
Lightweight Deepfake Detection Based on Multi-Feature Fusion


Abstract
1. Introduction
- The proposed fusion model introduces a novel approach to deepfake detection on platforms with limited memory and processing capabilities, effectively managing compressed video data;
- Using existing classification techniques for artifact analysis, the method achieves substantial data reduction while preserving detection accuracy;
- The methodology combines forty established ML classifiers (using HOG, LBP, and KAZE features) with diverse texture-based features, demonstrating reliable performance even with limited datasets;
- The evaluation primarily uses the Face Forensic++ dataset, which reflects real-world scenarios and emphasizes minimizing computational overhead.
2. Related Works
3. Proposed Fusion Model
3.1. LBP Features
3.2. HOG Features
- Gradient Calculation: For each pixel in the image, the gradients along the x- and y-axes are calculated using Sobel filters:The magnitude M and direction of the gradient are computed as:
- Cell Histogram Generation: The gradient magnitudes M are binned into orientation histograms, where the direction is quantized into a fixed number of bins (e.g., 9 bins for 0°–180° or 18 bins for 0°–360°). To improve invariance to illumination and contrast changes, the histograms are normalized within overlapping spatial blocks. Given a block B, normalization can be performed as:where is a small constant to prevent division by zero.
- Feature Vector Construction: The normalized histograms obtained from all the blocks are concatenated to form a single feature vector representing the image. HOG captures fine-grained details about edge orientations and their distribution, making it suitable for identifying subtle spatial distortions caused by deepfake manipulations.
- Cell Size: pixels;
- Block Size: cells;
- Number of Orientation Bins: 9 (0°–180°);
- Step Size: overlap between blocks.
3.3. KAZE Features
3.4. Proposed Feature Fusion and Classification
| Algorithm 1 Algorithm for merging LBP/HOG and KAZE features and classification |
| Require: Set of images , corresponding labels . Ensure: Classification accuracy.
|
4. Implementation
4.1. Experimental Design
4.2. Evaluation Criteria
4.3. Results and Discussion
4.4. Future Work and Implications of Visual Information Security
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kharvi, P.L. Understanding the Impact of AI-Generated Deepfakes on Public Opinion, Political Discourse, and Personal Security in Social Media. IEEE Secur. Priv. 2024, 22, 115–122. [Google Scholar] [CrossRef]
- Domenteanu, A.; Tătaru, G.C.; Crăciun, L.; Molănescu, A.G.; Cotfas, L.A.; Delcea, C. Living in the Age of Deepfakes: A Bibliometric Exploration of Trends, Challenges, and Detection Approaches. Information 2024, 15, 525. [Google Scholar] [CrossRef]
- Bale, D.; Ochei, L.; Ugwu, C. Deepfake Detection and Classification of Images from Video: A Review of Features, Techniques, and Challenges. Int. J. Intell. Inf. Syst. 2024, 13, 20–28. [Google Scholar] [CrossRef]
- Vijaya, J.; Kazi, A.A.; Mishra, K.G.; Praveen, A. Generation Furthermore, Detection of Deepfakes using Generative Adversarial Networks (GANs) and Affine Transformation. In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, J.; Jang, J.; Lee, J.; Chun, D.; Kim, H. CNN-Based Mask-Pose Fusion for Detecting Specific Persons on Heterogeneous Embedded Systems. IEEE Access 2021, 9, 120358–120366. [Google Scholar] [CrossRef]
