Realistic Data Delays and Alternative Inactivity Definitions in Telecom Churn: Investigating Concept Drift Using a Sliding-Window Approach



Abstract
1. Introduction
- Behavioral Changes Over Time: The behavior patterns of observed objects can change over time, and delays between the prediction and training intervals can affect the accuracy of the results. While these delays cannot be avoided, they must be taken into account when optimizing the practical outcome of the technology, as demonstrated in [24].
- Limitations of Traditional Data Splitting: The classic approach of artificially splitting a dataset into training, validation, and testing parts sections does not allow for the precise estimation of a model’s performance in a real-world scenario. Therefore, an additional set of data must be included, which we refer to as the “true testing data.” These data must be qualitatively different from the training/validation data and should consist of information from the future that can simulate and evaluate the model’s application with a delay.
- Impact of Delays in Different Time Windows: The effect of delays in training and prediction can vary depending on the specific time window. Observing different time windows is important to understand how model performance changes over time—we demonstrate the informative outcome of such an approach.
- We propose a methodology that simulates real-world application delays using a sliding window approach, allowing for the assessment of model performance across different temporal gaps. This addresses the need to handle evolving customer behavior over time (behavioral changes) and exposes concept drift more accurately.
- We highlight the limitations of traditional machine learning approaches in the context of changing customer behavior, demonstrating the necessity of using temporally distinct testing data. By comparing future-based “true tests” with artificial splits, we show how ignoring realistic data delays can affect the performance metrics.
- We provide insights into the impact of concept drift on churn prediction models, showing the need for models that remain robust despite delays in data availability. Our sliding-window experiments capture how shifts in time windows affect both partial and full churn definitions.
- We align the model evaluation with practical business objectives by considering real-world deployment challenges and the dynamic nature of customer behavior [27]. This underlines why genuinely future-based splits and flexible churn definitions (e.g., 40 days vs. 90 days) can help address the delays faced in live scenarios.
1.1. Datasets Background

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sources |
|---|---|
| IBM [28] | [10,11,13,14,20,37,38,39] |
| BigML [29] | [2,6,10,11,14,20,26,27,37,38,40,41] |
| cell2cell [30] | [10,14,20,37], [13,15,41,42] |
| Kaggle [31] | [26] |
| Kaggle2 [32] | [9,13,27,41] |
| Kaggle3 [33] | [14,27,37] |
| Kaggle4 [34] | [10,11,37] |
| Orange Telecom [36] | [12,14] |
| Kaggle5 [35] | [14] |
- The number of calls;
- The sum of the minutes from all calls;
- The payment amounts;
- The sum of the costs of customer payments;
- Activity metric (provided by company).
1.2. The Structure of the Article
2. The Methodology of the Research
2.1. Datasets Conveyor Approach
- The period of 90 days before the moment is used to extract features for the prediction;
