1. Introduction
Geophysical well logging is a crucial technical process in oilfield exploration and development, where the accurate calculation of reservoir parameters plays a significant role in reservoir characterization and hydrocarbon resource evaluation. Currently, methods for determining reservoir parameters are mainly classified into direct and indirect measurements. Direct measurement involves laboratory analysis of core samples to obtain rock physical properties, which is the most precise approach. However, due to its high cost and time-consuming nature, it is difficult to implement on a large scale. Indirect methods include conventional well log interpretation techniques and artificial intelligence (AI)-based approaches. Conventional interpretation relies on measuring the physical responses related to reservoir parameters and then deriving them using physical models or empirical formulas. While this method is easy to apply, it has limited adaptability and struggles to meet the demands of complex reservoir environments. With advancements in exploration technologies and the increasing intensity of oilfield development, both direct measurement and conventional interpretation methods are insufficient to meet the efficiency and quality requirements of well logging. Therefore, leveraging advanced AI algorithms to enhance the efficiency and accuracy of well logging data processing and interpretation has become a prominent research focus [
1,
2,
3,
4,
5,
6,
7].
In recent years, AI and big data technologies have been widely applied in petroleum exploration and development, achieving remarkable breakthroughs. Chen et al. (2020) [
8] proposed a multi-layer long short-term memory (LSTM) network that captures deep sequential dependencies to improve porosity prediction accuracy at significant inflection points. However, it still has limitations when handling discontinuous sequences and highly heterogeneous data. Shao et al. (2022) [
9] introduced a reservoir parameter prediction method based on transfer learning, significantly enhancing predictive performance, yet failing to fully address the local optimum problem. Muhammad et al. (2023) [
10] optimized the extreme gradient boosting (XGBoost) algorithm using a grid search (GS) optimization technique, improving the performance of porosity prediction models. However, due to the computational complexity of the grid search, the optimization efficiency and accuracy remained constrained. Pan et al. (2022) [
11] developed an XGBoost-based porosity prediction model using hybrid optimization methods, enhancing prediction performance while also suggesting directions for further optimization. Xu et al. (2024) [
12] combined deep learning with geological information to improve porosity interpretation accuracy for carbonate reservoirs with complex pore structures, providing valuable references for carbonate reservoir parameter prediction. Despite the progress made in applying AI to porosity prediction, several challenges remain: (1) Some models exhibit poor adaptability to discontinuous sequential data, making it difficult to effectively model the complex heterogeneity of reservoirs. (2) Traditional machine learning methods rely on manually crafted features, limiting their ability to fully exploit the deep information in well logging data. (3) Existing deep learning models mainly focus on either local features or time-series dependencies, lacking effective mechanisms to model global dependencies. Therefore, constructing a deep learning model that integrates local features, sequential information, and global dependencies has become a key research direction for porosity prediction in carbonate reservoirs.
In oil and gas exploration and development, studying carbonate reservoir parameters is of paramount importance. Due to influences such as depositional environments, dissolution, and diagenesis, carbonate reservoirs exhibit significant variability in properties such as porosity, lithology, hydrocarbon content, and electrical characteristics. Well logging curves contain a large amount of repetitive, redundant, and anomalous feature information, and each logging curve represents a comprehensive characterization of adjacent formations. Directly using traditional methods for point-by-point predictions while ignoring the influence of adjacent formations may lead to poor predictive performance and weak model generalization capability [
13,
14,
15]. To address these issues, this paper proposes a porosity prediction model that integrates convolutional neural networks (CNN), bidirectional long short-term memory (BiLSTM), and Transformer networks (CNN-BiLSTM-Transformer). The method utilizes CNN to extract local features from well logging curves, BiLSTM to capture sequential neighborhood information, and the self-attention mechanism of the Transformer to focus on temporal dependencies and input features, effectively modeling global relationships. To further optimize model performance, the Adam optimization algorithm is employed to adjust network weights, and hyperparameters are fine-tuned based on feedback from prediction accuracy. Finally, the effectiveness of the proposed method is validated through experiments and comparative analysis with traditional approaches, providing both theoretical and practical guidance for porosity prediction in highly heterogeneous carbonate reservoirs.
2. Methods
2.1. Overview of Regional Geology
The selected logging interval is from the Early Triassic Jialingjiang Formation in the Moxi area of the Sichuan Basin, People’s Republic of China. The Sichuan Basin is one of China’s largest hydrocarbon-bearing basins, having undergone three major tectonic evolutionary stages. As shown in
Figure 1, from the Ediacaran to the Late Triassic period, it was characterized by a marine carbonate platform [
16]. The basin is bordered by the Longmen Mountains to the west, the Daba Mountains to the north, and the Kangdian Uplift to the south. The Moxi Gas Field is located in the southern part of the gentle Zhongchang uplift structural belt in the central Sichuan Basin. Geographically, it lies approximately 30 km south of Suining City in Sichuan Province, situated in the southern section of the central Sichuan oil and gas region. During the Early Triassic Jialingjiang period, the Upper Yangtze Craton marine basin was influenced by the uplift of surrounding paleo-uplifts and fluctuations in sea level. Due to the constraints of surrounding paleo-uplifts and periodic global climate changes, the Sichuan Sea underwent three cycles of regression–stagnant water evaporative salt basin–transgression during the second substage of the Jialingjiang period. Under the overall regressive background of this stage, the environment evolved into a restricted marine setting [
17].
