1. Introduction
Web applications have become a critical infrastructure in modern society, supporting a wide range of social needs such as social media, e-commerce websites, online education, financial services, and remote work [
1,
2]. However, vulnerabilities in web applications can lead to severe consequences, including disruption of social services, financial losses, and data breaches [
3,
4]. As one of the most popular server-side programming languages, PHP is used by over 75% [
5] of websites, due to its ease of development and high efficiency, making it widely adopted in web application development. However, the flexibility of PHP also provides attackers with more opportunities to exploit vulnerabilities, thereby increasing security risks, such as common threats like SQL injection [
6], code execution [
7], and cross-site scripting (XSS) [
8].
To address these threats, security researchers have proposed various techniques for detecting vulnerabilities in web applications, which can generally be categorized into dynamic analysis and static analysis. Among these, static analysis has garnered significant attention because of its ability to cover all code paths. By precisely modeling the PHP language, static analysis can thoroughly examine every line of code, uncovering potential vulnerabilities to the greatest extent possible [
9]. However, static analysis often suffers from a high false-positive rate. Despite numerous studies attempting to mitigate this issue, security researchers still need to invest considerable time and effort in verifying whether the potential vulnerabilities reported are genuine. This has become a critical bottleneck that limits the practicality of static analysis. However, dynamic analysis typically injects attack payloads into the application in a real execution environment and identifies vulnerabilities based on actual behavior, resulting in few false positives [
10,
11,
12,
13]. Nevertheless, without a deep understanding of the application’s internal structure, dynamic analysis struggles to cope with the complex architectures and state-dependent characteristics of modern web applications. Consequently, it cannot effectively test deeper code regions, which are often more prone to harboring vulnerabilities.
To compensate for the respective limitations of static and dynamic analysis, it is crucial to combine the strengths of both approaches [
14]. In this context, our objective was to adopt directed fuzzing, using potential vulnerabilities identified in static analysis reports as guidance to focus dynamic analysis on verifying the authenticity of these vulnerabilities. This strategy not only leverages the high coverage of static analysis to uncover more potentially vulnerable areas, but also takes full advantage of the accuracy of dynamic analysis, significantly reducing the manual effort required to validate vulnerabilities.
Although directed fuzzing has made significant progress in native programs, its application in web applications remains limited, due to three core constraints:
Low Efficiency in Entry Point Detection. Existing research has often relied on crawlers [
13,
15] or manual efforts [
16,
17] to obtain testable URLs for web applications. However, these surface-level URLs often lack critical request parameters, preventing test requests from reaching the deeper code regions where potential vulnerabilities reside.
Limitations in Solving Control Flow Constraints. Even when the vulnerable code region is reached, navigating from the entry point to the vulnerable function requires satisfying a series of control flow constraints. Existing work have attempted to address this issue by extracting preset parameters via crawlers and assigning random values [
13] or by using static analysis [
15,
18] to extract partial constraints to generate preset values. However, these methods only partially solve the constraint problem and still exhibit significant accuracy deficiencies.
Inadequate Vulnerability Detection Methods. Existing approaches often rely on triggering syntax errors in the PHP parser and interpreting them as segmentation faults to identify vulnerabilities [
13,
15,
18]. However, in practice, syntax errors do not directly equate to the actual existence of vulnerabilities.
In this paper, we propose a directed fuzzing approach named CraftFuzz, designed to precisely generate requests for verifying PHP web vulnerabilities. First, by leveraging precise static analysis to extract application routing rules, CraftFuzz effectively generates entry URLs for potential vulnerabilities, thereby avoiding inefficient entry exploration. Second, we systematically identify 12 types of opcodes in PHP related to control flow constraints and extract constraint information for all branches of the target program. Based on this information, CraftFuzz constructs the necessary request parameters to traverse from the taint source to the sink. CraftFuzz then monitors the satisfaction of each constraint along the path from the taint source to the sink and employs targeted parameter mutations, significantly enhancing the ability to pass control flow constraints. Finally, through a novel payload insertion position analysis and four reflection methods, CraftFuzz precisely identifies the triggering of vulnerabilities, ensuring reliable and accurate verification results.
We evaluated CraftFuzz using both synthetic and real-world web applications across three dimensions: entry URL generation, path constraint solving, and known vulnerability verification (or data constraint solving). The results demonstrate that CraftFuzz could solve each entry URL and path constraint within 6 s and 20 s, respectively, achieving a 97.1% success rate in entry URL generation and a 95% success rate in path constraint solving. For known vulnerability verification, CraftFuzz successfully validated 88.88% of vulnerabilities, outperforming state-of-the-art fuzzers by 32.28%, showcasing significant performance advantages.
In summary, this paper makes the following contributions:
We designed and implemented CraftFuzz, a directed fuzzing approach capable of generating precise requests to validate PHP web vulnerabilities. Through a multi-stage refinement-solving strategy, including entry URL generation, path constraint analysis, and data constraint solving, CraftFuzz ensures that fuzzing requests accurately reach the target sink and successfully validate vulnerabilities.
We evaluated CraftFuzz on one microbenchmark and 29 real-world web applications. The results indicate that CraftFuzz achieved higher URL generation success rates and path constraint solving success rates than state-of-the-art methods, while also validating more real-world vulnerabilities.
The rest of the paper is structured as follows.
Section 2 presents the background and research motivation.
Section 3 summarizes three major challenges in the current research field.
Section 4 introduces the top-level design of CraftFuzz and explains how its three key stages address these challenges.
Section 5 evaluates the performance of CraftFuzz.
Section 6 discusses the limitations of CraftFuzz and potential future improvements.
Section 7 presents related work. Finally,
Section 8 concludes the paper.
2. Background and Motivation
2.1. Web Application Fuzzing
Since its proposal in 1990, fuzzing [
19] has evolved significantly over the past 30 years and is now widely applied to detect vulnerabilities across various software systems, including web applications. Based on the information relied on, web application fuzzing can generally be categorized into black-box fuzzing (scanning) and gray-box fuzzing.
Black-box fuzzing is conducted without access to internal information about the target web application [
20,
21]. For example, tools like Black Widow [
10] and ReScan [
12] implement black-box scanning by modeling navigation paths and constructing a state graph of the web application without internal knowledge. ReScan enhances scanning effectiveness and reduces false positives through dynamic browser interaction and cross-state dependency detection.
Gray-box fuzzing, in contrast, leverages lightweight feedback information (e.g., code coverage and branch execution data) to direct the fuzzing. Web application gray-box fuzzing typically involves four key steps: generating valid inputs, collecting program coverage, performing effective input mutations, and monitoring vulnerability triggers. WebFuzz [
16] employs a static instrumentation to gather code coverage feedback, while Witcher [
13] extends this by incorporating an interpreter instrumentation and coverage computation using QEMU. ATROPOS [
15] focuses on input validity by hooking string comparison opcodes to extract expected key–value pairs, thereby improving the efficiency of input mutation. PHUZZ [
17] enhances vulnerability monitoring by hooking dangerous functions to track the actual conditions when requests reach these functions, which improves the precision of vulnerability detection.
In recent years, research in web application fuzzing has gradually shifted from traditional black-box fuzzing to gray-box fuzzing [
22]. This shift has been largely driven by gray-box fuzzing’s ability to utilize internal program information, such as code coverage, to more effectively explore the state space of web applications. A broader state space increases the likelihood of discovering vulnerabilities, making gray-box fuzzing an increasingly popular focus of research. However, exploring the state space of web applications requires incorporating the expected parameters of the target application [
13,
15]. Without the correct request parameters, it becomes challenging to reasonably explore the input space of the target application. Consequently, achieving effective input mutation has become one of the primary bottlenecks in gray-box fuzzing for web applications.
