
CCD-Net: Color-Correction Network Based on Dual-Branch Fusion of Different Color Spaces for Image Dehazing


Abstract
1. Introduction
- An effective end-to-end two-branch image-dehazing network CCD-Net is proposed. It focuses on image clarity and color features to obtain high-quality images.
- A color-correction branch is proposed to utilize features from different color spaces to avoid the difficulty of feature extraction in ordinary RGB color space. In addition, we introduce the Convolutional Block Attention Module (CBAM) into the Color-Correction Network to improve the feature-extraction capability of the network and effectively recover the missing color and detail information.
- We propose a loss function based on Lab space and form a fused loss function with the loss function in RGB space, which more comprehensively considers image color recovery.
- Numerous pieces of experimental evidence show that the proposed CCD-Net achieves a better dehazing effect, enhances the color quality of images, and consumes less computational resources compared to other competing methods.
2. Related Work
2.1. Prior-Based Methods
2.2. Learning-Based Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Key Approach | Color Consideration |
|---|---|---|---|
| Prior-based methods | DCP [11] | Dark channel assumption | ✗ |
| CAP [32] | Blue channel attenuation | ✓ | |
| HSV-based [12] | Processes luminance in HSV space | ✓ | |
| Non-local Prior [33] | Color clustering for transmission estimation | ✗ | |