The Moxi Gas Field is a typical strongly heterogeneous carbonate gas reservoir, with proven natural gas reserves exceeding 326.59 billion cubic meters. As shown in
Table 1 and
Figure 1, the Jialingjiang Formation is subdivided into five members from bottom to top (T1j1 to T1j5). Members T1j4 and T1j5 are primarily composed of anhydrite and dolomite, while T1j1 and T1j3 consist mainly of limestone. During the T1j2 depositional period, the sedimentary system was a carbonate platform on an epeiric sea, characterized by restricted–evaporative platform deposits. The reservoir types are predominantly porous with locally developed fractures and display significant secondary alterations, diverse reservoir types, and strong heterogeneity. Therefore, further analysis of the porosity in carbonate reservoirs with complex pore structures serves as an important reference for evaluating this gas reservoir [
18,
19].
Figure 1.
Work area of Moxi block: (
a) tectonic divisions of Sichuan Basin (adapted from Shi, 2023) [
20]. (
b) Location map of the studied wells in the Moxi area. Red dots are wells used to train machine learning models. (
c) Stratigraphic characteristics of the Jia 2 member in the study area.
Figure 1.
Work area of Moxi block: (
a) tectonic divisions of Sichuan Basin (adapted from Shi, 2023) [
20]. (
b) Location map of the studied wells in the Moxi area. Red dots are wells used to train machine learning models. (
c) Stratigraphic characteristics of the Jia 2 member in the study area.
2.2. Method Process
Well logging curves have high vertical resolution, allowing for the continuous and quantitative characterization of sedimentary processes and providing geological information at different depths. To establish a nonlinear relationship between well logging curves and core analysis porosity while improving the accuracy of carbonate reservoir porosity prediction, this study proposes a deep learning model based on a convolutional neural network (CNN), bidirectional long short-term memory Network (BiLSTM), and Transformer (CNN-BiLSTM-Transformer). This model is applied to predict the porosity of the Jialingjiang Formation in the study area. To comprehensively evaluate the model’s effectiveness, ablation experiments are conducted to compare the prediction performance of different model structures, verifying the role of the CNN, BiLSTM, and Transformer layers in the prediction task. The methodological workflow of this study is illustrated in
Figure 2, comprising data preprocessing, feature engineering, deep learning model construction, performance evaluation, and ablation experiments. The specific process is as follows:
Data Preprocessing: Before training the model, data preprocessing steps such as data cleaning, normalization, and data augmentation are performed to improve data quality and ensure model stability.
Model Construction: (1) Feature and Label Extraction: Feature variables suitable for machine learning methods are selected from raw data to construct the dataset. (2) Selection of Sensitive Parameters: A Pearson correlation coefficient heatmap is generated to analyze and select porosity-sensitive parameters, providing better feature representation for the model. (3) Dataset Partitioning: The dataset is split into 80% training data and 20% testing data. To maintain the continuity of deep sequential data, training and testing sets are divided as continuous segments. (4) Deep Learning Model Development: The CNN layer first extracts local features, followed by the BiLSTM layer capturing long-term dependencies in deep sequential data. Finally, the Transformer layer applies a self-attention mechanism to focus on sequential neighborhood information and logging curve features, capturing global dependencies. This results in the CNN-BiLSTM-Transformer porosity prediction model. (5) Model Evaluation: The model’s performance is assessed using the RMSE, MAE, and R² metrics.
Ablation Experiment: To validate the model’s effectiveness, a comparative analysis is conducted by removing different network layers while keeping all other factors constant, examining their impact on model performance.
Model Finalization: Based on steps (2) and (3), a comprehensive comparison is conducted to determine the most suitable porosity prediction model for the study area.
Model Application: The optimized CNN-BiLSTM-Transformer model is applied to predict porosity in the Jialingjiang Formation. The predictions are compared with actual well logging data to validate the model’s practical applicability.
2.3. Data Description
The experimental data in this study were obtained from actual logging data of 14 cored wells in the Moxi Gas Field, Sichuan, China. The logging depth ranges from 1600 to 3300 m, comprising a total of 2409 sets of logging data samples. The study involves eight types of logging data: caliper logging (CAL), natural gamma ray logging (GR), acoustic logging (AC), compensated neutron logging (CNL), density logging (DEN), flushed zone resistivity (RXO), true formation resistivity (RT), and core analysis porosity (POR). The statistical analysis of the logging curve data is presented in
Table 2.
