1. Introduction
Electricity theft, a longstanding challenge for utility companies, has evolved with the advent of smart grids. In addition to traditional physical attacks (such as meter bypassing), modern cyberattacks (like spoofing and man-in-the-middle attacks) now target electronic meters, often leveraging low-cost, easily accessible tools. This shift towards cyberattacks is particularly prominent in advanced power systems. The economic impact is severe, with global losses reaching USD 96 billion in 2017 [
1], especially in developing countries such as India. Electricity theft not only results in financial losses but also leads to inaccurate power demand forecasts, contributing to poor power quality and infrastructure damage. Furthermore, it hampers investments in advanced technologies and safety measures. Despite strict regulations in various countries, the strong economic incentives continue to fuel electricity theft.
Traditional electricity theft detection (ETD) methods involve specialized metering hardware and on-site manual inspections. Although this hardware-based approach offers high detection accuracy, the additional costs associated with equipment and labor, as well as its low efficiency, make it less favored by electricity providers. Recently, based on the massive amount of data provided by the advanced metering infrastructure (AMI), several machine learning-based ETD methods have been proposed in the literature [
2,
3]. Generally, from the perspective of learning paradigm, the existing schemes can be classified into two categories: supervised learning-based and unsupervised learning-based. (1) Supervised learning-based detectors are trained using both normal and abnormal samples, typically requiring a large number of labeled samples while ensuring that the quantities of normal and abnormal samples are balanced. Typical supervised learning-based methods include support vector machine (SVM) [
4,
5,
6], classification-based methods (such as decision trees, random forests, gradient boosting models, etc.) [
7,
8], and deep neural networks (including convolutional neural networks, long short-term memory neural networks, etc.) [
9,
10]. However, in smart grids, it is impractical to obtain a large number of electricity theft samples, leading to a data imbalance between abnormal and normal samples. Under such circumstances, supervised models struggle to learn the general features of abnormal samples, resulting in poor detection performance when faced with new electricity theft methods. (2) Unsupervised learning-based detectors focus on capturing the characteristics of normal electricity consumption data, offering an effective solution to the data imbalance problem commonly faced by supervised learning-based methods. Unsupervised learning-based methods include distance-based detection methods such as k-nearest neighbor (kNN), one-class classification-based methods such as one-class SVM (OCSVM) and local outlier factor [
11], clustering-based methods such as K-means [
12,
13,
14], and autoencoder-based methods [
15,
16,
17,
18]. However, shallow unsupervised methods, such as one-class classification, often exhibit low detection accuracy when dealing with high-dimensional data. The architecture and loss function of autoencoders are relatively fixed, mainly optimized based on reconstruction error. They cannot fully exploit the temporal features in power data. Moreover, existing supervised and unsupervised learning-based approaches do not fully explore the periodic features.
Many deep learning-based studies have leveraged the periodicity in electricity consumption data to distinguish between electricity theft and normal usage. For example, several studies have transformed one-dimensional electricity consumption data into two-dimensional matrices and employed various deep neural networks (DNNs) to capture the underlying periodicity. ETD-ConvLSTM (electricity theft detector based upon convolutional long short term memory neural networks) [
19] uses a ConvLSTM network to capture the periodic patterns in users’ consumption. HORLN ( hybrid-order representation learning network) [
10] uses the autocorrelation function to determine whether there is periodicity in different electricity consumption data. Additionally, some studies (e.g., Reference [
20]) convert the electricity data into graphs and leverage graph convolutional networks (GCNs) to capture the periodicity within the graph structure. However, the aforementioned DNNs do not inherently capture temporal dependencies and fail to fully exploit the periodic features. Although HORLN uses autocorrelation to highlight the capture of periodic characteristics, it only incorporates it as a second-order feature, merging it with first-order feature information.
Based on the above considerations, we propose a periodicity-enhanced deep one-class classification framework (PE-DOCC) for ETD based on a periodicity-enhanced transformer encoder named Periodicformer encoder. PE-DOCC is particularly suited for ETD due to its ability to learn from normal data without requiring labeled instances of theft. This is crucial in real-world scenarios where labeled data are sparse or unavailable. By using one-class classification, PE-DOCC builds a model that learns the characteristics of normal (non-theft) consumption patterns and can then identify any deviation from this learned pattern as potential theft. The integration of DNN (specifically the Periodicformer encoder) allows PE-DOCC to handle complex, high-dimensional data, making it more effective in capturing the intricacies of electricity usage patterns. Within the Periodicformer encoder, the paper introduces autocorrelation-based criss-cross periodic attention (CCPA). As discussed earlier, autocorrelation helps capture periodic dependencies within time series data, while CCPA simultaneously computes and combines both horizontal and vertical autocorrelations, enhancing the model’s ability to extract richer, more comprehensive periodic features from the time series, thus resulting in better detection performance. The main contributions of this paper can be summarized as follows:
We propose a novel PE-DOCC framework for detecting electricity theft, which incorporates unsupervised representation learning (i.e., pre-training the Periodicformer encoder by recovering partially masked input sequences) and one-class classification (anomaly detection based on local outlier factor);
To extract richer periodic features, within the encoder, a novel criss-cross periodic attention (CCPA) is proposed, which comprehensively considers both the horizontal and vertical periodic features;
Extensive experiments with ETD using the Irish dataset are conducted to compare the performance with various state-of-the-art methods. Appropriate metrics are selected for evaluation, and the effectiveness of the proposed ETD scheme is verified.
The rest of the paper is organized as follows: In Section
Section 2, typical one-class (OC) classification (including traditional machine learning-based and recent deep learning-based) ETD schemes are summarized. Section
Section 3 presents the proposed ETD framework PE-DOCC and describes its main module in detail.
Section 4 provides the comprehensive performance comparison between the proposed framework and state-of-the-art ETD methods. Finally, we briefly conclude this paper.
2. Related Work
Unsupervised anomaly detection for electricity theft (and similar issues) is a highly challenging task, and over the past few years, various methods have been proposed to address it.
One traditional type is classification-based methods. Reference [
21] proposes a feature selection algorithm for mixed load data with statistical features based on random forest (FS-MLDRF) to reduce the dimension of user data and then uses the hybrid random forest and weighted support vector data description (HFR-WSVDD) to address the data imbalance issue. Reference [
22] proposes a privacy-preserving anomaly detection approach for LoRa-based IoT networks using federated learning. SVOC [
23], a data-driven approach to detect gas theft suspects among boiler room users, combines scenario-based data quality detection, deformation-based normality detection, and an OCSVM (one-class support vector machine)-based anomaly detection algorithm. Another common method is ensemble-based methods. TiWS-iForest [
24] incorporates weak supervision to reduce complexity and enhance anomaly detection performance. The approach addresses the limitations of standard iForest (isolation forest) in terms of memory, latency, and efficiency, particularly in low-resource environments like TinyML implementations on ultra-constrained microprocessors. Additionally, density-based methods, e.g., ELOF [
11] (ensemble local outlier factor) integrates multiple LOF models with optimized hyperparameters and distance metrics.
