
Case Study on Analysis of Soil Compression Index Prediction Performance Using Linear and Regularized Linear Machine Learning Models (In Korea)



Abstract
1. Introduction
2. Overview of the Study Area and Data Validity
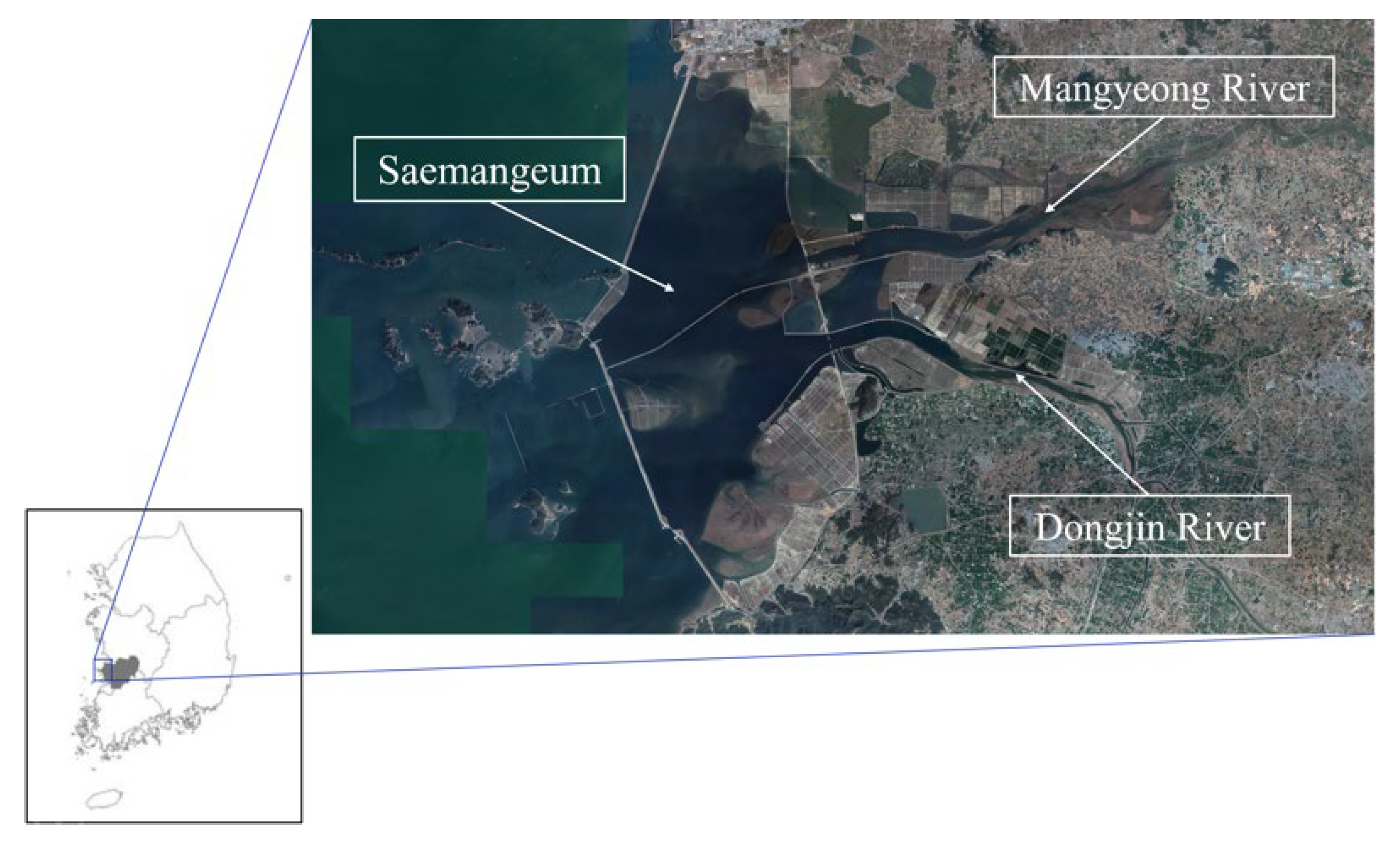
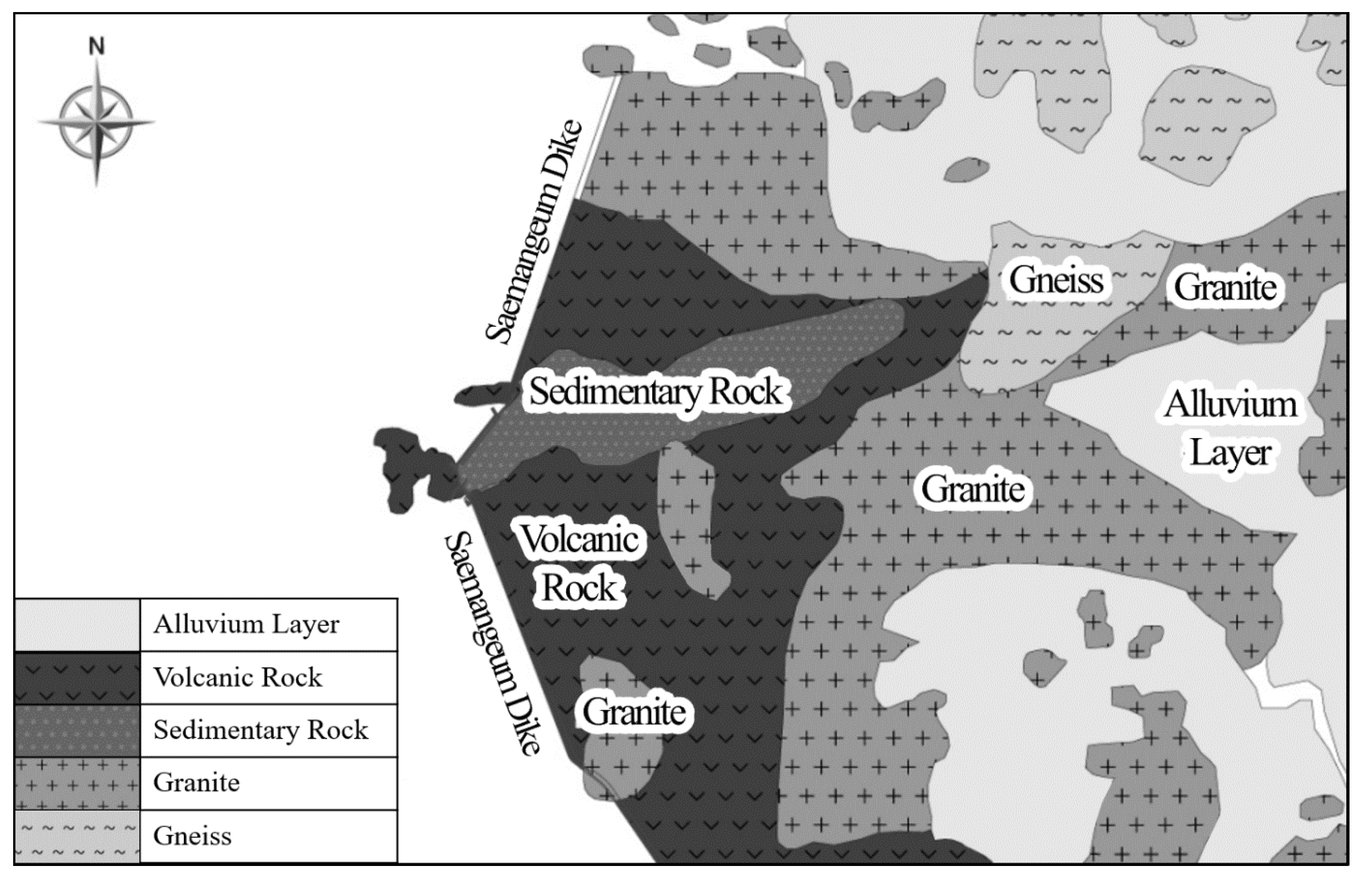
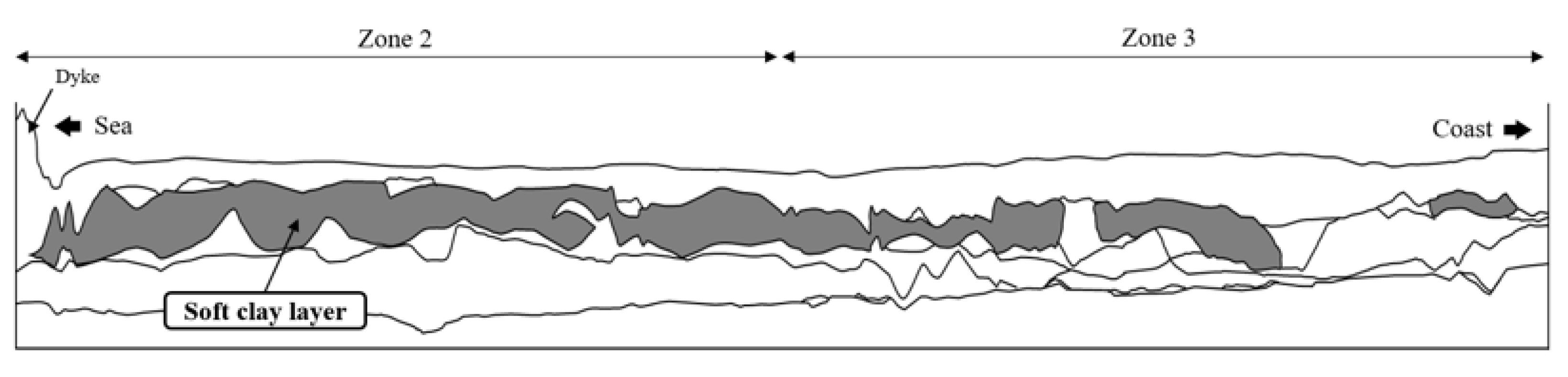
2.1. Hydrogeological Overview of the Saemangeum Reclaimed Land
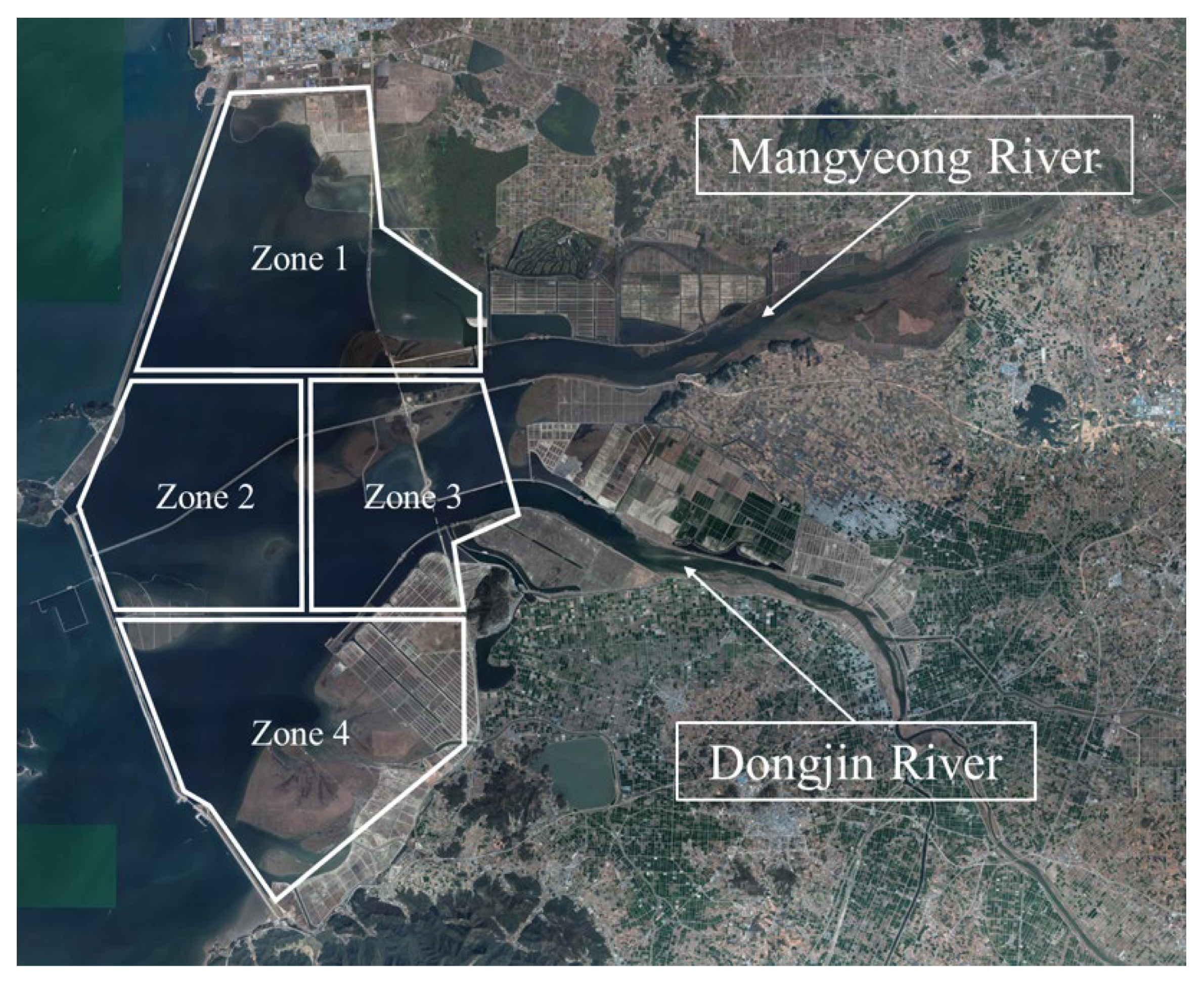
