1. Introduction
Chinese governments at all levels annually promulgate substantial policy instruments that establish strategic frameworks for socioeconomic advancement and industrial governance [
1]. Of particular significance are sector-specific support policies, whose timely acquisition and accurate interpretation could substantially enhance corporate competitiveness and operational efficiency. Nevertheless, current policy implementation mechanisms present systemic challenges: Enterprises must systematically monitor multidimensional policy release channels while simultaneously processing voluminous regulatory texts for actionable insights. This dual-demand paradigm not only imposes significant organizational resource burdens but frequently leads to critical misalignments between policy eligibility criteria and corporate operational timelines, ultimately resulting in missed declaration opportunities across industries.
Some researchers have attempted to extract filing requirements through keyword extraction techniques. For instance, Xiao et al. [
2] developed the Text2Policy system in 2012 for automated policy extraction, while Zeng et al. [
3] proposed a sentence importance calculation method in 2017 to identify critical information from massive science and technology policy texts. These keyword-driven methods demonstrate inadequate performance in practical applications due to their negligence of interdependent semantic relationships within policy documents. Through systematic comparative analysis, we find that enterprise declaration requirements in policy texts are mainly presented in the form of events, e.g., policies about fund declaration usually require conditions such as unit type and creation time. For this key feature, we propose an innovative event extraction technique for accurately identifying policy filing requirements. Compared with the above method of extracting declaration conditions using keyword technology, it can better adapt to the structure of policy text and accurately extract the corresponding declaration conditions.
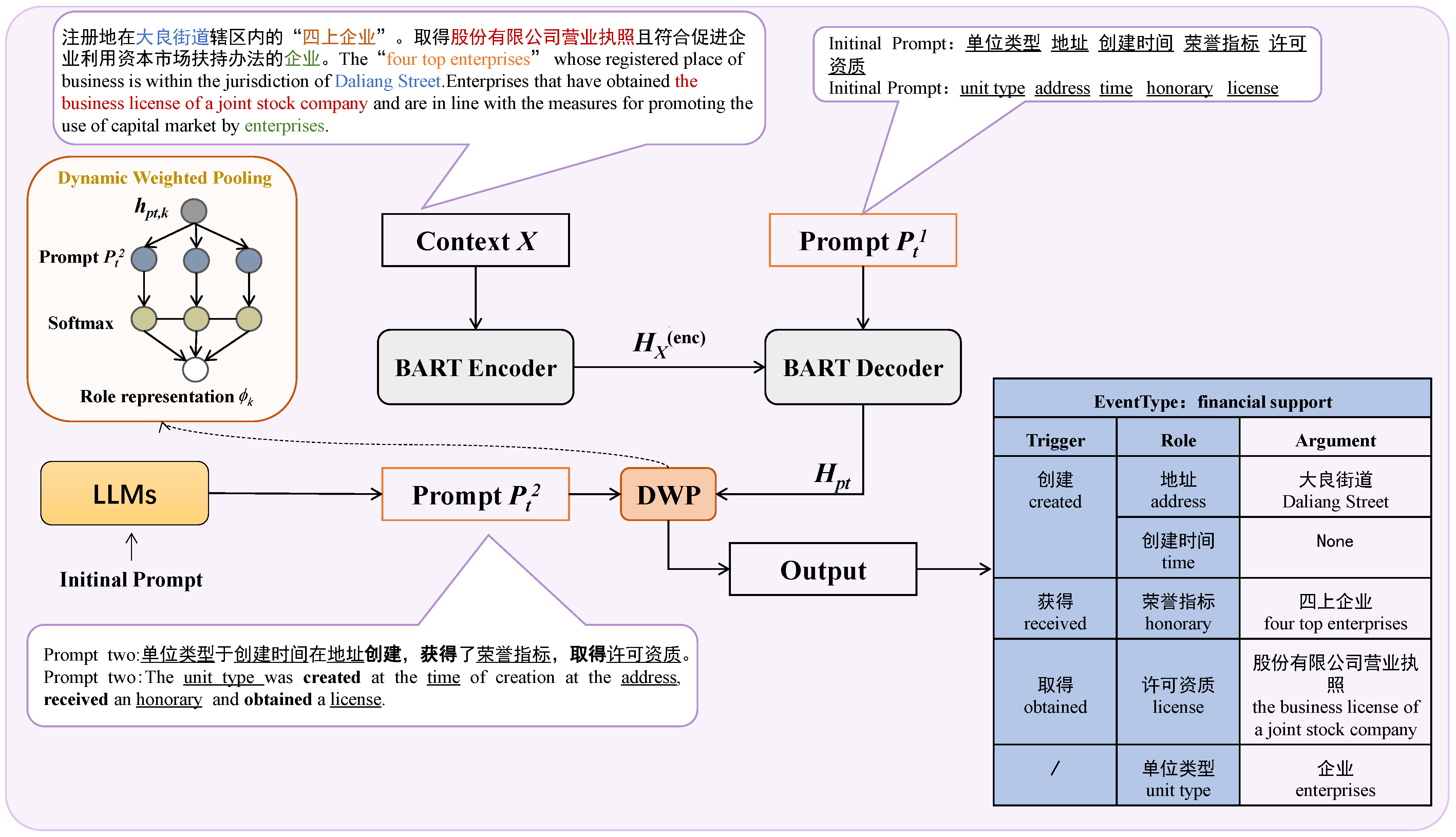
There are some challenges in applying event extraction to the policy domain: (1) As far as we know, this is the first attempt to apply event extraction technologies to the Chinese policy field. Therefore, there are no standard experimental data. (2) Policy text is mostly in the form of documents, while the text contains a large number of long and continuous arguments. As shown in
Figure 1: in the event “资金扶持 (financial support)”, the “单位类型 (unit type)” has a number of consecutive arguments in the text: “民营企业 (private enterprises)”, “股份有限公司 (joint-stock companies)”, “合作社 (cooperatives)” and “外资企业 (foreign-funded enterprises)”. In addition, the “服务业务 (services)”: “粮食收购, 储存, 运输, 贸易, 加工, 转化, 销售 (rain purchase, storage, transportation, trade, processing, conversion, or sales)” has a long span in example one. The text of “称号认定 (recognition of title)” shown in example two is relatively simple, containing only “地址 (address)”: “佛山市 (Foshan)”, “创建时间 (time)”: “ 3年以上 (more than 3 years)” and “单位类型 (unit type)”: “企业 (corporations)”.