Besides traditional methods, deep learning-based unsupervised anomaly detection algorithms have gained a lot attention recently. Tab-iForest [
25] combines the TabNet deep learning model with the isolation forest algorithm, where TabNet selects relevant features through pre-training and inputs them into isolation forest for anomaly detection. Reference [
26] combines autoencoding and one-class classification, designed to benefit from strong abstraction by neural networks (using an autoencoder) and the removal of the complex threshold selection (using an OC classifier). A new model selection method that discovers well-optimized models from a variety of combinations is also proposed. Reference [
27] proposes a two-step electricity theft detection strategy to enhance economic returns for power companies. It uses a convolutional autoencoder (CAE) to identify electricity theft and the Tr-XGBoost regression algorithm which combines XGBoost (extreme gradient boosting) with TrAdaBoost (Transfer Adaptive Boosting) strategy, to predict potentially stolen electricity (PSE). Reference [
16] proposes a deep learning-based electricity theft cyberattack detection method for AMIs, combining stacked autoencoders with an LSTM (long short-term memory neural networks)-based sequence-to-sequence (seq2seq) structure to capture sophisticated patterns and temporal correlations in electricity consumption data. Reference [
17] proposes a novel unsupervised two-stage approach for electricity theft detection, combining a Gaussian mixture model with cluster consumption patterns and an attention-based bidirectional LSTM encoder–decoder to enhance robustness against non-malicious changes. A novel anomaly score is proposed, which comprehensively considers the similarity of consumption patterns and reconstruction errors. Reference [
18] proposes a stacked sparse denoising autoencoder for electricity theft detection, leveraging the reconstruction error of anomalous behaviors to identify theft users.
To sum up, deep learning-based unsupervised anomaly detection methods typically begin by using deep neural networks (e.g., autoencoders) to extract temporal dependencies and periodic features present in electricity data. The features output by the DNN are often low-dimensional, addressing the curse of dimensionality that traditional machine learning struggles with. These extracted features are then analyzed through one-class classification, effectively tackling the data imbalance issue between normal and anomalous data.
3. Proposed Framework: PE-DOCC
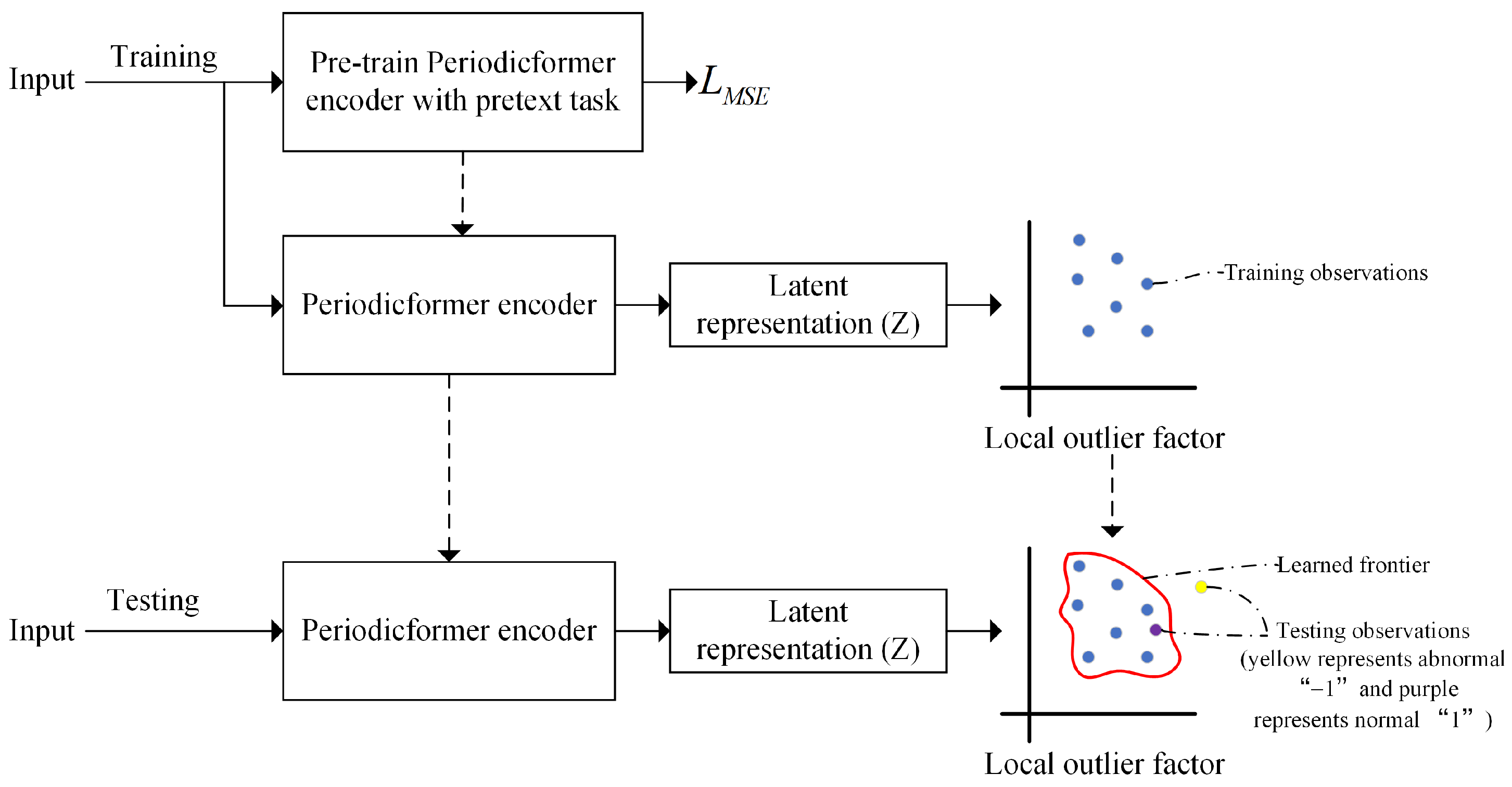
Figure 1 presents the proposed ETD framework, which explicitly consists of two main phases: model training and model testing. The training phase consists of two steps: Step 1: Pre-train the Periodicformer encoder by recovering partially masked input sequences (i.e., unsupervised representation learning). Step 2: Feed the latent representations output by the encoder into local outlier factor (LOF) to learn the anomaly detection boundary. In the testing phase, the input data are fed through the trained Periodicformer encoder and classifier to determine whether testing latent representation is within the trained boundary (1) or not (−1).
