
Label-Guided Data Augmentation for Chinese Named Entity Recognition


Abstract
1. Introduction
- We propose a novel Chinese NER model, LGDA, which introduces Label-Guided Data Augmentation to enhance performance in low-resource scenarios.
- We design a two-stage framework that includes a data augmentation module for expanding training data and a label semantic fusion module for integrating label information effectively.
- We validate the proposed method through extensive experiments on two public datasets, OntoNotes 4.0 (Chinese) and MSRA, achieving state-of-the-art performance.
2. Related Work
2.1. Chinese NER
2.2. Low-Resource NER
2.3. Data Augmentation
3. Primary Definition and Model Architecture
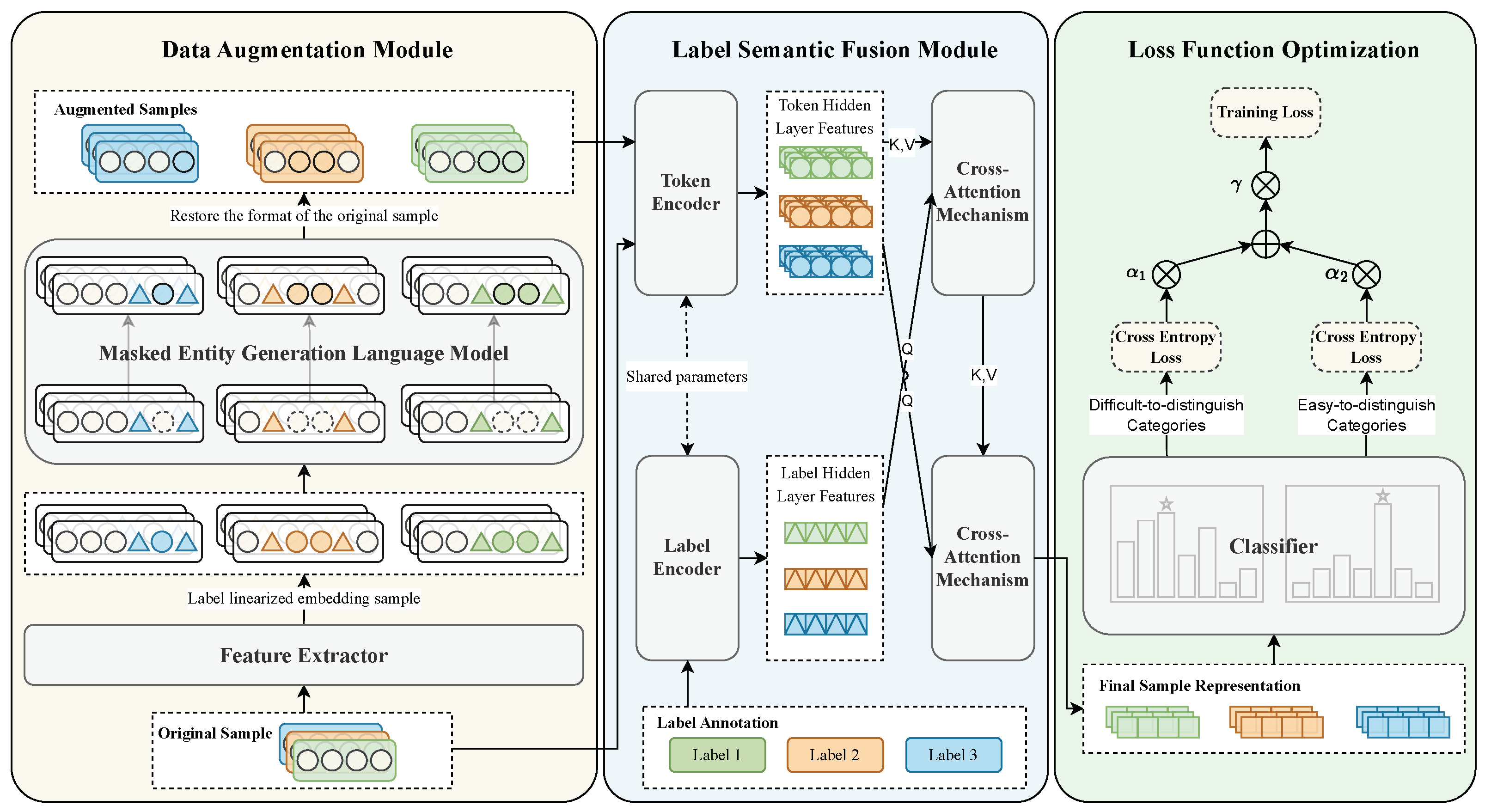
4. Approach
4.1. Data Augmentation Module
4.1.1. Label Linearization Embedding
4.1.2. Masked Entity Generation Language Model
4.2. Label Semantic Fusion Module
4.2.1. Twin Encoders
4.2.2. Cross-Attention Mechanism
4.3. Loss Function Optimization
| Algorithm 1 Pseudocode of LGDA model |
| Require: Dataset , Model f, Encoder Network Ensure: Model Parameters 1: , 2: for each mini-batch do 3: Obtain the original label linearization of X; 4: Randomly mask entities in to get ; 5: Fine-tune ; 6: end for 7: for each mini-batch do 8: Obtain the original label linearization of X; 9: Randomly mask entities in to get ; 10: Generate new text data ; 11: ; 12: ; 13: end for 14: for each mini-batch do 15: Convert labels Y to label annotation L; 16: Input L into the label encoder network to get its hidden layer features ; 17: Input X into the text encoder network to get its hidden layer features ; 18: Use cross-attention mechanism to obtain the final sample representation C through Equations (5)–(7); 19: Input into the final linear layer and calculate the to get the final prediction probability; 20: Calculate the total loss through Equation (9); 21: Update parameters to minimize the total loss . 22: end for |
5. Experiments Setting
5.1. Datasets and Evaluation Metrics
5.2. Baseline Models
- BERT (2018) [10]: BERT, a pre-trained language model with a labeled classifier, fully encodes words and further adds a CRF label decoding layer.
