1. Introduction
Recently, there has been a surge in document-based malicious attacks, particularly in formats such as Portable Document Format (PDF), Hangul Word Processor (HWP), Word, and Excel, posing a threat to users, including large public institutions and corporations [
1]. The widespread use of PDF and Office files, such as Word and Excel, across various devices, makes them extremely popular choices for malware writers as playload mechanisms. The evolution of malware makes it increasingly challenging to detect and understand its inner workings. While basic security measures like virus scanners were once effective in preventing simple attacks, modern threats employ more advanced techniques [
2]. SonicWall Capture Advanced Threat Protection has observed a year-over-year increase in new PDF-based attacks, with PDFs now ranking among the top malicious file types [
3]. In fact, SonicWall found nearly 9% of previously seen malware files in Office formats and over 14% in PDF files, indicating a growing prevalence of document-based attacks. During recent crises, such as the COVID-19 pandemic or the war between Russian and Ukraine, attackers have exploited opportunities to pilfer confidential information from organizations [
4,
5]. Malicious word files camouflaged as pandemic-related financial documents have been widely distributed. Document-type malware conceals a malicious code within the document itself, making it challenging to detect. If the malware has a .exe extension, the recipient will likely be suspicious. However, if it lacks an executable format, it can still be activated through tasks such as opening emails or editing documents. Consequently, document-type malware spreads by exploiting this vulnerability [
6].
The Hangul Word Processor is a Korean word processor developed by Hancom Inc., a South Korean company, and is predominantly used in South Korea. Its widespread use in South Korea increases the potential threat to users, as attacks well versed in the software may target it with increased aggression. North Korea is recognized for conducting cyberattacks as part of its asymmetric warfare strategy [
7], utilizing document-based malware to pilfer confidential information, pursue financial gain, and gather intelligence [
8]. Particularly, North Korea targets government agencies to leak national secrets. However, North Korea’s hacking endeavors extend beyond South Korea; they also aim to target America and other nations. According to SonicWall’s threat research [
3], the Asia–Pacific region has witnessed the most significant increase in malware volume at 38%. Therefore, studying the malware discovered in HWP would help determine North Korea’s hacking capabilities and facilitate the enhancement of new techniques for analyzing the composition of malware samples.
Compared to executable files, there has been little research conducted on document-type malware. While PDF has received some attention, other document files, especially HWP, have been largely overlooked. Research into malicious code analysis using document files is essential for preventing the dissemination of malware through such files especially targeting government agencies and corporations. Additionally, HWP malware encompasses different families, boasting a wider array of malware than MS Docs and PDFs. Therefore, it is imperative to conduct studies and analyses that correlate the functionalities and behaviors of malware samples with their respective families to gain deeper insights into their composition.
Numerous malware detection models rely on bytes, OPCode (operation code) [
9], and application programming interface (API) call sequences [
10] for executable files. However, extracting a scripting code from document-type malware presents significant challenges due to its release after compilation in an executable file. Extracting scripting codes from documents can reveal insights into how the malware was constructed and operates on the victim’s system. Leveraging natural language models [
11,
12] becomes advantageous as we can extract and analyze a scripting code from document-type malware.
Previous research on document-based malware needs to be expanded to develop a comprehensive model applicable to various document types, as current efforts focus on extracting features from malicious files in HWP and PDF documents. To effectively detect malware and its variants, it is imperative to employ generic methods that are not reliant on specific samples. Deep models are good at extracting features without human intervention in feature definition, making them ideal candidates for constructing a generic model. Therefore, using Transformer, we propose a language model known for its versatility across multiple languages for developing the document-type malware detection and family classification model. Transformer offers several key advantages over traditional machine learning models, including an attention mechanism focusing on relevant segments of the input sequence during prediction. This mechanism proves particularly useful for malware analysis, enabling the identification of key patterns and dependencies within the scripting code of malware samples. Furthermore, the context-aware nature of Transformer helps it to capture relationships between different segments of the malware code, leading to more accurate detection. We require a model capable of handling long-range dependencies to comprehend extensive relationships effectively.
To convert script codes into meaningful numerical vectors (as a deep learning model exclusively accepts numerical input), we propose employing a Word2Vec model [
13] on the malware script codes. Furthermore, to solve the class imbalance issue within the malware families and improve detection performance, we use a generative adversarial network (GAN) operating at the script code level.
Our first focus is on HWP files. Our detection framework can be applied to PDF or RTF file formats; an HWP document shares the same object linking and embedding (OLE) structure as MS documents and rich text format (RTF) files. A malicious code is often embedded within objects, and extracting a malicious code from document objects is feasible. The main contributions are listed as follows:
We propose a Transformer model tailored for document-based malware detection and classification. Our method is designed to perform detection at both the stream and file levels.
We propose using a word-embedding model, called MalCode2Vec, which we pre-train on malware script codes.
We propose employing a generative adversarial network to make malicious fake samples. These generated samples are used to solve the class imbalance problem within the malware family.
Our manuscript is organized as follows: In
Section 2, we review related research and explore different approaches.
Section 3 describes the proposed malware detection and classification model.
Section 4 presents the experiment results. In
Section 5, we address the discussion from the experiment results. Finally,
Section 6 provides conclusions to this paper.
2. Related Works
Most document-based attacks often include a scripting code to execute malicious code activities. Common scripting languages like JavaScript and VBScript are frequently used to exploit document vulnerabilities through API calls, ActionScript code, or file embedding [
14]. In our review of previous works focusing on static analysis, particularly for document-based malware, we found a range of models spanning from machine learning to deep learning techniques. Laskov and Šrndić (2011) developed a detection model specialized in malicious JavaScript-bearing PDF documents [
15]. Their static analysis involves examining lexical features in JavaScript. They achieved an 85.17% true-positive rate on large datasets from the VirusTotal portal. Al-Taharwa et al. (2012) [
16] analyzed the existence of obfuscated JavaScript (JS) codes. They developed a JS obfuscation detector utilizing an abstract syntax tree for a context-based feature extraction. Their datasets were from real-world web pages. Results showed that the RedJsod detector achieved 97.5% accuracy. Stokes et al. (2019) developed the ScriptNet system to detect malicious JavaScript [
17]. Their model combines convolutional neural networks (CNNs) and long short-term memory (LSTM), capable of processing JavaScript files as byte sequences. This model achieved an 81.66% true-positive rate and a false-positive rate of 0.50%. Jeong, Woo, and Kang (2019) proposed using CNN to detect malware in bytes of PDF files [
18]. Instead of feature engineering on malware documents, the proposed model transforms a stream into byte sequences, making it applicable to any document. Jeong et al. also proposed HWP malware detection using spatial pyramid average pooling (SPAP) in the CNN model [
19]. They experimented with various pooling layers in the CNN model and proposed an appropriate pooling method for the byte stream, achieving a 99% accuracy for approximately 6000 samples. Jeong, Mswahili, and Kang proposed byte level-malware detection using CNN models and SPAP [
20]. They used an aggregate function to digest the outputs of stream-level results to obtain file-level results.
Table 1 provides a summary of related studies, highlighting their features and algorithms.
Attention-based models have gained widespread usage across various domains. Choi et al. (2020) applied the attention mechanism to extract and highlight features from PE files automatically [
23]. Compared with CNN and skip-connected LSTM models, the attention model achieved an accuracy of 96.27%. In Demirci’s paper [
24], bidirectional LSTM (BiLSTM) and generative pre-trained Transformer 2 (GPT-2) were used to study and detect a malicious code in assembly instructions extracted from PE files. The study aimed to detect malware by classifying assembly instructions as benign or malicious at the sentence and document levels. Additionally, the authors trained the GPT-2-based model, observing an improvement in detection performance. Rahali and Akhloufi used bidirectional encoder representations from Transformer (BERT) to detect malware from the source code of Android applications [
25]. In addition to binary classification for malware detection, multi-classification was performed to classify the dataset into 11 different malware families. In comparison with other pre-trained language models, the BERT model demonstrated superior accuracy in both binary and cross-category classification tasks. Phung and Mimura used an oversampling method on an unbalanced dataset and proposed Doc2Vec to detect malicious JavaScript using [
22]. Features that extracted using Doc2Vec and the attention model were fed to a support vector machine (SVM). Results showed that while the attention model exhibited an excellent overall detection rate, the Doc2Vec model achieved the highest precision rate of 0.989 and the highest recall rate of 0.722. Our study [
26] investigated HWP malware detection using a Transformer model, achieving an F1 score of 82.90%. While the model demonstrated the ability to identify malicious patterns, its performance was hindered by data scarcity, limiting its generalization to a wider range of malware variants. In this extended work, we enhance feature representation by pre-training Code2Vec, which captures both character and word-level semantics more effectively. Additionally, we employ SeqGAN for data augmentation, addressing data scarcity and improving the model’s robustness. This combination leads to superior classification performance and better adaptability to emerging malware threats.
Through the literature review, several research gaps were identified as follows: First, many studies have developed detection models primarily focused on executable files. There is a noticeable absence of research on document-based malware, despite the increasing prevalence of document malware threats. Second, although bytes are commonly used as input for deep learning-based language models, script codes remain underexplored, despite their potential to benefit significantly from such models. Some studies use an n-gram language model to extract n-grams from bytes and apply machine learning models. Third, although deep learning models such as CNN and recurrent neural networks have been widely used, the state-of-the-art model known as Transformer has not yet been applied to a scripting code. Attention-based language models, which effectively focus on the malicious part in sequential input, have shown promise in malware detection. To overcome these drawbacks, we propose the development of a language model specifically tailored for malware detection.
3. Methodology
Based on the research gaps identified through a extensive literature review, we aim to achieve the following objectives: First, we intend to use the language model to analyze script codes, including tags. Script codes offer advantages over bytes in terms of model size and preserving the semantics of generative patterns due to their adoption of word-level embedding. While only 2-gram-byte embedding is feasible in bytes (character level), word-level embedding is attainable in script codes. A language model is more appropriate for script codes as word-level embedding preserves semantics. Second, we recognize the Transformer model’s superiority over other deep learning models due to its attention mechanism, which is essential for highlighting malware’s maliciousness in certain segments, making the attention mechanism invaluable for accurate detection. Third, we aim to enhance malware detection and improve accuracy in identifying malware families through data augmentation using sequence GAN.
