Named Entity Recognition in the Field of Small Sample Electric Submersible Pump Based on FLAT


Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Related Work on NER
2.2. A Method for NER in the Field of Small Sample ESP Based on FLAT
2.2.1. A Chinese Word Segmentation Method for ESP Domain Based on Dictionary Matching with Semantic Analysis
2.2.2. Char-CNN Character Embedding Method and BERT Word Embedding
2.2.3. FLAT Layer
2.2.4. CRF Layer
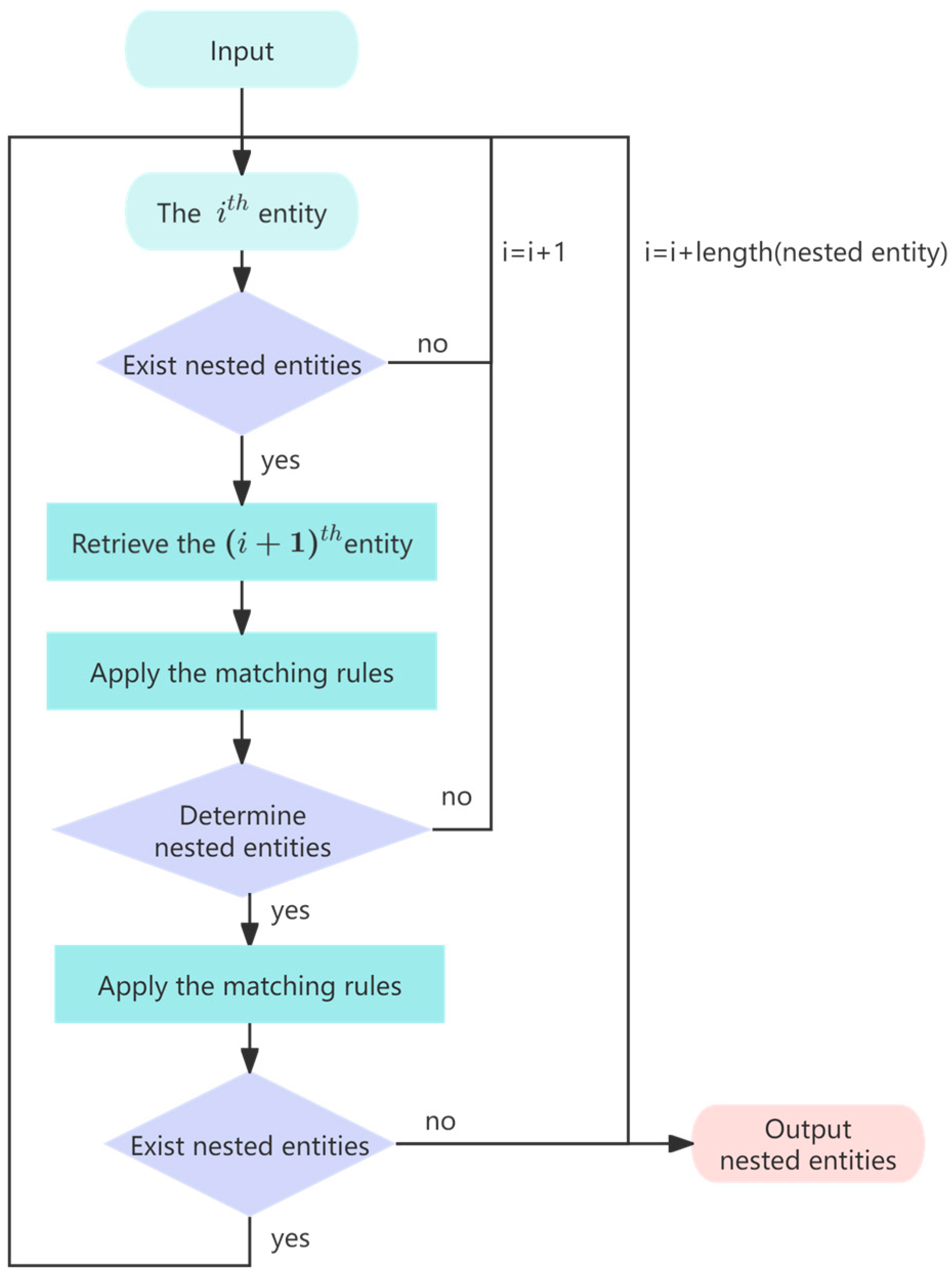
2.2.5. Nested Entity Matching Rule Mechanism
3. Named Entity Recognition Experiment
3.1. Experimental Setup
3.1.1. Experimental Corpus
3.1.2. Experimental Evaluation Criteria
3.1.3. Model Parameters
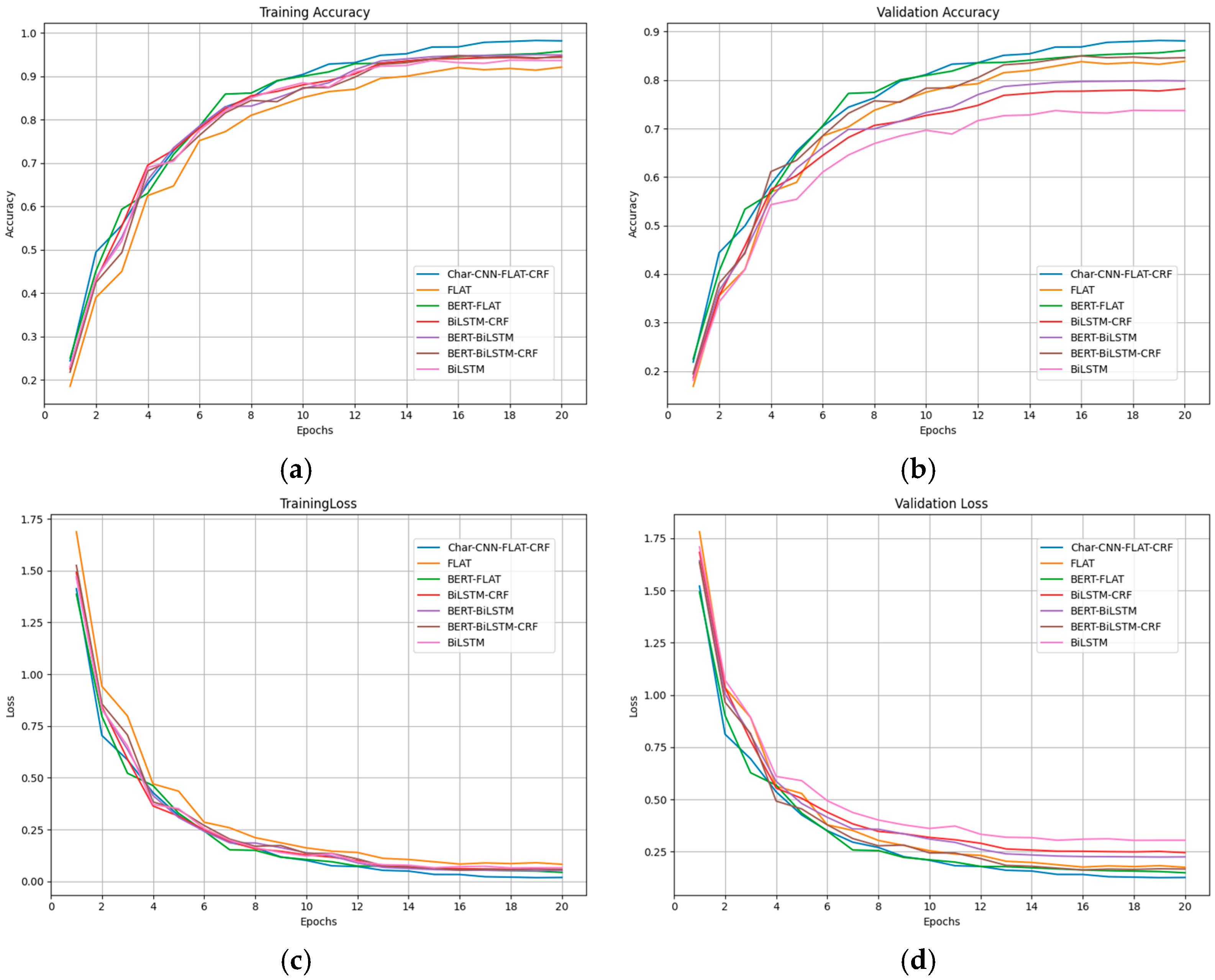
3.2. Results and Analysis
3.2.1. Ablation Study
3.2.2. Comparison Experiment
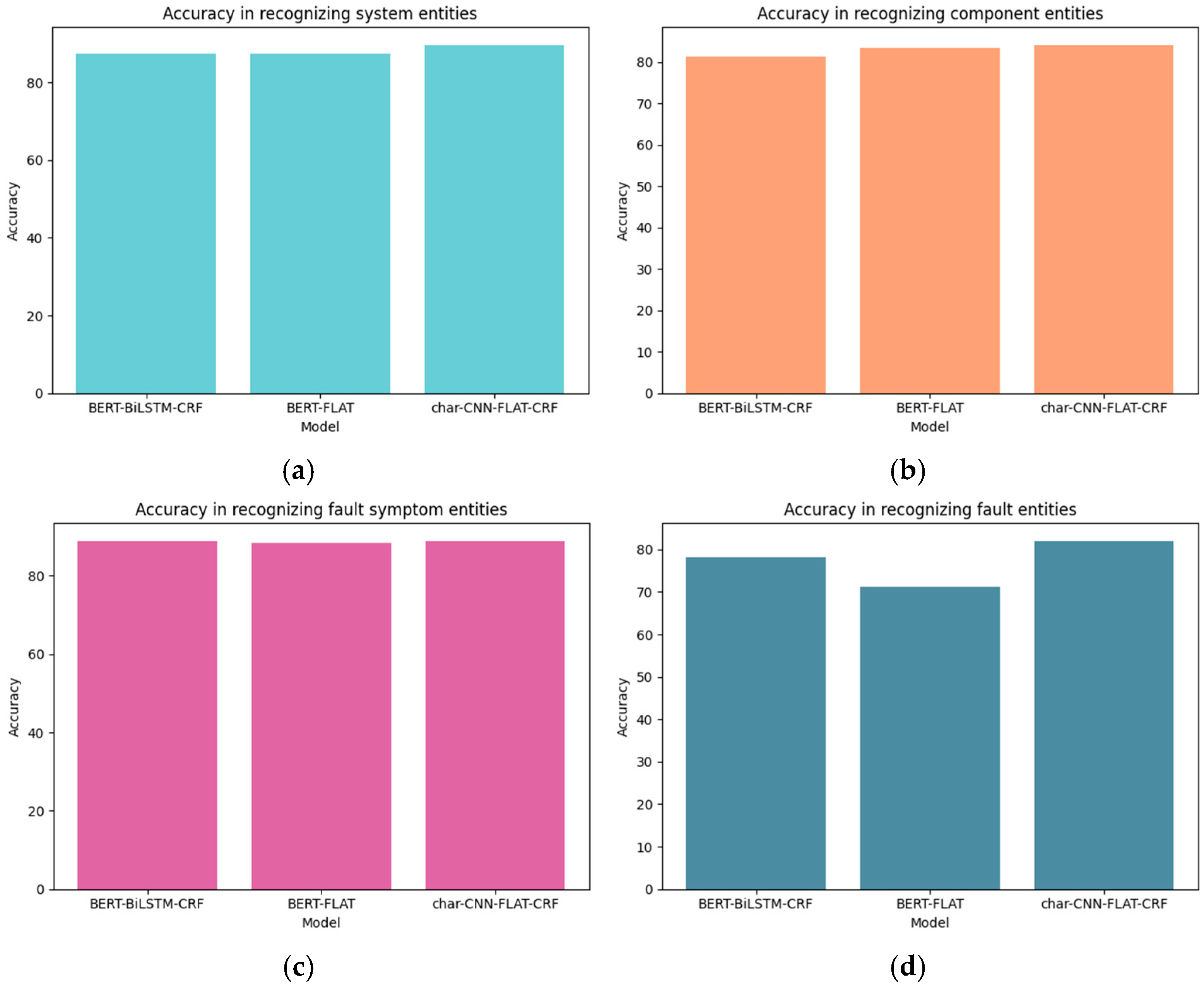
3.2.3. Rare Word Recognition Capability Analysis
4. Discussion
4.1. Discussion on Comparison Experiment
4.2. Discussion on the Recognition Capability of Rare Words and Nested Entities
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ESP | Electric submersible pump |
| NER | Named entity recognition |
| char-CNN | Character-level convolutional neural network |
| FLAT | Flat-Lattice Transformer |
| BERT | Bidirectional Encoder Representations from Transformers |
| BiLSTM | Bidirectional Long Short-Term Memory |
| HMM | Hidden Markov Model |
| SVM | Support Vector Machine |
| CRF | Conditional Random Field |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| BiLSTM-CRF | Bidirectional Long Short-Term Memory networks with Conditional Random Fields |
| GPT | Generative Pre-trained Transformer |
| CFG | Context-Free Grammar |
References
- Wang, Y.; Yao, R.; Zhao, K.; Wu, P.; Chen, W. Robotics Classification of Domain Knowledge Based on a Knowledge Graph for Home Service Robot Applications. Appl. Sci. 2024, 14, 11553. [Google Scholar] [CrossRef]
- Kalu-Ulu, T.C.; Okon, A.N.; Appah, D. Effective Marginal Field Production Using Electric Submersible Pump: Niger Delta Case Study. Asian J. Adv. Res. Rep. 2024, 18, 53–72. [Google Scholar]