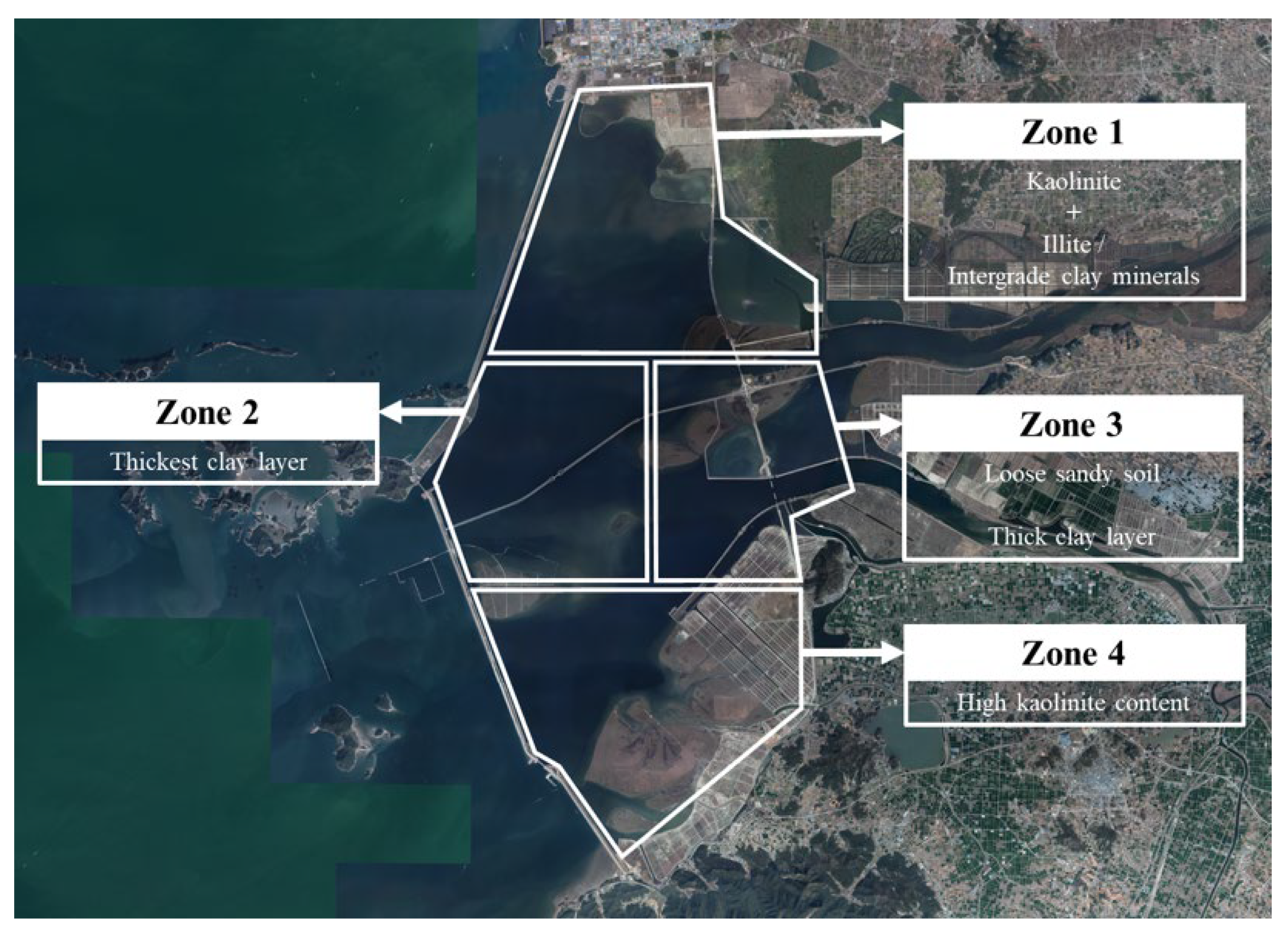
2.2. Zone Classification Based on Water Systems and Geological Characteristics
2.3. Data Validation (Assessing the Validity and Reliability of Data)
3. Machine Learning Techniques Based on Linear and Regularized Linear Models
3.1. Linear and Regularized Linear Models
3.1.1. Multiple Linear Regression (MLR)
3.1.2. Ridge Regression (RR)
3.1.3. LASSO (Least Absolute Shrinkage and Selection Operator) Regression (LR)
3.1.4. Elastic Net Regression (ENR)
