
Research on Price Prediction of Construction Materials Based on VMD-SSA-LSTM


Abstract
1. Introduction
1.1. Background and Significance of the Research
- Reducing cost uncertainties and improving budget accuracy: accurate price forecasting mitigates the impact of material price fluctuations on budgeting, thereby enhancing the reliability of financial planning for projects.
- Supporting decision-making and optimizing risk mitigation strategies: reliable predictions form a strong basis for implementing risk management measures, such as hedging and fixed-price contracts.
- Enhancing risk management capabilities and minimizing schedule delays and contractual disputes: fluctuations in material prices frequently lead to project schedule adjustments and contractual conflicts, which can be mitigated through accurate price forecasting.
- Strengthening corporate competitiveness: the ability to accurately predict material prices constitutes a strategic advantage, enabling firms to submit more competitive bids in tendering processes.
1.2. Current Status of Research
1.3. Innovation Points

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Characteristics | Limitations | Submitter |
|---|---|---|---|---|
| Statistical models | ARIMA | Time series analysis, suitable for linear and stationary data | Assumes linearity and stationarity, cannot handle nonlinearity | Suad H et al. [18]; Wang J et al. [19,20] |
| GM (1,1) | Grey forecasting, analyzes small sample data | Sensitive to input data quality, poor for long-term forecasting | Wang Y [17] | |
| Machine learning | Support Vector Machine (SVM) | Regression modeling for small to medium datasets | Sensitive to parameter tuning, requires thorough preprocessing | Tang B et al. [28] |
| Artificial Neural Networks (ANN) | Mimics brain structure, strong nonlinear modeling | Prone to overfitting, demands large datasets and computational resources | Jiang J et al. [15]; Mir Mostafa et al. [12] | |
| Long Short-Term Memory (LSTM) | A type of recurrent neural network, captures long-term dependencies | Sensitive to noise and non-stationary data, complex optimization | Huang C et al. [23]; Fang J et al. [24]; | |
| Hybrid approaches | GM (1,1) + BP Neural Network | Combines grey forecasting and neural networks for improved accuracy | Higher computational complexity | Luo Z et al. [26] |
