1. Introduction
Speech collected by microphones is often contaminated by various types of environmental noises, resulting in inevitable degradation in the speech’s perceptual quality and intelligibility. As a solution, an increasing amount of research has focused on the speech enhancement (SE) technique, which aims to suppress the noise components and recover the clean speech. SE is one of the most prominent speech front-end signal processing techniques, and it is widely used in scenarios such as telecommunication systems, hearing aid devices, and automatic speech recognition (ASR).
Recently, deep learning (DL)-based SE methods have illustrated outstanding performance, especially when the noise is non-stationary or the signal-to-noise ratio (SNR) is low. Some DL-based methods directly predict the enhanced speech from raw noisy speech by an end-to-end way in the time domain [
1,
2,
3]. For example, DEMUCS [
1] leverages a deep neural network (DNN) with multiple temporal convolutional and recurrent layers to capture both local and global features of the signal, achieving direct mapping from noisy to clean speech. Nevertheless, more methods realize SE in the time–frequency (TF) domain [
4,
5,
6,
7,
8,
9,
10]. The TF domain methods employ a DNN model to operate the noisy spectrum, suppress the noise components, and estimate the enhanced spectrum. In the past few years, a plethora of DNN models of different structures have been studied, such as convolutional neural network (CNN) [
11], recurrent neural network (RNN) [
12], and more recently, Transformer [
13,
14]. The CNN excels at extracting high-level features but primarily focuses on local TF patterns. RNN is able to capture long-distance contexts, but it performs poorly in the analysis of local feature information. As for Transformer, although it has demonstrated outstanding performance in SE, it simultaneously results in significant computational costs and memory consumption. This limits its practicality, particularly in real-time processing applications. In recent years, the convolutional recurrent network (CRN) has been introduced to SE, which effectively combines the strengths of both CNN and RNN.
By incorporating a symmetric convolutional encoder–decoder (CED) and a recurrent module, a CRN [
4] is proposed to receive a noisy magnitude spectrum and predict the enhanced one. To further correct the noisy phase and improve SE performance, the CRN is subsequently extended to its complex-valued version, known as DCCRN [
7]. In addition, the gated linear unit (GLU) is employed to replace the convolutional and deconvolutional layers in the CED, resulting in the GCRN [
15]. The GCRN utilizes two parallel decoders, respectively, to estimate the real and imaginary parts of the enhanced complex-valued speech spectrum. DPCRN [
16], on the other hand, employs intra-chunk long short-term memory (LSTM) and inter-chunk LSTM layers to achieve more comprehensive sequence modeling. More recently, FRCRN [
17] proposes a convolutional recurrent encoder–decoder (CRED) structure to boost the feature representation capability of the CED. ICCRN [
18] abandons the frequency downsampling operation of the convolutional encoder and implements SE in the cepstral space. SICRN [
19] enhances CRN by combining a state space model and the inplace convolution operation. In general, the CRN structure is commonly utilized in SE, and CRN-based models have exhibited excellent performance. Therefore, we also adopt the CRN structure as the network backbone in constructing the proposed DNN model.
Moreover, many researchers have enhanced the SE technique from various other perspectives. CTS-Net [
8] decouples the SE task into coarse magnitude spectrum estimation and fine-grained complex-valued spectrum refinement in a sequential manner, thus proposing a two-stage paradigm. Later, GaGNet [
20] modifies the coarse and fine-grained estimation in CTS-Net from sequential to parallel processing, which prevents error accumulation and ensures hierarchical optimization toward the complex-valued spectrum. Meanwhile, some works implement SE using multi-domain processing techniques. For example, CompNet [
21] enhances the noisy speech sequentially in both the time and TF domains, and FDFNet [
22] processes the speech spectrum sequentially in the Fourier transform and discrete cosine transform domains. Moreover, several full-band and sub-band fusion SE models have been proposed to integrate local sub-band spectrum features with global cross-band dependencies for better performance, including FullSubNet [
23], FullSubNet+ [
24], and LFSFNet [
25]. Based on these models, Inter-SubNet [
26] discards the full-band model and utilizes a sub-band interaction method to supplement global spectrum patterns for the sub-band model. Furthermore, generative SE approaches, such as NASE [
27], have also garnered increasing attention.
