7.1. CvT Model Incorporating Convolution Exhibits Excellent Performance in Facial Expression Recognition
The results in
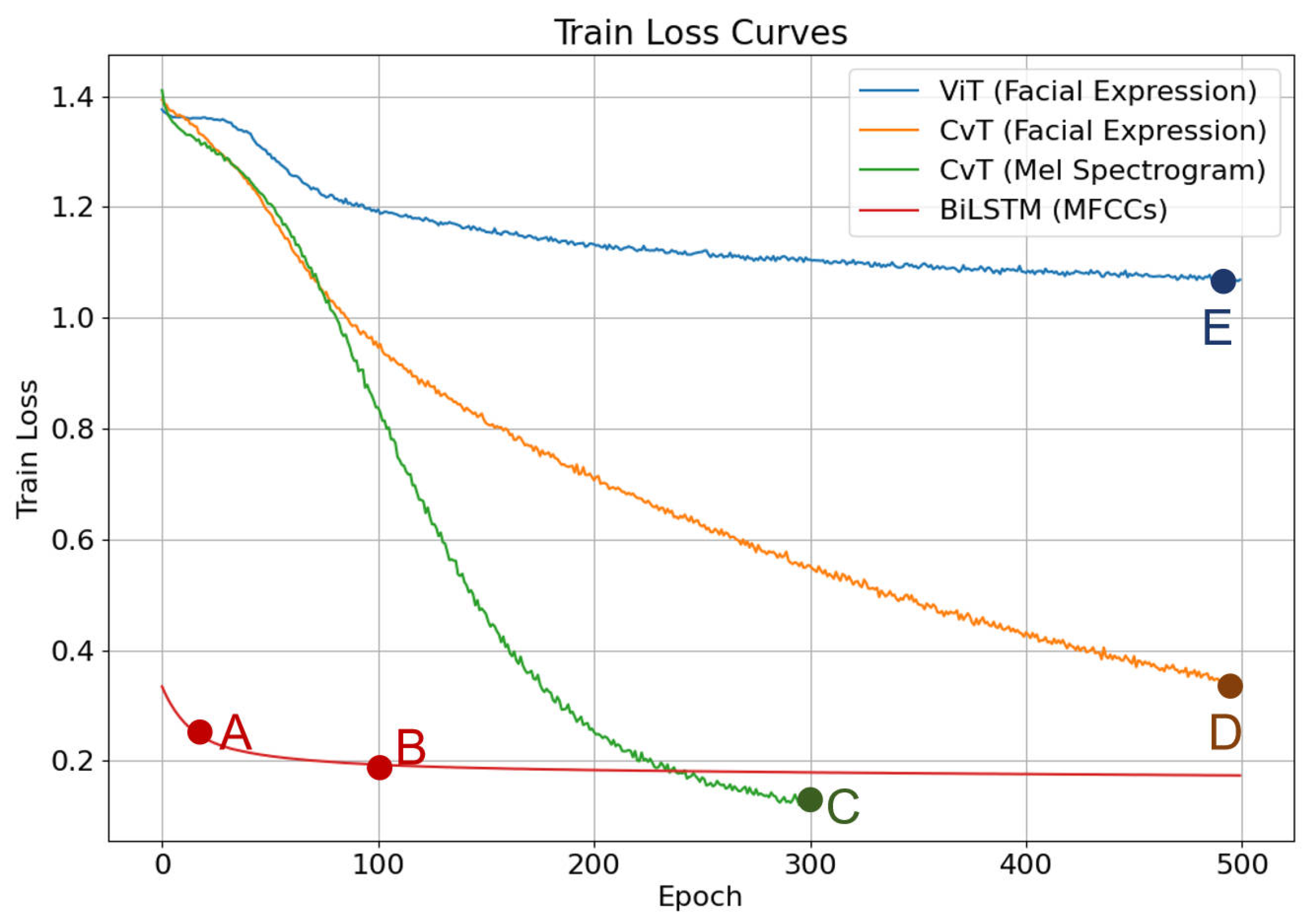
Table 7 clearly demonstrate that the CvT model (79.12%) significantly outperforms the ViT model (48%) in facial expression recognition for children with autism.
Building upon the established research on the facial expression characteristics of children with autism discussed in the Related Works Section, our findings confirm that models incorporating both local and global feature processing mechanisms perform better for this specific population. The CvT architecture, with its integration of convolutional operations, appears particularly suited for capturing the unique facial expression patterns exhibited by children with ASD, where emotional cues may manifest differently compared to typically developing children.
Children with autism exhibit reduced dynamic variability in their entire face and display a more balanced intensity of facial movements [
9], as compared with typically developing children. Gepner et al. [
35] discovered, via computational analysis, that children with autism have diminished complexity in all facial regions when experiencing sadness, whereas certain facial regions display atypical dynamics during moments of happiness. In order to accurately predict the emotional states of children with autism, it is crucial to analyze both the intricate features of their entire face and the distinct features of certain facial regions.
The CvT model synergistically integrates the advantages of CNN’s local feature recognition with the transformer’s global information processing capability, enabling collection of both local details and the overall structural characteristics of facial expressions. Compared with the ViT model, which mainly relies on global information processing, the CvT model shows better performance in dealing with tasks with special expression features such as those of children with autism. Wodajo et al. [
36] proposed a network structure including convolution and ViT for face forgery detection task, which raises the accuracy to more than 75%. It also demonstrates the efficacy of utilizing convolution and a transformer in combination, consistent with the findings of this research. Hence, when constructing a classification model for facial expression images of children with autism, it is necessary to thoroughly consider the differences in children’s facial expressions. In addition, incorporating the concept of convolution into the model enables it to effectively focus on the fine-grained features of the image.