The lithology of this block mainly consists of dolomite, limestone, and gypsum rocks. Dolomite and limestone serve as the primary reservoir rocks, while gypsum, with extremely poor physical properties, mostly acts as interlayers or cap rocks. Due to the strong heterogeneity of carbonate reservoirs, there are significant differences among the logging curves. These curves exhibit wide distribution ranges, inconsistent units of measurement, and diverse distribution characteristics. For example, the data show large variations in magnitude, necessitating logarithmic transformation to better represent data features. Therefore, further analysis and processing of the raw data are required.
Data quality has a significant impact on the predictive performance of machine learning models, making preprocessing a critical step in data mining and machine learning. The preprocessing methods employed in this study include handling outliers and missing values, resampling, and normalization. First, the data integrity was assessed, and missing data were addressed through interpolation or curve reconstruction. Outliers were removed, and logarithmic transformation was applied to mitigate the issue of large data range disparities, thereby improving data quality. Insufficient data samples and the randomness involved in splitting the training and testing sets can lead to model underfitting. This issue was addressed by applying data resampling techniques and adopting continuous sampling to preserve the neighborhood feature information in the depth sequence. In data prediction tasks, inconsistent data scales can heavily influence model performance. To eliminate the impact of inconsistent data dimensions—where large numerical differences among individual indicators can distort weight ratios—and to accelerate gradient descent, this study employed min–max normalization. This technique standardizes data into a consistent measurement scale, enhancing prediction accuracy and reducing training time. The specific normalization formula is as follows:
where
is the input feature variable data;
is the normalized feature variable;
is the maximum value of feature variable data;
is the minimum value of feature variable data.
This process ensures that all data are scaled within the range [0, 1], enabling the model to learn more effectively.
Based on geological data, depositional background, and geophysical logging knowledge of the study area, a correlation heatmap of logging curves was constructed using Pearson correlation coefficients, and the logging data were analyzed for correlation. Logging curves at the same depth reflect the same geological phenomena, while reservoir parameters represent another characterization of these phenomena. As shown in
Figure 3, the logging curves exhibit varying degrees of positive and negative correlation with porosity (POR). The correlation coefficients of GR, CAL, AC, CNL, RT, RXO, and DEN with POR are 0.079, −0.058, 0.31, 0.57, −0.53, −0.13, and −0.15, respectively. Among them, CAL has the lowest correlation with POR, while CNL has the highest. The other features fall between these two extremes. To improve computational efficiency and reduce multicollinearity, the sensitive parameters GR, CNL, AC, DEN, RXO, and RT were selected as input features to represent the target prediction variable POR. This ensures high-quality data for subsequent model development, data prediction, and model validation.
2.4. Evaluation Indicators
To evaluate the stability and prediction accuracy of the CNN-BiLSTM-Transformer algorithm, this study adopts root mean square error (RMSE), mean absolute error (MAE), and the coefficient of determination (R²) as evaluation metrics [
21,
22,
23,
24]. Their calculation formulas are as follows:
where:
The smaller the RMSE, the better the model’s performance and the lower the prediction error. A smaller MAE indicates a lower average error, meaning the prediction results are closer to the actual values. An value closer to 1 signifies stronger explanatory power of the model for the data and a higher degree of fit.
2.5. Algorithm Principle
2.5.1. Principle of Convolutional Neural Network
Convolutional neural network (CNN) is a classic deep learning model typically composed of multiple convolutional layers, pooling layers, and fully connected layers. It is widely used in geophysical well logging to extract features. The convolutional layer extracts feature information between well logging curves and core analysis porosity. The pooling layer reduces the sequence size, lowering computational complexity, and the fully connected layer is used for classification or regression tasks. The core idea is to map input data to a high-dimensional feature space through convolution and pooling operations to extract features effectively [
25,
26,
27]. The primary characteristics of CNN are weight sharing and local connections, which significantly reduce the number of model parameters, lower the risk of overfitting, improve generalization ability, and enhance feature extraction capabilities. The convolution operation is defined by the following formula:
where
represents the output feature data;
is the convolution kernel (filter);
denotes the input data;
b is the bias term;
K is the length of the data (or kernel size).
The convolution operation integrates information from neighboring regions by sliding the kernel across the input feature map, effectively capturing local spatial dependencies.
2.5.2. Principle of Bidirectional Long Short-Term Memory
LSTM (long-short term memory) is an improved recurrent neural network (RNN) introduced by Hochreiter and characterized by its ability to maintain dependencies over long time sequences. Unlike traditional RNNs, where neurons are connected sequentially, LSTM introduces a memory cell and gating mechanisms (input gate, output gate, and forget gate) that enable selective memory retention and information flow control (
Figure 4). This structure allows LSTM to extract sequential dependencies in data effectively, solving the vanishing and exploding gradient issues commonly faced in standard RNNs. As a result, LSTM improves prediction accuracy and enhances the model’s generalization capability [
28]. The mathematical formulations of the LSTM model are as follows:
where
: Input gate, forget gate, and output gate, respectively;
: Cell state at time t;
: Hidden state at time t;
and : Weight matrix and bias term corresponding to a specific gate or state ;
: Sigmoid activation function;
: Hyperbolic tangent function;
⨀: Element-wise multiplication (Hadamard product).
