
A Novel Pseudo-Siamese Fusion Network for Enhancing Semantic Segmentation of Building Areas in Synthetic Aperture Radar Images


Abstract
1. Introduction
- We designed an innovative network for the segmentation of building areas in SAR images, named PSANet, which extends the existing encoder–decoder architecture. Additionally, extensive experiments were conducted across regions with diverse geographical characteristics, and the outcomes indicate the advanced performance of PSANet in building area segmentation;
- We constructed a new encoding network based on a Pseudo-Siamese structure to extract building area features from SAR images, achieving efficient feature encoding;
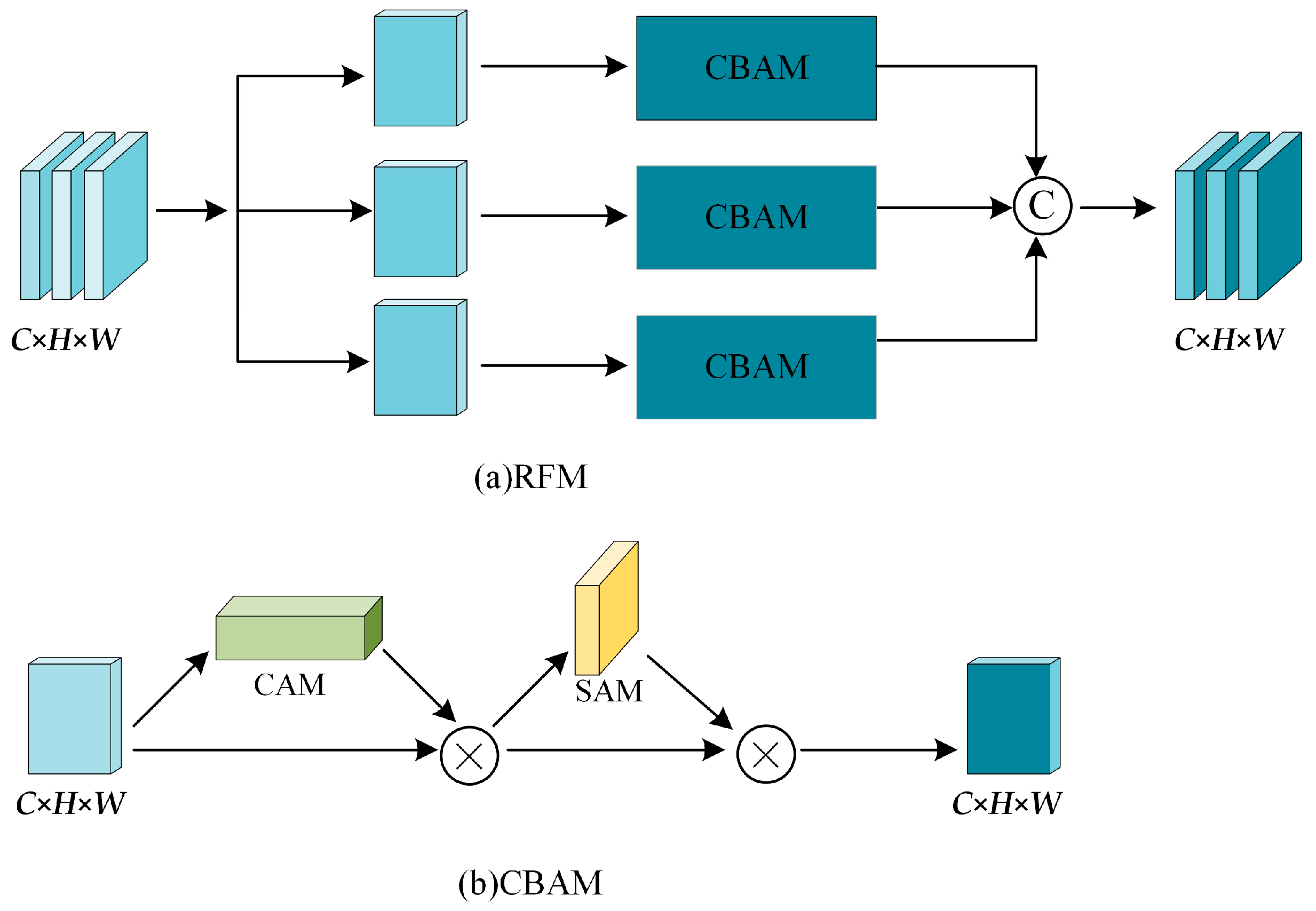
- We combined the advantages of skip connections and transposed convolutions to design a hierarchical decoder. Meanwhile, to reduce noise interference, we constructed feature refinement modules in the skip connections, thereby achieving more accurate feature reconstruction.