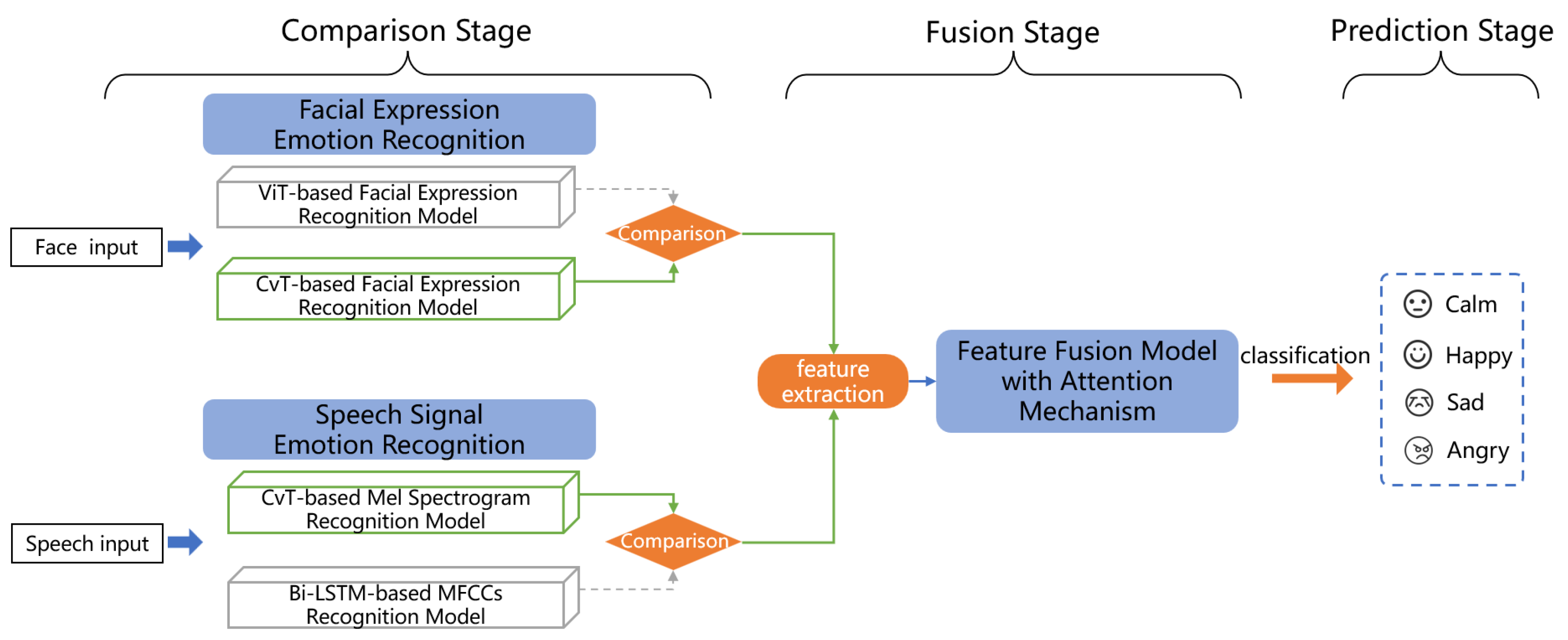
7.3. Feature Fusion Models Leverage the Complementary Benefits of Multimodal Data
Based on the results presented in
Table 8, the expression and speech feature fusion model demonstrates superior recognition performance against the single-modal data model, which proves that the complementary advantages of multimodal data overcome the limitations of single-modal data.
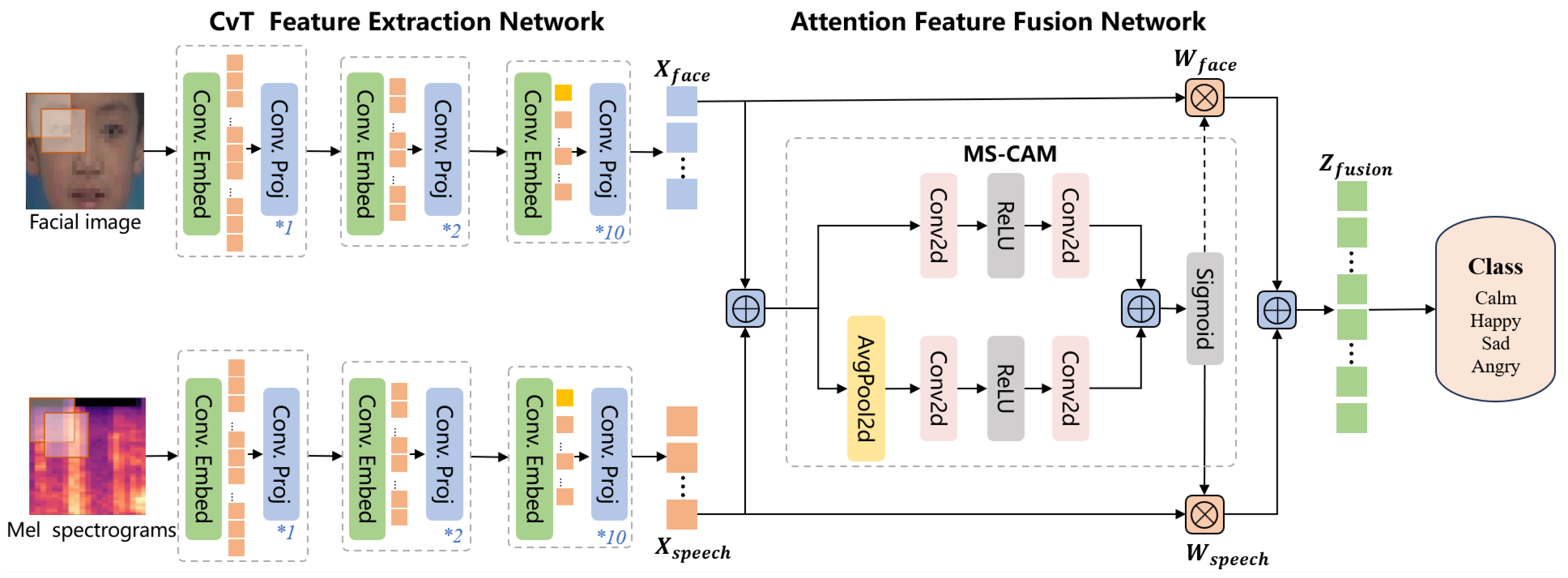
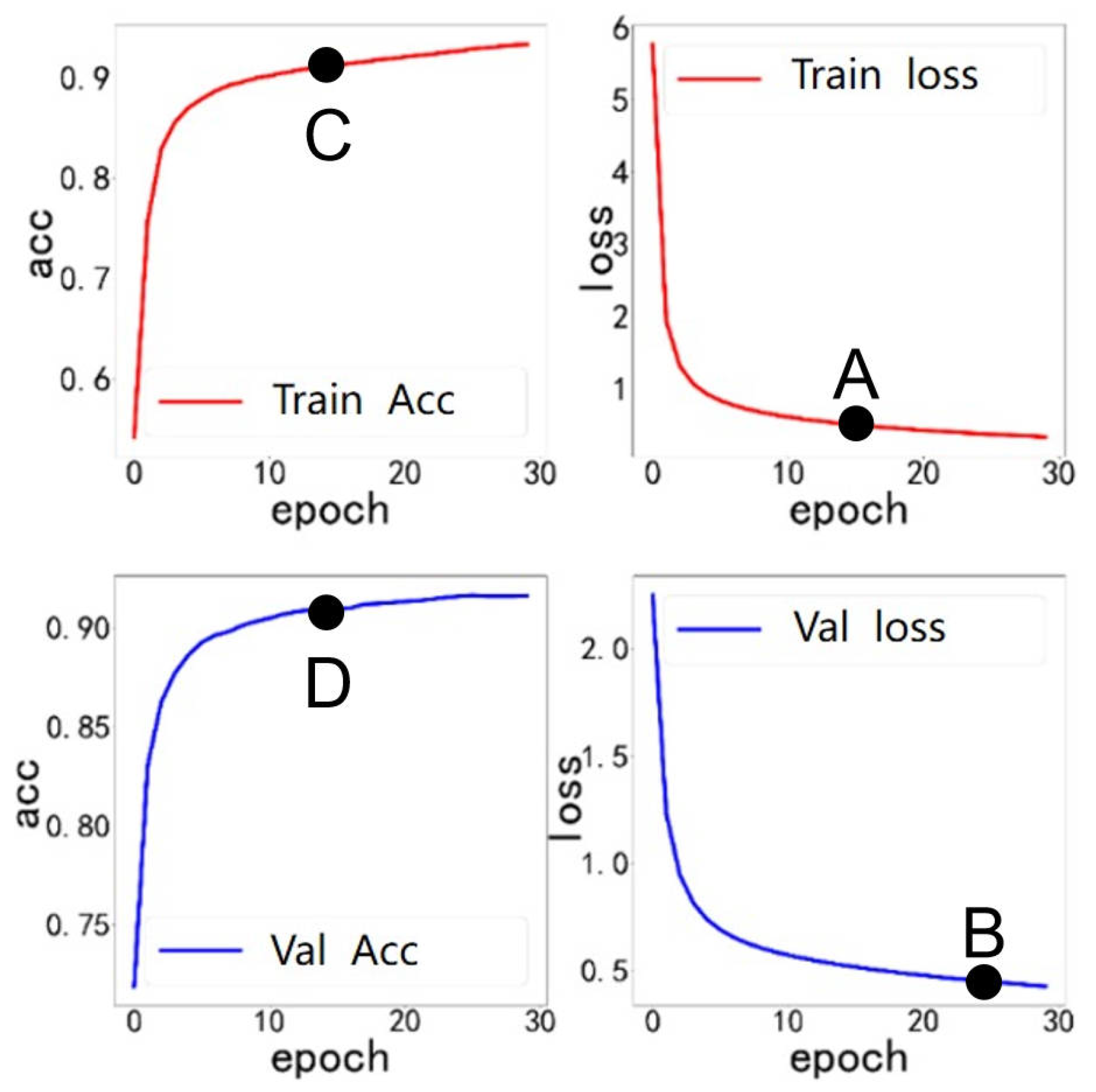
The empirical results of our multimodal feature fusion model (90.73% accuracy) validate the theoretical framework of multimodal emotion recognition discussed in the Related Works Section. The substantial performance improvement over single-modal approaches (facial expression: 79.12%; speech: 83.47%) empirically demonstrates the complementary nature of these information sources when applied specifically to children with autism. This performance enhancement is particularly significant given the documented challenges in emotion recognition for this population, where traditional single-modal approaches may fail to capture the full spectrum of emotional expressions.
Expression and speech, two distinct sources of emotional information, provide complementary data. Expression mainly conveys non-verbal emotional information, whereas signals such as intonation and rhythm in speech also contain emotion, which