
Content Analysis of E-Participation Platforms in Taiwan with Topic Modeling: How to Train and Evaluate Neural Topic Models? †


Abstract
1. Introduction
- 1.
- Insight into Platforms: We provide a comprehensive analysis of two e-participation platforms, Join and iVoting, highlighting their thematic focuses, user engagement patterns, and platform-specific trends. This comparison offers valuable insights into how public participation varies across platforms and governance contexts.
- 2.
- Language-Independent Pipeline Evaluation: We propose a robust method for evaluating text-mining pipelines across languages using neural topic models. This approach ensures flexibility and applicability in multilingual e-participation settings, enabling a more inclusive analysis of public sentiment and thematic trends.
- 3.
- Evaluation Framework for Neural Topic Models: We introduce a systematic framework to assess the performance of neural topic models, combining metrics such as coherence evaluated with NPMI (Normalized Point Mutual Information) and computational efficiency. This framework provides researchers and practitioners with practical tools to balance semantic quality and processing demands effectively.
2. Literature Review
2.1. E-Participation Platforms in Taiwan
2.2. Neural Topic Modeling in Policy Informatics
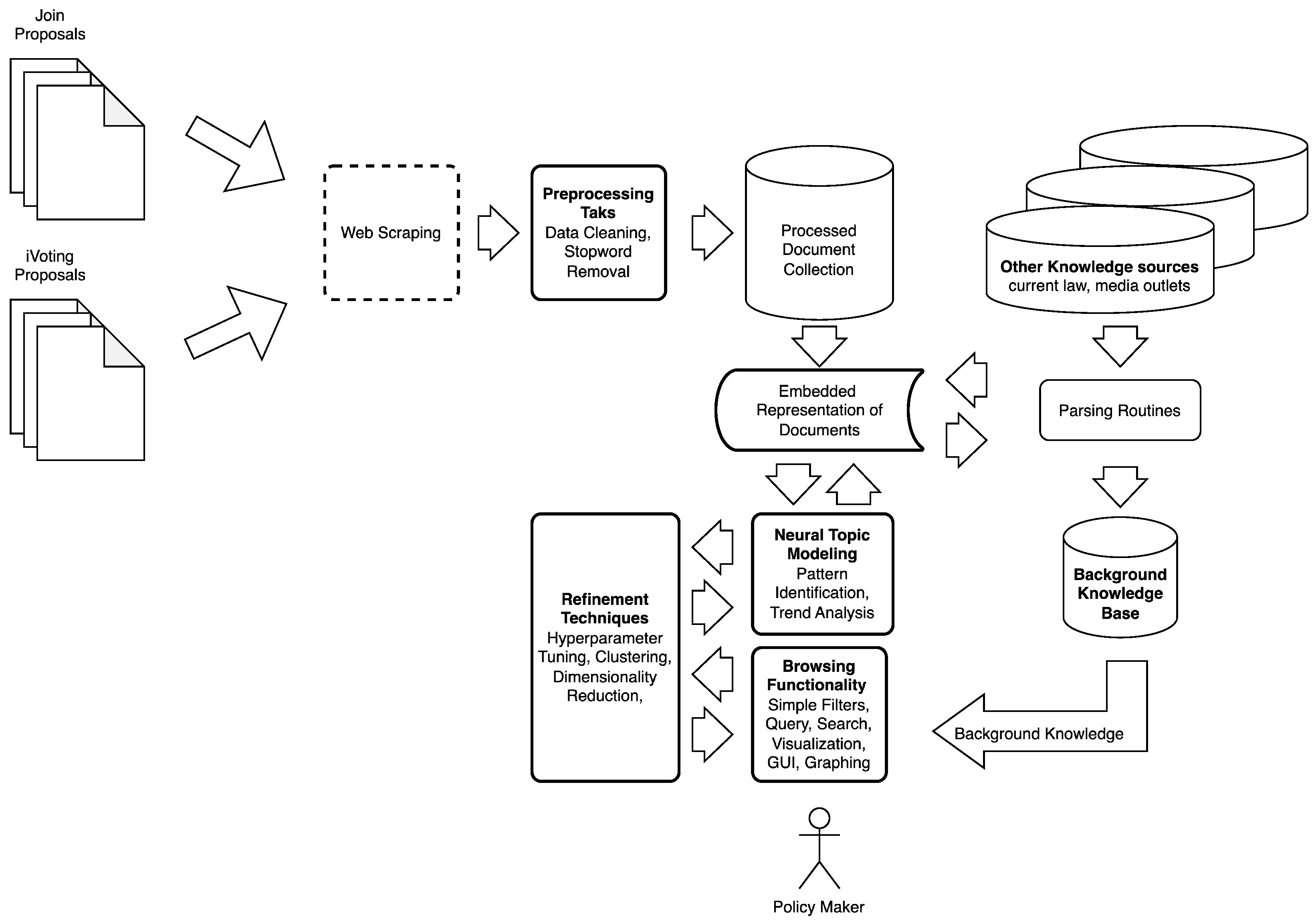
