

A Real-Time Fabric Defect Detection Method Based on Improved YOLOv8
 , ,
, ,
Abstract
1. Introduction
2. Related Work
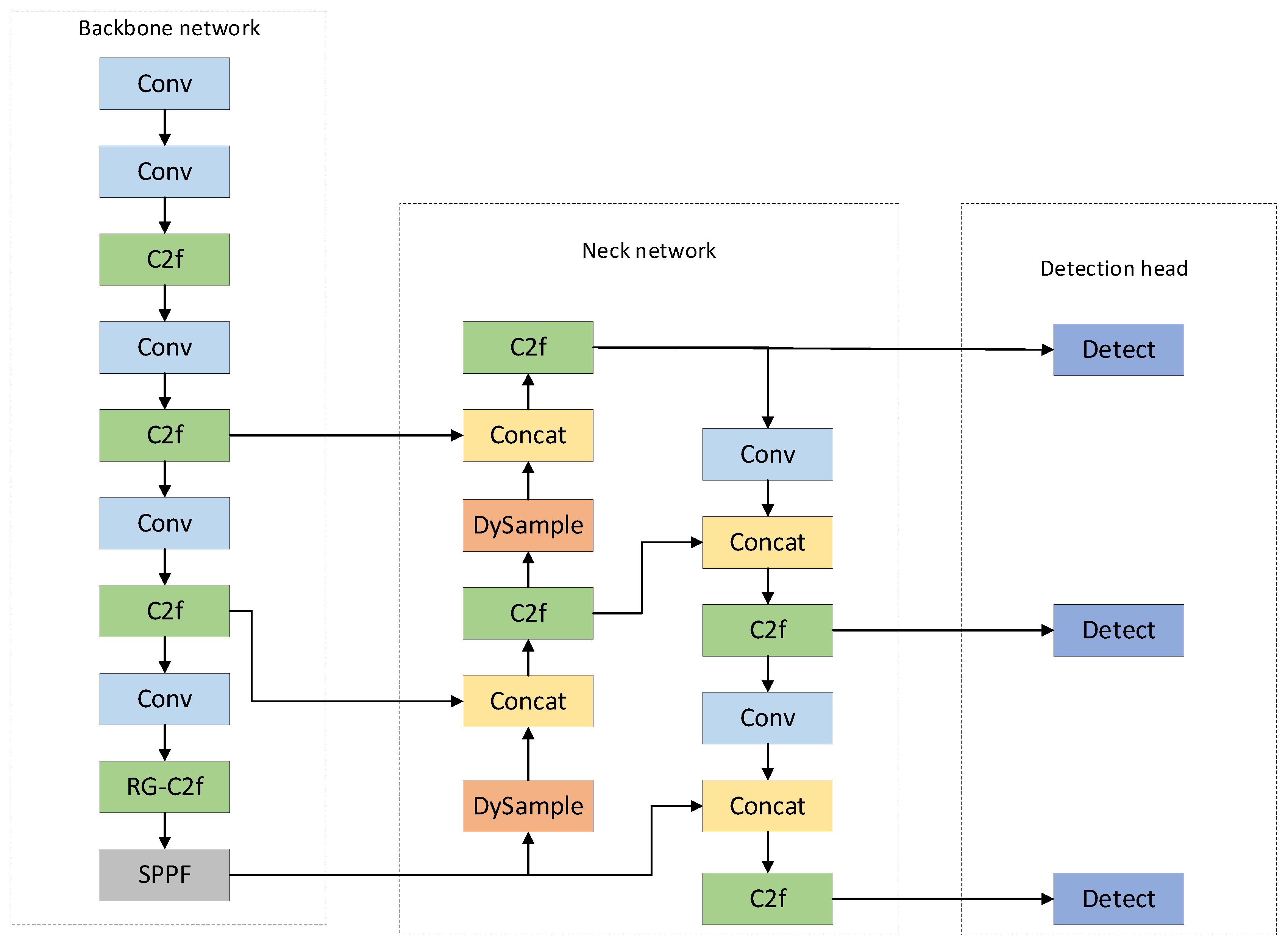
3. Methods
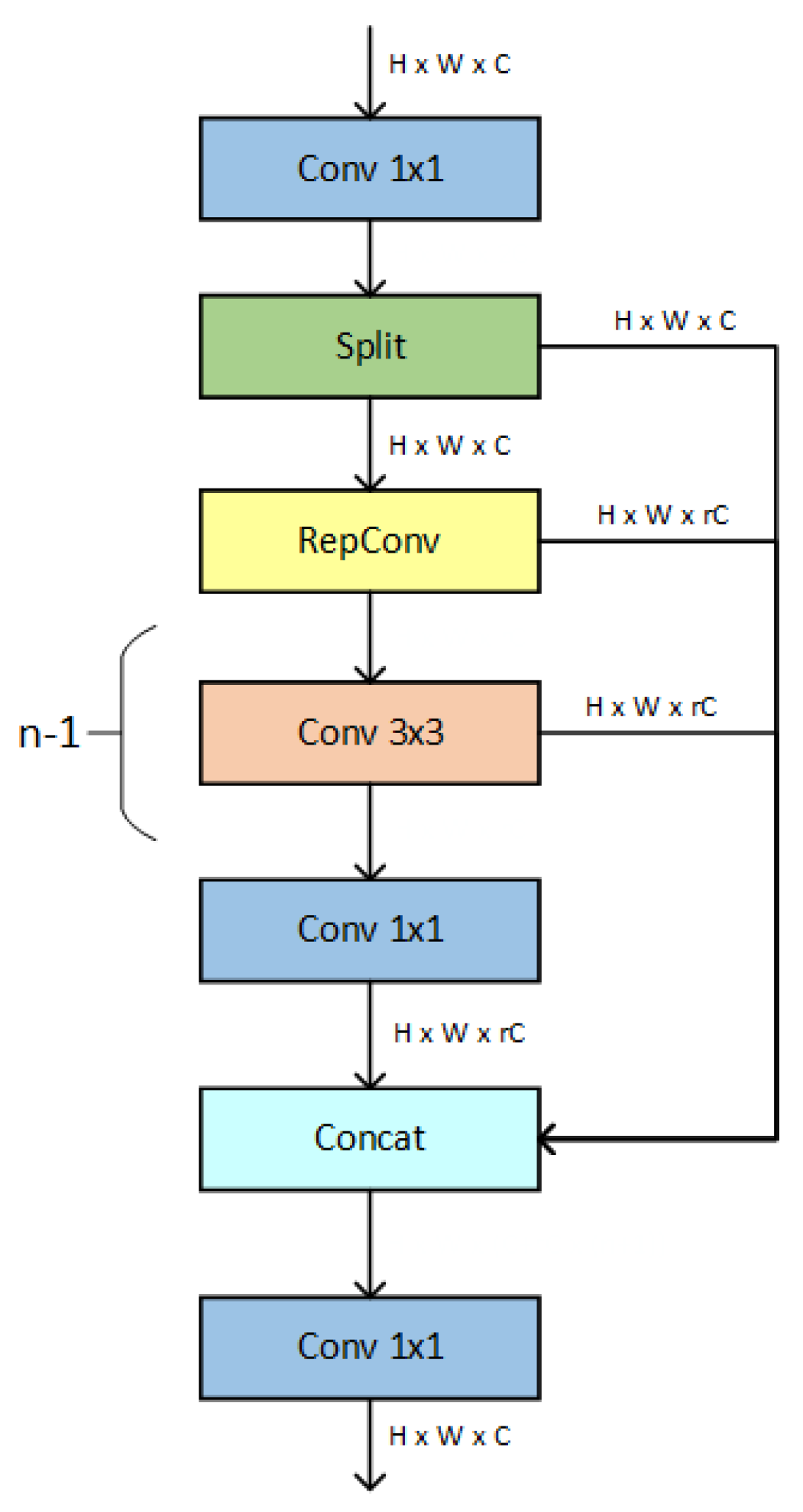
3.1. RG-C2f Module
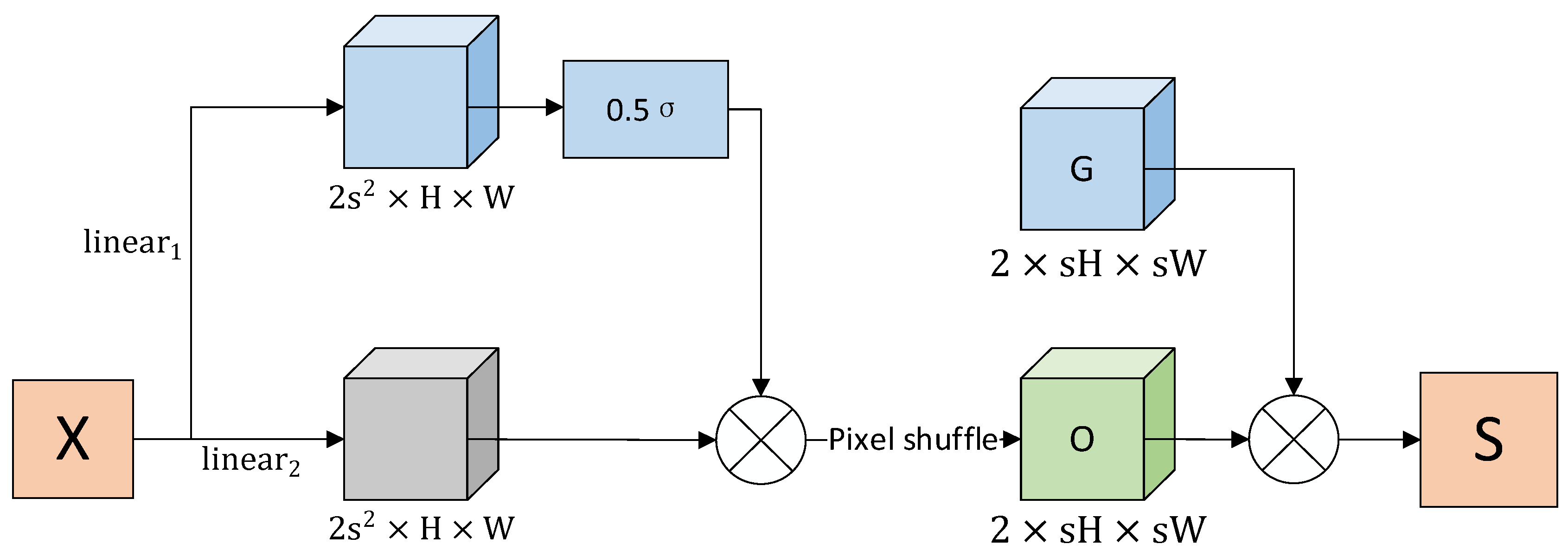
3.2. DySample Upsampling Operator
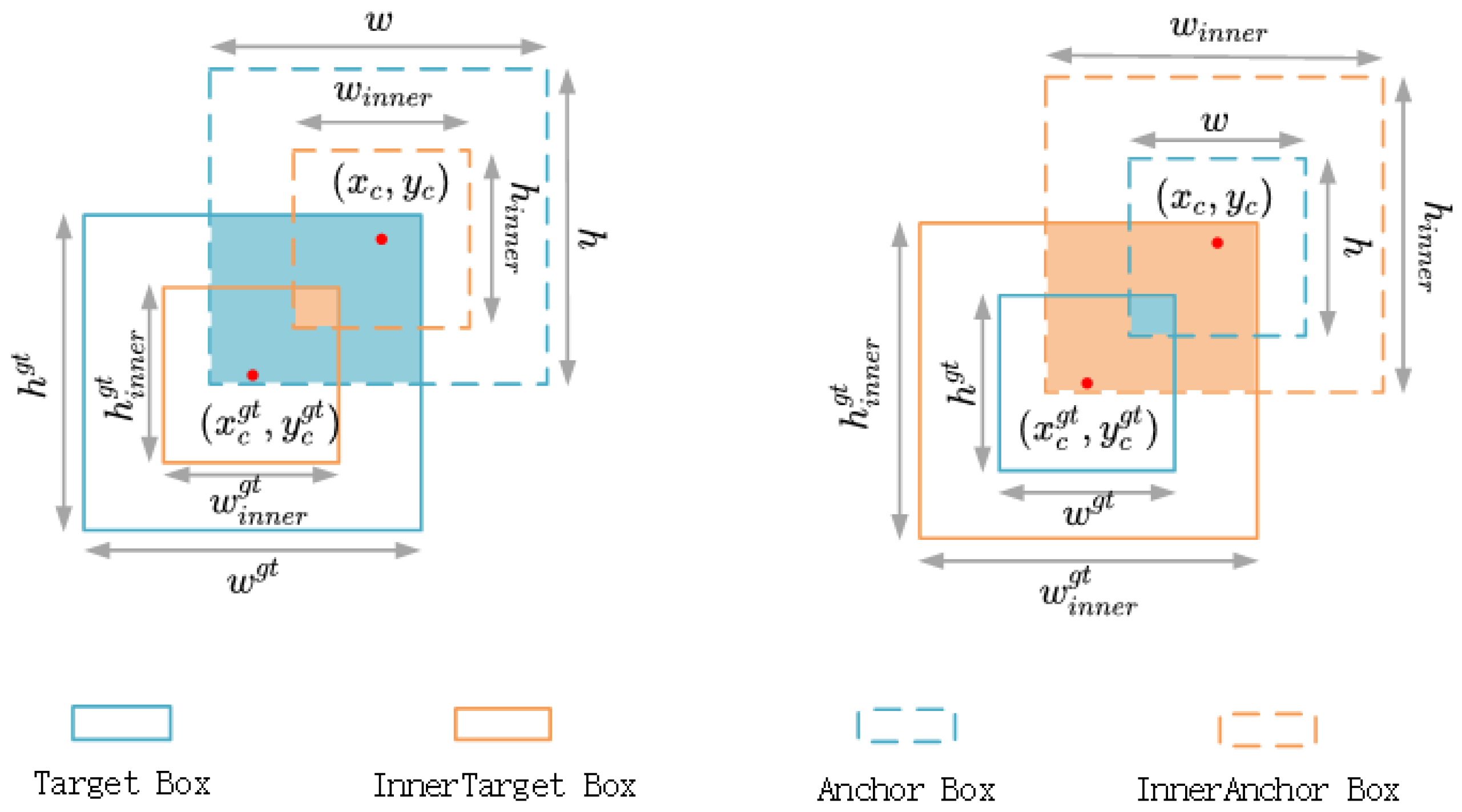
3.3. Inner-WIoU Loss Function
4. Experimental Results and Analysis
4.1. Datasets
4.1.1. TILDA Dataset
4.1.2. Tianchi Dataset
4.2. Experimental Environment
4.3. Evaluation Metrics
4.4. Ablation Experiments
4.5. Comparison Experiment
4.5.1. Comparative Analysis of Different Modules
4.5.2. Comparative Analysis of Different Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liangtai, F.; Zijing, D.; Wenbo, Z.; Xinyuan, W.; Mimi, Z.; Lingjie, Y.; Runjun, S. Research Progress on Fabric Surface Defect Detection. Wool Text. J. 2023, 4, 94–101. [Google Scholar] [CrossRef]
- Chandurkar, P.; Kakde, M.; Patil, C.; Shirpur, D. Minimization of Defects in Knitted Fabric. Int. J. Text Eng. Process 2016, 2, 13–18. [Google Scholar]
- Liu, Q.; Wang, C.; Li, Y.; Gao, M.; Li, J. A Fabric Defect Detection Method Based on Deep Learning. IEEE Access 2022, 10, 4284–4296. [Google Scholar] [CrossRef]
