A Benchmark for Water Surface Jet Segmentation with MobileHDC Method


Abstract
1. Introduction
- We introduce a benchmark for water jet trajectory extraction accompanied by two publicly available datasets, Libary and SegQinhu, providing a challenging set of real-world data to facilitate the development of intelligent jet systems;
- In light of the extreme pixel imbalance characteristic of the jet datasets, we propose a new evaluation protocol that comprehensively assesses the model’s segmentation results from the aspects of accuracy, continuity, and efficiency;
- We propose a pipeline solution with a novel backbone named MobileHDC, and extensive comparative experiments demonstrate that our method achieves optimal performance on the proposed benchmark.
2. Related Work
2.1. Segmentation Datasets
2.2. Jet Trajectory Extraction Methods
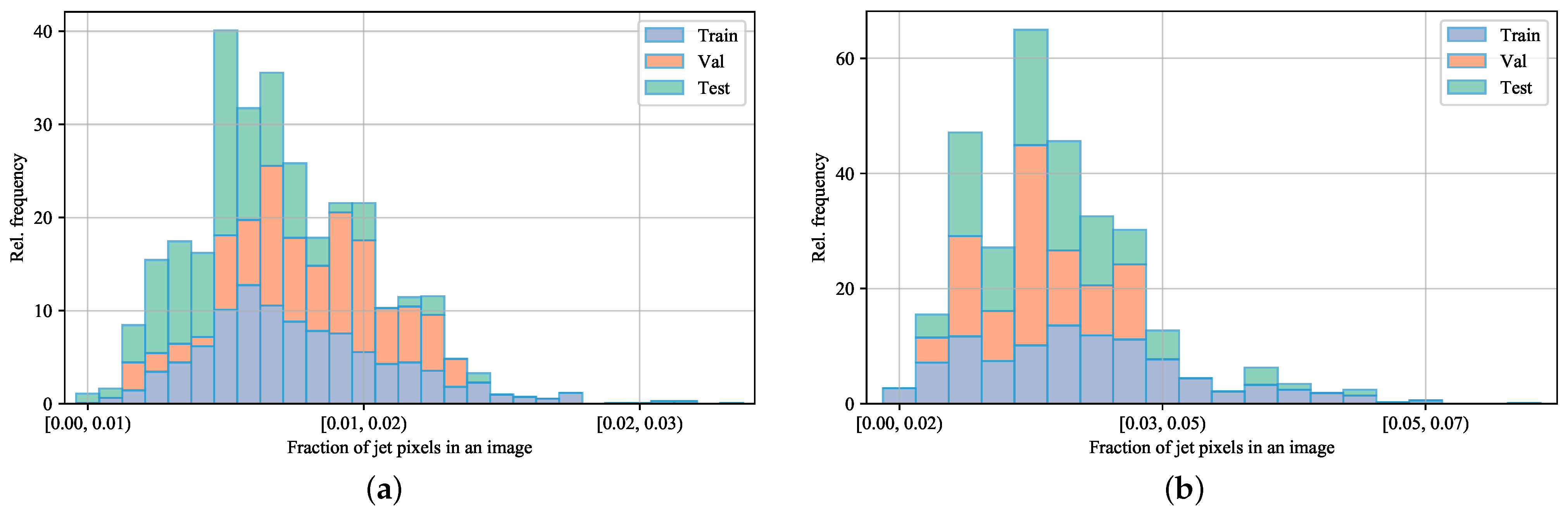
3. Benchmark Description
3.1. Motivation
3.2. Benchmark and Datasets
3.3. Metrics
3.3.1. Accuracy Evaluation Metrics
3.3.2. Continuity Evaluation Metrics
3.3.3. Efficiency Evaluation Metrics
4. Method
4.1. Overall Architecture
4.2. MobileHDC: A Novel Hybrid MobileNetV2 Backbone
4.3. Decoder Module
5. Experiments
5.1. Datasets
5.2. Implementation Details
5.3. Ablation Study
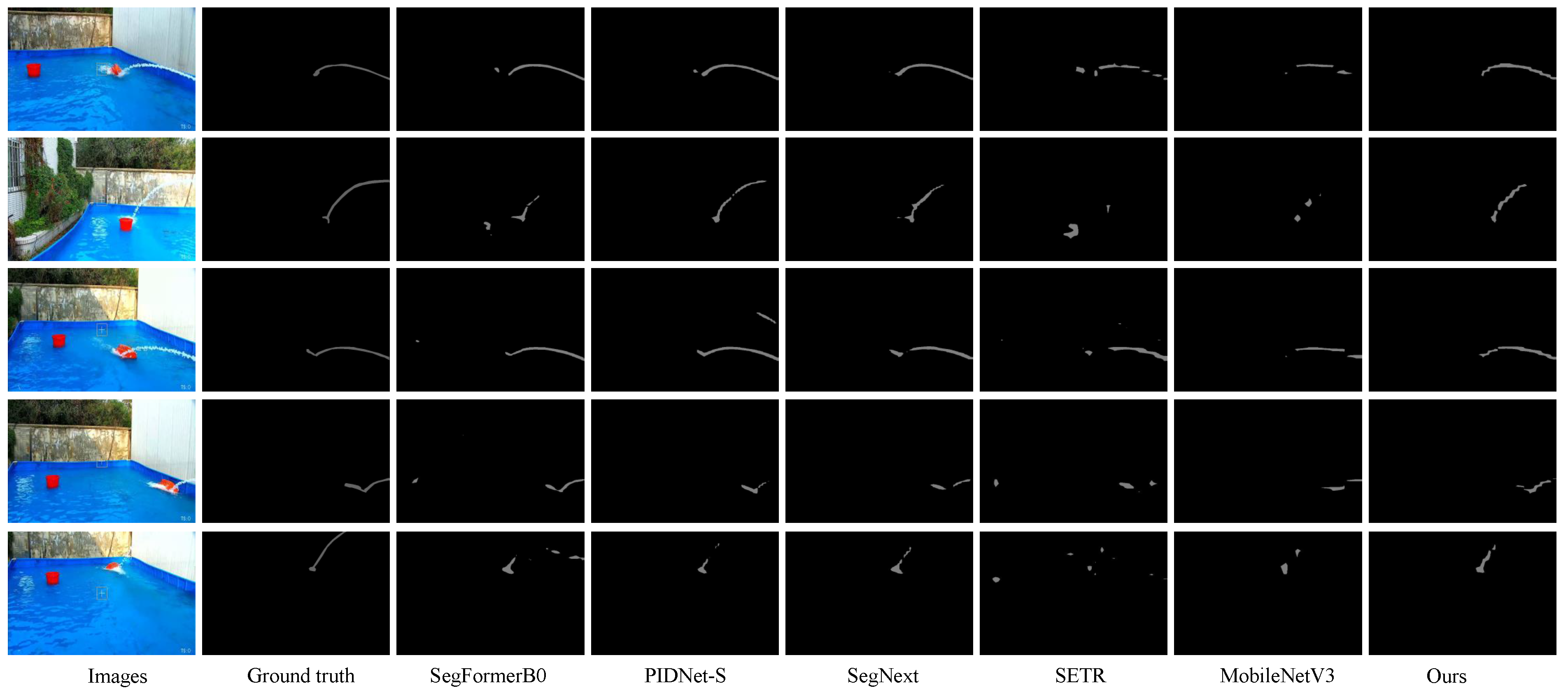
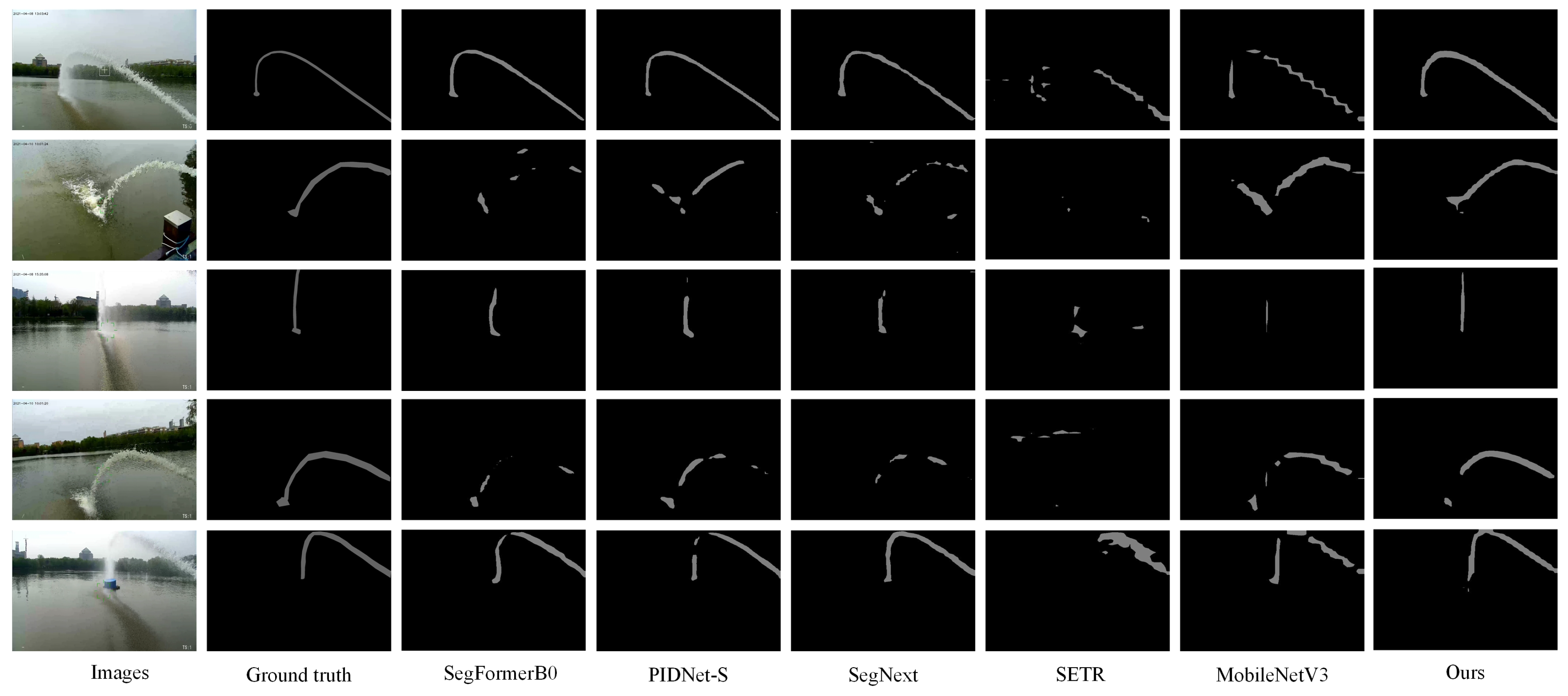
5.4. Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pérez-Guerrero, C.; Palacios, A.; Ochoa-Ruiz, G.; Mata, C.; Gonzalez-Mendoza, M.; Falcón-Morales, L.E. Comparing machine learning based segmentation models on jet fire radiation zones. In Proceedings of the Advances in Computational Intelligence: 20th Mexican International Conference on Artificial Intelligence, MICAI 2021, Mexico City, Mexico, 25–30 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 161–172. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1209–1218. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Xin, Y.; Thumuluru, S.; Jiang, F.; Yin, R.; Yao, B.; Zhang, K.; Liu, B. An experimental study of automatic water cannon systems for fire protection of large open spaces. Fire Technol. 2014, 50, 233–248. [Google Scholar] [CrossRef]
- Zhu, J.; Li, W.; Lin, D.; Zhao, G. Real-time monitoring of jet trajectory during jetting based on near-field computer vision. Sensors 2019, 19, 690. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Pan, L.; Zhao, G. An improved near-field computer vision for jet trajectory falling position prediction of intelligent fire robot. Sensors 2020, 20, 7029. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Gamal, M.; Siam, M.; Abdel-Razek, M. Shuffleseg: Real-time semantic segmentation network. arXiv 2018, arXiv:1803.03816. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Guo, Z.; Bian, L.; Huang, X.; Wei, H.; Li, J.; Ni, H. DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation. arXiv 2024, arXiv:2406.03702. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G.; Shen, C. Topformer: Token pyramid transformer for mobile semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12083–12093. [Google Scholar]
- Wang, J.; Gou, C.; Wu, Q.; Feng, H.; Han, J.; Ding, E.; Wang, J. RTFormer: Efficient design for real-time semantic segmentation with transformer. Adv. Neural Inf. Process. Syst. 2022, 35, 7423–7436. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J.; Yu, G.; Zhang, L. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. arXiv 2023, arXiv:2301.13156. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar]
- Bovcon, B.; Muhovič, J.; Perš, J.; Kristan, M. The mastr1325 dataset for training deep usv obstacle detection models. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: New York, NY, USA, 2019; pp. 3431–3438. [Google Scholar]
- Cheng, Y.; Jiang, M.; Zhu, J.; Liu, Y. Are we ready for unmanned surface vehicles in inland waterways? The usvinland multisensor dataset and benchmark. IEEE Robot. Autom. Lett. 2021, 6, 3964–3970. [Google Scholar]
- Yao, S.; Guan, R.; Wu, Z.; Ni, Y.; Huang, Z.; Liu, R.W.; Yue, Y.; Ding, W.; Lim, E.G.; Seo, H.; et al. WaterScenes: A multi-task 4d radar-camera fusion dataset and benchmarks for autonomous driving on water surfaces. IEEE Trans. Intell. Transp. Syst. 2024, 25, 16584–16598. [Google Scholar]
- Žust, L.; Perš, J.; Kristan, M. Lars: A diverse panoptic maritime obstacle detection dataset and benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 20304–20314. [Google Scholar]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 82–92. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 1451–1460. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking bisenet for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9716–9725. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A real-time semantic segmentation network inspired by PID controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19529–19539. [Google Scholar]




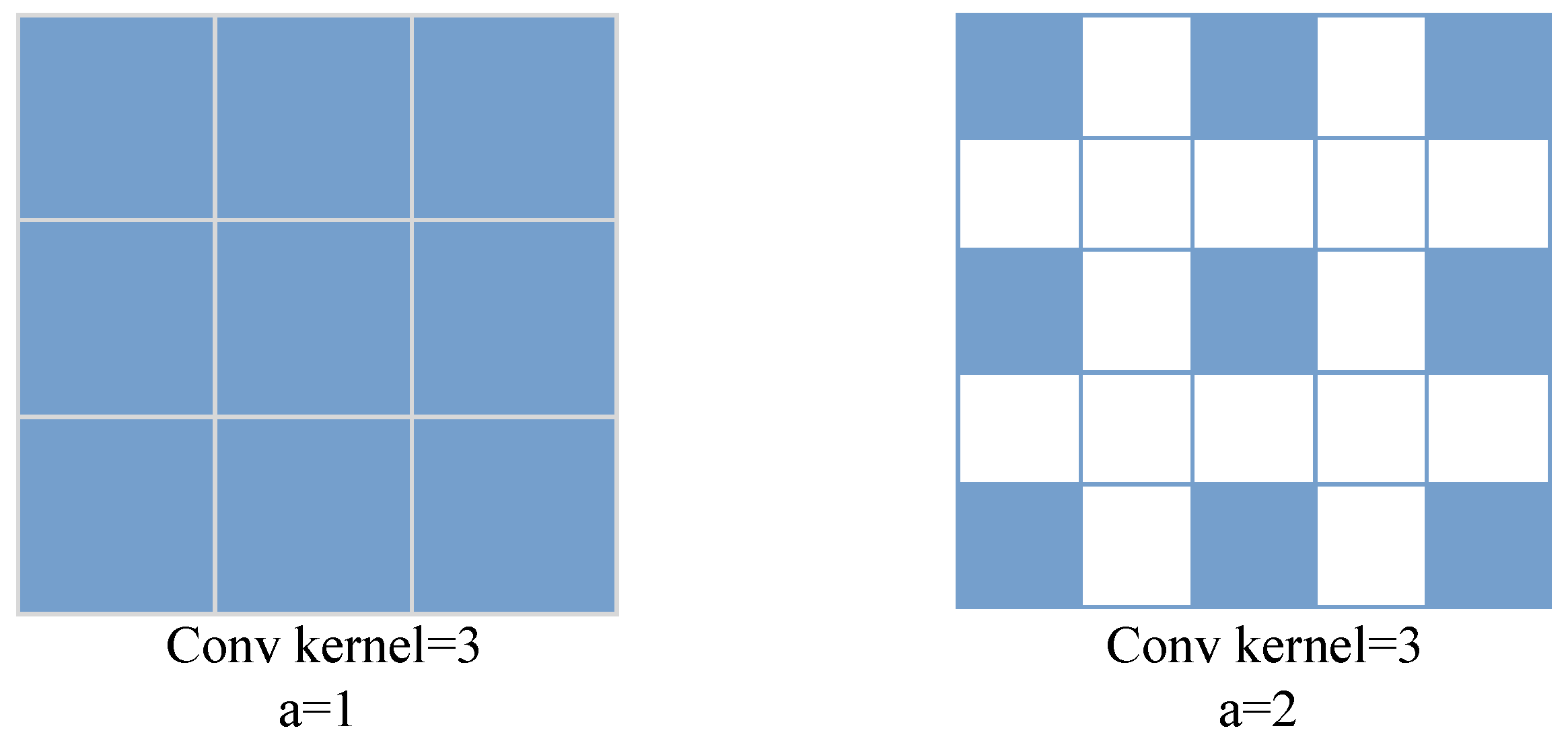