cannot be fully accessed in a single modality. Furthermore, a single modality has constraints when it comes to addressing nuanced alterations in emotional displays. Multimodal fusion has the ability to decrease errors or ambiguities that arise from a single source of information, thus enhancing the accuracy and robustness of the model. In special groups such as children with emotional interaction disorders, the change of facial expressions may be less discernible, thus incorporating speech signals can enhance the model’s comprehension of the individual’s emotional state.
The advantages of multimodal data were also verified by Li et al. [
34]. They used auditory and visual clues from children with autism to predict children’s positive, negative, and neutral emotional states in real-world game therapy scenarios, with a recognition accuracy of 72.40% [
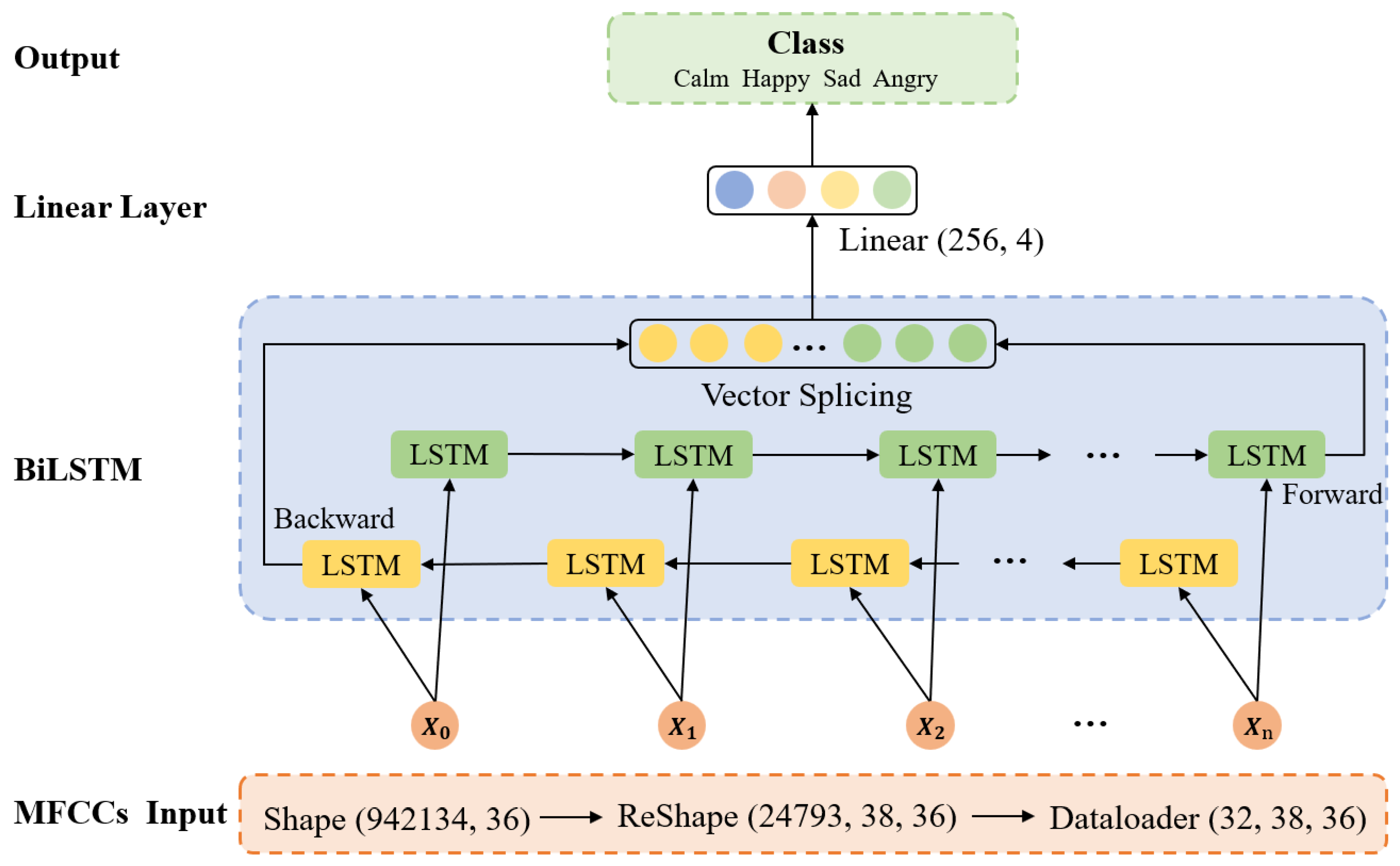
34]. We use the CvT network to extract the facial expression and speech features of children with autism. By using a multi-scale channel attention module, the model enables the fusion of multimodal data. The accuracy of multimodal emotion recognition is 90.73%, which is higher than the accuracy of 79.12% for the facial expression modality and 83.47% for the speech modality. This effectively enhances the model’s performance and makes use of a higher value between the data for both modalities.