| LSTM + Data Preprocessing | Combines interpolation, noise reduction, normalization with LSTM | Complex preprocessing, high implementation requirements | Peng Y et al. [22] | |
| LSTM +VMD | Signal decomposition (VMD) + LSTM | High computational cost, complex implementation and validation | Wang J et al. [31] | |
| LSTM + SSA | Optimization (SSA) + LSTM | High computational cost, complex implementation and validation | Zhao J et al. [32] | |
| Optimization algorithms | genetic algorithm (GA) or particle swarm optimization (PSO) | Optimizes neural network parameters | Prone to local optima, sensitive to initial parameters | Shiha A et al. [27]; Tu J et al. [25]; Tang B et al. [28] |
2. Methodology
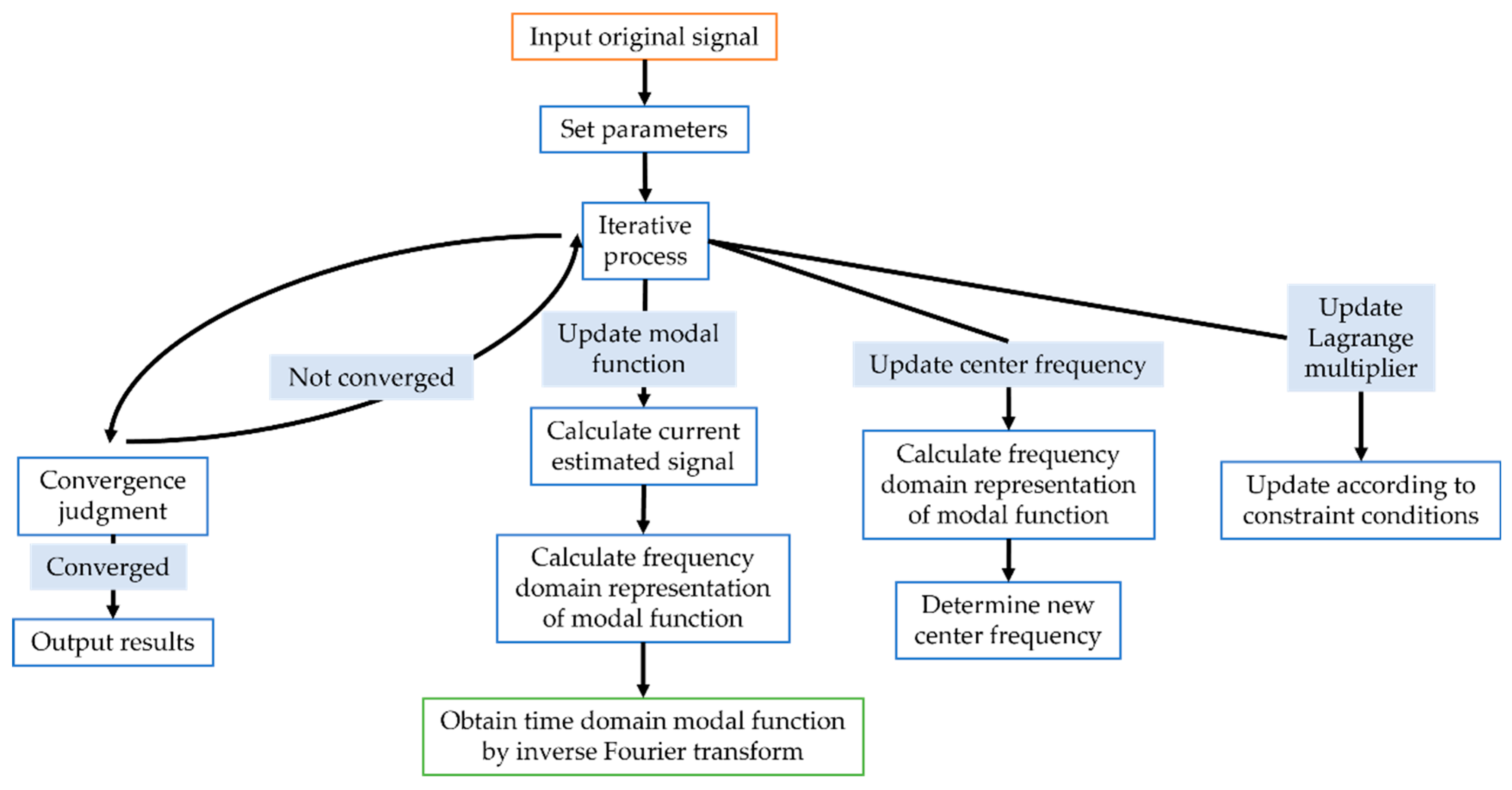
2.1. Variational Mode Decomposition (VMD)
2.2. Optimization Algorithm
- Producer update: A portion of sparrows (usually a certain percentage of the population, such as 10–20%) are considered producers. They are responsible for finding better food resources (i.e., better solutions) in the search space. The position update formula for producers is as follows:
- 2.