- The period lasting up to 90 days after that moment is used to label data—40 days are used for partial churn labeling and 90 for full churn labeling.
- During its training, the model can “see” data derived from standard learning/testing and labels derived from partial labeling;
- Simulation testing/labeling intervals were used to create the ultimate test data that could simulate the model’s use in a real scenario;
- True/standard labeling intervals are used to provide alternative tests for those who want to keep track of churned customers who were labeled using the 90-day period, the so-called “full churners”.
2.2. Results Evaluation
2.2.1. Evaluation Metrics
- Accuracy: The proportion of correct predictions among all predictions made. This is calculated as follows:While accuracy provides a straightforward measure of performance, it can be misleading in datasets with imbalanced class distributions.
- F1 Score: The harmonic mean of precision and recall, providing a balance between the two. It is defined as follows:The F1 score is particularly useful when the class distribution is uneven and when both false positives and false negatives are important.
- Area Under the ROC Curve (AUC): Measures the model’s ability to distinguish between classes by plotting the true positive rate against the false positive rate at various threshold settings. An AUC of 1 indicates perfect classification, while an AUC of 0.5 suggests no discriminative power.
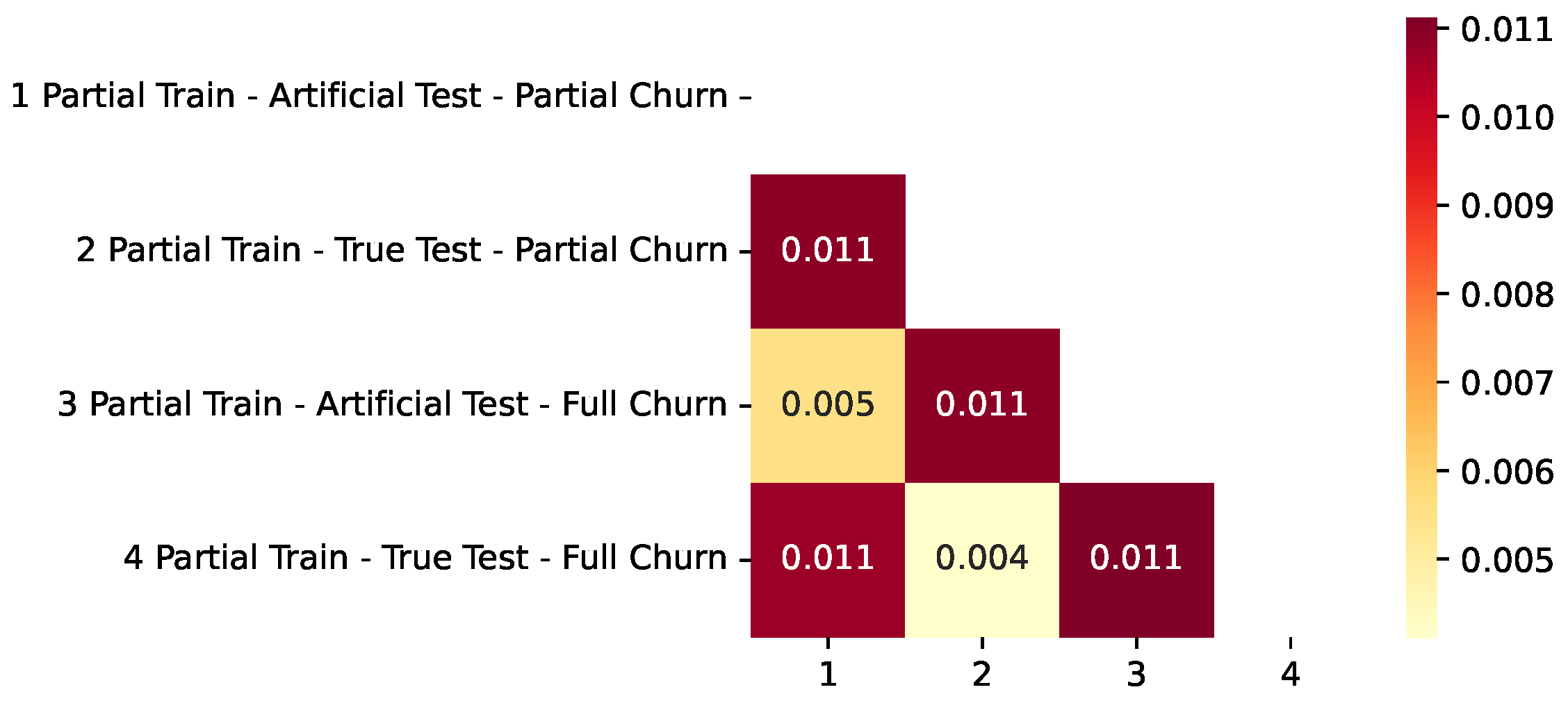
2.2.2. L2 Metric for Curve Difference Evaluation
2.3. Hyperparameter Optimization
2.3.1. Parameter Space
