
Comparative Performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for Layout Analysis of Historical Documents Images




Abstract
1. Introduction
- Creation and availability of a dataset of historical Brazilian newspapers for layout analysis, named “Brazilian Historical Newspaper” (BHN). As one of the main contributions of this paper, the first dataset of historical Brazilian newspapers with annotations for layout detection was created.
- Development of a combined dataset, combining the BHN, GBN, and Printed BlaLet GT datasets, consisting of 459 images of historical documents annotated for layout analysis. After organizing the data and reviewing the annotations, the dataset was made publicly available on the Roboflow (www.roboflow.com, accessed on 25 September 2024) website.
- Comparative analysis of the performance of the YOLOv8, YOLOv9, YOLOv10 and YOLOv11 architectures in the layout analysis task, trained on the combined dataset. As Section 2.3 explains, these architectures were selected because of their speed, ease of implementation, and suitability for the task of layout analysis. This paper highlights the potential of these architectures in layout analysis, where significant results were obtained that not only demonstrate the effectiveness of the architectures, but also motivate new scientific research in the area.
2. Materials and Methods
2.1. Proposed Dataset: Brazilian Historical Newspaper (BHN)
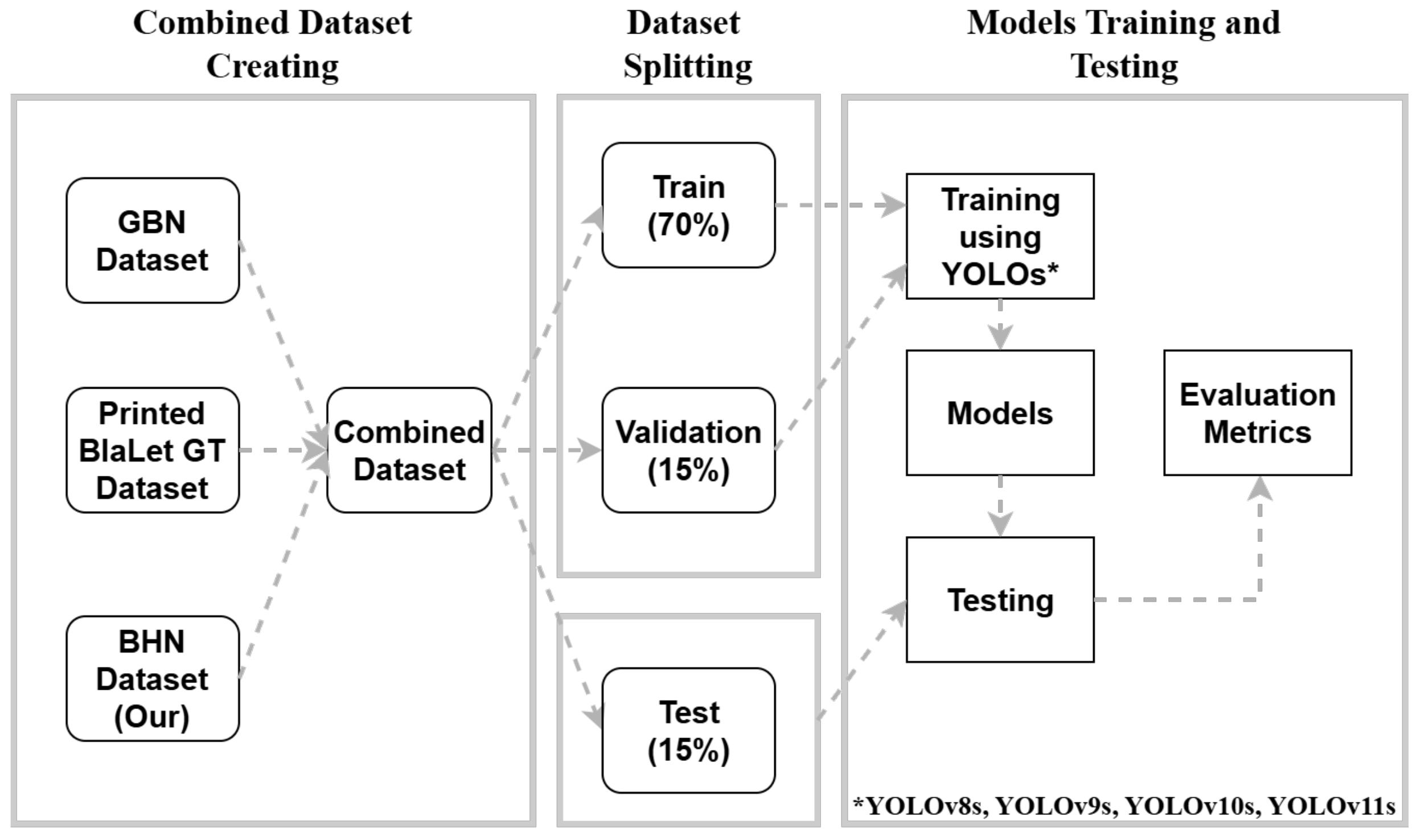
2.2. Combined Dataset and Pre-Processing
2.3. Used Architectures
- YOLOv8: This state-of-the-art algorithm can be used for object detection, image classification, and instance segmentation tasks [32]. YOLOv8 was developed by Ultralytics, which included several changes to the architecture and developer experience, as well as improvements over YOLOv5. YOLOv8 uses an anchor-free model with a decoupled head to independently process the objectivity, classification and regression tasks. This design allows each branch to concentrate on its task and improves the overall accuracy of the model. In the output layer of YOLOv8, the authors used the sigmoid function as the activation function for the objectivity score, representing the probability that the bounding box contains an object.
