
A New, Robust, Adaptive, Versatile, and Scalable Abandoned Object Detection Approach Based on DeepSORT Dynamic Prompts, and Customized LLM for Smart Video Surveillance



Abstract
1. Introduction
- Autonomous vehicles;
- Voice and video processing;
- Natural language processing;
- Handwritten character recognition;
- Medical image processing;
- Signature verification;
- Big data.
- This study focuses on providing a new and versatile method for abandoned object detection.
- Real-time, fast, and high-accuracy abandoned object detection is achieved with the integrated use of deep learning-based models.
- The use of YOLOv8, DeepSORT, and GenAI makes abandoned object detection more accurate and faster, while keyframe detection increases the efficiency by ensuring that only important frames are processed.
- The applicability of the model is supported by the result explanation module, which is suitable for improvement with user feedback based on the large language model.
- It is a pioneering approach to perform abandoned object detection in public areas in real time and with a low hardware cost.
- The created system will be used in subsequent studies as a module of the Video Analytics Artificial Intelligence library.
2. Related Work
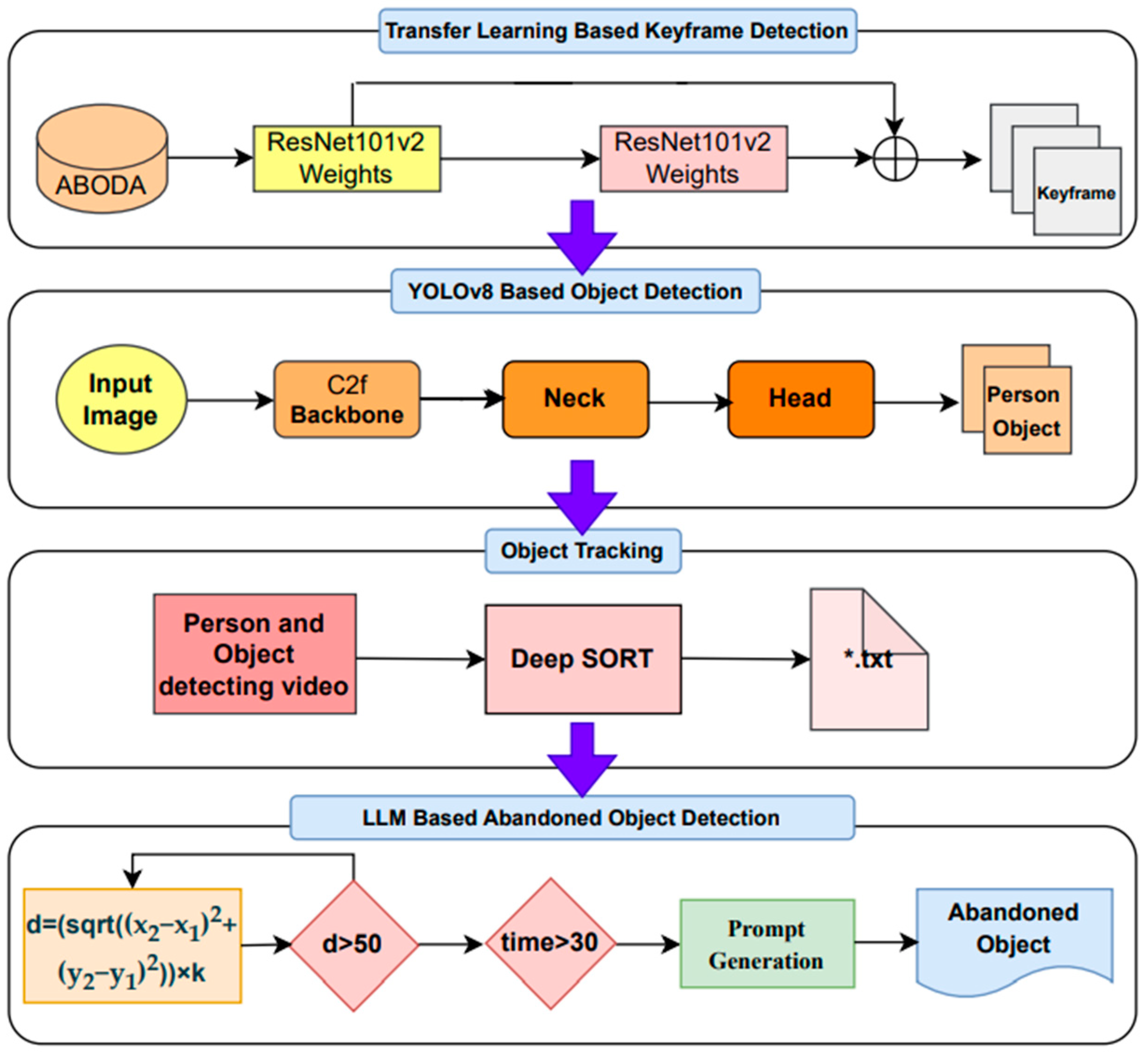
3. Proposed Approach
- Keyframes based on deep transfer learning were detected in the dataset.
- The YOLOv8 deep neural network was used in different sub-architectures to detect people and objects, such as bags, suitcases, etc., in the videos.
- The weights of the YOLOv8l model with the highest performance were recorded to be used as the input in the DeepSort algorithm.
- The object and human classes detected using the Deepsort object tracking algorithm were tracked. The ID and coordinate information of the human and object classes were recorded in a *.txt file for each frame.