- Iterations (parameter iterations): Fixed at 2000. A high iteration count was chosen, relying on early stopping in CatBoost to prevent overfitting.
- Learning rate (parameter learning_rate): Sampled from a log-uniform distribution over . Formally, ifthenThis distribution is appropriate for the learning rates, which often span multiple orders of magnitude.
- Depth (parameter depth): Sampled from a quantized uniform distribution over :
- L2 leaf regularization (parameter l2_leaf_reg): Sampled from a log-uniform distribution . This controls the strength of the regularization in leaf values.
- Random strength (parameter random_strength) and random subspace method (rsm): Sampled from a uniform distribution over and , respectively.
- Grow polic (parameter grow_policy): Chosen via parameter hp.choice among the following options:
- SymmetricTree (no minimum data in leaf constraint);
- Depthwise, requiring min_data_in_leaf_depthwise sampled from a quantized uniform distribution over ;
- Lossguide, requiring min_data_in_leaf_lossguide similarly sampled.
This nested choice approach allowed us to conditionally sample a min_data_in_leaf parameter for the selected grow policy. - Bootstrap type (parameter bootstrap_type): Chosen via hp.choice among the following options:
- Bayesian, which also samples bagging_temperature from a uniform distribution ;
- Bernoulli, which also samples subsample_bernoulli from a uniform distribution ;
- No, which disables bootstrapping altogether.
This conditional structure ensured that bagging_temperature or subsample were only relevant if the chosen bootstrap_type supported them.
2.3.2. Optimization Process
- It initially randomly samples hyperparameter configurations;