3.1. Periodicformer Encoder for Unsupervised Representation Learning
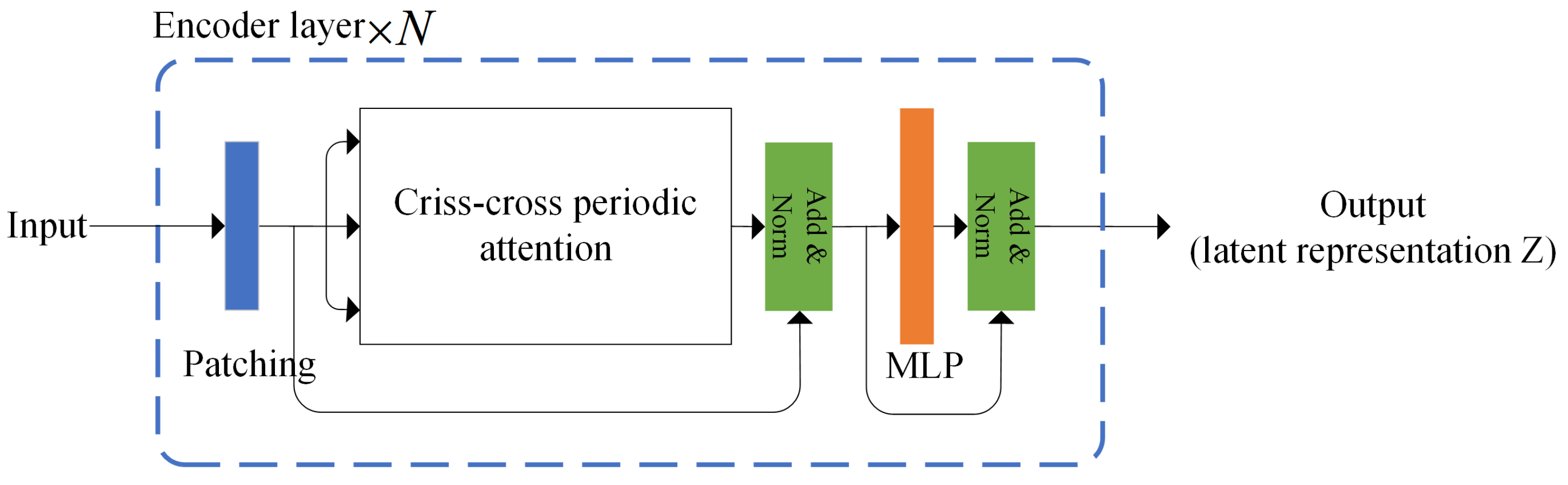
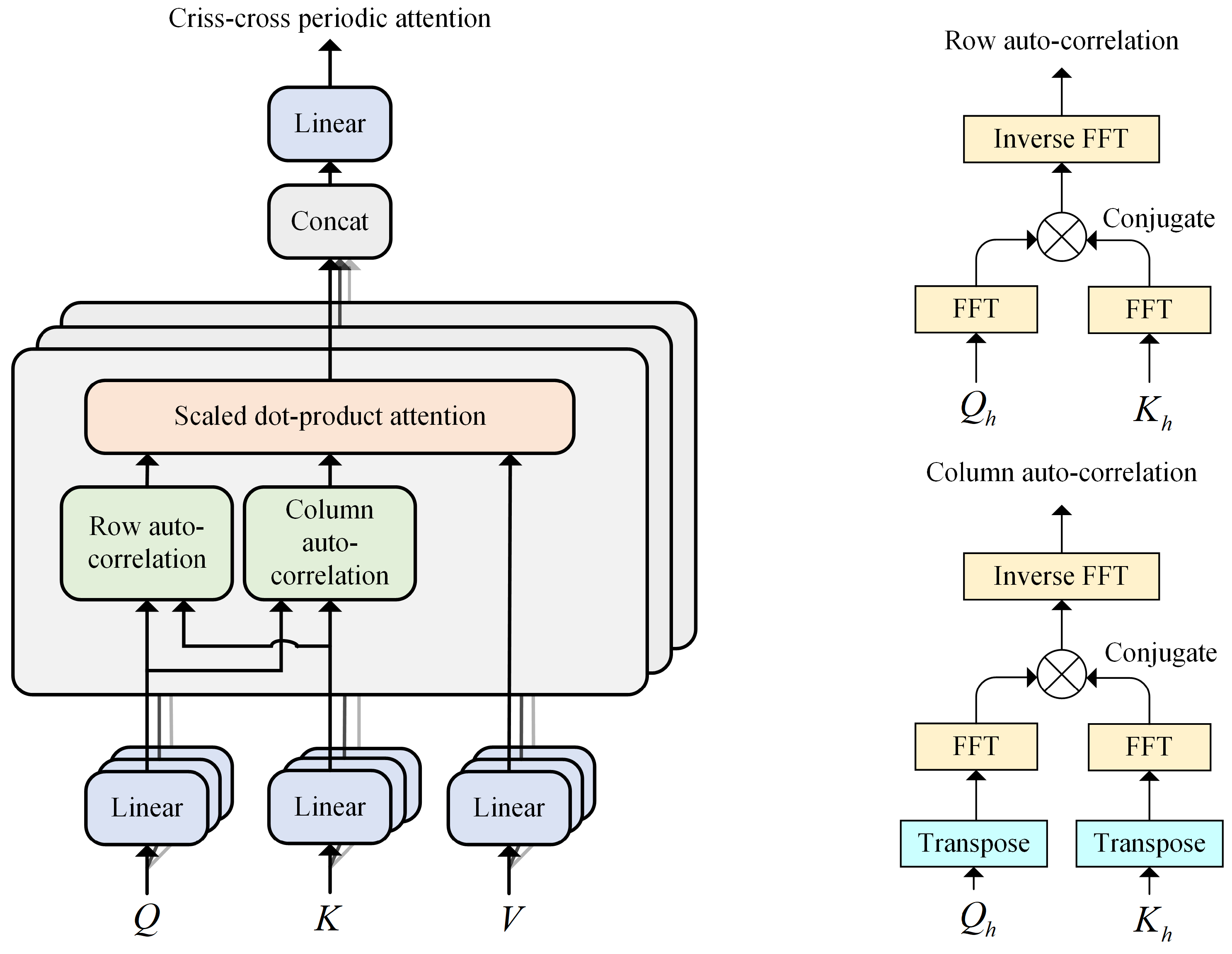
Figure 2 illustrates the overall architecture of the proposed Periodicformer encoder, which is composed of three modules: the patching module, the proposed criss-cross periodic attention module, and the multilayer perceptron (MLP) module (consisting of two linear layers with a GELU activation function).
In layer i, we denote the patch size as , the length of the input feature as , and the embedding dimension as d.
3.1.1. Patching Operation
The input feature for layer i is first divided into multiple patches. ( is the number of the patches, each patch ). Then, these patches are flattened and embedded into a new feature map .
It is worth noting that we do not use positional encoding here, as our experimental results show that adding positional encoding actually reduces detection performance, which is consistent with the findings in Reference [
28].
3.1.2. Criss-Cross Periodic Attention
As shown in
Figure 3, we propose the criss-cross periodic attention mechanism to mine richer periodic scale characteristics. Row autocorrelation and column autocorrelation explore periodic dependencies by calculating autocorrelation.