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Purpose | Year | Classes | Resolution | Synthetic /Real | Samples (Training) | Samples (Validation) | Samples (Test) | Pixel Ratio |
|---|---|---|---|---|---|---|---|---|---|
| PASCAL VOC 2012 [25] | generic | 2012 | 21 | Variable | R | 1464 | 1449 | Private | 17.3% |
| Microsoft COCO [4] | generic | 2014 | +80 | Variable | R | 82,783 | 40,504 | 81,434 | 10.7% |
| SYNTHIA [26] | urban (driving) | 2016 | 11 | S | 13,407 | N/A | N/A | - | |
| Cityscapes (fine) [2] | urban | 2015 | 30 (8) | R | 2975 | 500 | 1525 | 6.2% | |
| Cityscapes (coarse) [2] | urban | 2015 | 30 (8) | R | 22,973 | 500 | N/A | - | |
| CamVid [27] | urban (driving) | 2009 | 11 | R | 367 | 100 | 233 | 9.1% | |
| MaSTr1325 [28] | maritime obstacle | 2019 | 4 | R | 1325 | N/A | N/A | - | |
| USVInland [29] | water (driving) | 2021 | 2 | Variable | R | 700 | N/A | N/A | - |
| WaterScenes [30] | water (driving) | 2023 | 7 | R | 54,120 | N/A | N/A | 31.0% | |
| LaRS [31] | maritime obstacle | 2023 | 11 | Variable | R | 2603 | 201 | 1202 | 19.5% |
| Libary (ours) | jet flow | 2024 | 2 | R | 1100 | 100 | 100 | 1.4% | |
| SegQinhu (ours) | jet flow | 2024 | 2 | R | 700 | 23 | 100 | 2.8% |
| Challenging Scenarios | Libary | SegQinhu |
|---|---|---|
| Strong light exposure | 373 (28.69%) | 125 (15.19%) |
| Occlusion or interference | 79 (6.08%) | 84 (10.21%) |
| Minimal pixel coverage | 59 (4.54%) | 17 (2.07%) |
| Multi-angle capture | 138 (10.62%) | 19 (2.31%) |
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| conv2d | - | 32 | 1 | 2 | |
| bottleneck | 1 | 16 | 1 | 1 | |
| bottleneck | 6 | 24 | 2 | 2 | |