3. Methods
3.1. Dataset
3.2. Proposed Pipeline
3.3. Pipeline Mathematical
3.4. Document Embeddings
3.5. Dimensionality Reduction
3.6. Clustering with HDBSCAN
3.7. Topic Representation
3.8. Topic Evaluation Metrics
3.8.1. NPMI for Topic Coherence
3.8.2. Topic Diversity
3.9. Refinements
3.10. Problem Definition
- Concept Selection
- Concept Proportion
- Conditional Concept Proportion
- Concept Proportion Distribution
- Average Concept Proportion
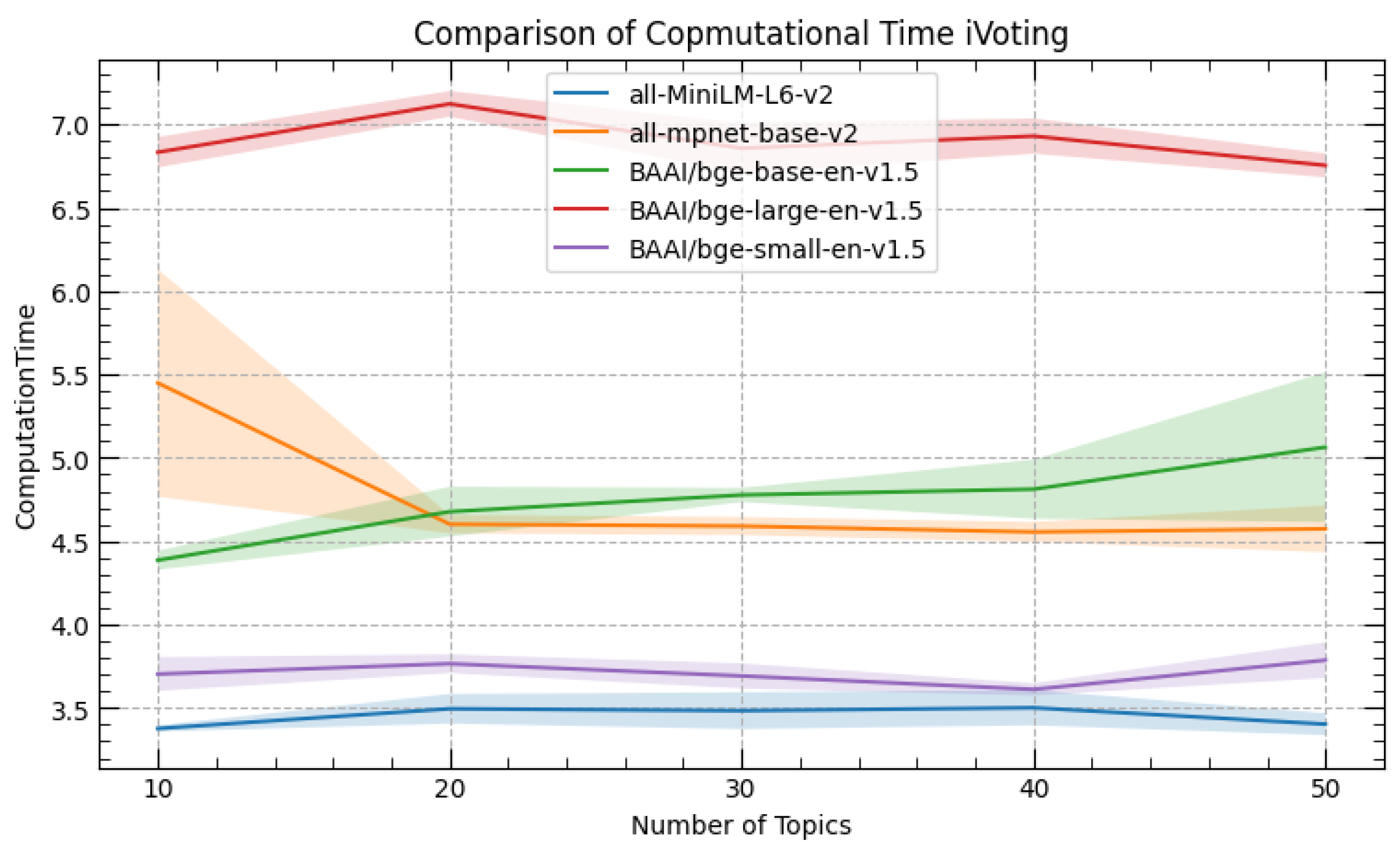
3.11. Evaluation
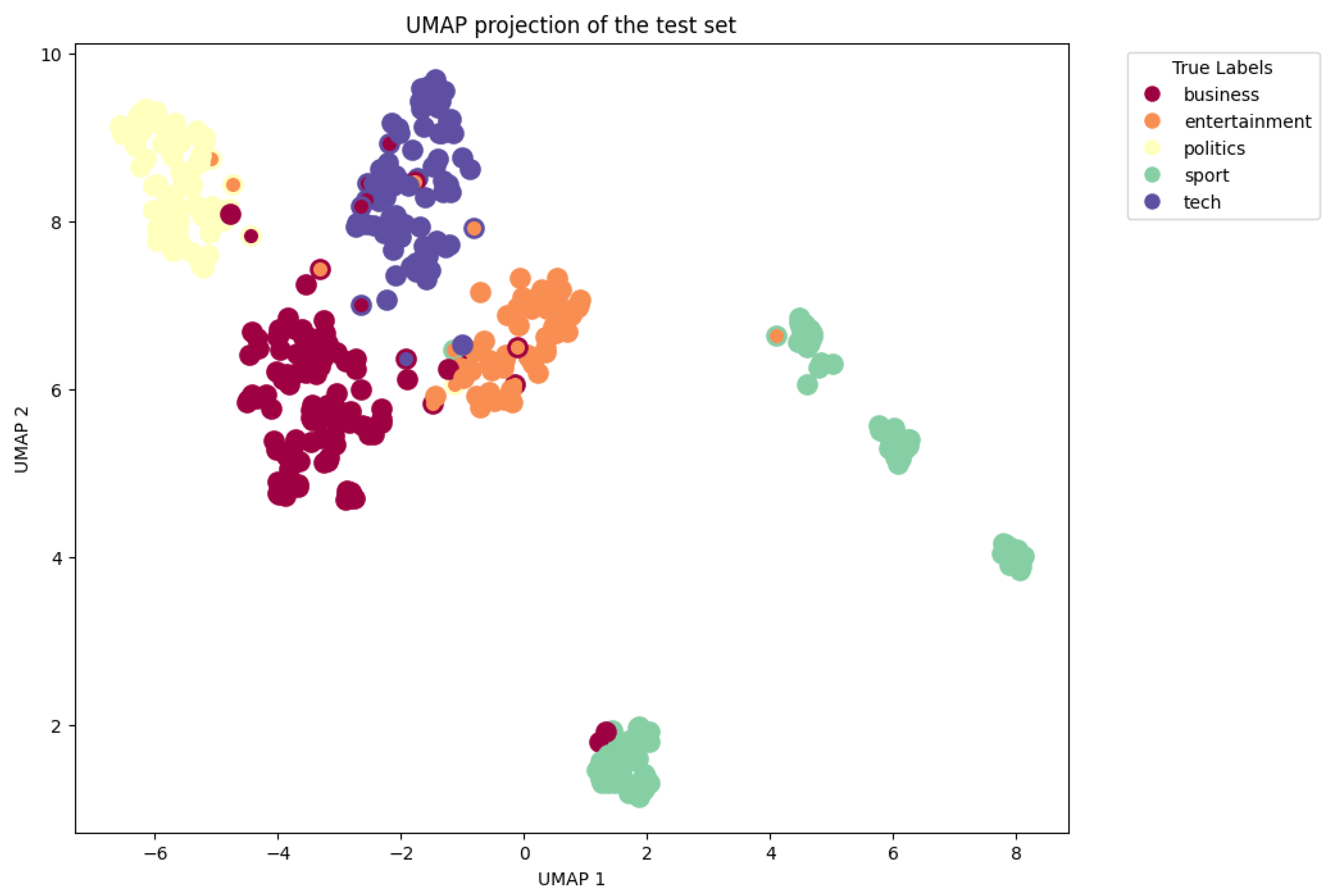
4. Results
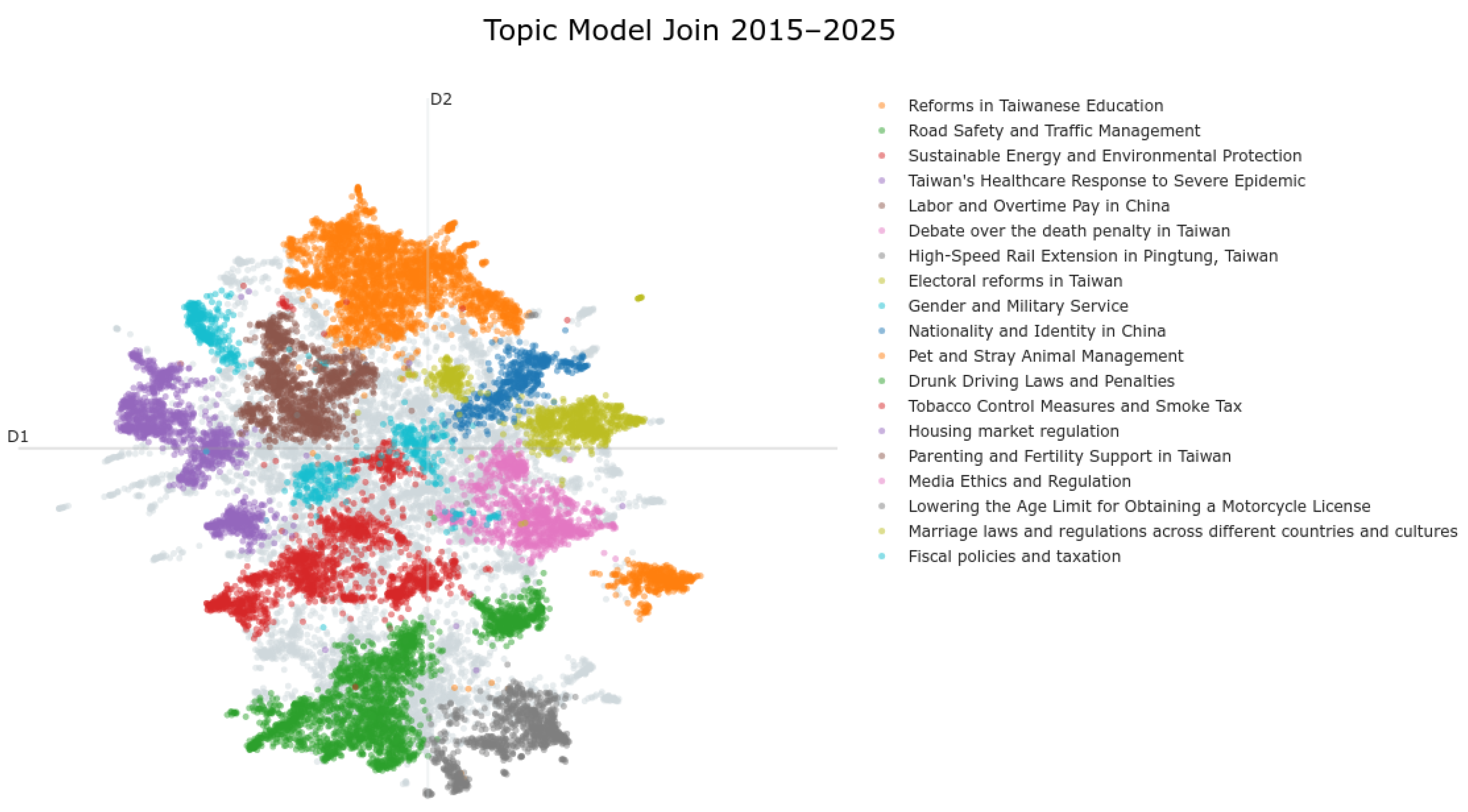
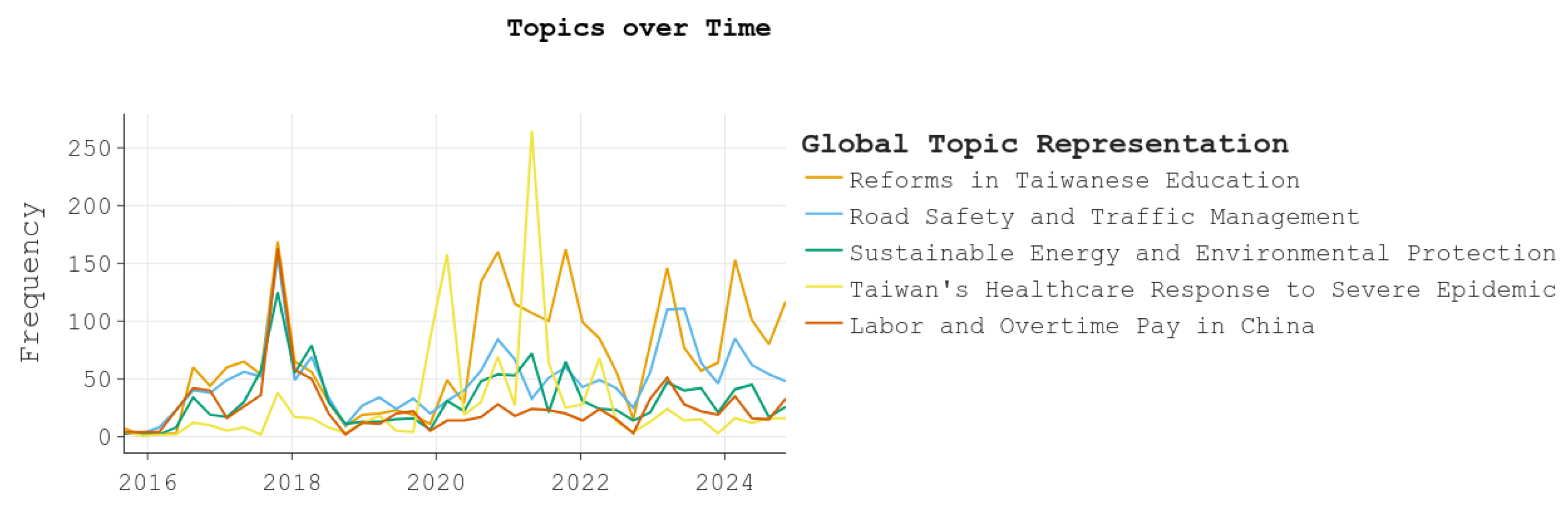
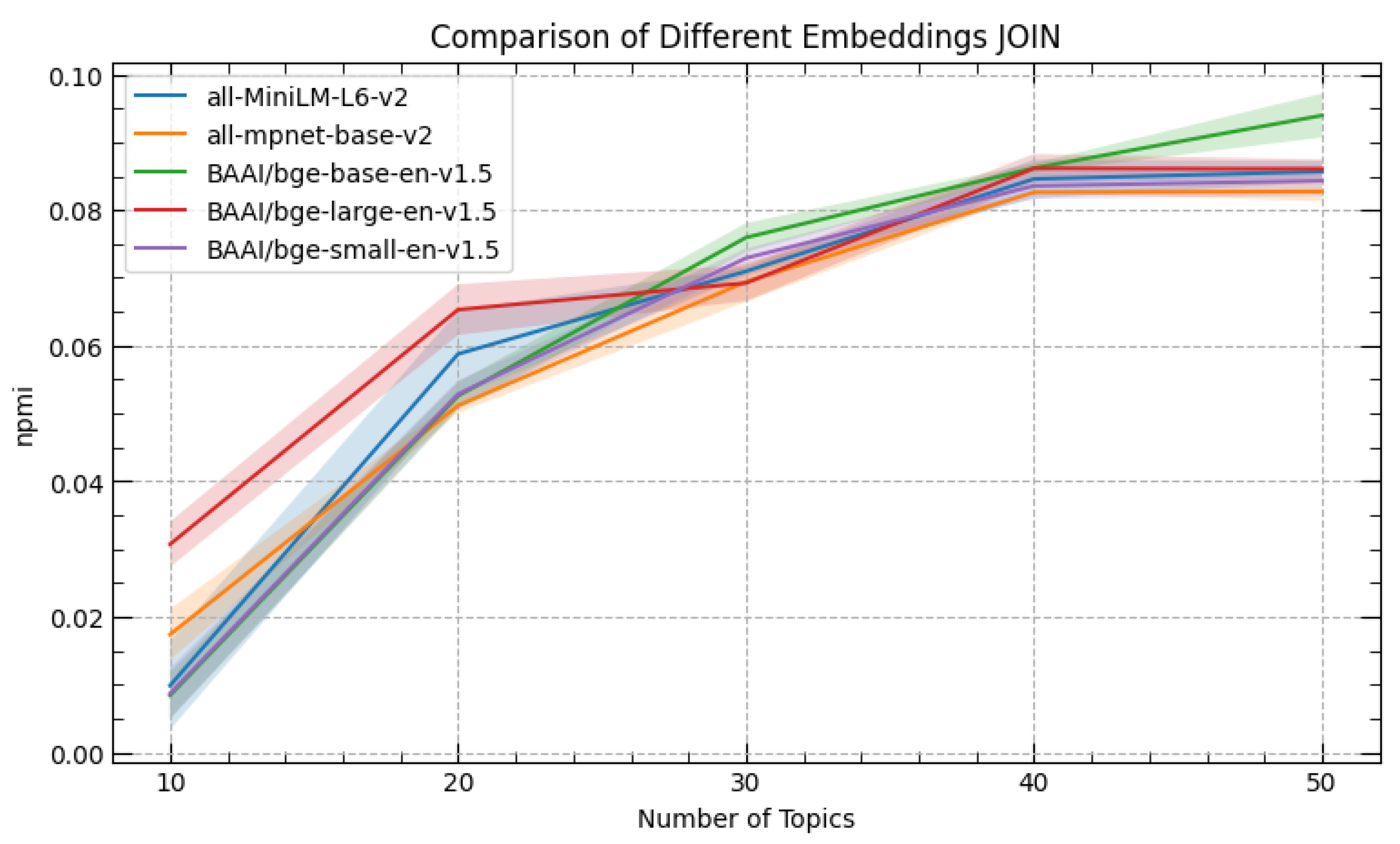