Period-based dependencies: Inspired by the autocorrelation mechanism [
29], for an input sequence
with length
L, we can obtain the autocorrelation
by the following Equation (
1):
reflects the time-delay similarity between
and its
lag series
. Taking the row autocorrelation in
Figure 3 as an example, for single head
h and input sequence
where
, after the linear projector, we get query
, key
, and value
. At this point, we consider
as sequences along the row direction, i.e.,
where
is the embedding dimension of
, with
treated in the same manner. Then, we can obtain the row autocorrelation
using the following Equation (
2):
where
is the autocorrelation between
and
. The calculation of the column autocorrelation is similar to that of row autocorrelation, with the only difference being that
and
are treated as sequences along the column direction. The formula for calculating column autocorrelation is provided in Equation (
3).
where
is the autocorrelation between the transpose of
and the transpose of
;
Criss-cross periodic attention: To comprehensively capture the different periodic features extracted by row and column autocorrelation, we use the scaled dot product attention, with the product of row and column autocorrelation serving as the new attention weights. For a single head
h, the criss-cross periodic attention (CCPA) mechanism is as shown in the following Equation (
4):
For the multi-head version, with
H heads, the process is as shown in Equation (
5):
Efficient computation: The Wigner–Khinchin theorem establishes that the Fourier transform of the autocorrelation function of a signal equals its power spectral density. For the autocorrelation computation (Equation (
1)), the given input sequence
,
can be calculated by the discrete Fourier transforms (DFT) as Equation (
6):
where
,
denotes DFT and
is its inverse transformation. ∗ denotes the conjugate operation, and
is the power spectral density. In practice, we use fast Fourier transforms (FFT) to reduce the time complexity from
to
. The FFT algorithm process can be seen in Algorithm 1.
| Algorithm 1: Fast Fourier transform (FFT) |
![Applsci 15 02193 i001]() |
3.1.3. Unsupervised Representation Learning
Electricity consumption data are treated as a univariate time series of length
T, expressed as
. To determine whether the data point
at time
t is an anomaly, we analyze a contextual window of length
L, defined as
, instead of focusing solely on a single point. The training set can be represented as
. For simplicity, windows
are omitted when
[
30].
Unsupervised representation learning involves two steps: creating a Boolean mask
M and calculating the mean squared error (MSE) loss. The mask
M is generated with alternating segments of 0 s and 1 s, where the lengths of the 0 s and 1 s follow geometric distributions with means
and
, respectively. The proportion
r determines the ratio of 0 s in the mask, and the length
is computed as
. The masked detection window
is then passed through the encoder, producing feature representation
Z. The output
Z is flattened and passed through a linear layer to forecast the masked values, yielding
. The MSE loss is computed by comparing the predicted values
to the actual masked values
at the indices in
, which are the positions where
, as Equations (
7)–(
9).
where ⊙ is the Hadamard product,
B is a batch of training samples, and
represents the batch size. The overall process of unsupervised representation learning is described in detail in Algorithm 2.
| Algorithm 2: Unsupervised representation learning |
![Applsci 15 02193 i002]() |
Note that the objective of the unsupervised representation learning is to learn latent representations Z for subsequent one-class classification-based anomaly detection. In the subsequent anomaly detection process, the linear layer originally used for outputting the masked time series is discarded.
3.2. One-Class Classifier for Anomaly Detection
Once the unsupervised training is completed, the training data are rejected into the trained Periodicformer encoder and the latent representation () is fed to the local outlier factor (LOF) as input where is the number of training data.
LOF is a density-based outlier detection algorithm. The determination of the outlier is judged based on the density between each data point and its neighbor points. The lower the density of the point, the more likely it is to be identified as the outlier. The key definitions for the LOF are as follows:
Definition 1. k-distance of data point . For a given dataset D and any positive integer k, the k-distance of , denoted as , is defined as the distance between data point and data point in the following conditions:
For at least k data points , it holds that ;
for at most objects , it holds that .