2. Related Work
2.1. Advances in Encoder Research for Building Area Segmentation
2.2. Advances in Decoder Research for Building Area Segmentation
3. Methods
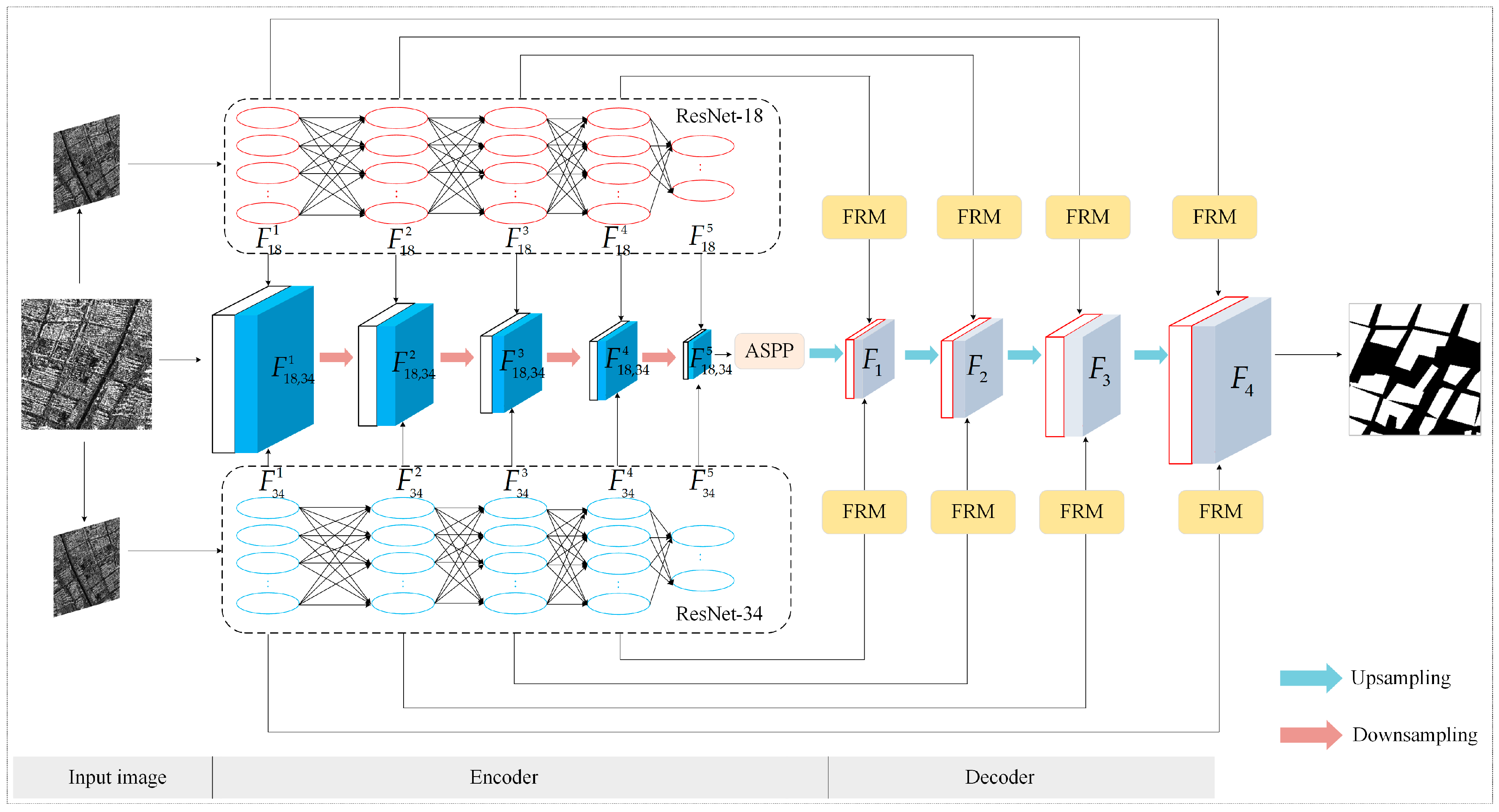
3.1. Overview of the PSANet Structure
3.2. Encoder
3.2.1. Pseudo-Siamese Fusion Encoding Network
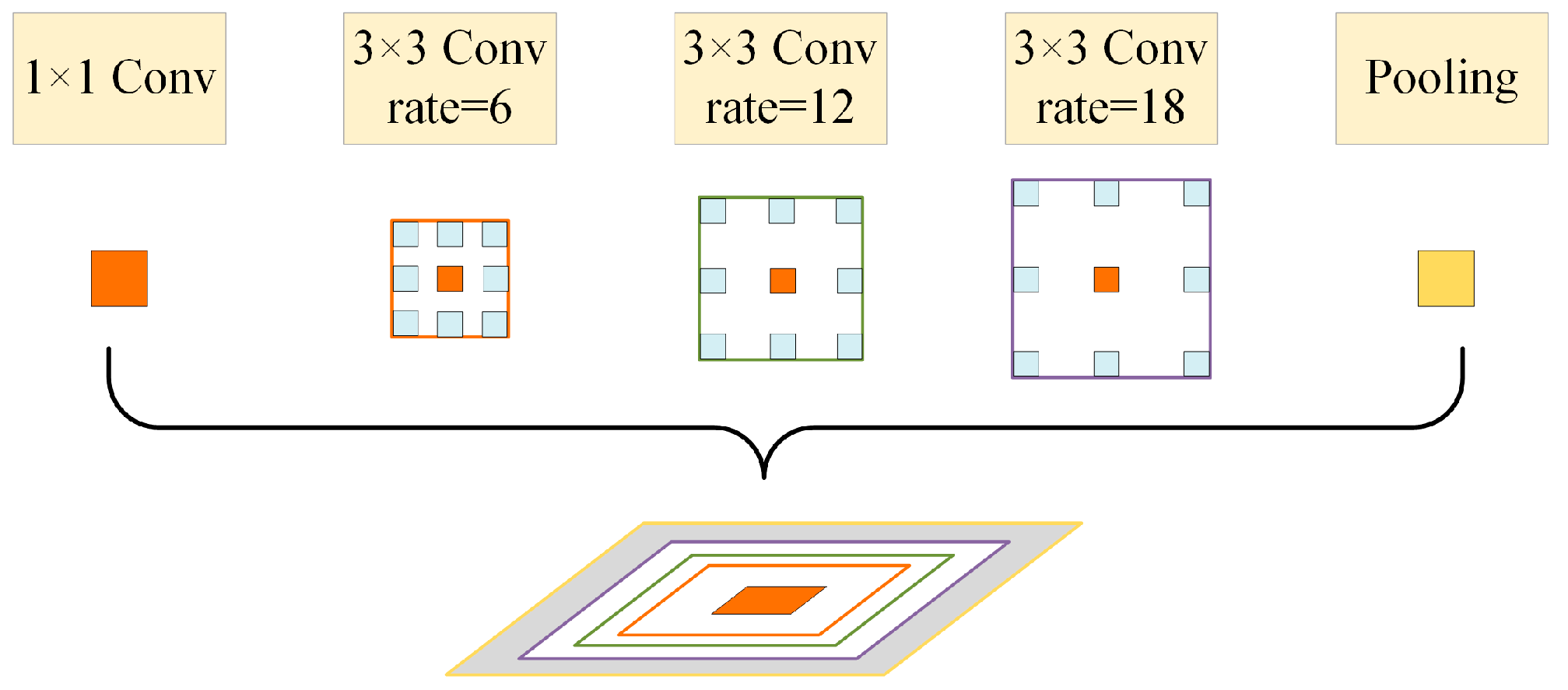
3.2.2. Atrous Spatial Pyramid Pooling
3.3. Decoder
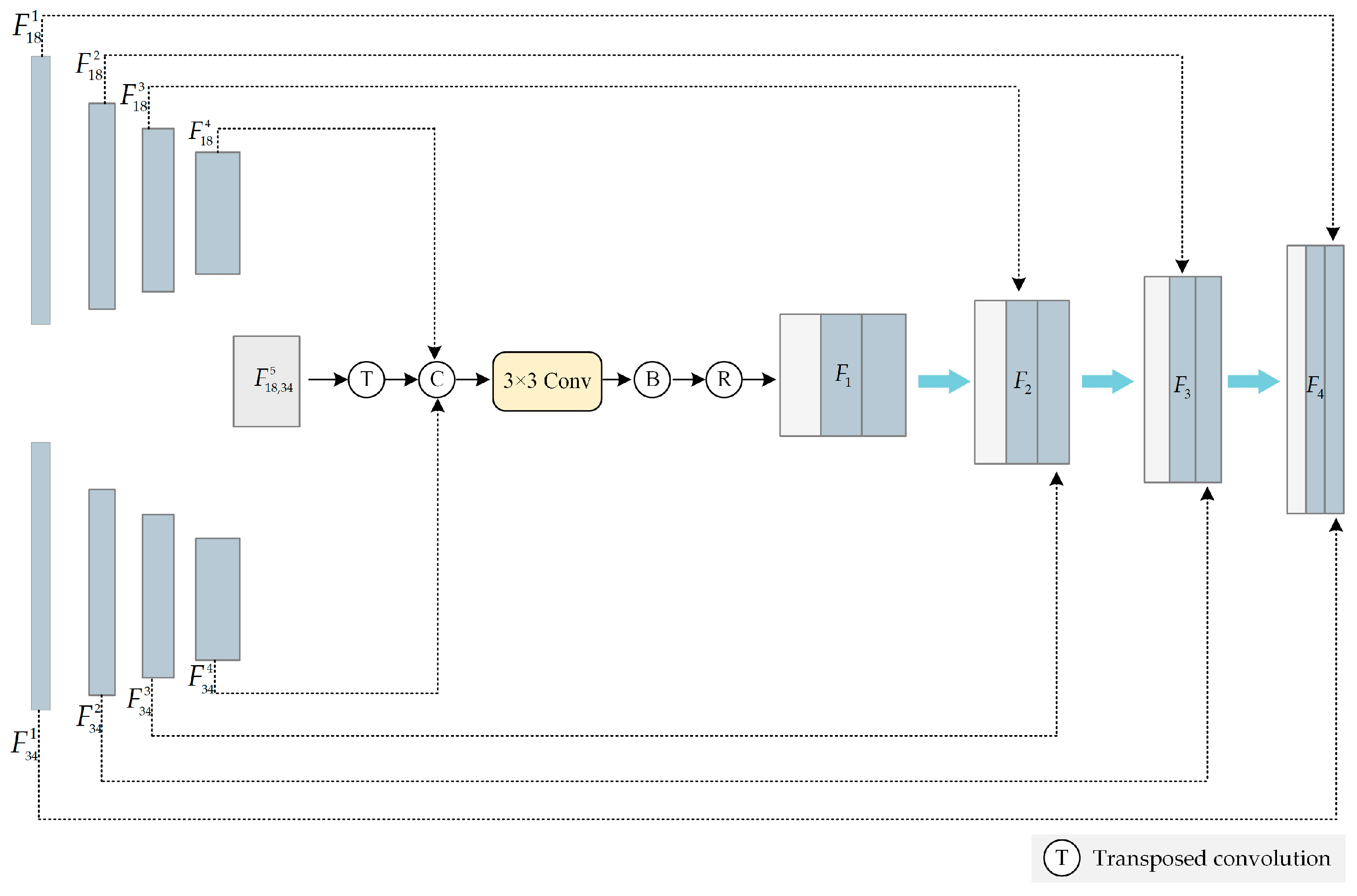
3.3.1. Hierarchical Decoder
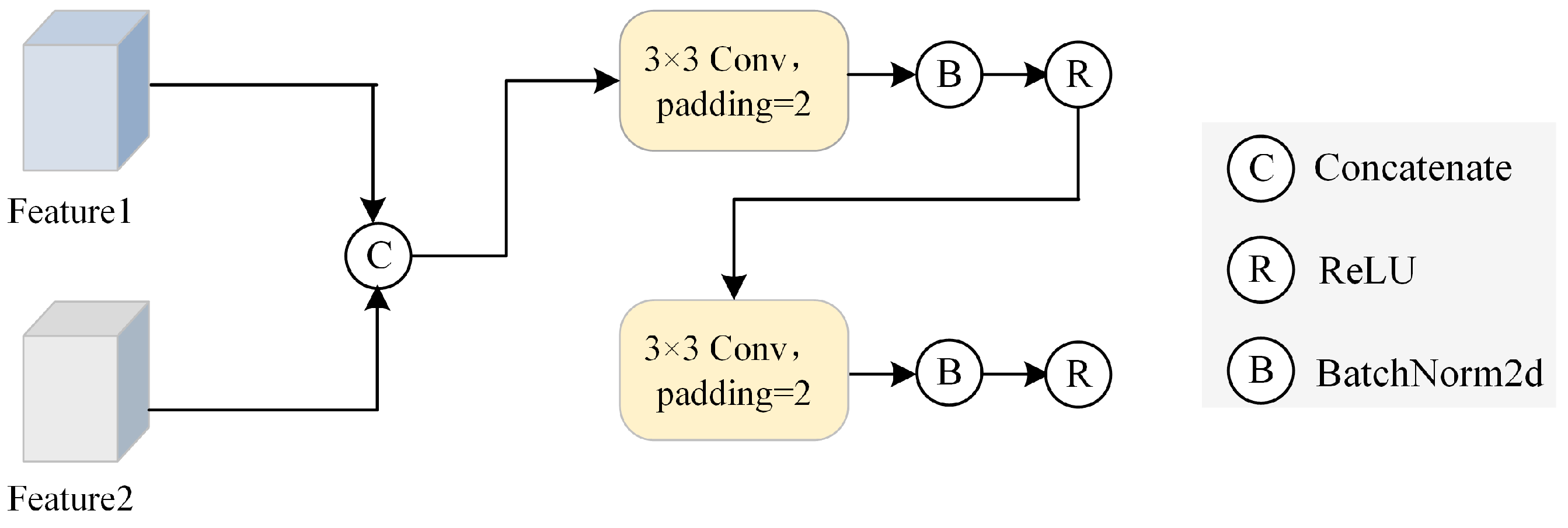
3.3.2. Feature Refinement Module
3.4. Loss Function Combining Cross-Entropy and Dice Loss
4. Experiments and Analysis
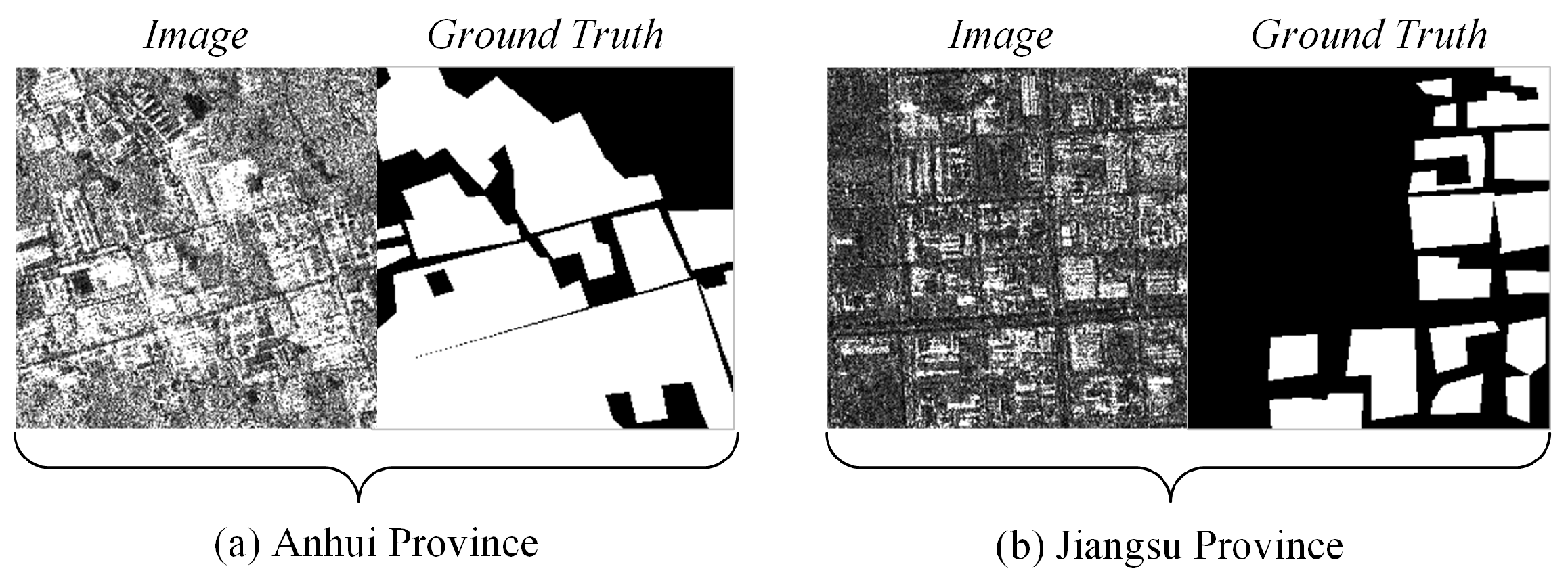
4.1. Dataset Introduction
4.2. Evaluation Metrics
4.3. Hyperparameter Setting
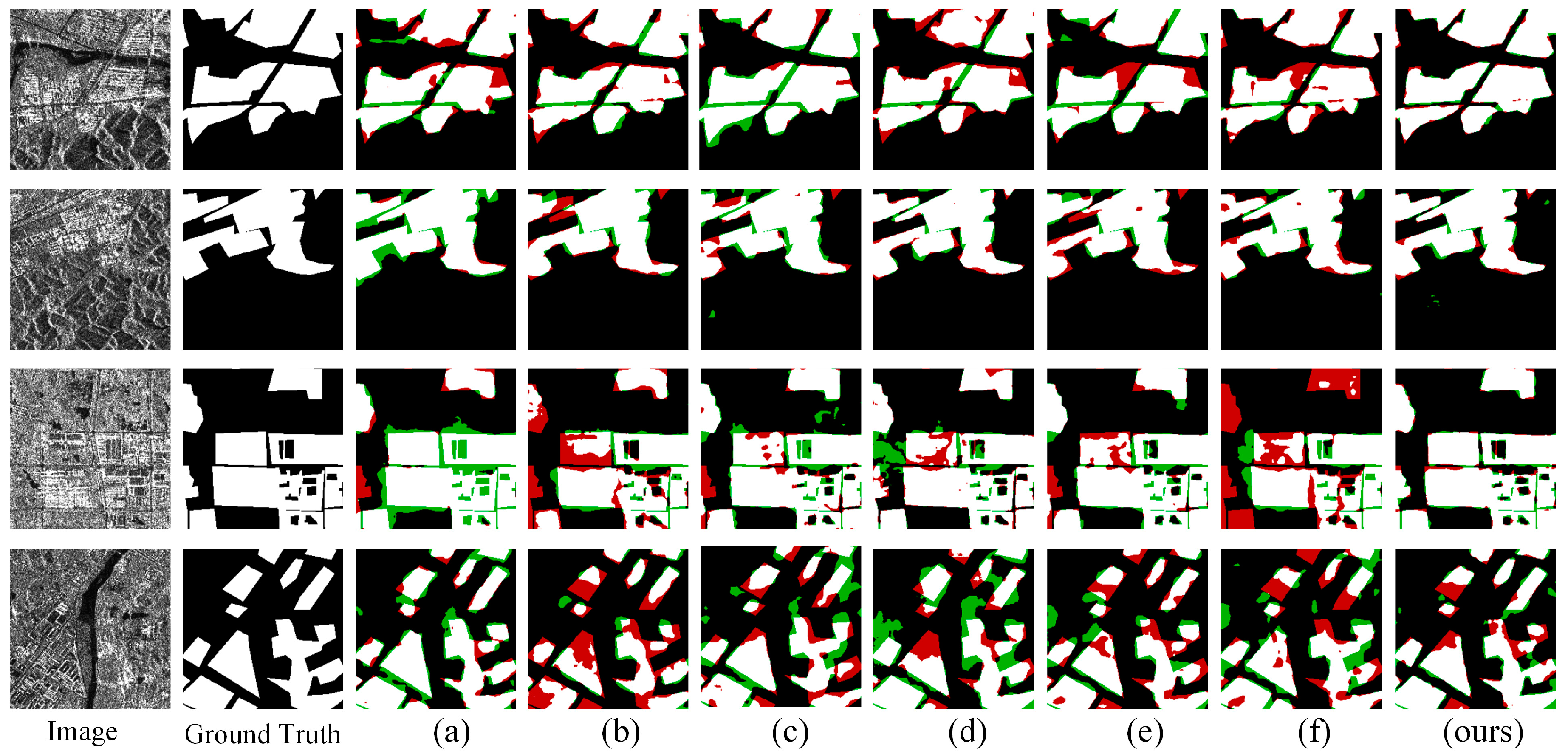
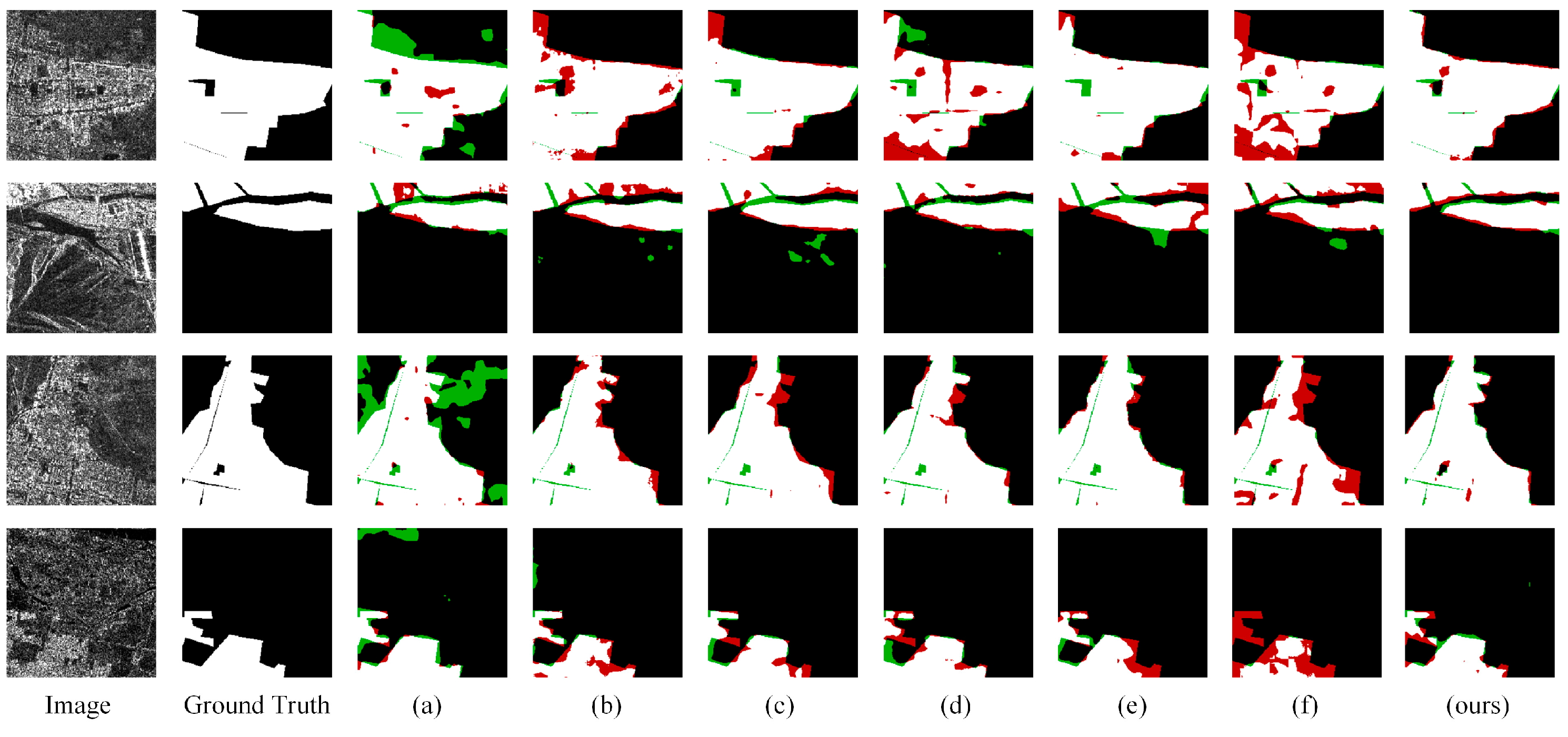
4.4. Experimental Results
4.4.1. Anhui Province
4.4.2. Jiangsu Province
4.5. Ablation Experiment
4.5.1. Effect of Different Modules
- Base: The encoder consisted solely of ResNet34, and the decoder used only a hierarchical decoder to decode the encoded features;
- Proposal 1: The encoder consisted of ResNet34 and ASPP, and the decoder used only a hierarchical decoder to decode the encoded features;
- Proposal 2: The encoder consisted of ResNet34 and ASPP, and the decoder used a hierarchical decoder and FRM to decode the encoded features;
- Proposal 3: The encoder consisted of the Pseudo-Siamese fusion encoding network and ASPP, and the decoder used a hierarchical decoder and FRM to decode the encoded features.
4.5.2. Effect of Different Encoding Networks
4.5.3. Effect of FRM
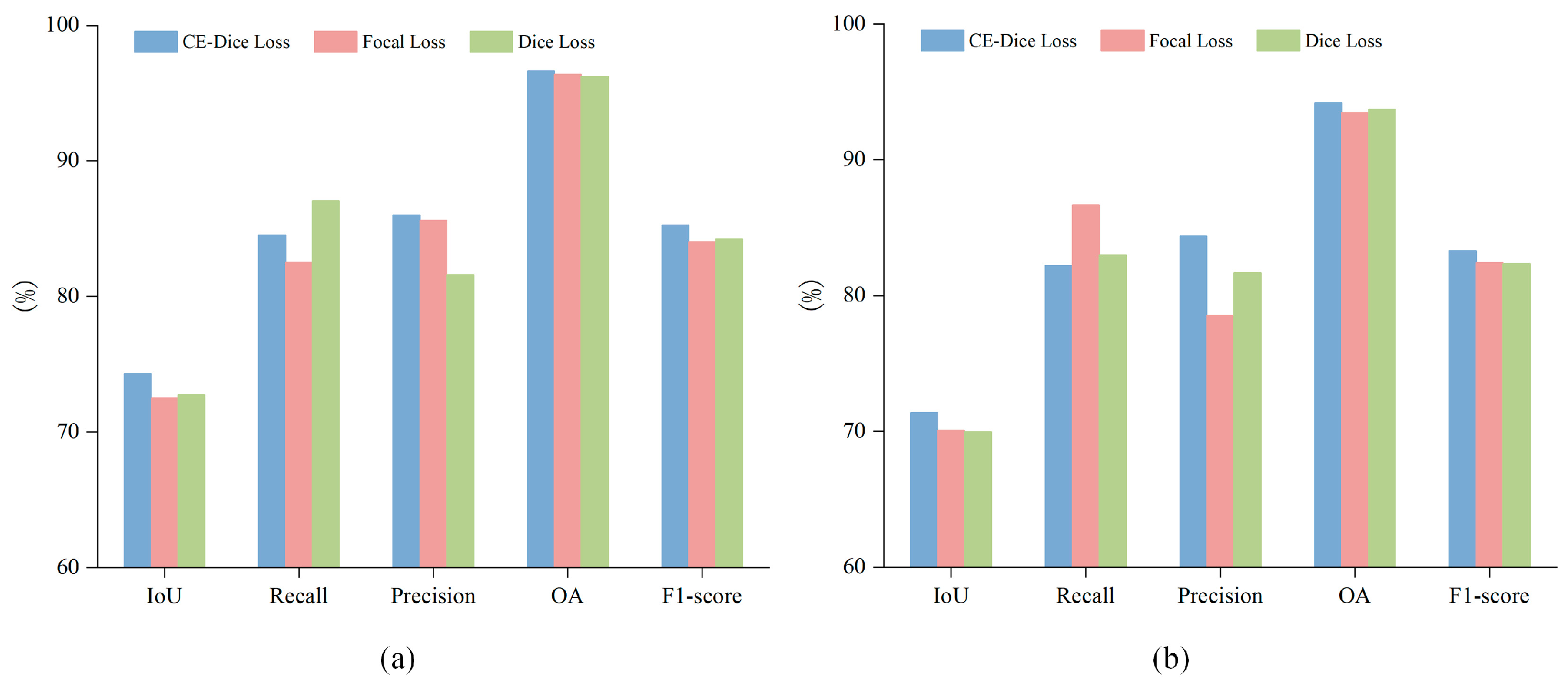
4.5.4. Effect of Loss Function
4.5.5. Model Efficiency Evaluation
4.5.6. Effect of Dilation Rate
5. Discussion
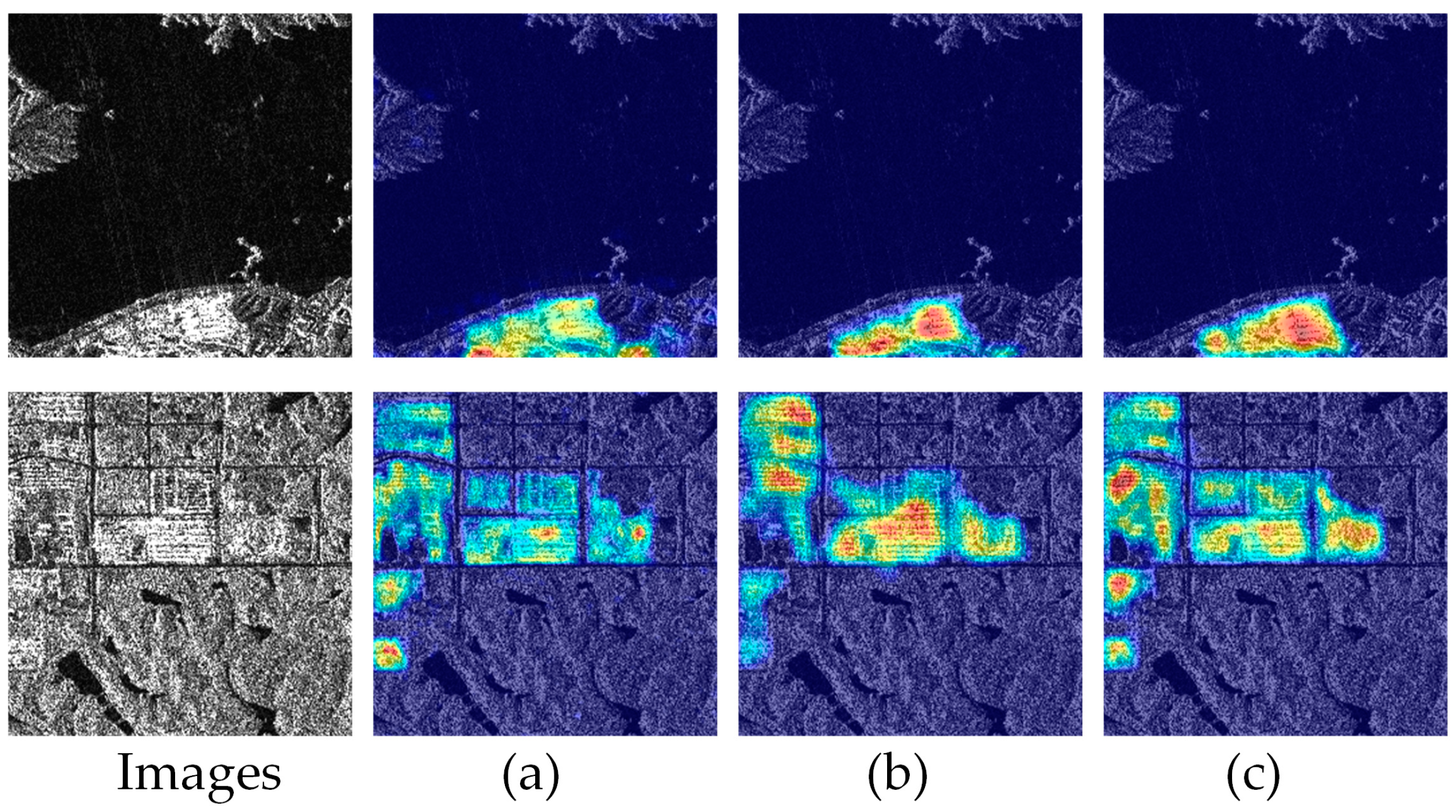
5.1. Feature Visualization Analysis
5.2. Method Applicability