2.2. Directed Fuzzing for Web Applications
However, the state space of modern web applications is highly complex, with challenges such as infinite crawls and session management significantly constraining the in-depth exploration of this state space [
10]. Directed fuzzing focuses on specific areas of interest in the code, aiming to minimize blind testing of irrelevant parts. It has demonstrated its effectiveness in native application environments. The success of methods like AFLGo [
23] has sparked a surge of research interest in directed fuzzing in recent years.
Theoretically, directed web application fuzzing methods could effectively reduce the challenges associated with exploring complex state spaces. However, to date, only Cefuzz [
24] and Predator [
18] have emerged as primary directed fuzzing approaches for web applications. This limited development of directed web application fuzzing can largely be attributed to two critical challenges.
The first challenge is how to accurately guide the fuzzer toward potentially vulnerable code regions. Cefuzz uses static analysis results to treat the target file as the entry, while Predator further analyzes call chains and file inclusion chains to identify predecessor files that can reach the target file. However, even the state-of-the-art Predator cannot handle web applications where entry scripts are dynamically generated based on routing rules, which limits the efficiency of entry detection.
The second challenge is how to effectively obtain the correct request parameters and their corresponding values. Cefuzz focuses on bypassing filters for command execution payloads but neglects the constraint information along the path from the source to the sink. Predator uses reverse data flow analysis to identify critical request parameters that may influence the control flow, primarily focusing on values on the right-hand side of assignments and conditional statements. However, this approach misses other types of constraints, such as variables on the left-hand side of conditional statements or checks for whether a variable is set. These limitations significantly restrict the coverage and efficiency of directed fuzzing for web applications.
2.3. Motivation
Despite the limitations posed by the two key challenges in directed fuzzing for web applications, the approach still demonstrates significant potential for automatically validating static analysis reports to detect vulnerabilities in web applications. On the one hand, directed fuzzing can fully leverage the high coverage of static analysis to extract as much program knowledge as possible, helping to overcome complex execution path constraints and accurately reach areas where vulnerabilities may exist. On the other hand, using fuzzing to validate vulnerability reports generated by static analysis can not only significantly reduce the cost of manual verification but also mitigate the compromises made by purely static analysis when dealing with dynamic programming languages like PHP. This approach improves both the efficiency and accuracy of vulnerability detection.
3. Challenge
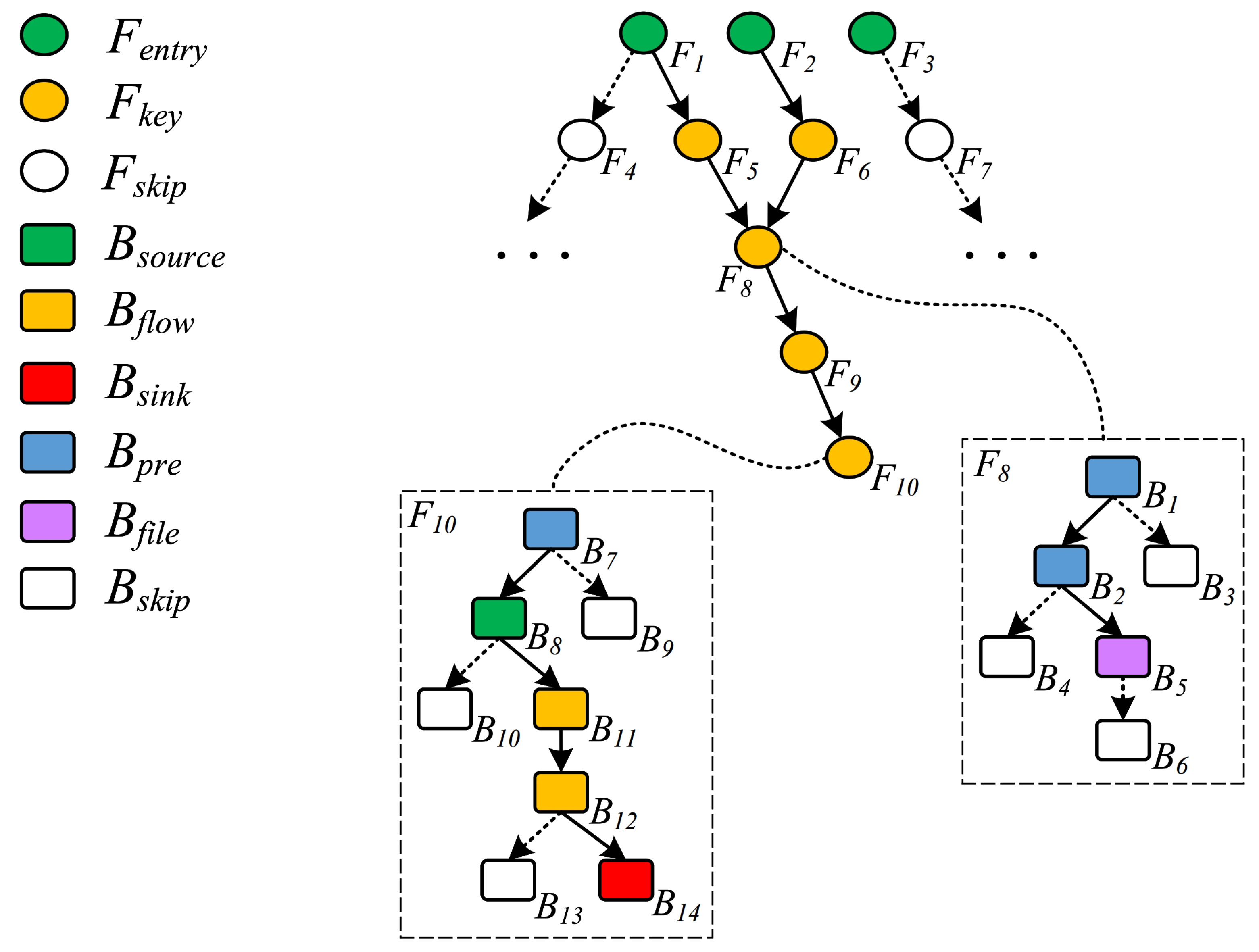
Although directed fuzzing has demonstrated significant potential, its application to the automated verification of vulnerabilities identified in static analysis reports still faces three major challenges. To illustrate these challenges more intuitively, we present a schematic of a taint propagation chain in a web application in
Figure 1. In this figure, circles represent files(F), rectangles denote basic blocks(B), and the dashed rectangles on the left and right depict the layout of basic blocks in files F10 and F8, respectively. The taint propagation chain resides in F10, originating at the source B8, propagating through B11 and B12, and reaching the sink B14.
Challenge 1: Generating Targeted Entry URLs. Static analysis reports of web application vulnerabilities typically include information about taint sources, propagation paths, and sinks. To verify the validity of these vulnerabilities dynamically, the first task is to generate URL requests that can reach the file containing the source.
However, the file with the taint source is not always directly accessible and may require traversal through a series of file inclusions. The starting file in such inclusion chains is referred to as the entry file of the target application. For example, in
Figure 1, F1, F2, and F3 are entry files; attempting to directly access F5 may result in logical errors due to missing variable information initialized in F1. The URLs corresponding to these entry files are called
entry URLs.
Web application URL routing can generally be categorized into two types: static routing and dynamic routing. Static routing uses fixed mappings, where URLs are typically generated directly based on the file system paths of the web application. Dynamic routing, on the other hand, maps URLs dynamically to a specific processing logic or resources according to developer-defined routing rules. Thus, identifying the entry file corresponding to the taint source and generating the entry URL linked to the entry file is the primary challenge we face.