- To detect abandoned objects, the duration of the object staying in the same place in consecutive frames was determined. Then, the distance between the human and the object class was measured using the coordinate information in the *.txt file.
| Algorithm 1: Steps to implement the proposed approach |
| Step 1: Keyframe Detection keyframes = detect_keyframes(dataset) Step 2: Object and Human Detection with YOLOv8 for each frame in video: Object and human detection is done with YOLOv8 detections = YOLOv8.detect(frame) Classes of objects: People, bags, suitcases etc. people = filter_classes(detections, “person”) objects = filter_classes(detections, [“bag”, “suitcase”, “object”]) Deepsort tracks objects tracked_objects = Deepsort.track(people + objects) The ID and coordinate information of the tracked objects are saved save_tracking_info_to_txt(tracked_objects) Step 3: Abandoned Object Detection abandoned_objects = [] for each frame in video: Get coordinate and ID information from *.txt file tracking_data = load_tracking_data_from_txt(frame) The time the object stays in the same place is calculated if is_object_still(tracking_data, frame): time_stayed = calculate_time_stayed(tracking_data) If the object is stationary for a certain period of time, it may be abandoned if time_stayed > threshold_time: The distance is checked distance = calculate_distance(tracking_data[“person”], tracking_data[“object”]) If the distance is greater than 50 cm, it is considered abandoned if distance > 50: abandoned_objects.append(tracking_data[“object”]) Step 4: Generating Descriptive Output with GPT-3.5-Turbo for each abandoned_object in abandoned_objects: Send the object and human coordinate information to the GPT-3.5-Turbo model descriptive_output = generate_descriptive_output_with_GPT3(tracking_data) |
| print(descriptive_output) |
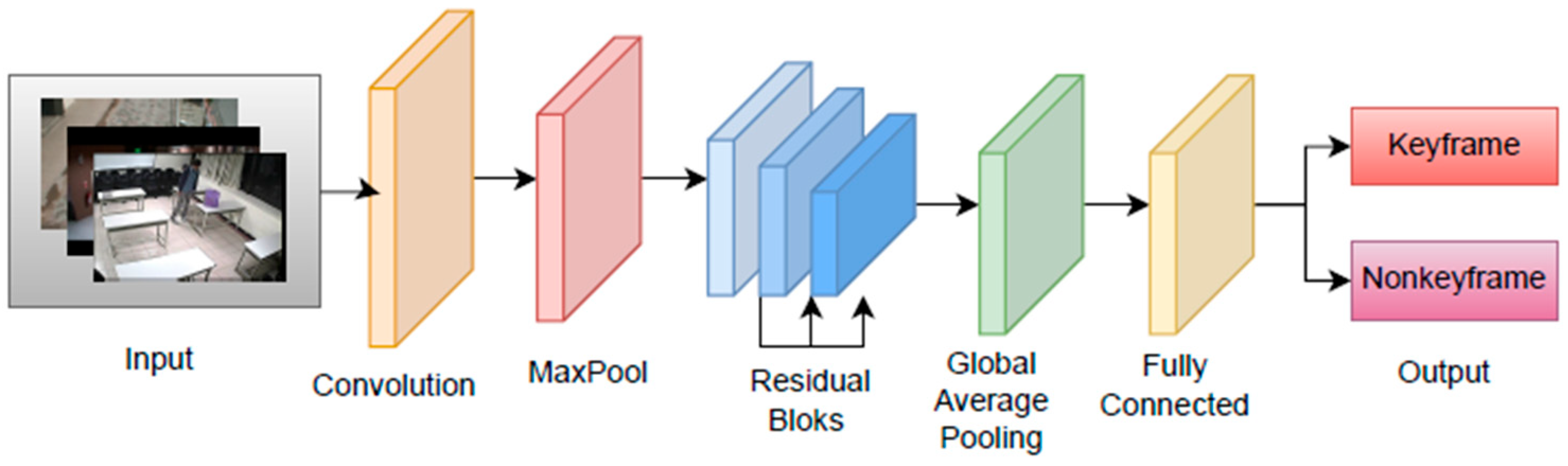
3.1. Keyframe Detection with Transfer Learning
3.2. YOLOv8-Based Person and Object Detection
- It has a single stage and high detection speed;
- It provides high accuracy (mAP) on visual data;
- Its architecture is not complex;
- It does not require high-standard hardware.
3.3. Object Tracking with DeepSORT
- High tracking accuracy due to using deep features;
- Not having a high computational cost;
- Providing image tracking, even in densely crowded environments.