- Yongjie, W.; Liang, M. Heavy oil development: Shengli Oilfield. Geogr. Res. Bull. 2022, 1, 78–80. [Google Scholar]
- Chen, Y.; Yan, Y.; Zhao, C.; Qi, Z.; Chen, Z. Energy—Oil and Gas Research; Findings from Sinopec Group Provide New Insights into Oil and Gas Research (Gini Coefficient: An Effective Way To Evaluate Inflow Profile Equilibrium of Horizontal Wells In Shengli Oil Field). Energy Wkly. News. 2020, 195, 35–38. [Google Scholar]
- Yang, J.; Wang, S.; Zheng, C.; Feng, G.; Du, G.; Tan, C.; Ma, D. Fault Diagnosis Method and Application of ESP Well Based on SPC Rules and Real-Time Data Fusion. Math. Probl. Eng. 2022, 2022, 8497299. [Google Scholar] [CrossRef]
- Solovyev, G.I.; Lapik, I.O.; Govorkov, A.D. Hydrodynamics of transient processes in a well with an electric submersible pump. Bulletin of the Tomsk Polytechnic University. Geo Assets Eng. 2023, 334, 50–60. [Google Scholar]
- Wei, Q.; Tan, C.; Gao, X.; Guan, X.; Shi, X. Research on early warning model of electric submersible pump wells failure based on the fusion of physical constraints and data-driven approach. Geoenergy Sci. Eng. 2024, 233. [Google Scholar] [CrossRef]
- Liu, X.F.; Liu, C.H.; Zheng, Y.; Yu, J.F.; Zhou, W.; Wang, M.X.; Liu, P.; Zhou, Y.F. Numerical simulation of the electromagnetic torques of PMSM with two-way magneto-mechanical coupling and nonuniform spline clearance in electric submersible pumping wells. Pet. Sci. 2024, 21, 4417–4426. [Google Scholar] [CrossRef]
- Bogdanović, M.; Gligorijević, M.F.; Kocić, J.; Stoimenov, L. Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT. Appl. Sci. 2025, 15, 615. [Google Scholar] [CrossRef]
- Jazuli, A.; Widowati; Kusumaningrum, R. Optimizing Aspect-Based Sentiment Analysis Using BERT for Comprehensive Analysis of Indonesian Student Feedback. Appl. Sci. 2024, 15, 172. [Google Scholar] [CrossRef]
- Yadav, A.; Khan, A.F.; Singh, V. A Multi-Architecture Approach for Offensive Language Identification Combining Classical Natural Language Processing and BERT-Variant Models. Appl. Sci. 2024, 14, 11206. [Google Scholar] [CrossRef]