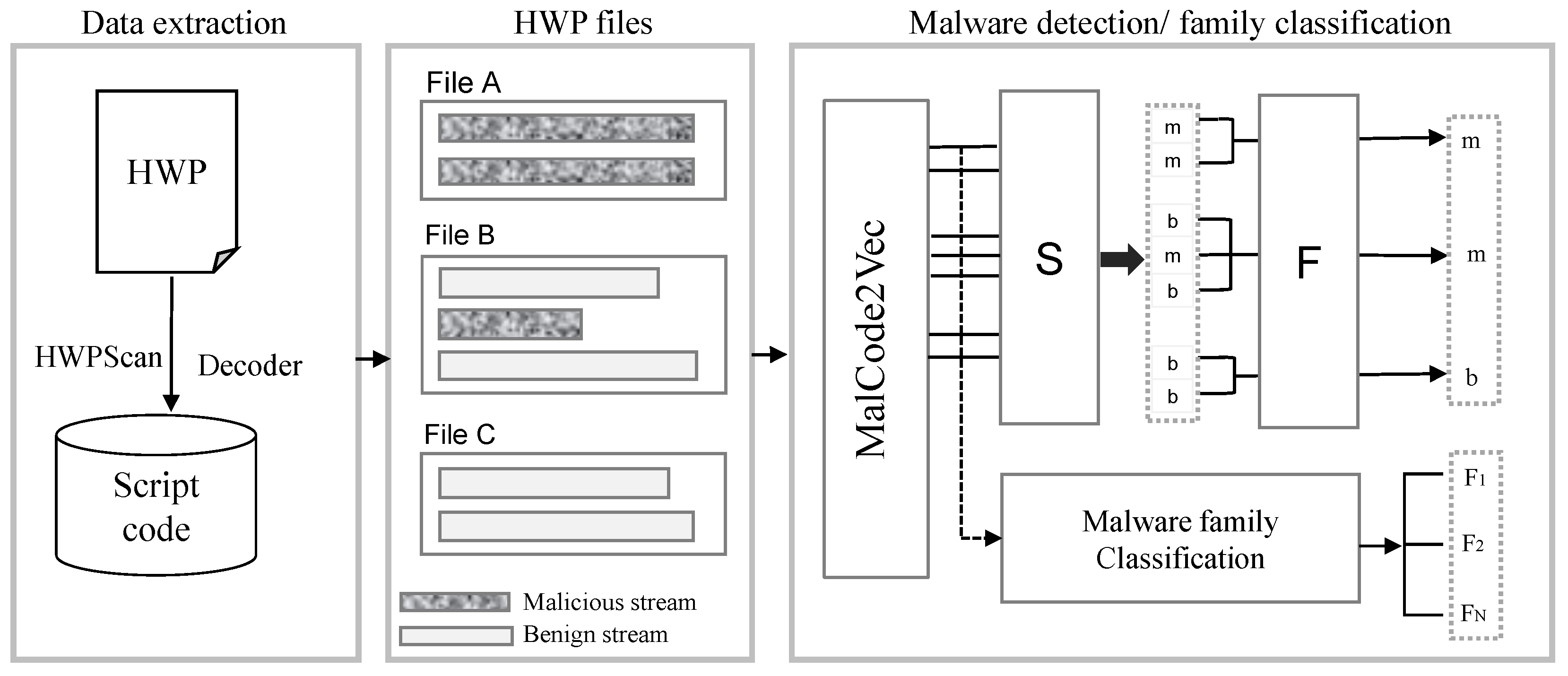
The framework for HWP malware detection and a family classification framework is depicted in
Figure 1.
3.1. OLE Structure of HWP Document
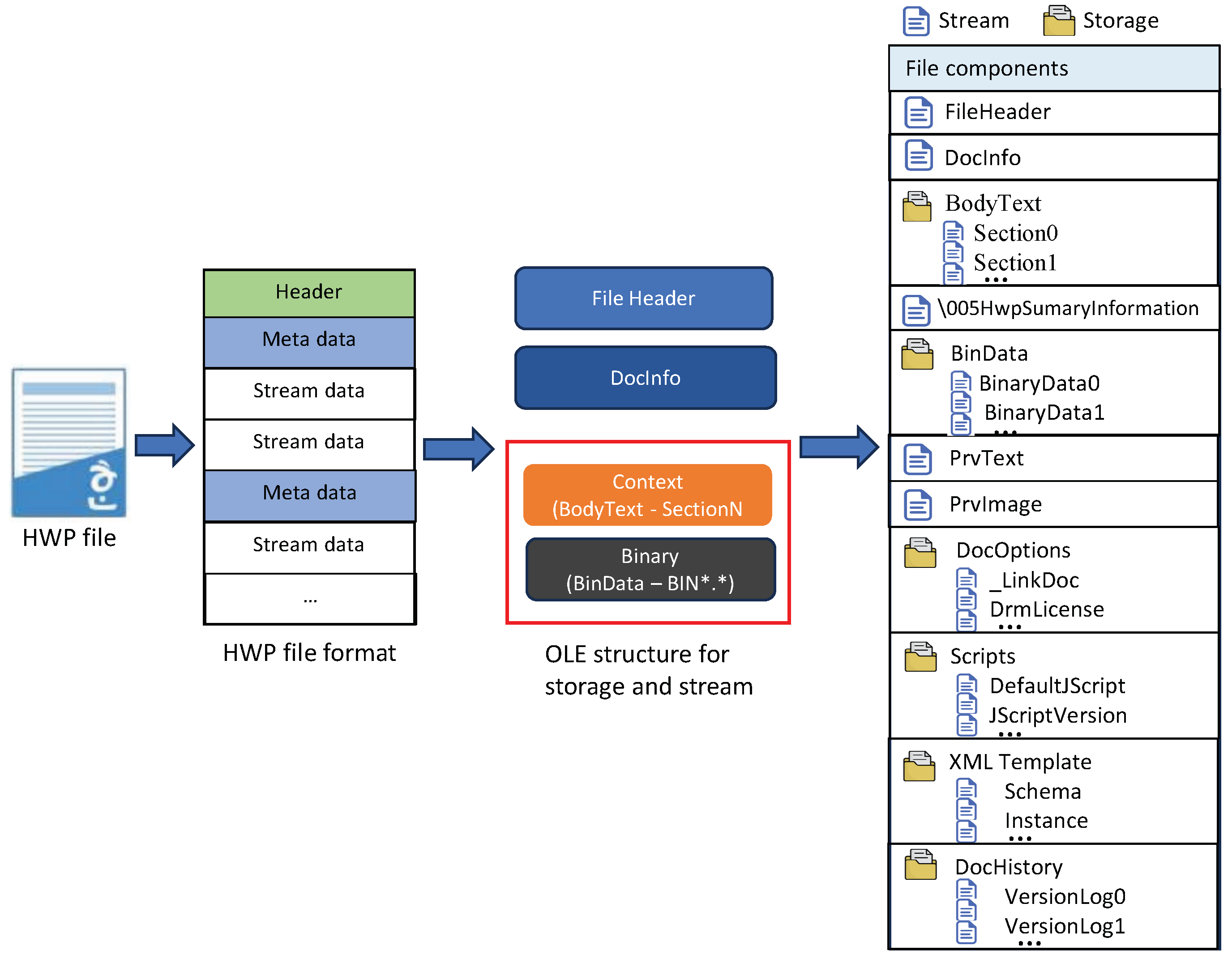
Hangul files are structured using the Compound File Binary Format (CFBF), which employs Object Linking and Embedding (OLE) to connect data such as images, tables, and other elements across files that adhere to this format. The CFBF format is organized into a hierarchical system of directories (storages) and files (streams), where data are stored within streams nested inside storages. This research focuses specifically on streams that may contain a malicious code. HWP files are organized in a tree-like structure, with RootEntry serving as the top-level element. Key components such as the file header, document information (DocInfo), preview text, and preview images are stored within streams. The text visible in the HWP viewer is distributed across multiple streams located in the BodyText storage, which includes paragraphs, tables, drawings, and textual content. Binary data are also stored in streams within memory, with each body text and binary data segment following a record structure that includes a record header and the corresponding data. HWP files have following structure shown in
Figure 2. Documents are constructed using tags, which differ based on the document format, such as MS Word, PDF, or HWP. Malware is often created by embedding malicious streams, such as shellcode or script language, within the body text or binary data. Streams containing a malicious code typically have a longer length compared with normal streams. As a result, this study proposes a detection model designed to identify malicious streams. Files found to contain such streams are classified as malware.
3.2. Script Codes
Malware often undergoes an obfuscated or packing process to evade the detection model. These techniques involve writing a code in a programming language, altering the file structure format to make it challenging to interpret [
10]. Encrypting or compressing executable files complicates the extraction of script codes responsible for generating executable files. Malicious binaries are encoded and concealed within documents, necessitating decryption to analyze the script codes. Tags, binaries, and scripts become observable after decryption, which we refer to as script codes.
Figure 3a shows an example of hex bytes from a malicious file containing encrypted content stored in a stream, while
Figure 3b displays an example of decoded text from
Figure 3a. ‘/limit’ and ‘/len’ serve as examples of tags used in an HWP document.
Script codes are extracted from streams within the file. A single file contains multiple streams, some of which may be compressed or encrypted, depending on the file type. The script code is from both the compressed and decompressed streams since a malicious code is inserted into streams differently. A decoder is used to convert raw bytes (hex) into ASCII, rendering them printable and human-readable. Decoder information is documented in files, although non-standard decoders are used for malware. Printable ASCII characters, comprising English upper- and lowercase letters, numbers, and symbols such as parentheses and periods, are extracted from PostScript, VBA script, or JavaScript. Key observations regarding scripting codes in malware encompass Windows Application Programming Interfaces (APIs) such as GetFileSize, FindFirstFileW, GetDriveTypeW, CreateDirectoryW, CreateProcessA, ReadFile, CreateFileW, FindClose, MoveFileA, lstrcatW, RegOpenKeyExW, RegCloseKey, RegSetValueExA, RegOpenKeyExA, and ShellExecuteA; file names such as kernel32.dll, WSHELL32.dll, and user32.dll; class names such as Descriptor, Object, CONNECT, Agent, Base, User, and compatible; and phrases such as ‘not enough for stdio initialization’ and ‘pure virtual function call’.
3.3. Models
The proposed model is designed to detect HWP malicious documents using a Transformer-based language model to leverage the linguistic characteristics (context) of malware. HWP malware is often encoded to evade detection; thus, it is first decoded into a human-readable code format. To embed this transformed code in a manner similar to language embedding, we implement MalCode2Vec. Since text cannot be directly processed in language models, it must be converted into numerical representations. However, instead of arbitrary numbers, these values should encapsulate the relationships between words, embedding them into a meaningful vector space. Similarly, in malware analysis, malware code chunks are converted into numerical values that retain their semantic relationships. This study not only determines whether a document is malicious but also classifies the type of malware. However, there is a class imbalance among different malware types. In classification tasks, class imbalance results in the model failing to learn sufficient representations for the minority class, leading to reduced performance for those classes. To address this issue, we employ a data augmentation approach to generate additional samples for the minority class. The sample generation process utilizes a generative adversarial network (GAN). The rationale for using a GAN instead of a large-scale language model that generates grammatically refined text is that the generated samples do not need to function as actual malware but merely need to capture the characteristics of malware. Hence, a smaller model that effectively incorporates these characteristics is preferred.