5.2.1. Tibet Province
5.2.2. Taiwan Province
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, N.; Jiang, M.; Hu, X.; Su, Z.; Zhang, W.; Li, R.; Luo, J. NPSFF-Net: Enhanced Building Segmentation in Remote Sensing Images via Novel Pseudo-Siamese Feature Fusion. Remote Sens. 2024, 16, 3266. [Google Scholar] [CrossRef]
- Cao, H.; Zhang, H.; Wang, C.; Zhang, B. Operational built-up areas extraction for cities in China using Sentinel-1 SAR data. Remote Sens. 2018, 10, 874. [Google Scholar] [CrossRef]
- Sun, Y.; Hua, Y.; Mou, L.; Zhu, X.X. CG-Net: Conditional GIS-aware network for individual building segmentation in VHR SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Miura, H.; Midorikawa, S.; Matsuoka, M. Building Damage Assessment Using High-Resolution Satellite SAR Images of the 2010 Haiti Earthquake. Earthq. Spectra 2016, 32, 591–610. [Google Scholar] [CrossRef]
- Tan, C.; Chen, T.; Liu, J.; Deng, X.; Wang, H.; Ma, J. Building Extraction from Unmanned Aerial Vehicle (UAV) Data in a Landslide-Affected Scattered Mountainous Area Based on Res-Unet. Sustainability 2024, 16, 9791. [Google Scholar] [CrossRef]
- Semenzato, A.; Pappalardo, S.E.; Codato, D.; Trivelloni, U.; De Zorzi, S.; Ferrari, S.; De Marchi, M.; Massironi, M. Mapping and Monitoring Urban Environment through Sentinel-1 SAR Data: A Case Study in the Veneto Region (Italy). ISPRS Int. J. Geo Inf. 2020, 9, 375. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Sun, C.; Fan, Y. Investigation, Evaluation, and Dynamic Monitoring of Traditional Chinese Village Buildings Based on Unmanned Aerial Vehicle Images and Deep Learning Methods. Sustainability 2024, 16, 8954. [Google Scholar] [CrossRef]