7.4. Visualization of Emotional Features in Autistic Children
This study uses the gradient-weighted class activation mapping (Grad-CAM) algorithm to generate heat maps to visually represent the significant basis for model prediction. The darker red color displayed on the heat map signifies a greater contribution and heightened response of the region to the emotion recognition model, which serves as the primary foundation for discriminating emotions in the model.
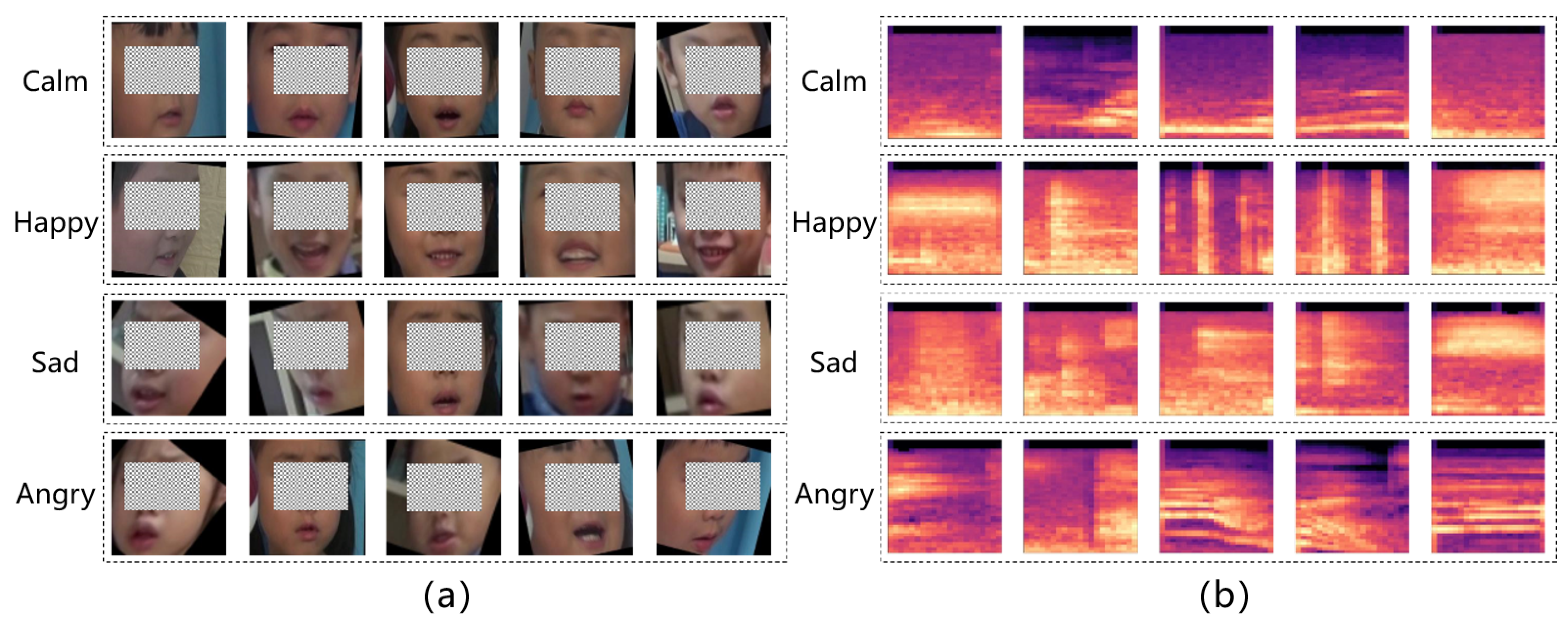
Figure 13 presents Grad-CAM heat maps visualizing the critical facial regions that influence the model’s emotion recognition decisions for children with autism. In these visualizations, red areas represent regions of high activation that strongly contribute to classification decisions, while blue areas indicate regions with minimal contribution. Analysis of these activation patterns reveals consistent attention distributions across different emotional states, as follows:
- (1)
For calm emotions (first row), the model demonstrates distributed attention across multiple facial areas, with particular focus on the upper cheeks, forehead, jaw regions, and nasolabial folds. This pattern suggests that neutral emotional states in children with autism are characterized by subtle features distributed across the face rather than concentrated in specific expressive regions.
- (2)
For happy emotions (second row), the model consistently emphasizes sensory regions and their surrounding areas, particularly the eyes, mouth, and periorbital muscles. The activation patterns show concentrated attention on smile-related features, including the corners of the mouth and the orbicularis oculi muscles that are activated during genuine expressions of happiness. This finding aligns with previous research indicating that children with autism may express happiness through characteristic eye and mouth movements, albeit with different muscular coordination than typically developing children [
9].
- (3)
For sad emotions (third row), the model exhibits targeted attention to specific sensory regions, predominantly focusing on the eyes, mouth, and nasal areas. The consistent activation around the eyes and the downturned mouth corners corresponds to the characteristic facial configurations associated with sadness. This localized attention pattern suggests that children with autism express sadness through distinctive movements in these specific facial regions rather than through global facial configurations.
- (4)
For angry emotions (fourth row), the model demonstrates more holistic attention patterns spanning across broader facial regions, with activation distributed across the brow, eyes, and mouth areas. This comprehensive attention distribution suggests that anger expression in children with autism involves coordinated movements across multiple facial regions, though with activation patterns that may differ from those observed in typically developing children.
