
Talent Supply and Demand Matching Based on Prompt Learning and the Pre-Trained Language Model


Abstract
1. Introduction
- Proposing a method that leverages prompt learning combined with large language models to extract highly discriminative descriptions of talent ability and demand information from the unstructured data.
- Utilizing a pre-trained large language model (BERT) to generate feature embedding, that effectively capture the contextual relationships within the text, reflecting the nuanced dependencies and long-range interactions inherent in the data.
- Leveraging talent-ability-specific and demand-specific encoding networks, which consist of 1D-CNN and Bi-LSTM, to capture both local and global representations of talent ability and demand, thus providing a comprehensive expression of these features.
2. Materials and Methods
2.1. Benchmark Datasets
2.2. Feature Representation
2.3. The Architecture of TSDM
2.4. Feature Extracting with Prompt Learning
2.5. Feature Embedding with the Pre-Trained BERT Model
2.6. Demand-Specific and Talent-Ability-Specific Encoding Network
2.7. The Classification Prediction Network
2.8. Loss Function
2.9. Performance Evaluation Metrics
3. Results and Discussion
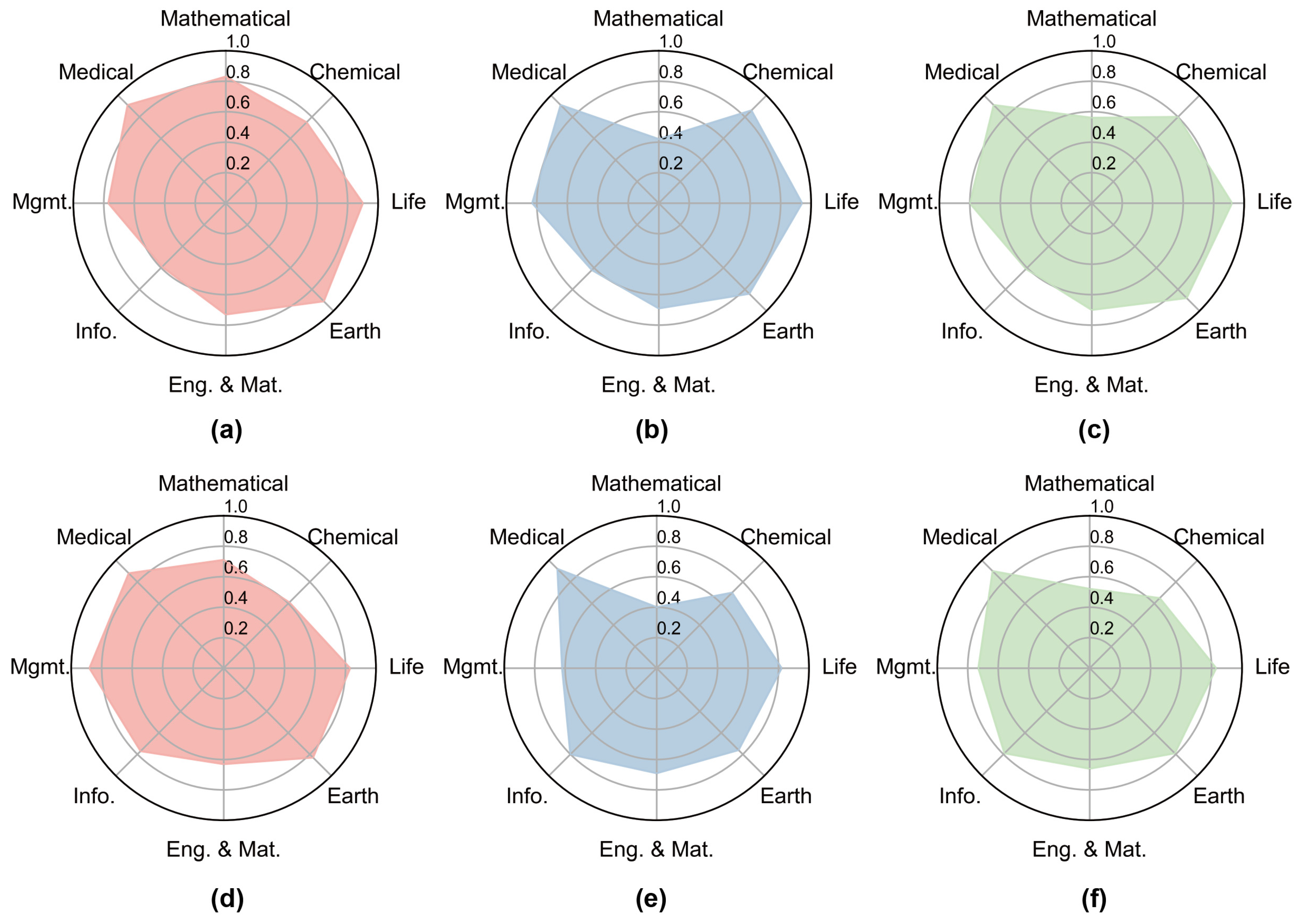
3.1. Feature Embedding Extracted by the BERT Language Model Was Effective in Accounting for Talent Supply and Demand
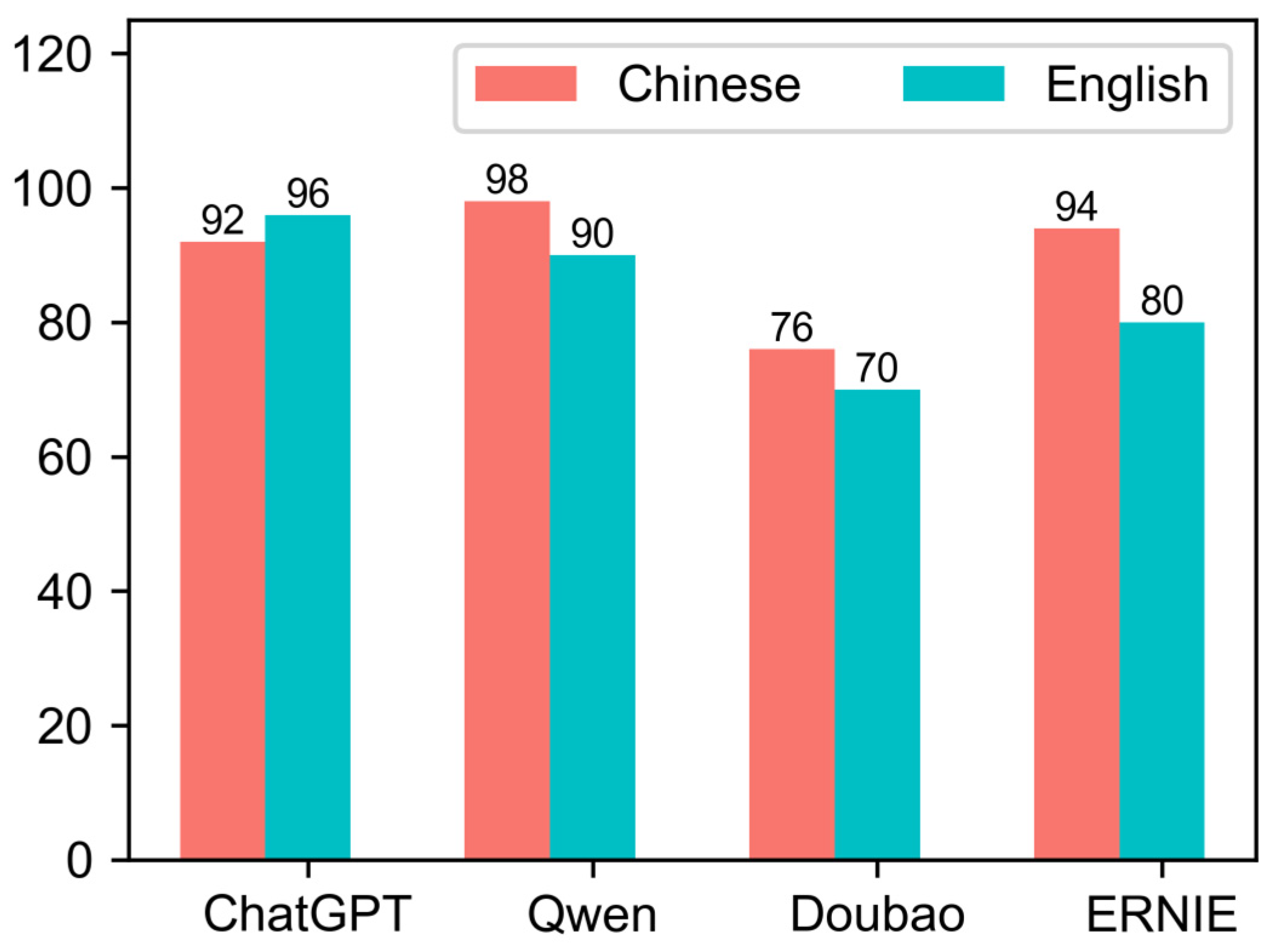
3.2. Comparison of Prompt Learning Effectiveness Across Different Large Language Models
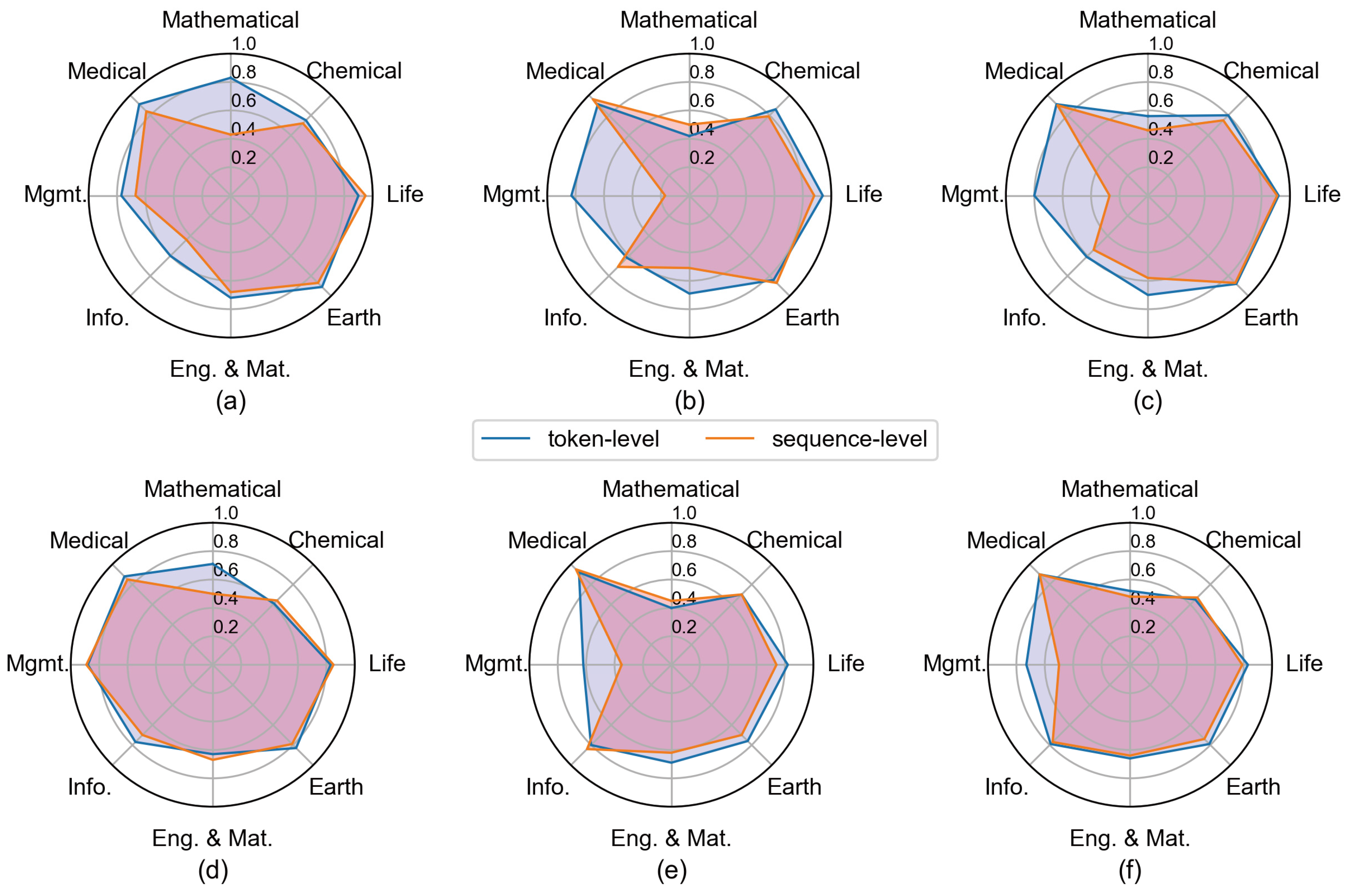
3.3. The Impact of Sentence-Level and Token-Level Feature Embedding from the Pre-Trained BERT Model
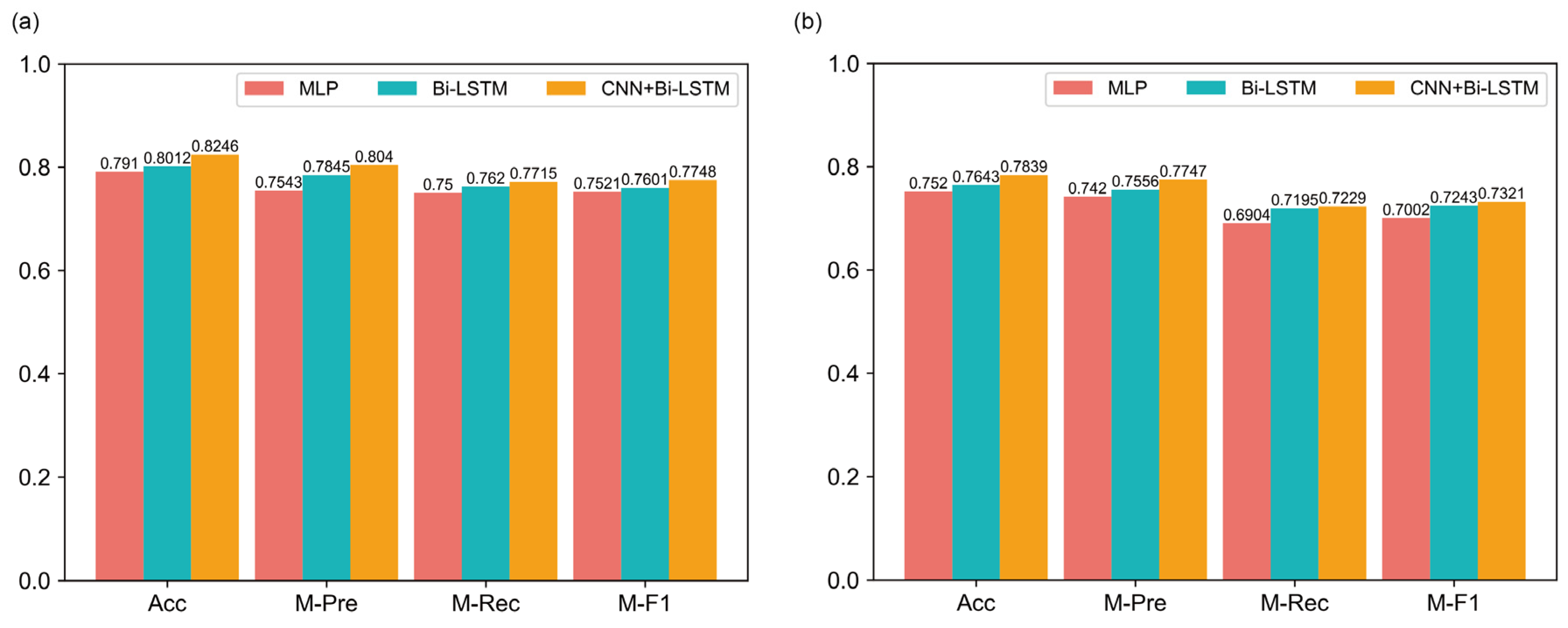
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Academic | Hot Topic |
|---|---|
| Mathematical | Ab Initio Calculations, Machine Learning, Numerical Simulation, Deep Learning, Two-Dimensional Materials |
| Chemical | Structure-Activity Relationship, Photocatalysis, Reaction Mechanism, Ionic Liquids, Electrocatalysis |