| Boundary Constraint [34] | Boundary constraints and regularization | ✗ | |
| 3C Color Channel Compensation [35] | Adjusts color channels separately | ✓ | |
| Learning-based methods | DehazeNet [16] | CNN-based transmission prediction | ✗ |
| MSCNN [17] | Multi-scale CNN estimation | ✗ | |
| AOD-Net [37] | Joint transmission-atmosphere model | ✗ | |
| Enhanced Pix2Pix Dehazing [38] | Image-to-image translation | ✗ | |
| Gated Context Aggregation [39] | Gated feature aggregation | ✗ | |
| FFA-Net [40] | Feature fusion attention | ✗ | |
| Contrastive Learning Dehazing [41] | Contrastive feature training | ✗ |
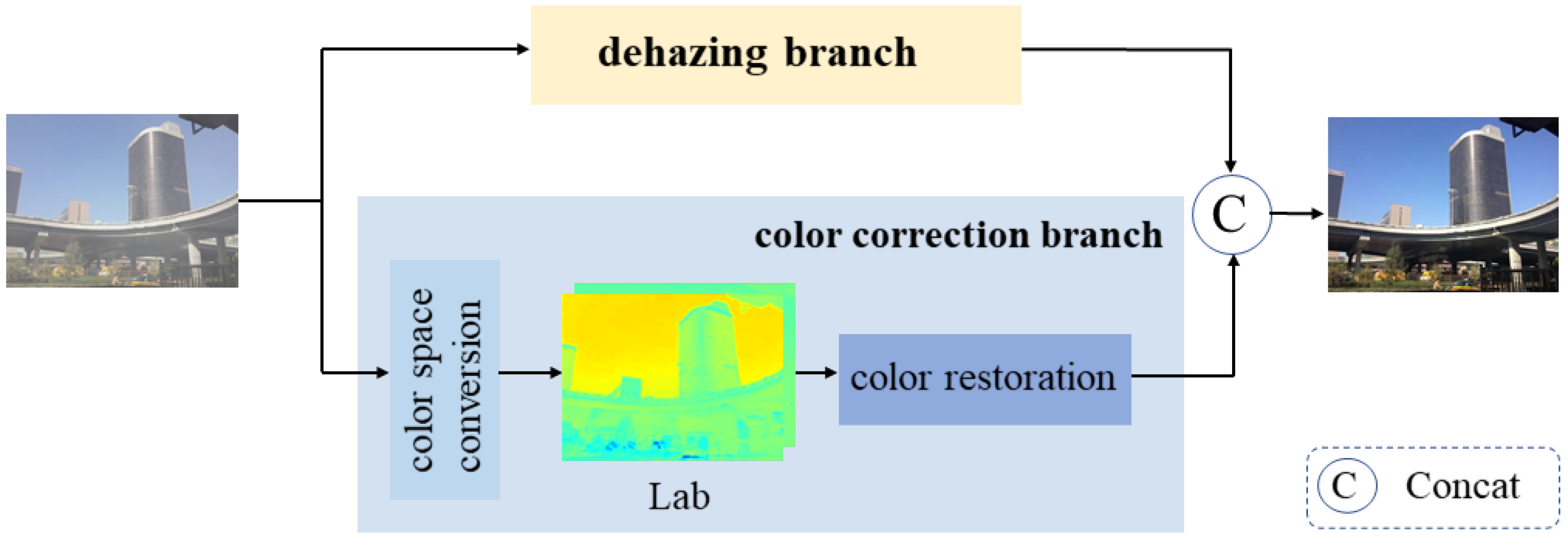
3. Our Method
3.1. Overall Framework
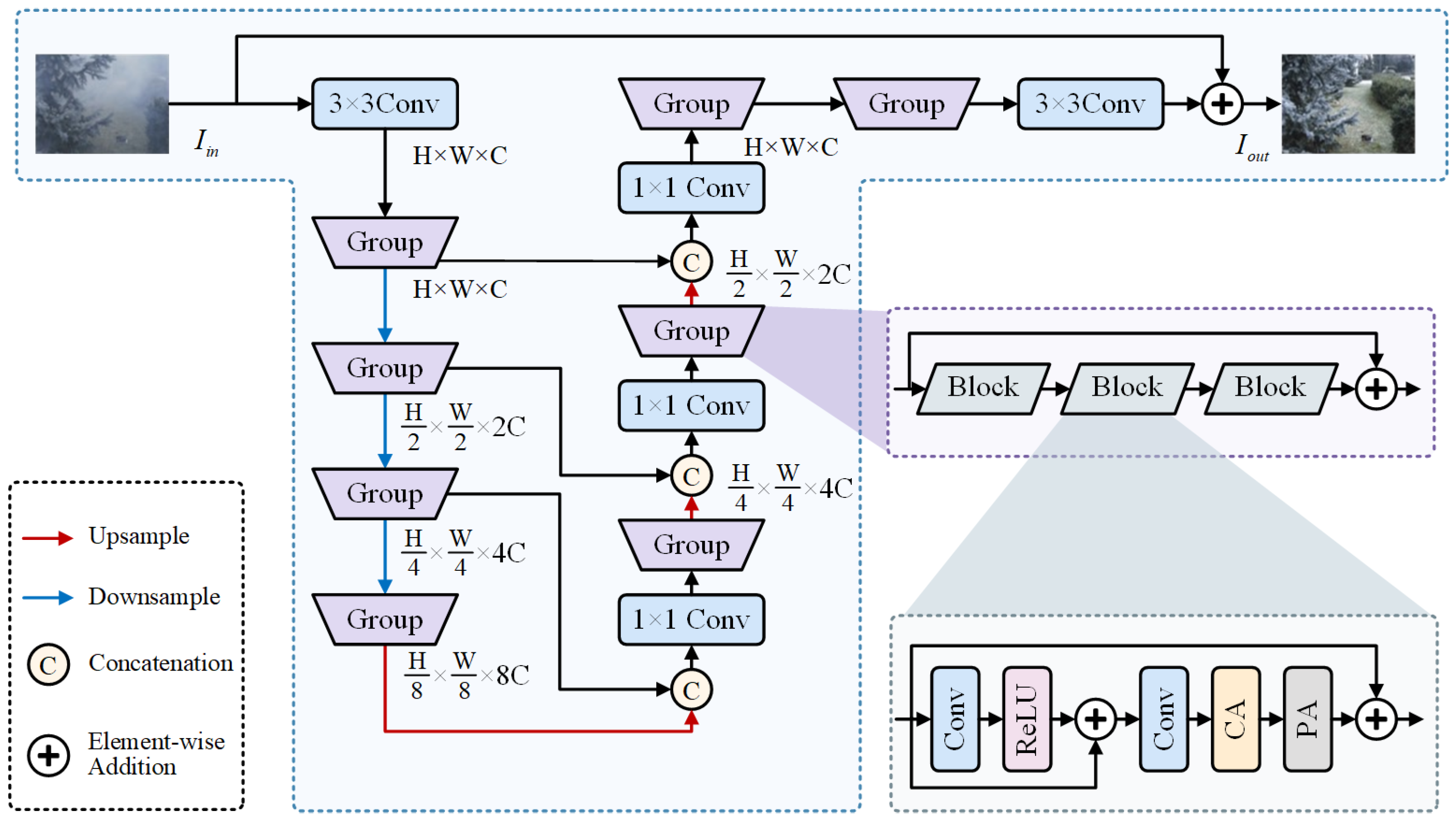
3.2. Dehazing Branch
3.3. Color-Correction Branch
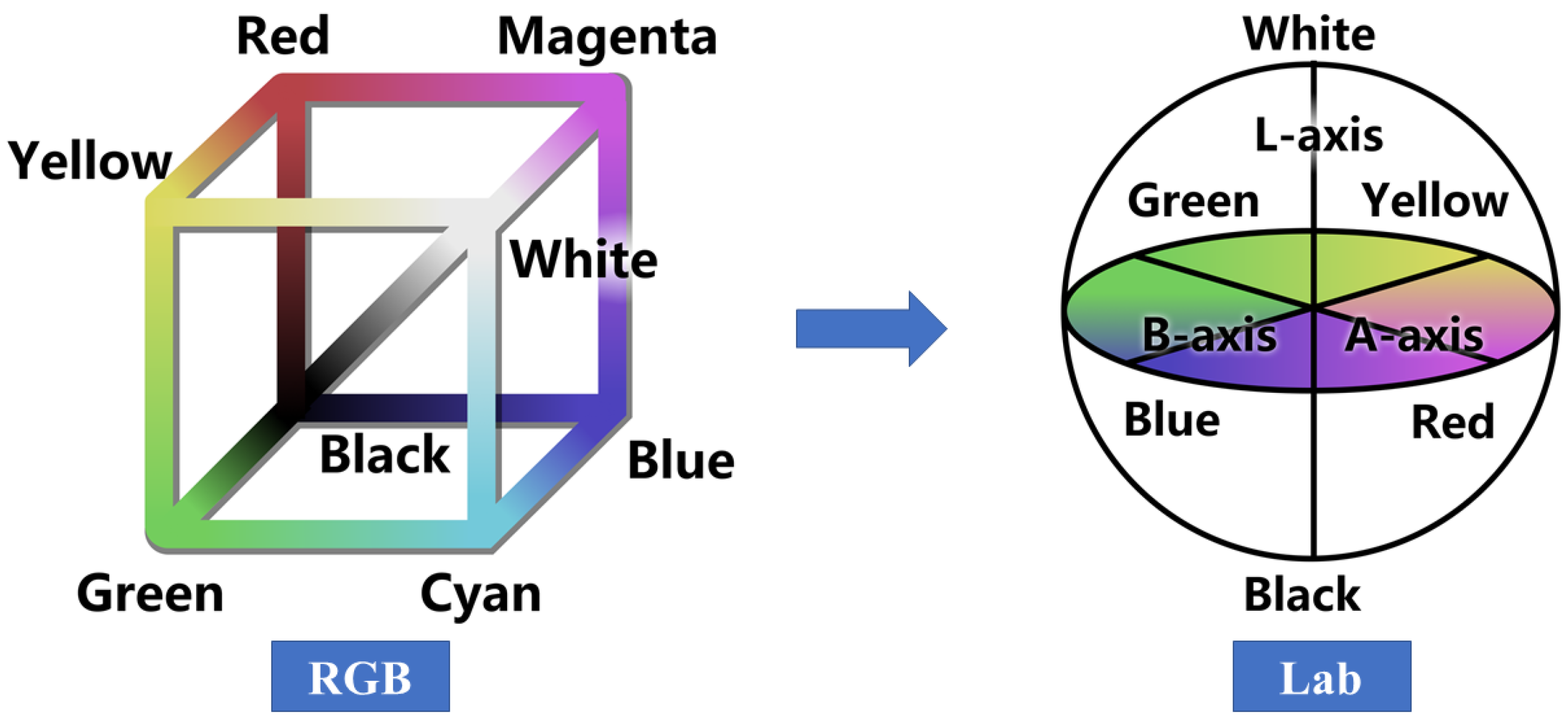
3.3.1. Advantages of Lab Color Space
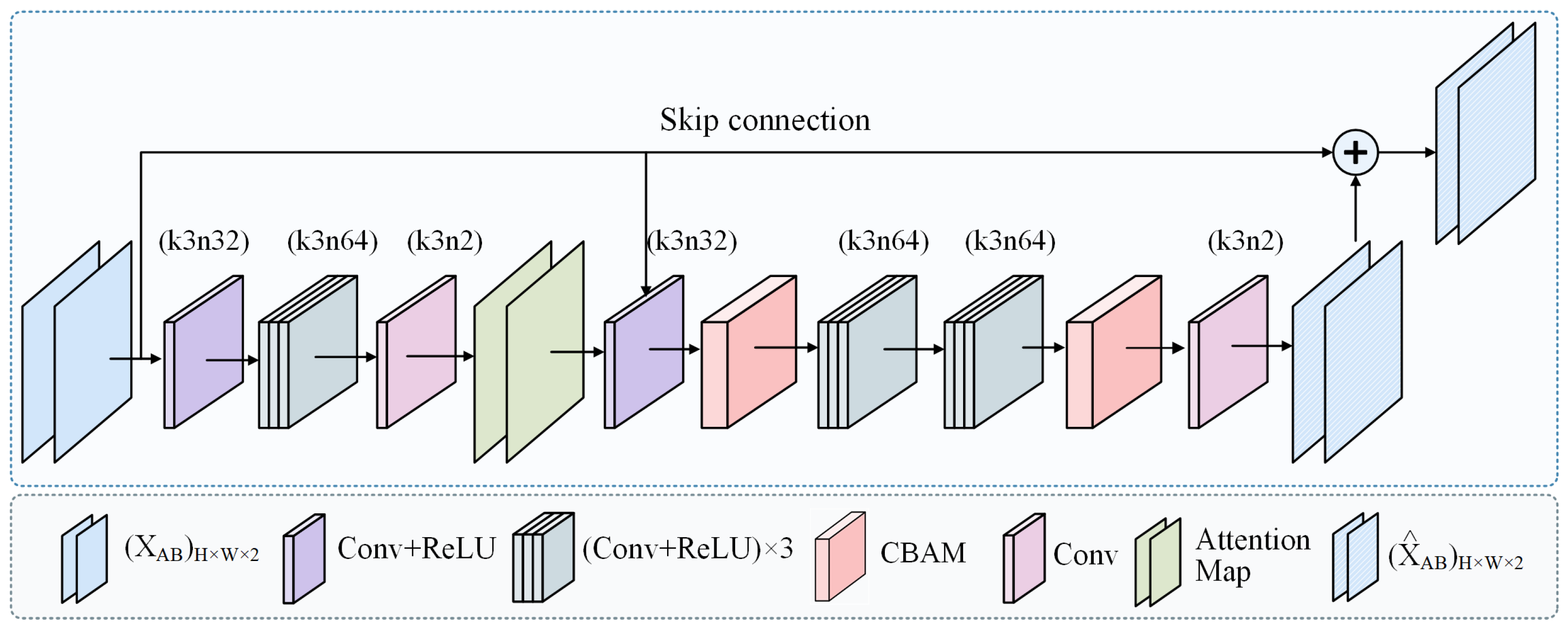
3.3.2. Architecture of Color-Correction Branch
3.4. Loss Function
4. Experiments
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Comparison with Other Methods
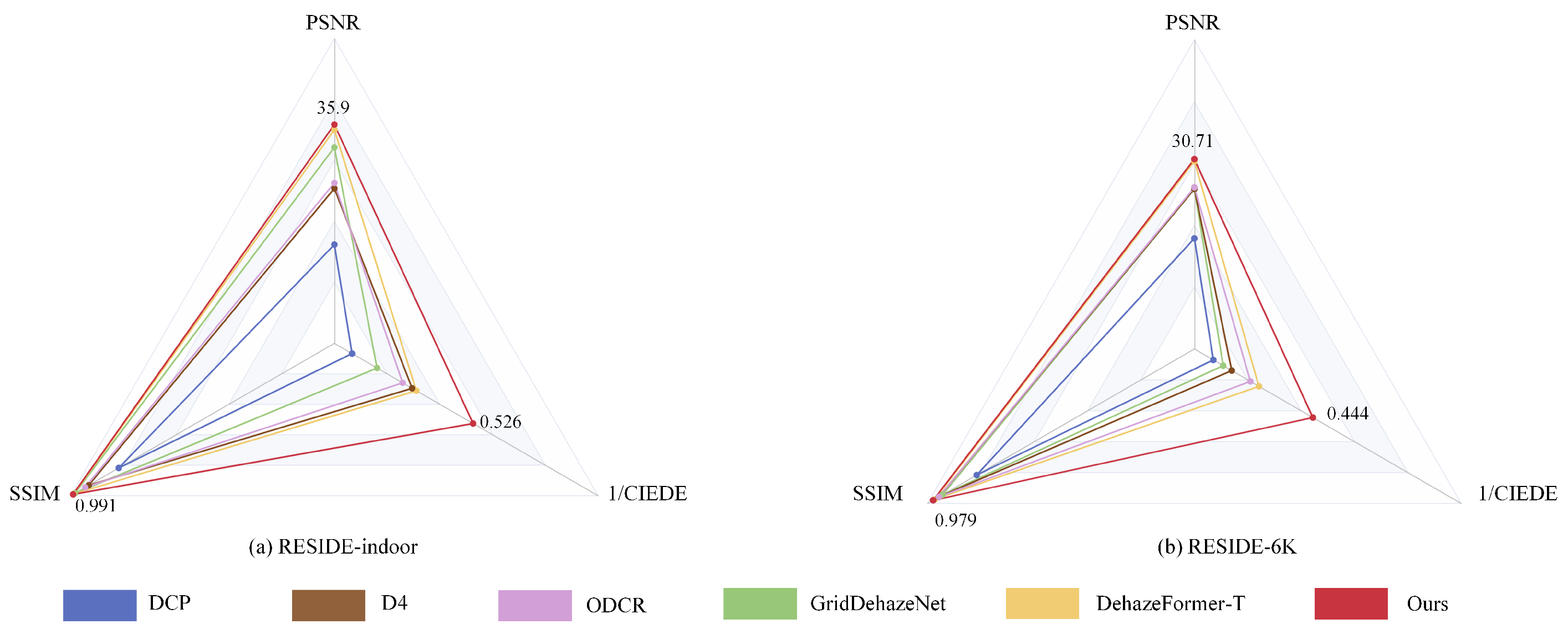
4.3.1. Quantitative Comparison
| Method | RESIDE-Indoor | RESIDE-6K | Overhead | |||||
|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | SSIM | CIEDE | PSNR (dB) | SSIM | CIEDE | Param (M) | Inference Time (ms) | |
| DCP [11] | 16.20 | 0.818 | 14.86 | 17.88 | 0.816 | 14.03 | - | - |
| GridDehazeNet [50] | 32.16 | 0.984 | 6.17 | 25.86 | 0.944 | 9.28 | 0.956 | 2.575 |
| DehazeFormer-T [51] | 35.05 | 0.989 | 3.21 | 30.36 | 0.973 | 4.13 | 0.686 | 12.90 |