BiLSTM (bidirectional long short-term memory) improves upon the traditional LSTM by incorporating a forward LSTM layer and a backward LSTM layer. BiLSTM reads both past and future sequence information through its hidden layers, enabling bidirectional fitting of the data. This design allows the model to better capture hidden state information, with both forward and backward sequences influencing the output. This dual consideration of past and future data helps further improve prediction accuracy [
29,
30]. The structure of BiLSTM is shown in
Figure 5, where
represent the sequence input and output data and the forward and backward hidden states of the LSTM, respectively.
2.5.3. Principle of Transformer
Transformer is a deep learning model based on the self-attention mechanism and is capable of dynamically adjusting the relationship weights between different parts of the input sequence. This allows it to more effectively capture long-range dependencies within the sequence and model complex interactions among multiple variables. The Transformer network supports parallel computation, with each Transformer block consisting of a multi-head self-attention layer and a position-wise fully connected feedforward network. The blocks are connected via residual connections and layer normalization structures to accelerate training and improve model stability.
The formula for attention computation is as follows:
Here, , and V represent the query, key, and value matrices, respectively, while is the scaling factor. In this study, the temporal dependencies captured by the LSTM are used as input to the Transformer, processed through the encoder layer to focus on key features.
As shown in
Figure 6, the global dependencies are captured using the multi-head self-attention mechanism, and a feedforward neural network further extracts and transforms the features. The resulting feature data are then passed through residual connections and layer normalization before being fed into the fully connected layer.
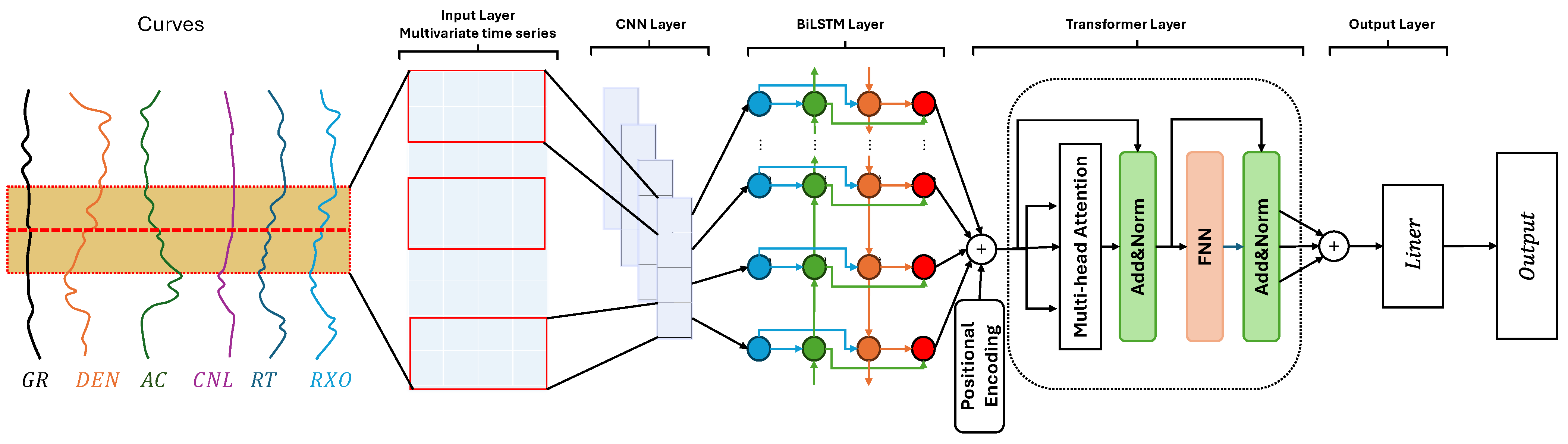
2.5.4. Principle of CNN-BiLSTM-Transformer
This study proposes a neural network model that organically integrates three deep learning architectures—convolutional neural network (CNN), bidirectional long short-term memory network (BiLSTM), and Transformer—to capture neighborhood deep sequences (
Figure 7). As shown in
Figure 7, the model first employs CNN to capture local spatial features in logging data. Then, the BiLSTM layer integrates past and future sequence information to extract the temporal sequence features of the logging data. Subsequently, the Transformer encoder, using the multi-head self-attention mechanism, captures global dependencies and feature interactions in the logging data. Finally, the extracted deep features are mapped to the porosity prediction space through a fully connected layer, completing the porosity prediction.
This method enhances prediction accuracy and improves the model’s generalization ability through the multi-scale integration of local, temporal, and global features. It provides a valuable reference for the extraction and prediction of temporal features in geophysical logging.