Existing web application fuzzing methods often rely on web crawlers or manual approaches to identify URLs. However, these methods do not account for the need to generate targeted URLs for the files containing taint sources, leading to significant time being wasted on randomly searching for entry URLs and a low likelihood of successfully reaching the target file. Additionally, two directed fuzzers, Cefuzz and Predator, assume that web applications use static routing, directly mapping file system paths to URLs. This assumption fails to accommodate for the growing trend in web applications adopting dynamic routing, thereby limiting the applicability and effectiveness of these tools.
Challenge 2: Constructing Parameters to Satisfy Path Constraints. After obtaining the entry URL, the next objective is to reach the sink. Taking the path in
Figure 1 as an example, the program must first ensure the correct execution of the file inclusion chain, such as F1->F5->F8->F9->F10 or F2->F6->F8->F9->F10.
Achieving this requires satisfying the following conditions: the basic blocks containing the file inclusion statements in each file (e.g., basic block B5 in F8) must be executed, and the target paths of the file inclusions must be correct. Furthermore, the program must follow the expected execution order along the path from the source to the sink. For instance, in F10, the basic blocks along the path B7->B8->B11->B12->B14 must be triggered in the correct sequence. These control flow path restrictions from the entry to the sink are collectively referred to as
path constraints.
Path constraints can be classified into two categories: user-controllable and user-uncontrollable. User-controllable constraints must be satisfied through HTTP request parameters, making the construction of parameters that fulfill these constraints the second critical challenge.
In existing work, Cefuzz focuses on bypassing command execution payload filters, which is only effective in scenarios with minimal path constraints. Witcher [
13] uses web crawlers to extract form parameter names and assigns random values, attempting to satisfy constraints by cross-mutating parameter names and values. However, the use of random values makes this method ineffective in handling strictly regulated constraints in web applications. ATROPOS [
15] and Predator improve upon this by extracting right-hand values from opcodes as preset values for path construction. Additionally, Predator introduces a dependent parameter-sensitive mutation mechanism, which offers some improvement but still falls short when addressing more complex path constraints.
Challenge 3: Constructing Parameters to Satisfy Data Constraints. After generating a request that reaches the sink, the next task is to construct a request that triggers the vulnerability. Vulnerabilities are often exploited by leveraging the provided code interface to perform unintended actions. Successfully triggering a vulnerability typically requires concatenating or closing strings within the original functionality, to generate new strings that meet the conditions necessary to exploit the vulnerability. These conditions are referred to as data constraints. Thus, constructing request parameters that satisfy data constraints becomes the third key challenge we face.
In existing methods, PHP parser syntax errors are often used as potential indicators of vulnerabilities. By escalating syntax errors to segmentation faults, the efficiency of vulnerability detection can be improved. However, syntax errors do not directly equate to the actual presence of a vulnerability. They merely suggest that a potential vulnerability might exist at a given location, requiring further expert validation. This limitation makes it difficult to achieve automated verification of static analysis reports. Cefuzz attempts to address this by crafting commands designed to produce echoes, enabling the determination of whether a vulnerability has been successfully triggered based on the echo content. However, this approach is only applicable to data constraints in scenarios involving command execution and code execution vulnerabilities, making it insufficient for handling the diverse and complex constraints encountered in real-world applications.
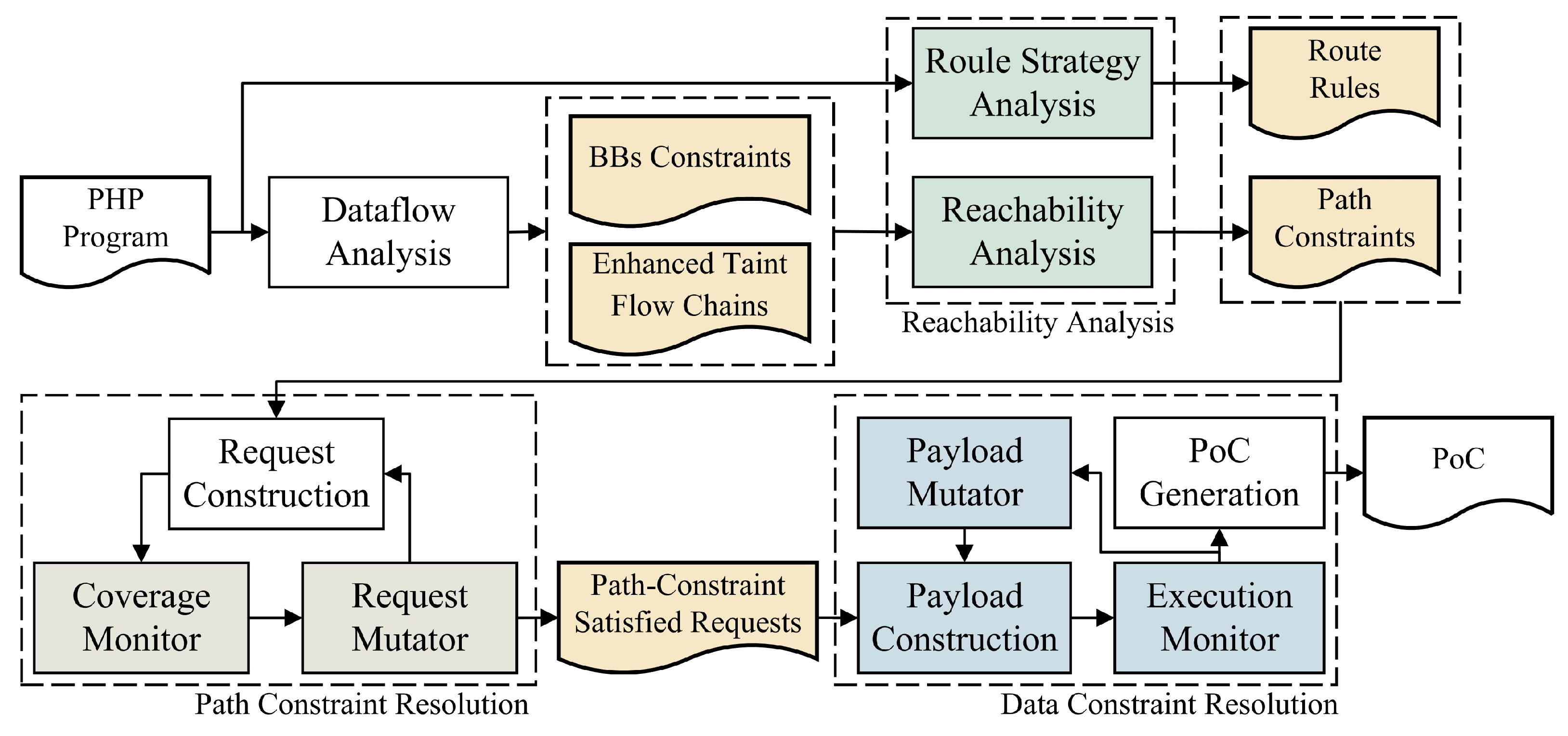
4. CraftFuzz
The overall architecture of CraftFuzz, as shown in
Figure 2, consists of three main stages: reachability analysis, path constraint solving, and data constraint solving.