- Then, it trains and evaluates a CatBoost classification model for each set of hyperparameters;
- It collects the performance results (F1 score, accuracy, etc.);
- It updates an internal model of “good” vs. “bad” hyperparameter densities;
- It proposes new configurations that are more likely to yield an improved performance.
3. Results
3.1. Hyperparameter Optimization
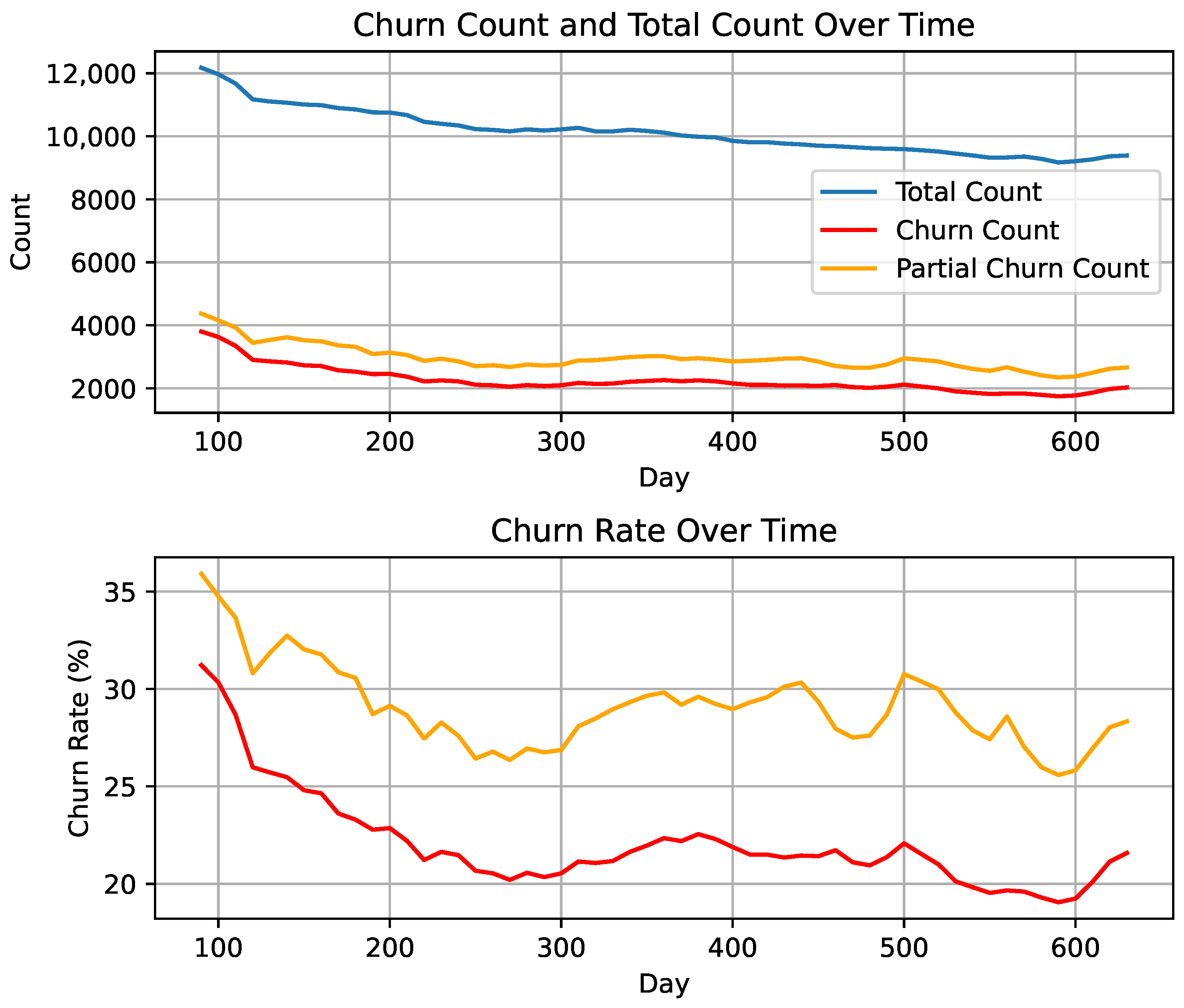
3.2. Dataset Properties
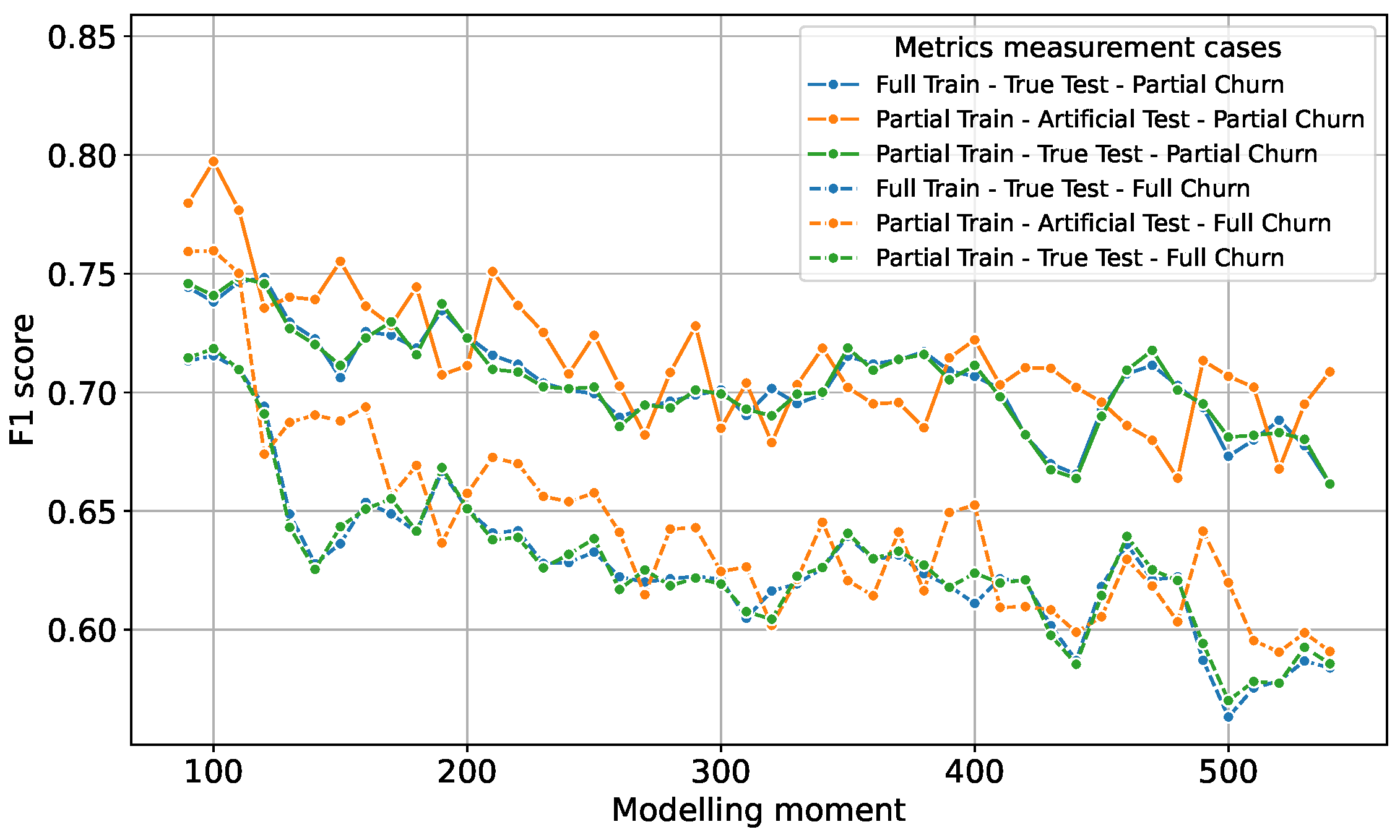
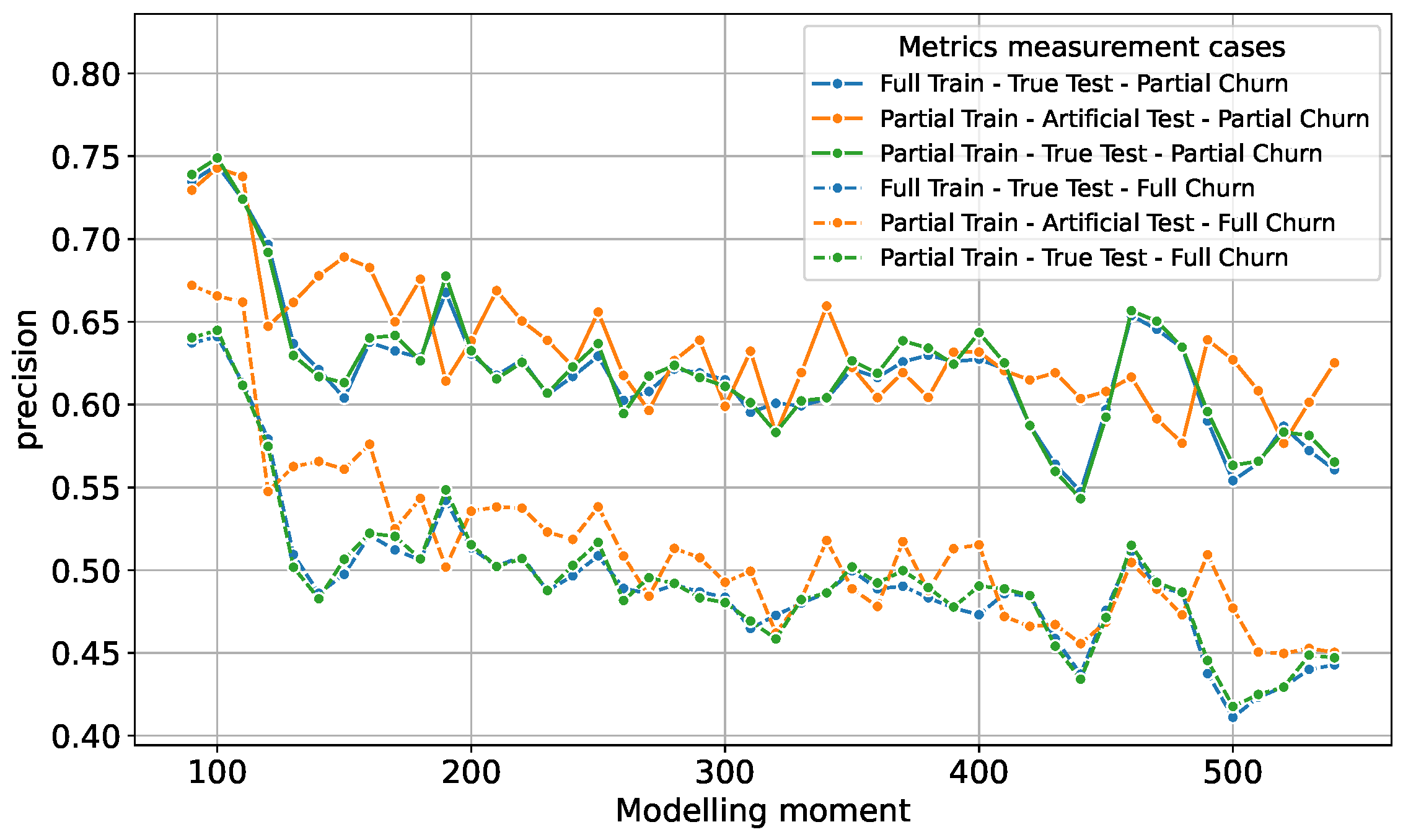
3.3. ML Experiments’ Setup Cases
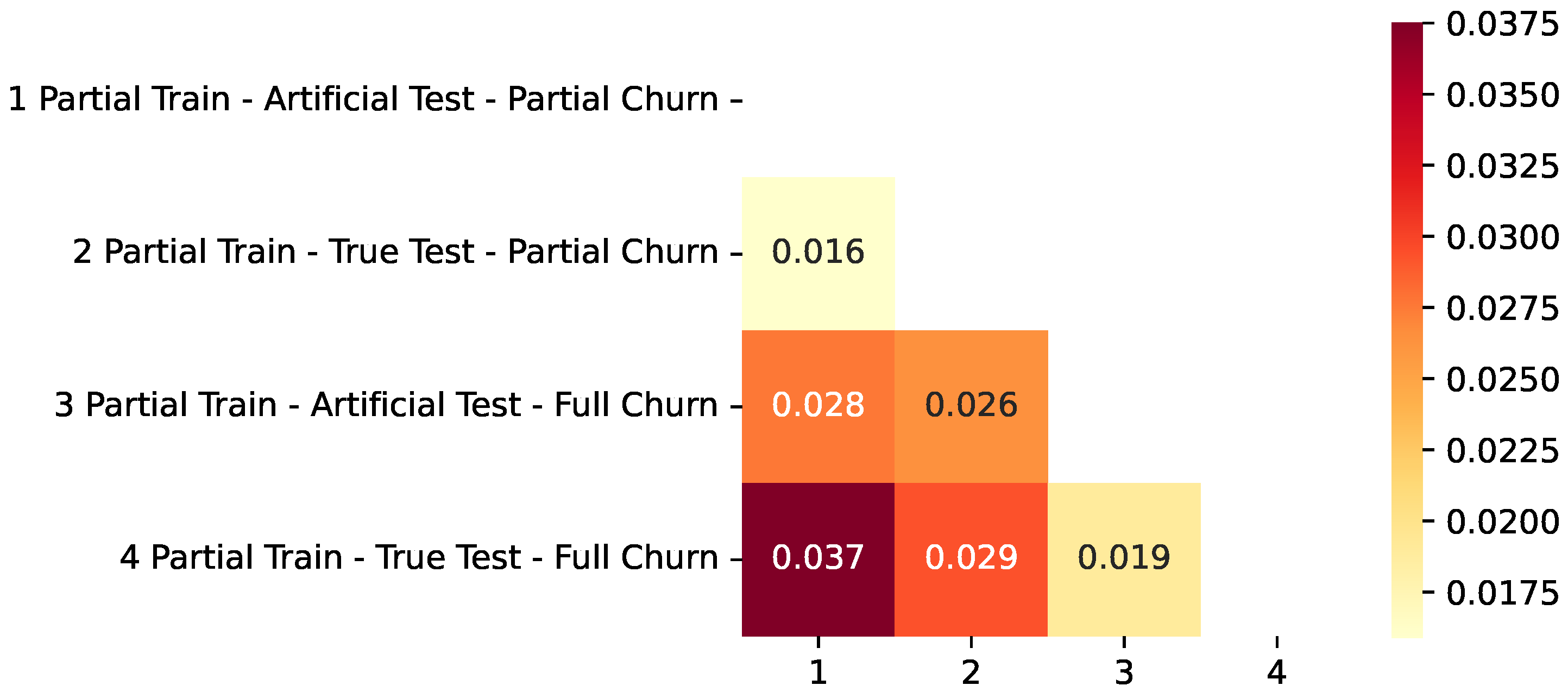
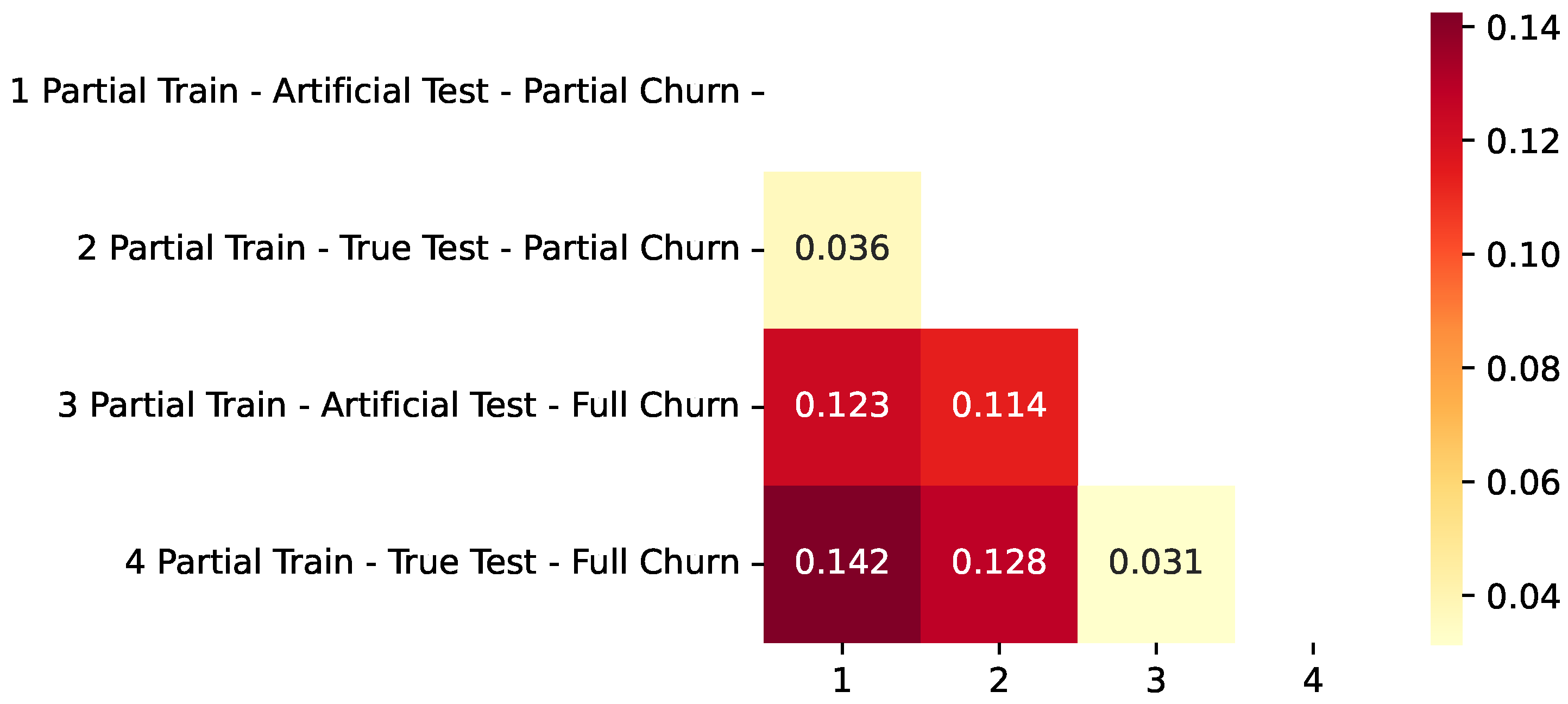
- An actual application case using the full train dataset for training and the true test dataset for testing, with metrics measuring partial churn prediction success. In the Figures, we refer to this as “Full Train–True Test–Partial Churn”.
- Same as the previous case, but with metrics measuring full churn prediction success. In the Figures, we refer to this as “Full Train–True Test–Full Churn”.
- An actual application case using the partial train dataset (80% sample) for training and true test dataset for testing. In the Figures, we refer to this as “Partial Train–True Test–Partial Churn”.
- Same as the previous case, but with metrics measuring full churn prediction success. In the Figures, we refer to this as “Partial Train–True Test–Full Churn”.
- A typical ML approach using a partial train dataset consisting of 80% of the initial data used for training, with the remaining 20% of the same dataset being used for testing—this testing is referred to as the artificial test. In the Figures, we refer to this as “Partial Train–Artificial Test–Partial Churn”.