- Lattice LSTM (2018) [11]: A dictionary-based Chinese named entity recognition method using a lattice structure that fully utilizes the information of characters and character sequences.
- BERT-MRC (2019) [15]: It reconstructs the named entity recognition task as a reading comprehension task, with entity labels as query questions and answers as entities, promoting entity extraction with this query prior knowledge.
- MECT (2021) [20]: A cross-Transformer model based on multi-modal data embeddings that integrates the structural information of Chinese characters to improve the effect of low-resource Chinese named entity recognition.
- Multi-Grained (2021) [21]: A multi-grained distillation method for named entity recognition, using an improved Viterbi algorithm to construct pseudo-labels and transfer knowledge from teacher models to lightweight models.
- LEAR (2021) [8]: It views the named entity recognition task as a question-answering task, using preset questions for entity extraction, and proposes using label knowledge to improve text representation.
- PCBERT (2022) [9]: A two-stage model for low-sample Chinese named entity recognition: the first stage uses P-BERT with prompt templates to extract implicit label features, and the second stage fine-tunes a lexicon-based C-BERT with label expansion functions.
- XLNet-Transformer-R (2023) [16]: A model that combines XLNet and a Transformer encoder with relative positional encodings to process long text and contextual information and uses R-Drop to prevent overfitting.
- MW-NER (2023) [17]: A model for Chinese NER that fuses multi-granularity word information by using a strong–weak feedback attention mechanism and combines it with character information via two fusion strategies to enrich semantics and reduce segmentation errors.
- E-strPron (2024) [18]: A method that integrates pronunciation, radical, strokes, writing order, and lexicon features, using two cross-Transformers to capture attention and a soft fusion module to combine mutual attention.
5.3. Research Questions
- RQ1
- Compared with the baseline models, can the LGDA model achieve better results in Chinese named entity recognition tasks?
- RQ2
- How does the LGDA model perform under the few-shot setting?
- RQ3
- Which module in the LGDA model contributes the most to improving the model’s performance?