- Yang, H.; Jing, J.; Wang, Z.; Huang, Y.; Song, S. YOLOV4-TinyS: A New Convolutional Neural Architecture for Real-Time Detection of Fabric Defects in Edge Devices. Text. Res. J. 2024, 94, 49–68. [Google Scholar] [CrossRef]
- Prunella, M.; Scardigno, R.M.; Buongiorno, D.; Brunetti, A.; Longo, N.; Carli, R.; Dotoli, M.; Bevilacqua, V. Deep Learning for Automatic Vision-Based Recognition of Industrial Surface Defects: A Survey. IEEE Access 2023, 11, 43370–43423. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Y. A Real-Time and Accurate Convolutional Neural Network for Fabric Defect Detection. Complex Intell. Syst. 2024. [CrossRef]
- Guo, Y.; Kang, X.; Li, J.; Yang, Y. Automatic Fabric Defect Detection Method Using AC-YOLOv5. Electronics 2023, 12, 2950. [Google Scholar] [CrossRef]
- Zhang, H.; Li, S.; Miao, Q.; Fang, R.; Xue, S.; Hu, Q.; Hu, J.; Chan, S. Surface Defect Detection of Hot Rolled Steel Based on Multi-Scale Feature Fusion and Attention Mechanism Residual Block. Sci. Rep. 2024, 14, 7671. [Google Scholar] [CrossRef] [PubMed]
- Xiao, G.; Hou, S.; Zhou, H. PCB Defect Detection Algorithm Based on CDI-YOLO. Sci. Rep. 2024, 14, 7351. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved Faster R-CNN for Fabric Defect Detection Based on Gabor Filter with Genetic Algorithm Optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]