- Same as the previous case, but with metrics measuring full churn prediction success. In the Figures, we refer to this as “Partial Train–Artificial Test–Full Churn”.
3.4. Analysis of the Results
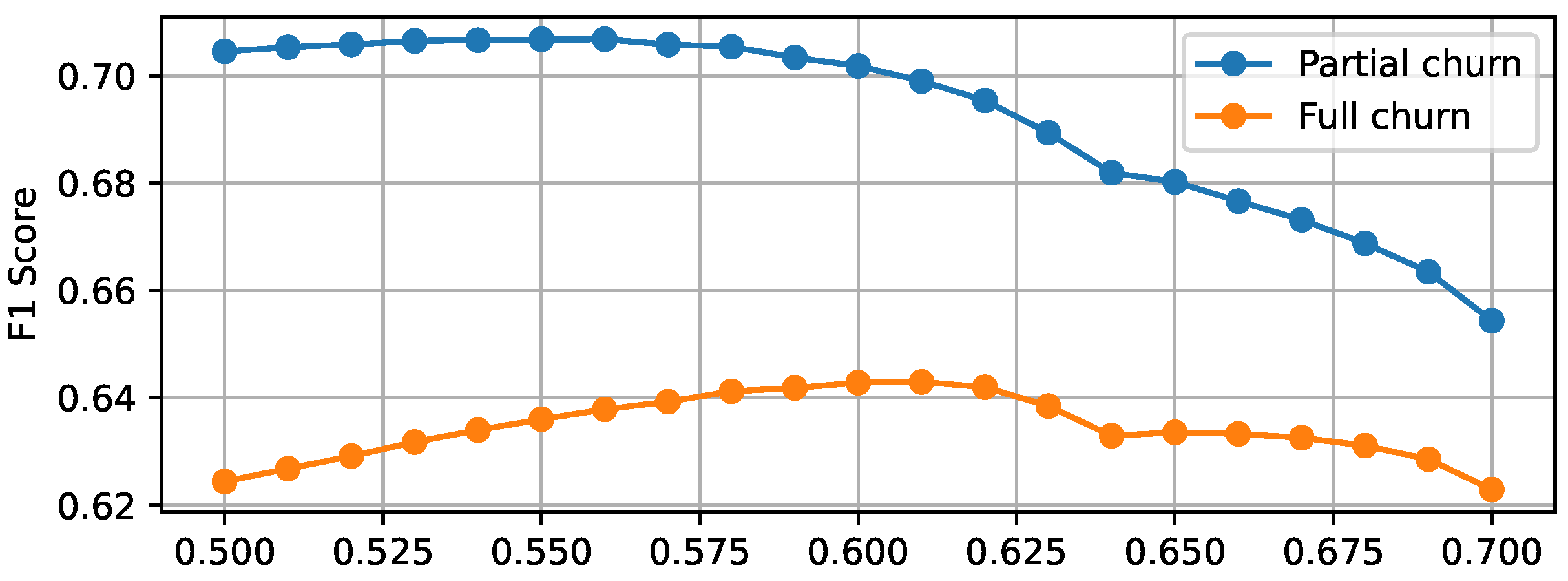
Investigating the Proposed Hypotheses: Time-Window Shifts and Threshold Tuning
- We modified the original Catboost model by selecting a custom decision threshold, varying it from 0.5 to 0.7 with a step of 0.01.
- For clarity, we analyzed two scenarios that obtained the richest results from a practical point of view—both full train and true test scenarios, with different labels of partial and full churn, respectively.
- At each step, we evaluated the performance by averaging the F1 score metric over all time windows.
- Finally, we selected the decision threshold that obtained the best results and investigated it more closely.
- As previously mentioned, the model is trained to solve different tasks than it was tested on; although the difference is small, these differences lead to the unique effect of an indirect connection between tasks being observed.
- The complexities of the partial and full churn problems might be different, and the latter might be harder to predict. However, this specific question is beyond the scope of the current research, because it would require double the amount of computations without clear practical usefulness in the context of the current article.
4. Discussion
4.1. Model Evaluation
4.2. Model Relevance with Different Shifting Test Intervals
4.3. Transfer Learning Without Extra Labels
4.4. Unique Temporal Dataset and Practical Takeaways
- It matches real-world cases where the training data always come before the data on which the model will be tested.
- It reveals certain drift patterns—CatBoost is relatively stable, yet its performance changes slightly with when future data are collected.
- It confirms that an 80% split for training can, in some cases, match the performance of a full training dataset.
4.5. Conceptual and Business-Level Implications
5. Conclusions
- It proposes a time-based testing methodology for telecommunication churn data, showing how models behave under realistic delays.
- It demonstrates that partial-churn labels can serve as a good substitute for full-churn labeling, saving weeks of waiting time without losing much predictive power.