3.3.1. Transformer
We propose a Transformer-based model for malware detection and also malware family classification, using the script code extracted from HWP files. A Transformer is a neural network architecture that introduces attention [
27] for sequential data. Similar to recurrent neural networks, this architecture transforms one sequence into another using an encoder and decoder. Recurrent neural networks excel at processing sequential data; their sequential computation hampers parallelization, which becomes critical for longer sequence lengths [
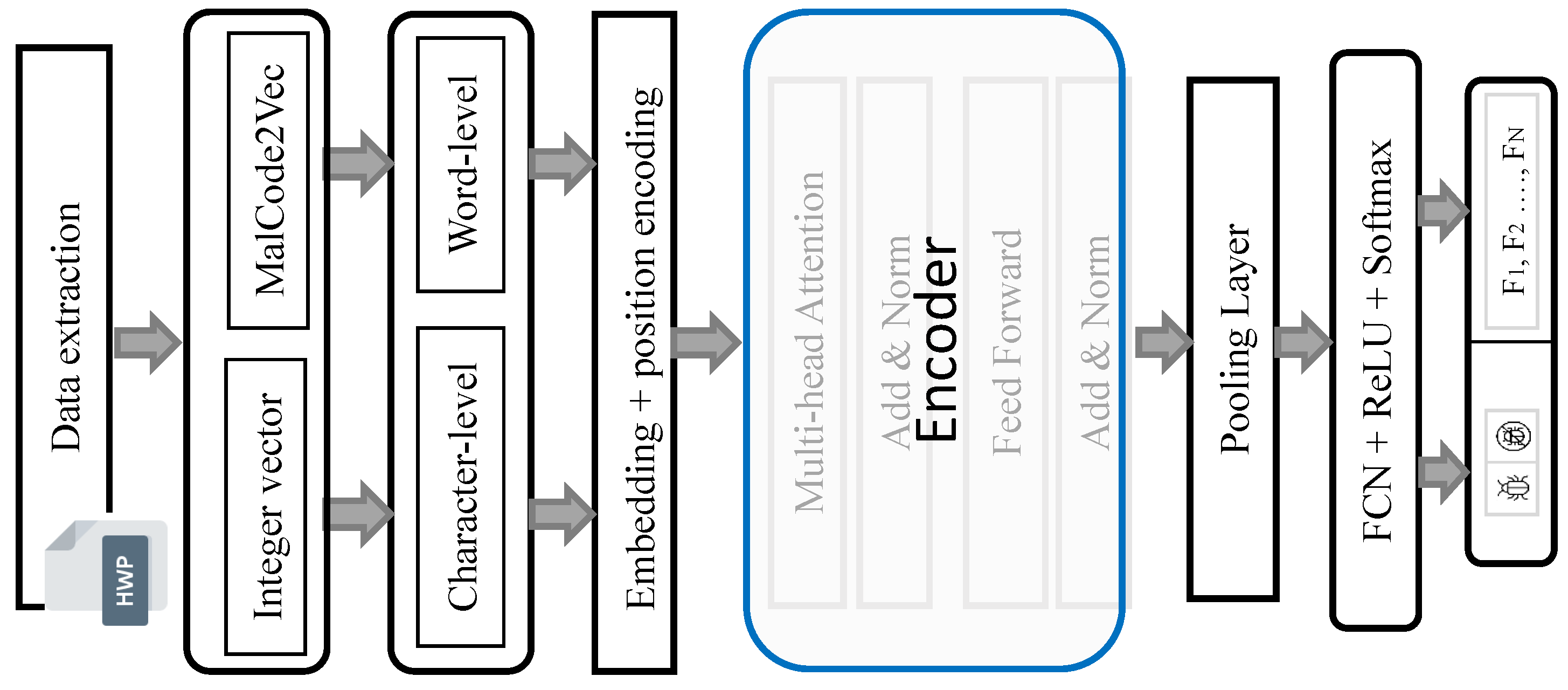
27]. With its self-attention mechanism, the Transformer has shown to be effective in handling sequence-based input without relying on recursion. The attention mechanism learns internal dependencies by calculating correlation values of internal features within the script codes. This enables the identification of the main patterns through the weighted average of feature representations. We exclusively use the encoder part of the Transformer to generate representations containing information, determined by the attention of the input sequence. In addition to the Transformer layer, the model also features a feed-forward network, a pooling layer, and two fully connected layers, as depicted in
Figure 4.
3.3.2. MalCode2Vec
We need to convert input text into a numeric vector representation to make it feedable to the deep learning model. For example, given the script code from our dataset s1 = ‘BC dcesdlocdhgpDERXGdces nIJ)R7J)R7KKKH BCZ’, and s2 = ‘exch dup length2 index length add string dup dup’, we can encode them using one-hot encoding. In one-hot encoding, each token of the sentence is represented as binary features in a row, where a feature receives a 1 if it corresponds to the original category and 0 otherwise. Thus, if our vocabulary consists of the words [BC, dcesdlocdhgpDERXGdces, nIJ)R7J)R7KKKH, BCZ, exch, dup, length2, index, length, add, string], the word ‘exch’ is represented as [0,0,0,0,1,0,0,0,0,0,0]. We employed two approaches to generate vector representation: (1) integer encoding and (2) MalCode2Vec. Integer encoding transforms each text into sequential integers ranging from one to the total number of features. In the example, two sentences are represented as [1 2 3 4] and [5 6 7 8 9 10 11 6 6], where 1∼11 corresponds to the defined vocabulary. However, this method does not capture the relationship between words; it only sequentially maps each word into a number. Language naturally has a distancing mechanism based on associations between words or characters. There is an association between script codes in tags and script languages. Therefore, we constructed a script code association dictionary using Word2Vec to capture these associations better.
Word2vec is designed to learn associations between words from a large corpus using a neural network model. We constructed a pre-trained embedding model, MalCode2Vec, using our malware dataset and used it to represent malware. The model was trained using the same architecture as Word2Vec [
13]. The efficiency of Word2Vec stems from its ability to group vectors of related words (e.g., malicious and malware). The model learns the vector representation of words from the training data. Words with common contexts in the corpus are allocated close to each other in the vector space, operating under the assumption that the meaning of a word can be inferred from its nearby words. The MalCode2Vec model was obtained using continuous bag-of-word (CBoW) and skip-gram methods. In the CBoW model, the model learns to predict a target word from the surrounding context words.
The skip-gram model is the inverse of CBoW; it predicts surrounding words given the target word. The skip-gram model excels at capturing semantic relationships (i.e., ‘malware’ is closer to ‘virus’), where CBoW is more proficient at learning syntactic relationships (i.e., ‘virus’ is close to ‘viruses’). Skip-gram functions efficiently with a small amount of data, even representing rare words well, whereas CBoW performs better with more frequent words.
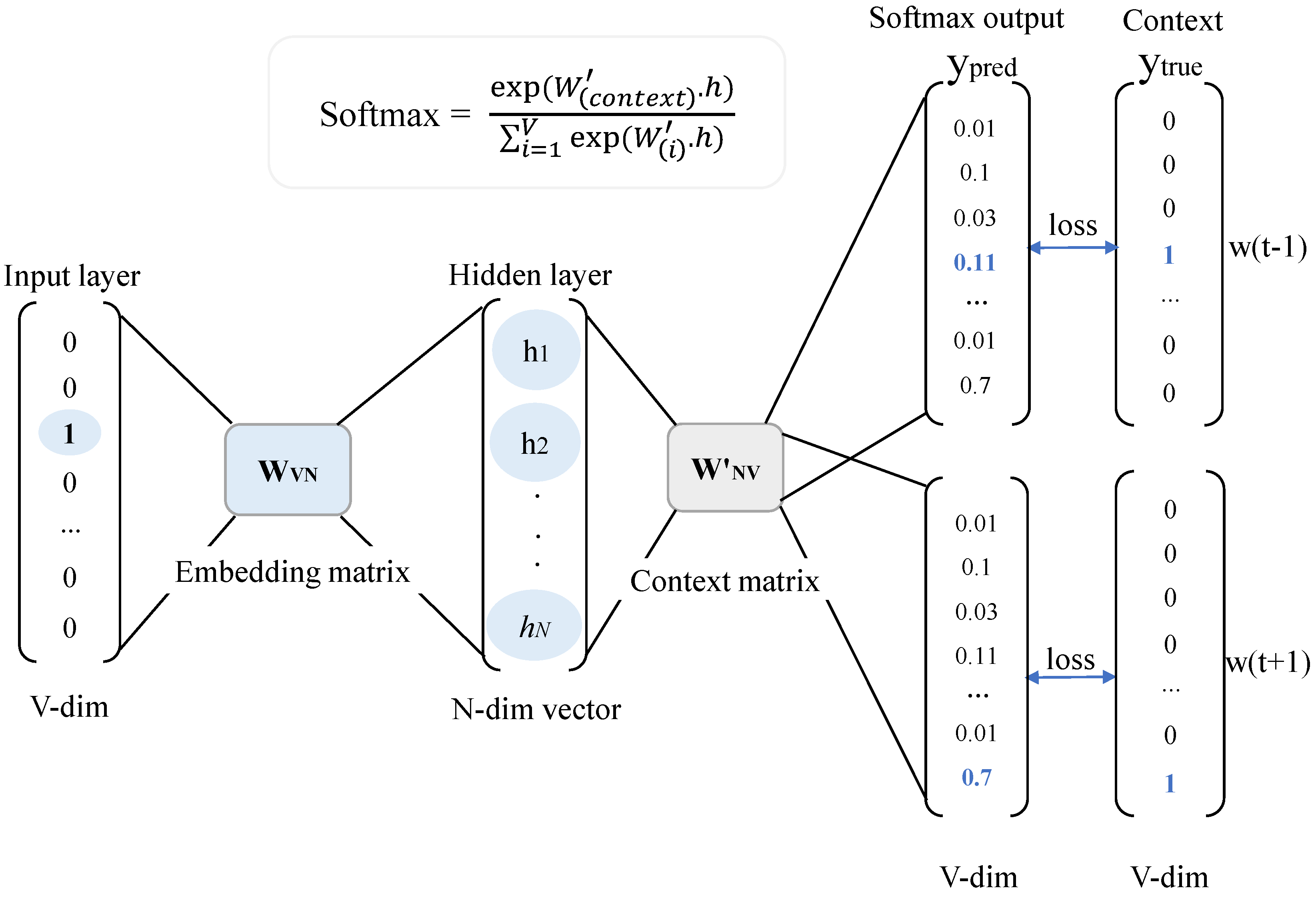
Figure 5 shows the skip-gram model. The input layer comprises a one-hot encoded vector of size
V (vocabulary size), where every vector is zero except for the target word
t. The random initialized input weight matrix (W
VN) transforms the input into a hidden (projection) layer of an
N-dimension vector. Each row of W
VN represents the
N-dimension vector associated with the respective word in the input layer. The output weight matrix, W’
NV, serves as the embedding matrix for context words. Multiplying the output weight matrix within the hidden layer yields a dot product vector of size
V. The softmax function is then applied to compute the probability distribution (score) of each unique vocabulary in
V appearing in the context of
t. Finally, the error is calculated between the score and the one-hot vector of the context words, and optimization is performed through backward propagation. In our study, we trained the skip-gram model with a vector length of 100 features and a window size of three.