| D4 [52] | 25.42 | 0.932 | 3.85 | 25.91 | 0.958 | 7.15 | 10.74 | 75.82 |
| ODCR [53] | 26.32 | 0.945 | 3.46 | 26.14 | 0.957 | 4.76 | 11.38 | 27.38 |
| Ours | 35.90 | 0.991 | 1.90 | 30.71 | 0.979 | 2.25 | 16.97 | 34.27 |
4.3.2. Visual Comparisons
4.3.3. Lab Color-Space Analysis
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, C.; Rong, X.; Yu, X. MSAFF-Net: Multiscale attention feature fusion networks for single image dehazing and beyond. IEEE Trans. Multimed. 2022, 25, 3089–3100. [Google Scholar] [CrossRef]
- Mehra, A.; Mandal, M.; Narang, P.; Chamola, V. ReViewNet: A fast and resource optimized network for enabling safe autonomous driving in hazy weather conditions. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4256–4266. [Google Scholar] [CrossRef]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How to train your deep multi-object tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6787–6796. [Google Scholar]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. TCTrack: Temporal contexts for aerial tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 14798–14808. [Google Scholar]
- Yin, J.; Wang, W.; Meng, Q.; Yang, R.; Shen, J. A unified object motion and affinity model for online multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6768–6777. [Google Scholar]