These visualization findings provide important insights into how the model interprets the facial expressions of children with autism. The observed attention patterns confirm the findings of previous research suggesting that children with autism rely more on specific facial regions for emotional expression rather than coordinated global facial movements (Guha et al., 2016 [
9]; Samad et al., 2015 [
7]). Furthermore, these visualizations offer a quantitative basis for understanding the distinctive facial expression characteristics in this population, potentially informing both diagnostic approaches and therapeutic interventions targeting emotional communication.
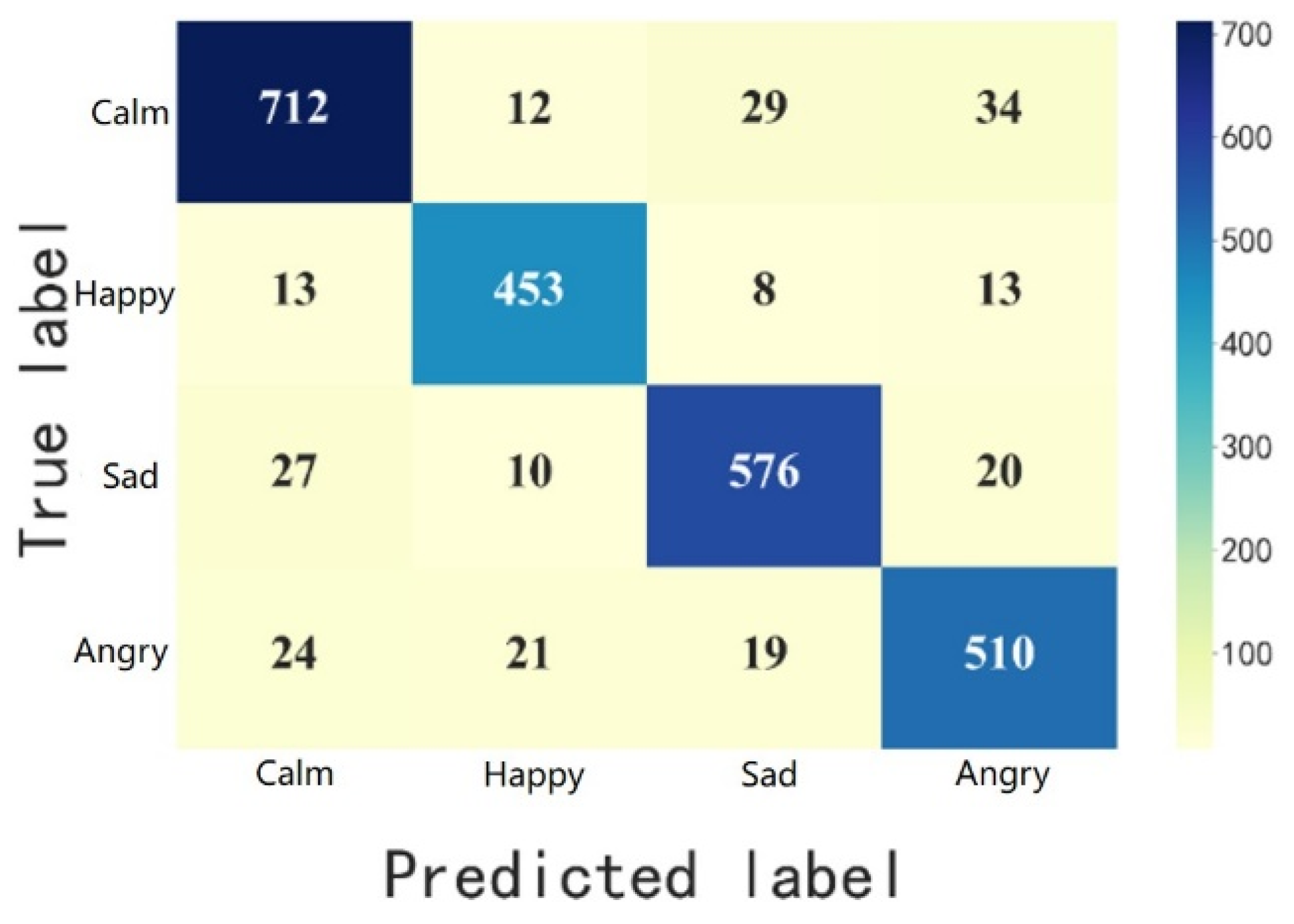
The analysis of misclassification patterns revealed important insights into the model’s limitations. The confusion between calm and sad emotional states represents the most frequent error pattern in our facial expression recognition system, with bidirectional misclassifications accounting for approximately 4.6% of errors across these categories. In cases where the model incorrectly classified sad expressions as calm, the Grad-CAM visualizations typically showed insufficient attention to subtle mouth configurations while maintaining focus on the eye regions. This pattern suggests that the model occasionally struggles to integrate multiple facial cues when expression intensity is reduced, a common characteristic in children with autism who often exhibit flattened affect. In contrast, happy expressions were rarely confused with other emotions (misclassification rate of only 2.8%), likely due to the distinctive activation patterns around the mouth region that our model successfully captured through the attention mechanism.