3.3.3. SeqGAN
GAN, as proposed by [
28], is a deep learning-based model used for generating realistic data from random input. GAN comprises two deep learning networks, the generator and discriminator, both trained collaboratively. The discriminator
D is tasked to distinguish between real (training data) and fake (generated) data, while the generator
G aims to deceive
D by producing new samples that closely resemble real data, stemming from random input distribution. GAN training operates on a minimax game framework, where each network strives to maximize its respective benefits. While GANs (conditional GANs, Wasserstein GANs, etc.) have achieved notable success in image generation, they are primarily designed to generate real-valued, continuous data. Therefore, generating sequences of discrete tokens, such as text, poses a significant challenge. The discrete nature of generated data makes it difficult for
D to guide
G on the outputs.
SeqGAN [
29] extends GAN for sequential generation tasks. In this framework, the generator is regarded as a reinforcement learning agent, where each generated token represents a state and the selection of the next token constitutes an action.
A discriminator is trained to provide rewards for complete sequences, and Monte Carlo search is employed to sample complete sequences.
The generative model was constructed using LSTM [
30], while CNN was used as the discriminator.
The effectiveness of the GAN model was demonstrated in [
31], where a CNN-based ACGAN was applied to grayscale images of malware. This approach notably enhanced the generality of the detector. We utilized the SeqGAN model for malware families, particularly focusing on addressing a few highly imbalanced classes.
4. Experimental Results
4.1. Dataset
Our dataset comprises 626 malicious HWP files and 216 benign files; benign files were sourced from websites, usually originating from government agencies. Malicious files were provided by a Korean cybersecurity company. From 842 files, we collected 6782 streams, (benign: 5470; malicious: 1312). Subsequently, the data were split into training and testing sets, with a ratio of 85% and 15%, respectively. The statistical distribution of benign and malicious streams was 4657:1107 for training and 813:205 for testing.
The streams were categorized as either malicious or benign, and further categorized into a specific malware family. Given that a single file comprises several streams, as mentioned in
Section 3.1, the classification process begins with per-stream prediction. Each stream is evaluated for maliciousness. Subsequently, the file-level detection is obtained based on the aggregation of the stream-level results.
4.2. Malware Families
This section describes various malware families and their potential utilization as malicious vectors.
Table 2 presents an overview of the seven families along with their distribution within our dataset.
4.2.1. Encapsulated PostScript (EPS)
EPS is a file format used for graphics, particularly in professional and high-quality image printing. These files are created with a PostScript code, necessitating a separate interpreter for execution. However, due to vulnerabilities in the interpreter, EPS files can be exploited to run a shellcode.
Figure 6 shows an example of EPS malware, where the OLE viewer discovers EPS within the body text. When inspecting the hex representation of an EPS file, we observe a string that initiates EPS as highlighted in yellow. Decrypt and decompress the hex; it reveals that this file contains shellcodes along with EPS script codes responsible for executing these shellcodes.
4.2.2. Shellcode
It refers to a small piece of code executed by a target program following the exploitation of a vulnerability, enabling control over the target system. Attackers often embed malicious shellcodes within macros to execute unauthorized actions when the document is opened.
4.2.3. Portable Executable (PE)
This is a file format used for executable files. Attackers can employ various techniques to obfuscate a malicious code within the document’s structure, such as embedding malicious scripts or exploiting file format vulnerabilities.
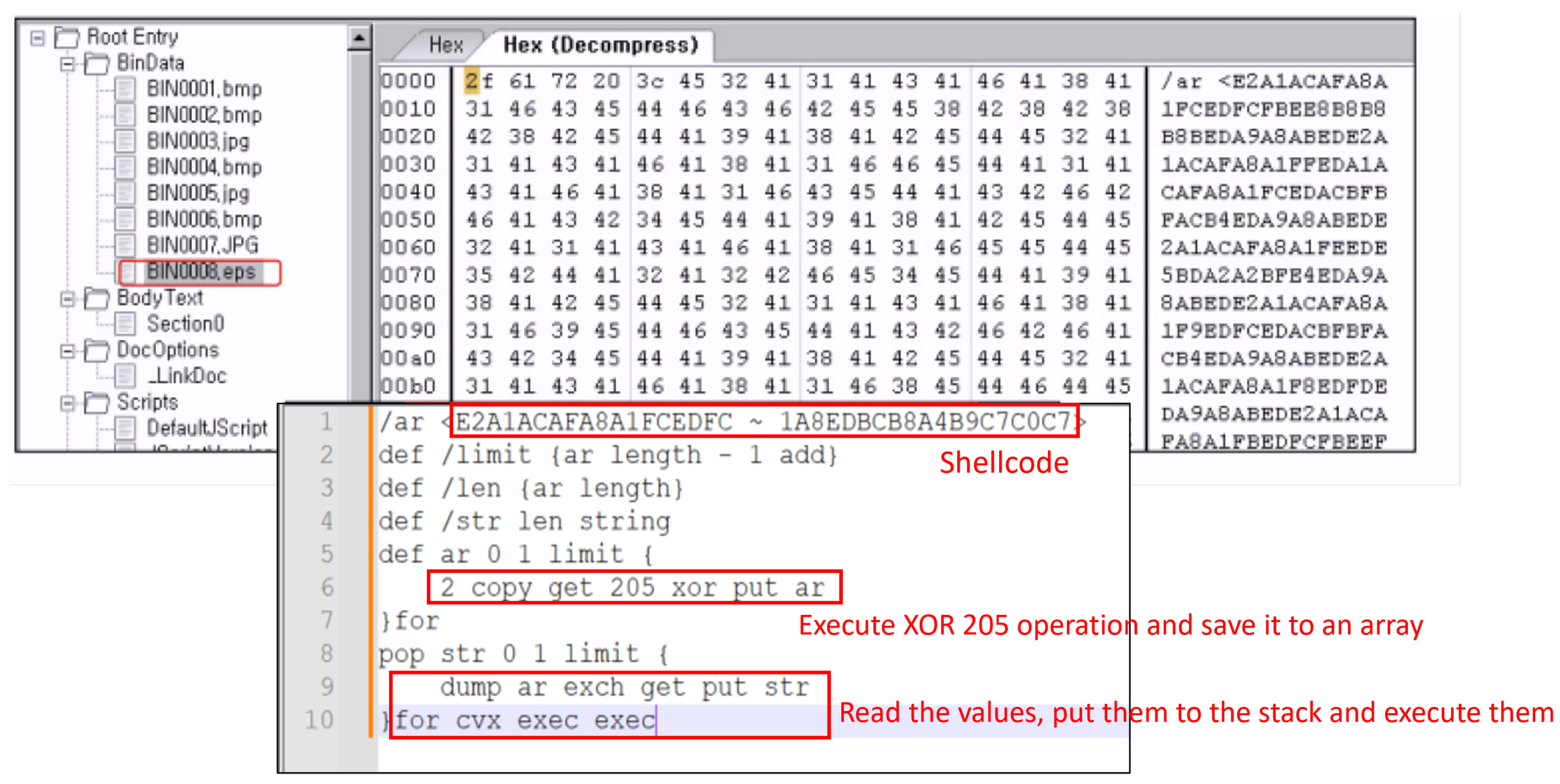
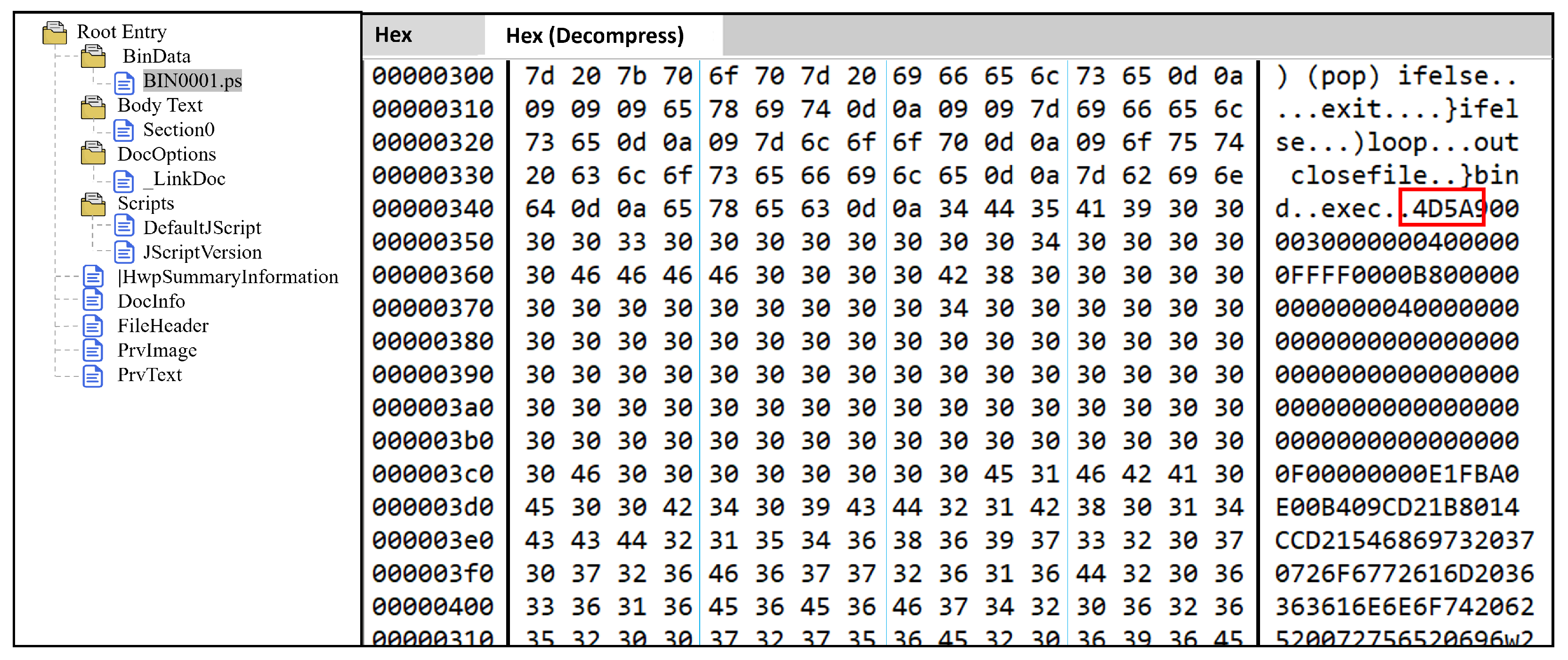
Figure 7 is an example of a case where PE is included within an HWP file as it is. Upon opening the file with the HWP OLE viewer, the PostScript codes are displayed, and at the bottom, the DOS signature indicating the beginning of the PE file, 4D 5A (MZ), is shown, as depicted in
Figure 7. For more details, The highlighted file, BWAV0.EPS, is likely an EPS file containing a malicious code. The image displays HEX values alongside their ASCII representation, extracted from the EPS file. Repetitive patterns such as 41 41 41 suggest encoded or obfuscated data. This section contains an embedded shellcode that is responsible for executing malicious actions: ‘dst/limit’ defines a specific length. ‘copy get 205 xor put st’ performs an XOR 205 operation. The XOR 205 operation is used to restore obfuscated data before executing them, which indicates self-decrypting shellcode behavior. Then, it stores the result in an array. ‘The for … loop’ reads the values, pushes them onto the stack, and executes them.