Definition 2. k-distance neighborhood of data point . Given the k-distance of , the k-distance neighborhood of contains every data point whose distance from is not greater than the k-distance, as described in Equation (10). Definition 3. Reachability distance of data point with respect to data point . Let k be a natural number. The reachability distance of with respect to is defined as Equation (11). Definition 4. Local reachability density of data point . The local reachability density of is defined as Equation (12).where is the k-distance neighborhood of data point . Definition 5. Local outlier factor of data point . The local outlier factor of is defined as Equation (13). The contamination rate hyper-parameter determines the threshold based on the LOF of the training samples. During testing, data points with LOF values greater than the threshold are considered outliers.
4. Results
We have implemented the entire setup using Python 3.8.17. The Periodicformer encoder model and unsupervised representation learning process were developed with PyTorch 2.0.1 and PyTorch-Ignite 0.3.0, while the one-class classifier model and training process were built using scikit-learn. We use the Adam optimizer to train all models with a learning rate of 0.001. We implement all the methods three times, and report the results as the mean. The equipment used in this study includes an Intel i3-12100F CPU, manufactured by Intel Corporation, headquartered in Santa Clara, CA, USA, and an NVIDIA GeForce RTX 2060 12G GPU, produced by NVIDIA Corporation, also located in Santa Clara, CA, USA.
4.1. Dataset
The dataset utilized in this study for experimental evaluation is the publicly available electricity consumption dataset from the Irish CER Smart Metering Project [
31]. It includes daily electricity consumption records for approximately 5000 residential and commercial users. Details of Irish dataset are shown in
Table 1.
For the experiments, we use data collected over a 365-day period. We exclude users with missing values (NaN), correct erroneous data, and apply min-max normalization to preprocess the dataset [
13]. To enhance detection performance, the detection window is set to cover 7 days (
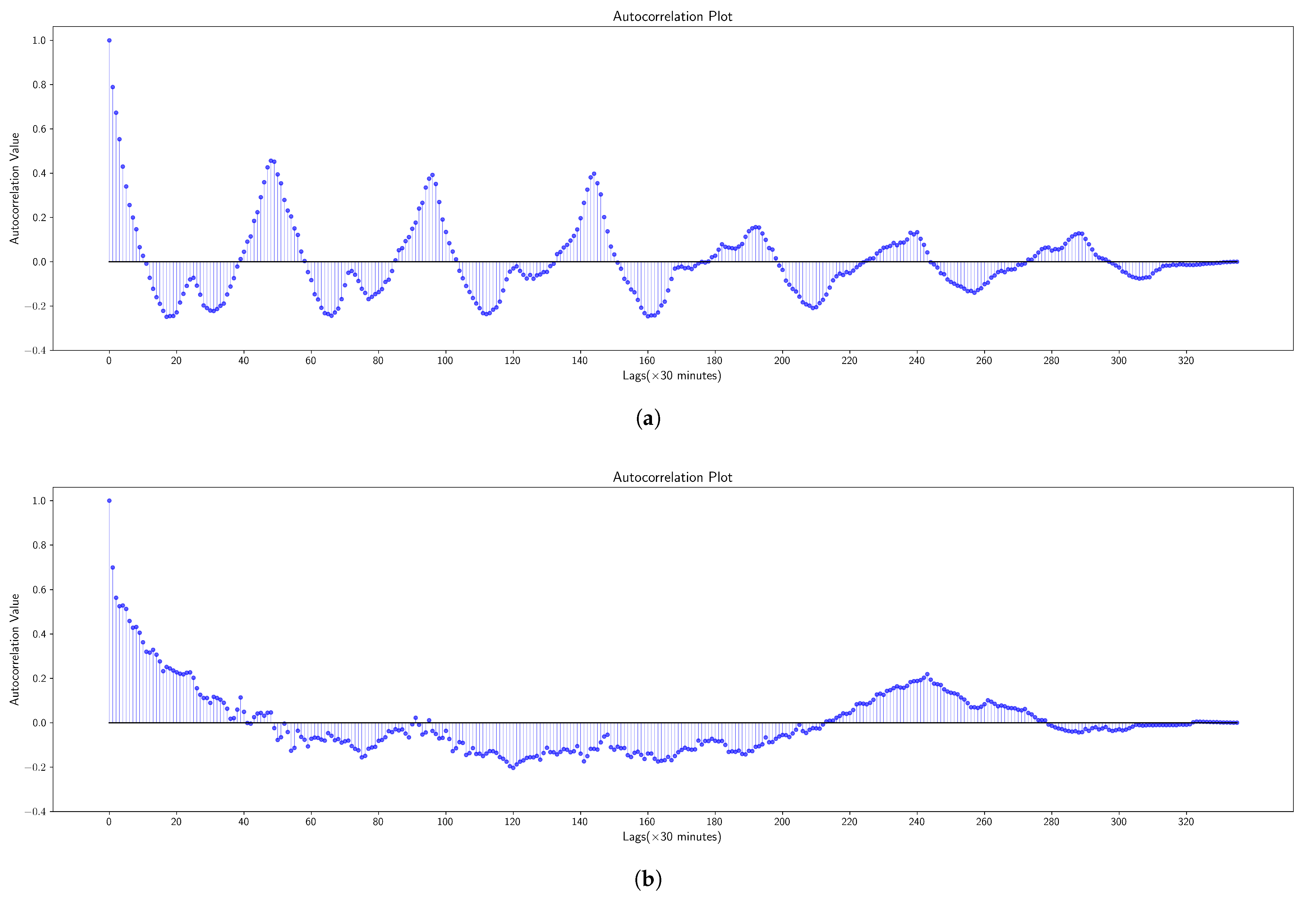
) instead of a single day. We indeed assume that the distribution of electricity usage data exhibits periodicity within the 7-day detection window for each day. As shown in the
Figure 4, we plotted the autocorrelation graphs for both normal and abnormal samples. It is clear that in the autocorrelation graph of the normal sample, the electricity usage data distribution shows periodicity, especially with similar usage patterns between consecutive days. In contrast, the autocorrelation graph of the abnormal sample shows almost no periodicity in the electricity usage data distribution. This provides factual support for our designed PE-DOCC. We believe that for legitimate users, their electricity usage data may exhibit periodicity between days, weeks, and months. However, considering that the time complexity of our designed CCPA is
, to save computational costs while still capturing sufficient periodic information within the detection window, we have chosen a 7-day detection window. The electricity consumption data from 5000 residential users is split into training, validation, and test sets in a ratio of 8:1:1. The training set is treated as clean, normal data for model training. In the validation and test sets, 10% of the data is randomly selected and tempered using the attack models described in
Section 4.2. The validation set is utilized for hyper-parameter tuning, while the test set is reserved for evaluating the model’s anomaly detection performance.
4.2. Attack Model
False data injection is a type of cyber attack in which manipulated or false information is deliberately introduced into a system to mislead its operations or decision-making processes. It is commonly employed to compromise the integrity of data in power systems, sensor networks, and other critical infrastructures.
In this study, to simulate various electricity theft patterns, six different false data injection attacks are implemented [
32,
33], as shown in
Table 2.
represents the electricity consumption data for a day, and
denotes the data at time
t after being subjected to an attack.
is the randomly chosen time period throughout a day.
is the randomly selected starting times, needing to meet that
. These attacks are broadly categorized into two types: reduced consumption attacks and load profile shifting attacks [
1]. Types 1–4 primarily reduce the electricity consumption recorded by the meter, while Types 5 and 6 shift electricity usage from high-price periods to low-price periods.
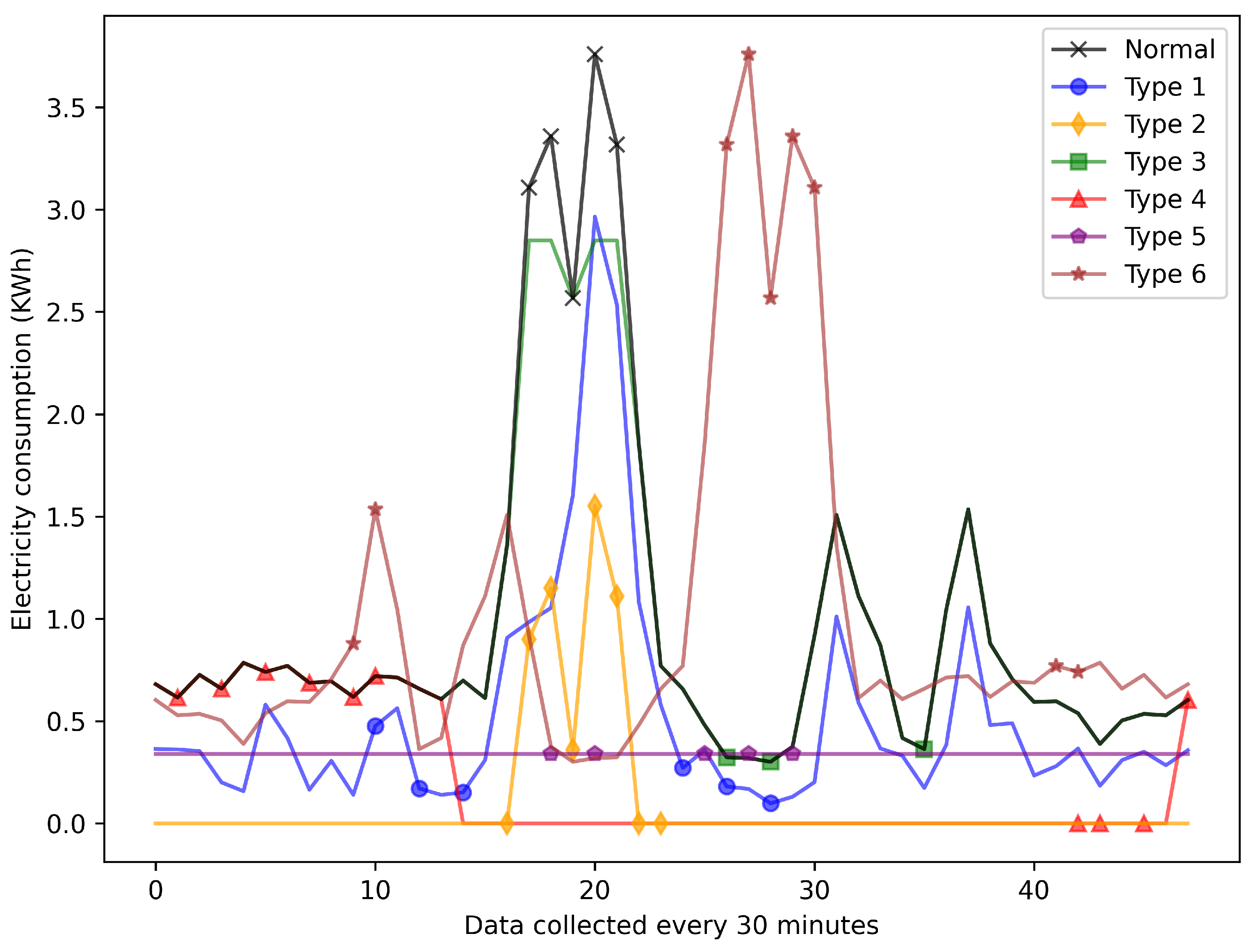
The physical interpretations of these six attacks are as follows: FDI1: Electricity consumption recorded at each time point is scaled down by a randomly selected proportion. FDI2: A constant value is subtracted from the electricity consumption data. FDI3: Electricity consumption values exceeding a preset threshold are capped at the threshold value. FDI4: Consumption data within a randomly selected time interval during the day are replaced with zeros. FDI5: The total daily electricity consumption is evenly distributed across all recording points and reduced by a fixed proportion. FDI6: The entire daily electricity consumption profile is inverted. Additionally,
Figure 5 illustrates examples of both normal electricity consumption data and data affected by each of these six attack types.