- Melhem, Y.W.; Abdi, A.; Meziane, F. Deep Learning Classification of Traffic-Related Tweets: An Advanced Framework Using Deep Learning for Contextual Understanding and Traffic-Related Short Text Classification. Appl. Sci. 2024, 14, 11009. [Google Scholar] [CrossRef]
- Xiong, Y.; Chen, G.; Cao, J. Research on Public Service Request Text Classification Based on BERT-BiLSTM-CNN Feature Fusion. Appl. Sci. 2024, 14, 6282. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y.; Qi, H.; Wang, D.; Huang, A. A complex history browsing text categorization method with improved BERT embedding layer. Appl. Intell. 2025, 55, 398. [Google Scholar] [CrossRef]
- Chen, S.; Lang, B.; Chen, Y.; Xie, C. Detection of Algorithmically Generated Malicious Domain Names with Feature Fusion of Meaningful Word Segmentation and N-Gram Sequences. Appl. Sci. 2023, 13, 4406. [Google Scholar] [CrossRef]
- Tang, Y.; Deng, J.; Guo, Z. Candidate Term Boundary Conflict Reduction Method for Chinese Geological Text Segmentation. Appl. Sci. 2023, 13, 4516. [Google Scholar] [CrossRef]
- Tsang, Y.K.; Yan, M.; Pan, J.; Chan, M.Y. A corpus of Chinese word segmentation agreement. Behav. Res. Methods 2024, 57, 25. [Google Scholar] [CrossRef]
- Xu, Z.; Xiang, Y. Improving Chinese word segmentation with character–lexicon class attention. Neural Comput. Appl. 2024; prepublish, 1–11. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, K.; Tong, R.; Cai, C.; Chen, D.; Wu, X. A Flat-Span Contrastive Learning Method for Nested Named Entity Recognition. Int. J. Asian Lang. Process. 2025, prepublish. [Google Scholar] [CrossRef]
- Hou, Z.; Du, Y.; Li, W.; Hu, J.; Li, H.; Li, X.; Chen, X. C-BDCLSTM: A false emotion recognition model in micro blogs combined Char-CNN with bidirectional dilated convolutional LSTM. Appl. Soft Comput. J. 2022, 130, 109659. [Google Scholar] [CrossRef]