- Pang, Y.; Xie, J.; Khan, M.H.; Anwer, R.M.; Khan, F.S.; Shao, L. Mask-Guided Attention Network for Occluded Pedestrian Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Nie, J.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Enriched feature guided refinement network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, New Orleans, LA, USA, 19–24 June 2022; pp. 9537–9546. [Google Scholar]
- Li, Y.; Pang, Y.; Shen, J.; Cao, J.; Shao, L. NETNet: Neighbor erasing and transferring network for better single shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13349–13358. [Google Scholar]
- Nayar, S.K.; Narasimhan, S.G. Vision in bad weather. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; Volume 2, pp. 820–827. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Fattal, R. Single Image Dehazing. ACM Trans. Graph. (TOG) 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Liu, J.; Li, S.; Liu, H.; Dian, R.; Wei, X. A lightweight pixel-level unified image fusion network. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 18120–18132. [Google Scholar] [CrossRef]
- Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. Oneformer: One transformer to rule universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Waikoloa, HI, USA, 2–8 January 2023; pp. 2989–2998. [Google Scholar]
- Zhou, J.; Li, B.; Zhang, D.; Yuan, J.; Zhang, W.; Cai, Z.; Shi, J. UGIF-Net: An efficient fully guided information flow network for underwater image enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–169. [Google Scholar]
- Deng, Z.; Zhu, L.; Hu, X.; Fu, C.W.; Xu, X.; Zhang, Q.; Qin, J.; Heng, P.A. Deep multi-model fusion for single-image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 2453–2462. [Google Scholar]