4.3. Evaluation Metrics
The confusion matrix quantifies all classification outcomes of a model, providing an intuitive representation of classification accuracy. In this paper, electricity theft samples are considered as the positive class, while normal electricity usage samples are treated as the negative class. The definitions of true positive (TP), false positive (FP), false negative (FN), and true negative (TN) are summarized in
Table 3.
Based on the above confusion matrix, we use the F1 score (F1), the area under the receiver operating characteristic (ROC) curve (AUC), recall, and false positive rate (FPR) to evaluate the performance of the proposed electricity theft detection framework.
, also known as true positive rate (
), evaluates a model’s effectiveness in identifying all actual positive instances within a dataset, highlighting its sensitivity to true positives. It is calculated as follows.
quantifies the rate at which negative samples are misclassified as positive, reflecting the model’s tendency for false alarms. It is computed as follows:
In anomaly detection, we generally aim for a model that has a low FPR while maintaining a high TPR.
quantifies the accuracy of positive predictions, calculated as follows:
captures the trade-off between
precision and
recall, offering a single metric to evaluate performance, particularly in scenarios with imbalanced data. It is calculated as follows:
AUC evaluates a model’s capability to differentiate between classes over varying decision thresholds, with larger values reflecting stronger discriminative power.
Model size reflects the storage space occupied by the model file. For devices with limited storage resources (such as smart meters), a smaller model size is important. In this article, model size refers to the size of the trained DNN model. The OC classifier (e.g., OCSVM/iForest/LOF) requires negligible additional storage.
Training time refers to the time required for a model to complete a full training cycle on the training data. For models in electricity theft detection that require frequent updates or retraining, a shorter training time is important. In this article, the training time is the sum of the DNN training time and the OC classifier training time.
Prediction speed reflects how many observations per second the model can process. For scenarios that require rapid response (such as electricity theft detection), a higher prediction speed is necessary.
4.4. Analysis of Model Hyper-Parameters
We applied grid search on the validation set to identify the optimal hyper-parameters. The selection ranges for each parameter and the corresponding best results are presented in
Table 4.
For the Periodicformer encoder, the hyper-parameters primarily consist of three components: the number of heads
H, the encoder embedding dimension
d, and the number of layers
N. The best results for
H,
d, and
N in this paper are consistent with those in Reference [
34]. As for the patch size for each layer
, this paper empirically concludes that the patch size should initially be larger and then gradually decrease. For LOF, we explore three values for number of neighbors
k, and test three different values for the contamination rate parameters to control the expected proportion or number of anomaly points. Additionally, we experiment two different distance metrics. The best combination of parameters was selected based on performance.
4.5. Comparison with Other Methods
In this part, we compare the the proposed method with six one-class classification-based ETD methods. We implement all these methods on the preprocessed data for fair comparison.
OCSVM [
35]: OCSVM is a support vector machine-based algorithm designed for anomaly detection. It distinguishes normal samples from anomalies by maximizing the margin between the data and the origin in the feature space. We set the kernel function and
parameters as ’linear’ and 0.2, respectively;
iForest [
36]: iForest is an efficient unsupervised anomaly detection method leveraging random forests. It isolates anomalies by exploiting their tendency to be easier to separate from the majority of the data through random partitioning. We set the contamination, maxFeatures, and nEstim parameters as 0.1, 0.6, and 300, respectively;
LOF [
37]: LOF is a density-based anomaly detection algorithm. It detects outliers by comparing the local density of a sample with the densities of its neighbors, identifying anomalies as points with significantly lower densities. We set the contamination rate as 0.1 while keeping other parameters as default;
Autoencoder with one-class (OC) classifier [
26]: Reference [
26] incorporates the concept of autoencoding and OC classification. We implement this method using CNN-AE(1D) as the autoencoder along with three OC classifiers.
Figure 6 shows the confusion matrix of different methods. Based on the confusion matrix, we can calculate recall, FPR, precision, and F1 score using the formulas mentioned above.
Table 5 presents the comparison results between our proposed method and six baseline methods, and the following findings can be observed:
Overall, the combination of the Periodicformer encoder and LOF achieved the best performance, with F1, AUC, recall, and FPR scores of 0.833, 0.973, 0.877, and 0.025, respectively. Compared to the second-best approach, the combination of autoencoder and LOF (F1, AUC, recall, and FPR scores of 0.814, 0.952, 0.856, and 0.027, respectively), it achieved improvements of 2.3%, 1.7%, 2.4%, and 8% in F1, AUC, recall, and FPR, respectively.
The three approaches that rely solely on the OC classifier exhibit relatively poor anomaly detection performance, with some even failing (defined as AUC or recall values below 0.5). This observation aligns with the findings reported in Reference [
26]. This suggests that the one-class classifier fails to effectively capture the distribution of normal samples in the training dataset, making it difficult to distinguish between normal and anomalous samples in the test set. This underscores the importance of designing a robust unsupervised representation learning method to extract meaningful features, aiding the one-class classifier in better modeling the distribution of normal samples and improving anomaly detection performance.
Comparing the proposed combination of the Periodicformer encoder and OC classifier with the combination of autoencoder and OC classifier, specifically the combination of the Periodicformer encoder and LOF versus autoencoder and LOF, the Periodicformer encoder demonstrates superior suitability for modeling time series data. Additionally, our proposed criss-cross periodic attention further enhances the model’s ability to capture richer periodic features, which helps distinguish normal data from anomalous data. In contrast, the autoencoder relies solely on CNN to capture local features without considering the periodicity of time series data, resulting in poorer performance;
In the three combinations of the Periodicformer encoder with different OC classifiers, the scheme combined with iForest yields the poorest performance. According to Reference [
38], iForest is sensitive only to global outliers and struggles with detecting local outliers. The distribution of power theft behavior data is particularly unfavorable for iForest detection. For instance, when considering an entire year (365 days), power theft typically occurs on specific days or weeks. These anomalies may not be noticeable when viewed in the context of the whole year. However, when compared to adjacent days or weeks, these outliers may become more apparent. This is precisely where iForest’s limitations lie. Regarding the combination with OCSVM, Reference [
39] states that OCSVM is sensitive to noise and prone to false positives, which aligns with our experimental findings. Although it achieves a high recall, it also results in a relatively high false positive rate.