| Life | Molecular Mechanism, Gene Function, Transcription Factors, Rice, Regulatory Network |
| Earth | Climate Change, Numerical Simulation, Tibetan Plateau, Deep Learning, Model Simulation |
| Engineering and Materials | Mechanical Properties, Numerical Simulation, Nanocomposites, Composites, Multi-Field Coupling |
| Information | Deep Learning, Machine Learning, Artificial Intelligence, Privacy Protection, Edge Computing |
| Management | Machine Learning, Health Management, Big Data, Artificial Intelligence, Sustainable Development |
| Medical | Exosomes, Macrophages, Autophagy, Ferroptosis, Long Non-Coding RNA (lncRNA) |
References
- Xie, Y. Study on Supply and Demand Matching of High-Skilled Talents in Strategic Emerging Industries in Shanghai. Oper. Res. Fuzziol. 2023, 13, 1601–1609. [Google Scholar] [CrossRef]
- Brunello, G.; Wruuck, P. Skill shortages and skill mismatch: A review of the literature. J. Econ. Surv. 2021, 35, 1145–1167. [Google Scholar] [CrossRef]
- Liu, Y. Talent scouting to accelerate technological innovation during the COVID-19 global health crisis: The role of organizational innovation in China. Eur. Manag. J. 2024; in press. [Google Scholar] [CrossRef]
- Liu, X. Research on the Impact of Technological Talent Loss in High tech Enterprises on the Construction of Enterprise Talent Teams. Front. Bus. Econ. Manag. 2023, 9, 99–102. [Google Scholar] [CrossRef]
- Makarius, E.E.; Srinivasan, M. Addressing skills mismatch: Utilizing talent supply chain management to enhance collaboration between companies and talent suppliers. Bus. Horiz. 2017, 60, 495–505. [Google Scholar] [CrossRef]
- Jooss, S.; Collings, D.G.; McMackin, J.; Dickmann, M. A skills-matching perspective on talent management: Developing strategic agility. Hum. Resour. Manag. 2024, 63, 141–157. [Google Scholar] [CrossRef]
- Moheb-Alizadeh, H.; Handfield, R.B. Developing Talent from a Supply–Demand Perspective: An Optimization Model for Managers. Logistics 2017, 1, 5. [Google Scholar] [CrossRef]