Before these three primary stages, a preliminary phase of data flow analysis is conducted to extract information on the jump constraints of basic blocks, file inclusion chains, call chains, and taint propagation chains within the target program. This information is integrated to form
enhanced taint propagation chains, which are used to identify the entry files containing the taint sources. This phase relies on our previous advanced and precise PHP data flow analysis tool,
Yama [
9]. It first constructs per-file control flow graphs (CFGs) by extracting opcodes through the ZendVM kernel hook and organizing them based on jump instructions. It then carries out various data flow analyses, including taint analysis, to detect vulnerabilities in PHP applications. By leveraging accurate variable type inference, Yama defines taint sources, sanitizers, and sinks, and performs precise context-sensitive, path-sensitive, and interprocedural taint tracking. For complex dynamic features and built-in functions, Yama uses concrete execution to resolve concrete values. Leveraging Yama’s precise data flow analysis capabilities, CraftFuzz obtains the jump constraint information of basic blocks and the enhanced taint propagation chains.
In the reachability analysis stage, CraftFuzz utilizes the jump constraint information of basic blocks and the enhanced taint propagation chains to extract the constraints along the path. It also analyzes the routing strategy of the target program to generate routing rules. Based on these rules, CraftFuzz can generate entry URLs corresponding to each enhanced taint propagation chain, ensuring that test requests can smoothly reach the target files.
In the path constraint solving stage, CraftFuzz constructs HTTP requests using the predefined path constraints and entry URLs. Through coverage monitoring, CraftFuzz tracks the nodes reached by the request along the path constraints in real time and performs targeted mutations on the parameters until the sink has been successfully reached.
In the data constraint solving stage, CraftFuzz first analyzes the user-controllable parts in the data constraints and concatenates different command modules based on their location. It then generates payloads based on four reflection strategies and constructs HTTP requests, monitoring whether each request successfully triggers the corresponding reflective behavior. This process determines whether the vulnerability has been successfully exploited. If the vulnerability is exploited, CraftFuzz generates a proof-of-concept (PoC) containing valid payloads. Otherwise, it continues to mutate the request parameters until the data constraints have been satisfied.
4.1. Reachability Analysis
Revisiting Challenge 1, we need to accurately identify the entry file containing the taint source and generate the entry URL corresponding to this file. To locate the entry file, we integrate the file inclusion chains, call chains, and taint propagation chains provided by Yama, enabling precise identification of the target entry file. For entry URL generation, we analyze the routing rules of the target program and, in combination with the entry file’s path in the file system, deduce its corresponding entry URL based on the routing rules. Additionally, we extract the path constraints of the enhanced taint propagation chain through static analysis, providing the necessary data support for the subsequent path constraint solving stage.
4.1.1. Route Strategy Analysis
To extract the routing rules of the target program, we first determine whether it uses static or dynamic routing, as described in Algorithm 1. When determining the routing type, we collect all subdirectories under the root directory of the target application, excluding directories containing static resources. Next, we gather PHP file paths from these subdirectories that meet a specified file count threshold. If directories with characteristics of dynamic routing (e.g., a “controller” directory) are identified, PHP file paths from those directories are prioritized.
Subsequently, we concatenate the relative paths of these PHP files with the application’s host address to form request URLs and send HTTP requests. After collecting all responses, we calculate the proportion of 2XX responses based on the HTTP status codes [
25]. If this proportion exceeds a predefined error threshold, the application is determined to be using dynamic routing; otherwise, it is classified as using static routing.
| Algorithm 1 Determine CMS Routing Mode |
Require: , - 1:
Define as a list of directory names to exclude (e.g., ’assets’, ’static’). - 2:
Extract from by excluding directories matching . - 3:
for each in do - 4:
Traverse to collect up to PHP files. - 5:
If DYM-like subdirectories (e.g., ’controller’) are found, prioritize their PHP files. - 6:
end for - 7:
for each selected in test files do - 8:
Test file accessibility by constructing URLs from and paths relative to . - 9:
end for - 10:
Calculate . - 11:
if then - 12:
return True (Dynamic routing) - 13:
else - 14:
return False (Static routing) - 15:
end if
|
For applications using static routing, URLs can be directly generated based on the file system paths of the web application. For applications employing dynamic routing, a dynamic routing solving Algorithm 2 is required. Specifically, we enable Xdebug’s trace mode [
26] to track the variable usage during the application’s execution and extract variables related to routing. These variables are then reorganized to derive routing rules. Next, the controller name is extracted from the entry file path and matched with the entry method name and routing rules. Upon a successful match, the request URL is generated based on the routing rules. If the routing rules require parameters, these are populated with the default values specified in the rules, resulting in a basic entry URL.
| Algorithm 2 Generate Dynamic Request URL |
Require:
, , , ,
Ensure: Generated URL
- 1:
Enable xdebug in trace mode. - 2:
Perform multiple random accesses to the target application to generate trace files. - 3:
Extract routing variables from trace files(e.g., ). - 4:
Normalize and - 5:
Extract controller name from - 6:
for each in do - 7:
if matches matches then - 8:
Generate parameters dynamically based on and - 9:
Construct URL using , , , based on - 10:
return - 11:
end if - 12:
end for
|
4.1.2. Constraint Extraction
CraftFuzz leverages the jump constraint information of basic blocks and enhanced taint flow analysis to extract path constraints. Specifically, it first performs a reachability analysis for basic blocks. If a basic block on the path is determined to be unreachable, its constraints are skipped to reduce unnecessary overhead. Algorithm 3 begins by locating basic blocks using line numbers and function names. If a basic block does not exist, it returns an unreachable status; if it does exist, the control flow graph is extracted, reachability is assessed, and the basic block is returned along with its reachability information.
| Algorithm 3 Compute Block Reachability |
Require:
, , ,
Ensure:
Reachability information for the basic block
- 1:
Find basic block for in and - 2:
if is null then - 3:
return { “filepath”: , “reachability”: 0 } - 4:
end if - 5:
Control flow graph of - 6:
Check reachability of in - 7:
return { “filepath”: , “BB”: , “reachability”: }
|
Subsequently, Algorithm 4 extracts path constraints by traversing the reachable paths of basic blocks, capturing the control dependencies and constraints of each block. After deduplicating the path results, the reachable paths and their associated constraint information are recorded. Finally, the algorithm returns the reachability and constraint information for all paths.
Table 1 summarizes all relevant opcodes involved in the extracted constraints.
| Algorithm 4 Extract Reachability and Constraints |
Require:
,
Ensure:
Reachable paths with constraints
- 1:
for each in do - 2:
for each in do - 3:
if has control dependencies then - 4:
Extract constraints from - 5:
if not in then - 6:
Append { “Filepath”: , “Line”: , “Constraints”: } to - 7:
end if - 8:
end if - 9:
end for - 10:
end for - 11:
return
|
4.2. Path Constraint Resolution
Revisiting Challenge 2, we need to construct request parameters that satisfy path constraints, in order to generate URLs capable of reaching the sink. In the previous stage, the predefined values of path constraints were extracted. Based on these predefined values and the entry URL, CraftFuzz generates HTTP requests and uses coverage monitoring to track, in real time, the nodes reached by the requests along the path constraints. For unmet constraints, CraftFuzz performs precise mutations on the request parameters until the sink is successfully reached. The following sections detail the specific mechanisms for coverage monitoring and precise parameter mutation.