- RQ4
- What is the impact of label annotation on the LGDA model?
- RQ5
- How do different hyperparameter settings affect the LGDA model?
5.4. Parameter Settings
6. Results and Discussion
6.1. Overall Model Performance
- Conclusion 1: The proposed model, LGDA, performs better than the baseline models in the majority of metrics and achieves superior results in Chinese named entity recognition tasks.
6.2. Few-Shot Experiment
- Conclusion 2: In the few-shot scenario, the LGDA model still significantly outperforms the baseline models, with the data augmentation module playing the most significant role.
6.3. Ablation Study
- Conclusion 3: In low-resource scenarios, the data augmentation module contributes the most to improving model performance; for scenarios with fewer entity types, the label semantic fusion module of the proposed model plays the most significant role in enhancing recognition effectiveness.
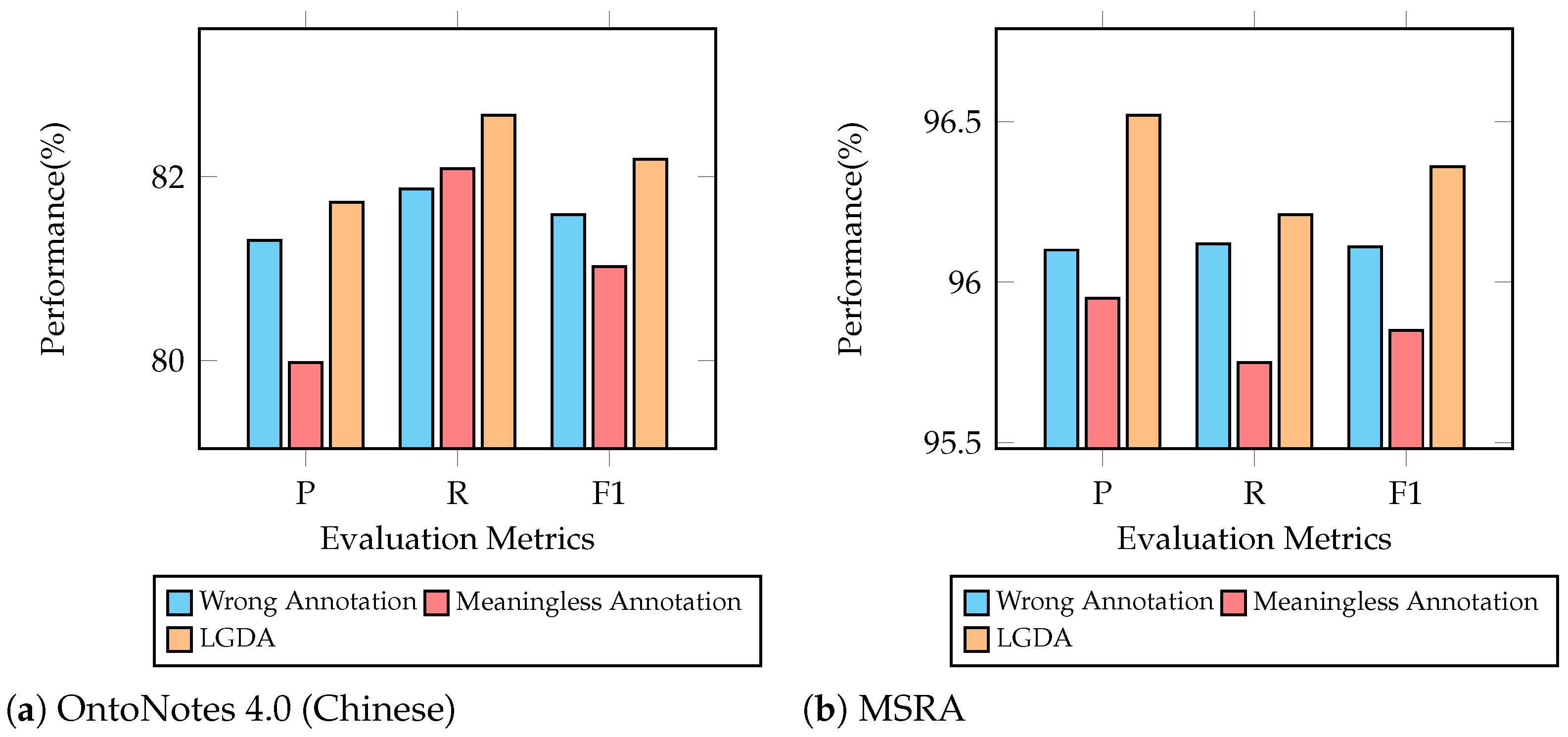
6.4. Label Annotation Experiment
- Conclusion 4: Correct label annotation contributes to enhancing effectiveness in named entity recognition.