- Nath, R.K.; Ahmad, T. Content Based Recommender System: Methodologies, Performance, Evaluation and Application. In Proceedings of the 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 16–17 December 2022; pp. 423–428. [Google Scholar]
- Mustafa, N.; Ibrahim, A.O.; Ahmed, A.; Abdullah, A. Collaborative filtering: Techniques and applications. In Proceedings of the 2017 International Conference on Communication, Control, Computing and Electronics Engineering (ICCCCEE), Khartoum, Sudan, 16–18 January 2017; pp. 1–6. [Google Scholar]
- Koren, Y.; Rendle, S.; Bell, R. Advances in Collaborative Filtering. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Eds.; Springer: New York, NY, USA, 2022; pp. 91–142. [Google Scholar]
- Chaudhari, A.; Seddig, A.A.H.; Sarlan, A.; Raut, R. A Hybrid Recommendation System: A Review. IEEE Access 2024, 12, 157107–157126. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, L. College Student Employment Recommendation Algorithm Based on Convolutional Neural Network. In Proceedings of the 2022 International Conference on Education, Network and Information Technology (ICENIT), Liverpool, UK, 2–3 September 2022; pp. 71–74. [Google Scholar]
- Derry, A.; Krzywinski, M.; Altman, N. Convolutional neural networks. Nat. Methods 2023, 20, 1269–1270. [Google Scholar] [CrossRef]
- Nguyen, N.K.; Le, A.-C.; Pham, H.T. Deep Bi-Directional Long Short-Term Memory Neural Networks for Sentiment Analysis of Social Data; Springer: Cham, Switzerland, 2016; pp. 255–268. [Google Scholar]
- Youping, L.; Jiangang, S. Talent Recruitment Platform for Large-Scale Group Enterprises Based on Deep Learning. In Proceedings of the 2022 7th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 22–24 April 2022; pp. 172–176. [Google Scholar]
- Zhao, Z.D.; Shang, M.S. User-Based Collaborative-Filtering Recommendation Algorithms on Hadoop. In Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010; pp. 478–481. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, Hong Kong, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Yao, S.; Yi, Z.; Zhang, L. Researches on the best-fitted talents recommendation algorithm. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 4247–4252. [Google Scholar]