- Zheng, L.; Li, Y.; Zhang, K.; Luo, W. T-net: Deep stacked scale-iteration network for image dehazing. IEEE Trans. Multimed. 2022, 25, 6794–6807. [Google Scholar] [CrossRef]
- Zheng, C.; Zhang, J.; Hwang, J.N.; Huang, B. Double-branch dehazing network based on self-calibrated attentional convolution. Knowl. Based Syst. 2022, 240, 108148. [Google Scholar] [CrossRef]
- Yi, Q.; Li, J.; Fang, F.; Jiang, A.; Zhang, G. Efficient and accurate multi-scale topological network for single image dehazing. IEEE Trans. Multimed. 2021, 24, 3114–3128. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, Z.; Li, P.; Song, H.; Chen, C.P.; Sheng, B. FSAD-Net: Feedback spatial attention dehazing network. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7719–7733. [Google Scholar] [CrossRef]
- Han, M.; Lyu, Z.; Qiu, T.; Xu, M. A review on intelligence dehazing and color restoration for underwater images. IEEE Trans. Syst. Man. Cybern. Syst. 2018, 50, 1820–1832. [Google Scholar] [CrossRef]
- Li, C.; Guo, J. Underwater image enhancement by dehazing and color correction. J. Electron. Imaging 2015, 24, 033023. [Google Scholar] [CrossRef]
- Deng, X.; Wang, H.; Liu, X. Underwater image enhancement based on removing light source color and dehazing. IEEE Access 2019, 7, 114297–114309. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Garcia, R. Locally adaptive color correction for underwater image dehazing and matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Venice, Italy, 22–29 October 2017; pp. 1–9. [Google Scholar]