- Consumer update: The remaining sparrows are considered consumers. They follow the producers to find food resources. Consumer sparrows update their positions by randomly selecting a producer and approaching it. At the same time, they are also influenced by random factors to increase search diversity. The position update formula for consumers is as follows:
- 3.
- Scout update: In the sparrow population, there will also be some sparrows acting as scouts, responsible for monitoring the danger of the surrounding environment. When the warning value is less than the safety value, the scouts will guide the sparrow group to fly to other safe places. The position update formula for scouts is as follows:
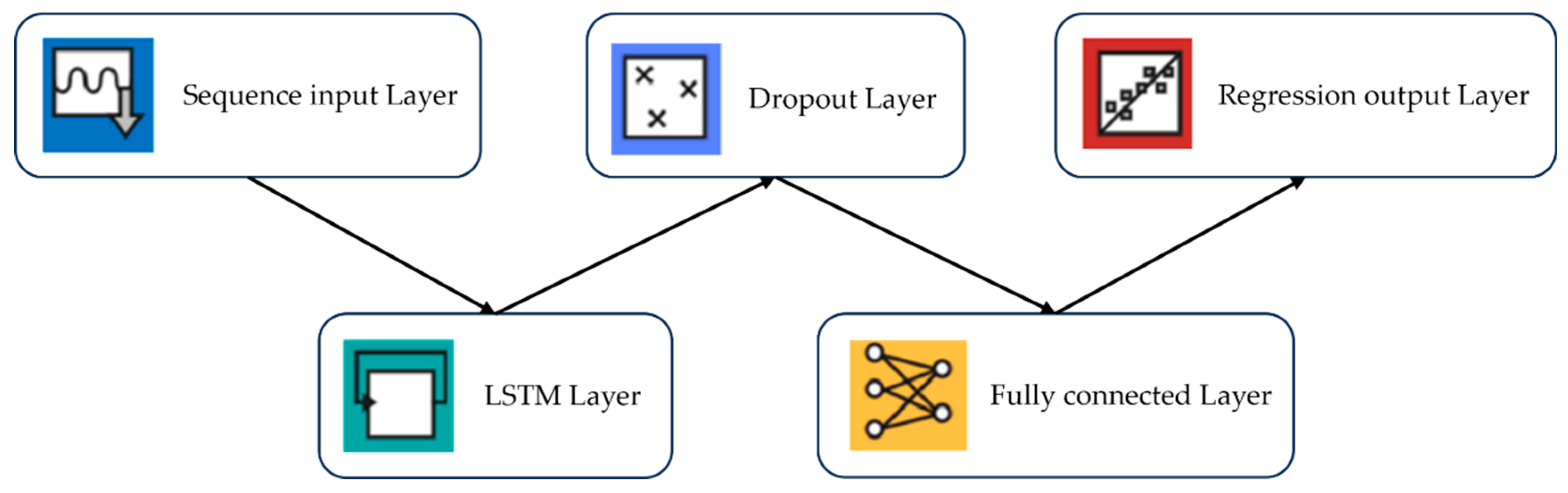
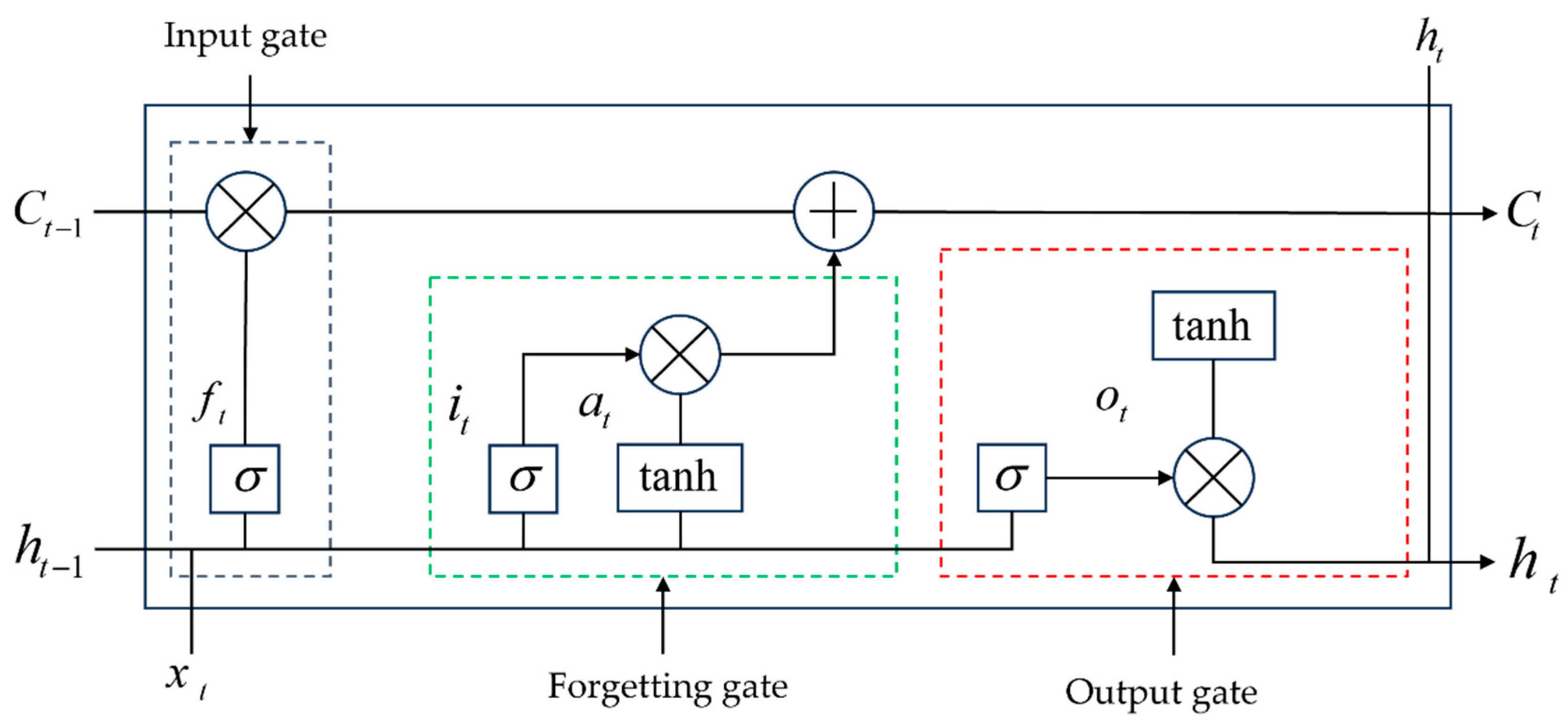
2.3. Long Short-Term Memory (LSTM)
3. Model Established
3.1. VMD-SSA-LSTM Model Established
3.2. Model Evaluation
3.3. Parameter Settings
3.3.1. LSTM Initial Hyperparameter Settings
3.3.2. SSA Initial Hyperparameter Settings
3.3.3. VMD Initial Hyperparameter Settings
4. Experimental Data Processing and Analysis
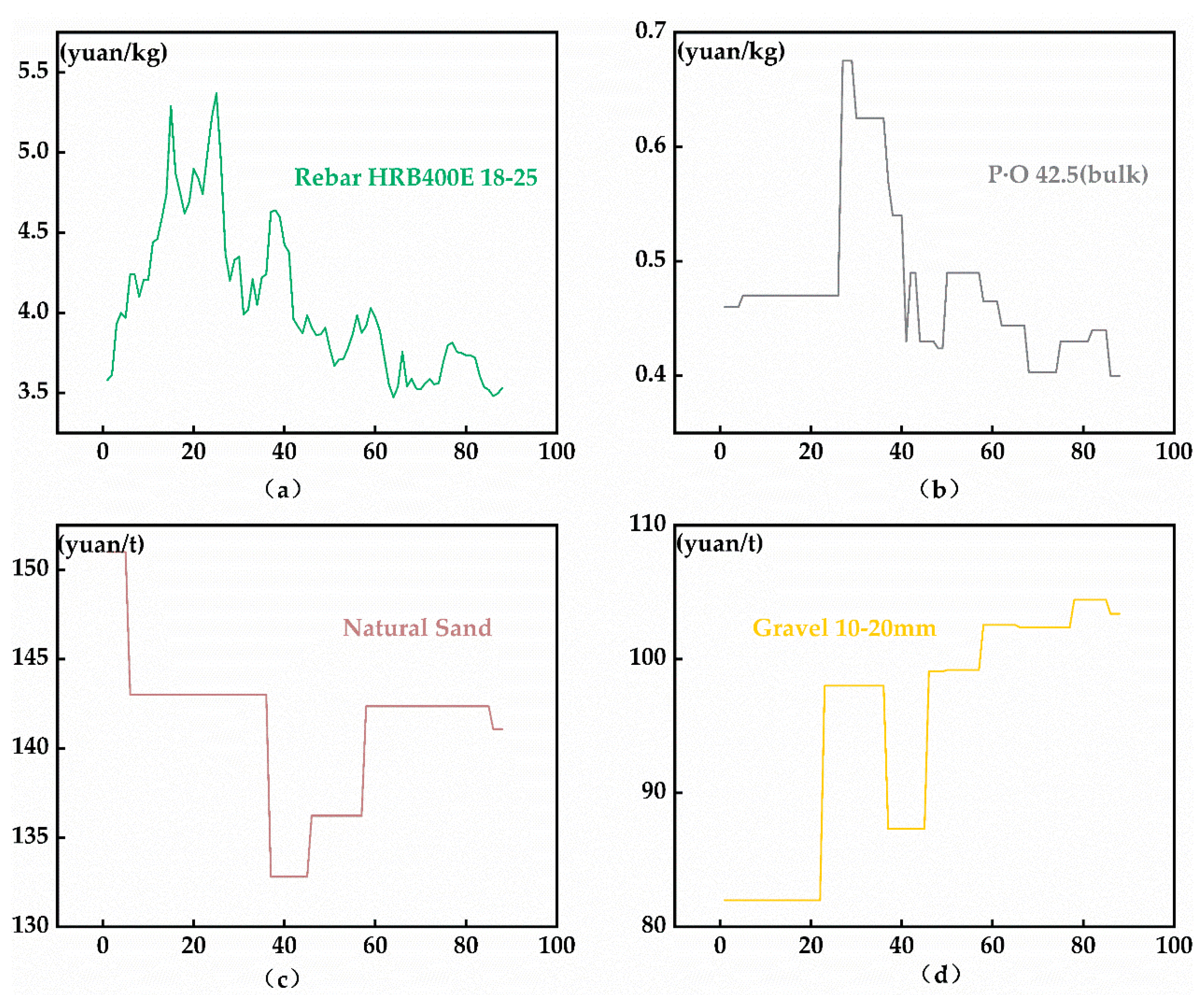
4.1. CMP Analysis
4.2. Data Pre-Processing
- Missing data
- 2.