3.2. Hyperparameter Tuning for Optimal Model
4. Model Prediction Results and Analysis
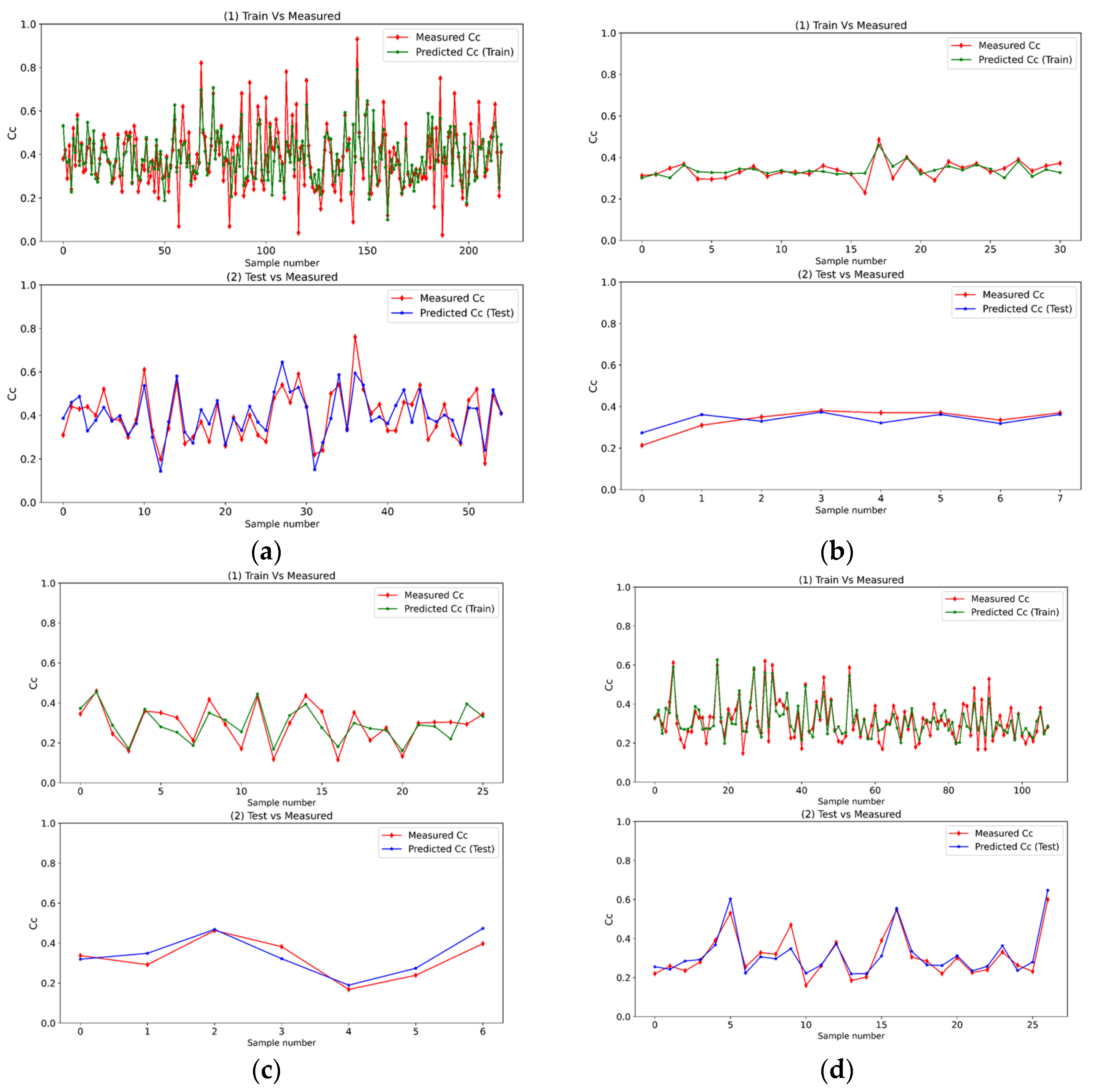
4.1. Prediction Results
4.2. Impact of Silt and Clay
4.3. Impact of Clay Minerals
5. Conclusions
- 1.
- Predicting the compression index of zones classified based on the geotechnical and hydrogeological characteristics resulted in improved model performance and prediction accuracy compared with using the entire dataset.
- 2.
- The silt and clay content of the soil significantly affected the performance of the ML models. Zone 2, which had the thickest clay layer (composed of clay and silt), experienced the lowest prediction accuracy due to its minimal hydrogeological influence and significant exposure to open-sea effects.
- 3.
- The type of clay minerals significantly affected the performance of the ML models, and differences in the composition of clay minerals in the soil led to differences in the prediction accuracy. Notably, zones 1, 3, and 4 exhibited a higher R2 compared with the predictions using the entire dataset. Additionally, zones influenced by a single water system (zones 1 and 4) demonstrated improved prediction performance, making the use of LR models more suitable. In contrast, zones influenced by multiple water systems (zones 2 and 3) showed relatively lower performance, where the use of MLR models was more appropriate.
- 4.