- Shan, Z.P.; Lei, Y.Q.; Zhang, D.F.; Zhou, J. NASM: Nonlinearly Attentive Similarity Model for Recommendation System via Locally Attentive Embedding. IEEE Access 2019, 7, 70689–70700. [Google Scholar] [CrossRef]
- Girase, S.; Powar, V.; Mukhopadhyay, D. A user-friendly college recommending system using user-profiling and matrix factorization technique. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 1–5. [Google Scholar]
- Chou, Y.C.; Yu, H.Y. Based on the application of AI technology in resume analysis and job recommendation. In Proceedings of the 2020 IEEE International Conference on Computational Electromagnetics (ICCEM), Singapore, 24–26 August 2020; pp. 291–296. [Google Scholar]
- Biswas, P.K.; Liu, S. A hybrid recommender system for recommending smartphones to prospective customers. Expert Syst. Appl. 2022, 208, 118058. [Google Scholar] [CrossRef]
- Ponnaboyina, R.; Makala, R.; Venkateswara Reddy, E. Smart Recruitment System Using Deep Learning with Natural Language Processing; Springer: Singapore, 2022; pp. 647–655. [Google Scholar]
- Aničin, L.; Stojmenović, M. Understanding Job Requirements Using Natural Language Processing. In International Scientific Conference—Sinteza 2022; Singidunum University: Belgrade, Serbia, 2022. [Google Scholar]
- Abisha, D.; Keerthana, S.; Kavitha, K.; Ramya, R. Resspar: AI-Driven Resume Parsing and Recruitment System using NLP and Generative AI. In Proceedings of the 2024 Second International Conference on Intelligent Cyber Physical Systems and Internet of Things (ICoICI), Coimbatore, India, 28–30 August 2024; pp. 1–6. [Google Scholar]
- Strübbe, S.M.; Grünwald, A.T.D.; Sidorenko, I.; Lampe, R. A Rule-Based Parser in Comparison with Statistical Neuronal Approaches in Terms of Grammar Competence. Appl. Sci. 2024, 15, 87. [Google Scholar] [CrossRef]