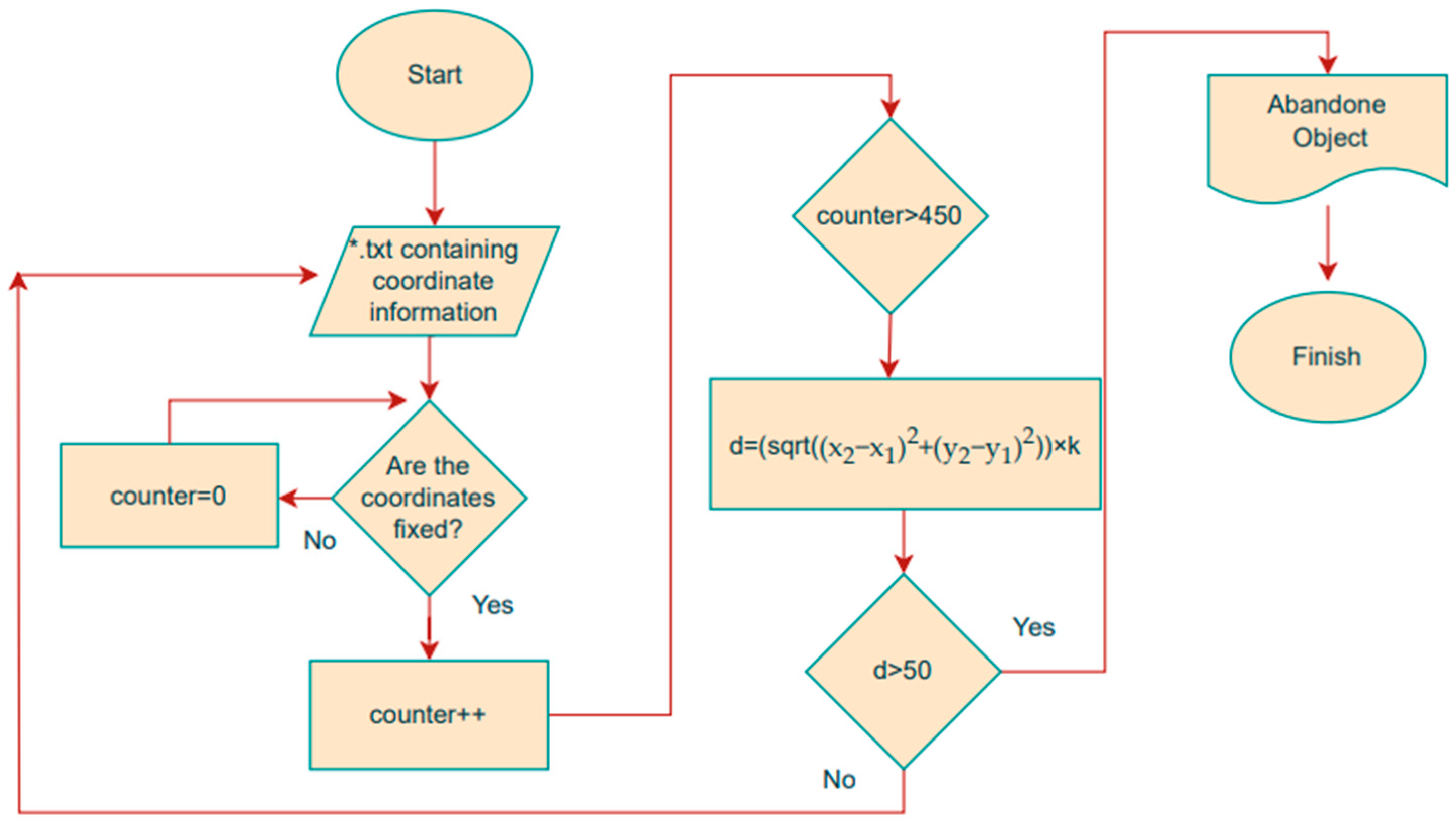
3.4. Abandoned Object Detection
| Algorithm 2: Abandoned Object Detection |
| Input: DeepSort Output Video Class Coordinate Information txt folder Output: Abandoned Object while f < 450 Time calculation if |x(t) − x(t − 1) |= 0 & |y(t) − y(t − 1) |= 0 f = f + 1 else f = 0 while i < d Measure distance between person and object d = (sqrt((x2 − x1)^2 + (y2 − y1)^2)) × k if distance (d) > 50 then Object = Abandoned Object else uptade new frame i = i + 1 |
| end |
4. Experimental Results
4.1. Keyframe Detection Results
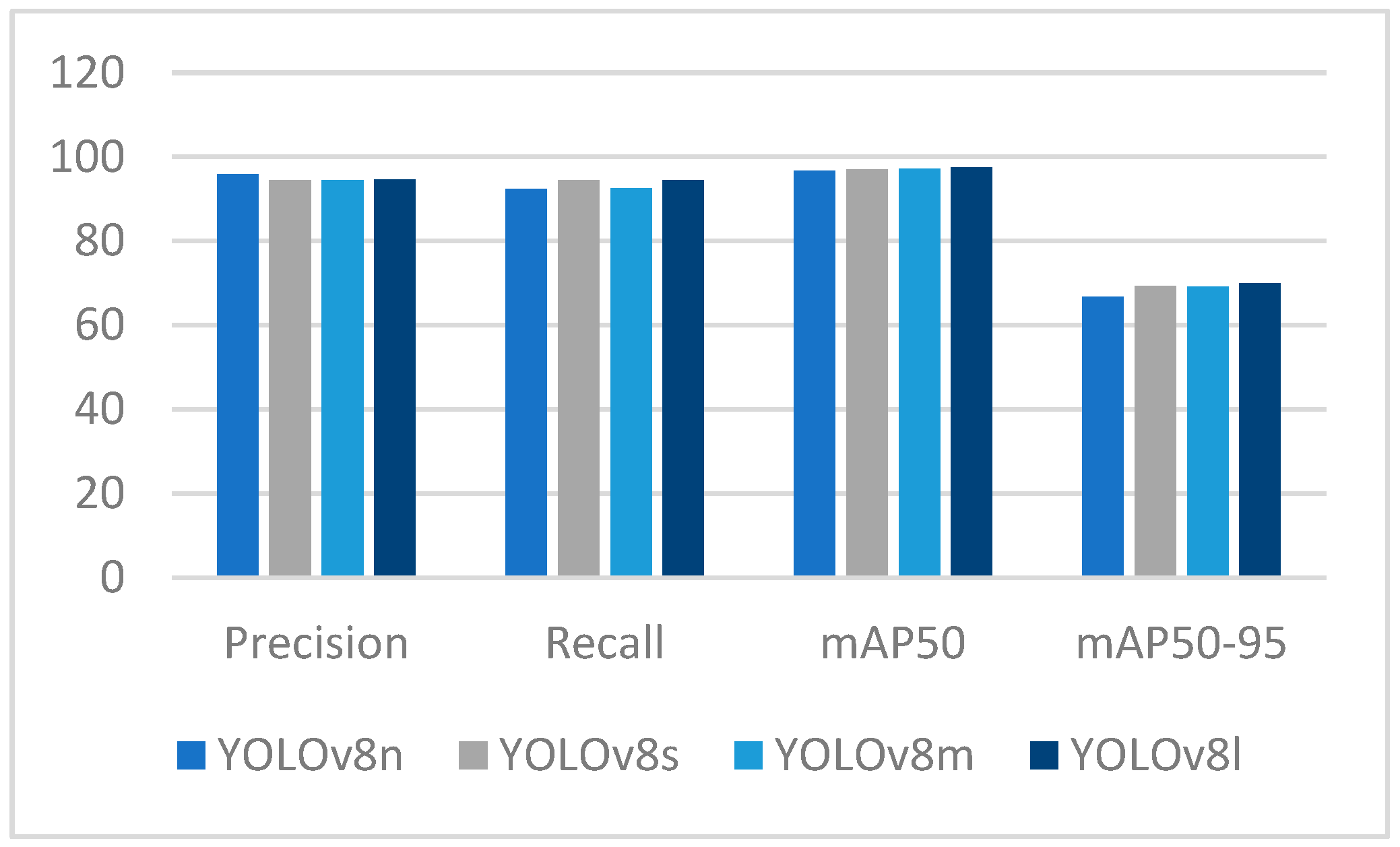
4.2. YOLOv8-Based Person and Object Detection Results
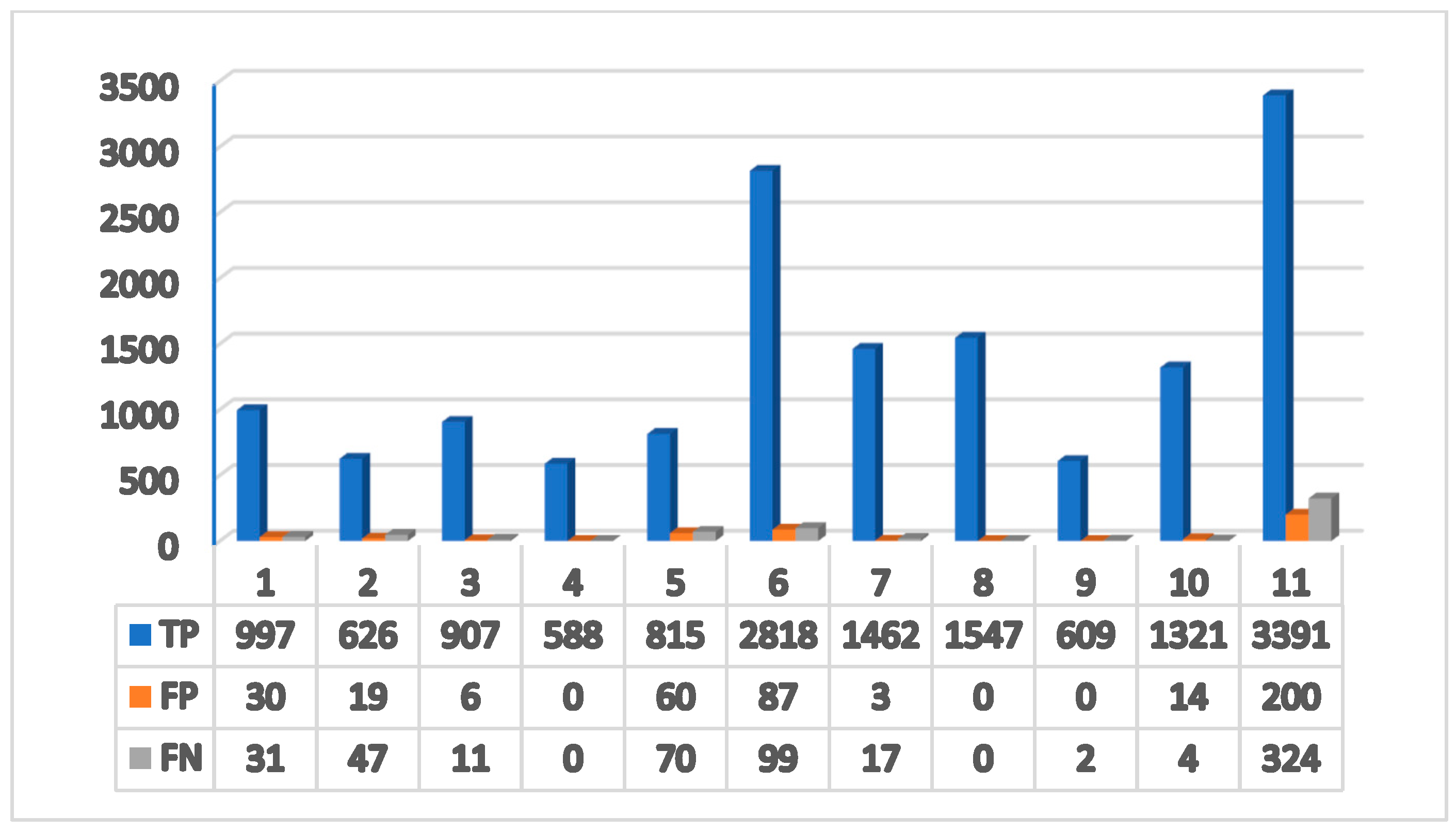
4.3. Object Tracking and Abandoned Object Detection Result
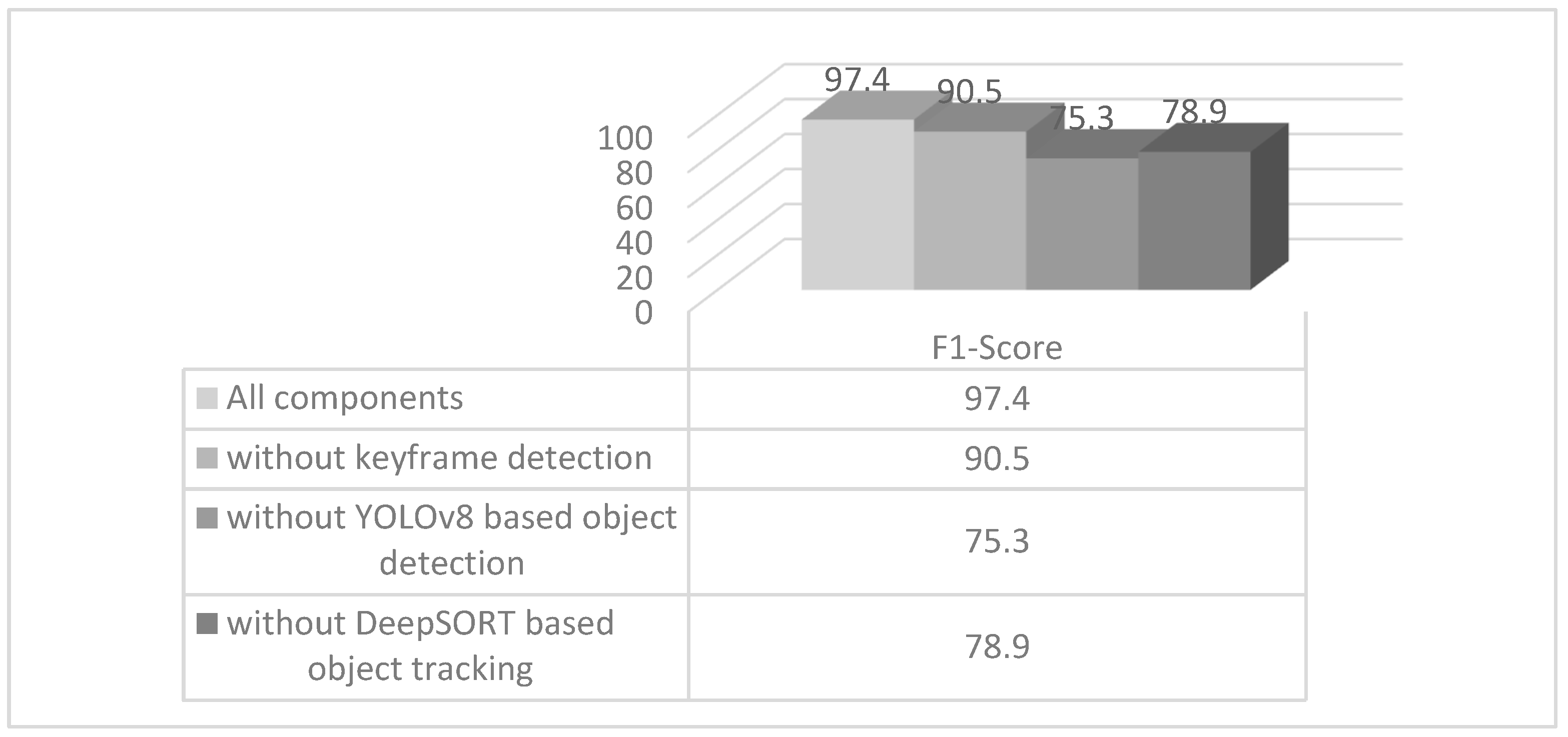
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wonghabut, P.; Kumphong, J.; Satiennam, T.; Ung-Arunyawee, R.; Leelapatra, W. Automatic helmet-wearing detection for law enforcement using CCTV cameras. IOP Conf. Ser. Earth Environ. Sci. 2018, 143, 012063. [Google Scholar] [CrossRef]
- Berardini, D.; Migliorelli, L.; Galdelli, A.; Frontoni, E.; Mancini, A.; Moccia, S. A deep-learning framework running on edge devices for handgun and knife detection from indoor video-surveillance cameras. Multimed. Tools Appl. 2024, 83, 19109–19127. [Google Scholar] [CrossRef]
- Cohen, N.; Gattuso, J.; MacLennan-Brown, K. CCTV Operational Requirements Manual 2009; Home Office Scientific Development Branch: St. Albans, UK, 2009. [Google Scholar]
- Tripathi, R.K.; Jalal, A.S.; Agrawal, S.C. Suspicious human activity recognition: A review. Artif. Intell. Rev. 2018, 50, 283–339. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Ristea, N.C.; Dăscălescu, D.; Ionescu, R.T.; Khan, F.S.; Shah, M. Lightning fast video anomaly detection via multi-scale adversarial distillation. Comput. Vis. Image Underst. 2024, 247, 104074. [Google Scholar] [CrossRef]
- Wang, H.; Wang, W.; Liu, J. Temporal memory attention for video semantic segmentation. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2254–2258. [Google Scholar] [CrossRef]
- Jha, S.; Seo, C.; Yang, E.; Joshi, G.P. Real time object detection and trackingsystem for video surveillance system. Multimed. Tools Appl. 2021, 80, 3981–3996. [Google Scholar] [CrossRef]
- Khan, S.; AlSuwaidan, L. Agricultural monitoring system in video surveillance object detection using feature extraction and classification by deep learning techniques. Comput. Electr. Eng. 2022, 102, 108201. [Google Scholar] [CrossRef]