4.2.4. Visual Basic Action (VBA) Script
VBA is a scripting language often used to provide functionality in program development environments. While VBA scripts offer valuable features, they can also be exploited maliciously, often when embedded within program or document files to execute alongside them. VBA macros use the VBA application to create custom user-generated functions. The flexibility of a VBA macro renders HWP vulnerable to exploitation. Similar to the Microsoft Office program, macros in HWP are configured akin to a programming language, allowing users the ability to perform a wide range of actions rather than a simple keystroke repetition. This inherent flexibility exposes VBA macros to potential misuse as a malicious code.
4.2.5. Iframe
It is an HTML element used to embed another HTML element within a web page. The 〈
iframe〉 tag is usually found at the end of the malware files. A malicious iframe has the potential to redirect the victim to any domain, as shown in
Figure 8.
4.2.6. Heuristic Family
It refers to samples containing malicious RTF files, JavaScript, keywords or patterns, etc. Attackers can use obfuscation techniques to conceal the malicious code within a file or modify the behavior of a file to make it appear benign during initial analysis.
Selected samples underwent analysis against known signatures to identify malicious actions. Subsequently, these actions were executed in a virtual environment for validation. A rule-based system was developed based on the sample analysis to determine the respective families to which a sample belonged. This served as the ground truth for classifying malware families. To address data imbalance in the three classes, VBS, iframe, and EPS, data augmentation was conducted using a sequence generative adversarial network (SeqGAN) [
29].
4.3. Baselines
BERT, CNN, and a large language model were selected as reference models for comparison with the Transformer-based malware detection model. BERT is a language model based on the Transformer encoder structure, designed for bidirectional learning that considers both left and right contexts simultaneously. It is pre-trained using two objectives: the Masked Language Model (MLM), which involves masking certain words and predicting them, and Next Sentence Prediction (NSP), which determines whether two given sentences are consecutive. To assess whether this pre-training approach influences malware detection, BERT was chosen as a comparison model. The CNN model, although primarily used for image processing, was selected because it is effective in learning local patterns in text data.
4.3.1. Bidirectional Encoder Representations from Transformers (BERT)
BERT is a deep stack of bidirectional Transformer-based encoders that uses the attention mechanism [
27] to learn the relationship between words. It uses WordPiece tokenization to generate a fixed-size vocabulary encompassing single characters, common words, and subwords from the training corpus. BERT accepts input data in a specific format with limited input sequences of 512 tokens. In our study, we pre-trained a custom code-text BERT model using malware scripts and subsequently fine-tuned it on our dataset. During fine-tuning, we added a BiLSTM layer with an input dimension of 256.
4.3.2. Convolution Neural Network (CNN)
CNN is known for its capability to effectively capture local patterns within data and generate high-level representations of features. By learning the structural information of the malware stream, CNN can determine whether a given sequence is malicious. We opted for this model due to its demonstrated performance in previous studies [
18,
19]. The model architecture comprises an embedding layer, three convolution layers, and the GlobalMaxPooling layer for downsampling operations. The fully connected (FC) layer gathers essential patterns from the pooling layer’s output, while the final layer uses a softmax activation function to represent the likelihood of the given input containing malicious actions.
4.3.3. Gemini
Gemini is a large-scale AI model designed to process and generate insights from a wide range of data types, including text, codes, images, audio, and video. Built on a foundation of Transformer decoders, the model is enhanced with architectural advancements and optimization techniques to improve its performance across modalities. The model showcases exceptional generalist capabilities of recalling and reasoning over fine-grained information from millions of tokens of context. For this study, we utilized Gemini-2.0-Flash-001 for analysis and detection tasks.
4.4. Parameter Settings
The main objective of our study is to develop a malware detection framework using a Transformer-based model with the MalCode2Vec embedding method. The analysis of a HWP document structure was performed at both the stream and file levels. At the stream level, streams were classified as either malicious or benign (i.e., binary classification). Furthermore, file level performance was determined based on the output of the binary classification. If any stream within a file was identified as malicious, the entire HWP file was classified as malicious (see
Figure 1). To achieve this, each stream originating from the same file was assigned a unique label. For both encoding methods (integer encoding and MalCode2Vec), features were in word- and character-level embeddings. Character embedding facilitated the construction of the word even for out-of-vocabulary terms, while word embedding was limited to the seen words.
Figure 4 illustrates an overview of the proposed classification approach. In the character-level embedding approach, the vocabulary was built with characters and a punctuation, while for word-level embedding, the vocabulary was built with words (including characters). The vocabulary size was 76 for character-level embedding, while for word-level embedding, it was built with 236,820 tokens. The generated representations served as input to the Transformer model, which learned them and incorporated the positional information into each token within the sequence. The Transformer received these representations and used a self-attention mechanism to capture the correlation between each pair of tokens.
The proposed architecture was developed through iterative running of different HWP document structures with different parameter configurations to determine the most effective settings.
Table 3 presents the optimal parameters identified for the classification models. For integer encoding, we set the embedding size to 50, utilized three attention heads, and configured the Transformer’s feed-forward network with a hidden layer size of 32. The model incorporates a GlobalMaxPooling1D() layer, followed by two or three fully connected layers with ReLU activation [
32]. Optimization was handled using the Adam optimizer [
33] with an initial learning rate of 0.001. A dropout rate of 0.2 [
34] was applied to the fully connected layers, and early stopping was implemented to prevent overfitting. The sequence lengths for character-level and word-level embeddings were set to 6400 and 270, respectively. We evaluated the performance for both phases using accuracy, precision, recall, and F1 score. All experiments were conducted using six-fold cross-validation for robust evaluation.
4.5. Results
Table 4 shows the results of the two phases (stream- and file-level classifications) using integer encoding and MalCode2Vec, respectively. A single file consists of multiple streams, if even one stream is malicious, so the entire file is considered malicious. This rule, where a file is classified as malicious if at least one of its streams is detected as malicious, was applied to evaluate performance at the file level. As previously discussed, the Transformer’s capability to focus on different parts of the sequence and identify key patterns in malware scripts significantly influences the model’s effectiveness. This was evident in the strong performance of the Transformer with integer encoding, outperforming CNN using MalCode2Vec. In malware detection, false negatives are critical because they refer to cases where malware is mistakenly identified as benign. This allows the malware to evade detection and carry out attacks on the system, potentially leading to data leaks, backdoor installations, and other security breaches. Additionally, a detection model with a high false-negative rate suffers from reduced reliability, making it difficult to use it in real-world applications.
Table 5 shows the false-positive rates. Our model shows the lowest false-positive rate.
Figure 9 shows the predictions made by the Transformer model, highlighting the words that contributed the most influence on the prediction category. Notably, the EPS family malware includes string manipulation operations (
exch, concatstrings, roll, copy), file operations (
writestring, readhexstring, concatstrings, closefile), and a suspicious long hexadecimal string at the end (
bindexec4d5a …), which is likely an encoded malicious payload. The attention mechanism highlights these operators along with ‘.exe’, underlining their significance in the prediction process.
PE family malware often highlights elements such as the batch file, directory path of batch files and registries kernel.dll, and API functions. The directory path of the batch file is mentioned to add a path to the PATH environment variable of the operating system, a tactic commonly associated with exploiting the Windows operating system.
Figure 10 shows the highlights on the bat file and its corresponding suspicious file path involving
qwer.bat. The repetitive creation of similarly named files (
Users/105/Desktop, AppData/Local/Temp) in different directories is a common malware behavior for persistence and propagation.
VBA script family malware usually includes various scripts.
Figure 11 highlights the key suspicious elements, such as the character code operation (
fromCharCode) and control flow elements like
else and
return.
ShellCode family malware includes an NOP (no-operation) sled, which comprises a sequence of NOP instructions (opcode 0 × 90, AAAAAAAAAAAAA), inserted before a shellcode to ensure proper execution by aligning the instruction pointer.
Figure 12 shows the highlights on the
AAAAAAAAAAAAA NOP sled. Our model inherently captures structural and semantic representations of a code, making it more resilient to simple obfuscation techniques that do not alter the program’s logic.