- Zhang, Y.; Tuo, M.; Yin, Q.; Qi, L.; Wang, X.; Liu, T. Keywords extraction with deep neural network model. Neurocomputing 2020, 383, 113–121. [Google Scholar] [CrossRef]
- Quazi, S.; Musa, S.M. Performing Text Classification and Categorization through Unsupervised Learning. In Proceedings of the 2023 1st International Conference on Advanced Engineering and Technologies (ICONNIC), Kediri, Indonesia, 14 October 2023; pp. 1–6. [Google Scholar]
- Qi, S. Evaluation index system of science and technology innovation think tank talents based on competency model. J. Comp. Methods Sci. Eng. 2024, 24, 1101–1117. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, Y.; Qiang, J.; Wu, X. Prompt-Learning for Short Text Classification. IEEE Trans. Knowl. Data Eng. 2024, 36, 5328–5339. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Yuan, H.; Hernandez, A.A. User Cold Start Problem in Recommendation Systems: A Systematic Review. IEEE Access 2023, 11, 136958–136977. [Google Scholar] [CrossRef]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609. [Google Scholar]
- Tanwar, M.; Duggal, R.; Khatri, S.K. Unravelling unstructured data: A wealth of information in big data. In Proceedings of the 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions), Noida, India, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Adnan, K.; Akbar, R. An analytical study of information extraction from unstructured and multidimensional big data. J. Big Data 2019, 6, 91. [Google Scholar] [CrossRef]
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Singh, S.; Singh, S.; Kraus, S.; Sharma, A.; Dhir, S. Characterizing generative artificial intelligence applications: Text-mining-enabled technology roadmapping. J. Innov. Knowl. 2024, 9, 100531. [Google Scholar] [CrossRef]
- Jovanović, M.; Campbell, M. Generative Artificial Intelligence: Trends and Prospects. Computer 2022, 55, 107–112. [Google Scholar] [CrossRef]
- Zubiaga, A. Natural language processing in the era of large language models. Front. Artif. Intell. 2023, 6, 1350306. [Google Scholar] [CrossRef] [PubMed]