- Yilmazer, M.; Karakose, M.; Tanberk, S.; Arslan, S. A New Approach to Detecting Free Parking Spaces Based on YOLOv6 and Keyframe Detection with Video Analytics. In Proceedings of the 2024 28th International Conference on Information Technology (IT), Zabljak, Montenegro, 21–24 February 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–4. [Google Scholar]
- Yilmazer, M.; Karakose, M. Mask R-CNN architecture based railway fastener fault detection approach. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1363–1366. [Google Scholar] [CrossRef]
- Yapıcı, M.M.; Tekerek, A.; Topaloğlu, N. Literature review of deep learning research areas. Gazi J. Eng. Sci. 2019, 5, 188–215. [Google Scholar] [CrossRef]
- Ucar, A.; Karakose, M.; Kırımça, N. Artificial intelligence for predictive maintenance applications: Key components, trustworthiness, and future trends. Appl. Sci. 2024, 14, 898. [Google Scholar] [CrossRef]
- Park, H.; Park, S.; Joo, Y. Detection of abandoned and stolen objects based on dual background model and mask R-CNN. IEEE Access 2020, 8, 80010–80019. [Google Scholar] [CrossRef]
- Ferariu, L.; Chile, C.F. Fusing Faster R-CNN and Background Subtraction Based on the Mixture of Gaussians Model. In Proceedings of the 2020 24th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 8–10 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 367–372. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Saluky, S.; Nugraha, G.B.; Supangkat, S.H. Enhancing Abandoned Object Detection with Dual Background Models and Yolo-NAS. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 547–554. [Google Scholar]
- Qasim, A.M.; Abbas, N.; Ali, A.; Al-Ghamdi, B.A.A.R. Abandoned Object Detection and Classification Using Deep Embedded Vision. IEEE Access 2024, 12, 35539–35551. [Google Scholar] [CrossRef]
- Li, G.; Ji, J.; Qin, M.; Niu, W.; Ren, B.; Afghah, F.; Ma, X. Towards high-quality and efficient video super-resolution via spatial-temporal data overfitting. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 10259–10269. [Google Scholar] [CrossRef]
- Dwivedi, N.; Singh, D.K.; Kushwaha, D.S. An approach for unattended object detection through contour formation using background subtraction. Procedia Comput. Sci. 2020, 171, 1979–1988. [Google Scholar] [CrossRef]
- Lwin, S.P.; Tun, M.T. Deep convonlutional neural network for abandoned object detection. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 4, 1549–1553. [Google Scholar]