- Normalization data
5. Model Application and Results Discussion
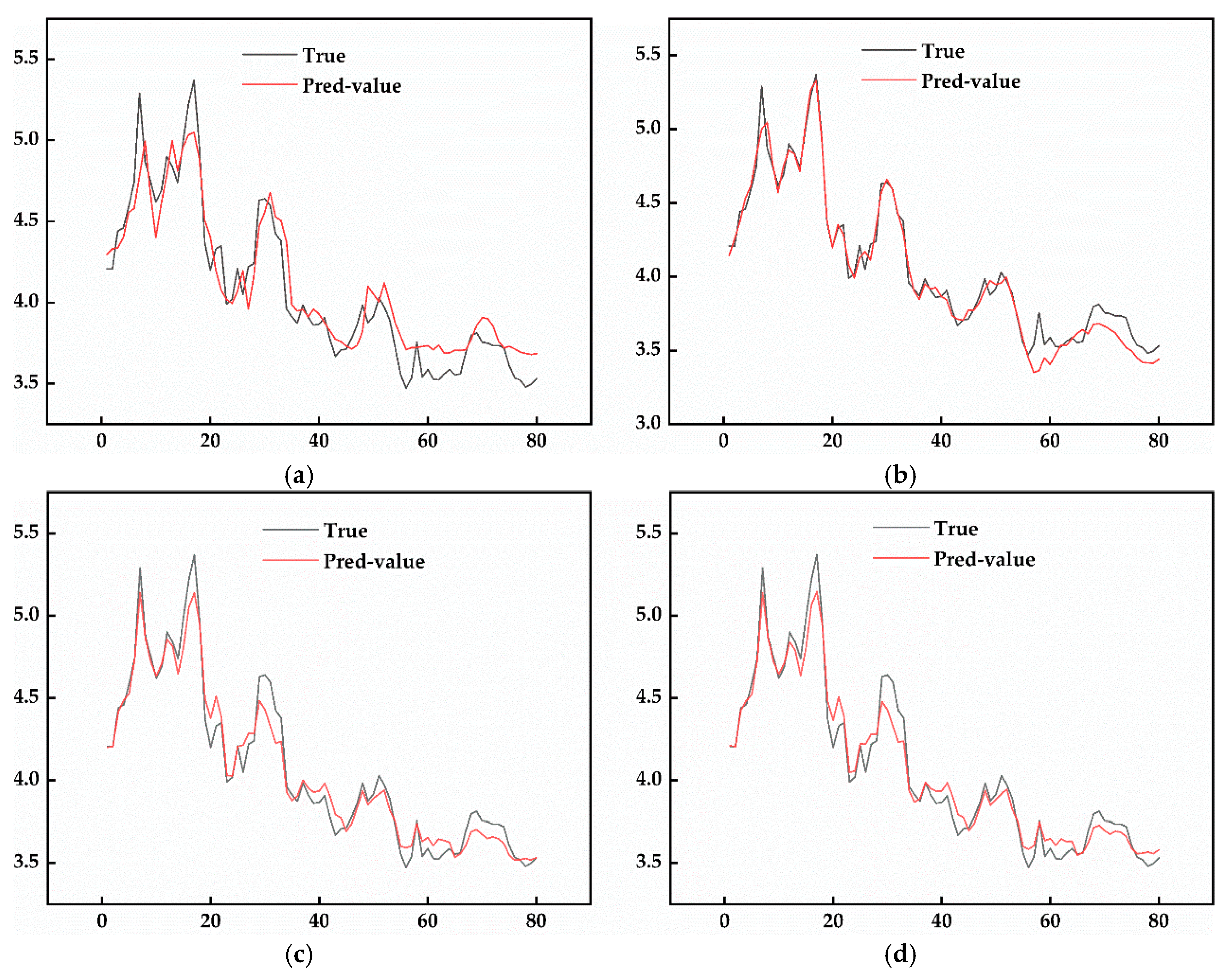
5.1. Model Application Comparison
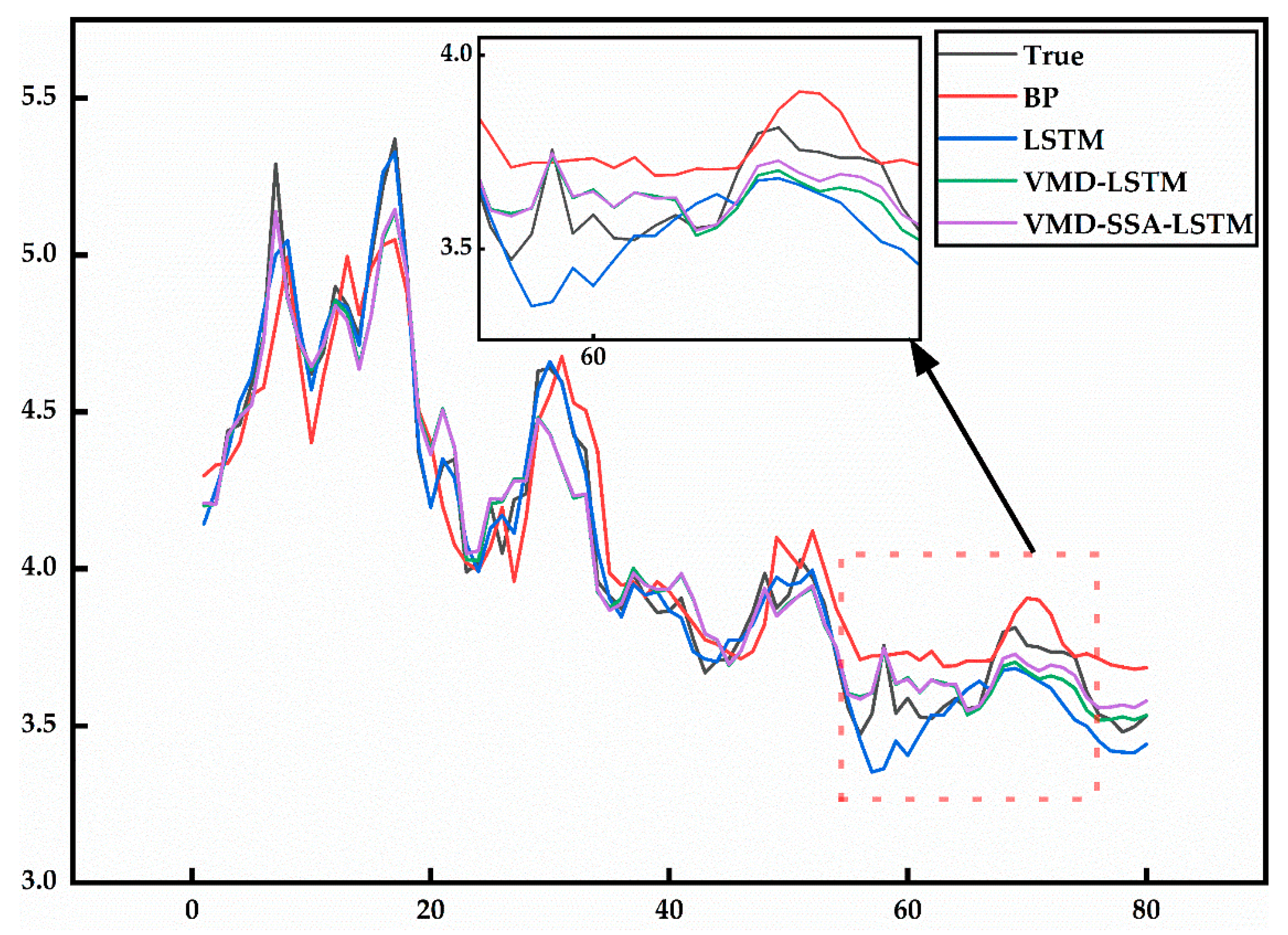
5.2. Results Discussion
- The model’s RMSE is reduced by 41.22% compared to the BP model and by 2.99% compared to the standalone LSTM model, indicating superior performance in capturing complex price patterns.
- The R2 value for the VMD-SSA-LSTM model is 96.532%, showcasing its robustness in fitting observed data.
6. Conclusions
- A novel framework is developed for CMP forecasting that surpasses traditional methods in both accuracy and stability. By employing VMD to decompose and denoise the data, critical features are extracted, enhancing data quality and mitigating the limitations of single-model approaches that often result from insufficient data learning. Furthermore, SSA addresses issues like rapid convergence and local optima, complementing the LSTM model and significantly improving its predictive performance and robustness.
- The constructed VMD-SSA-LSTM prediction model shows a reduction in RMSE of 2.68% compared to the VMD-LSTM model, 2.99% compared to the single LSTM model, and 41.22% compared to the BP model. Additionally, the R2 values increase by 0.196%, 0.217%, and 6.566%, respectively. The model enhances budget accuracy by reducing material price prediction errors by over 40% compared to traditional methods, leading to better financial planning and fewer cost overruns.