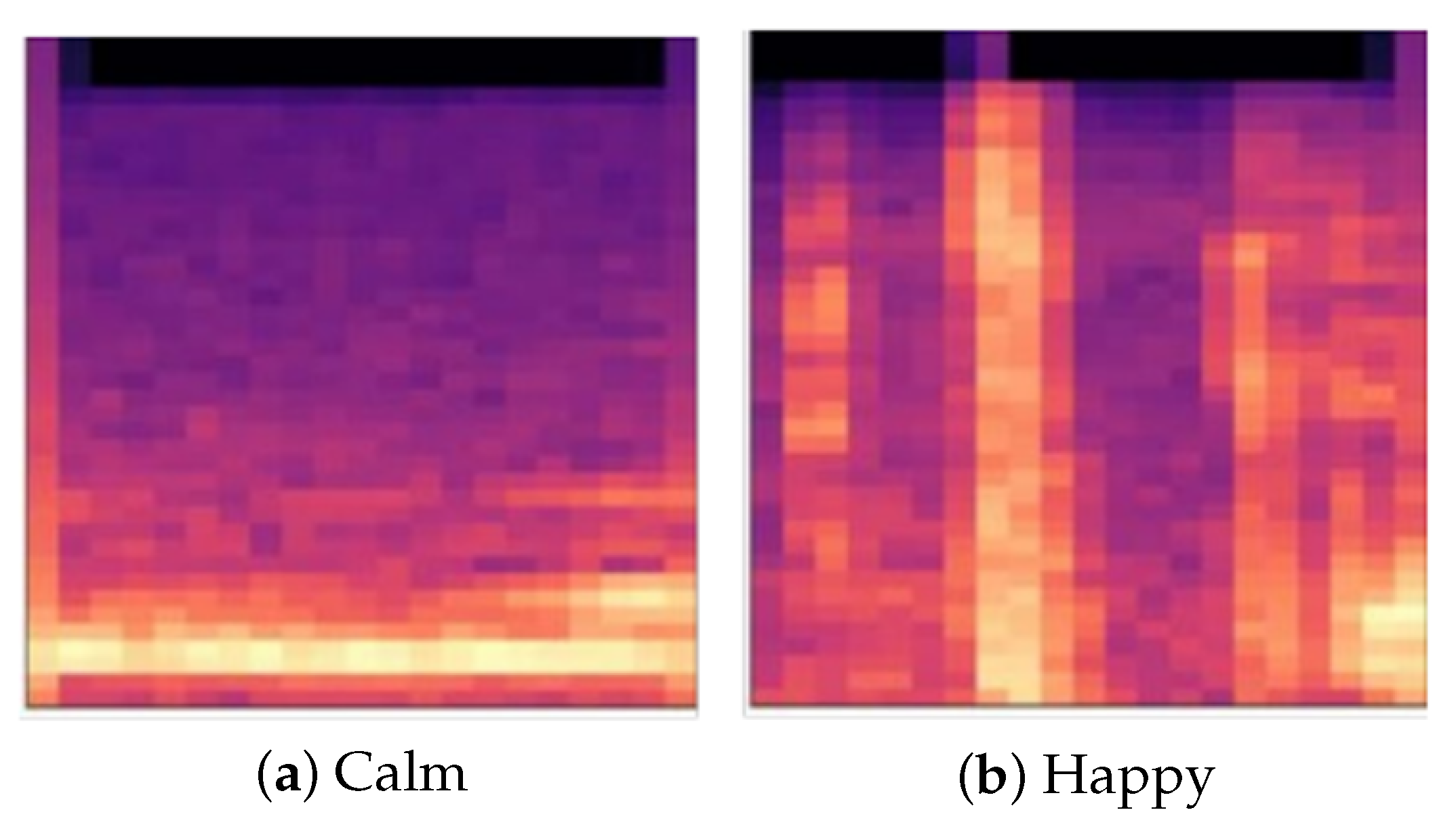
Figure 14 presents the Grad-CAM heat maps highlighting the critical time–frequency regions of Mel spectrograms that significantly influence the model’s emotion classification decisions. The intensity of the red coloration corresponds to the degree of feature importance, with darker regions indicating stronger activation in the model’s decision-making process. Our comprehensive analysis reveals distinctive attention patterns across the four emotional states as follows:
- (1)
For calm emotional states, the model predominantly attends to low-frequency components and regions of minimal energy variation. This concentration of attention corresponds to the acoustic characteristics of calm speech in children with autism, which typically exhibits minimal spectral variation and more stable frequency patterns across time.
- (2)
In happy emotional expressions, the model directs significant attention to regions of elevated energy in the middle and low frequency bands. The heat map reveals concentrated activation in areas with distinctive tonal qualities and increased spectral energy density.
- (3)
For sad emotional states, the model identifies and emphasizes regions exhibiting irregular frequency distributions and notable temporal fluctuations. The heat map demonstrates focused on transitional components in the spectrogram, indicating the model’s sensitivity to the distinctive rhythm and prosodic features.
- (4)
In angry emotional expressions, the heat map exhibits pronounced activation in high-frequency and high-energy regions of the spectrogram. This pattern of attention demonstrates the model’s ability to identify the increased speech signal energy and intensity characteristic of angry vocalizations.
The examination of speech emotion recognition errors revealed that angry vocalizations were occasionally misclassified as sad (approximately 6.2% of cases). In these instances, the Grad-CAM visualizations showed the model attending to lower frequency regions that typically characterize sad expressions rather than the high-energy, high-frequency components more common in angry vocalizations. This finding suggests that the model struggles with distinguishing between angry vocalizations with suppressed intensity (common in children with autism who may internalize anger) and sad emotional expressions. This pattern aligns with clinical observations that children with autism may express anger differently than typically developing children, often with atypical vocal characteristics that blend emotional categories that are more distinct in neurotypical populations.