All of the aforementioned methods take the clean speech as the predicting target, so they can be referred as the speech-prediction methods. However, these methods lack explicit analysis and modeling for the characteristics of noise components. In addition, predicting the clean speech from low-SNR signals can be challenging, potentially resulting in poor quality of the enhanced speech. Consequently, the noise-prediction method [
28] attempts to predict the pure noise, which is then subtracted from the noisy speech to indirectly obtain the enhanced speech. But the benefit is still limited. Motivated by the speech-prediction and noise-prediction methods, some subsequent methods [
29,
30,
31] propose a dual-branch network to simultaneously predict the target speech and noise signals. Additionally, the bidirectional information interaction module is typically introduced between the speech and noise branches to further optimize the speech and noise modeling process [
29]. Although the interactive speech and noise modeling-based dual-branch network has illustrated excellent performance, it significantly increases the model complexity. Unfortunately, the huge model complexity may be intolerable in many resource-constrained devices.
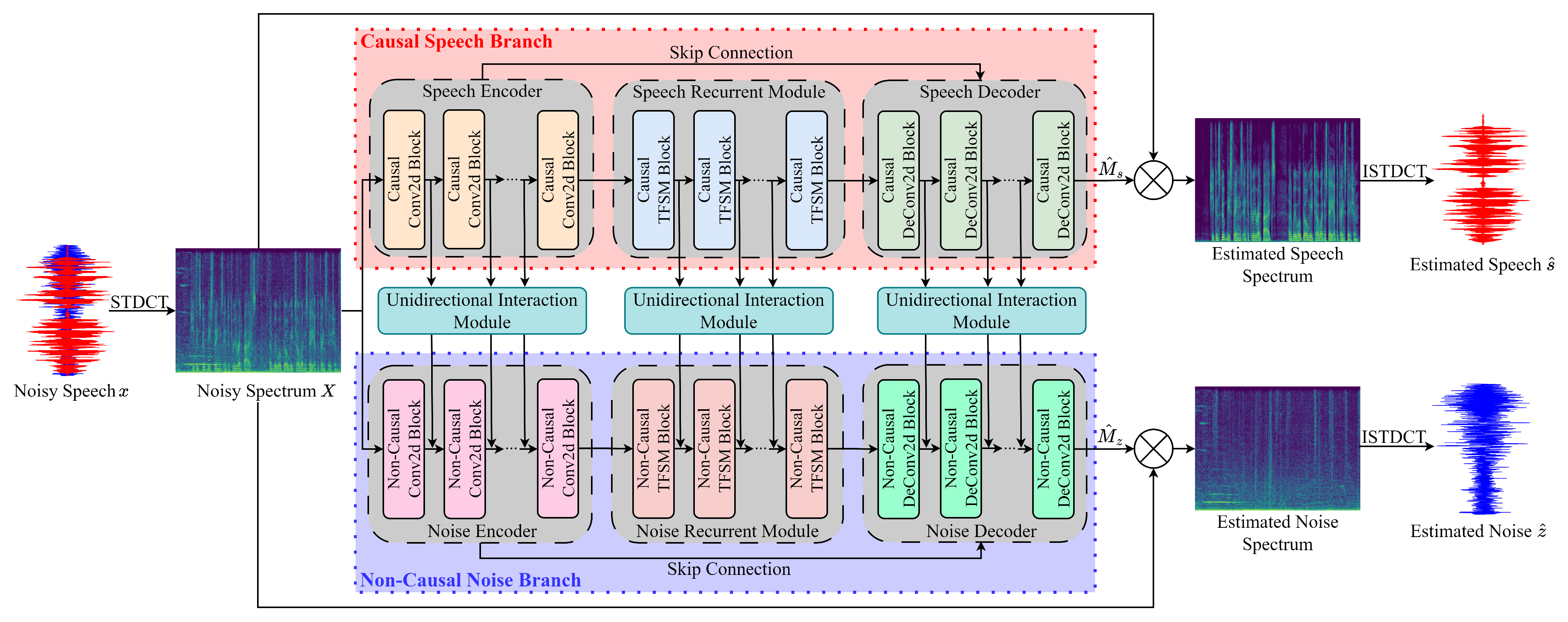
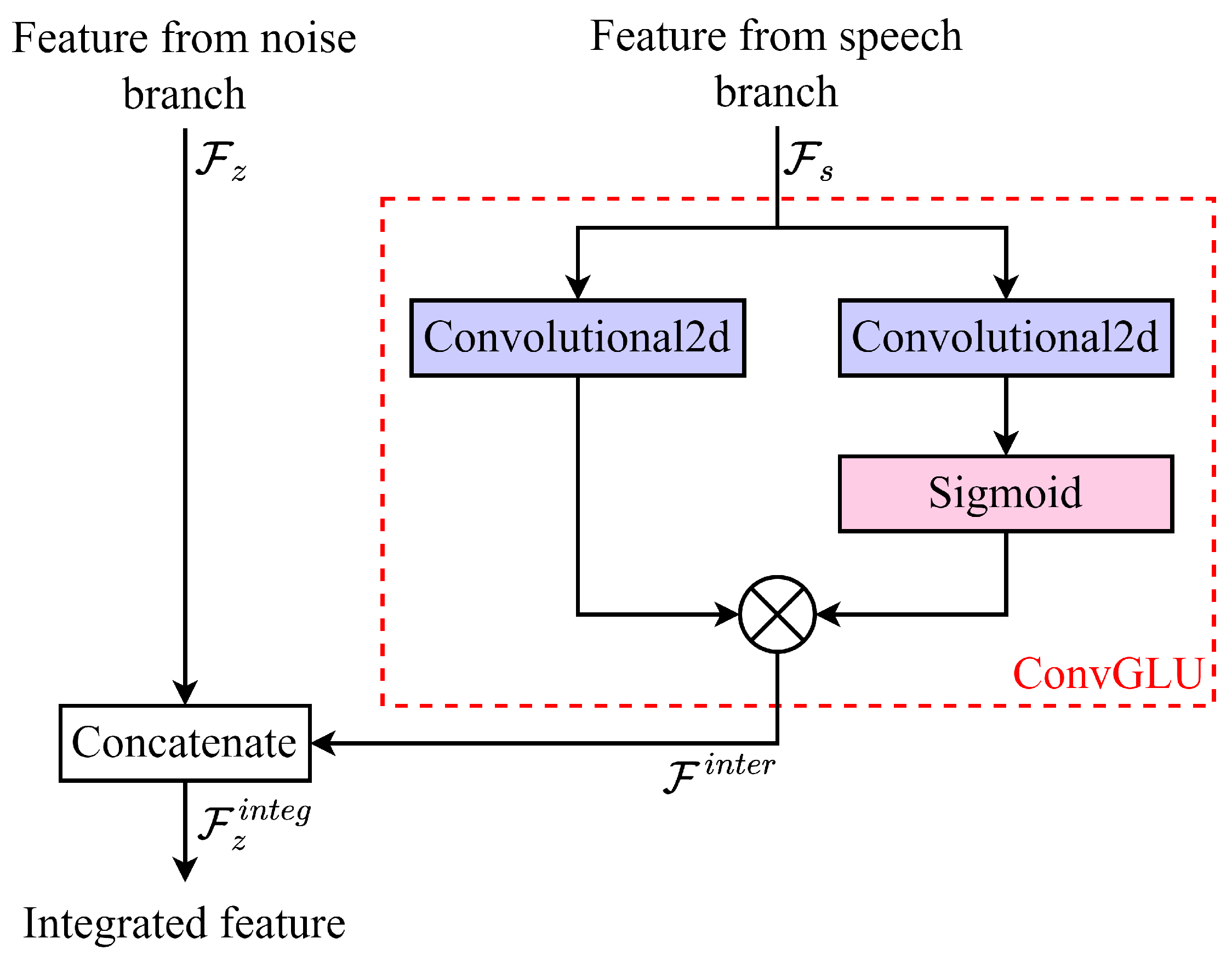