3. Results
This experiment was implemented using Python 3.10 software combined with the PyTorch 1.0 software framework. The optimizer chosen for the model is Adam, and the loss function is the cross-entropy loss function. The number of epochs is set to 500, and the batch size, representing the number of data samples used in a single training batch, is set to 64. The learning rate is 0.001. The CNN-BiLSTM-Transformer model comprises two 1D convolutional layers, two LSTM layers, two Transformer encoders, and two fully connected layers. This method utilizes the Adam optimizer, which features an adaptive learning rate and momentum update mechanism, to train the model. The mean squared error loss (MSELoss) is employed to calculate the error between the predicted values and the actual porosity values, providing a comprehensive evaluation and analysis of the model.
3.1. Ablation Study
To better validate the effectiveness of the different layers in the proposed network structure, this section conducts ablation experiments on the components of the proposed method using the same dataset. To ensure the independence of other variables in each ablation experiment, the training parameters, such as sample size, initial learning rate, and training epochs, are kept consistent with the original setup. Ablation of the Feature Extraction CNN Layer: The first experiment removes the CNN layer responsible for extracting local features from well logging data. Instead, the model directly predicts using the preprocessed well logging data without the CNN feature extraction step. Ablation of the Global Dependency Transformer Layer: The second experiment excludes the Transformer layer, which builds global dependencies using the Transformer encoder. This setup uses only the sequence information extracted by the CNN and BiLSTM layers. Simultaneous Ablation of CNN and Transformer Layers: The third experiment removes both the CNN layer and the Transformer layer, leaving only the BiLSTM layer to process the data. The results of each ablation experiment are compared with the CNN-BiLSTM-Transformer model using the test set. The comparison results, shown in
Figure 8, illustrate the effectiveness of each network layer and its contribution to the overall model. The results of the three ablation experiments indicate that the feature extraction CNN layer and the global dependency Transformer layer significantly enhance the predictive performance of the network structure. These layers improve the model’s accuracy and robustness. The CNN-BiLSTM-Transformer model achieves the lowest RMSE and MAE and the highest R
2, demonstrating that the CNN-BiLSTM-Transformer network structure outperforms single deep learning networks and delivers improved prediction capabilities.
3.2. Model Evaluation
To verify the accuracy and reliability of the proposed model, this study constructs four porosity prediction models—XGBoost, LSTM, BiLSTM, and CNN-BiLSTM-Transformer—based on preprocessed well logging data. Comprehensive comparison and analysis of these models are conducted. To quantitatively evaluate the predictive performance and generalization ability of each model, root mean square error (RMSE), mean absolute error (MAE), and the coefficient of determination (R
2) are used as evaluation metrics. Prediction error analysis is performed on the test set. The model comparison results are shown in
Table 3. As indicated in
Table 3, the XGBoost model performs the worst, with RMSE, MAE, and R² values of 0.029, 0.018, and 0.49, respectively. The improved deep learning models significantly outperform traditional machine learning models. The LSTM model achieves an R
2 of 0.52, while BiLSTM further improves it to 0.75, demonstrating that incorporating bidirectional temporal features enhances predictive capability. The proposed CNN-BiLSTM-Transformer model achieves the best performance, with an R
2 of 0.98 and the lowest RMSE and MAE values. This indicates that the model has a superior ability to learn the complex nonlinear relationships within well logging data. Furthermore, error analysis reveals that XGBoost and LSTM exhibit lower prediction accuracy in regions with strong reservoir heterogeneity. In contrast, the CNN-BiLSTM-Transformer model integrates CNN for local feature extraction, BiLSTM for deep sequential information processing, and Transformer for global dependency modeling. This comprehensive approach enables the model to better capture the complex relationships between well logging curves and porosity, making it more effective for predicting porosity in highly heterogeneous carbonate reservoirs.
Based on the same processing workflow and dataset, the regression performance of each model for porosity prediction in the training and test sets is shown in
Figure 9. As shown in
Figure 9, the traditional machine learning model XGBoost demonstrates a certain degree of regression prediction capability. However, the data points in the test set are widely scattered, indicating limited generalization ability and a tendency toward overfitting. In contrast, LSTM and BiLSTM significantly reduce prediction errors by capturing sequential neighborhood features. However, due to the relatively small dataset and the discontinuity in core sampling, LSTM struggles to fully capture deep sequential features, leading to suboptimal predictions for certain data points. Comprehensive comparative analysis shows that the CNN-BiLSTM-Transformer model, by integrating CNN for local feature extraction, BiLSTM for deep sequential modeling, and Transformer for global dependency capture, produces predictions that closely match actual porosity values. The R
2 values for the training and test sets reach 0.99 and 0.98, respectively, indicating the highest prediction accuracy and generalization ability. Compared with the traditional XGBoost model and single deep learning networks, CNN-BiLSTM-Transformer demonstrates significant improvements, proving to be a practical and effective approach for deep-sequence reservoir porosity prediction.
