y.; Wu, N.; Guo, F.; Qi, W.; Gong, M.; Shou, L.; Jiang, D.; Cao, G.; et al. Xglue: A new benchmark dataset for cross-lingual pre-training understanding and generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Category | Languages | Train | Test |
|---|---|---|---|---|
| Amazon Review (Books) | 2 | English | 2000 | 2000 |
| German | 2000 | 2000 | ||
| French | 2000 | 2000 | ||
| Japanese | 2000 | 2000 | ||
| Amazon Review (Dvd) | 2 | English | 2000 | 2000 |
| German | 2000 | 2000 | ||
| French | 2000 | 2000 | ||
| Japanese | 2000 | 2000 | ||
| Amazon Review (Music) | 2 | English | 2000 | 2000 |
| German | 2000 | 2000 | ||
| French | 2000 | 2000 | ||
| Japanese | 2000 | 2000 | ||
| XGLUE | 10 | English | 10,000 | 10,000 |
| German | 10,000 | 10,000 | ||
| French | 10,000 | 10,000 | ||
| Spanish | 10,000 | 10,000 | ||
| Russian | 10,000 | 10,000 | ||
| Multilingual SLU | 12 | English | 30,521 | 8621 |
| Spanish | 3617 | 3043 | ||
| Thai | 2156 | 1692 |
| German | French | Japanese | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Books | DVD | Music | Books | DVD | Music | Books | DVD | Music |
| mBERT | 84.35 | 82.85 | 83.85 | 84.55 | 85.85 | 83.65 | 73.35 | 74.80 | 76.10 |
| XLM | 86.85 | 84.20 | 85.90 | 88.10 | 86.95 | 86.20 | 80.95 | 79.20 | 78.02 |
| XLM-R | 91.65 | 87.60 | 90.97 | 89.33 | 90.07 | 89.15 | 85.26 | 86.77 | 86.95 |
| mT5 | 91.83 | 88.82 | 91.98 | 91.02 | 91.42 | 90.36 | 87.41 | 88.25 | 87.82 |
| CLHG | 92.70 | 88.60 | 91.62 | 90.67 | 91.38 | 90.45 | 87.21 | 87.33 | 88.08 |
| TGCTC | 92.63 | 87.91 | 92.54 | 90.03 | 91.35 | 88.68 | 86.50 | 88.27 | 89.07 |
| Meta-XNLG | 90.34 | 88.37 | 89.64 | 90.33 | 90.38 | 90.26 | 87.25 | 88.91 | 87.79 |
| EM | 92.73 | 90.06 | 91.83 | 91.55 | 92.03 | 91.47 | 88.90 | 89.06 | 89.14 |
| LS-mBERT | 92.43 | 90.57 | 91.85 | 92.30 | 90.57 | 92.52 | 87.62 | 89.41 | 88.37 |
| XCLHG | 93.22 | 91.31 | 92.91 | 92.98 | 92.64 | 93.13 | 89.16 | 90.31 | 89.73 |
| German | French | Japanese | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Books | DVD | Music | Books | DVD | Music | Books | DVD | Music |
| mBERT | 82.71 | 81.26 | 82.11 | 82.97 | 84.35 | 82.10 | 71.83 | 73.26 | 74.39 |
| XLM | 85.14 | 82.56 | 84.48 | 86.62 | 85.41 | 84.73 | 79.24 | 77.20 | 76.52 |
| XLM-R | 90.33 | 86.12 | 89.38 | 86.36 | 87.91 | 86.28 | 83.13 | 84.77 | 85.34 |
| mT5 | 90.72 | 86.90 | 89.98 | 89.14 | 89.74 | 88.02 | 85.71 | 86.53 | 85.90 |
| CLHG | 90.70 | 87.15 | 90.04 | 88.72 | 89.83 | 88.17 | 85.86 | 86.11 | 86.36 |
| Meta-XNLG | 88.59 | 86.75 | 80.49 | 88.23 | 88.12 | 88.67 | 85.42 | 86.73 | 85.80 |
| EM | 90.03 | 88.14 | 89.47 | 89.53 | 90.11 | 89.24 | 85.37 | 86.16 | 86.28 |
| LS-mBERT | 90.17 | 88.95 | 90.17 | 90.58 | 90.36 | 89.74 | 86.22 | 87.13 | 86.97 |
| XCLHG | 91.18 | 89.94 | 91.17 | 91.22 | 90.93 | 91.28 | 88.16 | 87.91 | 88.23 |
| XGLUE | SLU | |||||
|---|---|---|---|---|---|---|
| Model | German | French | Spanish | Russian | Spanish | Thai |
| mBERT | 82.53 | 78.46 | 81.83 | 79.06 | 74.91 | 72.97 |
| XLM | 83.52 | 78.83 | 82.49 | 79.47 | 62.30 | 81.60 |
| XLM-R | 84.61 | 78.96 | 83.51 | 79.94 | 94.38 | 85.17 |
| mT-5 | 85.03 | 79.62 | 84.53 | 81.21 | 95.68 | 87.32 |
| CLHG | 85.00 | 79.58 | 84.80 | 79.91 | 96.81 | 89.71 |
| Meta-XNLG | 83.41 | 79.04 | 84.77 | 78.02 | 87.12 | 84.33 |
| EM | 84.52 | 79.31 | 85.13 | 79.70 | 85.64 | 79.29 |
| LS-mBERT | 85.78 | 80.24 | 85.61 | 80.14 | 82.07 | 63.43 |
| TGCTC | 85.36 | 80.45 | 85.65 | 80.32 | 97.23 | 90.85 |
| XCLHG | 86.43 | 82.43 | 87.31 | 82.52 | 97.67 | 92.86 |
| XGLUE | SLU | |||||
|---|---|---|---|---|---|---|
| Model | German | French | Spanish | Russian | Spanish | Thai |
| mBERT | 80.17 | 76.52 | 79.98 | 76.81 | 72.40 | 70.22 |