6.5. Hyperparameter Experiment
- Conclusion 5: When the hyperparameter , the model achieves a balance in focusing on easy- and difficult-to-distinguish samples, resulting in optimal performance.
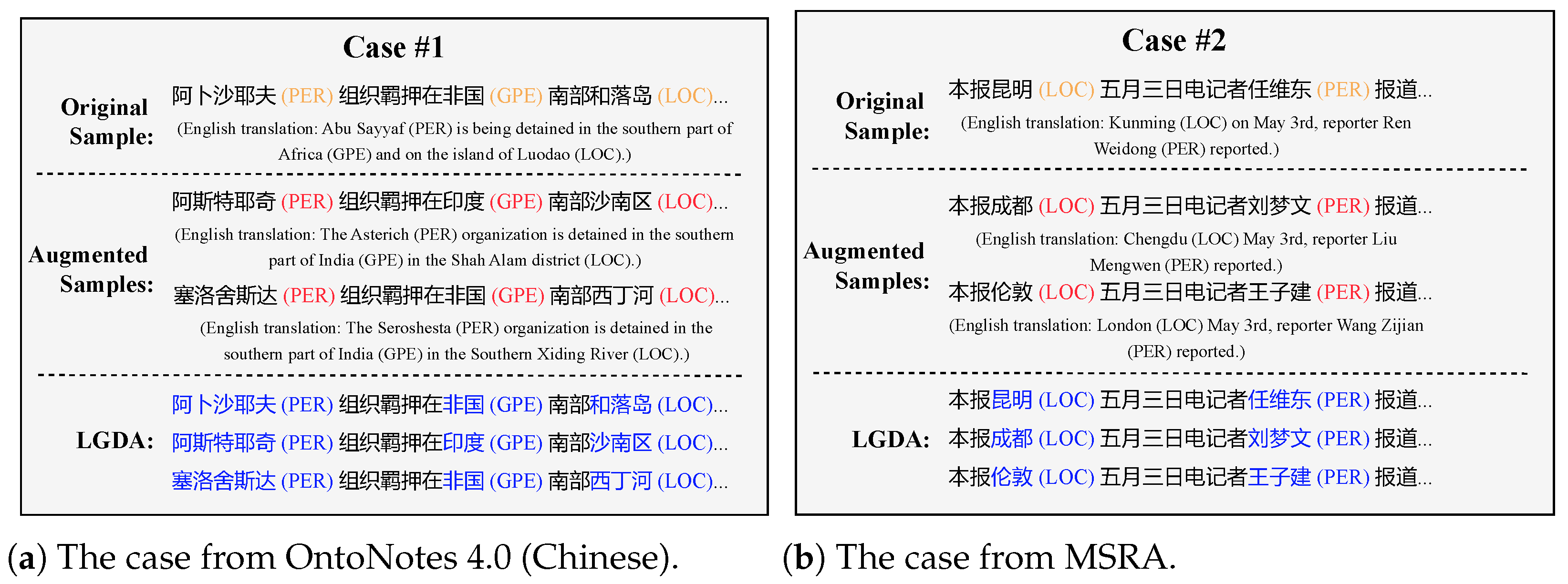
6.6. Case Study
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Supplementary Experiments
Appendix A.1. The Effect of Augmented Samples
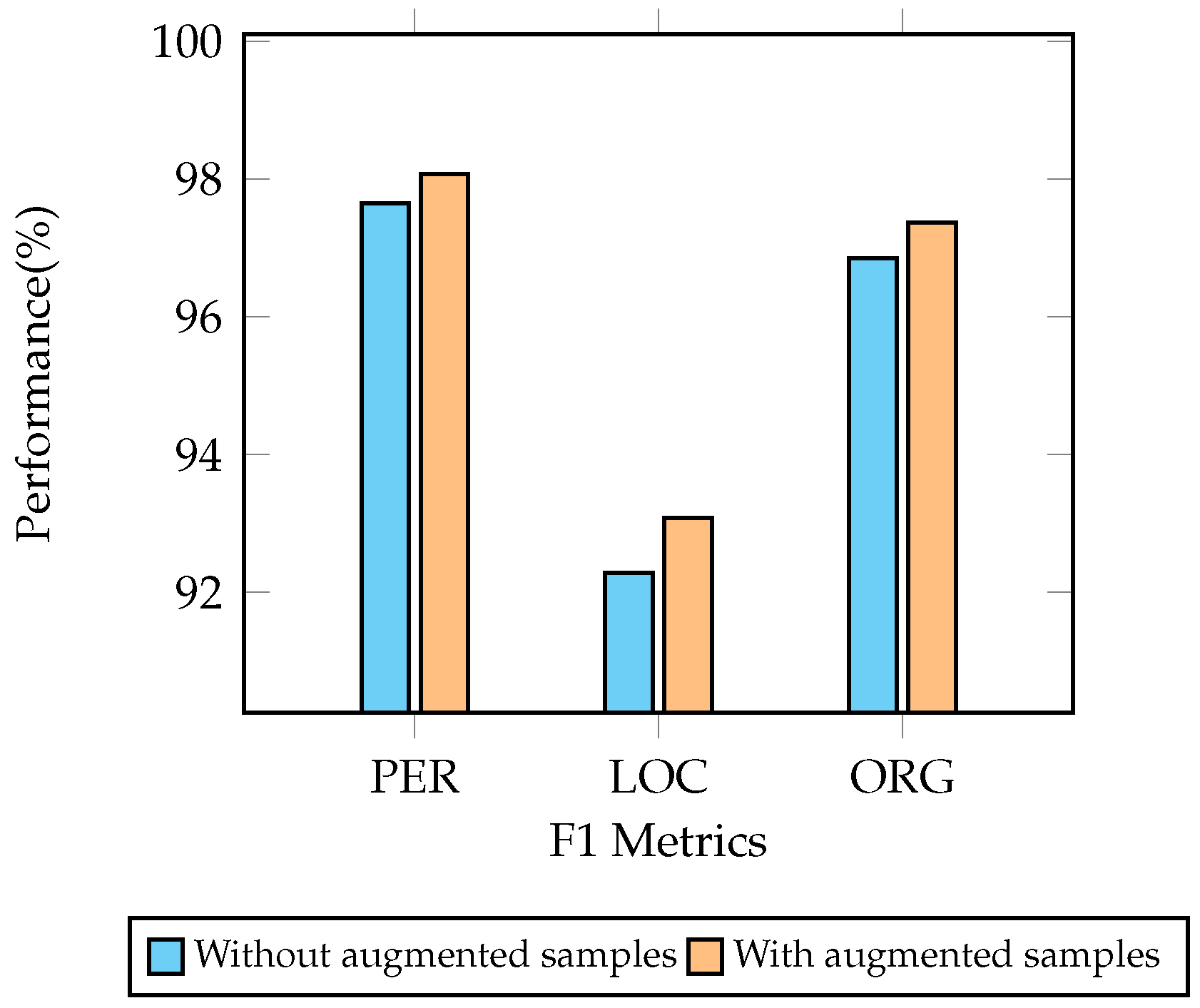
Appendix A.2. Efficiency Evaluation of Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | OntoNotes 4.0 (Chinese) | MSRA | ||
|---|---|---|---|---|
| Training | Inference | Training | Inference | |
| BERT + CRF | 58.3 (×1.0) | 5.2 (×1.0) | 167.8 (×1.0) | 5.1 (×1.0) |
| BERT − MRC | 258.1 (×4.4) | 19.7 (×3.8) | 626.7 (×3.7) | 14.5 (×2.8) |
| LGDA | 116.4 (×2.0) | 5.8 (×1.1) | 314.4 (×1.87) | 5.4 (×1.1) |
Appendix A.3. Impact of Pre-Trained Language Model
| Model | OntoNotes 4.0 (Chinese) | MSRA | ||||
|---|---|---|---|---|---|---|
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | |
| LEAR | 81.23 | 83.07 | 82.14 | 96.18 | 95.42 | 95.82 |
| E-strPron | 84.90 | 77.96 | 81.28 | 96.18 | 95.94 | 96.06 |
| LGDA (with RoBERTa) | 81.72 | 82.67 | 82.19 | 96.52 | 96.21 | 96.36 |
| LGDA (with BERT) | 81.67 | 82.59 | 82.13 | 96.40 | 96.19 | 96.29 |
References
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Dai, X.; Adel, H. An analysis of simple data augmentation for named entity recognition. arXiv 2020, arXiv:2010.11683. [Google Scholar]
- Min, J.; McCoy, R.T.; Das, D.; Pitler, E.; Linzen, T. Syntactic data augmentation increases robustness to inference heuristics. arXiv 2020, arXiv:2004.11999. [Google Scholar]
- Gao, F.; Zhu, J.; Wu, L.; Xia, Y.; Qin, T.; Cheng, X.; Zhou, W.; Liu, T.Y. Soft contextual data augmentation for neural machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5539–5544. [Google Scholar]
- Hou, Y.; Liu, Y.; Che, W.; Liu, T. Sequence-to-sequence data augmentation for dialogue language understanding. arXiv 2018, arXiv:1807.01554. [Google Scholar]