- When developing machine learning models to predict the compression index for large-scale sites, it is essential to define the influence range based on the hydrogeological characteristics of the target area and perform data preprocessing in accordance with the data distribution. Subsequently, the optimal design parameters must be calculated for each defined influence range.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, S. A Review on Trends in Ground Improvement Techniques. J. Geotech. Eng. 2018, 5, 18–22. [Google Scholar] [CrossRef]
- Gouw, T.L.; Gunawan, A. Vacuum Preloading, an alternative soft ground improvement technique for a sustainable development. IOP Conf. Ser. Earth Environ. Sci. 2020, 426, 012003. [Google Scholar] [CrossRef]
- Oda, K.; Yokota, K.; Bu, L.D. Stochastic estimation of consolidation settlement of soft clay layer with Artificial Neural Network. Jpn. Geotech. Soc. Spec. Publ. 2016, 2, 2529–2534. [Google Scholar] [CrossRef]
- KDS 44 30 00 Road Earthworks; Ministry of Land, Infrastructure and Transport: Sejong, Republic of Korea, 2022. (In Korean)
- Boulanger, R.W.; Idriss, I.M. Liquefaction susceptibility criteria for silts and clays. J. Geotech. Geoenviron. Eng. 2006, 132, 1413–1426. [Google Scholar] [CrossRef]
- Ural, N. The importance of clay in geotechnical engineering. In Current Topics in the Utilization of Clay in Industrial and Medical Applications; IntechOpen: London, UK, 2018. [Google Scholar]
- Younis, S.N.; Mahmood, R.A.; Alsaad, H.A. Swelling potential and mineralogy of al-Hartha City soil in Basrah-Southern Iraq. Iraqi J. Sci. 2024, 65, 2020–2030. [Google Scholar] [CrossRef]
- Firoozi, A.A.; Firoozi, A.A.; Baghini, M.S. A review of clayey soils. Asian J. Appl. Sci. 2016, 4, 1319–1330. [Google Scholar]
- Analysis of Ground Settlement and Deformation Behavior of Civil Engineering Structures; Korea National Housing Corporation: Jinju-si, Republic of Korea, 1994. (In Korean)
- Trinh Dinh, T. A study on settlements of road embankments on soft ground using vertical drains. Transp. Commun. Sci. J. 2024, 75, 1477–1488. [Google Scholar] [CrossRef]
- Kurnaz, T.F.; Dagdeviren, U.; Yildiz, M.; Ozkan, O. Prediction of compressibility parameters of the soils using artificial neural network. SpringerPlus 2016, 5, 1801. [Google Scholar] [CrossRef]
- Bardhan, A.; Kardani, N.; Alzo’ubi, A.K.; Samui, P.; Gandomi, A.H.; Gokceoglu, C. A comparative analysis of hybrid computational models constructed with swarm intelligence algorithms for estimating soil compression index. Arch. Comput. Method Eng. 2022, 29, 4735–4773. [Google Scholar] [CrossRef]
- Azzouz, A.S.; Krizek, R.J.; Corotis, R.B. Regression analysis of soil compressibility. Soils Found. 1976, 16, 19–29. [Google Scholar] [CrossRef]
- Rendon-Herrero, O. Universal compression index equation. J. Geotech. Eng. Div. 1980, 106, 1179–1200. [Google Scholar] [CrossRef]
- Koppula, S. Statistical estimation of compression index. Geotech. Test. J. 1981, 4, 68–73. [Google Scholar] [CrossRef]
- Park, H.I.; Lee, S.R. Evaluation of the compression index of soils using an artificial neural network. Comput. Geotech. 2011, 38, 472–481. [Google Scholar] [CrossRef]
- Kalantary, F.; Kordnaeij, A. Prediction of compression index using artificial neural network. Sci. Res. Essays 2012, 7, 2835–2848. [Google Scholar] [CrossRef]
- Nishida, Y. A brief note on Compression Index of Soil. J. Soil Mech. Found. Div. 1956, 82, 1–14. [Google Scholar] [CrossRef]
- Gunduz, Z.; Arman, H. Possible relationships between compression and recompression indices of a low-plasticity clayey soil. Arab. J. Sci. Eng. 2007, 32, 179–190. [Google Scholar]
- Terzaghi, K.; Peck, R.B.; Mesri, G. Soil Mechanics in Engineering Practice; John Wiley & Sons: New York, NY, USA, 1996. [Google Scholar]
- Kulkarni, M.P.; Patel, A.; Singh, D.N. Application of shear wave velocity for characterizing clays from coastal regions. KSCE J. Civ. Eng. 2010, 14, 307–321. [Google Scholar] [CrossRef]
- Alizadeh Majdi, A.; Dabiri, R.; Ganjian, N.; Ghalandarzadeh, A. Determination of the soil compression index (CC) in clayey soils using shear wave velocity (Case study: Tabriz city). Iran. J. Sci. Technol. Trans. Civ. Eng. 2018, 43, 577–588. [Google Scholar] [CrossRef]
- Al-Khafaji, A.W.; Andersland, O.B. Equations for compression index approximation. J. Geotech. Eng. ASCE 1992, 118, 148–153. [Google Scholar] [CrossRef]
- Ozer, M.; Isik, N.S.; Orhan, M. Statistical and neural network assessment of the compression index of clay-bearing soils. Bull. Eng. Geol. Environ. 2008, 67, 537–545. [Google Scholar] [CrossRef]