- Wang, J.; Yang, J.; Lu, G.; Zhang, C.; Yu, Z.; Yang, Y. Adaptively Fused Attention Module for the Fabric Defect Detection. Adv. Intell. Syst. 2023, 5, 2200151. [Google Scholar] [CrossRef]
- Weihong, L.; Min, L.; Ping, Z.; Shuqin, C.; Xiaoyun, Y. Improved Fabric Defect Detection Algorithm Based on YOLOv8n. Cotton Text. Technol. 2024, 52, 19–25. [Google Scholar]
- Zhang, Y.; Zhang, H.; Huang, Q.; Han, Y.; Zhao, M. DsP-YOLO: An Anchor-Free Network with DsPAN for Small Object Detection of Multiscale Defects. Expert Syst. Appl. 2024, 241, 122669. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Xiong, X.; Kuang, J.; Xiang, S. A Lightweight and Efficient Multi-Type Defect Detection Method for Transmission Lines Based on DCP-YOLOv8. Sensors 2024, 24, 4491. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Lv, H.; Chen, W.; Wang, Y. Research on Defect Detection for Overhead Transmission Lines Based on the ABG-YOLOv8n Model. Energies 2024, 17, 5974. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6027–6037. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–28 June 2018; pp. 6154–6162. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 2778–2788. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv8 | RG-C2f | DySample | Inner-WIoU | P | R | mAP | FLOPs | FPS | Params |