Compared to the other six methods, our proposed PE-DOCC has a larger model size (
bytes, which is approximately 3.11 MB), a longer training time (around 700 s), and a slower prediction speed (around 150 observations per second). However, in our experimental scenario with 5000 users uploading electricity consumption records every 30 min, we can calculate that the minimum acceptable and reasonable prediction speed range is 3–5 observations per second. Our prediction speed far exceeds this range, meeting the requirements for this scenario. Additionally, the model size is only 3.11 MB, which is also applicable for a smart meter.
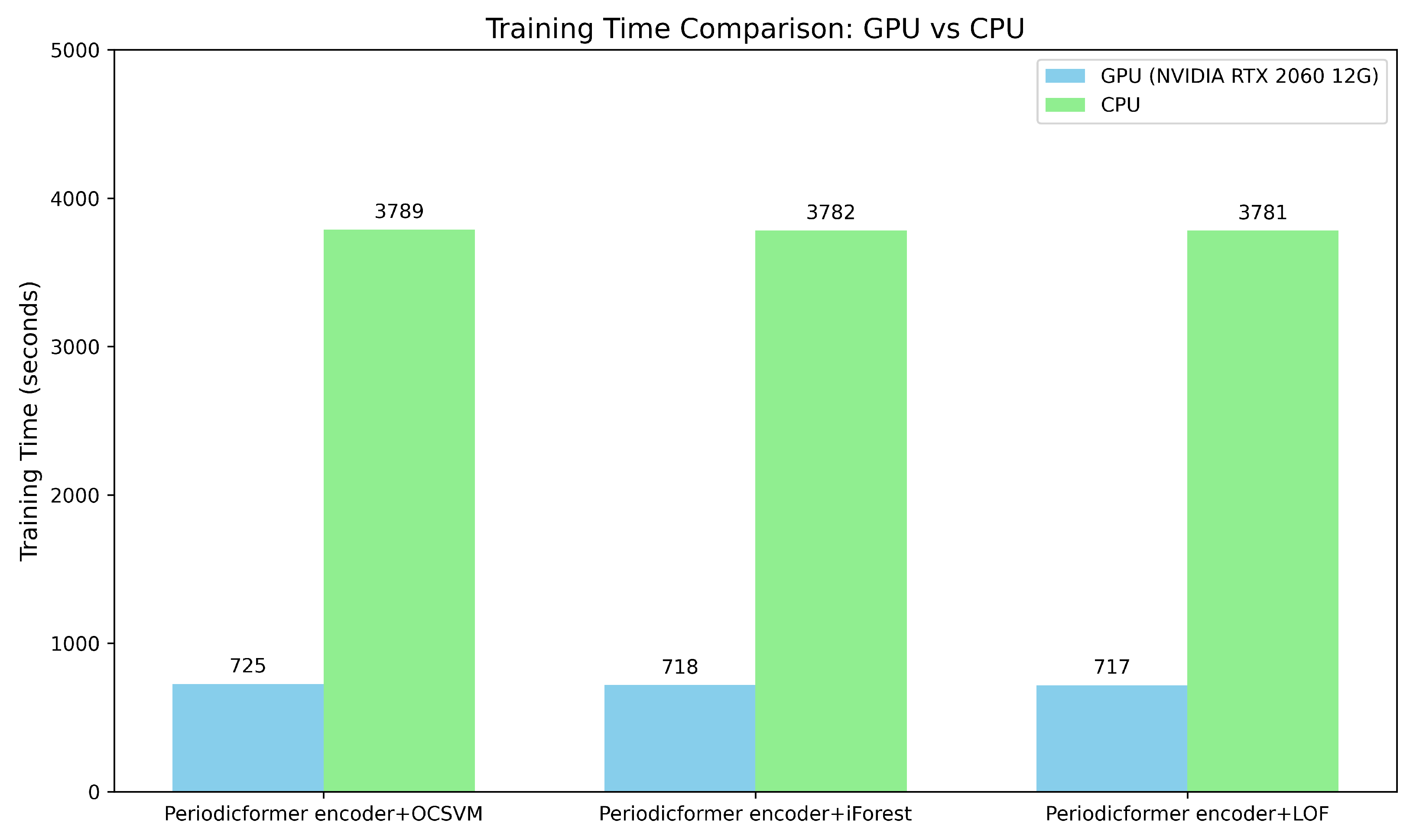
Figure 7 compares the training time of the proposed PE-DOCC with GPU acceleration (NVIDIA GeForce RTX 2060 12 G) and without GPU acceleration (CPU). The training time of our proposed PE-DOCC solution on a CPU is approximately 3780 s, which is about one hour. The training for electricity theft detection is typically conducted offline, and our solution follows the same approach; thus, it does not affect the efficiency of real-time detection. If the model requires daily updates, the one-hour training time can be scheduled during off-peak hours (e.g., early morning) without impacting real-time predictions. If the model only needs to be updated weekly or monthly, the one-hour training time is entirely acceptable and will not impose any significant burden on the system.
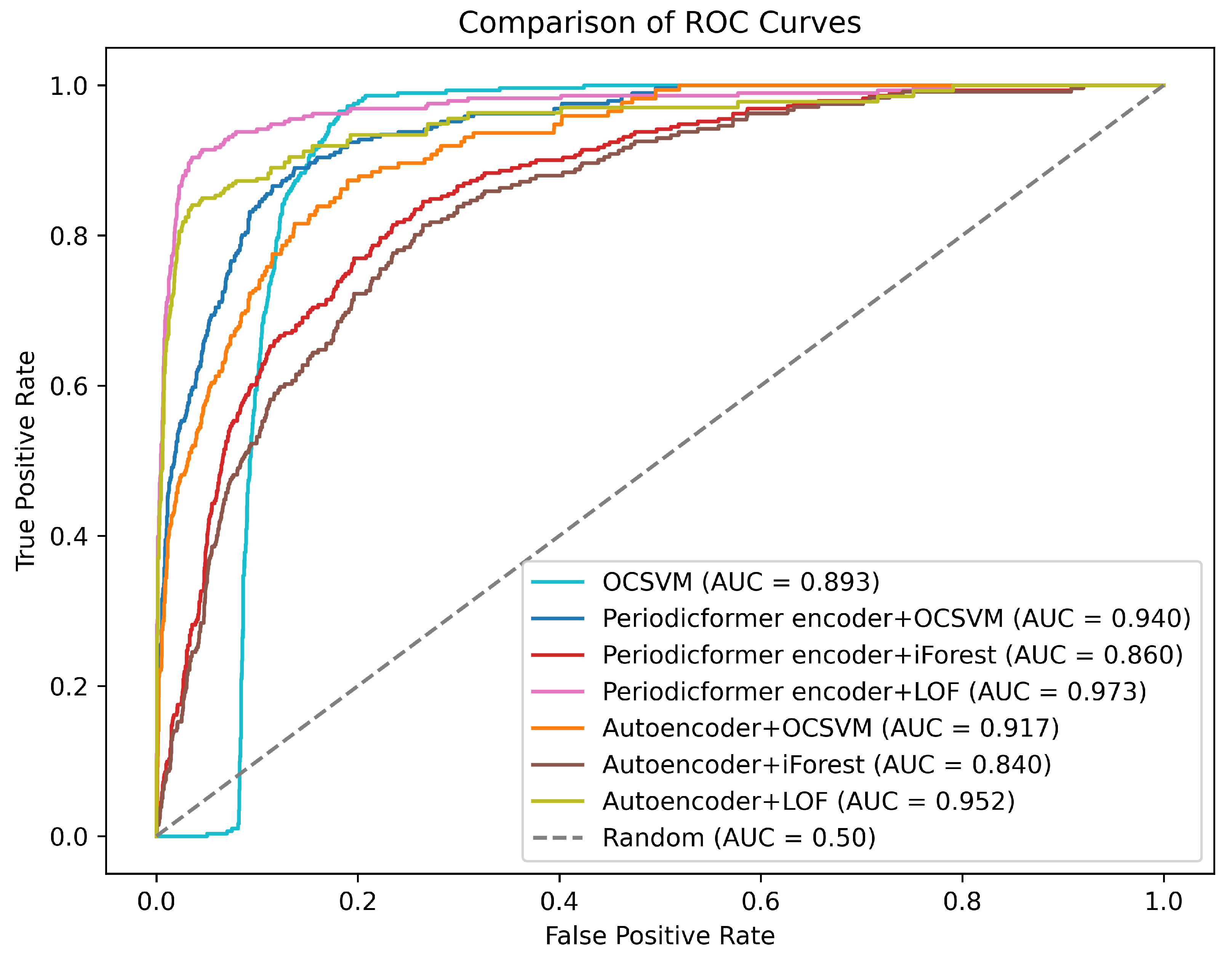
For anomaly detection tasks, our goal is to develop a model that achieves a low false positive rate (FPR) while maintaining a high true positive rate (TPR). To showcase the performance of all the methods in this regard, we have plotted the ROC curve, as shown in
Figure 8. The proposed combination of the Periodicformer encoder and LOF achieves the highest TPR at the lowest FPR, and the combination of autoencoder, and iForest yields the poorest performance.