- Huang, J.; Ding, R.; Wu, X.; Chen, S.; Zhang, J.; Liu, L.; Zheng, Y. WERECE: An Unsupervised Method for Educational Concept Extraction Based on Word Embedding Refinement. Appl. Sci. 2023, 13, 12307. [Google Scholar] [CrossRef]
- Zhang, H.; Dang, Y.; Zhang, Y.; Liang, S.; Liu, J.; Ji, L. Chinese nested entity recognition method for the finance domain based on heterogeneous graph network. Inf. Process. Manag. 2024, 61, 103812. [Google Scholar] [CrossRef]
- Xia, Y.; Tong, Z.; Wang, L.; Liu, Q.; Wu, S.; Zhang, X.Y. MPE[formula omitted]: Learning meta-prompt with entity-enhanced semantics for few-shot named entity recognition. Neurocomputing 2025, 620, 129031. [Google Scholar] [CrossRef]
- Chen, J.; Su, L.; Li, Y.; Lin, M.; Peng, Y.; Sun, C. A multimodal approach for few-shot biomedical named entity recognition in low-resource languages. J. Biomed. Inform. 2024, 161, 104754. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Lai, P.; Fang, R.; Fu, Y.; Ye, F.; Wang, Y. FE-CFNER: Feature Enhancement-based approach for Chinese Few-shot Named Entity Recognition. Comput. Speech Lang. 2025, 90, 101730. [Google Scholar] [CrossRef]
- Ren, Z.; Qin, X.; Ran, W. SLNER: Chinese Few-Shot Named Entity Recognition with Enhanced Span and Label Semantics. Appl. Sci. 2023, 13, 8609. [Google Scholar] [CrossRef]
- Yang, M.; Liu, S.; Chen, K.; Zhang, H.; Zhao, E.; Zhao, T. A Hierarchical Clustering Approach to Fuzzy Semantic Representation of Rare Words in Neural Machine Translation. IEEE Trans. Fuzzy Syst. 2020, 28, 992–1002. [Google Scholar] [CrossRef]
- Khassanov, Y.; Zeng, Z.; Pham, V.T.; Xu, H.; Chng, E.S. Enriching Rare Word Representations in Neural Language Models by Embedding Matrix Augmentation. arXiv 2019, arXiv:1904.0379. [Google Scholar]
- Park, Y.; Son, G.; Rho, M. Biomedical Flat and Nested Named Entity Recognition: Methods, Challenges, and Advances. Appl. Sci. 2024, 14, 9302. [Google Scholar] [CrossRef]
- Zia, G.A.; Sharifi, A. ZHMM-Based Dari Named Entity Recognition for Information Extraction. In CS & IT Conference Proceedings; Computer Science & Information Technology (CS & IT): Cambridge, MA, USA, 2019; Volume 9. [Google Scholar]