- YOLOv9: YOLOv9 was launched in February 2024 [33] as an update to previous versions. YOLOv9 boasts two key innovations: the Programmable Gradient Information (PGI) framework and the Generalized Efficient Layer Aggregation Network (GELAN). The PGI framework aims to address the issue of information bottlenecks, inherent in deep neural networks in addition to enabling deep supervision mechanisms to be compatible with lightweight architectures. By implementing PGI, both lightweight and deep architectures can leverage substantial improvements in accuracy, as PGI mandates reliable gradient information during training, thus enhancing the architecture’s capacity to learn and make accurate predictions.
- YOLOv10: YOLOv10 [34] sets a new standard in real-time object detection by addressing the shortcomings of previous YOLO versions and incorporating innovative design strategies. Its ability to deliver high accuracy with low computational cost makes it an ideal choice for a wide range of real-world applications. To address the Non-Maximum Suppression (NMS) dependency and architectural inefficiencies of past YOLO versions, YOLOv10 introduces consistent dual assignments for training without NMS and a holistic model design strategy aimed at efficiency and accuracy. Thus, its main features are NMS-free training, holistic model design, and enhanced model features.
- YOLOv11: According to [35], YOLOv11 represents the latest advancement in the YOLO family, building on the strengths of its predecessors while introducing innovative features and optimizations aimed at enhancing performance across various computer vision tasks. The YOLOv11 architecture has optimized feature extraction capabilities, making it possible to capture intricate details in images [36]. This model supports a range of applications, including real-time object detection, instance segmentation, and pose estimation, which allows it to accurately identify objects regardless of their orientation, scale, or size, making it versatile for industries like agriculture and surveillance. The YOLOv11 model utilizes enhanced training techniques that have led to improved results on benchmark datasets. YOLOv11 is optimized for real-time applications, ensuring fast processing even in demanding environments.