- Ahammed, M.T.; Ghosh, S.; Ashik, M.A.R. Human and Object Detection using Machine Learning Algorithm. In Proceedings of the 2022 Trends in Electrical, Electronics, Computer Engineering Conference (TEECCON), Bengaluru, India, 26–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 39–44. [Google Scholar] [CrossRef]
- Jeong, M.; Kim, D.; Paik, J. Practical Abandoned Object Detection in Real-World Scenarios: Enhancements Using Background Matting with Dense ASPP. IEEE Access 2024, 12, 60808–60825. [Google Scholar] [CrossRef]
- Preetha, K.G. A fuzzy rule-based abandoned object detection using image fusion for intelligent video surveillance systems. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 3694–3702. [Google Scholar] [CrossRef]
- Melegrito, M.P.; Alon, A.S.; Militante, S.V.; Austria, Y.D.; Polinar, M.J.; Mirabueno, M.C.A. Abandoned-cart-vision: Abandoned cart detection using a deep object detection approach in a shopping parking space. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 13–15 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Park, H.; Park, S.; Joo, Y. Robust detection of abandoned object for smart video surveillance in illumination changes. Sensors 2019, 19, 5114. [Google Scholar] [CrossRef]
- Russel, N.S.; Selvaraj, A. Ownership of abandoned object detection by integrating carried object recognition and context sensing. Vis. Comput. 2023, 40, 4401–4426. [Google Scholar] [CrossRef]
- Teja, Y.D. Static object detection for video surveillance. Multimed. Tools Appl. 2023, 82, 21627–21639. [Google Scholar] [CrossRef]
- Dubey, P.; Mittan, R.K. A Critical Study on Suspicious Object Detection with Images and Videos Using Machine Learning Techniques. SN Comput. Sci. 2024, 5, 505. [Google Scholar] [CrossRef]
- Dhevanandhini, G.; Yamuna, G. An optimal intelligent video surveillance system in object detection using hybrid deep learning techniques. Multimed. Tools Appl. 2024, 83, 44299–44332. [Google Scholar] [CrossRef]
- Nalgirkar, S.; Sharma, D.K.; Chandere, S.L.; Sasar, R.K.; Kasurde, G.N. Next-Gen Security Monitoring: Advanced Machine Learning for Intelligent Object Detection and Assessment in Surveillance. Int. J. Multidiscip. Innov. Res. Methodol. 2023, 2, 6–13. [Google Scholar]
- Lin, K.; Chen, S.C.; Chen, C.S.; Lin, D.T.; Hung, Y.P. Abandoned object detection via temporal consistency modeling and back-tracing verification for visual surveillance. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1359–1370. [Google Scholar] [CrossRef]