- Suganda, A.G.; Krisna, B.N. Six classes named entity recognition for mapping location of Indonesia natural disasters from twitter data. Int. J. Intell. Comput. Cybern. 2024, 17, 395–414. [Google Scholar]
- Fang, T.; Yang, Y.; Zhou, L. Enhanced Precision in Chinese Medical Text Mining Using the ALBERT+Bi-LSTM+CRF Model. Appl. Sci. 2024, 14, 7999. [Google Scholar] [CrossRef]
- Jayakumar, H.; Krishnakumar, M.S.; Peddagopu, V.V.V.; Sridhar, R. RNN based question answer generation and ranking for financial documents using financial NER. Sādhanā 2020, 45, 1–10. [Google Scholar] [CrossRef]
- Tao, G.; Zhichao, Z. LB-BMBC: MHBiaffine-CNN to Capture Span Scores with BERT Injected with Lexical Information for Chinese NER. Int. J. Comput. Intell. Syst. 2024, 17, 269. [Google Scholar]
- Smita, S.; Biswajit, P.; Deepa, G. Study of Word Embeddings for Enhanced Cyber Security Named Entity Recognition. Procedia Comput. Sci. 2023, 218, 449–460. [Google Scholar]
- Ngo, H.D.; Koopman, B. From Free-text Drug Labels to Structured Medication Terminology with BERT and GPT. AMIA Annu. Symp. Proc. 2023, 2023, 540–549. [Google Scholar] [PubMed]
- Chen, P.; Zhang, M.; Yu, X.; Li, S. Named entity recognition of Chinese electronic medical records based on a hybrid neural network and medical MC-BERT. BMC Med. Inform. Decis. Mak. 2022, 22, 315. [Google Scholar] [CrossRef]
- Zhao, H.; Xiong, W. A multi-scale embedding network for unified named entity recognition in Chinese Electronic Medical Records. Alex. Eng. J. 2024, 107, 665–674. [Google Scholar] [CrossRef]
- Li, M.; Gao, C.; Zhang, K.; Zhou, H.; Ying, J. A weakly supervised method for named entity recognition of Chinese electronic medical records. Med. Biol. Eng. Comput. 2023, 61, 2733–2743. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Wang, S.; Cao, X. Multi-Feature Fusion Method for Chinese Shipping Companies Credit Named Entity Recognition. Appl. Sci. 2023, 13, 5787. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Terminal Symbol | Derivation Result |