- Risk mitigation and strategic planning: accurate forecasts allow companies to proactively manage risks by locking in prices or adjusting project schedules, minimizing financial uncertainties and delays.
- Optimized resource allocation and bidding: the model’s improved predictive accuracy supports efficient resource allocation, competitive bidding, and strategic procurement, helping firms stay within budget and maintain profitability.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barg, S.; Flager, F.; Fischer, M. An analytical method to estimate the total installed cost of structural steel building frames during early design. J. Build. Eng. 2018, 15, 41–50. [Google Scholar] [CrossRef]
- Tao, X.; Li, Y. Research on risk management of material price in engineering cost control. Constr. Econ. 2006, 7, 73–75. [Google Scholar]
- Bayram, S.; Al-Jibouri, S. Efficacy of estimation methods in forecasting building projects’ costs. J. Constr. Eng. Manag. 2016, 142, 05016012. [Google Scholar] [CrossRef]
- Wang, X.; Xing, L. Significant project cost estimation method based on BP neural network. People’s Yellow River 2011, 33, 115–116+119. [Google Scholar]
- Weidman, J.E.; Miller, K.R.; Christofferson, J.P.; Newitt, J. Best practices for dealing with price volatility in commercial construction. Int. J. Constr. Educ. Res. 2011, 7, 276–293. [Google Scholar] [CrossRef]
- Hwang, S.; Park, M.; Lee, H.S.; Kim, H. Automated time-series cost forecasting system for construction materials. J. Constr. Eng. Manag. 2012, 138, 1259–1269. [Google Scholar] [CrossRef]
- Shahandashti, S.M.; Ashuri, B. Forecasting engineering news-record construction cost index using multivariate time series models. J. Constr. Eng. Manag. 2013, 139, 1237–1243. [Google Scholar] [CrossRef]
- Lu, Y.; Nie, C.; Zhou, D.; Shi, L. Research on programmatic multi-attribute decision-making problem: An example of bridge pile foundation project in karst area. PLoS ONE 2023, 18, e0295296. [Google Scholar] [CrossRef]
- Joukar, A.; Nahmens, I. Volatility forecast of construction cost index using general autoregressive conditional heteroskedastic method. J. Constr. Eng. Manag. 2016, 142, 04015051. [Google Scholar] [CrossRef]
- Cao, M.T.; Cheng, M.Y.; Wu, Y.W. Hybrid computational model for forecasting Taiwan construction cost index. J. Constr. Eng. Manag. 2015, 141, 04014089. [Google Scholar] [CrossRef]
- Elfahham, Y. Estimation and prediction of construction cost index using neural networks, time series, and regression. Alex. Eng. J. 2019, 58, 499–506. [Google Scholar] [CrossRef]
- Mir, M.; Kabir, H.M.D.; Nasirzadeh, F.; Khosravi, A. Neural network-based interval forecasting of construction material prices. J. Build. Eng. 2021, 39, 102288. [Google Scholar] [CrossRef]
- Yip, H.; Fan, H.; Chiang, Y. Predicting the maintenance cost of construction equipment: Comparison between general regression neural network and Box–Jenkins time series models. Autom. Constr. 2014, 38, 30–38. [Google Scholar] [CrossRef]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Jiang, J.; Qi, C.; Bo, B.; Li, P. Research on Prediction of Construction Material Prices Based on BP Neural Network. Proj. Manag. Technol. 2022, 20, 24–27. [Google Scholar]
- Ouyang, H.; Li, X.; Zhang, X. Application of Artificial Neural Network in the Prediction of Building Material Prices. J. Wuhan Univ. Technol. (Inf. Manag. Eng.) 2013, 35, 115–118. [Google Scholar]
- Wang, Y. Major Material Price Forecast based on GM (1,1) Grey Dynamic Model in Tender Offer. Railw. Eng. Technol. Econ. 2013, 28, 39–43. [Google Scholar]
- Suad, H.; Elshaimaa, E.; Hossam, H. Prediction of construction material prices using ARIMA and multiple regression models. Asian J. Civ. Eng. 2023, 24, 1697–1710. [Google Scholar]
- Wang, J.; Fang, X. Price prediction of mass engineering materials based on ARIMA construction research. Eng. Cost Manag. 2020, 65–75. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C. Analysis and Prediction of Building Material Prices. Energy Conserv. 2015, 34, 7–10. [Google Scholar]