4.2.1. Coverage Monitor
First, we utilize Xdebug’s xdebug_get_code_coverage function [
27] in combination with PHP’s auto_prepend_file mechanism [
28] to obtain coverage data for each request. These data are then evaluated using Algorithm 5. The inputs to the algorithm include distance information for the target path (
targetDistance) and path reachability data (
sourceReachabilitys and
source2sinkReachabilitys). Based on the coverage data, the algorithm sequentially checks the coverage status of each node to determine whether the target path fully satisfies the coverage conditions. The algorithm dynamically adjusts its evaluation by combining the path’s coverage status with information about unmet constraints. Ultimately, it provides a comprehensive assessment of path coverage completeness and constraint satisfaction, forming the basis for subsequent mutation operations.
| Algorithm 5 Evaluate Coverage |
Require:
, ,
Ensure:
Coverage evaluation result
- 1:
Get current coverage data - 2:
Evaluate with - 3:
if SRC_PATH_COVERED then - 4:
return
- 5:
end if - 6:
Evaluate with - 7:
if S2S_PATH_COVERED then - 8:
return {“status”: , “con2pass”: or or , “distance”: } - 9:
end if - 10:
return { “status”: S2S_PATH_COVERED, “con2pass”: null, “distance”: 999 }
|
4.2.2. Request Mutator
The request mutator, upon receiving feedback about unmet constraints from coverage monitoring, performs targeted mutations based on Algorithm 6. This algorithm extracts the relevant request data from the constraint information, iteratively sets parameters, and sends mutated requests. It simultaneously evaluates changes in coverage and dynamically adjusts its strategy based on the results. If the coverage improves, the algorithm recursively optimizes the mutations; once the target coverage has been achieved, the mutation process halts, and the results are recorded.
| Algorithm 6 Handle Mutation Requests |
Require:
, , ,
Ensure: Updated coverage and mutation results
- 1:
Request data based on - 2:
for each in do - 3:
Set request parameters using - 4:
Send the request and obtain the response - 5:
Evaluate coverage after mutation - 6:
Determine next action based on - 7:
if MUTATION_IMPROVED then - 8:
Recurse: Call mutation process with - 9:
else if
MUTATION_GOAL_REACHED then - 10:
Stop mutation and record results - 11:
return - 12:
end if - 13:
end for
|
Since web applications often have input constraints with explicit semantic requirements, existing mutation strategies designed for native programs (e.g., bit flipping, byte flipping) are often ineffective. To address this, CraftFuzz relies on the
potential values obtained during the constraint extraction phase, iteratively testing these values. These
potential values are derived from variable inference [
9] or constants in branches of data flow analysis. If none of the potential values satisfy the constraint, CraftFuzz logs the constraint information and skips verification for this enhanced taint propagation chain.
Additionally, CraftFuzz provides a manual review interface for security researchers. Researchers can review unmet constraints recorded by CraftFuzz and add their analysis results to a manually curated preset dictionary. In subsequent fuzzing processes, if the predefined values still fail to satisfy the constraints and the preset dictionary is not empty, CraftFuzz will attempt to use values from the manually preset dictionary. It is important to note that this is not a real-time hot-plug interface.
To minimize the impact of ineffective mutations on fuzzing performance, this strategy allows CraftFuzz to quickly skip enhanced taint propagation chains that cannot currently be processed and proceed to validate the next chain. Combined with the results of manual reviewing, CraftFuzz can attempt to address previously unresolvable chains in subsequent tests.
4.3. Data Constraint Resolution
Revisiting Challenge 3, we need to construct request parameters that satisfy data constraints, to generate requests that trigger vulnerabilities. Since the location of user-controllable regions in the data constraints directly affects the effectiveness of command concatenation, if the inserted payload causes the concatenated command to fail to execute correctly, it will be impossible to verify the existence of the vulnerability. Furthermore, many types of vulnerabilities lack clear feedback when triggered, making it challenging to determine whether the vulnerability in the web application has been successfully exploited.
To address these issues, CraftFuzz uses payload construction to carefully design concatenation and closure symbols, ensuring that the concatenated commands execute correctly. Additionally, CraftFuzz constructs four types of reflective commands to ensure that triggering the vulnerability produces clear feedback. CraftFuzz then employs an execution monitor to observe whether each request successfully triggers the expected reflective behavior, determining whether the vulnerability has been successfully exploited. If the exploitation is successful, CraftFuzz generates a proof-of-concept (PoC) containing valid payload data. If exploitation fails, the payload mutator further mutates the request parameters until the data constraints have been satisfied.
The following sections provide detailed descriptions of the mechanisms behind payload construction, the execution monitor, and payload mutator.
4.3.1. Payload Construction
In CraftFuzz, we define a user-controllable payload command format to ensure the flexibility and effectiveness of payload command concatenation. The format is as follows:
To facilitate explanation, we define LOCA as the position where the Controlled_Payload is inserted into the original command. The Controlled_Payload consists of four core elements:
R (Random String): Used to complete the command before and after LOCA, ensuring the payload seamlessly integrates with the context of the original command.
S (Pre-connector): A connector placed before LOCA to link with the preceding command. Our design goal was to ensure that our constructed reflection command will also be enforced in the event that the previous original command cannot be executed. (e.g., &).
C (reflection Command): A predefined module designed to explicitly validate a vulnerability through its execution results. CraftFuzz supports four reflection strategies: outputting characteristic strings, accessing external services with special parameters, performing file system operations, and executing delay commands.
For example, in the case of command execution vulnerabilities, Listing 1 illustrates a sample payload for each of the four types of reflection commands.
| Listing 1. PoC template file. |
["command" => "echo $this->indicatorMd5", "type" => self::HTTP_REFLECTION].
["command" => "wget $this->logRequesturl", "type" => self::
EXTERNAL_REFLECTION].
["command" => "echo $this->randomFileContent > $this->fileForWrite", "type"
=> self::FILE_REFLECTION].
["command" => "sleep $this->sleepTime", "type" => self::TIME_REFLECTION]. |
E (Post-closure Symbol): A closure symbol placed after LOCA to prevent commands following LOCA from being executed. Our design goal was to ensure that after inserting a constructed command, the original command string following it is not executed. Taking as an example, first use $ to enforce a non-existent command (nonexistentCommand), and then connect the following original commands with &&, so that the subsequent original commands will not be executed, because the nonexistentCommand command is invalid.
During data flow analysis, to determine the LOCA for payload commands, we insert a placeholder into the tainted position of the sink function’s parameters, while analyzing the taint flow. By analyzing the position of the placeholder within the string, we can identify whether it is at the beginning, middle, or end, thereby accurately determining the insertion point for the payload command. Based on the insertion position, we can flexibly decide whether elements such as <R>, <S>, and <E> are required. For instance, when LOCA is at the very beginning of the command, there is no need to concatenate preceding commands, and using <C>, <E>, and <R> alone is sufficient to meet the concatenation requirements. This can effectively reduce the cleaning risks caused by excessive connectors.
4.3.2. Execution Monitor
The execution monitor is designed with four monitoring strategies corresponding to the four types of reflection commands constructed for the payload, as described in Algorithm 7. These strategies are used to verify whether the vulnerability has been successfully triggered:
HTTP Response Validation: This monitors the response packets of requests, to check whether they contain specific characteristic strings, confirming the presence of feedback behavior.
External Callback Detection: By monitoring the request logs of a designated server, this detects whether external requests with special parameters have been triggered.
File System Monitor: This monitors a pre-created folder in the target program to detect any file creation, deletion, modification, or access behavior.
Time Delay Inference: This strategy compares the response times of successive requests to infer the presence of a vulnerability, such as a significant increase in server response time.
| Algorithm 7 Execute Monitor |
Require: , , ,
Ensure: Validation result (true/false)
- 1:
switch () - 2:
case HTTP_REFLECTION: - 3:
return Check features in - 4:
case EXTERNAL_REFLECTION: - 5:
return Check if
exists - 6:
case FILE_REFLECTION: - 7:
return Detect file system changes - 8:
case TIME_REFLECTION: - 9:
return Compare with - 10:
end switch
|
4.3.3. Payload Mutator
When the execution monitor fails to capture feedback, CraftFuzz optimizes the payload through mutation. Initially, CraftFuzz iteratively tests payloads from a pre-constructed list of carefully designed payloads. After each attempt, CraftFuzz replaces the currently used <R>, <S>, and <E> elements, cycling through all possible combinations.