|---|---|
| S | NP VP |
| NP | N | N N |
| VP | V | V NP | V V |
| Rules | Example |
|---|---|
| Component + Component = Component | Stator winding |
| Component + Fault = Fault | Sand prevention malfunction |
| Fault + Fault = Fault | Underload shutdown |
| Hyperparameters | Value |
|---|---|
| Layers number in char-CNN | 7 |
| Character Embedding Dimension | 64 |
| Word Embedding Dimension | 64 |
| Learning Rate | 0.001 |
| Optimizer | AdamW |
| Weight Decay | 0.05 |
| Momentum Coefficient | 0.99 |
| Embedding Layer Dropout Rate | 0.5 |
| Input Layer Dropout Rate | 0.5 |
| Fully Connected Layer Dropout Rate | 0.3 |
| Model | Precision (%) |
|---|---|
| char-CNN-FLAT-CRF | 86.16 |
| char-CNN-FLAT | 82.33 |
| Model | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|
| FLAT | 81.89 | 89.68 | 85.61 |
| BiLSTM | 60.76 | 57.43 | 59.05 |
| BERT-FLAT | 84.13 | 89.91 | 86.92 |
| BiLSTM-CRF | 75.22 | 54.25 | 63.04 |
| BERT-BiLSTM | 79.00 | 62.38 | 69.71 |
| BERT-BiLSTM-CRF | 83.96 | 63.49 | 72.29 |
| char-CNN-FLAT-CRF | 86.16 | 88.49 | 87.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, F.; Tong, S.; Du, C.; Wan, Z.; Qiu, S. Named Entity Recognition in the Field of Small Sample Electric Submersible Pump Based on FLAT. Appl. Sci. 2025, 15, 2359. https://doi.org/10.3390/app15052359
Gong F, Tong S, Du C, Wan Z, Qiu S. Named Entity Recognition in the Field of Small Sample Electric Submersible Pump Based on FLAT. Applied Sciences. 2025; 15(5):2359. https://doi.org/10.3390/app15052359
Chicago/Turabian StyleGong, Faming, Siyuan Tong, Chengze Du, Zhenghao Wan, and Shiyu Qiu. 2025. "Named Entity Recognition in the Field of Small Sample Electric Submersible Pump Based on FLAT" Applied Sciences 15, no. 5: 2359. https://doi.org/10.3390/app15052359
APA StyleGong, F., Tong, S., Du, C., Wan, Z., & Qiu, S. (2025). Named Entity Recognition in the Field of Small Sample Electric Submersible Pump Based on FLAT. Applied Sciences, 15(5), 2359. https://doi.org/10.3390/app15052359