- Amin, F.; Mondal, A.; Mathew, J. A large dataset with a new framework for abandoned object detection in complex scenarios. IEEE Multimed. 2021, 28, 75–87. [Google Scholar] [CrossRef]
- Wahyono; Pulungan, R.; Jo, K.H. Stationary object detection for vision-based smart monitoring system. In Intelligent Information and Database Systems, Proceedings of the 10th Asian Conference, ACIIDS 2018, Dong Hoi, Vietnam, 19–21 March 2018; Proceedings, Part II 10; Springer: Cham, Switzerland, 2018; pp. 583–593. [Google Scholar] [CrossRef]
- Abdulhussain, S.H.; Ramli, A.R.; Saripan, M.I.; Mahmmod, B.M.; Al-Haddad, S.A.R.; Jassim, W.A. Methods and challenges in shot boundary detection: A review. Entropy 2018, 20, 214. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Sadiq, B.O.; Muhammad, B.; Abdullahi, M.N.; Onuh, G.; Muhammed, A.A.; Babatunde, A.E. Keyframe extraction techniques: A review. ELEKTRIKA-J. Electr. Eng. 2020, 19, 54–60. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Vats, A.; Anastasiu, D.C. Enhancing retail checkout through video inpainting, yolov8 detection, and deepsort tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5530–5537. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Adu, G. Artificial Intelligence in Software Testing: Test Scenario and Case Generation with an AI Model (GPT-3.5-Turbo) Using Prompt Engineering, Fine-Tuning and Retrieval Augmented Generation Techniques. Master’s Thesis, University of Eastern Finland, Kuopio, Finland, 2024. [Google Scholar]
- He, Y.; Chen, W.; Tan, Y.; Wang, S. Usd: Unknown sensitive detector empowered by decoupled objectness and segment anything model. arXiv 2023, arXiv:2306.02275. [Google Scholar]
- Smeureanu, S.; Ionescu, R.T. Real-Time Deep Learning Method for Abandoned Luggage Detection in Video. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Dataset | Method |
|---|---|---|
| [19] | ABODA Dataset | Background subtraction method |
| [20] | Private Dataset | YOLOv4 |
| [22] | KISA Dataset. ABODA Dataset | Background Matting with Dense ASPP |
| [25] | PETS2006, ABODA, Private Dataset | Dual background model |
| [31] | PETS2006 and AVSS2007, ABODA Dataset | Short- and long-term background models |
| [32] | IITP20 Dataset, PETS06 Dataset, ABODA Dataset, CAVIAR Dataset | Convolutional Neural Network (CNN) |
| [33] | iLIDS and ISLab Dataset | SVM classifier |
| Video | Recorded Location | Lighting |
|---|---|---|
| 1 | Indoor | Normal indoor illumination |
| 2 | Outdoor | Daylight |
| 3 | Outdoor | Daylight |
| 4 | Outdoor | Daylight |
| 5 | Outdoor | Night |
| 6 | Outdoor | Night illumination |