|---|---|---|---|---|---|---|---|---|---|
| √ | 0.743 | 0.750 | 0.756 | 8.1G | 103.5 | 3,006,428 | |||
| √ | √ | 0.727 | 0.725 | 0.761 | 7.9G | 119.3 | 2,801,431 | ||
| √ | √ | 0.751 | 0.716 | 0.763 | 8.1G | 95.4 | 3,018,780 | ||
| √ | √ | 0.783 | 0.740 | 0.772 | 8.1G | 104.0 | 3,006,428 | ||
| √ | √ | √ | 0.844 | 0.710 | 0.788 | 7.9G | 115.5 | 2,915,341 | |
| √ | √ | √ | √ | 0.824 | 0.744 | 0.82 | 7.9G | 114.7 | 2,915,341 |
| Name | All_Time | Mean_Time | FPS | FLOPs | Params |
|---|---|---|---|---|---|
| C3 | 4.64141 | 0.00232 | 430.9031312336256 | 4.832G | 295,680 |
| ELAN | 6.09753 | 0.00305 | 328.00192876805573 | 8.053G | 492,288 |
| C2f | 5.76367 | 0.00288 | 347.0011744981227 | 7.516G | 459,520 |
| RG-C2f | 4.15235 | 0.00208 | 481.6544469393704 | 3.565G | 217,920 |
| Models | P | R | mAP | FPS |
|---|---|---|---|---|
| Faster RCNN | 0.75 | 0.65 | 0.71 | 25.0 |
| Cascade RCNN | 0.79 | 0.72 | 0.78 | 35.1 |
| TPH-YOLOv5 | 0.738 | 0.68 | 0.725 | 108.5 |
| YOLOv5 | 0.722 | 0.604 | 0.686 | 118.0 |
| YOLOv8 | 0.743 | 0.75 | 0.756 | 103.5 |
| ours | 0.824 | 0.744 | 0.82 | 110.2 |