2.4. Training Hyperparameters
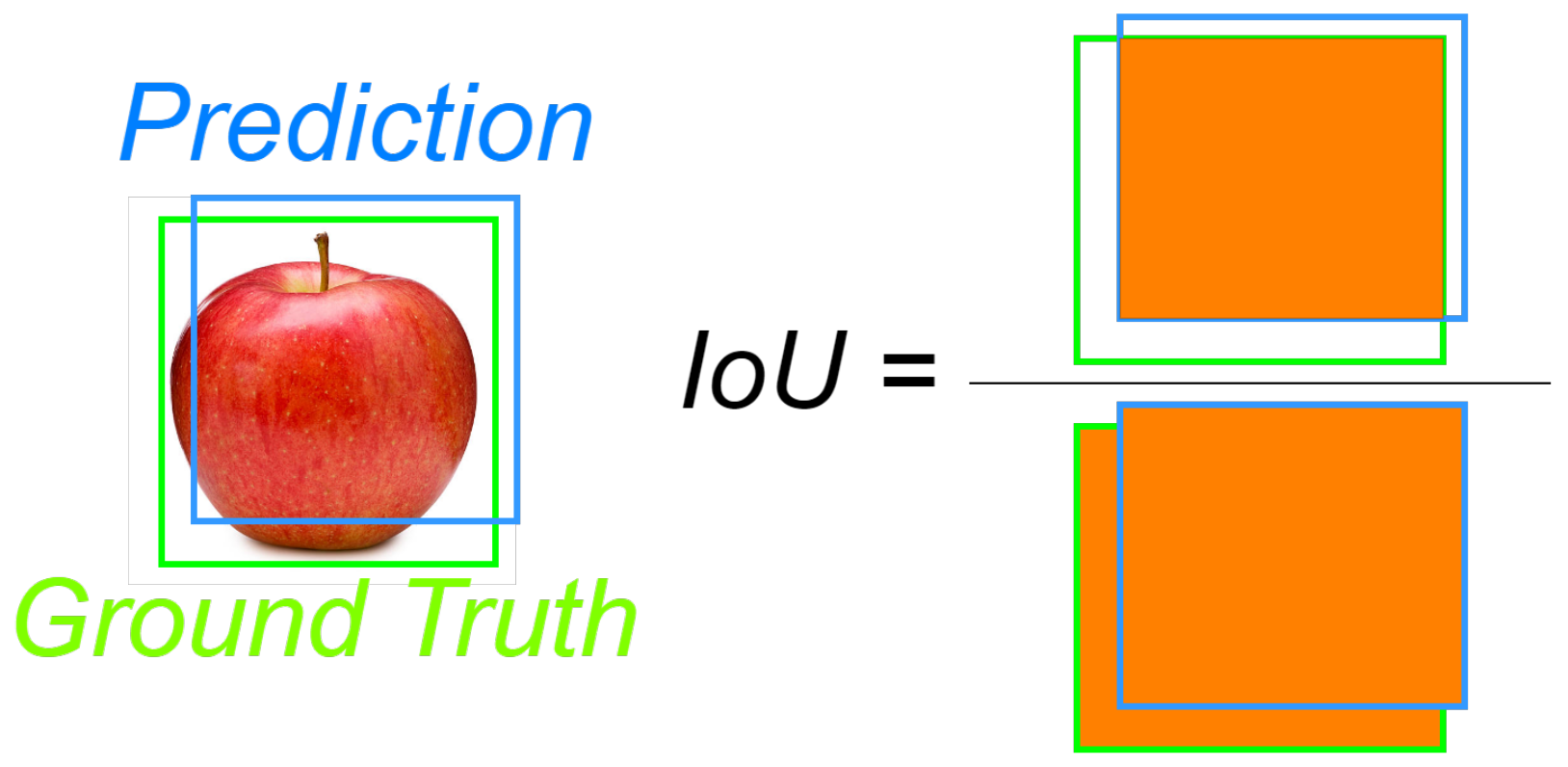
2.5. Evaluation Metrics
- True Positive (TP): Correct detection of a true bounding box;
- False Positive (FP): An incorrect detection of a nonexistent object or a misplaced detection of an existing object;
- False Negative (FN): An undetected ground-truth bounding box;
- mAP: It is an evaluation metric that has been widely used for evaluating the quality of object detectors [44]. This metric is the most popular among benchmark challenges, such as the COCO and ImageNET challenges. The measure, used in multiclass problems, is defined from the Average Precision () of each class.The is calculated by Equation (4) and is defined as the area under the precision (P) × recall (R) curve, where M is the number of interpolated points.Therefore, the metric calculates the of each category separately and then averages these APs across all categories. This approach ensures that the model’s performance is assessed for each category individually, providing a more comprehensive assessment of the model’s overall performance [43]. The is expressed mathematically by Equation (5), where N is the number of classes in the problem.It is important to note that for this work, a threshold of was selected when evaluating the architectures. In this case, the notation is used to indicate the threshold.