| bottleneck | 6 | 32 | 3 | 2 | |
| bottleneck | 6 | 64 | 4 | 2 | |
| bottleneck | 6 | 96 | 3 | 1 | |
| bottleneck | 6 | 160 | 3 | 1 | |
| dilated | - | 256 | - | 1 | |
| dilated | - | 256 | - | 1 | |
| dilated | - | 256 | - | 1 | |
| dilated | - | 256 | - | 1 | |
| conv2d 1 × 1 | - | 256 | - | 1 | |
| conv2d 1 × 1 | - | 256 | - | 1 | |
| conv2d 3 × 3 | - | 512 | - | 1 | |
| conv2d 3 × 3 | - | 512 | - | 1 | |
| conv2d 1 × 1 | - | k | - | 1 |
| Atrous Rates | Libary | SegQinhu | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | mIoU (%) | Precision (%) | Recall (%) | mIoU (%) | |
| None | 86.52 | 88.84 | 80.18 | 89.51 | 87.00 | 80.93 |
| (2, 3, 4, 5) | 79.73 | 95.63 | 78.12 | 96.83 | 82.37 | 81.01 |
| (2, 3, 4, 7) | 84.63 | 95.42 | 82.37 | 96.18 | 85.17 | 83.23 |
| (2, 4, 4, 5) | 86.48 | 92.13 | 82.10 | 98.16 | 83.39 | 82.56 |
| (2, 4, 4, 7) | 85.33 | 96.50 | 83.55 | 92.07 | 90.02 | 84.78 |
| Decoder | Libary | SegQinhu | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | mIoU (%) | Precision (%) | Recall (%) | mIoU (%) | |
| ✗ | 84.14 | 95.99 | 82.22 | 93.62 | 87.20 | 83.55 |
| ✓ | 85.33 | 96.50 | 83.55 | 92.07 | 90.02 | 84.78 |
| Method | Reference | Backbone | Accuracy | Continuity | |||||
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | mIoU (%) | DH (pixel) | Ncc | Rcc (%) | |||
| MobileNetv2 [11] | CVPR18 | MobileNetv2 | 84.27 | 80.41 | 82.22 | 73.77 | 81.86 | 6.78 | 0.11 |
| UNet [37] | MICCAI15 | - |  |  | 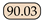 |  | 19.91 | 1.84 | 1.07 |
| MobileNetv3 [38] | ICCV19 | V3-Small | 70.40 | 72.59 | 71.44 | 63.64 | 34.08 | 3.04 | 0.21 |