If the payload still fails to trigger the vulnerability after testing all <S> and <E> combinations, CraftFuzz further mutates the functions or keywords used in <C>. These mutations include methods such as encoding conversion and case rewriting to bypass potential keyword detection or dangerous function restrictions implemented in the target application.
Once a vulnerability has been successfully triggered, CraftFuzz saves the corresponding HTTP request as a proof of concept (PoC). If all attempts fail, the enhanced taint propagation chain is marked as free from vulnerabilities. Additionally, CraftFuzz logs related information, enabling researchers to manually review and analyze chains where vulnerabilities were not triggered.
It is worth mentioning that CraftFuzz does not produce false positives (FPs), because all enhanced taint propagation chains identified as vulnerabilities are observed with successful payload execution. The semantics of these payloads are equivalent to the successful exploitation of the vulnerability, ensuring that a payload cannot execute successfully without representing a real vulnerability. However, CraftFuzz may produce false negatives. This could result from path or data constraints not being correctly solved or from potential flaws in the current payload design. We will further discuss possible improvements to address these issues in the discussion section.
5. Evaluation
In this section, we address the following research questions to evaluate CraftFuzz:
- RQ1:
How effective and efficient is CraftFuzz in generating entry URLs?
- RQ2:
How well does CraftFuzz perform in solving path constraints?
- RQ3:
How effective and efficient is CraftFuzz in verifying known vulnerabilities?
5.1. Datasets and Experimental Setup
Baseline: Considering the limited research on directed fuzzing for web applications, we selected all recent relevant works on web application fuzzing as baselines. Since these studies differ from CraftFuzz in terms of their scope of vulnerability analysis, we conducted targeted comparisons between CraftFuzz and each baseline based on specific types of vulnerabilities. Specifically, we included the following baselines: Cefuzz for CE (command/code execution) vulnerabilities; WebFuzz [
29] for XSS vulnerabilities; Witcher and Atropos for SQLi and CE vulnerabilities; Predator for SQLi, XSS, and CE vulnerabilities; and PHUZZ [
17] for SQLi, XSS, CE, PT [
30], IDes [
31], and OpRe [
32] vulnerabilities.
It should be noted that we did not include Wfuzz [
33] as a baseline, because it is essentially a brute-forcing tool and does not align with the characteristics of fuzzing. Additionally, since authentication bypass (IDes) and operation replay (OpRe) vulnerabilities are beyond CraftFuzz’s scope, results for these two types of vulnerabilities were not included in the experiments.
Dataset 1 (Microtest): This dataset originated from the prior research work on Witcher, and includes 13 microtests [
34] artificially constructed with various types of path constraints to evaluate the capability of web application fuzzers in handling path constraints. Notably, Witcher’s experiments only utilized 10 of these microtests for evaluation. To enhance the comprehensiveness of our experiments, we included the remaining 3 microtests from the Witcher code repository. These 3 microtests have more complex path constraints, providing further validation of the tool’s performance.
Dataset 2 (Real-world applications): Given the difficulty in constructing environments for some baseline tools, we selected applications used in previous baseline studies whenever possible. This allows us to directly reference evaluation results from the corresponding papers when the testing environment could not be successfully built. Additionally, we included web applications that use dynamic routing to assess CraftFuzz’s effectiveness in detecting vulnerabilities in such applications.
Table 2 presents the specific applications selected: applications marked as C indicate they have been used in multiple baseline studies, while those marked as D represent applications that use dynamic routing.
All experiments were conducted on a machine with an Intel Core i7-10875h processor, four 2.30 GHz logical cores, and 16 GB of RAM, running 64-bit Windows 10 22H2 or Linux Ubuntu 18.04 or 22.04. PHP versions were 8.2.9, 8.0.25, or 7.2.25, and JDK versions were 1.8_221 or 11.0.22. Apache 2.4 was chosen as the HTTP server. Due to the varying development times of the baselines, we configured both older and newer environments, to ensure compatibility.
5.2. RQ1: Evaluation of Entry URL Generation Effectiveness
In this subsection, we evaluate the effectiveness of CraftFuzz in generating entry URLs using Dataset 2, with the experimental results presented in
Table 3. Report indicates the number of vulnerabilities detected in the static analysis report. Since CraftFuzz currently supports the verification of only five types of vulnerabilities—SQL Injection (SQLi), Command/Code Execution (CE), Cross-Site Scripting (XSS), Unrestricted File Upload (UFU) [
35], and File Inclusion (FI) [
36]—the reported vulnerability count includes only these five types. SR(Static Reports) Count represents the number of entry URLs successfully generated by CraftFuzz, while Avg SR Time records the average time taken to generate each entry URL.
It is worth noting that the routing strategy determination algorithm, which distinguishes between static and dynamic routing for applications, is not included in the entry URL generation time. On average, this algorithm took 5.012 s per application. In our experiments, we used two threshold parameters: MIN_TEST_FILES was set to 10, and ERROR_THRESHOLD was set to 50%. These thresholds were found to provide reasonably accurate results in practice.
The experimental results demonstrate that CraftFuzz incurred minimal overhead in generating entry URLs. Out of 206 static analysis reports, CraftFuzz successfully generated 200 entry URLs, achieving a success rate of 97.1%. For SuiteCRM, however, entry URLs for six static reports could not be generated correctly. The reason was that the static analysis failed to accurately resolve the file inclusion chains, preventing the identification of entry files and thus the generation of correct entry URLs.
5.3. RQ2: Evaluation of Path Constraint Solving Capability
In this subsection, we evaluate CraftFuzz’s path-constraint-solving capabilities using both Dataset 1 and Dataset 2. First, we tested Dataset 1 with five runs of experiments using WebFuzz, PHUZZ, Witcher, and CraftFuzz, with each run lasting 4 h. The results are shown in
Table 4.
Since the microtest code does not contain any frontend form information, WebFuzz and PHUZZ, which rely on crawling to find request data, failed to yield any results. While Witcher also depends on crawling, we found preset request data in its code repository and used this for testing. However, the test results showed slight discrepancies compared to those reported in the Witcher paper. We suspect this might have been due to differences between the request data used in our experiments and the final version in the paper, or the activation of randomization options during testing.
CraftFuzz performed exceptionally well in the microtest evaluations, consistently solving constraints within 20 s. It also excelled in handling the newly added test cases, branching2 and branching5. This success is attributed to its data flow analysis [
9], which enables interprocedural constraint extraction and effectively addresses the challenge of interprocedural constraint solving.
Additionally, since the source code for Predator is not yet open-source and as the environment setup for Atropos proved difficult, these tools were not included in the microtest comparison experiments.
Building on RQ1, we further evaluated CraftFuzz’s path-constraint-solving capabilities on Dataset 2, with the results shown in
Table 3. PC(Path Constraints) Count represents the number of path constraints successfully solved by CraftFuzz, while Avg PC Time records the average time taken to solve each path constraint.
The experimental results indicate that CraftFuzz incurred a low performance overhead in path constraint solving. Out of 200 entry URLs, CraftFuzz successfully solved 190 path constraints, achieving a success rate of 95%. Overall, applications with larger codebases tend to have longer enhanced taint propagation chains, meaning more constraint nodes need to be solved and validated, leading to longer solving times; for instance, applications such as SuiteCRM, Leantime, and Mana. Laravel exhibited relatively higher solving times.