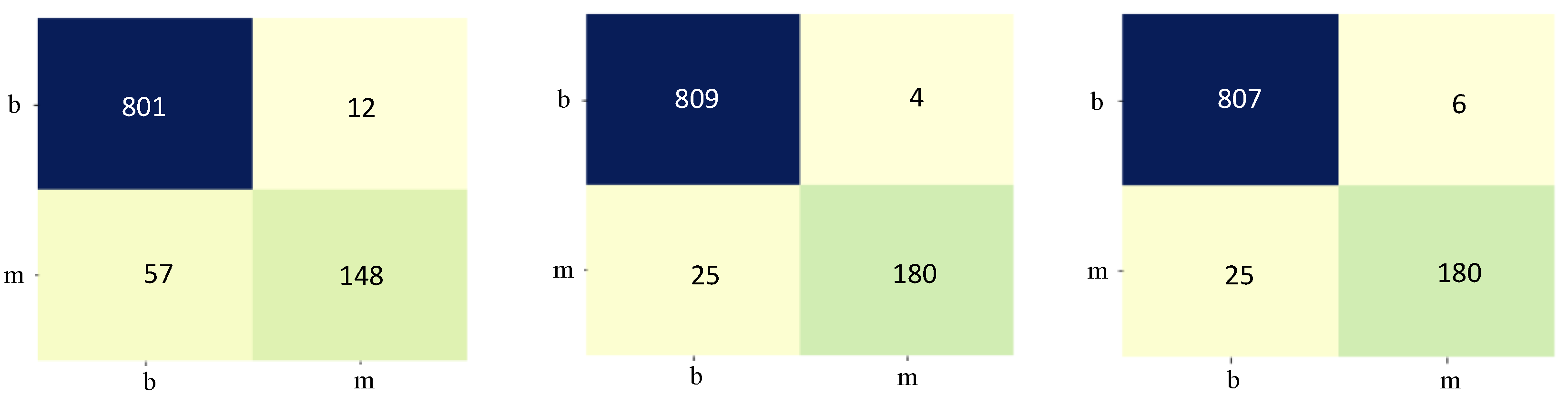
Attention mechanisms improve the detection of a code or behavior indicative of malware; this suggests that the Transformer is powerful, with self-attention as the key. Interestingly, the results obtained from both approaches, integer encoding and the MalCode2Vec model, exhibit comparative performance.
Figure 13 demonstrates this using the confusion matrix results. This can happen because most of the tokens in the malware data have no semantic meaning as normal text in the vector space representation. Word-level embeddings generally achieve higher accuracy than character-level embeddings. This advantage stems from the fact that words inherently convey more meaning, aiding in the differentiation between malicious and benign patterns. In contrast, character-level embeddings can be affected by data sparsity, particularly in languages with complex scripts or where words are formed by combining multiple characters. The MalCode2Vec model, which utilizes word-level embeddings, delivers optimal performance in stream and file-level classification. This suggests that embedding vectors effectively capture meaningful relationships within malware sequences, allowing words with similar meanings to be closely positioned in the embedding space. As a result, the model excels both semantically (by comparing similar scripts) and syntactically (by learning sequence patterns), as discussed in [
13].
In the evaluation of inference time, we found that the Transformer model with integer encoding achieved a faster inference time of 1.981 milliseconds compared with the Code2Vec model, which took 2.497 milliseconds on the GeForce GTX 1080 Ti GPU (NVIDIA, San Jose, CA, USA). The longer inference time of Code2Vec can be attributed to its more complex architecture. Code2Vec employs neural embeddings and context-aware vector representations, which require additional processing steps. Despite the higher inference time, the model achieved better accuracy in malware detection, making it a more precise and effective choice for the task.
4.6. Data Imbalance
4.6.1. Oversampling and Undersampling
Data imbalance can impact training, especially for classes with fewer samples. To investigate the impact of unbalanced data, we employed sampling methods: oversampling and undersampling [
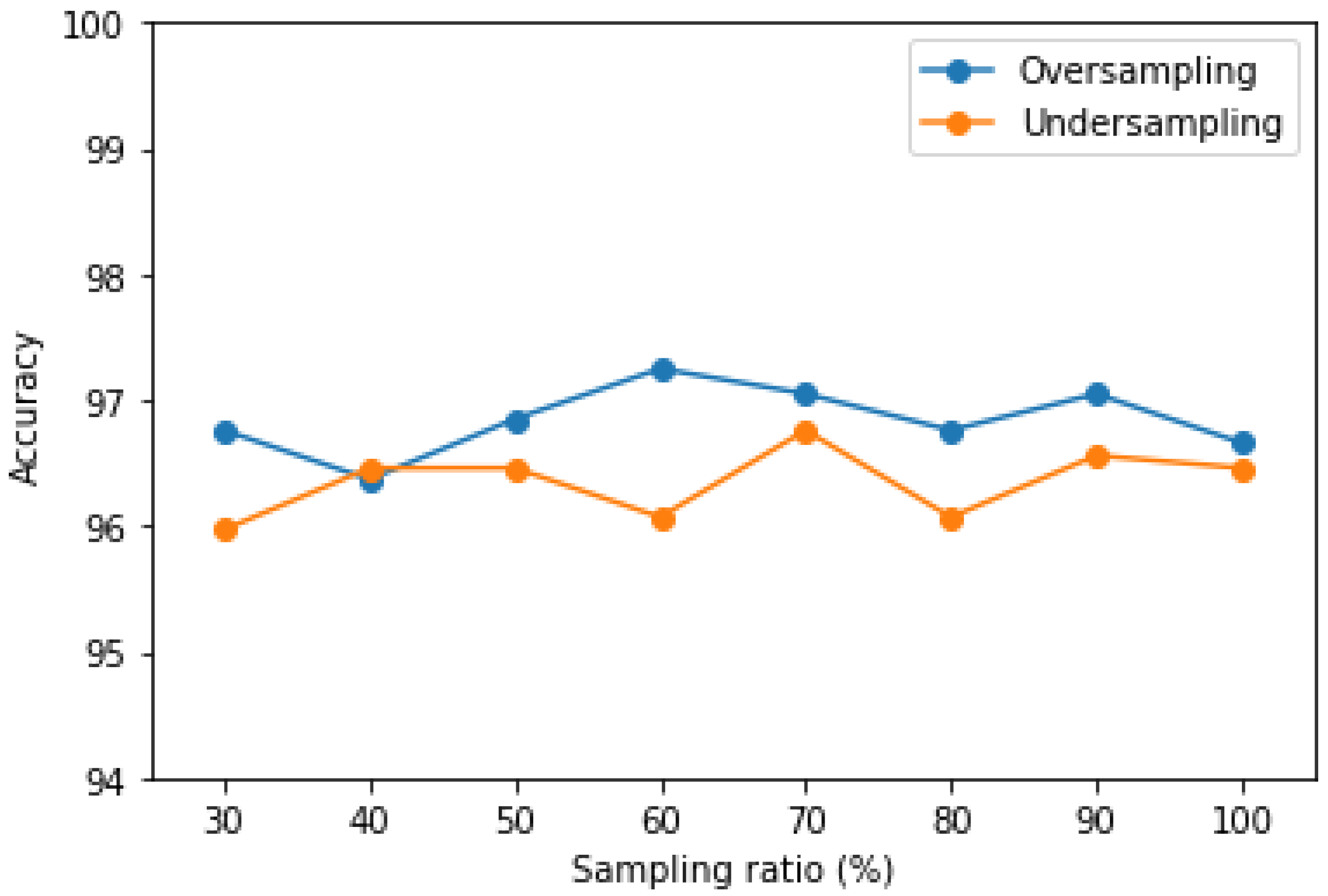
35] on stream-level detection. Oversampling augments the minority samples with multiple copies, thus balancing the classes. Conversely, undersampling entails reducing the number of samples from majority classes by deleting them until a balanced distribution is achieved. We use the Transformer with word-level embedding, a model that offers the best performance. The data were sampled at levels ranging from 30% in the step of 10% until the balance was achieved. The results, shown in
Figure 14, illustrate that oversampling provides more favorable solutions than undersampling. With an oversampling ratio of 60%, the model outperforms the original model by achieving an accuracy of 97.25%. As the oversampling ratio increased, the number of false negatives (FN) and false positives (FP) either decreased or remained stable within 22∼24 and 4∼14, respectively. The undersampling strategy showed little improvement for either the FN (24∼33) or FP (5∼23) rate. We believe that the sampling method has a greater effect on the importance of features, especially the undersampling, reducing the number of features, hence causing the classifier to miss useful information (patterns) that could be used in determining the decision boundary between the classes [
36]. Generally, one can choose the best method by evaluating the performance at different levels of resampling. The overall results of the experiments conducted in this study suggest that our proposed method is the best and can effectively handle unbalanced data.
4.6.2. SeqGAN: Malware Family Augmentation
To achieve a balanced dataset, an
n-amount of samples were added for each class, as shown in
Table 2. The quality of the synthetic samples generated by SeqGAN was evaluated by the BLEU (Bilingual Evaluation Understudy) score metric. The BLEU metric assesses the similarity between the generated samples and real samples by comparing overlapping n-grams. The generated samples are not intended to perform actual malicious activities but rather serve as data to address class imbalance. Therefore, similarity was measured simply as the degree of word overlap.
We compared 1 gram of the generated and real samples, motivated by the nature of malware scripts, where individual commands and API calls are the fundamental units of malicious functionality. The generated samples achieved higher BLEU-1 scores. A higher BLEU-1 score indicates a successful replication of malicious samples. This quantitative validation demonstrates that our synthetic samples effectively capture the essential characteristics of script samples. In
Table 6, we report the BLEU-1 scores for the generated samples. A lower score on EPS can be attributed to the architectural complexity and payload flexibility inherent in EPS malware. The combination of a PostScript code with binary data introduces more variability in patterns compared with the simpler structure of iframe and VBS scripts. Additionally, the flexibility of EPS files, which can embed various types of malicious content, such as shellcode or executables, leads to greater variation between samples.
Although these generated samples may not represent actual malware, they contribute to enhancing the model’s robustness when combined with the original samples. After data augmentation, the F1 score increased by 35.58% for the VBA class, which was the most inadequate class, and improved for other classes, as shown in
Table 7. Compared with CNN, the Transformer model performs better before and improves after data augmentation. This suggests the possibility of using a Transformer model to overcome the limitations of unbalanced data. We leave this for future analysis study.
5. Discussion
We conducted experiments to compare with baseline models, namely, CNN, BERT, and Gemini. For BERT, the selected model was cased with a vocabulary size of 32K. Leveraging the success of the MalCode2Vec model, which performs well with the Transformer model, we adapted it for the CNN classifier. The embedding was performed at the word level. The results presented in
Table 4 show that our proposed Transformer model outperformed the baseline models in file-level and binary malware detection. The results of CNN were more accurate than that of the BERT model. Notably, CNNs are known to have a powerful feature extraction network; therefore, they can learn patterns from the code sequences. The BERT model is more advanced, having features such as the ability to learn the contextual relationship between words; however, the sequence length limitation is the challenge in fine-tuning the Transformers on long text datasets. BERT models have a maximum sequence length of 512 tokens. This limits the input of important features to BERT, as the malware sequence has a longer sequence length of more than 10K. The results from the Gemini model indicate that the model excels at the objective of minimizing the false negatives with a higher recall of 89.76%. However, the precision is relatively low at 29.02%, suggesting that while the model is good at recognizing malware, it also misidentifies a considerable number of benign instances as malware. The result reflects that the model is generally precise when identifying benign samples but faces challenges in achieving a balance between precision and recall for the malware class. While Gemini is a powerful large language model trained on a multi-domain dataset, its performance may not be optimal for domain-specific tasks like malware detection. Most LLMs, including Gemini, are trained on diverse, general-purpose datasets, which may not capture the nuances of the cybersecurity domain, such as the specific characteristics of malware or benign data. Therefore, further domain-specific fine-tuning would likely improve the model’s ability to distinguish between malware and benign more accurately.