- Mishra, T.; Sutanto, E.; Rossanti, R.; Pant, N.; Ashraf, A.; Raut, A.; Uwabareze, G.; Oluwatomiwa, A.; Zeeshan, B. Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers. Sci. Rep. 2024, 14, 31672. [Google Scholar] [CrossRef] [PubMed]
- Younesi, R.T.; Tanha, J.; Namvar, S.; Mostafaei, S.H. A CNN-BiLSTM based deep learning model to sentiment analysis. In Proceedings of the 2024 20th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP), Babol, Iran, 21–22 February 2024; pp. 1–6. [Google Scholar]
- Zhang, L.; Xiang, F. Relation Classification via BiLSTM-CNN; Springer: Cham, Switzerland, 2018; pp. 373–382. [Google Scholar]
- Sharma, N.; Jain, V.; Mishra, A. An Analysis of Convolutional Neural Networks for Image Classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Amjoud, A.B.; Amrouch, M. Object Detection Using Deep Learning, CNNs and Vision Transformers: A Review. IEEE Access 2023, 11, 35479–35516. [Google Scholar] [CrossRef]
- Zou, N.; Xiang, Z.; Chen, Y.; Chen, S.; Qiao, C. Boundary-Aware CNN for Semantic Segmentation. IEEE Access 2019, 7, 114520–114528. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Jatnika, D.; Bijaksana, M.A.; Suryani, A.A. Word2Vec Model Analysis for Semantic Similarities in English Words. Procedia Comput. Sci. 2019, 157, 160–167. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Mostafa, M.M. Twenty years of Wikipedia in scholarly publications: A bibliometric network analysis of the thematic and citation landscape. Qual. Quant. 2023, 57, 5623–5653. [Google Scholar] [CrossRef]
- Farquhar, S.; Kossen, J.; Kuhn, L.; Gal, Y. Detecting hallucinations in large language models using semantic entropy. Nature 2024, 630, 625–630. [Google Scholar] [CrossRef]
- Zhu, G.; Zhao, B.; Tang, J. A Study of the AIGC-Enabled BOPPPS Smart Teaching Model. In Proceedings of the 2024 International Symposium on Artificial Intelligence for Education, Xi’an, China, 6–8 September 2024; pp. 166–170. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]