Figure 7.
Comparison of training time with and without GPU acceleration.
Figure 7.
Comparison of training time with and without GPU acceleration.
Figure 8.
ROC curves of the proposed method and other methods and the value of the area under each curve AUC.
Figure 8.
ROC curves of the proposed method and other methods and the value of the area under each curve AUC.
4.6. Ablation Analysis
An ablation study is conducted to demonstrate the impact of the main components in the proposed framework on the ETD performance. Specifically, three variants of our proposed method are implemented:
RA-DOCC: This method uses a combination of a Periodicformer encoder with only row autocorrelation and LOF.
CA-DOCC: This method uses a combination of a Periodicformer encoder with only column autocorrelation and LOF.
Vanilla-DOCC: This method uses a combination of a vanilla Transformer encoder [
40] and LOF.
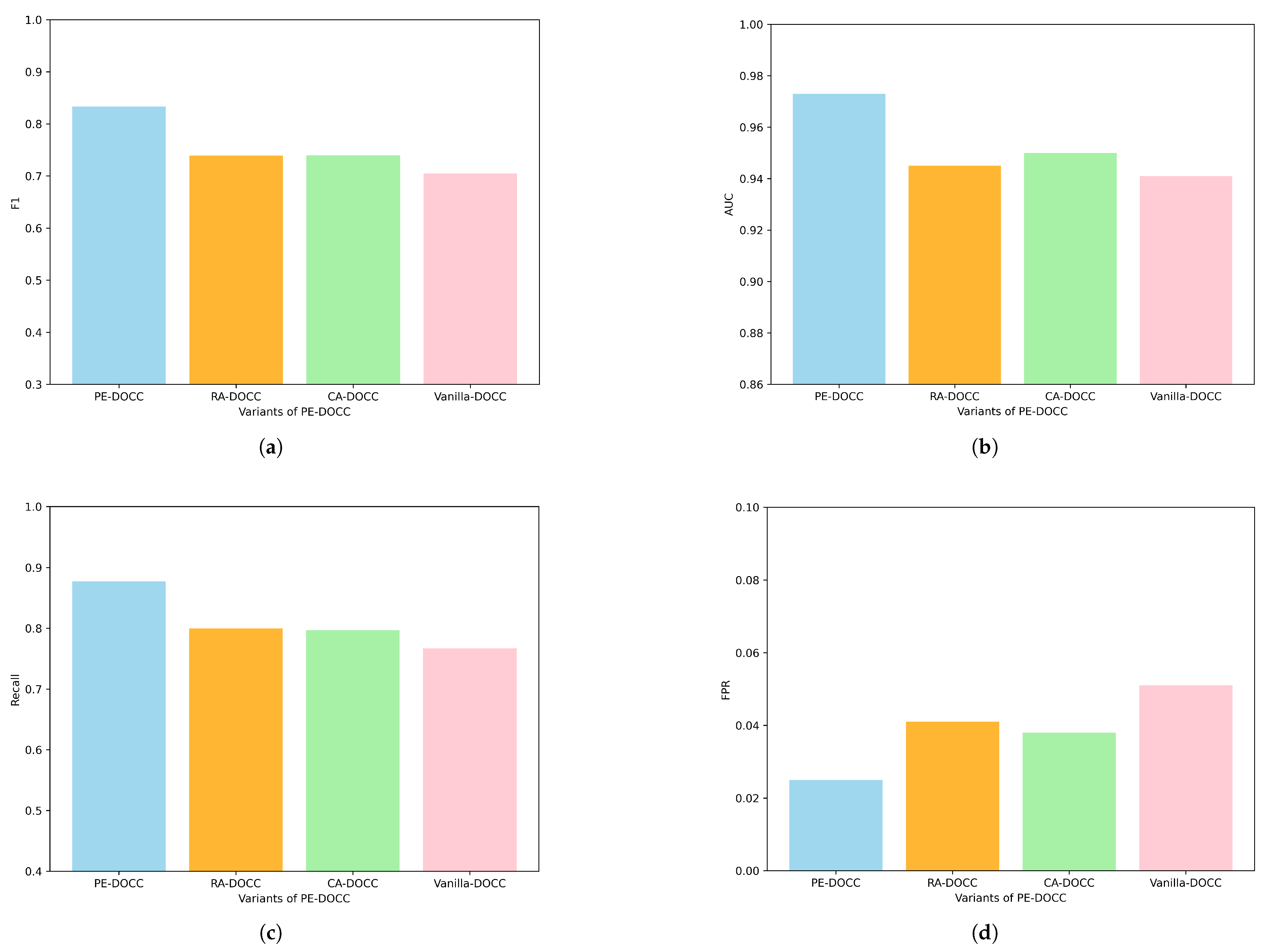
Figure 9 shows the results of the ablation experiments, from which the following findings can be drawn:
RA-DOCC and CA-DOCC produce comparable experimental results, but show notable improvements over Vanilla-DOCC. Specifically, F1, AUC, recall, and FPR improve by approximately 5%, 1%, 4%, and 34%, respectively. This suggests that row autocorrelation and column autocorrelation are all effective in capturing periodic features, which help the model distinguish anomalous samples.
Our proposed criss-cross periodic attention effectively integrates multiple periodic features. Compared to the vanilla Transformer encoder, F1, AUC, recall, and FPR have improved by 15.3%, 3.2%, 12.5%, and 104%, respectively.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}