- Zhang, Y.; Yang, F.; He, W. An approach for underwater image enhancement based on color correction and dehazing. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420961643. [Google Scholar] [CrossRef]
- Espinosa, A.R.; McIntosh, D.; Albu, A.B. An efficient approach for underwater image improvement: Deblurring, dehazing, and color correction. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–8 January 2023; pp. 206–215. [Google Scholar]
- Kong, L.; Feng, Y.; Yang, S.; Gao, X. A Two-stage Progressive Network for Underwater Image Enhancement. In Proceedings of the 2024 5th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 19–21 April 2024; pp. 1013–1017. [Google Scholar]
- Huang, Z.; Li, J.; Hua, Z.; Fan, L. Underwater image enhancement via adaptive group attention-based multiscale cascade transformer. IEEE Trans. Instrum. Meas. 2022, 71, 1–18. [Google Scholar] [CrossRef]
- Khan, R.; Mishra, P.; Mehta, N.; Phutke, S.S.; Vipparthi, S.K.; Nandi, S.; Murala, S. Spectroformer: Multi-domain query cascaded transformer network for underwater image enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–8 January 2023; pp. 1454–1463. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 27 June–2 July 2016; pp. 1674–1682. [Google Scholar]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the IEEE international Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 617–624. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Sbert, M. Color channel compensation (3C): A fundamental pre-processing step for image enhancement. IEEE Trans. Image Process. 2019, 29, 2653–2665. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3194–3203. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced Pix2pix Dehazing Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8152–8160. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10551–10560. [Google Scholar]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Suny, A.H.; Mithila, N.H. A shadow detection and removal from a single image using LAB color space. Int. J. Comput. Sci. Issues 2013, 10, 270. [Google Scholar]
- Chung, Y.S.; Kim, N.H. Saturation-based airlight color restoration of hazy images. Appl. Sci. 2023, 13, 12186. [Google Scholar] [CrossRef]
- Alsaeedi, A.H.; Hadi, S.M.; Alazzawi, Y. Adaptive Gamma and Color Correction for Enhancing Low-Light Images. Int. J. Intell. Eng. Syst. 2024, 17, 188. [Google Scholar]
- Zhang, W.; Wang, Y.; Li, C. Underwater image enhancement by attenuated color channel correction and detail preserved contrast enhancement. IEEE J. Ocean. Eng. 2022, 47, 718–735. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef]
- CIE. Commission Internationale de L’Eclariage. Colorimetry; Bureau Central de la CIE: Vienna, Austria, 1976. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-augmented unpaired image dehazing via density and depth decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 2037–2046. [Google Scholar]