4. Discussion
4.1. Ablation Experiment Results
This study validates the superiority of the CNN-BiLSTM-Transformer model through ablation experiments, highlighting the effectiveness of combining local feature extraction, bidirectional sequential dependency modeling, and global dependency capture in improving prediction accuracy and generalization ability. The model first extracts local features through the CNN layer, then captures sequential neighborhood information using the BiLSTM layer, and finally employs the Transformer layer with a self-attention mechanism to focus on temporal information and input features, capturing global dependencies. By integrating these features, the model enables accurate porosity prediction for complex carbonate reservoirs with deep-sequence well logging data. The R2 values for the training and test sets reach 0.99 and 0.98, respectively. This method demonstrates strong feature extraction capabilities, high generalization ability, and suitability for highly heterogeneous reservoirs. The CNN component enhances local feature extraction, BiLSTM handles deep sequential dependencies, and Transformer focuses on global information, significantly improving prediction accuracy. Compared to XGBoost and standalone LSTM models, CNN-BiLSTM-Transformer provides more accurate porosity distribution predictions in complex reservoirs. The high R² on the test set confirms that the model maintains strong stability and accuracy across different well logging data combinations. In conclusion, the CNN-BiLSTM-Transformer network structure provides a novel and effective reference for accurately evaluating porosity in complex and highly heterogeneous carbonate reservoirs.
4.2. Model Application Evaluation
In this study, Well M149 was selected as an example to analyze the practical application of the CNN-BiLSTM-Transformer model and compare its performance with other models (
Figure 10). As shown in
Figure 10. the figure consists of nine tracks. The first four tracks display depth and well logging curves, while tracks five to nine present the porosity predictions of different models alongside core physical analysis results. The CNN-BiLSTM-Transformer model effectively integrates neighborhood information and curve features to comprehensively predict porosity. As a result, its prediction error remains the most stable and exhibits the least fluctuation across all depth intervals, indicating that the CNN-BiLSTM-Transformer achieves the best prediction performance and the strongest generalization ability among the compared models. The results demonstrate that the CNN-BiLSTM-Transformer achieves the lowest prediction error and the most stable porosity estimates across different depth intervals. By leveraging neighborhood information and temporal features from well logging curves, this model enables accurate porosity prediction across the entire well section.
4.3. Model Limitations
The proposed porosity prediction model based on CNN-BiLSTM-Transformer demonstrates strong temporal feature-capturing capabilities, effectively incorporating neighborhood information and well logging curve characteristics for comprehensive porosity prediction. However, as the number of network layers increases, the model becomes more complex, requiring greater computational resources. Additionally, the model relies on large, continuous datasets to capture temporal features effectively, thereby enhancing prediction accuracy and generalization ability. The study area provides an extensive dataset of continuous well logging curves and experimental measurements, enabling the CNN-BiLSTM-Transformer model to perform exceptionally well. However, in regions with limited or lower-quality data, the effectiveness of this method requires further validation. The model has certain limitations, including high computational resource consumption, sensitivity to data quality, and complex hyperparameter optimization. Future research could integrate geological background information or seismic data to further refine the network structure, improve model interpretability, and expand its applicability.
5. Conclusions
This study proposes a deep learning model integrating convolutional neural network (CNN), bidirectional long short-term memory (BiLSTM), and Transformer for predicting carbonate reservoir porosity. A comparative analysis with XGBoost, LSTM, BiLSTM, CNN-BiLSTM, and BiLSTM-Transformer models yields the following conclusions:
The strong heterogeneity of carbonate reservoirs results in wide-ranging and unevenly distributed logging data. To address this, the proposed approach employs data preprocessing, sensitivity parameter analysis, and feature extraction, effectively mitigating heterogeneity and enhancing data quality and model stability.
Ablation experiments demonstrate that CNN’s feature extraction capability and Transformer’s global dependency modeling significantly improve prediction performance. This hybrid model surpasses traditional machine learning methods and single deep learning architectures in terms of prediction accuracy, generalization ability, and stability.
Compared to existing studies, this model reduces RMSE and MAE by 0.016 and 0.014, respectively, while improving R² by 0.23, demonstrating superior predictive performance. Most previous studies have relied on either single deep learning models or traditional machine learning techniques, with limited exploration of hybrid frameworks combining CNN, BiLSTM, and Transformer. This study confirms the advantages of integrating local feature extraction, sequential modeling, and global dependency capturing, offering a novel approach for predicting porosity in heterogeneous carbonate reservoirs.
The primary contribution of this study is the introduction of an efficient prediction method tailored for highly heterogeneous reservoirs, providing new insights into accurate porosity evaluation. However, the model’s reliance on high-quality data and substantial computational resources presents challenges. Its applicability in regions with sparse or low-quality data remains to be further validated. Future research should explore the integration of prior geological knowledge, multi-scale data fusion, and seismic data to enhance model interpretability and applicability. Additionally, further studies should assess the model’s performance across different geological settings to establish its robustness and generalization capabilities.