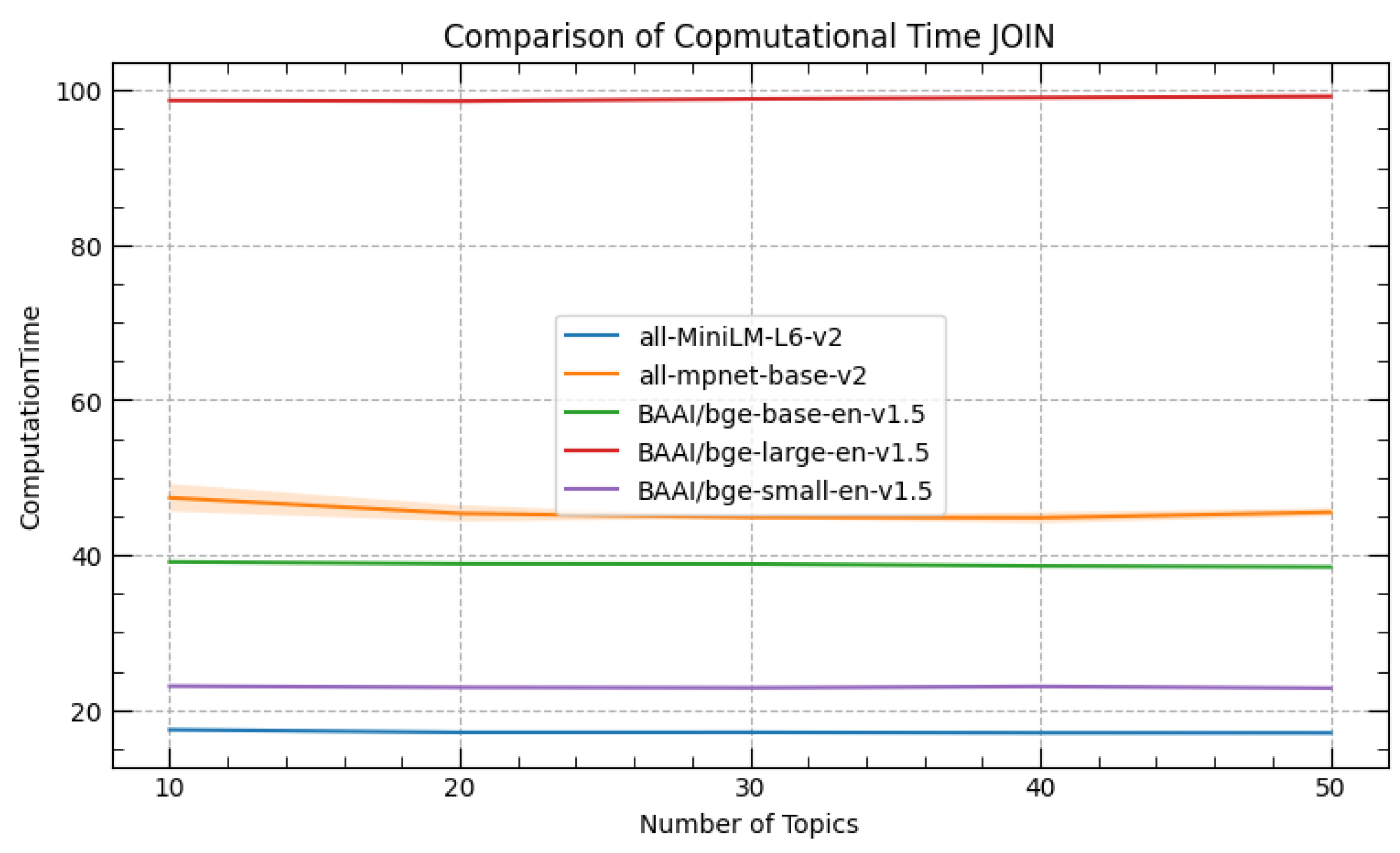
4.1. Topic Models
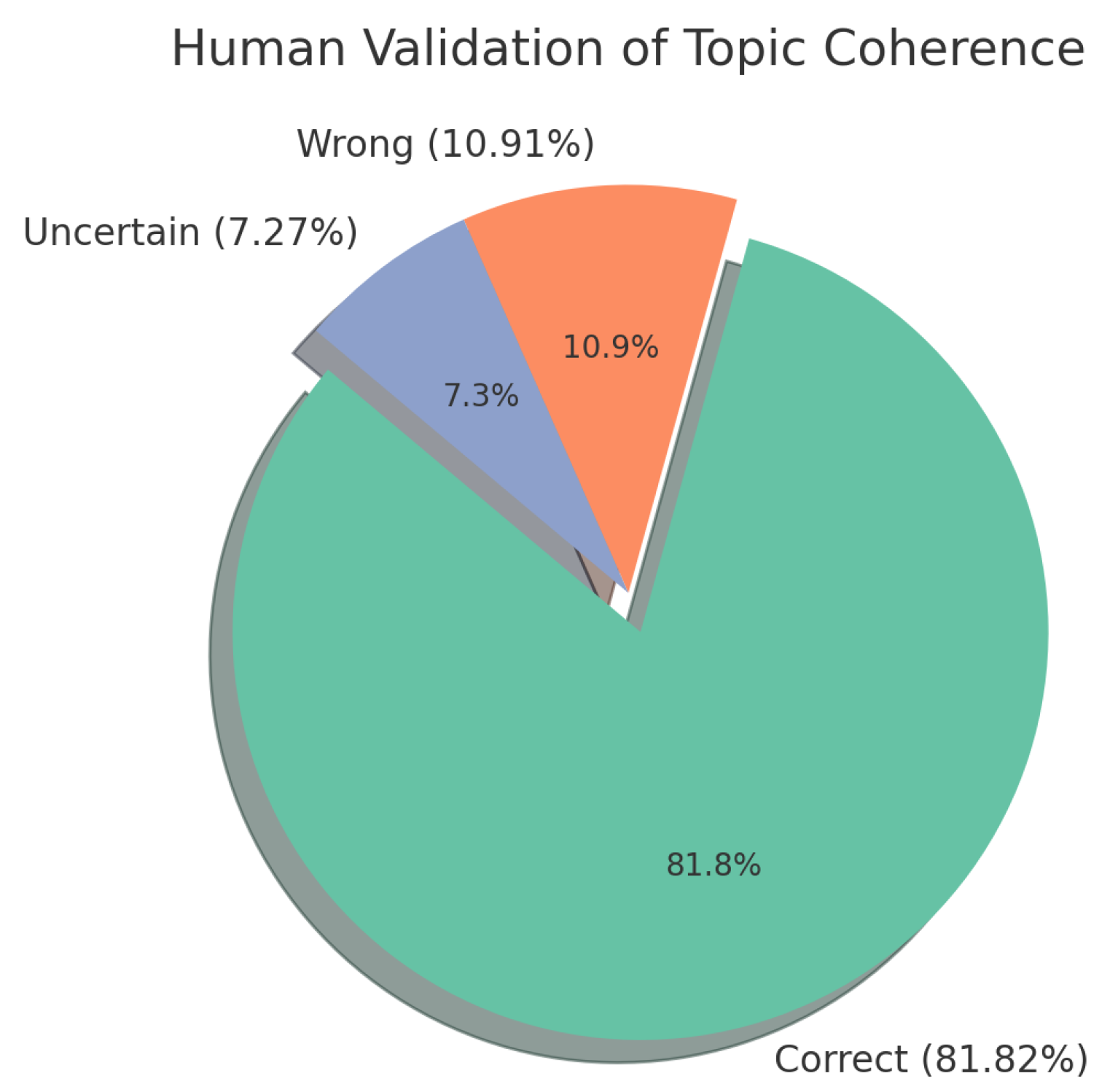
4.2. Human Validation of Topic Coherence
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dumas, C.L.; LaManna, D.; Harrison, T.M.; Ravi, S.S.; Kotfila, C.; Gervais, N.; Hagen, L.; Chen, F. Examining Political Mobilization of Online Communities through E-Petitioning Behavior in We the People. Big Data Soc. 2015, 2, 2053951715598170. [Google Scholar] [CrossRef]
- Park, C.H.; Johnston, E.W. An Event-Driven Lens for Bridging Formal Organizations and Informal Online Participation: How Policy Informatics Enables Just-in-Time Responses to Crises. In Policy