In the field of event extraction, research in recent years has focused on prompt-based approaches. For example, in 2024, Peng et al. [
4] proposed a multi-template selection model to provide more information to the model to guide PLM for event extraction. In 2024, Li et al. [
5] used prompt-based modeling to obtain candidate triggers and parameters, then constructed heterogeneous event graphs to encode the structure within and between events. In 2024, Wu et al. [
6] formulated soft prompt tuning to maximize mutual information between prompt and other model parameters (or coded representations). According to previous research, the prompt-based approach enables specialized prompt design tailored to the context, effectively addressing the challenge of extracting long and contiguous arguments.
Therefore, this paper explores prompt-based learning for extraction and introduces the Two-step Prompt learning Event Extraction Framework (TPEE). It integrates all argument roles into the prompt, allowing role information to interact with PLMs and enabling joint selection of optimal argument spans via specific role queries. To leverage semantic associations between roles, a dynamic weighting mechanism is introduced to refine role representations based on the prompt. It is designed in this paper to solve the problem of long arguments extraction. The main contribution of this paper consists of three parts: (1) In this paper, the TPEE model is innovatively proposed, which can efficiently extract policy events by designing two-step prompts; (2) Capturing parameter relationships using a dynamic weighting mechanism; (3) In this paper, the method is validated on DEE-Policy and DuEE-Fin to demonstrate the effectiveness of TPEE.
The structure of the paper is as follows:
Section 2 reviews related work,
Section 3 provides a detailed description of the model,
Section 4 presents our experimental study, and
Section 5 offers a summary of the paper along with discussion of future research directions.
2. Related Work
Event extraction, a challenging task in Natural Language Processing (NLP), focuses on identifying event arguments that serve as key roles in an event and assigning them to their corresponding pre-defined event types. In the Chinese policy domain, the type of declared policy represents the type of event, and the conditions for applying the corresponding type of policy represent the thesis element of the event. This paper focuses on the events of “资金扶持 (financial support)” and “称号认定 (recognition of title)” in the context of Chinese policies. There are two types of event extraction methods: pipeline methods and joint models. The pipeline approach divides the event extraction task into multiple subtasks and processes them in a sequential manner. It has the disadvantage of error propagation between different subtasks. In order to solve such problems, joint models have been proposed for event extraction, which usually contain joint inference and joint modeling. Joint inference uses integrated learning to optimize a model through an overall objective function. The joint model treats the event structure as a dependency tree and then transforms the extraction task into a dependency tree prediction. It can recognize trigger words and extract arguments simultaneously. The inference and modeling share hidden layer parameters, which can avoid performance degradation due to error propagation.
From a technical point of view, event extraction methods can also be categorized into template and rule-based methods and deep learning-based methods. Early event extraction methods were based on template matching or regular expressions. The researchers used syntactic analysis and semantic constraints to identify events in sentences [
7]. In 1995, Kim et al. [
8] used semantic frames and phrase patterns to represent the extraction patterns of events. Over-incorporating semantic information from wordnets can approach human results in specific domains. However, the performance of template methods is highly dependent on the language and is poorly portable.
In recent years, most event extraction parties are based on deep learning. Deep learning methods are more generalized than traditional template- and rule-based methods. Early deep learning methods used various neural networks to extract events, such as convolutional neural network (CNN)-based models (Chen et al., 2015 [
9]), recurrent neural network (RNN)-based models (Nguyen et al., 2016 [
10]; Sha et al., 2018 [
11]), and graph neural network (GNN)-based models (Liu et al., 2018 [
12]; Dai et al., 2021 [
13]). Pre-trained models have been shown to be powerful in language comprehension and generation (Devlin et al., 2019 [
14]; Lewis et al., 2019 [
15]). Approaches based on pre-trained language models (PLMs-based) can be divided into two categories: fine-tuning and prompt-tuning.