3. Results and Discussion
3.1. Models Performance
3.2. Some Visual Results
- In test image 1 (Figure 5a), it can be seen that YOLOv8 (Figure 5b) detects all the desired regions correctly, despite producing two false positives for the Text class: one at the bottom of the document, with 0.25 confidence, and another at the top left. YOLOv9 (Figure 5c), even though many regions on the page are well detected, it has limitations related to the fragmentation of text blocks, low confidence scores in specific areas and confusion between nearby classes. YOLOv10 (Figure 5d) was able to detect all regions, generating only one false positive, which proves its high precision, shown in Table 4. YOLOv11 (Figure 5e) shows a similar result to YOLOv8, but with three false positives from the Text class;
- In test image 2 (Figure 5f), which has a high number of instances, all of which are of the Text class, the YOLOv8 (Figure 5g) and YOLOv11 (Figure 5j) architectures performed better in the layout analysis task. However, it can be seen that YOLOv9 (Figure 5h) and YOLOv10 (Figure 5i) did not locate all the text regions, which is in line with the lower recall of these architectures.
- In test image 3 (Figure 5k), it can be seen that YOLOv8 (Figure 5l) correctly identified all text regions, whether in the form of a paragraph, title or subtitle, as well as detecting the graphic element present on the page. Only a section of the subtitle was not detected by YOLOv8 and was left out of the bounding box that was generated for that text. YOLOv9 (Figure 5m) detected fewer layout elements, missing some parts of the text by producing inaccurate bounding boxes and giving rise to false positives for the graphic and text class. YOLOv10 (Figure 5n) and YOLOv11 (Figure 5o), in turn, achieved a similar performance to YOLOv8, with YOLOv11’s result showing bounding boxes better adjusted to the text blocks;
- In test image 4 (Figure 5p), YOLOv8 (Figure 5q) detected the blocks of text and the image on the newspaper page more accurately and consistently, with the bounding boxes delimiting the text columns well. YOLOv9 (Figure 5r) correctly recognized the image on the page, but did not detect all the text regions, once again underperforming YOLOv8. YOLOv10 (Figure 5s) had the worst result for test image 4 among the architectures, failing to detect several text regions just below the title. Once again, YOLOv11 (Figure 5t) performed closely to YOLOv8, capturing the text regions and the image on the page well.
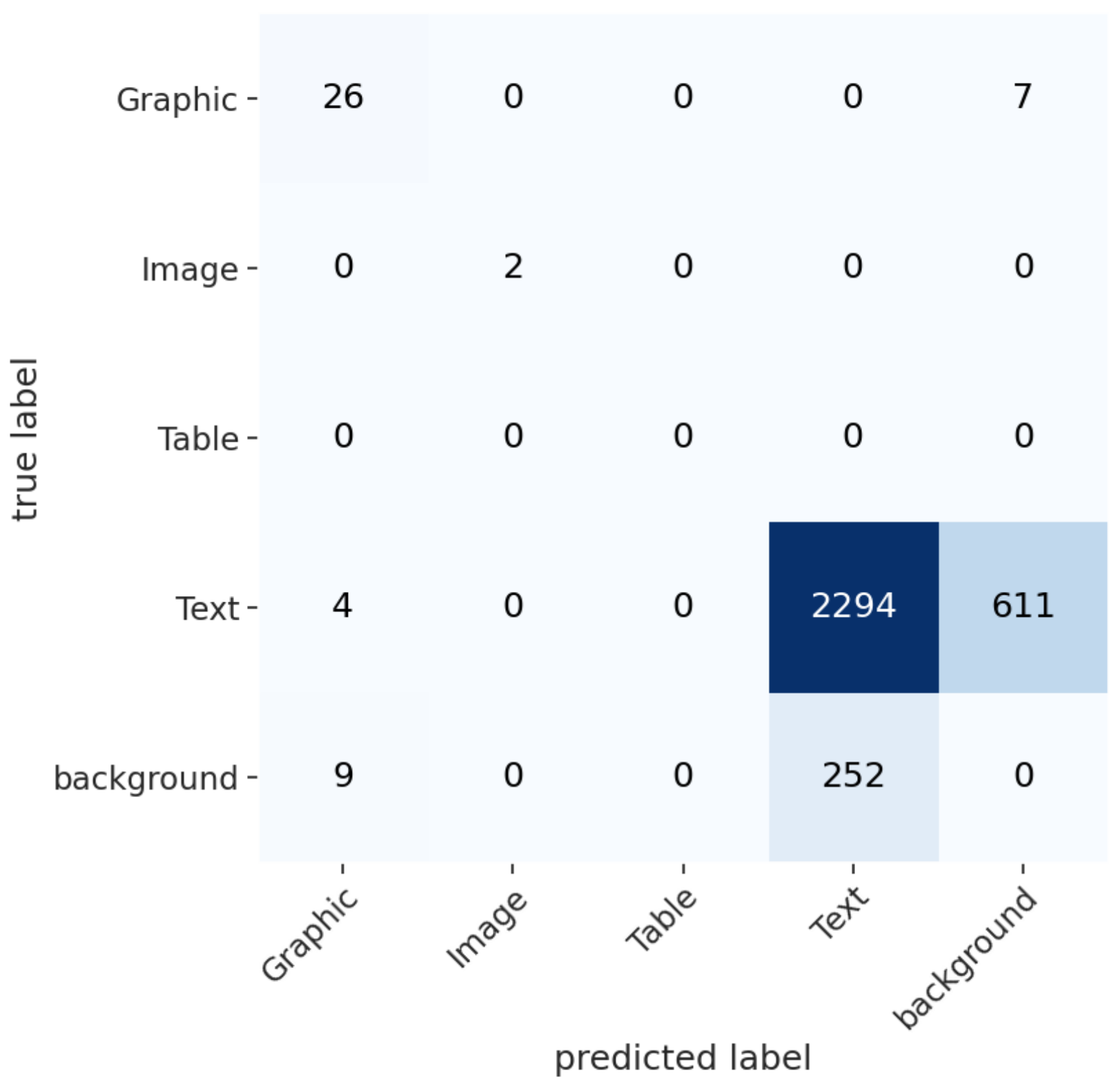
3.3. Best Model (YOLOv8) Details
4. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nguyen, T.T.; Le, H.; Nguyen, T.; Vo, N.D.; Nguyen, K. A brief review of state-of-the-art object detectors on benchmark document images datasets. Int. J. Doc. Anal. Recognit. IJDAR 2023, 26, 433–451. [Google Scholar] [CrossRef]
- Lopatin, L. Library digitization projects, issues and guidelines: A survey of the literature. Libr. Hi Tech 2006, 24, 273–289. [Google Scholar] [CrossRef]