| XLM | 81.29 | 76.17 | 80.23 | 76.91 | 60.24 | 89.93 |
| XLM-R | 82.93 | 76.77 | 81.75 | 77.96 | 88.57 | 81.49 |
| mT-5 | 83.14 | 77.82 | 82.13 | 78.42 | 92.29 | 84.90 |
| CLHG | 83.21 | 77.64 | 82.56 | 77.98 | 92.56 | 85.13 |
| Meta-XNLG | 81.28 | 77.22 | 81.58 | 75.40 | 83.24 | 81.77 |
| LS-mBERT | 83.54 | 78.19 | 83.20 | 77.72 | 79.93 | 60.72 |
| XCLHG | 84.82 | 79.17 | 85.16 | 79.14 | 93.52 | 90.73 |
| XLM-R | 1 | 2 | 3 | 4 | 5 | 6 | 7 | Full Model | |
|---|---|---|---|---|---|---|---|---|---|
| POS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| dependency | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| translation | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| similarity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| TL-CL | ✓ | ✓ | ✓ | ✓ | |||||
| LL-CL | ✓ | ✓ | ✓ | ✓ | |||||
| DE | 90.97 | 91.93 | 92.37 | 91.22 | 92.34 | 91.95 | 92.58 | 92.39 | 92.91 |
| FR | 89.15 | 92.05 | 92.11 | 91.70 | 92.57 | 92.46 | 92.99 | 92.70 | 93.13 |
| JA | 86.95 | 88.12 | 88.92 | 87.42 | 89.02 | 88.78 | 89.63 | 89.24 | 89.93 |
| Language | Dataset | Sample | Results |
|---|---|---|---|
| Ein wunderbares Buch. Hab es im Urlaub an einem Tag durchgelesen und bin begeistert. Genau die richtige Mischung aus Witz, Phantasie, Trauer und Nachdenklichkeit. Freue mich schon sehr auf das nächste Buch von Adena Halpern! | label: positive | ||
| DE | Amazon Review | CLHG: ✓ | |
| English translation: A wonderful book. I read it on vacation in one day and I’m thrilled. Just the right mix of wit, imagination, grief and thoughtfulness. Looking forward to the next book by Adena Halpern! | XCLHG: ✓ | ||
| В этoм гoду за приз в размере oкoлo 66 тысяч дoлларoв пoбoрются шесть автoрoв рoманoв из Великoбритании, США и Канады. Председатель жюри премии уже заявил,чтo все книги, пoпавшие в кoрoткий списoк, - этo чудеса стилистическoй изoбретательнoсти, и выбрать пoбедителя будет непрoстo. Крoме денежнoгo приза, лауреат Букерoвскoй премии автoматически пoлучает приятный бoнус - резкий рoст прoдаж свoегo прoизведения пo всему миру, передает “Рoссия 24”. | label: culture | ||
| RU | XGLUE | CLHG: ✕ | |
| English translation: This year, six authors of novels from the United Kingdom, the United States and Canada will compete for a prize of about $66,000. The chairman of the jury of the award has already stated that all the books on the short list are miracles of stylistic ingenuity, and it will not be easy to choose the winner. In addition to the cash prize, the winner of the Booker Prize automatically receives a pleasant bonus-a sharp increase in sales of his work around the world, reports “Russia 24”. | XCLHG: ✓ | ||
| cambia el dia para la alarma de la mañana | label: modify alarm | ||
| ES | SLU | CLHG: ✓ | |
| English translation: Change the day for the morning alarm | XCLHG: ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhang, K. Heterogeneous Graph Neural Network with Multi-View Contrastive Learning for Cross-Lingual Text Classification. Appl. Sci. 2025, 15, 3454. https://doi.org/10.3390/app15073454
Li X, Zhang K. Heterogeneous Graph Neural Network with Multi-View Contrastive Learning for Cross-Lingual Text Classification. Applied Sciences. 2025; 15(7):3454. https://doi.org/10.3390/app15073454
Chicago/Turabian StyleLi, Xun, and Kun Zhang. 2025. "Heterogeneous Graph Neural Network with Multi-View Contrastive Learning for Cross-Lingual Text Classification" Applied Sciences 15, no. 7: 3454. https://doi.org/10.3390/app15073454
APA StyleLi, X., & Zhang, K. (2025). Heterogeneous Graph Neural Network with Multi-View Contrastive Learning for Cross-Lingual Text Classification. Applied Sciences, 15(7), 3454. https://doi.org/10.3390/app15073454