Analytics, Modelling, and Informatics: Innovative Tools for Solving Complex Social Problems; Gil-Garcia, J.R., Pardo, T.A., Luna-Reyes, L.F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 343–361. [Google Scholar] [CrossRef]
- Hagen, L. Content Analysis of E-Petitions with Topic Modeling: How to Train and Evaluate LDA Models? Inf. Process. Manag. 2018, 54, 1292–1307. [Google Scholar] [CrossRef]
- Chen, C.H.; Liu, C.L.; Hui, B.P.H.; Chung, M.L. Does Education Background Affect Digital Equal Opportunity and the Political Participation of Sustainable Digital Citizens? A Taiwan Case. Sustainability 2020, 12, 1359. [Google Scholar] [CrossRef]
- Rodríguez Bolívar, M.P. Policy Makers’ Perceptions About Social Media Platforms for Civic Engagement in Public Services. An Empirical Research in Spain. In Policy Analytics, Modelling, and Informatics: Innovative Tools for Solving Complex Social Problems; Gil-Garcia, J.R., Pardo, T.A., Luna-Reyes, L.F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 267–288. [Google Scholar] [CrossRef]
- Arnstein, S.R. A Ladder Of Citizen Participation. J. Am. Inst. Planners 1969, 35, 216–224. [Google Scholar] [CrossRef]
- Huesmann, C.; Renkamp, A. Digitale Bürgerdialoge—Eine Chance für die lokale Demokratie. Available online: https://www.bertelsmann-stiftung.de/doi/10.11586/2021015 (accessed on 30 December 2024).