- Joyce, K.E.; Samsonov, S.; Levick, S.R.; Engelbrecht, J.; Belliss, S. Mapping and monitoring geological hazards using optical, LiDAR, and synthetic aperture RADAR image data. Nat. Hazards 2014, 73, 137–163. [Google Scholar] [CrossRef]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A novel framework based on mask R-CNN and histogram thresholding for scalable segmentation of new and old rural buildings. Remote Sens. 2021, 13, 1070. [Google Scholar] [CrossRef]
- Orhei, C.; Vert, S.; Vasiu, R. A novel edge detection operator for identifying buildings in augmented reality applications. In Proceedings of the International Conference on Information and Software Technologies, Kaunas, Lithuania, October 15–17 2020; pp. 208–219. [Google Scholar]
- Liu, K.; Ma, H.; Zhang, L.; Liang, X.; Chen, D.; Liu, Y. Roof segmentation from airborne LiDAR using octree-based hybrid region growing and boundary neighborhood verification voting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2134–2146. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Z. A Study on Carbon Emission Reduction in the Entire Process of Retrofitting High-Rise Office Buildings Based on the Extraction of Typical Models. Sustainability 2024, 16, 8506. [Google Scholar] [CrossRef]
- Muhammed, E.; El-Shazly, A.; Morsy, S. Building Rooftop Extraction Using Machine Learning Algorithms for Solar Photovoltaic Potential Estimation. Sustainability 2023, 15, 11004. [Google Scholar] [CrossRef]
- Paul, A.; Mukherjee, D.P.; Das, P.; Gangopadhyay, A.; Chintha, A.R.; Kundu, S. Improved Random Forest for Classification. IEEE Trans. Image Process. 2018, 27, 4012–4024. [Google Scholar] [CrossRef]
- Emek, R.A.; Demir, N. Building Detection from Sar Images Using Unet Deep Learning Method. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 44, 215–218. [Google Scholar] [CrossRef]
- Jing, H.; Sun, X.; Wang, Z.; Chen, K.; Diao, W.; Fu, K. Fine Building Segmentation in High-Resolution SAR Images via Selective Pyramid Dilated Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6608–6623. [Google Scholar] [CrossRef]