The 10 unsolved path constraints were primarily due to the use of unmodeled built-in functions in the paths, causing CraftFuzz to fail during the constraint extraction phase and preventing the completion of solving. These issues provide directions for further improving the path-constraint-solving ability of CraftFuzz.
5.4. RQ3: Verification of Known Vulnerabilities
In this subsection, we evaluated CraftFuzz and baseline tools on their ability to verify known vulnerabilities using Dataset 3. For tools requiring manual entry URLs, we clicked on as many accessible entry points as possible to simulate real-world vulnerability testing scenarios. For tools using web crawlers, to obtain entry points, we provided a 4-h crawling window. The fuzzing duration followed the recommended settings in Witcher, with 20 min of fuzzing per URL. The experimental results are presented in
Table 5. In the table, CrF, PRE, Wit, Atr, PHU, CeF, and Web represent CraftFuzz, Predator, Witcher, Atropos, PHUZZ, Cefuzz, and WebFuzz, respectively. Since Predator is not open-source and as Atropos is challenging to build, we referenced the evaluation results reported in their respective papers. A hyphen (“-”) indicates that Predator and Atropos did not test a specific target application.
Overall, the target applications contained 189 known vulnerabilities, of which CraftFuzz successfully verified 168, including 70 SQL Injection (SQLi) vulnerabilities, 14 Command/Code Execution (CE) vulnerabilities, 63 Cross-Site Scripting (XSS) vulnerabilities, 9 Unrestricted File Upload (UFU) vulnerabilities, and 12 File Inclusion (FI) vulnerabilities. This indicates that out of the 190 paths solved in RQ2, the data constraints for 168 paths were successfully solved.
The unverified vulnerabilities were primarily due to two reasons. First, false positives in the static analysis report, such as insufficient modeling of sink functions or inaccurate identification of dangerous parameters, led to CraftFuzz generating requests that reached the sink point but failed to verify the existence of the vulnerability. Second, some data constraints had conditions too stringent to be addressed by the payload list, and effective payloads could not be generated through mutation, resulting in failed vulnerability exploitation.
From the perspective of vulnerability types, the complexity of data constraints affected the verification rates differently. CraftFuzz successfully verified 100% of Command/Code Execution and File Inclusion vulnerabilities, 89.7% (70/78) of SQL injection vulnerabilities, 86.3% (63/73) of XSS vulnerabilities, and 75% (9/12) of File Upload vulnerabilities. The lower verification rate for XSS vulnerabilities was due to CraftFuzz’s lack of dedicated modeling for stored XSS, reducing the detection rates. For SQL injection vulnerabilities, some sanitization functions increased the complexity of data constraint solving. Similarly, the challenges in verifying File Upload vulnerabilities were mainly due to constraints introduced by sanitization functions.
Comparison with Predator [18]: The performance improvement of CraftFuzz primarily stemmed from its ability to recognize more opcodes related to path constraints and its more generalized constraint-handling capability. Additionally, CraftFuzz supports the construction of cookie parameters, which are necessary for triggering certain vulnerabilities. For example, Predator failed to test DVWA effectively. According to its paper, this was due to an inability to handle hidden random CSRF tokens. However, the low, medium, and high security levels of DVWA do not carry such tokens. We suspect the failure to test properly was due to incorrect cookie parameter settings, causing DVWA to remain in an “impossible” state.
Comparison with Witcher [13]: CraftFuzz’s performance improvement largely came from its superior entry URL recognition capability. We observed that Witcher struggled to collect valid entry URLs for certain applications, preventing effective testing during the fuzzing phase. Even when extending Witcher’s crawling time beyond the allotted period, it was still unable to observe valid entry URLs being successfully crawled. This limitation was more pronounced when Witcher crawled applications with dynamic routing, where it failed to collect any usable URLs, resulting in no meaningful results for such applications.
Comparison with Atropos [15]: Since we could not successfully reproduce Atropos’s work, its test results were limited to three applications, making comprehensive performance comparisons infeasible. We speculate that Atropos’s parameter inference mechanism would perform well, yielding results consistent with CraftFuzz. Atropos uses a snapshot-based approach to maintain a consistent program state during testing, but this significantly reduces its ease of use.
Comparison with Cefuzz [24]: Cefuzz, our previous work, mainly focuses on solving data constraints but has weaker capabilities for handling path constraints. Moreover, Cefuzz only supports applications with static routing. Compared to CraftFuzz, it cannot detect command/code execution vulnerabilities in applications with dynamic routing.
Comparison with WebFuzz [16] and PHUZZ [17]: WebFuzz and PHUZZ rely on manual interaction to collect URLs and form information for target applications. In contrast, CraftFuzz demonstrated more efficient and precise entry URL recognition. For applications with dynamic routing, many entry URLs cannot be obtained through frontend interaction. Instead, they require static analysis combined with routing rules to generate the necessary parameters for correct access. This limitation hampers manual interaction and crawling methods in obtaining entry URLs for dynamic routing applications. PHUZZ’s innovative design for instrumenting dangerous functions enables it to detect parameters passed to these functions, enhancing its vulnerability-verification capabilities. This feature made PHUZZ’s performance second only to CraftFuzz.
6. Discussion
This section describes the current limitations of CraftFuzz and our plans to resolve them as part of our future work.
File Inclusion Chain Identification: As discussed in the evaluation section, incomplete file inclusion chain identification during static analysis may lead to URL generation failures. The primary reason for this lies in the fact that large-scale applications often undergo a unified initialization phase that executes numerous file inclusion operations. These inclusions are often unrelated to vulnerability analysis, resulting in overly long file inclusion chains and increasing the likelihood of errors in static analysis. To address this issue, we plan to introduce a caching mechanism in the future. When it is detected that the application consistently executes a unified initialization phase, the program state after initialization will be saved and used as the starting point for subsequent analyses, thereby avoiding the interference of this initialization phase with the static analysis accuracy.
Unsolvable Built-in Constraints: Built-in functions remain a significant challenge in static analysis. CraftFuzz has abstracted some commonly used PHP built-in functions, allowing it to correctly extract their constraint semantics. However, this expert-driven modeling approach addresses the symptoms, but not the root cause. To achieve greater scalability, we plan to introduce large language models in the future. Leveraging their extensive knowledge, we will design algorithms to automatically extract the semantics of most built-in functions.
Constraint-Dependent Program Variables: Program variables can participate in both path constraints and data constraints. Currently, CraftFuzz handles path constraints and data constraints independently. However, when a variable is a critical component of both constraints, this separation may lead to problems. Specifically, if a variable’s value is adjusted to satisfy the path constraint, it may no longer satisfy the data constraint. Similarly, if the variable is mutated to meet the data constraint, it may break its compliance with the path constraint. This could lead to a deadlock between solving path and data constraints. To address this, we plan to introduce symbolic execution in the future. When a variable is detected as being involved in both path and data constraints, symbolic execution will be employed to solve the variable, ensuring consistency across both constraints.
7. Related Work
In recent years, detecting vulnerabilities in web applications has garnered widespread attention. Previous research has primarily focused on two approaches: static analysis [
9,
37,
38,
39,
40,
41,
42,
43] and dynamic testing. For static analysis, data flow (taint) analysis has become the predominant method. Recent works have often modeled source code using code property graphs [
37,
42], abstract syntax trees [
43], or opcodes [
9]. However, these tools are often associated with a potentially high false positive rate. Dynamic approaches [
13,
15,
16,
17,
18,
24] are more closely related to our work.
Dynamic approaches primarily refer to fuzzing. As mentioned in the background section, modern web application fuzzing can generally be categorized into three types: black-box fuzzing, gray-box fuzzing, and directed fuzzing.