- Fischer, D.; Brändle, F.; Mertes, A.; Pleger, L.E.; Rhyner, A.; Wulf, B. Partizipation im digitalen Staat: Möglichkeiten und Bedeutung digitaler und analoger Partizipationsinstrumente im Vergleich. Swiss Yearb. Adm. Sci. 2020, 11, 129–144. [Google Scholar] [CrossRef]
- Dienel, H.L.; von Blanckenburg, C.; Bach, N. Mini Publics Online: Erfahrungen mit Online-Bürgerräten und Online-Planungszellen. In Handbuch Digitalisierung und Politische Beteiligung; Kersting, N., Radtke, J., Baringhorst, S., Eds.; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2020; pp. 1–16. [Google Scholar] [CrossRef]
- Liao, D.c.; Chen, B. Strengthening Democracy: Development of the iVoter Website in Taiwan. In Political Behavior and Technology: Voting Advice Applications in East Asia; Liao, D.c., Chen, B., Jensen, M.J., Eds.; Palgrave Macmillan US: New York, NY, USA, 2016; pp. 67–89. [Google Scholar] [CrossRef]
- Rauchfleisch, A.; Tseng, T.H.; Kao, J.J.; Liu, Y.T. Taiwan’s Public Discourse About Disinformation: The Role of Journalism, Academia, and Politics. J. Pract. 2023, 17, 2197–2217. [Google Scholar] [CrossRef]
- Liebeck, M.; Esau, K.; Conrad, S. Text Mining Für Online-Partizipationsverfahren: Die Notwendigkeit Einer Maschinell Unterstützten Auswertung. HMD Prax. Wirtsch. 2017, 54, 544–562. [Google Scholar] [CrossRef]
- Huang, H.Y.; Kovacs, M.; Kryssanov, V.; Serdült, U. Towards a Model of Online Petition Signing Dynamics on the Join Platform in Taiwan. In Proceedings of the 2021 Eighth International Conference on eDemocracy & eGovernment (ICEDEG), Quito, Ecuador, 28–30 July 2021; pp. 199–204. [Google Scholar] [CrossRef]
- Tang, A. A Young Democracy Is a Strong Democracy: Civil Rights of Taiwan’s Children. 2020. Available online: https://freedomreport.5rightsfoundation.com/protecting-children-online-the-past-present-and-future (accessed on 17 February 2025).
- Hsiao, H. ICT-mixed community participation model for development planning in a vulnerable sandbank community: Case study of the Eco Shezi Island Plan in Taipei City, Taiwan. Int. J. Disaster Risk Reduct. 2021, 58, 102218. [Google Scholar] [CrossRef]
- Lee, C.p.; Chen, D.Y.; Huang, T.y. The Interplay Between Digital and Political Divides. Soc. Sci. Comput. Rev. 2014, 32, 37–55. [Google Scholar] [CrossRef]
- Törnberg, P. How to Use LLMs for Text Analysis. arXiv 2023, arXiv:2307.13106. [Google Scholar]
- Sontheimer, M.; Fahlbusch, J.; Korjako, T.; Chou, S.Y. Text-Mining of E-Participation Platforms: Applying Topic Modeling on Join and iVoting in Taiwan. In Proceedings of the TE2024: Engineering for Social Change, London, UK, 9–11 July 2024; Cooper, A., Ed.; pp. 105–112. [Google Scholar] [CrossRef]
- Lapesa, G.; Blessing, A.; Blokker, N.; Dayanik, E.; Haunss, S.; Kuhn, J.; Padó, S. Analysis of Political Debates through Newspaper Reports: Methods and Outcomes. Datenbank-Spektrum 2020, 20, 143–153. [Google Scholar] [CrossRef]
- Dayanik, E.; Blessing, A.; Blokker, N.; Haunss, S.; Kuhn, J.; Lapesa, G.; Pado, S. Improving Neural Political Statement Classification with Class Hierarchical Information. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 2367–2382. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Malzer, C.; Baum, M. A Hybrid Approach To Hierarchical Density-based Cluster Selection. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, Germany, 14–16 September 2020; pp. 223–228. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Airoldi, E. The Structural Topic Model and Applied Social Science. In Proceedings of the International Conference on Neural Information Processing, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Doan, T.N.; Hoang, T.A. Benchmarking Neural Topic Models: An Empirical Study. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; pp. 4363–4368. [Google Scholar]
- Moodley, A.; Marivate, V. Topic Modelling of News Articles for Two Consecutive Elections in South Africa. In Proceedings of the 2019 6th International Conference on Soft Computing & Machine Intelligence (ISCMI), Johannesburg, South Africa, 19–20 November 2019; pp. 131–136. [Google Scholar] [CrossRef]
- Li, Z.; Mao, A.; Stephens, D.; Goel, P.; Walpole, E.; Dima, A.; Fung, J.; Boyd-Graber, J. Improving the TENOR of Labeling: Re-evaluating Topic Models for Content Analysis. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), St. Julian’s, Malta, 17–22 March 2024; Graham, Y., Purver, M., Eds.; Association for Computational Linguistics: St. Julian’s, Malta, 2024; pp. 840–859. [Google Scholar]
- Terragni, S.; Fersini, E. An Empirical Analysis of Topic Models: Uncovering the Relationships between Hyperparameters, Document Length and Performance Measures. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Online, 1–3 September 2021; pp. 1408–1416. [Google Scholar]
- Terragni, S.; Fersini, E.; Galuzzi, B.G.; Tropeano, P.; Candelieri, A. OCTIS: Comparing and Optimizing Topic Models Is Simple! In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Online, 19–23 April 2021; pp. 263–270. [Google Scholar] [CrossRef]
- Bose, B. BBC News Classification; Kaggle: San Francisco, CA, USA, 2019; Available online: https://kaggle.com/competitions/learn-ai-bbc (accessed on 1 February 2025).