Fine-tuning approaches aim to design multiple neural networks to migrate pre-trained language models to event extraction tasks. Based on the way the event extraction task is modeled, the existing fine-tuning work can be further classified into three groups:
(1) Classification-based approaches: In 2021, Xiangyu et al. [
16] proposed a neural architecture with a novel bi-directional entity-level recursive decoder that extracts the ontology by combining the ontology roles of contextual entities. In 2020, Ma et al. [
17] proposed a trigger-relative sequence with several types of representation of a trigger-aware sequence encoder.
(2) Methods based on machine reading comprehension: Naturally inducing linguistic knowledge from pre-trained language models. Wei et al. consider implicit interactions between roles by adding mutual constraints to the templates, while in 2021, Liu et al. [
18] utilized data enhancement to improve performance. However, such methods can only predict role-by-role, which is inefficient and usually leads to sub-optimal performance.
(3) Generation-based approaches: In 2021, Pao et al. [
19] proposed a pipeline model driven by a pre-trained model Text to Text Transfer Transformer (T5) [
20] that “translates” a sequence of plain text inputs into a sequence of event starting words and arguments labeled respectively. In 2021, Lu et al. [
21] used an end-to-end approach and the output has a complex tree structure. The prompt tuning approach aims at designing a template that provides useful cue information for extracting events for pre-trained language models. For example, in 2021, Li et al. [
22] created templates for each event type based on the event ontology definition and modeled the event extraction task as conditional text generation. The method obtains event thesis elements by comparing the designed template with the generated natural language text. In 2021, Hsu et al. [
23] improved the approach of Li et al. [
22] by replacing the non-semantic placeholders tokens in the design template with specific role label semantics. In 2021, Li and Liang. [
24] addressed generation tasks and introduced lightweight prefix tuning, which involved freezing model parameters while adjusting a sequence of task-specific vectors.
Prompt-based learning is a new paradigm emerging in the field of pre-trained language modeling (Liu et at., 2023 [
25]). Unlike the pre-training and fine-tuning paradigms, the cue-based approach transforms the downstream task into a form that more closely matches the model’s pre-training task. As prompt tuning better utilizes the a priori knowledge embedded in pre-trained language models, this new paradigm is starting to catch on in NLP tasks and achieve promising performance. For example, in 2020, Schick et al. [
26] transformed various categorization problems into a completion task by constructing prompt words associated with spaces and finding a mapping from a specific fill to a predicted category. In 2021, Cui et al. [
27] used candidate entity span and entity type tag words to obtain templates and recognize entities based on the pre-trained generative language model’s share of each template. In 2021, Hu et al. [
28] converted the text categorization task into a masked language modeling problem by predicting words populated in ‘[MASK]’ tokens, and proposed a knowledge-based verbal mapping of predicted words to tags. In 2022, Chen et al. [
29] treated the relation extraction problem as a gap-filling task and used the knowledge of relation label semantics to initialize virtual tag word embeddings for each relation label.
Additionally, event extraction has been used in many fields. In the justice field, Li et al. (2019) [
30]; Zhang et al. (2023) [
31] and Li et al. [
32] sought to use event extraction technology to obtain the key information of the case so as to accelerate the clearness of the dispute issues. Wan et al. (2023) [
33] and Yi et al. (2024) [
34] devised an integral framework for Chinese financial event extraction. To deal with the complexities of event extraction in the biomedical field, in 2024, Su et al. [
35] presented a novel tree-like structured perceptron designed for transition-based biomedical event extraction. In 2017, Wang et al. [
36] proposed a multiple distributed representation method for biomedical event extraction.
There are many methods of event extraction, each of which has its advantages and disadvantages. In practical use, it is necessary to balance various requirements according to specific domains, choose appropriate methods, and to solve some domain-specific problems. In our approach, we adopt a prompt-based method for detecting policy events. The event types are defined according to domain knowledge. The prompts are used to extract role characters, and a dynamic weighting mechanism is also employed to enhance information transfer between arguments.
3. Methodology
The main idea of the TPEE is to utilize multiple arguments and their interaction information by prompting pre-trained language models (PLMs) for the extraction of event arguments.
Figure 2 shows an overview of the model. A dynamic weighted pooling is introduced to better capture the importance differences of different roles in the context and improve the accuracy of event extraction. At the same time, the design of prompts is optimized by combining expert knowledge through LLMs. In the following sections, this paper will first introduce the design of the prompt, and then describe each component in turn.
3.1. Task Definition
In this paper, the Event Extraction (EE) task is formalized as a prompt-based spanning extraction problem on the dataset . Given an instance , where X denotes the context, e denotes the event type, and denotes the set of event-specific role types, the goal of this study is to extract a set of fragments . Each is a fragment of X denoting an argument associated with .