Table 8 compares our work with other malware detection works conducted on Hangul Word Processor files [
19,
37]. All studies used convolutional neural networks with spatial pyramid average pooling in [
19]. The studies show strong recall and better precision for malicious cases, indicating a significant number of false negatives. In comparison, our models demonstrate higher performance in benign classification and a fair recall score in malicious class. We believe that the unbalanced data ratio for malicious samples may be one of the contributing factors. The Transformer-based model with MalCode2Vec word embedding outperforms the CNN approach, showing an improvement of 3.41% in recall and 2.2% in F1 score for the malicious class.
Given our aim for detecting the malware attacks within the document file, the false-negative rate is important to be minimized because it represents the ratio of missed malicious cases that could be considered benign. Therefore, a higher recall (i.e., sensitivity) of malicious cases is prioritized.
The Transformer model achieved the highest recall of 87.80% with a strong balance between minimizing false negatives and false positives. Overall, when we take account of the recall and F1 score of malicious cases, the optimal model achieved 87.80% and 92.54%, respectively, using the MalCode2Vec embedding at the word level. We also observed a lower rate of false negatives compared with the model using integer encoding.
The proposed model can be applied to PDF malware. A PDF file consists of four main sections: Header, Body, Cross-Reference table, and Trailer. Header contains the document version information in 8 bytes. Body comprises objects that contain the actual document information. The object types include the Boolean value that presents TRUE or FALSE, elements of an array, or entries in a dictionary, an array that can hold a combination of various types of objects, a dictionary that consists of key-value pairs, and a stream. The stream means a sequence of bytes (binary data) with no length restrictions, typically used for large image files or page composition objects. It is composed of a dictionary object, followed by the keyword ‘stream’ and ‘endstream’, enclosing multiple bytes. Malicious JavaScript can be encoded and embedded within a PDF stream. This is similar to how a malicious code is embedded in HWP documents. However, since PDFs use a different syntax, directly applying a model trained on Hangul document malware to PDFs is challenging. Nevertheless, since both document formats follow an OLE-based structure, the approach of identifying streams and analyzing their content remains the same.
Figure 15 shows an example of a PDF file that includes objects. In future work, we will build a model that works across malware documents that have an OLE structure, including RTF word, PDF, and so on.
Deep learning models are highly susceptible to adversarial examples [
38], and even minute alterations can lead to misclassification. While we utilize the SeqGAN model to address the issue of sample imbalance, we believe that incorporating our proposed sample augmentation technique can yield a model that is more robust to such perturbations. Prior research [
39] has already demonstrated that adversarial training makes models less sensitive to adversarial examples and improves their generalization capabilities.
6. Conclusions
Malware attacks have become a significant threat to information security, especially during a pandemic, when remote activities increase. Attackers frequently employ techniques like code obfuscation to evade detection. To combat these threats, advanced methods are needed to analyze their strategies and identify shared characteristics, such as code structure.
In this study, we proposed methods to detect malicious cases in HWP document files. First, we developed document-type malware detection and a family classification system using Transformer to address emerging forms of malware. Transformer has been used for executable malware, but it has not been used for document-type malware, especially script codes. We demonstrate that Transformer, an attention-based model, works well in the detection tasks. Experiments were performed at both the stream- and file-level binary classification (i.e., detecting whether a stream or file is malicious or benign). The malware code sequences were embedded at the character and word levels using a pre-trained MalCode2Vec embedding model. The efficiency was studied in terms of accuracy, precision, recall, and F1 score. Notably, the model utilizing MalCode2Vec at the word level outperformed other approaches with an accuracy of 97.15% for the stream classification and 95.66% for the file-level classification.
Second, we proposed the use of SeqGAN to resolve the class imbalance problem for malware family classification. We examined the generated samples that mimic the characteristics of the original families. They have the features of the families and improve the family classification performance. Third, we established the experimental framework for HWP files, which encompass various types. We performed the sample analyses based on malware families, emphasizing the features of each family.
Moving forward, in our future research, we will focus on mitigating false negatives by increasing the number of malicious samples through advanced augmentation techniques. Additionally, we will focus on techniques that are used to distribute malware by exploiting the file vulnerabilities. By understanding their tactics and targets, we can take preventative measures. Additionally, we intend to learn more about developers’ new approaches and traits using a time-stamped dataset. This will help us determine how frequently the proposed architecture should be updated to defend against bypass attempts and other vulnerabilities. Further, we plan to analyze the model against adversarial instances or code obfuscation methods that are frequently utilized by attackers.
Author Contributions
Conceptualization, S.-M.L., J.-H.K. and Y.-S.J.; methodology, G.L.M., S.-M.L., J.-H.K., Y.-S.J. and J.W.; software, S.-M.L. and J.-H.K.; data curation, A.R.K.; writing—original draft preparation, G.L.M. and J.W.; writing—review and editing, G.L.M. and J.W.; funding acquisition, A.R.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by an Institute of Information and Communications Technology Planning and Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2019-0-00026, ICT infrastructure protection against intelligent malware threats, the Basic Science Research Program partly supported this work through the National Research Foundation of Korea (NRF), funded by the Ministry of Education (No. NRF-2020R1I1A3056858) and in part by the Soonchunhyang University Research Fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Singh, P.; Tapaswi, S.; Gupta, S. Malware detection in pdf and office documents: A survey. Inf. Secur. J. Glob. Perspect. 2020, 29, 134–153. [Google Scholar] [CrossRef]
- Lee, G.; Shim, S.; Cho, B.; Kim, T.; Kim, K. Fileless cyberattacks: Analysis and classification. ETRI J. 2021, 43, 332–343. [Google Scholar] [CrossRef]
- SonicWall. 2023 Sonicwall Cyber Threat Report; SonicWall: San Jose, CA, USA, 2023. [Google Scholar]
- Khweiled, R.; Jazzar, M.; Eleyan, D. Cybercrimes during COVID-19 Pandemic. Int. J. Inf. Eng. Electron. Bus. 2021, 13, 1–10. [Google Scholar] [CrossRef]
- Pranggono, B.; Arabo, A. COVID-19 pandemic cybersecurity issues. Internet Technol. Lett. 2021, 4, e247. [Google Scholar] [CrossRef]
- Mainka, C.; Mladenov, V.; Rohlmann, S. Shadow Attacks: Hiding and Replacing Content in Signed PDFs. In Proceedings of the 2019 Network and Distributed System Security Symposium, Internet Society, San Diego, CA, USA, 21–24 February 2021. [Google Scholar]
- Kim, M.h. North korea’s cyber capabilities and their implications for international security. Sustainability 2022, 14, 1744. [Google Scholar] [CrossRef]
- Polito, C. The Evolution of North Korean Cyber Threats. 2019. Available online: https://www.jstor.org/stable/pdf/resrep20679.pdf (accessed on 17 May 2023).
- Wang, Q.; Qian, Q. Malicious code classification based on opcode sequences and textCNN network. J. Inf. Secur. Appl. 2022, 67, 103151. [Google Scholar] [CrossRef]
- Conti, M.; Vinod, P.; Vitella, A. Obfuscation detection in android applications using deep learning. J. Inf. Secur. Appl. 2022, 70, 103311. [Google Scholar] [CrossRef]
- Ito, R.; Mimura, M. Detecting unknown malware from ASCII strings with natural language processing techniques. In Proceedings of the 2019 14th Asia Joint Conference on Information Security (AsiaJCIS), Kobe, Japan, 1–2 August 2019; pp. 1–8. [Google Scholar]
- Rahali, A.; Akhloufi, M.A. MalBERTv2: Code Aware BERT-Based Model for Malware Identification. Big Data Cogn. Comput. 2023, 7, 60. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Li, Y.; Wang, X.; Shi, Z.; Zhang, R.; Xue, J.; Wang, Z. Boosting training for PDF malware classifier via active learning. Int. J. Intell. Syst. 2022, 37, 2803–2821. [Google Scholar] [CrossRef]
- Laskov, P.; Šrndić, N. Static detection of malicious JavaScript-bearing PDF documents. In Proceedings of the 27th Annual Computer Security Applications Conference, Orlando, FL, USA, 5–9 December 2011; pp. 373–382. [Google Scholar]
- Al-Taharwa, I.A.; Lee, H.M.; Jeng, A.B.; Wu, K.P.; Mao, C.H.; Wei, T.E.; Chen, S.M. Redjsod: A readable javascript obfuscation detector using semantic-based analysis. In Proceedings of the 2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 1370–1375. [Google Scholar]
- Stokes, J.W.; Agrawal, R.; McDonald, G.; Hausknecht, M. Scriptnet: Neural static analysis for malicious javascript detection. In Proceedings of the MILCOM 2019-2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; pp. 1–8. [Google Scholar]
- Jeong, Y.S.; Woo, J.; Kang, A.R. Malware detection on byte streams of pdf files using convolutional neural networks. Secur. Commun. Netw. 2019, 2019, 8485365. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Woo, J.; Lee, S.; Kang, A.R. Malware Detection of Hangul Word Processor Files Using Spatial Pyramid Average Pooling. Sensors 2020, 20, 5265. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Mswahili, M.E.; Kang, A.R. File-level malware detection using byte streams. Sci. Rep. 2023, 13, 8925. [Google Scholar] [CrossRef] [PubMed]
- Corona, I.; Maiorca, D.; Ariu, D.; Giacinto, G. Lux0r: Detection of malicious pdf-embedded javascript code through discriminant analysis of api references. In Proceedings of the 2014 Workshop on Artificial Intelligent and Security Workshop, Scottsdale, AZ, USA, 7 November 2014; pp. 47–57. [Google Scholar]
- Phung, N.M.; Mimura, M. Detection of malicious javascript on an imbalanced dataset. Internet Things 2021, 13, 100357. [Google Scholar] [CrossRef]
- Choi, S.; Bae, J.; Lee, C.; Kim, Y.; Kim, J. Attention-based automated feature extraction for malware analysis. Sensors 2020, 20, 2893. [Google Scholar] [CrossRef]
- Demırcı, D.; Acarturk, C. Static Malware Detection Using Stacked BiLSTM and GPT-2. IEEE Access 2022, 10, 58488–58502. [Google Scholar] [CrossRef]
- Rahali, A.; Akhloufi, M.A. MalBERT: Malware Detection using Bidirectional Encoder Representations from Transformers. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 3226–3231. [Google Scholar]
- Martin, G.L.; Jeong, Y.S.; Kang, A.R.; Woo, J. HWP Malware Detection using Transformer. J. Korea Soc. Comput. Inf. 2025, 30, 87–97. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Montreal, QC, Canada, 2014; pp. 2672–2680. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Li, J.; Liu, B.; Gao, X.; Liu, X. Malware detection method based on image analysis and generative adversarial networks. Concurr. Comput. Pract. Exp. 2022, 34, e7170. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wager, S.; Wang, S.; Liang, P. Dropout training as adaptive regularization. arXiv 2013, arXiv:1307.1493. [Google Scholar]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 243–248. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Jeong, Y.S.; Woo, J.; Kang, A.R. Malware detection on byte streams of hangul word processor files. Appl. Sci. 2019, 9, 5178. [Google Scholar] [CrossRef]
- Zhang, J.; Li, C. Adversarial examples: Opportunities and challenges. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2578–2593. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
Figure 1.