- Lee, S.I.; Kim, H. GaussianMask: Uncertainty-aware Instance Segmentation based on Gaussian Modeling. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 3851–3857. [Google Scholar]
- Chun, D.; Lee, S.; Kim, H. USD: Uncertainty-Based One-Phase Learning to Enhance Pseudo-Label Reliability for Semi-Supervised Object Detection. IEEE Trans. Multimed. 2024, 26, 6336–6347. [Google Scholar] [CrossRef]
- Lee, J.J.; Kim, H. Multi-Step Training Framework Using Sparsity Training for Efficient Utilization of Accumulated New Data in Convolutional Neural Networks. IEEE Access 2023, 11, 129613–129622. [Google Scholar] [CrossRef]
- Abbas, F.; Taeihagh, A. Unmasking deepfakes: A systematic review of deepfake detection and generation techniques using artificial intelligence. Expert Syst. Appl. 2024, 252, 124260. [Google Scholar] [CrossRef]
- Naskar, G.; Mohiuddin, S.; Malakar, S.; Cuevas, E.; Sarkar, R. Deepfake detection using deep feature stacking and meta-learning. Heliyon 2024, 10, e25933. [Google Scholar] [CrossRef]
- Rana, M.S.; Murali, B.; Sung, A.H. Deepfake Detection Using Machine Learning Algorithms. In Proceedings of the 2021 10th International Congress on Advanced Applied Informatics (IIAI-AAI), Niigata, Japan, 11–16 July 2021; pp. 458–463. [Google Scholar] [CrossRef]
- Tsalera, E.; Papadakis, A.; Samarakou, M.; Voyiatzis, I. Feature Extraction with Handcrafted Methods and Convolutional Neural Networks for Facial Emotion Recognition. Appl. Sci. 2022, 12, 8455. [Google Scholar] [CrossRef]
- Moore, S.; Bowden, R. Local binary patterns for multi-view facial expression recognition. Comput. Vis. Image Underst. 2011, 115, 541–558. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the European Conference on Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 214–227. [Google Scholar]
- Huda, N.u.; Javed, A.; Maswadi, K.; Alhazmi, A.; Ashraf, R. Fake-checker: A fusion of texture features and deep learning for deepfakes detection. Multimed. Tools Appl. 2024, 83, 49013–49037. [Google Scholar] [CrossRef]
- Khalid, N.A.A.; Ahmad, M.I.; Chow, T.S.; Mandeel, T.H.; Mohammed, I.M.; Alsaeedi, M.A.K. Palmprint recognition system using VR-LBP and KAZE features for better recognition accuracy. Bull. Electr. Eng. Inform. 2024, 13, 1060–1068. [Google Scholar] [CrossRef]
- Ghosh, B.; Malioutov, D.; Meel, K.S. Efficient Learning of Interpretable Classification Rules. J. Artif. Intell. Res. 2022, 74, 1823–1863. [Google Scholar] [CrossRef]
- Patel, Y.; Tanwar, S.; Gupta, R.; Bhattacharya, P.; Davidson, I.E.; Nyameko, R.; Aluvala, S.; Vimal, V. Deepfake Generation and Detection: Case Study and Challenges. IEEE Access 2023, 11, 143296–143323. [Google Scholar] [CrossRef]
- Chen, P.; Xu, M.; Wang, X. Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier. Symmetry 2022, 14, 2691. [Google Scholar] [CrossRef]
- Hong, H.; Choi, D.; Kim, N.; Kim, H. Mobile-X: Dedicated FPGA Implementation of the MobileNet Accelerator Optimizing Depthwise Separable Convolution. IEEE Trans. Circuits Syst. II Express Briefs 2024, 71, 4668–4672. [Google Scholar] [CrossRef]
- Ki, S.; Park, J.; Kim, H. Dedicated FPGA Implementation of the Gaussian TinyYOLOv3 Accelerator. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 3882–3886. [Google Scholar] [CrossRef]
- Du, M.; Pentyala, S.; Li, Y.; Hu, X. Towards Generalizable Deepfake Detection with Locality-aware AutoEncoder. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM’20), Virtual, 19–23 October 2020. [Google Scholar] [CrossRef]