- Zhou, R.; Li, X.; He, R.; Bing, L.; Cambria, E.; Si, L.; Miao, C. MELM: Data augmentation with masked entity language modeling for low-resource NER. arXiv 2021, arXiv:2108.13655. [Google Scholar]
- Ma, J.; Ballesteros, M.; Doss, S.; Anubhai, R.; Mallya, S.; Al-Onaizan, Y.; Roth, D. Label semantics for few shot named entity recognition. arXiv 2022, arXiv:2203.08985. [Google Scholar]
- Yang, P.; Cong, X.; Sun, Z.; Liu, X. Enhanced language representation with label knowledge for span extraction. arXiv 2021, arXiv:2111.00884. [Google Scholar]
- Lai, P.; Ye, F.; Zhang, L.; Chen, Z.; Fu, Y.; Wu, Y.; Wang, Y. PCBERT: Parent and Child BERT for Chinese Few-shot NER. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2199–2209. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER using lattice LSTM. arXiv 2018, arXiv:1805.02023. [Google Scholar]
- Meng, Y.; Wu, W.; Wang, F.; Li, X.; Nie, P.; Yin, F.; Li, M.; Han, Q.; Sun, X.; Li, J. Glyce: Glyph-vectors for chinese character representations. Adv. Neural Inf. Process. Syst. 2019, 32, 2746–2757. [Google Scholar]
- Liu, W.; Fu, X.; Zhang, Y.; Xiao, W. Lexicon enhanced Chinese sequence labeling using BERT adapter. arXiv 2021, arXiv:2105.07148. [Google Scholar]
- Li, X.; Yan, H.; Qiu, X.; Huang, X. FLAT: Chinese NER using flat-lattice transformer. arXiv 2020, arXiv:2004.11795. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A unified MRC framework for named entity recognition. arXiv 2019, arXiv:1910.11476. [Google Scholar]
- Ji, W.; Zhang, Y.; Zhou, G.; Wang, X. Research on Named Entity Recognition in Improved transformer with R-Drop structure. arXiv 2023, arXiv:2306.08315. [Google Scholar]
- Liu, T.; Gao, J.; Ni, W.; Zeng, Q. A Multi-Granularity Word Fusion Method for Chinese NER. Appl. Sci. 2023, 13, 2789. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Zhou, Q. E-strPron: Chinese named entity recognition based on enhanced structure and pronunciation features. In Proceedings of the 2024 43rd Chinese Control Conference (CCC), Kunming, China, 28–31 July 2024. [Google Scholar]