- Yoon, G.L.; Kim, B.T. Regression analysis of compression index for Kwangyang Marine Clay. KSCE J. Civ. Eng. 2006, 10, 415–418. [Google Scholar] [CrossRef]
- Ibrahim, D. An overview of soft computing. Procedia Comput. Sci. 2016, 102, 34–38. [Google Scholar] [CrossRef]
- Mamudur, K.; Kattamuri, M.R. Application of boosting-based ensemble learning method for the prediction of compression index. J. Inst. Eng. (India) Ser. A 2020, 101, 409–419. [Google Scholar] [CrossRef]
- Long, T.; He, B.; Ghorbani, A.; Khatami, S.M.H. Tree-based techniques for predicting the compression index of clayey soils. J. Soft Comput. Civ. Eng. 2023, 7, 52–67. [Google Scholar] [CrossRef]
- Lee, S.; Kang, J.; Kim, J.; Baek, W.; Yoon, H. A study on developing a model for predicting the compression index of the South Coast Clay of korea using statistical analysis and Machine Learning Techniques. Appl. Sci. 2024, 14, 952. [Google Scholar] [CrossRef]
- Kumar, V.P.; Rani, C.S. Prediction of compression index of soils using artificial neural networks (ANNs). Int. J. Eng. Res. Appl. 2011, 1, 1554–1558. [Google Scholar]
- Al-Taie, A.J.; Al-Bayati, A.F.; Taki, Z.N. Compression index and compression ratio prediction by Artificial Neural Networks. J. Eng. 2017, 23, 96–106. [Google Scholar] [CrossRef]
- Zhang, P.; Yin, Z.Y.; Jin, Y.F.; Chan, T.H.T.; Gao, F.P. Intelligent modelling of clay compressibility using hybrid meta-heuristic and machine learning algorithms. Geosci. Front. 2021, 12, 441–452. [Google Scholar] [CrossRef]
- Díaz, E.; Spagnoli, G. A super-learner machine learning model for a global prediction of compression index in Clays. Appl. Clay Sci. 2024, 249, 107239. [Google Scholar] [CrossRef]
- Final Design Report for the Saemangeum East-West Axis 2 Road Construction Project (Section 1); Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2015. (In Korean)
- Lee, H.J.; Jo, H.R.; Kim, M.J. Topographical changes and textural characteristics in the areas around the Saemangeum dyke. Ocean Polar Res. 2006, 28, 293–303. (In Korean) [Google Scholar] [CrossRef]
- Park, Y.A.; Kang, H.J.; Song, Y.I. Sandy sediment transport mechanism on tidal sand bodies, west coast of Korea. Korean J. Quat. Res. 1991, 5, 33–45. [Google Scholar]
- Choi, H.Y. Constitutive Characteristics Among Saemangeum Soft Ground. Master’s Thesis, Chung-Ang University, Seoul, Republic of Korea, 2023. [Google Scholar]
- Final Design Geotechnical Investigation Report for the Saemangeum East-West Axis 2 Road Construction Project (Section 1); Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2015. (In Korean)
- Geotechnical Investigation Report for the Saemangeum East-West Axis 2 Road Construction Project (Section 2); Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2015. (In Korean)
- Geotechnical Investigation Report for the Second Phase (Section 1) of the Saemangeum North-South Road Construction Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2018. (In Korean)
- Final Design Report for the Second Phase (Section 1) of the Saemangeum North-South Road Construction Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2018. (In Korean)
- Geotechnical Investigation Report for the Second Phase (Section 2) of the Saemangeum North-South Road Construction Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2018. (In Korean)
- Final Design Report for the Second Phase (Section 2) of the Saemangeum North-South Road Construction Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2018. (In Korean)
- Geotechnical Investigation Report for the Second Phase (Section 4) of the Saemangeum North-South Road Construction Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2017. (In Korean)
- Soil Investigation Report for the Saemangeum District Industrial Complex Development Project; Korea Rural Community Corporation: Naju-si, Republic of Korea, 2010. (In Korean)
- Geological and Material Source Investigation Report for the Saemangeum Smart Waterfront City Reclamation Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2021. (In Korean)
- Final Design Report for the Saemangeum Smart Waterfront City Reclamation Project; Saemangeum Development and Investment Agency: Gunsan-si, Republic of Korea, 2021. (In Korean)
- Bourouis, M.A.; Zadjaoui, A.; Djedid, A. The Neuro-genetic approach for estimating the compression index. J. Mater. Eng. Struct. 2018, 5, 305–315. [Google Scholar]
- Marill, K.A. Advanced statistics: Linear regression, part II: Multiple linear regression. Acad. Emerg. Med. 2004, 11, 94–102. [Google Scholar] [CrossRef] [PubMed]