| Models | P | R | mAP | FPS |
|---|---|---|---|---|
| Faster RCNN | 0.485 | 0.35 | 0.355 | 25.0 |
| Cascade RCNN | 0.52 | 0.433 | 0.421 | 35.1 |
| TPH-YOLOv5 | 0.511 | 0.42 | 0.378 | 108.5 |
| YOLOv5 | 0.49 | 0.38 | 0.325 | 118.0 |
| YOLOv8 | 0.516 | 0.416 | 0.427 | 103.5 |
| ours | 0.534 | 0.459 | 0.442 | 110.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.; Liu, X.; Nan, K.; Wang, S.; Wang, T.; Zhang, Z.; Zhang, X. A Real-Time Fabric Defect Detection Method Based on Improved YOLOv8. Appl. Sci. 2025, 15, 3228. https://doi.org/10.3390/app15063228
Jin Y, Liu X, Nan K, Wang S, Wang T, Zhang Z, Zhang X. A Real-Time Fabric Defect Detection Method Based on Improved YOLOv8. Applied Sciences. 2025; 15(6):3228. https://doi.org/10.3390/app15063228
Chicago/Turabian StyleJin, Yanxia, Xinyu Liu, Keliang Nan, Songsong Wang, Ting Wang, Zhuangwei Zhang, and Xiaozhu Zhang. 2025. "A Real-Time Fabric Defect Detection Method Based on Improved YOLOv8" Applied Sciences 15, no. 6: 3228. https://doi.org/10.3390/app15063228
APA StyleJin, Y., Liu, X., Nan, K., Wang, S., Wang, T., Zhang, Z., & Zhang, X. (2025). A Real-Time Fabric Defect Detection Method Based on Improved YOLOv8. Applied Sciences, 15(6), 3228. https://doi.org/10.3390/app15063228