- Jia, C.; Shi, Y.; Yang, Q.; Zhang, Y. Entity enhanced BERT pre-training for Chinese NER. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6384–6396. [Google Scholar]
- Wu, S.; Song, X.; Feng, Z. MECT: Multi-metadata embedding based cross-transformer for Chinese named entity recognition. arXiv 2021, arXiv:2107.05418. [Google Scholar]
- Zhou, X.; Zhang, X.; Tao, C.; Chen, J.; Xu, B.; Wang, W.; Xiao, J. Multi-Grained Knowledge Distillation for Named Entity Recognition. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5704–5716. [Google Scholar]
- Lee, D.H.; Kadakia, A.; Tan, K.; Agarwal, M.; Feng, X.; Shibuya, T.; Mitani, R.; Sekiya, T.; Pujara, J.; Ren, X. Good examples make A faster learner: Simple demonstration-based learning for low-resource NER. arXiv 2021, arXiv:2110.08454. [Google Scholar]
- Li, D.; Hu, B.; Chen, Q. Prompt-based Text Entailment for Low-Resource Named Entity Recognition. arXiv 2022, arXiv:2211.03039. [Google Scholar]
- Park, E.; Jeon, D.; Kim, S.; Kang, I.; Na, S.H. LM-BFF-MS: Improving Few-Shot Fine-tuning of Language Models based on Multiple Soft Demonstration Memory. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 310–317. [Google Scholar]
- Ma, R.; Zhou, X.; Gui, T.; Tan, Y.; Zhang, Q.; Huang, X. Template-free prompt tuning for few-shot NER. arXiv 2021, arXiv:2109.13532. [Google Scholar]
- Li, X.; Zhang, H.; Zhou, X.H. Chinese clinical named entity recognition with variant neural structures based on BERT methods. J. Biomed. Inform. 2020, 107, 103422. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Li, S.; Wang, Y.; Xu, L. Named Entity Recognition of BERT-BiLSTM-CRF Combined with Self-attention. In Proceedings of the International Conference on Web Information Systems and Applications, Chengdu, China, 1–3 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 556–564. [Google Scholar]