- Barlindhaug, G. Artificial Intelligence and the Preservation of Historic Documents; University of Akron Press: Akron, OH, USA, 2022. [Google Scholar]
- Biffi, S. Document Layout Analysis: Segmentation and Classification with Computer Vision and Deep Learning Techniques. Master’s Thesis, ING-Scuola di Ingegneria Industriale e dell’Informazione, Milan, Italy, 2016. [Google Scholar]
- Chandra, S.; Sisodia, S.; Gupta, P. Optical character recognition-A review. Int. Res. J. Eng. Technol. (IRJET) 2020, 7, 3037–3041. [Google Scholar]
- Araújo, A.B. Análise de layout de página em jornais históricos germano-brasileiros. Master’s Thesis, UFPR-Federal University of Paraná, Curitiba, Brazil, 2019. [Google Scholar]
- Jannidis, F.; Kohle, H.; Rehbein, M. Digital Humanities; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Zhu, W.; Sokhandan, N.; Yang, G.; Martin, S.; Sathyanarayana, S. DocBed: A multi-stage OCR solution for documents with complex layouts. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 12643–12649. [Google Scholar] [CrossRef]
- Dai-Ton, H.; Duc-Dung, N.; Duc-Hieu, L. An adaptive over-split and merge algorithm for page segmentation. Pattern Recognit. Lett. 2016, 80, 137–143. [Google Scholar] [CrossRef]
- Shehzadi, T.; Stricker, D.; Afzal, M.Z. A hybrid approach for document layout analysis in document images. In Proceedings of the International Conference on Document Analysis and Recognition, Athens, Greece, 30 August–4 September 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 21–39. [Google Scholar] [CrossRef]
- Cong, X.; Li, S.; Chen, F.; Liu, C.; Meng, Y. A review of YOLO object detection algorithms based on deep learning. Front. Comput. Intell. Syst. 2023, 4, 17–20. [Google Scholar] [CrossRef]
- Lavanya, G.; Pande, S.D. Enhancing Real-time Object Detection with YOLO Algorithm. EAI Endorsed Trans. Internet Things 2024, 10, 12. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M. YOLOv1 to YOLOv10: The fastest and most accurate real-time object detection systems. APSIPA Trans. Signal Inf. Process. 2024, 13, e29. [Google Scholar] [CrossRef]
- Saha, R.; Mondal, A.; Jawahar, C. Graphical object detection in document images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 51–58. [Google Scholar] [CrossRef]
- Alaasam, R.; Kurar, B.; El-Sana, J. Layout analysis on challenging historical arabic manuscripts using siamese network. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 738–742. [Google Scholar] [CrossRef]
- Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M. Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 1192–1200. [Google Scholar]
- Appalaraju, S.; Jasani, B.; Kota, B.U.; Xie, Y.; Manmatha, R. Docformer: End-to-end transformer for document understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 993–1003. [Google Scholar]
- Huang, Y.; Lv, T.; Cui, L.; Lu, Y.; Wei, F. Layoutlmv3: Pre-training for document ai with unified text and image masking. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 4083–4091. [Google Scholar] [CrossRef]