| 7 | Indoor | Normal indoor illumination |
| 8 | Indoor | Contrast illumination |
| 9 | Indoor | Normal indoor illumination |
| 10 | Indoor | Normal indoor illumination |
| 11 | Indoor (Crowded) | Normal indoor illumination |
| Dataset | Model | Epoch | Optimizer | Image Size |
|---|---|---|---|---|
| ABODA | ResNet101v2 | 10 | Adam | 720 × 480 |
| Metric | Meaning |
|---|---|
| CR | Compression ratio |
| Nk | Total number of extracted keyframes |
| Nf | Total number of frames in the original video |
| Nm | Number of missed keyframes |
| Na | Number of correctly extracted keyframes |
| Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|
| 70% | 80% | 70% | 74% |
| Video | Nf | Nk | Na | Nm | CR | Calculation Time (s) | Keyframe Precision | Keyframe Recall | Keyframe F1-Score |
|---|---|---|---|---|---|---|---|---|---|
| V_1 | 2189 | 1058 | 1000 | 60 | 51.7% | 337 | 94.5% | 94.3% | 94.4% |
| V_2 | 2818 | 692 | 680 | 23 | 75.4% | 393 | 98.3% | 96.7% | 97.5% |
| V_3 | 2608 | 924 | 900 | 40 | 64.8% | 359 | 97.4% | 95.7% | 96.5% |
| V_4 | 1169 | 588 | 570 | 55 | 49.7% | 164 | 96.9% | 91.2% | 93.9% |
| V_5 | 3297 | 945 | 930 | 73 | 71.3% | 495 | 98.4% | 92.7% | 95.5% |
| V_6 | 6744 | 3004 | 2955 | 100 | 55.5% | 1043 | 98.4% | 96.7% | 97.5% |
| V_7 | 4801 | 1482 | 1346 | 84 | 69.1% | 681 | 90.8% | 94.1% | 92.4% |
| V_8 | 4781 | 1547 | 1507 | 98 | 67.6% | 675 | 97.4% | 93.9% | 95.6% |
| V_9 | 2485 | 611 | 600 | 65 | 75.4% | 322 | 98.2% | 90.2% | 94.0% |
| V_10 | 2260 | 1339 | 1298 | 39 | 40.8% | 307 | 96.9% | 97.1% | 97.0% |
| V_11 | 4501 | 3915 | 2500 | 77 | 13.0% | 657 | 63.9% | 97.0% | 77.0% |
| Video | Precision | Recall | F1-Score |
|---|---|---|---|
| 1 | 97.0% | 97.0% | 97.0% |
| 2 | 97.0% | 93.0% | 95.0% |
| 3 | 99.3% | 98.8% | 99.0% |
| 4 | 100% | 100% | 100% |
| 5 | 93.1% | 92.1% | 92.6% |
| 6 | 97.0% | 96.6% | 96.8% |
| 7 | 99.8% | 98.9% | 99.3% |
| 8 | 100% | 100% | 100% |
| 9 | 100% | 99.7% | 99.8% |
| 10 | 98.9% | 99.7% | 99.3% |
| 11 | 94.4% | 91.2% | 92.7% |
| Feature | Contribution | Contribution Rate |
|---|---|---|
| New | New in terms of integrating advanced deep learning technologies for object detection and tracking. | The method supported by new transformer-based models is an innovative study in the field with a confidence rate of over 97%. |
| Robust | In cases where objects are partially visible in consecutive frames or disappear and become visible again, DeepSORT can be used to track them when they become visible again. Robust due to its ability to continue its function even in such unexpected situations. | Our model can detect abandoned objects with a 97.4% f1-score confidence rate. |