- Ji, B.; Li, S.; Gan, S.; Yu, J.; Ma, J.; Liu, H. Few-shot Named Entity Recognition with Entity-level Prototypical Network Enhanced by Dispersedly Distributed Prototypes. arXiv 2022, arXiv:2208.08023. [Google Scholar]
- Kumar, V.; Choudhary, A.; Cho, E. Data augmentation using pre-trained transformer models. arXiv 2020, arXiv:2003.02245. [Google Scholar]
- Liu, L.; Ding, B.; Bing, L.; Joty, S.; Si, L.; Miao, C. MulDA: A multilingual data augmentation framework for low-resource cross-lingual NER. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual, 1–6 August 2021; pp. 5834–5846. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]


| Label | Annotation |
|---|---|
| PER (Person) | Names and fictional characters |
| LOC (Location) | Natural landscape locations such as mountain ranges, rivers, etc. |
| ORG (Organization) | Organizations, including companies, government parties, schools, governments, and news agencies |
| GPE (Geo-Political Entity) | Geopolitical entities divided by geographical location, including countries, cities, and towns |
| Dataset | Tr Set | Val Set | Test Set |
|---|---|---|---|
| OntoNotes 4.0 (Chinese) | 15,650 | 4301 | 4346 |
| MSRA | 41,729 | 4637 | 4366 |
| Category | Tr Set | Val Set | Test Set |
|---|---|---|---|
| PER | 4391 | 1652 | 1864 |
| LOC | 928 | 483 | 491 |
| GPE | 4960 | 3166 | 3452 |
| ORG | 3088 | 1649 | 1877 |
| Totally | 13,367 | 6950 | 7684 |
| Category | Tr Set | Val Set | Test Set |
|---|---|---|---|
| PER | 16,105 | 1510 | 1973 |
| LOC | 3486 | 1657 | 2877 |
| ORG | 19,481 | 1090 | 1331 |
| Totally | 70,446 | 4257 | 6181 |
| Model | OntoNotes 4.0 (Chinese) | MSRA | ||||
|---|---|---|---|---|---|---|
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | |
| BERT + CRF | 72.84 | 59.72 | 65.63 | 90.57 | 83.06 | 86.65 |
| LatticeLSTM | 76.35 | 71.56 | 73.88 | 93.57 | 92.79 | 93.18 |
| BERT-MRC | 82.98 | 81.25 | 82.11 | 96.18 | 95.12 | 95.75 |
| MECT | 77.57 | 76.27 | 76.92 | 94.55 | 94.09 | 94.32 |