Based on the aforementioned analysis, it is concluded that the speech characteristics associated with happy, sad, angry, and calm emotions in children with autism are significantly different, primarily in terms of frequency and energy distribution.
7.5. Performance and Computational Efficiency Trade-Offs
While our proposed approach demonstrates superior accuracy for emotion recognition in children with autism, its practical deployment in intervention settings necessitates the evaluation of its computational efficiency alongside performance benefits.
- 1.
Computational Complexity Comparison
Vision transformers and convolutional neural networks represent different approaches to feature extraction with distinct computational profiles. According to Dosovitskiy et al. [
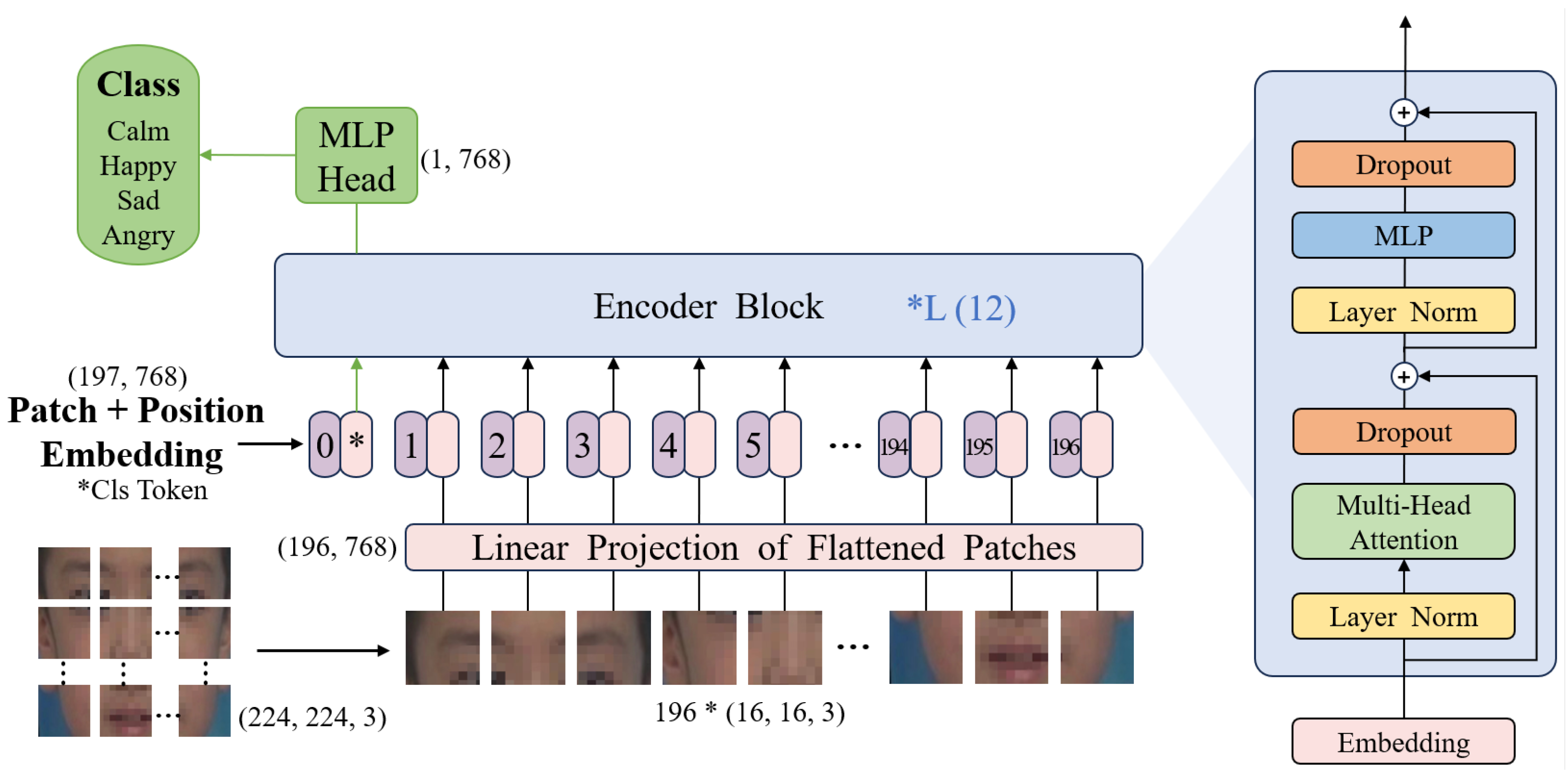
39], ViT models exhibit quadratic computational complexity O (n²) with respect to token count, creating substantial overhead for image processing. For standard 224 × 224 pixel inputs with 16 × 16 patches, this results in processing 196 token sequences through multiple transformer layers.
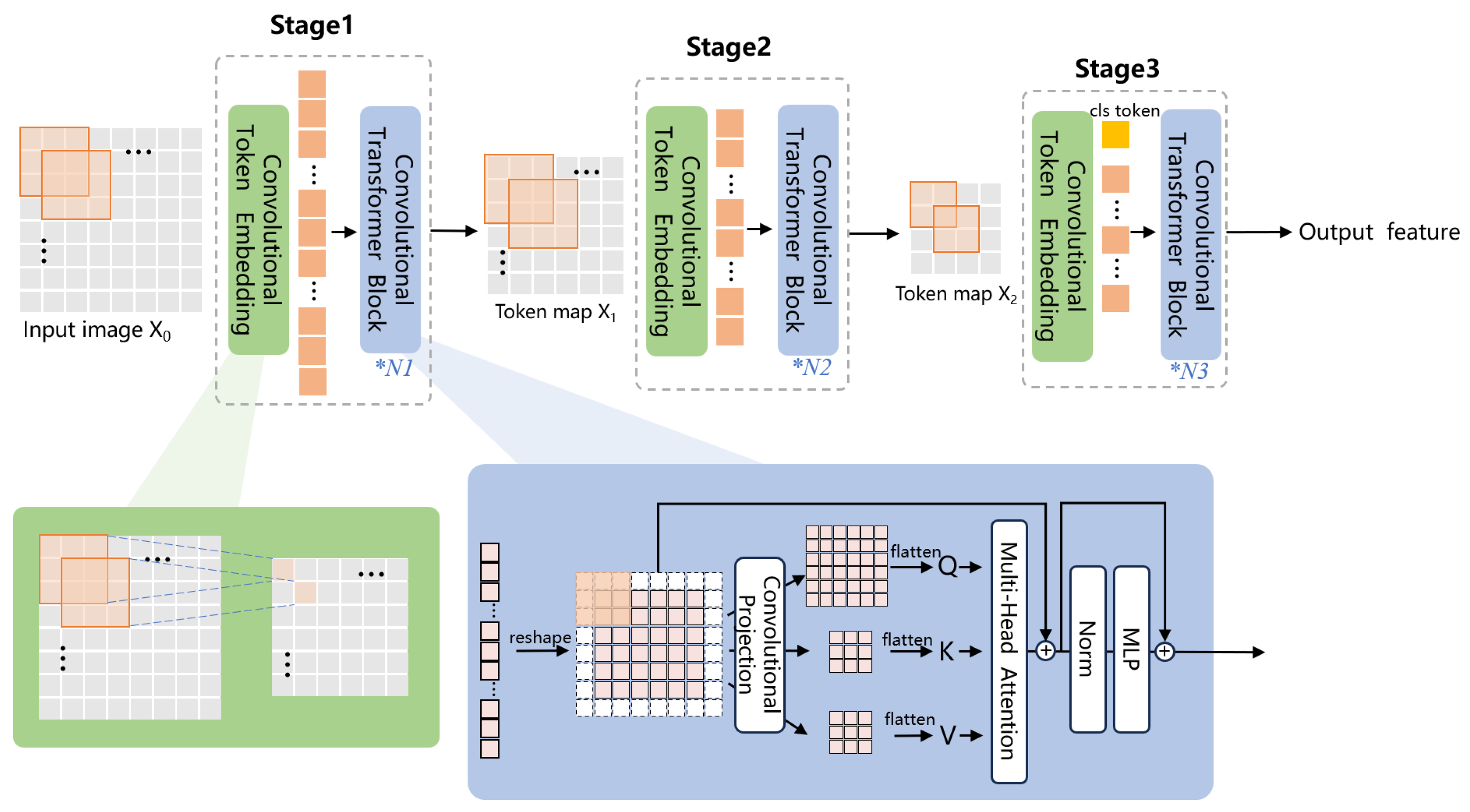
The CvT architecture addresses this limitation through a hierarchical design that progressively reduces spatial resolution [
40]. Their analysis demonstrates that CvT-13 achieves higher accuracy than ViT-B/16 while requiring approximately 20% fewer parameters (20 M vs. 86 M) and 30% less computational overhead (4.5 G vs. 17.6 G FLOPs). This efficiency gain stems from two key factors as follows: convolutional token embedding that downsamples spatial dimensions and convolutional projection layers that introduce inductive biases beneficial for visual tasks.
- 2.
Efficiency-Performance Balance in Practice
Hybrid architectures combining convolutional operations with transformer elements consistently demonstrate favorable efficiency–performance trade-offs. Graham et al. [
41] showed that such models achieve up to 5× faster inference speed compared to pure transformer approaches at comparable accuracy levels. Similarly, Hassani et al. [
42] demonstrated that compact transformer designs incorporating convolutional principles can maintain competitive performance while significantly reducing parameter count.