Author Contributions
Conceptualization, S.L. (Shuiliang Luo) and S.T.; methodology, Y.Q.; software, Y.Q.; validation, J.R.; formal analysis, D.G.; investigation, Y.Q.; resources, Q.L.; data curation, S.L. (Sheng Li); writing—original draft preparation, Y.Q.; writing—review and editing, S.L. (Shuiliang Luo); visualization, Y.Q.; supervision, S.L. (Sheng Li); funding acquisition, D.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China Youth Fund Project ”Sedimentary evolution of Late Ordovician carbonate platform margin in Tazhong area and its response to paleostructure and sea level change (Project No.41502104)”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors upon request.
Conflicts of Interest
Authors Song Tang, Jifu Ruan were employed by PetroChina Southwest Oil & Gas Field Company. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AC | Acoustic time difference logging |
| CAL | Caliper logging |
| CNL | Compensated neutron logging |
| DEN | Density logging |
| GR | Gamma ray logging |
| RT | True formation resistivity logging |
| Rxo | Flushed zone formation resistivity logging |
| POR | Measured Porosity |
| XGBoost | Extreme gradient boosting |
| CNN | Convolutional neural network |
| LSTM | Long short-term neural network |
| BiLSTM | Bidirectional long short-term memory |
References
- Chen, Y. Automatic microseismic event picking via unsupervised machine learning. Geophys. J. Int. 2020, 222, 1750–1764. [Google Scholar] [CrossRef]
- Xie, J.; Chen, W.; Zhang, D.; Zu, S.; Chen, Y. Application of principal component analysis in weighted stacking of seismic data. Geosci. Remote Sens. Lett. 2017, 14, 1213–1217. [Google Scholar] [CrossRef]
- Zou, Y.; Chen, Y.; Deng, H. Gradient Boosting Decision Tree for Lithology Identification with Well Logs: A Case Study of Zhaoxian Gold Deposit, Shandong Peninsula, China. Nat. Resour. Res. 2021, 30, 3197–3217. [Google Scholar] [CrossRef]
- Zheng, D.; Hou, M.; Chen, A.; Zhong, H.; Qi, Z.; Ren, Q.; You, J.; Wang, H.; Ma, C. Application of machine learning in the identification of fluvial-lacustrine lithofacies from well logs: A case study from Sichuan Basin, China. J. Pet. Sci. Eng. 2022, 215, 110610. [Google Scholar] [CrossRef]
- Han, X.; Zhang, H.; Mao, X.; Xu, D.; Guo, H.; Jiang, J.; Luo, X.; Wang, Z.; Liu, Z.; Li, J.; et al. A method of gas porosity measurement for tight reservoirs based on mechanical analysis of core chamber. Chin. J. Geophys. 2021, 64, 289–297. [Google Scholar]
- Bom, C.R.; Valentín, M.B.; Fraga, B.M.O.; Campos, J.; Coutinho, B.; Dias, L.O.; Faria, E.L.; de Albuquerque, M.P.; de Albuquerque, M.P.; Correia, M.D.B. Bayesian deep networks for absolute permeability and porosity uncertainty prediction from image borehole logs from Brazilian carbonate reservoirs. J. Pet. Sci. Eng. 2021, 201, 108361. [Google Scholar] [CrossRef]
- Ao, Y.; Lu, W.; Hou, Q.; Jiang, B. Sequence-to-sequence borehole formation property prediction via multi-task deep networks with sparse core calibration. J. Pet. Sci. Eng. 2022, 208, 109637. [Google Scholar] [CrossRef]
- Chen, W.; Yang, L.; Zha, B.; Zhang, M.; Chen, Y. Deep learning reservoir porosity prediction based on multilayer long short-term memory network. Geophysics 2020, 85, 213–225. [Google Scholar] [CrossRef]
- Shao, R.; Xiao, L.; Liao, G.; Zhou, J.; Li, G. A reservoir parameters prediction method for geophysical logs based on transfer learning. Chin. J. Geophys. 2022, 65, 796–808. [Google Scholar]
- Muhammad, H.; Sudarmaji, S.; Suryo, P. An implementation of XGBoost algorithm to estimate effective porosity on well log data. J. Phys. Conf. Ser. 2023, 2498, 878–886. [Google Scholar] [CrossRef]
- Pan, S.; Zheng, Z.; Guo, Z.; Luo, H. An optimized XGBoost method for predicting reservoir porosity using petrophysical logs. J. Pet. Sci. Eng. 2022, 208, 9520. [Google Scholar] [CrossRef]
- Xu, H.; Xiao, H.; Cheng, G.; Liu, N.; Cui, J.; Shi, X.; Chen, S. Log interpretation of carbonate rocks based on petrophysical facies constraints. Geosciences 2024, 5, 100269. [Google Scholar] [CrossRef]