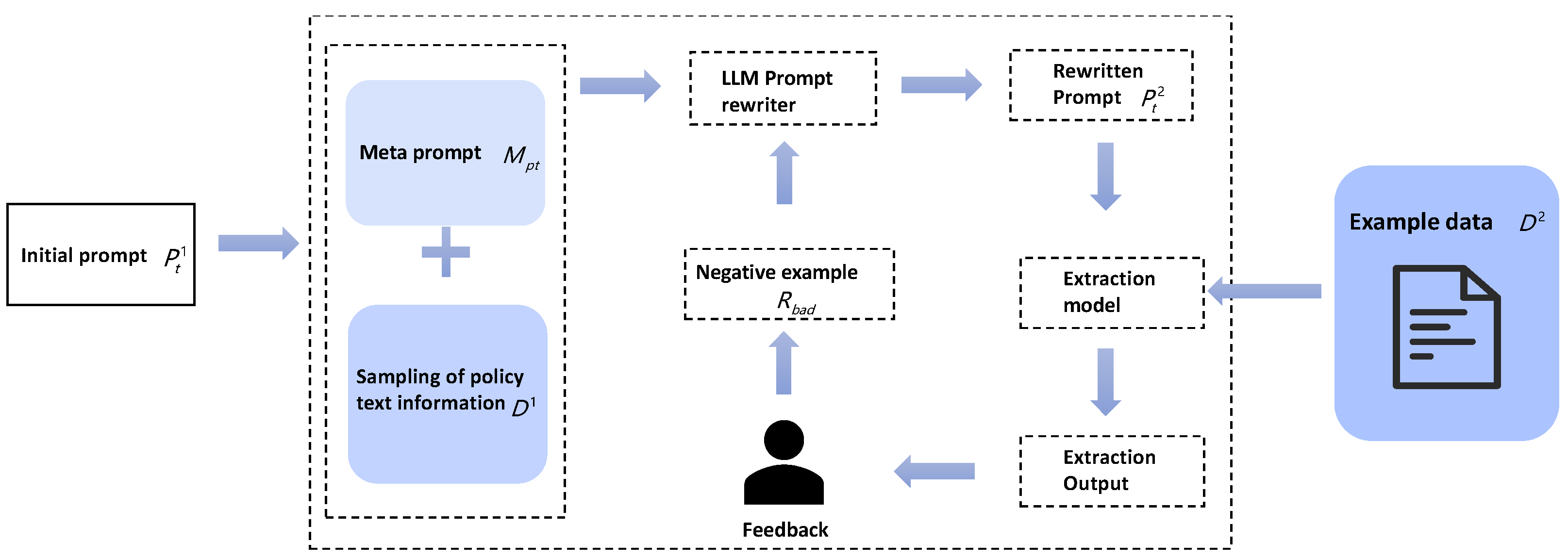
3.2. Design of the Prompt
LLMs and domain expert knowledge are combined to design the prompt. The domain expert first designs a preliminary prompt
based on the textual information as well as the event type and the role of the argument
. The
and a small amount of policy text are then provided to LLMs, which generates a prompt variant
based on the available information. The
is manually evaluated using a small amount of data and the extraction results are fed back to LLMs, which readjust the
based on the feedback. After going through several rounds of iterations, an efficient and applicable prompt can eventually be obtained. The flowchart for optimizing prompt design using LLMs is shown in
Figure 3, where the meta prompt is used to guide the model in optimizing the initial prompt based on the provided materials.
3.2.1. Initial Prompt
A set of prompts is designed for each event type
e (financial support and recognition of title) in the dataset
. Each prompt contains all the roles
corresponding to the event type. For the event type, the initial prompt
might be defined as follows:
where
f denotes that according to the contextual characteristics of the policy text (e.g., verb collocations and fixed phrases, e.g., for “许可资质 (licensing)”) the fixed collocation of “取得 …… (get ……)” is usually used, and since there are a few fixed triggers in the policy text, these verbs play the role of triggers in the prompts.
3.2.2. Meta Prompt
In this step, a sample of some policies is select in the dataset by following these rules: diversity, representativeness, and relevance. Then, the model is given a meta prompt
in conjunction with the policy samples, which tells the LLMs the role they play in the task, the questions they need to deal with, the rules they follow, and the form of the answer output. The basic structure is as follows:
where
is the description of the task and
denotes the sample policy text at the screening. The
can, in turn, be specified as follows:
where
denotes what the LLMs need to do.
denotes the manually designed primitive prompt.
denotes the set of ontological roles contained in event type
e.
S denotes the formatting requirements for the output of LLMs.
3.2.3. Prompt Rewriting and Feedback
The optimized prompt
is applied to the event extraction model TPEE to extract the dataset
. Then, it is manually screened for data that are poorly extracted from the results to make up the negative samples
:
The negative samples are fed back to the LLMs to guide its optimization prompt:
After continuous optimization, the prompt gradually integrates the usage structure and terminology of the policy text, which is more in line with the context of the policy text, improving the effectiveness of arguments extraction for some contiguous long texts in policy texts. Meanwhile, in our model, there are two places where the prompt is used: the first one utilizes the prompt to make the character fuse the information from the input text, and the second one utilizes the prompt in combination with the dynamic weighting mechanism to generate a more accurate representation of the character’s features. We optimize the prompt in these two places.
3.3. BART-Based Encoder and Decoder
The approach uses the BART model [
15] as the underlying framework, utilizing its included encoder and decoder modules (
and
) for context and prompt processing. The interaction between context and prompt is realized in the cross-attention mechanism of the decoder. This interaction generates role representations that incorporate contextual features.