| Multi-grained KD | 77.94 | 74.23 | 76.05 | 93.90 | 92.11 | 92.99 |
| LEAR | 81.23 | 83.07 | 82.14 | 96.18 | 95.42 | 95.82 |
| PCBERT | - | - | 81.57 | - | - | 89.72 |
| XLNet-Transformer-R | 79.34 | 83.16 | 81.21 | 92.07 | 94.01 | 93.03 |
| MW-NER | - | - | 81.51 | - | - | 95.47 |
| E-strPron | 84.90 | 77.96 | 81.28 | 96.18 | 95.94 | 96.06 |
| LGDA | 81.72 | 82.67 | 82.19 | 96.52 | 96.21 | 96.36 |
| Settings | Model | OntoNotes 4.0 (Chinese) | MSRA | ||||
|---|---|---|---|---|---|---|---|
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | ||
| 1-shot | LEAR | - | - | 7.28 | - | - | 0.39 |
| LGDA w/o Data Augmentation | 15.09 | 11.13 | 12.81 | 3.74 | 13.35 | 5.85 | |
| LGDA | 23.13 | 22.41 | 22.76 | 12.70 | 23.63 | 16.53 | |
| 5-shot | LEAR | - | - | 41.32 | - | - | 26.22 |
| LGDA w/o Data Augmentation | 42.41 | 46.16 | 44.20 | 39.44 | 48.13 | 43.35 | |
| LGDA | 44.88 | 63.67 | 52.65 | 50.98 | 64.08 | 56.78 | |
| Model | OntoNotes 4.0 (Chinese) | MSRA | ||||
|---|---|---|---|---|---|---|
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | |
| LGDA | 81.72 | 82.67 | 82.19 | 96.52 | 96.21 | 96.36 |
| 80.98 | 81.92 | 81.45 | 95.63 | 96.16 | 95.89 |
| 80.08 | 82.12 | 81.09 | 95.75 | 96.25 | 96.00 |
| 80.13 | 82.35 | 81.22 | 96.01 | 95.80 | 95.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, M.; Chen, H. Label-Guided Data Augmentation for Chinese Named Entity Recognition. Appl. Sci. 2025, 15, 2521. https://doi.org/10.3390/app15052521
Jiang M, Chen H. Label-Guided Data Augmentation for Chinese Named Entity Recognition. Applied Sciences. 2025; 15(5):2521. https://doi.org/10.3390/app15052521
Chicago/Turabian StyleJiang, Miao, and Honghui Chen. 2025. "Label-Guided Data Augmentation for Chinese Named Entity Recognition" Applied Sciences 15, no. 5: 2521. https://doi.org/10.3390/app15052521
APA StyleJiang, M., & Chen, H. (2025). Label-Guided Data Augmentation for Chinese Named Entity Recognition. Applied Sciences, 15(5), 2521. https://doi.org/10.3390/app15052521