- Lanzino, R.; Fontana, F.; Diko, A.; Marini, M.R.; Cinque, L. Faster Than Lies: Real-time Deepfake Detection using Binary Neural Networks. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 3771–3780. [Google Scholar] [CrossRef]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hong, H.; Choi, D.; Kim, N.; Lee, H.; Kang, B.; Kang, H.; Kim, H. Survey of convolutional neural network accelerators on field-programmable gate array platforms: Architectures and optimization techniques. J. Real-Time Image Process. 2024, 21, 64. [Google Scholar] [CrossRef]
- Heidari, A.; Jafari Navimipour, N.; Dag, H.; Unal, M. Deepfake detection using deep learning methods: A systematic and comprehensive review. WIREs Data Min. Knowl. Discov. 2024, 14, e1520. [Google Scholar] [CrossRef]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video Face Manipulation Detection Through Ensemble of CNNs. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5012–5019. [Google Scholar] [CrossRef]
- Saberi, M.; Sadasivan, V.S.; Rezaei, K.; Kumar, A.; Chegini, A.; Wang, W.; Feizi, S. Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks. In Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Dong, F.; Zou, X.; Wang, J.; Liu, X. Contrastive learning-based general Deepfake detection with multi-scale RGB frequency clues. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 90–99. [Google Scholar] [CrossRef]
- Raza, M.A.; Malik, K.M.; Haq, I.U. Holisticdfd: Infusing spatiotemporal transformer embeddings for deepfake detection. Inf. Sci. 2023, 645, 119352. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, C.; Gao, J.; Sun, X.; Rui, Z.; Zhou, X. High-compressed deepfake video detection with contrastive spatiotemporal distillation. Neurocomputing 2024, 565, 126872. [Google Scholar] [CrossRef]
- Almestekawy, A.; Zayed, H.H.; Taha, A. Deepfake detection: Enhancing performance with spatiotemporal texture and deep learning feature fusion. Egypt. Inform. J. 2024, 27, 100535. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Xia, Z.; Zhao, G. Privacy-preserving DeepFake face image detection. Digit. Signal Process. 2023, 143, 104233. [Google Scholar] [CrossRef]
- Tareen, S.A.K.; Saleem, Z. A comparative analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Yallamandaiah, S.; Purnachand, N. A novel face recognition technique using Convolutional Neural Network, HOG, and histogram of LBP features. In Proceedings of the 2022 2nd International Conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 12–14 February 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Cavalcanti, G.D.; Ren, T.I.; Pereira, J.F. Weighted Modular Image Principal Component Analysis for face recognition. Expert Syst. Appl. 2013, 40, 4971–4977. [Google Scholar] [CrossRef]
- Lu, G.F.; Zou, J.; Wang, Y. Incremental complete LDA for face recognition. Pattern Recognit. 2012, 45, 2510–2521. [Google Scholar] [CrossRef]
- Fathi, A.; Alirezazadeh, P.; Abdali-Mohammadi, F. A new Global-Gabor-Zernike feature descriptor and its application to face recognition. J. Vis. Commun. Image Represent. 2016, 38, 65–72. [Google Scholar] [CrossRef]
- Topi, M.; Timo, O.; Matti, P.; Maricor, S. Robust texture classification by subsets of local binary patterns. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000; Volume 3, pp. 935–938. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Déniz, O.; Bueno, G.; Salido, J.; De la Torre, F. Face recognition using histograms of oriented gradients. Pattern Recognit. Lett. 2011, 32, 1598–1603. [Google Scholar] [CrossRef]