The context is input to the BART-Encoder and the prompt is input to the BART-Decoder. In the cross-attention layer of the decoder module, the prompt interacts with the context.
where
represents the contextual text encoded representation and
is the decoded representation after the first prompt.
3.4. Dynamic Weighting Pooling
In TPEE, in order to utilize role-to-role dependencies, a dynamic weighting mechanism is introduced, which assigns a weight to each role by calculating the degree of association between each role and other roles, allowing us to focus on the role features that have dependencies on this role when generating role features. The specific steps are as follows:
1. Correlation calculation: The weight distribution of slots is generated by calculating the correlation score between the slot representation
and the overall representation of the prompt.
where
is the overall representation of second step prompt, obtained by pooling the mean of all slot representations.
2. Weight normalization: The correlation scores were normalized using the softmax function to obtain the weight distribution
.
3. Weighted pooling: The weighted slot representation is weighted and summed using the computed weights
to generate a weighted slot representation
.
After generating the character features
, the character trait span selector
is defined. For each role feature
, the start position selector
and the end position selector
are defined with the following formulas:
where
and
denote the linear transformation discretionary weights of the start and end positions, respectively.
are the shared learnable parameters for all role types. ∘ denotes element-by-element multiplication.
is the span selector for the
slot in the prompt. By the simple operation of using only one meta-head
, any number of role-spanning selectors can be generated, extracting relevant arguments from the context. A dynamic weighting mechanism is introduced in generating role profiles to more accurately capture the importance differences between slots. The process of generating role features is thus more refined, improving accuracy in the event extraction task.
3.5. Optimization
Given a context representation and a set of span selectors , the goal of each is to extract the corresponding span from . For an argument related to , where i and j are the start and end position indices in the context, the selector should output the result . When the corresponding slot is empty, the selector outputs an empty argument .
We compute the distribution of the start and end positions of each argument in the context:
where
and
denote the distribution of the start and end positions of each slot
k in the context text, and
L represents the length of the context text.
Then, we compute the probability of where the start/end position of the argument is located:
Finally, the loss function is defined and the context relevance weights are introduced into the loss function to enhance the focus on the more relevant parts of the context. The context relevance weights are considered when calculating the loss for each slot:
and the total loss is then the sum of the losses for all slots:
where denotes the context in the dataset and denotes the slot in prompt.
3.6. Inference
In the reasoning process, we define the set of candidate argument spans as
. The set contains all the spans that are less than the threshold
, and a special span
, which indicates that there is no thesis argument. The model extracts the arguments for each span selector
by traversing all candidate argument spans and scoring them with the scoring formula:
For slots, the final predicted span is determined by the following equation:
Since each slot in the prompt predicts at most one span; this strategy effectively avoids tedious threshold tuning.
4. Experiment Results
This section explains the experimental results in detail. The experiment is conducted on two datasets: the dataset for event extraction of policy, DEE-Policy, and the public finance dataset, DuEE-Fin. We first outline the implementation details, including dataset introduction, model selection, and hyperparameter settings. We then present the results of the experiments, including baseline comparisons and the main results for each dataset, the ablation experiments, and the performance of the model under different scaled datasets. In addition, we explore the importance of the model’s two prompts and analyze typical cases.
4.1. Datasets and Settings
Event extraction datasets serve as the cornerstone for conducting event extraction research. In the present study, due to the absence of publicly available datasets in the policy domain, it was necessary to first collect data. A total of 2300 policy documents, covering the period from 2023 to 2024, were gathered from various enterprise-friendly policy websites. The average length of these policy documents is 60 characters. These documents were available in diverse formats, including PDF files, Word documents, and web content. The initial step involved converting and parsing the collected policy documents into a processable plain text format, followed by data cleaning to remove blank lines, special characters, and extra spaces from the text.
Subsequently, we chose the large language model ChatGPT 3.5 to extract passages containing declarative conditions. A tailored prompt was designed to enhance the model’s performance in this extraction task. The model was then applied to each document, extracting relevant passages with declaration conditions. Finally, the extracted results were stored in a specified database or file for further processing and analysis.
We developed the appropriate arguments and argument roles based on the textual content of the policy, and identified a total of two event types: “资金扶持 (financial support)” and “称号认定 (recognition of title)”. The schema corresponding to the event type is shown in the
Table 1. Finally, this paper constructs a policy event extraction dataset (DEE-Policy) stored in JSON format.
For the preprocessed dataset, a semi-supervised labeling scheme was employed. Semi-automatic labeling was achieved by using a small portion of manually labeled data combined with unlabeled data to train the model. Once the labeling process was completed, the labeled data were randomly shuffled and split into training, validation, and test sets in a ratio of 7:1.5:1.5 for model evaluation. Eventually, we obtained a complete Chinese policy dataset DEE-Policy (
https://github.com/ghy0816/DEE-Policy/tree/main, 8 March 2025), in which “资金扶持 (financial support)” accounted for
with nine argument roles, and “称号认定 (recognition of title)” accounted for
with five argument roles.