- It confirms that CatBoost remained reasonably robust in our investigated time windows, though drift could become larger in rapidly changing environments, requiring ongoing checks or updates.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Additional Research Data


References
- Vafeiadis, T.; Diamantaras, K.I.; Sarigiannidis, G.; Chatzisavvas, K.C. A comparison of machine learning techniques for customer churn prediction. Simul. Model. Pract. Theory 2015, 55, 1–9. [Google Scholar] [CrossRef]
- Höppner, S.; Stripling, E.; Baesens, B.; Broucke, S.v.; Verdonck, T. Profit driven decision trees for churn prediction. Eur. J. Oper. Res. 2020, 284, 920–933. [Google Scholar] [CrossRef]
- Toor, A.A.; Usman, M. Adaptive telecom churn prediction for concept-sensitive imbalance data streams. J. Supercomput. 2022, 78, 3746–3774. [Google Scholar] [CrossRef]
- Alboukaey, N.; Joukhadar, A.; Ghneim, N. Dynamic behavior based churn prediction in mobile telecom. Expert Syst. Appl. 2020, 162, 113779. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 44. [Google Scholar] [CrossRef]
- Zhu, B.; Baesens, B.; vanden Broucke, S.K.L.M. An empirical comparison of techniques for the class imbalance problem in churn prediction. Inf. Sci. 2017, 408, 84–99. [Google Scholar] [CrossRef]
- Manzoor, A.; Qureshi, M.A.; Kidney, E.; Longo, L. A Review on Machine Learning Methods for Customer Churn Prediction and Recommendations for Business Practitioners. IEEE Access 2024, 12, 70434–70463. [Google Scholar] [CrossRef]
- Priya, S.; Uthra, R.A. Ensemble framework for concept drift detection and class imbalance in data stream. Multimed. Tools Appl. 2024. [CrossRef]
- Sudharsan, R.; Ganesh, E.N. A Swish RNN based customer churn prediction for the telecom industry with a novel feature selection strategy. Connect. Sci. 2022, 34, 1855–1876. [Google Scholar] [CrossRef]
- Garimella, B.; Prasad, G.; Prasad, M. Churn prediction using optimized deep learning classifier on huge telecom data. J. Ambient Intell. Humaniz. Comput. 2023, 14, 2007–2028. [Google Scholar] [CrossRef]
- Pustokhina, I.V.; Pustokhin, D.A.; Nguyen, P.T.; Elhoseny, M.; Shankar, K. Multi-objective rain optimization algorithm with WELM model for customer churn prediction in telecommunication sector. Complex Intell. Syst. 2023, 9, 3473–3485. [Google Scholar] [CrossRef]
- Arshad, S.; Iqbal, K.; Naz, S.; Yasmin, S.; Rehman, Z. A Hybrid System for Customer Churn Prediction and Retention Analysis via Supervised Learning. CMC-Comput. Mater. Contin. 2022, 72, 4283–4301. [Google Scholar] [CrossRef]
- Beeharry, Y.; Tsokizep Fokone, R. Hybrid approach using machine learning algorithms for customers’ churn prediction in the telecommunications industry. Concurr. Comput. Pract. Exp. 2022, 34, e6627. [Google Scholar] [CrossRef]
- Bogaert, M.; Delaere, L. Ensemble Methods in Customer Churn Prediction: A Comparative Analysis of the State-of-the-Art. Mathematics 2023, 11, 1137. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, J.; Zhang, J.; Yin, X.; Song, Z. Research on telecom customer churn prediction based on ensemble learning. J. Intell. Inf. Syst. 2023, 60, 759–775. [Google Scholar] [CrossRef]
- Zhu, B.; Qian, C.; vanden Broucke, S.; Xiao, J.; Li, Y. A bagging-based selective ensemble model for churn prediction on imbalanced data. Expert Syst. Appl. 2023, 227, 120223. [Google Scholar] [CrossRef]
- Nguyen, N.; Duong, T.; Chau, T.; Nguyen, V.H.; Trinh, T.; Tran, D.; Ho, T. A Proposed Model for Card Fraud Detection Based on CatBoost and Deep Neural Network. IEEE Access 2022, 10, 96852–96861. [Google Scholar] [CrossRef]
- Ibrahim, A.; Ridwan, R.; Muhammed, M.; Abdulaziz, R.; Saheed, G. Comparison of the CatBoost Classifier with other Machine Learning Methods. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 738–748. [Google Scholar] [CrossRef]
- Hancock, J.; Khoshgoftaar, T. CatBoost for big data: An interdisciplinary review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef]
- Amin, A.; Adnan, A.; Anwar, S. An adaptive learning approach for customer churn prediction in the telecommunication industry using evolutionary computation and Naive Bayes. Appl. Soft Comput. 2023, 137, 110103. [Google Scholar] [CrossRef]
- Alves, P.; Filipe, R.; Malheiro, B. Telco customer top-ups: Stream-based multi-target regression. Expert Syst. 2023, 40, e13111. [Google Scholar] [CrossRef]
- Liu, X.; Liu, H.; Zheng, K.; Liu, J.; Taleb, T.; Shiratori, N. AoI-Minimal Clustering, Transmission and Trajectory Co-Design for UAV-Assisted WPCNs. IEEE Trans. Veh. Technol. 2025, 74, 1035–1051. [Google Scholar] [CrossRef]
- Mitrovic, S.; Baesens, B.; Lemahieu, W.; De Weerdt, J. tcc2vec: RFM-informed representation learning on call graphs for churn prediction. Inf. Sci. 2021, 557, 270–285. [Google Scholar] [CrossRef]
- Bugajev, A.; Kriauzienė, R.; Vasilecas, O.; Chadyšas, V. The impact of churn labelling rules on churn prediction in telecommunications. Informatica 2022, 33, 247–277. [Google Scholar] [CrossRef]
- Kabas, O.; Ercan, U.; Dinca, M.N. Prediction of Briquette Deformation Energy via Ensemble Learning Algorithms Using Physico-Mechanical Parameters. Appl. Sci. 2024, 14, 652. [Google Scholar] [CrossRef]
- Saha, L.; Tripathy, H.; Gaber, T.; El-Gohary, H.; El-kenawy, E.S. Deep churn prediction method for telecommunication industry. Sustainability 2023, 15, 4543. [Google Scholar] [CrossRef]
- Ortakci, Y.; Seker, H. Optimising customer retention: An AI-driven personalised pricing approach. Comput. Ind. Eng. 2024, 188, 109920. [Google Scholar] [CrossRef]
- Corporation, I. Telco Customer Churn. 2024. Available online: https://www.kaggle.com/datasets/blastchar/telco-customer-churn (accessed on 19 July 2024).