HWP malware detection and family classification, where S indicates a stream-level detection and F is a file-level detection.
Figure 1.
HWP malware detection and family classification, where S indicates a stream-level detection and F is a file-level detection.
Figure 2.
Structure of HWP files.
Figure 2.
Structure of HWP files.
Figure 3.
Example of (a) encrypted script codes in the stream and (b) decrypted script codes from the stream.
Figure 3.
Example of (a) encrypted script codes in the stream and (b) decrypted script codes from the stream.
Figure 4.
Overview of the proposed method.
Figure 4.
Overview of the proposed method.
Figure 5.
Skip-gram model for MalCode2Vec.
Figure 5.
Skip-gram model for MalCode2Vec.
Figure 6.
Malware document including EPS.
Figure 6.
Malware document including EPS.
Figure 7.
Malware document including PE triggered by EPS.
Figure 7.
Malware document including PE triggered by EPS.
Figure 8.
Malware document exploiting iframe.
Figure 8.
Malware document exploiting iframe.
Figure 9.
Attention highlights on an EPS family sample.
Figure 9.
Attention highlights on an EPS family sample.
Figure 10.
Attention highlights on a PE family sample.
Figure 10.
Attention highlights on a PE family sample.
Figure 11.
Attention highlights on a VBA family sample.
Figure 11.
Attention highlights on a VBA family sample.
Figure 12.
Attention highlights on a shellcode family sample.
Figure 12.
Attention highlights on a shellcode family sample.
Figure 13.
Confusion matrix for stream-level malware detection using MalCode2Vec embedding at the character level (left) and word level (middle) and integer encoding at the word level (right).
Figure 13.
Confusion matrix for stream-level malware detection using MalCode2Vec embedding at the character level (left) and word level (middle) and integer encoding at the word level (right).
Figure 14.
Sampling results. The data were sampled in the range of 10% until the balance was achieved.
Figure 14.
Sampling results. The data were sampled in the range of 10% until the balance was achieved.
Figure 15.
PDF document object.
Figure 15.
PDF document object.
Table 1.
Summary of previous works on document-type malware detection.
Table 1.
Summary of previous works on document-type malware detection.
| Study | Sample | Data | Method | Algorithm |
|---|
| [15] (2011) | PDF | Source codes | Lexical analysis of JavaScript code and obfuscation in benign JavaScript | Machine learning |
| [16] (2012) | JavaScript | Source codes | Investigation and detection of obfuscated JavaScript codes | Bayesian method |
| [21] (2014) | PDF | Source codes | Reference chain5, compression, redundant information in JavaScript | Machine learning |
| [17] (2019) | JavaScript | Bytes | Propose a novel model combining LSTM and CNN for sequence learning | LSTM+CNN |
| [18] (2019) | PDF | Bytes | Manual labeling of the byte sequences, investigating the structure of the data | CNN |
| [19] (2020) | HWP | Bytes | Malware detection, propose a padding method to incorporate the length of byte streams | CNN (SPAP) |
| [22] (2021) | JavaScript | Source codes | Oversampling, feature extraction using Doc2Vec and attention | Doc2Vec, attention |
| [20] (2023) | MS Office | Bytes | Malware detection, propose a method that aggregates the stream-level results to obtain file-level results | CNN (MalCov, SPAP) |
Table 2.
HWP malware family statistics. The original number of samples and amount of augmented samples for the most imbalanced malware families.
Table 2.
HWP malware family statistics. The original number of samples and amount of augmented samples for the most imbalanced malware families.
| Malware Family | Number of Samples | Augmentation |
|---|
| Benign | 5470 | - |
| Heuristic | 282 | - |
| PE | 273 | - |
| EPS | 147 | 100 |
| Shellcode | 567 | - |
| Iframe | 34 | 250 |
| VBS | 9 | 270 |
Table 3.
Parameter settings for the proposed method and other reference models.
Table 3.
Parameter settings for the proposed method and other reference models.
| Model | Parameter Setting | Value |
|---|
| Transformer | Embedding dimension | 100 |
| Attention heads | 3 |
| Dropout | 0.2 |
| Dense layer (Transformer) | 32 units |
| Dense layer (FC) | (32, 16, 10) units |
| CNN | Filters | 256, 256, 128 |
| Kernel size | 3 |
| Dense layer (FC) | 64 units |
| BERT | LSTM units | 256 |
| Learning rate | 2 × 10−5 |
| Optimizer | Adam |
Table 4.
Experimental results using integer encoding and MalCode2Vec model. The accuracy and performance metrics are for the stream level. File-level accuracy is the model’s performance in categorizing the HWP files as benign or malicious. b and m correspond to benign and malicious cases, respectively.
Table 4.
Experimental results using integer encoding and MalCode2Vec model. The accuracy and performance metrics are for the stream level. File-level accuracy is the model’s performance in categorizing the HWP files as benign or malicious. b and m correspond to benign and malicious cases, respectively.
| Embed | Model | Stream-Level | Stream-Level Performance Metrics | File-Level |
|---|
| Acc | F1 | Precision | Recall | F1 | Acc | F1 |
|---|
| b | m | b | m | b | m |
|---|
| Integer | Transformerchar | 92.93 | 88.76 | 94.91 | 84.46 | 96.31 | 79.51 | 95.60 | 81.91 | 90.46 | 88.76 |
| encoding | Transformerword | 96.95 | 95.09 | 97.00 | 96.77 | 99.26 | 87.80 | 98.12 | 92.07 | 95.01 | 94.07 |
| MalCode2Vec | Transformerchar | 93.22 | 88.48 | 93.36 | 92.50 | 98.52 | 72.20 | 95.87 | 81.10 | 90.89 | 88.85 |
| Transformerword | 97.15 | 95.39 | 97.00 | 97.83 | 99.51 | 87.80 | 98.24 | 92.54 | 95.66 | 94.83 |
| CNNword | 96.37 | 94.05 | 96.19 | 97.19 | 99.38 | 84.39 | 97.76 | 90.34 | 94.79 | 93.72 |
| WordPiece | BERTBi−LSTM | 69.65 | 69.15 | 80.36 | 22.34 | 82.04 | 20.49 | 81.19 | 21.37 | 63.77 | 64.12 |
| | Gemini-2.0 | 53.73 | 57.27 | 94.53 | 29.02 | 44.65 | 89.76 | 60.65 | 43.86 | 62.69 | 59.88 |
Table 5.
False-negative rates (FNRs) for different models.
Table 5.
False-negative rates (FNRs) for different models.
| Model | FNR (Benign) | FNR (Malicious) |
|---|
| Integer encoding Transformer char | 3.57% | 20.49% |
| Integer encoding Transformer word | 0.74% | 12.20% |
| MalCode2Vec Transformer word | 0.49% | 12.20% |
| MalCode2Vec CNN word | 0.62% | 15.61% |
Table 6.
Results of BLEU for the augmented malware family.
Table 6.
Results of BLEU for the augmented malware family.
| Malware Family | BLEU-1 |
|---|
| EPS | 79.12 |
| Iframe | 99.03 |
| VBS | 97.45 |
Table 7.
Performance results (using MalCode2Vec embedding) without and with data augmentation. P, R, and F1 are precision, recall, and F1 score.
Table 7.
Performance results (using MalCode2Vec embedding) without and with data augmentation. P, R, and F1 are precision, recall, and F1 score.
| | Without Augmentation | With Augmentation (SeqGAN) |
|---|
| Malware | Transformer | CNN | Transformer | CNN |
|---|
| Family | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 |
|---|
| Normal | 97.87 | 98.76 | 98.31 | 95.90 | 98.19 | 97.02 | 97.89 | 98.68 | 98.28 | 96.37 | 97.4 | 96.86 |
| Heuristic | 93.79 | 77.67 | 84.16 | 97.66 | 75.23 | 83.74 | 95.32 | 81.96 | 87.92 | 96.20 | 72.04 | 82.14 |
| PE | 84.51 | 85.73 | 84.95 | 79.24 | 62.36 | 69.16 | 83.72 | 86.13 | 83.57 | 71.87 | 77.31 | 73.79 |
| EPS | 92.70 | 82.46 | 86.84 | 82.86 | 67.98 | 71.90 | 95.88 | 87.58 | 90.72 | 83.99 | 77.37 | 80.25 |
| Shellcode | 95.40 | 97.17 | 96.26 | 89.94 | 91.00 | 90.42 | 96.56 | 96.47 | 96.49 | 91.94 | 90.82 | 91.14 |
| Iframe | 96.67 | 93.81 | 95.13 | 90.29 | 67.14 | 75.50 | 100.0 | 99.30 | 99.64 | 96.13 | 94.34 | 94.92 |
| VBA | 70.00 | 60.00 | 63.33 | 40.00 | 40.00 | 40.00 | 99.63 | 98.21 | 98.91 | 95.67 | 95.71 | 95.57 |
Table 8.
A comparative summary of our proposed method with the previous study. SPAPConv stands for spatial pyramid average pooling CNN model.
Table 8.
A comparative summary of our proposed method with the previous study. SPAPConv stands for spatial pyramid average pooling CNN model.
| Study | Stream-Level Performance Metrics | Data Statistics |
|---|
| Precision | Recall | F1 Score | Benign | Malicious |
|---|
| b | m | b | m | b | m |
|---|
| [19] (SPAPConv) | 87.28 | 99.46 | 99.20 | 91.07 | 92.86 | 95.08 | 2852 | 3668 |
| [37] (CNN) | 88.22 | 99.09 | 99.07 | 88.42 | 93.33 | 93.45 | 6150 | 7031 |
| Ours (CNN-MalCode2Vec) | 96.19 | 97.19 | 99.38 | 84.39 | 97.76 | 90.34 | 5470 | 1312 |
| Ours (Transformer-MalCode2Vec) | 97.00 | 97.83 | 99.51 | 87.80 | 98.24 | 92.54 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}