In addition to datasets in the policy domain, this paper also conducts experiments on the publicly available financial dataset DuEE-Fin [
37] (
https://aistudio.baidu.com, 16 January 2023). DuEE-Fin is the latest chapter-level event extraction dataset released by Baidu in the financial domain. DuEE-Fin covers a total of 13 event types and 92 argument roles related to financial activities, such as “质押 (Equity Pledge)” and “股份回购 (Equity Repurchase)”.
Table 2 shows the distribution of all event types, in which “股份回购 (Equity Repurchase)” accounts for the largest proportion (
). And each event type has seven argument roles to be filled on average. We preprocessed the dataset beforehand to obtain two benchmark datasets, DEE-Policy and DuEE-Fin. The statistical results of the benchmark datasets are shown in
Table 3.
In the implementation, the maximum length for both encoded and decoded sentences was set to 1024 tokens, while the model was configured to extract text with a maximum length of 52 tokens. Additionally the batch size was set to 4 and the Adma optimizer with a learning rate of
was used during training. More detailed settings for the hyperparameters can be found in
Table 4.
Evaluation of indicators: There are two indicators which are used to evaluate the event extraction performance of the method: 1. Argument Identification: The model is required to recognize all the arguments from the text without evaluating their specific roles. 2. Argument Classification: The model is required to not only recognize the arguments in the text, but also to correctly categorize these arguments into specific roles. As in previous work, all methods were evaluated using standardized micro-average precision (P), recall (R), and F1-score (F1).
4.2. Baseline
In this paper, five baseline models are selected for comparison, which are as follows: rbt3 [
38], BART-Gen [
22], BertMRC [
39], GPLinker [
40] and PAIE [
41].
BART-Gen: A sequence-to-sequence conditional generation model, which, unlike methods for recognizing the span of an argument, generates the corresponding content based on the prompt.
BertMRC: Think of the event extraction process as a reading comprehension task, where appropriate answers are selected from the original text based on a question template.
PAIE: Models are extracted from hand-designed prompts, and the case where a unified argument role contains multiple arguments is addressed by the design of the prompt.
Rbt3: Baidu Thousand Words official baseline, using the Rbt3 model for event extraction.
GPLinker: Based on the relational extraction model GPLinker, a simpler but relatively complete event co-abstraction model is designed in conjunction with full subgraph search, which unifies scenarios with and without trigger words by treating the trigger word as an argument role of the event as well.
4.3. Main Results
Table 5 shows the experimental results of the proposed TPEE and baseline model. It can be seen that among the baseline models, the prompt-based model performs better than all the others overall. One of the classification-based models, the PAIE model, performed the best in the argument recognition task with an F1-score of
. The TPEE achieves a higher F1-score of
in the argument recognition task, realizing an absolute improvement of
. In addition, the TPEE performs equally well in the argument categorization task, obtaining a
F1-score, which is
higher than the
of the PAIE model. This shows that the prompt design method in this paper is more consistent with the characteristics of the policy text and improves the overall extraction effect. In addition, on the test set, by comparing the extraction results of TPEE with those of PAIE, it can be found that TPEE is superior to PAIE in extracting long and continuous parameters. Details are described in the case study.
Table 6 presents the informative argument extraction results for various models on the Duee-fin test set. It can be seen that the PAIE model performs strongly in the Arg Identification task, obtaining an F1-score of
, while the TPEE further improves on this task, reaching an F1-score of
, achieving an absolute improvement of
. In the Arg Classification task, the TPEE also performs well, achieving an F1-score of
, which outperforms the
of the PAIE model, an improvement of
. Compared to other baseline models, such as BertMRC and BART-Gen, the TPEE demonstrates more significant advantages in both the argument recognition and classification tasks, especially in the classification task, where it outperforms the Rbt3 model with
and the BertMRC model with
. These results suggest that event extraction in the financial domain is also more suitable for the use of a prompt-based approach, and that our prompt design approach has not only made enhancements in the policy domain, but also advances in the financial domain, with strong migratory properties.
On the policy and financial datasets, the prompt-based approach is significantly superior to other approaches in terms of F1 values. This is mainly due to the fact that policy data and financial data are usually highly structured and rules-based texts, often containing clear terms, conditions, regulations, etc., with a high degree of logic and consistency of content. The prompt-based approach guides the model through carefully designed instructions or prompts to extract information from these explicit rules, greatly reducing ambiguity and error. Compared with traditional model training methods, the prompt-based approach can make better use of domain knowledge.
4.4. Ablation Performance
4.4.1. Effects of Dynamic Weighting
In the TPEE method proposed in this paper, a dynamic weighting mechanism is introduced to enhance the ability to exchange information between parameters. To evaluate the role of different components in the model, an ablation experiment was performed to compare two ablation modes: (1) Removal of dynamic weighted pooling. (2) Mean pooling. The latter mode treats all token pairs in the prompt as the same contribution that the role generates. The experimental results are shown in
Table 7.
As can be seen from
Table 7, the F1 value on each dataset decreases without the weighted pooling mechanism. Compared with dynamic weighted pooling, average pooling reduces the F1 values on the policy and DuEE-Fin datasets by
and
, respectively. This indicates that the dynamic weighted pooling mechanism can describe the function of parameters more accurately. In addition, compared with the prompt-based approach, the effect of the reading comprehension-based approach is significantly lower than the prompt-based approach. This suggests that the prompt-based approach is more competitive in argument extraction. Meanwhile, we compare the results and find that the effect for long and continuous argument extraction is not very good when the dynamic weighting mechanism is not used, which shows that the dynamic weighting mechanism can well solve the challenge of long and continuous argument extraction in policy text.