| SETR [39] | CVPR21 | ViT-Base | 62.58 | 76.46 | 67.05 | 60.28 | 114.62 | 6.03 | 0.14 |
| SegFormer [40] | NeurIPS21 | MiT-B0 | 82.71 |  | 89.13 | 82.14 | 31.98 | 1.82 | 1.35 |
| SegNext [41] | NeurIPS22 | MSCAN-T | 80.93 | 97.13 | 87.35 | 79.80 | 18.66 | 2.12 | 0.56 |
| SeaFormer [24] | ICLR23 | SeaFormer-B |  |  | 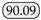 | 82.47 |  | 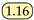 | 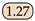 |
| PIDNet-S [42] | CVPR23 | - | 83.93 | 97.75 | 89.67 |  | 16.72 | 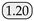 | 1.26 |
| DSNet-head64 [21] | TCSVT24 | - | 84.12 | 97.20 | 89.70 | 82.27 |  | 1.31 | 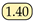 |
| Ours | - | MobileHDC |  | 96.50 | 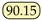 |  |  |  |  |
| Method | Reference | Backbone | Accuracy | Continuity | |||||
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | mIoU (%) | DH (pixel) | Ncc | Rcc (%) | |||
| MobileNetv2 [11] | CVPR18 | MobileNetv2 | 85.12 |  | 85.84 | 77.92 | 46.28 | 4.56 | 0.64 |
| UNet [37] | MICCAI15 | - | 86.40 | 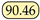 |  | 81.07 | 34.26 | 2.39 | 0.87 |
| MobileNetv3 [38] | ICCV19 | V3-Small | 92.99 | 72.96 | 79.93 | 71.36 | 48.22 | 3.04 | 0.13 |
| SETR [39] | CVPR21 | ViT-Base | 88.19 | 70.49 | 76.67 | 68.18 | 60.90 | 4.78 | 0.19 |
| SegFormer [40] | NeurIPS21 | MiT-B0 |  | 82.95 |  | 81.14 | 31.98 | 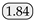 | 0.88 |
| SegNext [41] | NeurIPS22 | MSCAN-T |  | 78.15 | 85.75 | 77.82 |  | 2.36 | 0.69 |
| SeaFormer [24] | ICLR23 | SeaFormer-B |  | 84.22 |  |  | 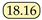 | 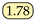 | 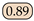 |