- Peng, B.; Zhang, W.; Hu, Y.; Chu, Q.; Li, Q. LRFFNet: Large Receptive Field Feature Fusion Network for Semantic Segmentation of SAR Images in Building Areas. Remote Sens. 2022, 14, 6291. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322. [Google Scholar] [CrossRef]
- Xiao, X.; Guo, W.; Chen, R.; Hui, Y.; Wang, J.; Zhao, H. A swin transformer-based encoding booster integrated in u-shaped network for building extraction. Remote Sens. 2022, 14, 2611. [Google Scholar] [CrossRef]
- Sariturk, B.; Seker, D.Z. A residual-inception U-Net (RIU-Net) approach and comparisons with U-shaped CNN and transformer models for building segmentation from high-resolution satellite images. Sensors 2022, 22, 7624. [Google Scholar] [CrossRef] [PubMed]
- Assad, M.B.; Kiczales, R. Deep Biomedical Image Classification Using Diagonal Bilinear Interpolation and residual network. Int. J. Intell. Netw. 2020, 1, 148–156. [Google Scholar] [CrossRef]
- Gu, Y.; Ren, C.; Chen, Q.; Bai, H.; Huang, Z.; Zou, L. A Conditionally Parameterized Feature Fusion U-Net for Building Change Detection. Sustainability 2024, 16, 9232. [Google Scholar] [CrossRef]
- Xu, Q.; Chen, K.; Sun, X.; Zhang, Y.; Li, H.; Xu, G. Pseudo-Siamese capsule network for aerial remote sensing images change detection. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Z.; Sabuncu, M.R. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 8792–8802. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Che, Z.; Shen, L.; Huo, L.; Hu, C.; Wang, Y.; Lu, Y.; Bi, F. MAFF-HRNet: Multi-attention feature fusion HRNet for building segmentation in remote sensing images. Remote Sens. 2023, 15, 1382. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. Epsanet: An efficient pyramid split attention block on convolutional neural network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ross, T.-Y.; Dollár, G. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2223–2232. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU | Recall | Precision | OA | F1-Score |