- Chen, S.; Sun, P.; Song, Y.; Luo, P. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 19830–19843. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 16965–16974. [Google Scholar]
- Zhao, Z.; Kang, H.; Wang, B.; He, C. Doclayout-yolo: Enhancing document layout analysis through diverse synthetic data and global-to-local adaptive perception. arXiv 2024, arXiv:2410.12628. [Google Scholar]
- Chai, M.; Shen, Z.; Zhang, C.; Zhang, Y.; Wang, X.; Dou, S.; Kang, J.; Zhang, J.; Zhang, Q. DocFusion: A Unified Framework for Document Parsing Tasks. arXiv 2024, arXiv:2412.12505. [Google Scholar]
- Salim, H.; Mustafa, F.S. A COMPREHENSIVE EVALUATION OF YOLOv5s AND YOLOv5m FOR DOCUMENT LAYOUT ANALYSIS. Eur. J. Interdiscip. Res. Dev. 2024, 23, 21–33. [Google Scholar]
- Deng, Q.; Ibrayim, M.; Hamdulla, A.; Zhang, C. The YOLO model that still excels in document layout analysis. Signal Image Video Process. 2024, 18, 1539–1548. [Google Scholar] [CrossRef]
- Gao, Z.; Li, S. YOLOLayout: Multi-Scale Cross Fusion Former for Document Layout Analysis. Int. J. Emerg. Technol. Adv. Appl. (IJETAA) 2024, 1, 8–15. [Google Scholar] [CrossRef]
- Fleischhacker, D.; Goederle, W.; Kern, R. Improving OCR Quality in 19th Century Historical Documents Using a Combined Machine Learning Based Approach. arXiv 2024, arXiv:2401.07787. [Google Scholar]
- Chen, H.C.; Wu, L.; Zhang, Y. EDocNet: Efficient Datasheet Layout Analysis Based on Focus and Global Knowledge Distillation. arXiv 2025, arXiv:2502.16541. [Google Scholar]
- Ströbel, P.; Clematide, S. Improving OCR of Black Letter in Historical Newspapers: The Unreasonable Effectiveness of HTR Models on Low-Resolution Images. In Proceedings of the Digital Humanities 2019 (DH2019), Utrecht, The Netherlands, 9–12 July 2019. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Kim, J.H.; Oh, W.J.; Lee, C.M.; Kim, D.H. Achieving optimal process design for minimizing porosity in additive manufacturing of Inconel 718 using a deep learning-based pore detection approach. Int. J. Adv. Manuf. Technol. 2022, 121, 2115–2134. [Google Scholar] [CrossRef]
- Sulzbach, L. Building a Dataset of Late Modern German-Brazilian Newspaper Advertisement Pages for Layout and Font Recognition. Bachelor’s Thesis, UFPR-Federal University of Paraná, Curitiba, Brazil, 2022. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Sapkota, R.; Meng, Z.; Churuvija, M.; Du, X.; Ma, Z.; Karkee, M. Comprehensive performance evaluation of yolo11, yolov10, yolov9 and yolov8 on detecting and counting fruitlet in complex orchard environments. arXiv 2024, arXiv:2407.12040. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Ramos, L.; Casas, E.; Bendek, E.; Romero, C.; Rivas-Echeverría, F. Hyperparameter optimization of YOLOv8 for smoke and wildfire detection: Implications for agricultural and environmental safety. Artif. Intell. Agric. 2024, 12, 109–126. [Google Scholar] [CrossRef]
- Ji, X.; Wan, J.; Zhang, Y.; Yang, T.; Yang, Q.; Liao, J. Hydrospot-Yolo: Real-Time Water Hyacinth Detection in Complex Water Environments; Elsevier: Amsterdam, The Netherlands, 2024. [Google Scholar]