In this work, we propose a unidirectional information interaction-based dual-branch network, abbreviated as UniInterNet. In the UniInterNet, intermediate features only flow from the speech branch to noise branch, thereby promoting the noise modeling. While the information flow from the noise branch to speech branch is discarded. in this way, the speech branch does not depend on any information from the noise branch when generating the enhanced speech. Therefore, the noise branch is utilized to assist the learning of speech branch by backpropagating the noise modeling results during the model training stage, and it is not needed in the deployment phase. Compared to the previous dual-branch methods [
29,
31], the proposed UniInterNet not only retains the benefit of noise prediction for SE but also reduces the deployment cost by avoiding the use of dual-branch network in the model inference stage. Moreover, previous methods typically employ the same network structure to construct the speech and noise branches. In contrast, we adopt a more complicated, and even non-causal network structure for the noise branch, while limiting the complexity and ensuring the causality of the speech branch. As a result, the noise modeling accuracy is guaranteed, and the computational cost and algorithm delay during the model inference phase are also satisfactory.
In addition, we adopt short-time discrete cosine transform (STDCT) [
32] instead of the most commonly used short-time Fourier transform (STFT) for TF transformation. Unlike the complex-valued STFT spectrum, the STDCT spectrum is real-valued and implicitly contains both the magnitude and phase information. This escapes the phase estimation problem in the STFT-based methods, thereby simplifying the design of DNN and improving the computational efficiency.