These findings align with our experimental results, where the CvT model outperformed the pure transformer approach (ViT) by 31.12% in accuracy for facial expression recognition. This substantial performance gap, combined with the inherent efficiency advantages of the CvT architecture, underscores the value of our approach for specialized applications like autism emotion recognition.
- 3.
Multimodal Fusion Considerations
Our multimodal fusion approach necessarily requires additional computational resources compared to single-modal methods. However, the substantial accuracy improvement (90.73% for fusion versus 79.12% and 83.47% for individual modalities) represents a compelling trade-off for clinical applications where recognition precision directly impacts intervention quality. As Liu et al. [
32] noted, models employing hierarchical designs with local processing elements typically achieve a more favorable computation–accuracy balance for complex vision tasks.
7.6. Limitations and Future Work
Despite the promising results achieved in this study, several limitations should be acknowledged that point toward directions for future research as follows:
- 1.
Error Patterns and Performance Variations
Despite achieving 90.73% overall accuracy, our model demonstrates systematic error patterns that warrant critical examination. Analysis reveals confusion primarily between calm and sad emotions (approximately 4.6% bidirectional misclassification), while angry emotions have the lowest recognition rate (88.85%) and happy emotions the highest (93.02%). These performance discrepancies reflect fundamental challenges in emotion recognition for children with autism rather than mere algorithmic limitations.
The calm–sad confusion pattern likely stems from the documented “flat affect” characteristic in autism spectrum disorders, where similar facial configurations may represent different internal emotional states. This inherent ambiguity presents a theoretical challenge that transcends technical solutions, suggesting potential limitations in discrete emotion classification approaches for this population. Similarly, the lower recognition rate for angry emotions may reflect the heterogeneous manifestation of negative emotional states in autism, where expressions may range from subtle microexpressions to pronounced but atypical configurations.
Our subject-level analysis reveals substantial performance variations across individual participants, with recognition accuracies ranging from 82.4% to 97.1%. Lower performance was consistently observed for minimally verbal participants and those with more severe autism symptoms. This variability indicates that autism severity and communication ability significantly influence emotional expression detectability, a critical factor not explicitly accounted for in our current model architecture. Future work should explore adaptation mechanisms that can accommodate this individual heterogeneity, potentially incorporating autism severity metrics as model parameters to enable more personalized emotion recognition.
- 2.
Dataset Limitations
The dataset, comprising data from only 33 children at a single educational facility in East China, introduces significant constraints on the generalizability of our findings, despite our basic data augmentation efforts through horizontal flipping and Gaussian blurring. This regional concentration raises critical questions about potential cultural influences on emotional expression patterns. Research demonstrates cultural variations in emotional display rules and expression intensity, potentially limiting our model’s applicability across diverse populations. Additionally, our dataset concerns children primarily aged 4–5 years, neglecting developmental trajectories in emotional expression across the lifespan of individuals with autism.
The relatively small sample size (33 participants) provides insufficient representation of the heterogeneity within autism spectrum disorders, particularly regarding symptom severity, verbal ability, and comorbid conditions. While we implemented careful subject separation during data division to prevent data leakage, our current augmentation approach addresses only a narrow range of potential variations. Future work should implement more comprehensive augmentation techniques including random rotations to simulate natural head movements, brightness and contrast adjustments for lighting robustness, and advanced methods such as mixup augmentation or generative approaches to create synthetic training examples. For speech data, time stretching, pitch shifting, and random time masking could further diversify the training samples and better account for the spectrum of communication variations in autism.
The class imbalance in our dataset (calm emotions over-represented at 31.7% compared to happy emotions at 19.6%) may bias the model toward better recognition of more frequently encountered emotional states, contributing to the observed performance disparities between emotion categories. Our data collection approach in semi-natural settings, while more ecologically valid than posed expressions, still occurred within structured rehabilitation environments, potentially missing emotional expressions that emerge in less constrained contexts. This methodological limitation may affect the model’s performance in real-world applications where environmental factors and social contexts differ significantly from training conditions, introducing additional sources of error not accounted for in our controlled evaluation.
Subsequent studies should gather data from diverse countries and regions with larger sample sizes to further validate the model’s applicability and universal effectiveness across different cultural contexts and autism presentation variations, while also incorporating a wider range of emotional states and purposefully sampling children across different points of the autism spectrum to better capture the heterogeneity of autism expression.
- 3.
Model Architecture Considerations
While we selected CvT as our primary model architecture due to its performance advantages, future work could explore more recent transformer variants such as the Swin Transformer with its hierarchical representation capabilities or ConvNeXt, which combines CNN efficiency with transformer-like performance. These architectures may offer additional performance improvements for autism-specific emotion recognition tasks, potentially addressing some of the current model’s limitations in distinguishing between similar emotional states.
Our current architecture processes individual frames rather than temporal sequences, missing potentially important information about expression velocity and coordination that characterize emotional states in autism. The fusion approach employs fixed attention weights after training, lacking adaptability to adjust feature importance dynamically for individuals with unique expression patterns. These architectural limitations could be addressed in future research through temporal modeling and adaptive fusion mechanisms.
- 4.
Model Analysis and Optimization
The current study did not conduct comprehensive ablation studies to determine the exact contribution of each model parameter to the overall performance. Future research should investigate the sensitivity of model performance to key parameters such as the number of attention heads, convolutional kernel sizes, and hidden layer dimensions to optimize the architecture specifically for emotion recognition in children with autism.
Additionally, our performance evaluation focused primarily on accuracy metrics rather than interpretability or computational efficiency. Future work should explore techniques such as knowledge distillation, structured pruning, and quantization to enhance computational efficiency while preserving the high accuracy essential for effective emotion recognition in autism intervention settings.
- 5.
Speech Feature Exploration
In speech signal modalities, only the most typical features of the Mel spectrogram and MFCCs are taken into account, while other features such as the linear prediction cepstrum coefficients (LPC), wavelet transforms, line–spectrum pair parameters, and amplitude ratios are not investigated. The impacts of individual features and feature combinations on the efficacy of emotion recognition models should be further examined in future research, and experiments are required to identify the speech elements that most accurately represent the emotions associated with autism. Future work should also explore end-to-end models like WaveNet for speech processing, which might capture temporal dynamics more effectively.
- 6.
Computational Efficiency Optimization
While our multimodal fusion approach achieves superior accuracy, its practical deployment in resource-constrained educational environments requires further optimization. Future work should explore techniques such as knowledge distillation, structured pruning, and quantization to enhance computational efficiency while preserving the high accuracy essential for effective emotion recognition in autism intervention settings.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