4.4.2. Influence of Prompt in Different Position
The TPEE method proposed in this paper includes two-prompt learning. The first is to use the prompt to interact with the input text in the BART decoder so that the slots in the prompt used to extract characters contain text information. The second is in the dynamic weighted pooling phase, where information for each role is fused with each token in the prompt, allowing the model to focus on information for the other roles, which is conducive to extracting it during the extraction phase. In order to explore the influence of these two prompts on parameter extraction, this paper designed a set of ablation experiments, and the results are shown in
Table 8.
In order to verify the effect of the two-step prompt, four sets of experiments were designed. Prompt_all_detailed is the fine design for both prompts. Prompt_one_detailed is the fine design for the first prompt. Prompt_two_detailed is the fine design for the second prompt, and Prompt_all means no fine design for both prompts. From the experimental results, it is can be seen that when fine-grained design is applied to both prompts, the F1 value of the argument classification on the two datasets (DEE-Policy, Duee-fin) reaches the highest value, which is and , respectively, and rises by , and compared to the F1 value of both prompts with no fine-grained design. In contrast, when only the second location of the prompt was fine-tuned, it yielded F1 values of and on the two datasets, which were only and lower than prompt_all_detailed. In contrast, the F1 values for the fine design of only the first prompt decreased by and . It shows that the design of both prompts has an effect on the overall extraction effect of the model, but the effect of the second prompt design on the extraction effect is more obvious compared to the first one.
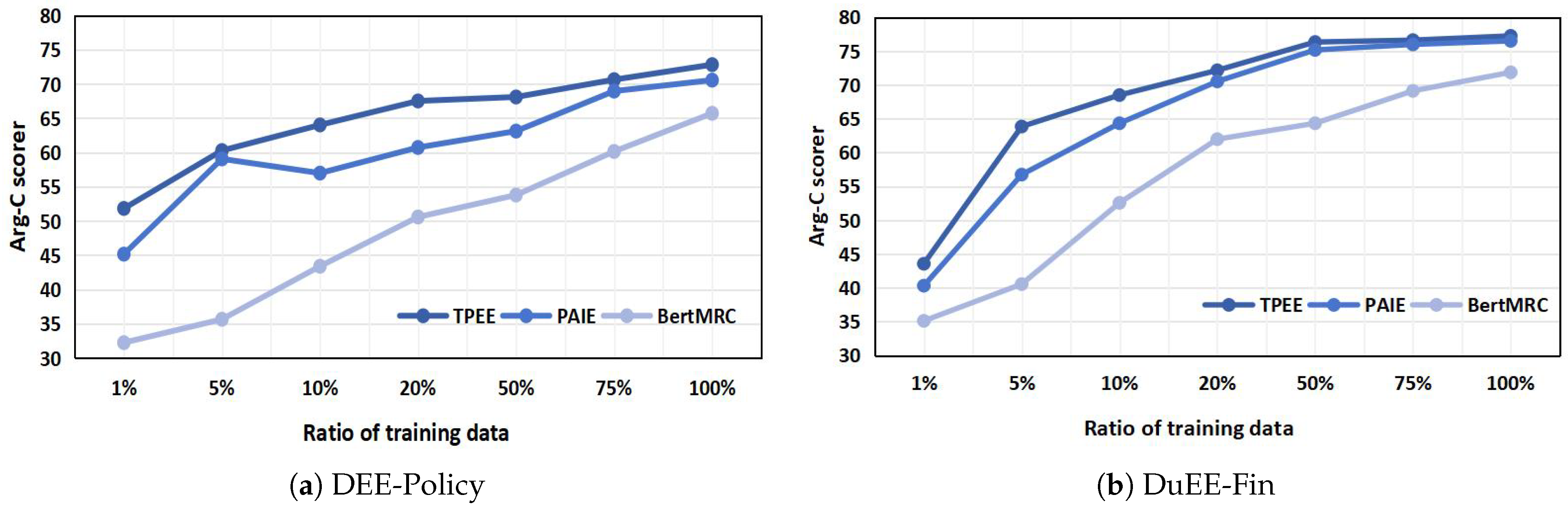
4.5. Influence of Dataset Size
In this paper, the influence of dataset size on the experimental results is further analyzed. Specifically, we randomly and uniformly sampled
,
,
,
,
,
, and
of the training data proportionally for model training, and the results are shown in
Figure 4. The figure shows how well our model and the two state-of-the-art methods perform in low-resource and high-resource scenarios.