|---|---|---|---|---|---|
| SegNet | 69.24 | 85.33 | 78.59 | 95.62 | 81.82 |
| DeepLabV3-Plus | 71.51 | 82.22 | 84.59 | 96.22 | 83.39 |
| MAFF-HRNet | 72.36 | 86.03 | 81.99 | 96.21 | 83.97 |
| UNet++ | 71.59 | 83.39 | 83.49 | 96.18 | 83.44 |
| SegFormer | 70.81 | 83.87 | 82.17 | 96.02 | 82.91 |
| PSPNet | 70.76 | 80.84 | 85.02 | 96.14 | 82.88 |
| PSANet (Ours) | 74.31 | 84.52 | 86.01 | 96.63 | 85.26 |
| Method | IoU | Recall | Precision | OA | F1-Score |
|---|---|---|---|---|---|
| SegNet | 65.93 | 84.73 | 74.82 | 92.27 | 79.47 |
| DeepLabV3-Plus | 68.52 | 78.04 | 84.89 | 93.67 | 81.32 |
| MAFF-HRNet | 69.75 | 82.28 | 82.08 | 93.71 | 82.18 |
| UNet++ | 69.37 | 83.18 | 80.71 | 93.52 | 81.92 |
| SegFormer | 68.58 | 81.85 | 80.88 | 93.38 | 81.36 |
| PSPNet | 67.86 | 82.72 | 79.06 | 93.08 | 80.85 |
| PSANet (Ours) | 71.38 | 82.23 | 84.39 | 94.18 | 83.31 |
| Dataset | Method | IoU | Recall | Precision | OA | F1-Score |
|---|---|---|---|---|---|---|
| Jiangsu Province | Base | 66.53 | 76.52 | 83.59 | 93.21 | 79.91 |
| Proposal 1 | 69.17 | 80.26 | 83.35 | 93.69 | 81.77 | |
| Proposal 2 | 69.51 | 81.61 | 82.42 | 93.68 | 82.02 | |
| Proposal 3 | 71.38 | 82.23 | 84.39 | 94.18 | 83.31 | |
| Anhui Province | Base | 69.54 | 79.24 | 85.02 | 95.99 | 82.03 |
| Proposal 1 | 70.99 | 81.86 | 84.25 | 96.14 | 83.04 | |
| Proposal 2 | 72.49 | 82.55 | 85.61 | 96.38 | 84.05 | |
| Proposal 3 | 74.31 | 84.52 | 86.01 | 96.63 | 85.26 |
| Dataset | Encoding Network | IoU | Recall | Precision | OA | F1-Score | Parameter (M) | Flops (G) |
|---|---|---|---|---|---|---|---|---|
| Jiangsu Province | MobileNetv3 | 67.97 | 77.98 | 84.11 | 93.51 | 80.93 | 26.59 | 26.02 |