- Chen, H.; Wang, J.; Du, Y. Advances of Research Methods on Reservoir Heterogeneity. Geol. J. Chin. Univ. 2017, 23, 104–116. [Google Scholar]
- Shalabi, A.; Sepehrnoori, K.; Delshad, M. Mechanisms behind low salinity water injection in carbonate reservoirs. Fuel 2014, 121, 11–19. [Google Scholar] [CrossRef]
- Wood, D. Gamma-ray log derivative and volatility attributes assist facies characterization in clastic sedimentary sequences for formulaic and machine learning analysis. Adv. Geo Energy Res. 2022, 6, 69–85. [Google Scholar] [CrossRef]
- Liu, S.; Deng, B.; Jansa, L.; Li, Z.; Sun, W.; Wang, G.; Luo, Z.; Yong, Z. Multi-Stage Basin Development and Hydrocarbon Accumulations: A Review of the Sichuan Basin at Eastern Margin of the Tibetan Plateau. J. Sci. 2017, 29, 307–325. [Google Scholar] [CrossRef]
- Tan, X.; Zou, J.; Li, L.; Zhou, Y.; Luo, B. Study on sedimentary microfacies of epicontinental sea type platform in Jia 2 member of Moxi gas field. Pet. Sin. 2008, 2, 219–225. [Google Scholar]
- Lin, L.; Huang, H.; Zhang, P.; Yan, W.; Wei, H.; Liu, H.; Zhong, Z. A deep-learning framework for borehole formation properties prediction using heterogeneous well-logging data: A case study of a carbonate reservoir in the Gaoshiti-Moxi area, Sichuan Basin, China. Geophysics 2024, 89, 295–308. [Google Scholar] [CrossRef]
- Xu, P.; Zhou, H.; Liu, X.; Chen, L.; Xiong, C.; Lyu, F.; Zhou, J.; Liu, J. Permeability prediction using logging data in a heterogeneous carbonate reservoir: A new self-adaptive predictor. Geoenergy Sci. Eng. 2023, 224, 16–35. [Google Scholar] [CrossRef]
- Shi, J.; Zhao, X.; Zeng, L.; Zhang, Y.; Zhu, Z.; Dong, S. Identification of reservoir types in deep carbonates based on mixed-kernel machine learning using geophysical logging data. Pet. Sci. 2023, 21, 1632–1648. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for solving optimization problems. Knowl. Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Zhong, Z.; Carr, T.R. Application of mixed kernels function (MKF) based support vector regression model (SVR) for CO2—Reservoir oil minimum miscibility pressure prediction. Fuel 2016, 184, 590–603. [Google Scholar] [CrossRef]
- Zhong, Z.; Timothy, R.; Carr, T.R.; Wu, X.; Wang, G. Application of a convolutional neural network in permeability prediction: A case study in the Jacksonburg-Stringtown oil field, West Virginia, USA. Geophysics 2019, 84, 363–373. [Google Scholar] [CrossRef]
- Mousavi, S.; Ellsworth, W.; Zhu, W.; Chuang, L.; Beroza, G. Earthquake transformer—An attentive deep learning model for simultaneous earthquake detection and phase picking. Nat. Commun. 2020, 11, 39–52. [Google Scholar] [CrossRef]
- Seda, Y.; Bahadır, T. Efficiency of convolutional neural networks (CNN) based image classification for monitoring construction related activities: A case study on aggregate mining for concrete production. Case Stud. Constr. Mater. 2022, 17, e01372. [Google Scholar] [CrossRef]
- Li, H.; Qiu, B.; Zhang, Y.; Wu, B.; Wang, Y.; Liu, N.; Gao, J. CNN-Based Network Application for Petrophysical Parameter Inversion: Sensitivity Analysis of Input–Output Parameters and Network Architecture. Trans. Geosci. Remote Sens. 2022, 60, 4513113. [Google Scholar] [CrossRef]
- Liu, F.; Wang, X.; Liu, Z.; Tian, F.; Zhao, Y.; Pan, G.; Peng, C.; Liu, T.; Zhao, L.; Zhang, K.; et al. Identification of tight sandstone reservoir lithofacies based on CNN image recognition technology: A case study of Fuyu reservoir of Sanzhao Sag in Songliao Basin. Geoenergy Sci. Eng. 2023, 222, 211459. [Google Scholar] [CrossRef]
- Hochreiter, S. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zou, M.; Ninoslav, H.; Josip, Đ.; Kuzle, I.; Roberto, L.; Vincenzo, D. Bayesian CNN-BiLSTM and Vine-GMCM Based Probabilistic Forecasting of Hour-Ahead Wind Farm Power Outputs. Trans. Sustain. 2022, 13, 1169–1187. [Google Scholar] [CrossRef]
- Bi, J.; Chen, Z.; Yuan, H.; Zhang, J. Accurate water quality prediction with attention-based bidirectional LSTM and encoder–decoder. Syst. Appl. 2024, 238, 121807. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}