- Khalil, S.S.; Youssef, S.M.; Saleh, S.N. iCaps-Dfake: An integrated capsule-based model for deepfake image and video detection. Future Internet 2021, 13, 93. [Google Scholar] [CrossRef]
- Ruano-Ordás, D. Machine Learning-Based Feature Extraction and Selection. Appl. Sci. 2024, 14, 6567. [Google Scholar] [CrossRef]
- Aslan, M.F.; Durdu, A.; Sabanci, K.; Mutluer, M.A. CNN and HOG based comparison study for complete occlusion handling in human tracking. Measurement 2020, 158, 107704. [Google Scholar] [CrossRef]
- Zare, M.R.; Alebiosu, D.O.; Lee, S.L. Comparison of Handcrafted Features and Deep Learning in Classification of Medical X-ray Images. In Proceedings of the 2018 Fourth International Conference on Information Retrieval and Knowledge Management (CAMP), Kota Kinabalu, Malaysia, 26–28 March 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zotova, D.; Pinon, N.; Trombetta, R.; Bouet, R.; Jung, J.; Lartizien, C. Gan-Based Synthetic Fdg Pet Images from T1 Brain MRI Can Serve to Improve Performance of Deep Unsupervised Anomaly Detection Models. SSRN 2024, 34. [Google Scholar] [CrossRef]
- Chen, Y.; Haldar, N.A.H.; Akhtar, N.; Mian, A. Text-image guided Diffusion Model for generating Deepfake celebrity interactions. In Proceedings of the 2023 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Port Macquarie, Australia, 28 November–1 December 2023; pp. 348–355. [Google Scholar]
- Yuan, G.; Cun, X.; Zhang, Y.; Li, M.; Qi, C.; Wang, X.; Shan, Y.; Zheng, H. Inserting anybody in diffusion models via celeb basis. arXiv 2023, arXiv:2306.00926. [Google Scholar]
- Abhisheka, B.; Biswas, S.K.; Das, S.; Purkayastha, B. Combining Handcrafted and CNN Features for Robust Breast Cancer Detection Using Ultrasound Images. In Proceedings of the 2023 3rd International Conference on Innovative Sustainable Computational Technologies (CISCT), Dehradun, India, 8–9 September 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Mohtavipour, S.M.; Saeidi, M.; Arabsorkhi, A. A multi-stream CNN for deep violence detection in video sequences using handcrafted features. Vis. Comput. 2021, 38, 2057–2072. [Google Scholar] [CrossRef]
- Devi, P.A.R.; Budiarti, R.P.N. Image Classification with Shell Texture Feature Extraction Using Local Binary Pattern (LBP) Method. Appl. Technol. Comput. Sci. J. 2020, 3, 48–57. [Google Scholar] [CrossRef]
- Werghi, N.; Berretti, S.; del Bimbo, A. The Mesh-LBP: A Framework for Extracting Local Binary Patterns From Discrete Manifolds. IEEE Trans. Image Process. 2015, 24, 220–235. [Google Scholar] [CrossRef]
- Kumar, D.G. Identical Image Extraction from PDF Document Using LBP (Local Binary Patterns) and RGB (Red, Green and Blue) Color Features. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 3563–3566. [Google Scholar] [CrossRef]
- Karunarathne, B.A.S.S.; Wickramaarachchi, W.H.C.; De Silva, K.K.K.M.C. Face Detection and Recognition for Security System using Local Binary Patterns (LBP). J. ICT Des. Eng. Technol. Sci. 2019, 3, 15–19. [Google Scholar] [CrossRef]
- Yang, B.; Chen, S. A comparative study on local binary pattern (LBP) based face recognition: LBP histogram versus LBP image. Neurocomputing 2013, 120, 365–379. [Google Scholar] [CrossRef]