| Xception | 68.46 | 81.96 | 80.61 | 93.34 | 81.28 | 33.11 | 21.28 | |
| ResNet50-ResNet101 | 71.49 | 86.59 | 80.38 | 94.09 | 83.37 | 207.91 | 126.62 | |
| VGG13-VGG16 | 68.26 | 79.87 | 82.43 | 93.65 | 81.13 | 46.73 | 40.19 | |
| Sum-Fusion | 70.33 | 81.92 | 83.25 | 93.89 | 82.58 | 41.75 | 36.45 | |
| Reference [1] | 70.49 | 82.25 | 83.15 | 94.12 | 82.69 | 43.29 | 38.71 | |
| Ours | 71.38 | 82.23 | 84.39 | 94.18 | 82.02 | 46.51 | 41.43 | |
| Anhui Province | MobileNetv3 | 69.41 | 79.99 | 84.01 | 95.93 | 81.94 | 26.59 | 26.02 |
| Xception | 71.85 | 81.56 | 85.79 | 96.31 | 83.62 | 33.11 | 21.28 | |
| ResNet50-ResNet101 | 72.58 | 84.79 | 83.44 | 96.11 | 84.11 | 207.91 | 126.62 | |
| VGG13-VGG16 | 71.64 | 78.98 | 88.49 | 96.19 | 83.47 | 46.73 | 40.19 | |
| Sum-Fusion | 73.24 | 83.29 | 85.84 | 96.49 | 84.55 | 41.75 | 36.45 | |
| Reference [1] | 73.81 | 84.54 | 85.32 | 96.35 | 84.92 | 43.29 | 38.71 | |
| Ours | 74.31 | 84.52 | 86.01 | 96.63 | 85.26 | 46.51 | 41.43 |
| Dataset | Strategy | IoU | Recall | Precision | OA | F1-Score |
|---|---|---|---|---|---|---|
| Jiangsu Province | CBAM | 70.85 | 82.49 | 83.38 | 94.01 | 82.94 |
| Replaced with PSAM | 70.91 | 80.55 | 85.54 | 94.16 | 82.97 | |
| Replaced with BAM | 71.14 | 81.81 | 84.51 | 94.14 | 83.12 | |
| FRM | 71.38 | 82.23 | 84.39 | 94.18 | 83.31 | |
| Anhui Province | CBAM | 73.54 | 83.61 | 85.94 | 96.53 | 84.75 |
| Replaced with PSAM | 73.44 | 82.43 | 87.06 | 96.56 | 84.68 | |
| Replaced with BAM | 74.13 | 83.81 | 86.51 | 96.61 | 85.14 | |
| FRM | 74.31 | 84.52 | 86.01 | 96.63 | 85.26 |
| Model | Parameters (M) | Flops (G) | Inference Time (s) | Training Time on Anhui Images | Training Time on Jiangsu Images | Memory (MB) |
|---|---|---|---|---|---|---|
| SegNet | 29.44 | 40.17 | 0.12 | 1 h 32 min 8 s | 2 h 35 min 17 s | 112 |
| DeepLabV3-Plus | 58.75 | 62.85 | 0.18 | 2 h 9 min 58 s | 3 h 40 min 54 s | 224 |