- Wang, Z.; Zhao, H.; Peng, J.; Yao, L.; Zhao, K. ODCR: Orthogonal Decoupling Contrastive Regularization for Unpaired Image Dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 16–20 June 2024; pp. 25479–25489. [Google Scholar]


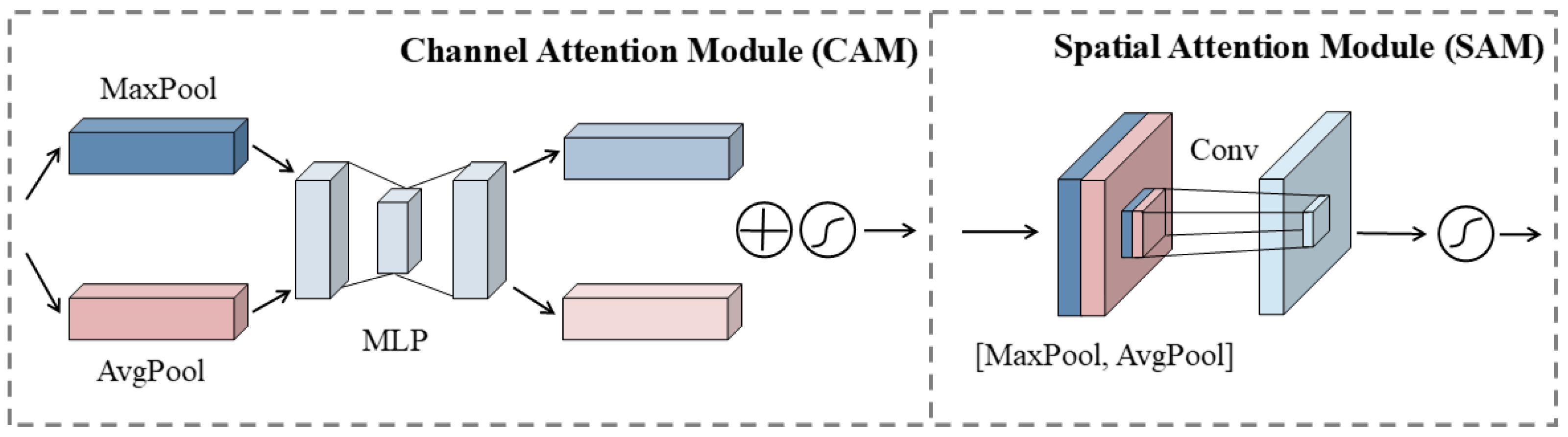





| Parameter | Values |
|---|---|
| Patch size | 128 × 128 |
| Batch size | 12 |
| Learning rate | 0.0003 |
| Iterations | 300,000 |
| Optimizer | AdamW |
| Method | RESIDE-Indoor | RESIDE-6K | ||||
|---|---|---|---|---|---|---|
| PSNR (dB) | SSIM | CIEDE | PSNR (dB) | SSIM | CIEDE | |
| 34.20 | 0.981 | 3.83 | 29.57 | 0.973 | 4.87 | |
| 35.12 | 0.982 | 2.78 | 30.38 | 0.975 | 3.96 | |
| 35.90 | 0.991 | 1.90 | 30.71 | 0.979 | 2.25 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Zhao, H. CCD-Net: Color-Correction Network Based on Dual-Branch Fusion of Different Color Spaces for Image Dehazing. Appl. Sci. 2025, 15, 3191. https://doi.org/10.3390/app15063191
Chen D, Zhao H. CCD-Net: Color-Correction Network Based on Dual-Branch Fusion of Different Color Spaces for Image Dehazing. Applied Sciences. 2025; 15(6):3191. https://doi.org/10.3390/app15063191
Chicago/Turabian StyleChen, Dongyu, and Haitao Zhao. 2025. "CCD-Net: Color-Correction Network Based on Dual-Branch Fusion of Different Color Spaces for Image Dehazing" Applied Sciences 15, no. 6: 3191. https://doi.org/10.3390/app15063191
APA StyleChen, D., & Zhao, H. (2025). CCD-Net: Color-Correction Network Based on Dual-Branch Fusion of Different Color Spaces for Image Dehazing. Applied Sciences, 15(6), 3191. https://doi.org/10.3390/app15063191