- Huang, Z.R. CN-LBP: Complex Networks-Based Local Binary Patterns for Texture Classification. In Proceedings of the 2021 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Adelaide, Australia, 4–5 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Rahayu, M.I.; Nasihin, A. Design of Face Recognition Detection Using Local Binary Pattern (LBP) Method. J. Teknol. Inf. Dan Komun. 2020, 9, 48–54. [Google Scholar] [CrossRef]
- Albiol, A.; Monzo, D.; Martin, A.; Sastre, J.; Albiol, A. Face recognition using HOG–EBGM. Pattern Recognit. Lett. 2008, 29, 1537–1543. [Google Scholar] [CrossRef]
- Kusniadi, I.; Setyanto, A. Fake Video Detection using Modified XceptionNet. In Proceedings of the 2021 4th International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 30–31 August 2021; pp. 104–107. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: New York, NY, USA, 2009; Volume 1. [Google Scholar]
- Fawzi, A.; Fawzi, O.; Gana, M.F. Robustness of classifiers: From the theory to the real world. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 505–518. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Dataset | Real Images | Fake Images |
|---|---|---|
| Celeb-DF | 382 | 346 |
| FaceForensics++ | 496 | 458 |
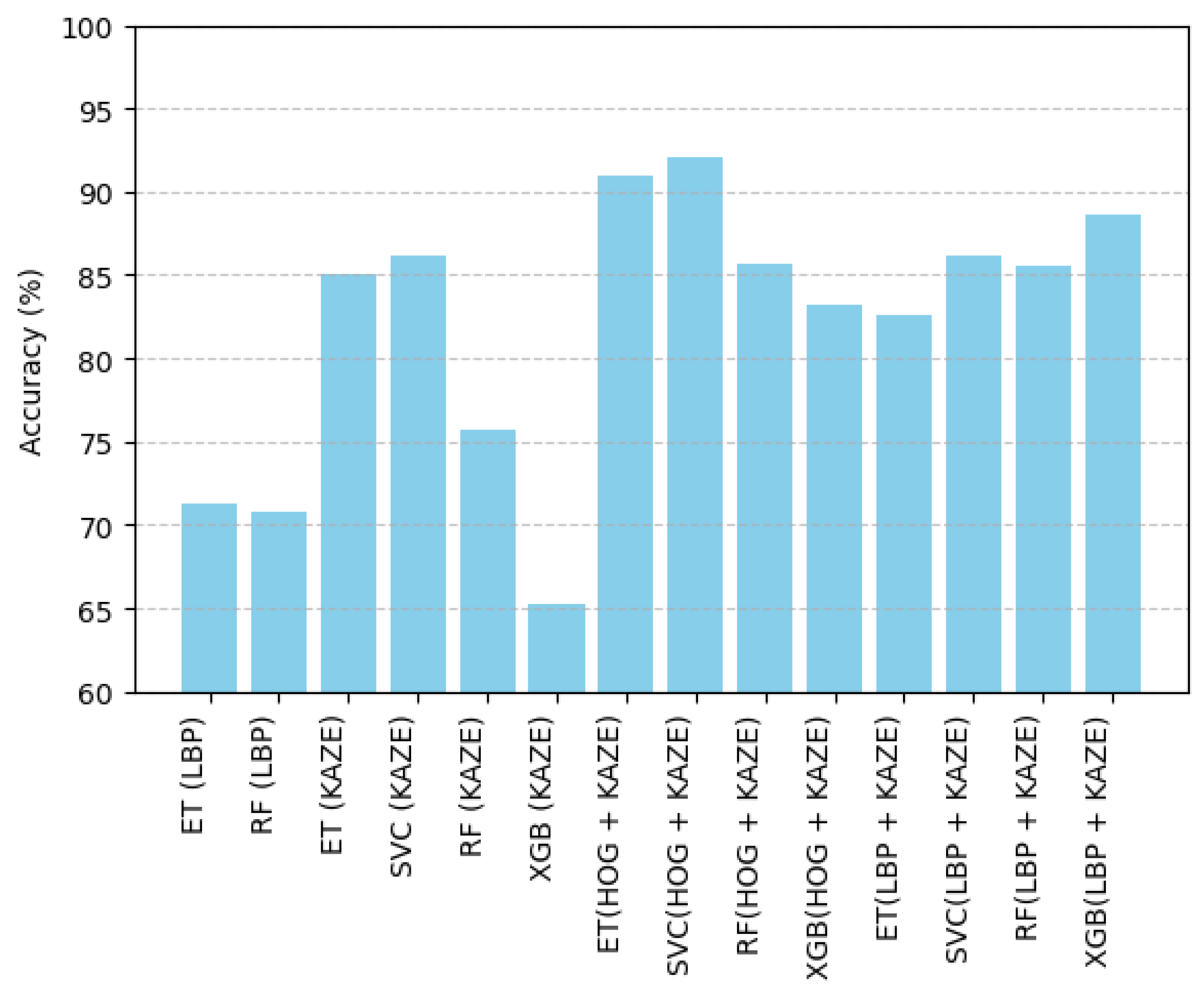
| Fusion of Features with Classifiers | Accuracy | |
|---|---|---|
| LBP Features | Extra Trees Classifier | 71.22% |
| RF Classifier | 70.76% | |
| KAZE Feature | Extra Trees Classifier | 85% |
| Support Vector Classifier | 86.12% | |
| RF Classifier | 75.70% | |
| XGB Classifier | 65.29% | |
| HOG + KAZE Feature | Extra Trees Classifier | 91% |
| Support Vector Classifier | 92.12% | |
| RF Classifier | 85.70% | |
| XGB Classifier | 83.19% | |
| LBP + KAZE Features | Extra Trees Classifier | 82.61% |
| Support Vector Classifier | 86.22% | |
| RF Classifier | 85.54% | |
| XGB Classifier | 88.56% | |
| Fusion of Features with Classifier | Accuracy | |
|---|---|---|
| LBP Features | Support Vector Classifier | 72% |
| HOG Features | Support Vector Classifier | 68% |
| HOG + KAZE Features | Support Vector Classifier | 78% |
| LBP + KAZE Features | Support Vector Classifier | 75% |
| Methods | Feature Extraction | Training | Inference GPU | CPU |
|---|---|---|---|---|
| Random forest | 0.5 s | 30 m | 15 ms | 92 ms |
| Extra Trees Classifier | 0.5 s | 25 m | 15 ms | 95 ms |
| Support Vector Classifier | 0.5 s | 60 m | 13 ms | 63 ms |
| XGB Classifier | 0.5 s | 45 m | 12 ms | 75 ms |
| Support Vector Machine | 0.5 s | 120 m | 25 ms | 85 ms |
| XceptionNet | 0.5 s | 210 m | 20 ms | 2 s |
| Convolutional Neural Network | 0.5 s | 180 m | 10 ms | 1.5 s |
| HOG + KAZE (Proposed) | 1.0 s | 45 m | 16 ms | 67 ms |
| LBP + KAZE (Proposed) | 0.5 s | 30 m | 09 ms | 56 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasir, S.M.; Kim, H. Lightweight Deepfake Detection Based on Multi-Feature Fusion. Appl. Sci. 2025, 15, 1954. https://doi.org/10.3390/app15041954
Yasir SM, Kim H. Lightweight Deepfake Detection Based on Multi-Feature Fusion. Applied Sciences. 2025; 15(4):1954. https://doi.org/10.3390/app15041954
Chicago/Turabian StyleYasir, Siddiqui Muhammad, and Hyun Kim. 2025. "Lightweight Deepfake Detection Based on Multi-Feature Fusion" Applied Sciences 15, no. 4: 1954. https://doi.org/10.3390/app15041954
APA StyleYasir, S. M., & Kim, H. (2025). Lightweight Deepfake Detection Based on Multi-Feature Fusion. Applied Sciences, 15(4), 1954. https://doi.org/10.3390/app15041954