| PIDNet-S [42] | CVPR23 | - | 90.39 | 84.69 | 87.33 | 79.77 | 22.31 | 2.12 | 0.35 |
| DSNet-head64 [21] | TCSVT24 | - | 91.50 | 84.01 | 88.10 | 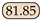 | 21.97 | 1.94 |  |
| Ours | - | MobileHDC | 92.07 | 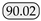 |  |  |  | 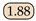 | 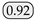 |
| Method | Backbone | T (ms) | |
|---|---|---|---|
| Libary | SegQinhu | ||
| MobileNetv2 [11] | MobileNetv2 | 24.5 | 23.2 |
| MobileNetv3 [38] | V3-Small | 34.2 | 32.1 |
| SegFormer [40] | MiT-B0 | 37.0 | 37.8 |
| SegNext [41] | MSCAN-T | 57.4 | 56.5 |
| SeaFormer [24] | SeaFormer-B | 32.7 | 33.7 |
| PIDNet-S [42] | - | 36.9 | 35.7 |
| DSNet-head64 [21] | - | 30.8 | 29.6 |
| Ours | MobileHDC | 27.5 | 26.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Quan, Q.; Wang, W.; Lin, Y. A Benchmark for Water Surface Jet Segmentation with MobileHDC Method. Appl. Sci. 2025, 15, 2755. https://doi.org/10.3390/app15052755
Chen Y, Quan Q, Wang W, Lin Y. A Benchmark for Water Surface Jet Segmentation with MobileHDC Method. Applied Sciences. 2025; 15(5):2755. https://doi.org/10.3390/app15052755
Chicago/Turabian StyleChen, Yaojie, Qing Quan, Wei Wang, and Yunhan Lin. 2025. "A Benchmark for Water Surface Jet Segmentation with MobileHDC Method" Applied Sciences 15, no. 5: 2755. https://doi.org/10.3390/app15052755
APA StyleChen, Y., Quan, Q., Wang, W., & Lin, Y. (2025). A Benchmark for Water Surface Jet Segmentation with MobileHDC Method. Applied Sciences, 15(5), 2755. https://doi.org/10.3390/app15052755