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. Cluster validity methods: Part I. ACM Sigmod Rec. 2002, 31, 40–45. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| JOIN Cluster | Count | iVoting Cluster | Count |
|---|---|---|---|
| Government Policies and Regulations | 6710 | Governance and Sustainability in Taiwan | 247 |
| Education Policies in Taiwan | 2702 | Taipei Public Transport Infrastructure | 26 |
| Traffic Safety Regulations | 1947 | Traffic Management | 81 |
| Energy Transition and Sustainable Development | 1294 | Taiwan’s Epidemic Prevention Efforts | 25 |
| Government Response to COVID-19 Epidemic | 1149 | Education Technology and Reform | 25 |
| Labor Rights and Regulations in Taiwan | 997 | Public Servant Conduct and Accountability | 24 |
| Debate over the death penalty in Taiwan | 810 | Waste Management and Recycling in Taiwan | 18 |
| High-Speed Rail Extension in Pingtung, Taiwan | 743 | Taiwan’s Epidemic Prevention Efforts | 15 |
| Electoral Reform | 729 | Labor and Social Welfare in Taiwan | 10 |
| Gender and Military Service | 535 | Inappropriate Content | 8 |
| Nationality and Identity in China | 513 | ||
| Pet and Stray Animal Management | 461 | ||
| Drunk Driving Laws and Penalties | 427 | ||
| Tobacco Control and Smoking Regulations | 416 | ||
| Housing Market Regulation | 360 | ||
| Parenting and Fertility Support in Taiwan | 289 | ||
| Media Regulation and False Information Online | 236 | ||
| Lowering the age limit for Obtaining a Motorcycle | 223 | ||
| Marriage Laws and Regulations | 205 | ||
| Fiscal policies and taxation | 177 |
| Model | 20 News Group | BBC News | Join | Trump | iVoting | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| NPMI | Diversity | NPMI | Diversity | NPMI | Diversity | NPMI | Diversity | NPMI | Diversity | |
| LDA | 0.058 | 0.749 | 0.014 | 0.577 | 0.001 | 0.572 | −0.011 | 0.502 | −0.04 | 0.124 |
| CTM_C | 0.096 | 0.886 | 0.094 | 0.819 | 0.033 | 0.862 | 0.009 | 0.855 | −0.24 | 0.746 |
| NMF | 0.089 | 0.663 | 0.012 | 0.549 | 0.061 | 0.322 | 0.009 | 0.379 | −0.04 | 0.343 |
| Top2Vec | 0.192 | 0.823 | 0.171 | 0.792 | 0.081 | 0.898 | −0.169 | 0.658 | −0.16 | 1.000 |
| Proposed Approach | 0.166 | 0.851 | 0.167 | 0.794 | 0.060 | 0.598 | 0.066 | 0.663 | −0.04 | 0.436 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sontheimer, M.; Fahlbusch, J.; Chou, S.-Y.; Kuo, Y.-L. Content Analysis of E-Participation Platforms in Taiwan with Topic Modeling: How to Train and Evaluate Neural Topic Models? Appl. Sci. 2025, 15, 2263. https://doi.org/10.3390/app15052263
Sontheimer M, Fahlbusch J, Chou S-Y, Kuo Y-L. Content Analysis of E-Participation Platforms in Taiwan with Topic Modeling: How to Train and Evaluate Neural Topic Models? Applied Sciences. 2025; 15(5):2263. https://doi.org/10.3390/app15052263
Chicago/Turabian StyleSontheimer, Moritz, Jonas Fahlbusch, Shuo-Yan Chou, and Yu-Lin Kuo. 2025. "Content Analysis of E-Participation Platforms in Taiwan with Topic Modeling: How to Train and Evaluate Neural Topic Models?" Applied Sciences 15, no. 5: 2263. https://doi.org/10.3390/app15052263
APA StyleSontheimer, M., Fahlbusch, J., Chou, S.-Y., & Kuo, Y.-L. (2025). Content Analysis of E-Participation Platforms in Taiwan with Topic Modeling: How to Train and Evaluate Neural Topic Models? Applied Sciences, 15(5), 2263. https://doi.org/10.3390/app15052263