| Adaptive | Adaptive due to providing high detection rates on images obtained under different lighting and climate conditions. | Our model can adapt to 15% data changes at a rate of 90%. |
| Versatile | Versatile due to its capacity to perform multiple phased functions, such as keyframe detection, detection of human/object classes, tracking of human/object classes, and abandoned object detection. | Our model is versatile with a minimum f1-score of 92% in indoor, outdoor, and different lighting conditions. |
| Scalable | Scalable due to its applicability on datasets of different sizes than those used experimentally in the study. | Although the calculation time increases as the video size increases, the keyframe detection rate remains limited to 20% at most. |
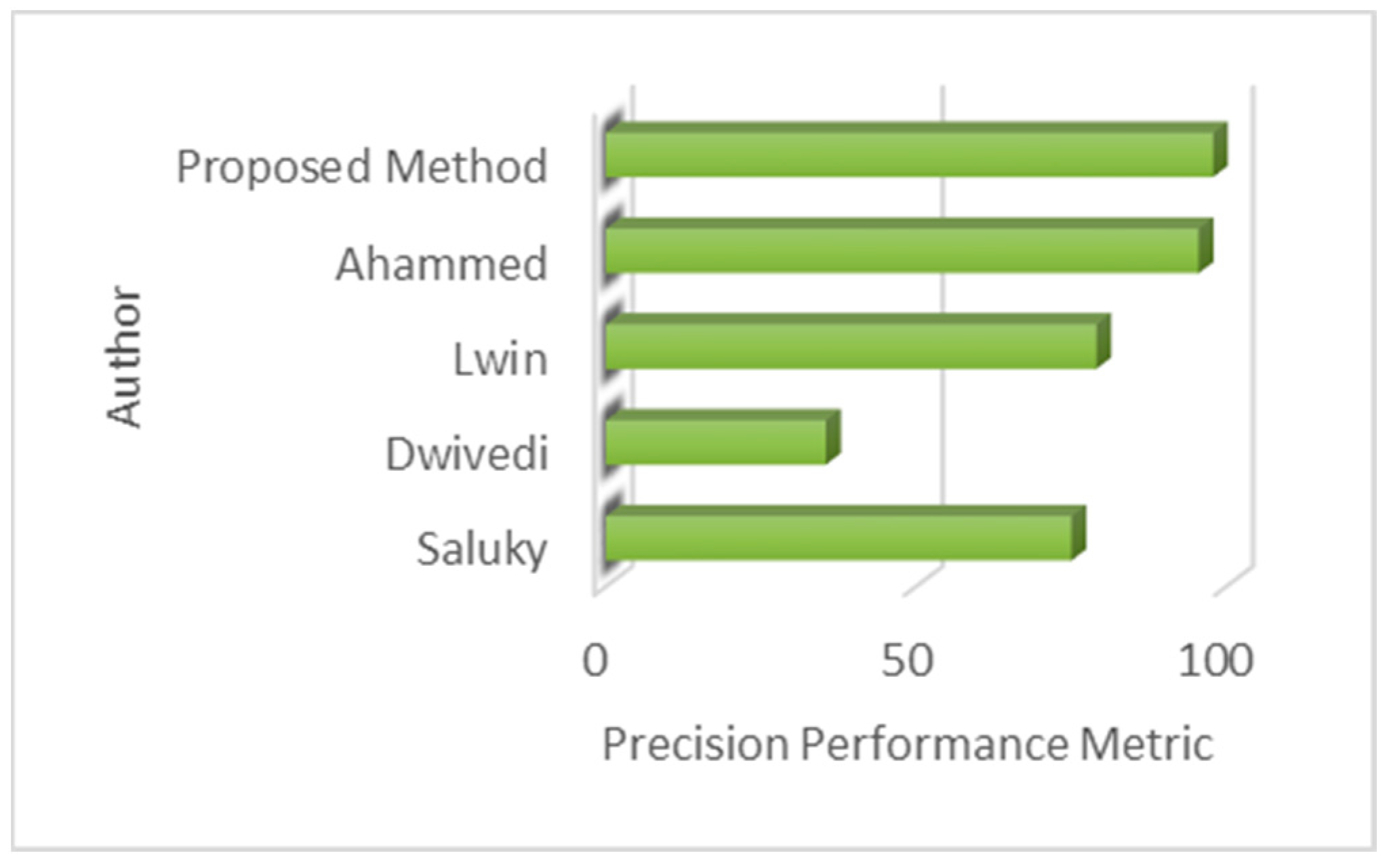
| Ref. | Dataset | Method | p (%) | r (%) | f1 (%) |
|---|---|---|---|---|---|
| [15] | ABODA | Dual background model YOLO-NAS | 75.00 | 75.00 | 75.00 |
| [18] | ABODA | Background subtraction | 35.41 | 70.83 | - |
| [19] | Self-collected dataset | YOLOv4 + Kalman Filter (KF) | 79.00 | 86.00 | 83.00 |
| [20] | i-Lids AVSS-AB data | YOLOv3 | 95.50 | 56.40 | - |
| Our Method | ABODA | Keyframe detection, YOLOv8l + Deep SORT | 97.90 | 97.00 | 97.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yilmazer, M.; Karakose, M. A New, Robust, Adaptive, Versatile, and Scalable Abandoned Object Detection Approach Based on DeepSORT Dynamic Prompts, and Customized LLM for Smart Video Surveillance. Appl. Sci. 2025, 15, 2774. https://doi.org/10.3390/app15052774
Yilmazer M, Karakose M. A New, Robust, Adaptive, Versatile, and Scalable Abandoned Object Detection Approach Based on DeepSORT Dynamic Prompts, and Customized LLM for Smart Video Surveillance. Applied Sciences. 2025; 15(5):2774. https://doi.org/10.3390/app15052774
Chicago/Turabian StyleYilmazer, Merve, and Mehmet Karakose. 2025. "A New, Robust, Adaptive, Versatile, and Scalable Abandoned Object Detection Approach Based on DeepSORT Dynamic Prompts, and Customized LLM for Smart Video Surveillance" Applied Sciences 15, no. 5: 2774. https://doi.org/10.3390/app15052774
APA StyleYilmazer, M., & Karakose, M. (2025). A New, Robust, Adaptive, Versatile, and Scalable Abandoned Object Detection Approach Based on DeepSORT Dynamic Prompts, and Customized LLM for Smart Video Surveillance. Applied Sciences, 15(5), 2774. https://doi.org/10.3390/app15052774