| MAFF-HRNet | 97.68 | 62.67 | 0.25 | 3 h 1 min 39 s | 5 h 30 min 49 s | 374 |
| UNet++ | 36.63 | 138.66 | 0.14 | 4 h 6 min 9 s | 7 h 32 min 17 s | 139 |
| SegFormer | 84.59 | 24.94 | 0.23 | 3 h 15 min 4 s | 5 h 44 min 36 s | 323 |
| PSPNet | 47.71 | 14.84 | 0.15 | 1 h 5 min 7 s | 1 h 41 min 59 s | 178 |
| PSANet (Ours) | 46.51 | 41.43 | 0.17 | 1 h 49 min 42 s | 3 h 7 min 11 s | 177 |
| Dataset | Method | IoU | Recall | Precision | OA | F1-Score |
|---|---|---|---|---|---|---|
| Jiangsu Province | ASPP-Small | 71.19 | 79.39 | 87.33 | 94.33 | 83.17 |
| ASPP-Large | 70.76 | 84.81 | 81.03 | 93.81 | 82.87 | |
| Ours | 71.38 | 82.23 | 84.39 | 94.18 | 83.31 | |
| Anhui Province | ASPP-Small | 73.77 | 80.64 | 89.64 | 96.69 | 84.89 |
| ASPP-Large | 73.35 | 84.97 | 84.29 | 96.44 | 84.63 | |
| Ours | 74.31 | 84.52 | 86.01 | 96.63 | 85.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, M.; Huang, L.; Li, S. A Novel Pseudo-Siamese Fusion Network for Enhancing Semantic Segmentation of Building Areas in Synthetic Aperture Radar Images. Appl. Sci. 2025, 15, 2339. https://doi.org/10.3390/app15052339
Liao M, Huang L, Li S. A Novel Pseudo-Siamese Fusion Network for Enhancing Semantic Segmentation of Building Areas in Synthetic Aperture Radar Images. Applied Sciences. 2025; 15(5):2339. https://doi.org/10.3390/app15052339
Chicago/Turabian StyleLiao, Mengguang, Longcheng Huang, and Shaoning Li. 2025. "A Novel Pseudo-Siamese Fusion Network for Enhancing Semantic Segmentation of Building Areas in Synthetic Aperture Radar Images" Applied Sciences 15, no. 5: 2339. https://doi.org/10.3390/app15052339
APA StyleLiao, M., Huang, L., & Li, S. (2025). A Novel Pseudo-Siamese Fusion Network for Enhancing Semantic Segmentation of Building Areas in Synthetic Aperture Radar Images. Applied Sciences, 15(5), 2339. https://doi.org/10.3390/app15052339