Black-box fuzzing gained significant popularity in earlier years because it requires no internal knowledge of the target application, thereby lowering the technical barrier to testing, while offering advantages such as rapid deployment and ease of implementation. Widely-used black-box web fuzzing tools include Burp Suite [
44], Acunetix Web Vulnerability Scanner [
45], HCL AppScan [
46], OWASP ZAP [
47], Enemy of the State [
20], Black Widow [
10], and ReScan [
12]. However, since most of these tools rely on predefined or user-defined rules for fuzzing and lack internal knowledge of the application, they often can only detect shallow vulnerabilities that match predefined patterns. In contrast, CraftFuzz leverages static analysis results to direct fuzzing, effectively utilizing internal application knowledge to enhance the validation of deep-level vulnerabilities.
Gray-box fuzzing has received increasing attention in recent years, due to its ability to improve testing efficiency by utilizing partial internal knowledge. WebFuzz [
16], as an earlier study in this domain, used AST-based static instrumentation to collect code coverage feedback. This work shifted the research focus from black-box to gray-box fuzzing. However, WebFuzz can only detect XSS vulnerabilities, and its test interfaces are limited to those identified by crawlers, restricting code coverage due to the crawler’s performance constraints. In comparison, CraftFuzz can detect a broader range of vulnerabilities and precisely generate effective requests that directly reach the vulnerability regions, resulting in a significantly higher effective code coverage.
Witcher [
13] further improved coverage collection by implementing interpreter-level instrumentation and QEMU-based coverage tracking. Additionally, it introduced a fault escalation method that treats syntax errors as equivalents to crashes in native program fuzzing, thereby alleviating the vulnerability monitoring challenge. ATROPOS [
15] focused on improving constraint-solving capabilities by hooking string comparison opcodes to extract expected key–value pairs. Compared to these tools, CraftFuzz, directed by static analysis results, significantly reduces unnecessary request mutation overhead. Its in-depth semantic analysis of PHP opcodes further enhances its constraint-solving capabilities.
PHUZZ [
17] enhanced vulnerability monitoring by hooking dangerous functions to capture the actual state of requests upon reaching these functions, significantly improving monitoring accuracy. However, PHUZZ did not optimize constraint-solving capabilities, making it difficult for the fuzzer to reach the vulnerability monitoring stage, which ultimately reduced its overall effectiveness. In contrast, CraftFuzz employs multiple reflective strategies to construct payloads for accurate vulnerability triggering, while simultaneously leveraging path constraint-solving techniques to reach these critical points more efficiently.
Crawlers [
48,
49] serve as a critical component in both black-box and gray-box fuzzing, since the pages discovered by crawlers often become the starting points for fuzzing. Typically, developers expect crawlers to cover as many pages as possible, to maximize code coverage and improve the likelihood of discovering vulnerabilities. Although the application of AI techniques in web crawlers has increased in recent years [
50,
51], most efforts have not focused on addressing the specific challenges posed by web application fuzzing [
52], such as infinite crawls and session management [
10]. These challenges have significantly hindered the advancement of black-box and gray-box fuzzing methods.
Gelato [
53] is a feedback-driven client-side security analysis approach that combines state-aware crawling with lightweight taint analysis to detect vulnerabilities such as DOM-based XSS in JavaScript applications. Its input generation relies on constraint-solving techniques, primarily based on data collected by runtime crawlers. However, due to its lack of internal knowledge, Gelato cannot fully comprehend the semantic constraints of form fields, such as whether they only accept specific formats (e.g., email or phone numbers), making it difficult to accurately analyze input dependencies. In contrast, CraftFuzz not only detects server-side vulnerabilities but also leverages internal knowledge to direct the generation of valid inputs. Similarly, the black-box fuzzing approach proposed by Alsaedi et al. [
54], which is also crawler-based, suffers from the same limitation—lacking internal knowledge. Essentially, it submits basic vulnerability payloads into discovered web forms, in the hope of triggering vulnerabilities. Such an approach is insufficient for handling the growing complexity of modern web applications, as it can only detect superficial vulnerabilities.
CrawlMLLM [
55] is a multi-modal large language model (MLLM)-based enhancement for web crawling, designed to improve attack surface coverage in web application fuzzing. It utilizes MLLM to analyze page structure, user interactions, and state transitions, optimizing crawling paths and input generation. However, CrawlMLLM relies heavily on LLM inference, which introduces instability in path exploration. Additionally, its lack of static analysis capabilities makes it difficult to generate test requests that accurately reach vulnerability trigger points.
FuzzCache [
56] is an optimization technique for web application fuzzing, designed to reduce computational overhead by caching database queries and network request data. By leveraging cross-process shared memory, FuzzCache improves the cache reuse efficiency in fuzzing. However, while this method enhances fuzzing execution efficiency, it merely improves vulnerability discovery within a limited time frame. The core challenge of vulnerability detection still lies in validating input constraints and refining exploit-triggering mechanisms to effectively direct fuzzers toward uncovering deeper security issues.
Directed fuzzing has increasingly drawn the attention of web application fuzzing researchers, because it offers a higher-level solution by overcoming many of the limitations faced by black-box and gray-box techniques. Cefuzz [
24] was the first to leverage static vulnerability analysis results for directed fuzzing, marking it as the first directed fuzzing method for web applications. It achieved excellent results in detecting command execution and code execution vulnerabilities. Predator [
18] introduced a static analysis phase to identify potential targets, focusing on constructing inclusion and call chains, while dynamically analyzing path changes to enhance path-exploration capabilities. Compared to these approaches, CraftFuzz has further expanded URL-generation capabilities by analyzing application routing rules and extracting constraint information with more precise static analysis, improving the success rate of path constraint solving. In vulnerability monitoring, CraftFuzz addresses the false positives caused by error escalation in previous works by constructing payloads with multiple reflection strategies, thereby enhancing the overall reliability and accuracy of vulnerability verification.
sqlFuzz [
57] is another directed fuzzing method specifically designed for detecting SQL injection vulnerabilities, but it has several limitations. First, it does not effectively resolve the correlation between crawler-discovered input points and static taint analysis results, making it heavily reliant on the crawler for test entry discovery. Second, its mutation strategy lacks precision, as it only interacts with existing parameter values, rather than leveraging internal knowledge to direct mutations. Finally, its vulnerability detection primarily relies on SQL syntax errors, leading to a high false positive rate.
8. Conclusions
This paper introduced CraftFuzz, a directed fuzzing approach that integrates static and dynamic analysis. It aims to bypass extensive ineffective path exploration and generate precise requests for validating PHP web vulnerabilities. Our approach is based on the following understanding: static analysis provides extensive coverage of the target program’s code but does not always produce accurate results; dynamic analysis, on the other hand, can verify the actual existence of vulnerabilities but is limited in code coverage. Building on this understanding, CraftFuzz combines the strengths of both methods and employs a multi-stage refinement-solving strategy. This strategy includes the static extraction of path constraints and routing rules for entry URL generation, solving path constraints through fuzzing and parameter mutation, and effectively addressing data constraints through payload construction using multiple reflection strategies. Ultimately, CraftFuzz ensures that test requests precisely reach the target sink points and successfully trigger vulnerabilities.
The experimental results demonstrate that CraftFuzz solved each entry URL and path constraint in an average of 6 s and 20 s, respectively, achieving success rates of 97.1% and 95%. For known vulnerability verification, CraftFuzz validated 88.88% of vulnerabilities, outperforming state-of-the-art fuzzers by 32.28%. This significantly enhances the efficiency and effectiveness of vulnerability verification.




{kind=link}
{kind=link}