- BigML. Telco Customer Churn: IBM Dataset. Available online: https://bigml.com/dashboard/source/669a36983b5846df24c14c0c (accessed on 19 July 2024).
- Teradata Center for Customer Relationship Management at Duke University. Telecom Churn (cell2cell). Available online: https://www.kaggle.com/datasets/jpacse/datasets-for-churn-telecom (accessed on 19 July 2024).
- Telecom_Churn. Available online: https://www.kaggle.com/datasets/priyankanavgire/telecom-churn (accessed on 19 July 2024).
- Customer Churn Prediction 2020. Available online: https://www.kaggle.com/c/customer-churn-prediction-2020/data (accessed on 26 July 2024).
- Customer Churn. Available online: https://www.kaggle.com/datasets/barun2104/telecom-churn (accessed on 26 July 2024).
- Telecom_ Customer. Available online: https://www.kaggle.com/datasets/abhinav89/telecom-customer (accessed on 1 August 2024).
- South Asian Churn Dataset. Available online: https://www.kaggle.com/datasets/mahreen/sato2015/data (accessed on 30 August 2024).
- Orange Telecom Dataset. Available online: https://www.kdd.org/kdd-cup/view/kdd-cup-2009 (accessed on 30 August 2024).
- Al-Shourbaji, I.; Helian, N.; Sun, Y.; Alshathri, S.; Abd Elaziz, M. Boosting Ant Colony Optimization with Reptile Search Algorithm for Churn Prediction. Mathematics 2022, 10, 1031. [Google Scholar] [CrossRef]
- Tavassoli, S.; Koosha, H. Hybrid ensemble learning approaches to customer churn prediction. Kybernetes 2022, 51, 1062–1088. [Google Scholar] [CrossRef]
- Kozak, J.; Kania, K.; Juszczuk, P.; Mitręga, M. Swarm intelligence goal-oriented approach to data-driven innovation in customer churn management. Int. J. Inf. Manag. 2021, 60, 102357. [Google Scholar] [CrossRef]
- Mirza, O.M.; Moses, G.J.; Rajender, R.; Lydia, E.L.; Kadry, S.; Me-Ead, C.; Thinnukool, O. Optimal Deep Canonically Correlated Autoencoder-Enabled Prediction Model for Customer Churn Prediction. CMC-Comput. Mater. Contin. 2022, 73, 3757–3769. [Google Scholar] [CrossRef]
- Wu, S.; Yau, W.C.; Ong, T.S.; Chong, S.C. Integrated Churn Prediction and Customer Segmentation Framework for Telco Business. IEEE Access 2021, 9, 62118–62136. [Google Scholar] [CrossRef]
- Adhikary, D.D.; Gupta, D. Applying over 100 classifiers for churn prediction in telecom companies. Multimed. Tools Appl. 2020, 80, 1–22. [Google Scholar] [CrossRef]
- Adams, R.A.; Fournier, J.J. Sobolev Spaces; Elsevier: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 115–123. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 24. [Google Scholar]
- Bootstrap Options. Available online: https://catboost.ai/docs/en/concepts/algorithm-main-stages_bootstrap-options (accessed on 28 January 2025).
- Przybyła-Kasperek, M.; Marfo, K.F.; Sulikowski, P. Multi-Layer Perceptron and Radial Basis Function Networks in Predictive Modeling of Churn for Mobile Telecommunications Based on Usage Patterns. Appl. Sci. 2024, 14, 9226. [Google Scholar] [CrossRef]








| Attribute | Data Type | Description |
|---|---|---|
| X1–X60 | Numerical | RFM features |
| X61–X510 | Numerical | The daily sums of parameters for the last 90 days |
| X511 | Numerical | Involvement of company |
| X512 | Numerical | Partial churn label |
| X513 | Categorical | Full churn label |
| Optimization Setting | Value |
|---|---|
| Algorithm | Tree-structured Parzen Estimator (TPE) |
| Library | Hyperopt |
| Initial Random Evaluations | 30 (via parameter n_startup_jobs) |
| Maximum Evaluations | 300 (via parameter max_evals) |
| Cross-Validation Folds | 5 (via parameter n_splits) |
| Objective Metric | Negative F1 score |
| Parameter | Value |
|---|---|
| bootstrap_type | No |
| depth | 5 |
| grow_policy | SymmetricTree |
| l2_leaf_reg | 0.357 |
| learning_rate | 0.058 |
| random_strength | 0.089 |
| rsm | 0.734 |
| eval_metric | F1 |
| early_stopping_rounds | 50 |
| verbose | 100 |
| iterations | 121 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bugajev, A.; Kriauzienė, R.; Chadyšas, V. Realistic Data Delays and Alternative Inactivity Definitions in Telecom Churn: Investigating Concept Drift Using a Sliding-Window Approach. Appl. Sci. 2025, 15, 1599. https://doi.org/10.3390/app15031599
Bugajev A, Kriauzienė R, Chadyšas V. Realistic Data Delays and Alternative Inactivity Definitions in Telecom Churn: Investigating Concept Drift Using a Sliding-Window Approach. Applied Sciences. 2025; 15(3):1599. https://doi.org/10.3390/app15031599
Chicago/Turabian StyleBugajev, Andrej, Rima Kriauzienė, and Viktoras Chadyšas. 2025. "Realistic Data Delays and Alternative Inactivity Definitions in Telecom Churn: Investigating Concept Drift Using a Sliding-Window Approach" Applied Sciences 15, no. 3: 1599. https://doi.org/10.3390/app15031599
APA StyleBugajev, A., Kriauzienė, R., & Chadyšas, V. (2025). Realistic Data Delays and Alternative Inactivity Definitions in Telecom Churn: Investigating Concept Drift Using a Sliding-Window Approach. Applied Sciences, 15(3), 1599. https://doi.org/10.3390/app15031599