- Farahani, H.A.; Rahiminezhad, A.; Same, L. A comparison of partial least squares (PLS) and ordinary least squares (OLS) regressions in predicting of couples mental health based on their communicational patterns. Procedia Soc. Behav. Sci. 2010, 5, 1459–1463. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras and Tensorflow; O’Reilly Media Inc.: Sebastopol, CA, USA, 2023. [Google Scholar]
- García-Nieto, P.J.; García-Gonzalo, E.; Paredes-Sánchez, J.P. Prediction of the critical temperature of a superconductor by using the WOA/Mars, Ridge, lasso and elastic-net machine learning techniques. Neural Comput. Appl. 2021, 33, 17131–17145. [Google Scholar] [CrossRef]
- Al-Obeidat, F.; Spencer, B.; Alfandi, O. Consistently accurate forecasts of temperature within buildings from sensor data using ridge and lasso regression. Future Gener. Comput. Syst. 2020, 110, 382–392. [Google Scholar] [CrossRef]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python, Scikit-Learn, and Tensorflow 2; Packt Publishing: Birmingham, UK, 2019. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Wang, S.; Ji, B.; Zhao, J.; Liu, W.; Xu, T. Predicting ship fuel consumption based on lasso regression. Transport. Res. Part D-Transport. Environ. 2018, 65, 817–824. [Google Scholar] [CrossRef]
- Chen, J.; de Hoogh, K.; Gulliver, J.; Hoffmann, B.; Hertel, O.; Ketzel, M.; Bauwelinck, M.; Van Donkelaar, A.; Hvidtfeldt, U.A.; Katsouyanni, K.; et al. A comparison of linear regression, regularization, and machine learning algorithms to develop Europe-wide spatial models of fine particles and Nitrogen Dioxide. Environ. Int. 2019, 130, 104934. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Factor | Correlation Coefficient | p-Value |
|---|---|---|---|
| 1 | wn | 0.7 | 0.000 |
| 2 | LL | 0.7 | 0.000 |
| 3 | PI | 0.69 | 0.000 |
| 4 | e0 | 0.75 | 0.000 |
| Min | Max | Mean | Std | ||
|---|---|---|---|---|---|
| Input Variable | wn (%) | 17.7 | 68.3 | 36.379 | 6.96 |
| LL (%) | 24.9 | 94 | 46.482 | 13.046 | |
| PI (%) | 2.2 | 62.8 | 24.778 | 13.295 | |
| e0 | 0.541 | 1.88 | 1.019 | 0.181 | |
| Output Variable | Cc | 0.03 | 0.93 | 0.359 | 0.127 |
| Zone | Model | Train Data | Test Data | |||
|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | |||
 | Total | MLR | 0.6258 | 0.0754 | 0.6742 | 0.0794 |
| RR | 0.6258 | 0.0754 | 0.6742 | 0.0794 | ||
| LR | 0.6233 | 0.0756 | 0.6699 | 0.08 | ||
| ENR | 0.6258 | 0.0754 | 0.6741 | 0.0794 | ||
 | Zone 1 | MLR | 0.5636 | 0.0942 | 0.7294 | 0.0591 |
| RR | 0.5636 | 0.0942 | 0.7296 | 0.0591 | ||
| LR | 0.5621 | 0.0944 | 0.7308 | 0.059 | ||
| ENR | 0.5635 | 0.0942 | 0.7298 | 0.0591 | ||
 | Zone 2 | MLR | 0.5002 | 0.0306 | 0.5539 | 0.0345 |
| RR | 0.4707 | 0.0315 | 0.5068 | 0.0363 | ||
| LR | 0.4177 | 0.033 | 0.4621 | 0.0379 | ||
| ENR | 0.4181 | 0.033 | 0.4628 | 0.0379 | ||
 | Zone 3 | MLR | 0.7159 | 0.0511 | 0.7575 | 0.0459 |
| RR | 0.4982 | 0.068 | 0.6543 | 0.0548 | ||
| LR | - | - | - | - | ||
| ENR | - | - | - | - | ||
 | Zone 4 | MLR | 0.7804 | 0.0492 | 0.831 | 0.0457 |
| RR | 0.7765 | 0.0497 | 0.8405 | 0.0444 | ||
| LR | 0.7695 | 0.0504 | 0.8546 | 0.0424 | ||
| ENR | 0.7692 | 0.0505 | 0.8527 | 0.0427 | ||
| Zone | Best Model | Regression Equation | R2 |
|---|---|---|---|
| 1 | LR | 0.7308 | |
| 2 | MLR | 0.5539 | |
| 3 | MLR | 0.7575 | |
| 4 | LR | 0.8546 |
| Zone 1 | Zone 2 | Zone 3 | Zone 4 | Saemangeum | |
|---|---|---|---|---|---|
| Mean R2 Value | 0.7299 | 0.4964 | 0.7059 | 0.8447 | 0.6942 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, S.; Kim, J.; Choi, H.; Lee, J.; Han, J. Case Study on Analysis of Soil Compression Index Prediction Performance Using Linear and Regularized Linear Machine Learning Models (In Korea). Appl. Sci. 2025, 15, 2757. https://doi.org/10.3390/app15052757
Ryu S, Kim J, Choi H, Lee J, Han J. Case Study on Analysis of Soil Compression Index Prediction Performance Using Linear and Regularized Linear Machine Learning Models (In Korea). Applied Sciences. 2025; 15(5):2757. https://doi.org/10.3390/app15052757
Chicago/Turabian StyleRyu, Seungyeon, Jin Kim, Hyoyeop Choi, Jongyoung Lee, and Junggeun Han. 2025. "Case Study on Analysis of Soil Compression Index Prediction Performance Using Linear and Regularized Linear Machine Learning Models (In Korea)" Applied Sciences 15, no. 5: 2757. https://doi.org/10.3390/app15052757
APA StyleRyu, S., Kim, J., Choi, H., Lee, J., & Han, J. (2025). Case Study on Analysis of Soil Compression Index Prediction Performance Using Linear and Regularized Linear Machine Learning Models (In Korea). Applied Sciences, 15(5), 2757. https://doi.org/10.3390/app15052757