The contributions of this study are as follows: (1) A unidirectional information interaction scheme is proposed to optimize the previous bidirectional interactive speech and noise modeling-based dual-branch SE framework so as to effectively reduce the model deployment costs without significant performance degradation. (2) As both the speech and noise branches utilize the CRN as backbone, experiments illustrate that the information interactions between the two branches’ encoders, recurrent modules, and decoders are all beneficial and necessary. (3) Ensuring causal inference, experimental results demonstrate the superiority of the proposed unidirectional information interaction-based SE model over existing benchmarks. The performance evaluation results of UniInterNet on both the VoiceBank+DEMAND [
33] and DNS-Challenge [
34] datasets are presented.
5. Conclusions
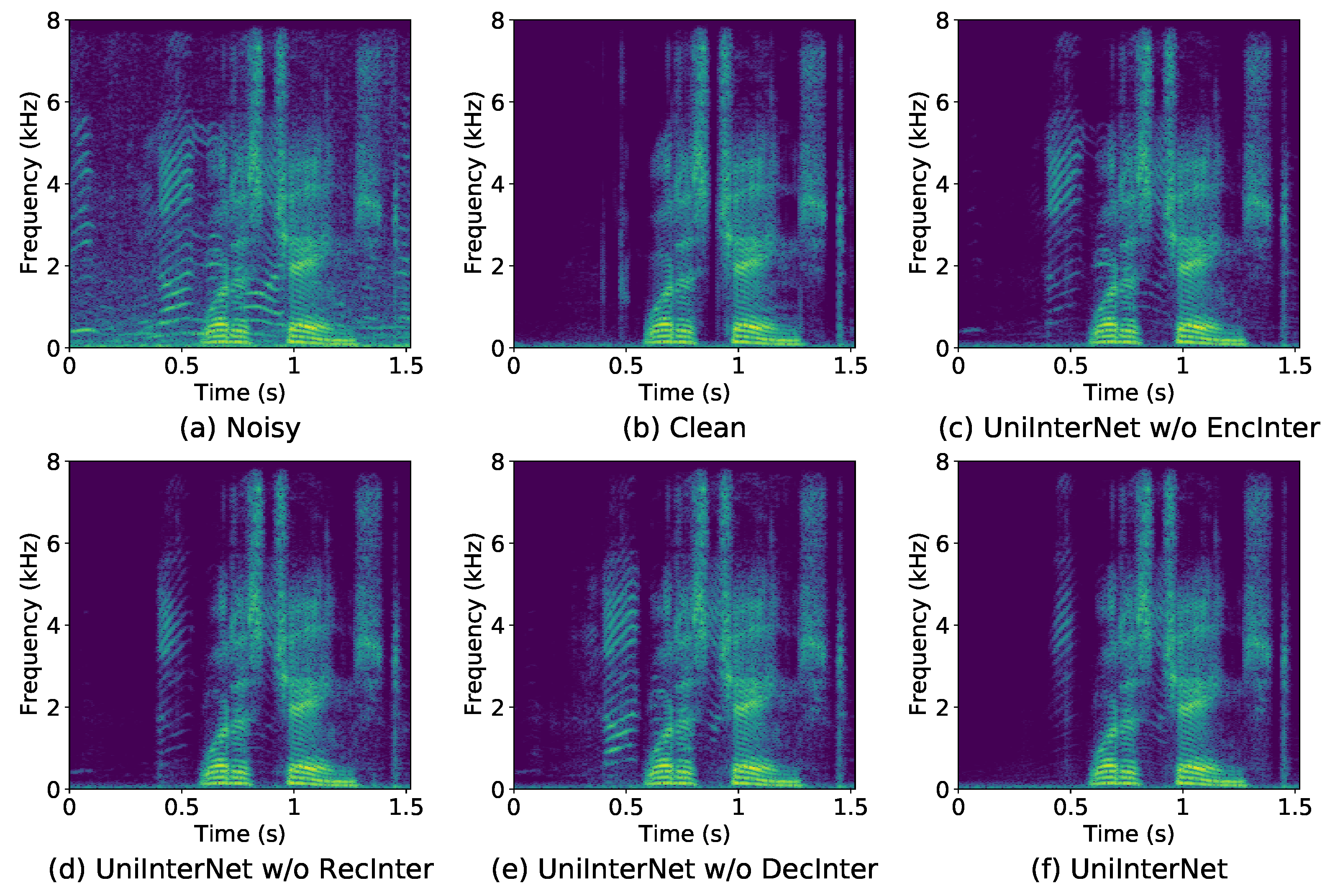
In this work, we design a novel SE model architecture based on a dual-branch network and auxiliary noise prediction. A unidirectional interaction module is proposed and inserted between the two branches to transfer useful information from the speech branch to the noise branch. As a result, the noise branch is not needed during the model deployment phase, which reduces the deployment cost compared to previous bidirectional interactive speech and noise modeling-based methods. Additionally, the speech branch is designed to be causal for small algorithm delay, while the noise branch adopts a non-causal design to improve the noise modeling accuracy and better assist the optimization of the speech branch. Therefore, UniInterNet offers great advantages over existing bidirectional interactive speech and noise modeling-based benchmark in terms of inference delay. Experimental results demonstrate the effectiveness of our design, where the proposed UniInterNet maintains comparable performance to the traditional dual-branch bidirectional interactive methods while significantly reducing the model inference complexity. Moreover, we find that the unidirectional information interaction between the two branches is necessary in all processing stages, including the high-level feature extraction at the encoder, the sequence modeling analysis at the recurrent module, and the target mask estimation at the decoder. Removing the unidirectional interaction module at any one of the three parts results in performance degradation. Among the three parts, the information interaction at the decoders is the most important. Eventually, the proposed UniInterNet outperforms the previous advanced methods on both VoiceBank+DEMAND and DNS-Challenge datasets.
In the future, we plan to integrate other related tasks into this proposed framework, such as speech dereverberation, declipping, and super-resolution. This expansion is motivated by research findings indicating that TF domain speech processing algorithms based on spectrum mask prediction remain effective for the related speech processing tasks.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}