- Nguyen, V.H.; Naeem, A.M.; Wichitaksorn, N.; Pears, R. A smart system for short-term price prediction using time series models. Comput. Electr. Eng. 2019, 76, 339–352. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, Y.; Zhang, R. Modeling and analysis of stock price forecast based on LSTM. Comput. Eng. Appl. 2019, 55, 209–212. [Google Scholar]
- Huang, C.; Cheng, X. Research on Stock Price Prediction Based on LSTM Neural Network. J. Beijing Inf. Sci. Technol. Univ. (Sci. Technol. Ed.) 2021, 36, 79–83. [Google Scholar] [CrossRef]
- Fang, J.; Liu, H.; Hu, Y. Soybean Futures Price Prediction Based on LSTM Deep Learning. Prices Mon. 2021, 7–15. [Google Scholar] [CrossRef]
- Tu, J.; Liu, Y.; Zhou, M.; Li, R. Prediction and analysis of compressive strength of recycled aggregate thermal insulation concrete based on GA-BP optimization network. J. Eng. Des. Technol. 2021, 19, 412–422. [Google Scholar] [CrossRef]
- Luo, Z.; Bu, Y. Research on Price Forecast Method of Building Materials Based on Grey Neural Network PGNN Model. Constr. Econ. 2020, 41, 115–120. [Google Scholar] [CrossRef]
- Shiha, A.; Dorra, M.E.; Nassar, K. Neural Networks Model for Prediction of Construction Material Prices in Egypt Using Macroeconomic Indicators. J. Constr. Eng. Manag. 2020, 146, 04020010. [Google Scholar] [CrossRef]
- Tang, B.; Han, J.; Guo, G.; Yi, C.; Sai, Z. Building material prices forecasting based on least square support vector machine and improved particle swarm optimization. Archit. Eng. Des. Manag. 2019, 15, 196–212. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Zhou, X.; Zhang, K. Ultra-short-term wind speed prediction based on VMD-LSTM. Power Syst. Prot. Control 2020, 48, 45–52. [Google Scholar] [CrossRef]
- Zhao, J.; Chi, Y.; Zhou, Y. Short-term power load forecasting based on SSA-LSTM model. Adv. Technol. Electr. Eng. Energy 2022, 41, 71–79. [Google Scholar]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, C.A. Mean squared error: Lot it or leave it? A new look at Signal Fidelity Measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Cameron, A.C.; Windmeijer, F.A.G. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econom. 1997, 77, 329–342. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Chen, T.; Wang, Y. Analysis of Budget and Control of New Green Buildings’ Project Cost. Eng. Econ. 2015, 31–36. [Google Scholar] [CrossRef]




| Max Epochs | Initial Learn Rate | Learn Rate Drop Period | Learn Rate Drop Factor | L2 Regularization | Hidden-Layer Units |
|---|---|---|---|---|---|
| 1200 | 0.005 | 600 | 0.2 | 0.0001 | 35 |
| K | Data | Evaluating Indicator | |
|---|---|---|---|
| RMSE | MAE | ||
| 7 | Train | 0.016 | 0.012 |
| Test | 0.015 | 0.013 | |
| 8 | Train | 0.012 | 0.009 |
| Test | 0.026 | 0.022 | |
| 9 | Train | 0.018 | 0.015 |
| Test | 0.025 | 0.019 | |
| 10 | Train | 0.016 | 0.012 |
| Test | 0.018 | 0.015 | |
| Model | /% | ||
|---|---|---|---|
| BP | 0.1543 | 0.1271 | 89.966 |
| LSTM | 0.0935 | 0.0681 | 96.315 |
| VMD-LSTM | 0.0932 | 0.0712 | 96.336 |
| VMD-SSA-LSTM | 0.0907 | 0.0699 | 96.532 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, S.; Nie, C.; Lu, Y.; Zheng, J. Research on Price Prediction of Construction Materials Based on VMD-SSA-LSTM. Appl. Sci. 2025, 15, 2005. https://doi.org/10.3390/app15042005
Xiong S, Nie C, Lu Y, Zheng J. Research on Price Prediction of Construction Materials Based on VMD-SSA-LSTM. Applied Sciences. 2025; 15(4):2005. https://doi.org/10.3390/app15042005
Chicago/Turabian StyleXiong, Sheng, Chunlong Nie, Yixuan Lu, and Jieshu Zheng. 2025. "Research on Price Prediction of Construction Materials Based on VMD-SSA-LSTM" Applied Sciences 15, no. 4: 2005. https://doi.org/10.3390/app15042005
APA StyleXiong, S., Nie, C., Lu, Y., & Zheng, J. (2025). Research on Price Prediction of Construction Materials Based on VMD-SSA-LSTM. Applied Sciences, 15(4), 2005. https://doi.org/10.3390/app15042005