| Academic | Training | Matching Test Set | Recommendation Test Set |
|---|---|---|---|
| Mathematical | 884 | 211 | 25 |
| Chemical | 1922 | 324 | 66 |
| Life | 2667 | 605 | 104 |
| Earth | 1570 | 223 | 38 |
| Engineering and Materials | 2223 | 412 | 55 |
| Information | 1673 | 286 | 24 |
| Management | 360 | 72 | 12 |
| Medical | 3337 | 952 | 45 |
| Mission Type | Models | Acc (%) | M-Pre (%) | M-Rec (%) | M-F1 (%) |
|---|---|---|---|---|---|
| Recommendation task | Word2Vec | 77.15 | 76.02 | 74.89 | 75.06 |
| GloVe | 79.40 | 77.34 | 75.45 | 75.89 | |
| BERT | 82.46 | 80.40 | 77.15 | 77.48 | |
| Prediction task | Word2Vec | 72.32 | 70.01 | 70.03 | 70.96 |
| GloVe | 76.33 | 75.33 | 71.50 | 71.69 | |
| BERT | 78.39 | 77.47 | 72.29 | 73.21 |
| Mission Type | Feature Embedding | Acc (%) | M-Pre (%) | M-Rec (%) | M-F1 (%) |
|---|---|---|---|---|---|
| Recommendation task | sentence-level | 76.05 | 70.42 | 67.19 | 66.38 |
| token-level | 82.46 | 80.40 | 77.15 | 77.48 | |
| Prediction task | sentence-level | 76.10 | 74.21 | 67.19 | 69.41 |
| token-level | 78.39 | 77.47 | 72.29 | 73.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Liu, J.; Zhuang, C. Talent Supply and Demand Matching Based on Prompt Learning and the Pre-Trained Language Model. Appl. Sci. 2025, 15, 2536. https://doi.org/10.3390/app15052536
Li K, Liu J, Zhuang C. Talent Supply and Demand Matching Based on Prompt Learning and the Pre-Trained Language Model. Applied Sciences. 2025; 15(5):2536. https://doi.org/10.3390/app15052536
Chicago/Turabian StyleLi, Kunping, Jianhua Liu, and Cunbo Zhuang. 2025. "Talent Supply and Demand Matching Based on Prompt Learning and the Pre-Trained Language Model" Applied Sciences 15, no. 5: 2536. https://doi.org/10.3390/app15052536
APA StyleLi, K., Liu, J., & Zhuang, C. (2025). Talent Supply and Demand Matching Based on Prompt Learning and the Pre-Trained Language Model. Applied Sciences, 15(5), 2536. https://doi.org/10.3390/app15052536