- Neupane, C.; Walsh, K.B.; Goulart, R.; Koirala, A. Developing Machine Vision in Tree-Fruit Applications—Fruit Count, Fruit Size and Branch Avoidance in Automated Harvesting. Sensors 2024, 24, 5593. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Wang, Y.; Yu, D.; Yuan, Z. YOLOv8-FDD: A real-time vehicle detection method based on improved YOLOv8. IEEE Access 2024, 12, 136280–136296. [Google Scholar] [CrossRef]
- Lee, Y.S.; Prakash Patil, M.; Kim, J.G.; Seo, Y.B.; Ahn, D.H.; Kim, G.D. Hyperparameter Optimization for Tomato Leaf Disease Recognition Based on YOLOv11m. Plants 2025, 14, 653. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 international conference on systems, signals and image processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 237–242. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D.M.; Ramirez-Pedraza, A.; Chavez-Urbiola, E.A. Loss functions and metrics in deep learning. A review. arXiv 2023, arXiv:2307.02694. [Google Scholar]
- Wang, B. A parallel implementation of computing mean average precision. arXiv 2022, arXiv:2206.09504. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Pages | ||
|---|---|---|---|---|
| Quality | DPI | Format | ||
| BlaLet GT | Gray | 224–521 | TIFF | 167 |
| GBN | Bitonal | 300 | PNG | 152 |
| RGB | 600 | |||
| BHN (Our) | RGB | 96 | PNG | 140 |
| Description | Count |
|---|---|
| Text | 14.333 |
| Image | 23 |
| Graphic | 462 |
| Table | 42 |
| Hyperparameter | Value |
|---|---|
| Epochs | 100 |
| Batch Size | 16 |
| Image Size | 640 × 640 |
| Learning Rate | 0.01 |
| Momentum | 0.937 |
| Architecture | Recall | Precision | mAP50 |
|---|---|---|---|
| YOLOv8 | 0.809 | 0.845 | 0.891 |
| YOLOv9 | 0.712 | 0.754 | 0.757 |
| YOLOv10 | 0.495 | 0.949 | 0.692 |
| YOLOv11 | 0.801 | 0.854 | 0.871 |
| Classes | Recall | Precision | mAP50 |
|---|---|---|---|
| Text | 0.825 | 0.888 | 0.911 |
| Image | 1.000 | 0.759 | 0.995 |
| Graphic | 0.602 | 0.887 | 0.768 |
| all | 0.809 | 0.845 | 0.891 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos Júnior, E.S.d.; Paixão, T.; Alvarez, A.B. Comparative Performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for Layout Analysis of Historical Documents Images. Appl. Sci. 2025, 15, 3164. https://doi.org/10.3390/app15063164
Santos Júnior ESd, Paixão T, Alvarez AB. Comparative Performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for Layout Analysis of Historical Documents Images. Applied Sciences. 2025; 15(6):3164. https://doi.org/10.3390/app15063164
Chicago/Turabian StyleSantos Júnior, Eder Silva dos, Thuanne Paixão, and Ana Beatriz Alvarez. 2025. "Comparative Performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for Layout Analysis of Historical Documents Images" Applied Sciences 15, no. 6: 3164. https://doi.org/10.3390/app15063164
APA StyleSantos Júnior, E. S. d., Paixão, T., & Alvarez, A. B. (2025). Comparative Performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for Layout Analysis of Historical Documents Images. Applied Sciences, 15(6), 3164. https://doi.org/10.3390/app15063164