According to
Figure 4, a clear upward trend in the F1 value is observed with increasing training data. Compared to the reading comprehension-based approach, the prompt-based approach significantly improves the performance of argument role categorization in low-resource data scenarios. This result suggests that the prompt-based approach makes better use of the rich knowledge in PLMs. And the TPEE achieves better performance in both high- and low-resource data scenarios due to better utilization of the connections between different roles. On the policy dataset, the PAIE model shows a brief increase in F1 values when using
of the data, but decreases when the data are expanded to
. This phenomenon reflects the model’s ability to learn useful information from more samples initially as the amount of training data increases, thus improving performance. However, data in the policy domain is usually presented in the form of documents, and as the data volume increases further, the PAIE model becomes less effective in processing long texts, resulting in a decrease in the F1 value. This also indicates that the TPEE has better performance compared to the PAIE model when dealing with a large amount of long text.
4.6. Case Study
In order to prove the effectiveness of the TPEE method for long-term continuous parameter extraction, this paper extracts several data items from the test set of policy data and compares their extraction effects on different models (TPEE, PAIE, BertMRC).
Table 9 shows the extraction results for events of the “资金扶持 (funding support)”, based on the reading comprehension method BertMRC, which can only recognize simple arguments, such as simple “地址 (address)” and “创建时间 (time)”, but not for “服务业务 (services)” and “财务状况 (financial)”, which are longer spanning arguments. There are omissions and errors in the extraction of the long and continuous argument “单位类型 (unit type)” in the text. The ineligible “单位类型 (unit type)”: “国有企业 (owned enterprises)” has been mistakenly extracted. This suggests that the reading comprehension-based approach has problems in understanding the policy text. For the prompt-based approach, PAIE accurately identified “财务状况 (financial)”, but still did not accurately identify “服务业务 (services)”, which is a much longer span of text. At the same time, there are still cases of omission of contiguous “单位类型 (unit type)”, but there are no cases of misidentification. This suggests that the prompt-based approach is more accurate in understanding policy semantics compared to the reading comprehension-based approach. TPEE was able to accurately extract arguments other than “服务业务 (service)” and did not miss or misrecognize the long and consecutive argument “单位类型 (unit type)”. For “服务业务 (service)”, the TPEE model only recognizes the part of “粮食收购, 储存, 运输, 贸易, 加工, 转化, 销售 (grain purchase, storage, transportation, trade, processing, transformation and sale)”, which shows that the TPEE model is still insufficient for extracting long arguments. This shows that the TPEE can better adapt to policy texts and solve the problem of long and contiguous argument extraction.
Table 10 shows the extraction results for events of the “称号认定 (recognition of title)” type. For the simpler “地址 (address)” and “单位类型 (unit)” type, all three models are able to extract them well, but for the more complex service operations, the PAIE model has omissions, only “智能建造 (intelligent construction)” being extracted, while BertMRC recognizes them completely. It follows that our model is competitive for the extraction of complex arguments, especially continuous multi-round elements.
From the two examples, it can be seen that TPEE still has deficiencies in the extraction of the complex event type “资金扶持 (financial support)”, in which the long thesis elements cannot be completely extracted. For the simpler “称号认定 (recognition of title)”, the TPEE model can have a good extraction result compared with other models.
4.7. Parameter Sensitivity Analysis
We conducted sensitivity experiments on the DEE-Policy dataset for parameters such as batch size, learning rate, and steps, and the results are shown in the
Table 11. The experimental results show that different hyperparameters have a large impact on the model performance as follows:
The learning rate is an important factor affecting the model. When the learning rate is and , the F1 values are similar: and , respectively. When the learning rate is , the performance drops to , which is the worst performance among all configurations. Therefore, the appropriate choice of learning rate is crucial for the convergence and final performance of the model training.
The batch size is another important factor affecting performance. The F1 value of the batch size fluctuates up to 4.47 percentage points. When the batch size is 4, the average performance of the model is , which is the optimal configuration; when the batch size is 3, the average performance is only . This indicates that increasing the batch size appropriately can significantly improve the training of the model.
For the number of steps, when the number of steps is greater than 10,000, the effect of parameter tuning on the model performance is relatively stable, and the performance is close at different numbers of steps, remaining at about 72 percent. When the number of steps decreases, the performance of the model decreases, where the model has the smallest F1 value when the number of steps is equal to 5000 with , which is 4.69 percentage points different from the best.
In summary, the learning rate, batch size, and step size are the main hyperparameters affecting the performance of the current model, and appropriate adjustments can significantly improve the model results.
5. Conclusions
In this paper, an event extraction model TPEE based on a two-step prompt is proposed. The model designs the second step prompt based on the LLMs and the initial prompt to precisely extract arguments from the input text. In addition, a dynamic weighting method is also used to enhance the interaction between the first extraction results and the elements of the precise prompt, and finally, improve the accuracy of the policy field event extraction. Other than that. a complete policy domain dataset DEE-Policy is constructed for future event extraction efforts in the policy domain.
Experimental results on the Chinese policy domain dataset show that the TPEE framework proposed in this paper is superior to the baseline model. It is worth mentioning that TPEE also achieves good results on publicly available datasets in the financial field with similar text structures, which indicates that the method in this paper has strong generalization.
In addition, through case analysis, it can be found that in the identification process, some arguments that are far from other argument elements are often not easy to identify. In the future, we plan to introduce domain vocabulary information and paragraph abstract semantic information to overcome the difficulty of domain vocabulary recognition and fragmentation of argument elements.




{kind=link}
{kind=link}
{kind=link}
{kind=link}