

Acute Respiratory Distress Identification via Multi-Modality Using Deep Learning


Abstract
1. Introduction
- We propose the use of multi-modality data to improve the performance of acute respiratory distress detection systems.
- We introduce straightforward yet effective data pre-processing techniques to normalize the depth modality to ensure uniform scaling.
- We investigate various feature fusion methods to effectively integrate information from both RGB and depth modality. Our experimental results demonstrate that simple feature fusion techniques are especially beneficial when working with limited data, resulting in significant improvements in detection performance.
2. Related Work
2.1. Methods for Respiratory Parameter Analysis
2.2. Multi-Modality Fusion Techniques
3. Proposed Model
3.1. Problem Formulation
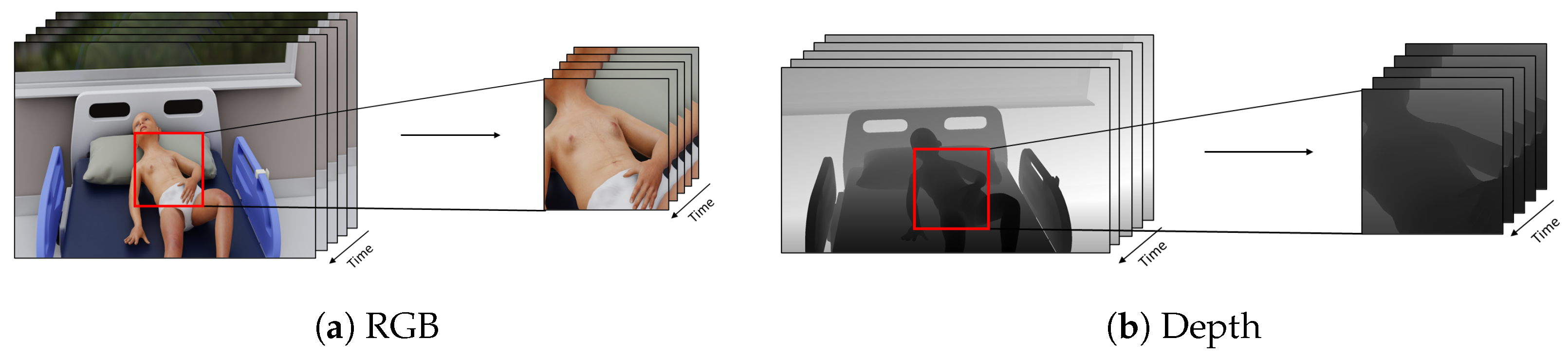
3.2. Data Pre-Processing Module
| Algorithm 1: Pseudo code for depth video normalization process. |
 |
3.3. Feature Extraction Module
3.4. Feature Fusion Module
4. Experimental Analysis
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Ablation Study
4.4.1. Baseline
4.4.2. RGB-D Acute Respiratory Distress Detection
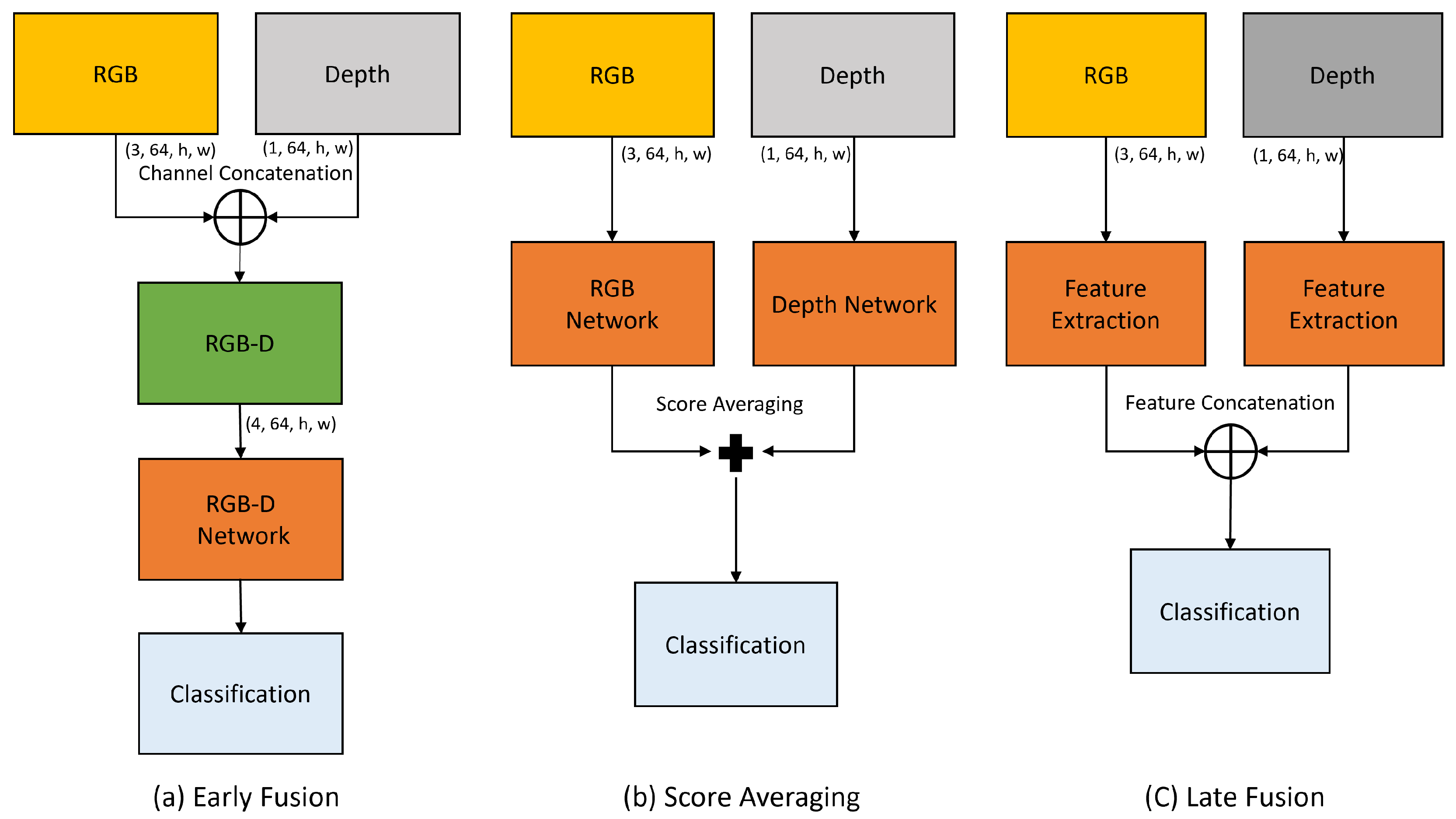
4.4.3. Early Fusion
4.4.4. Late Fusion
4.4.5. Performance Analysis Across Age Groups
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Edwards, M.O.; Kotecha, S.J.; Kotecha, S. Respiratory distress of the term newborn infant. Paediatr. Respir. Rev. 2013, 14, 29–37. [Google Scholar] [CrossRef] [PubMed]
- Diamond, M.; Peniston, H.L.; Sanghavi, D.K.; Mahapatra, S. Acute respiratory distress syndrome. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2023. [Google Scholar]
- Taussig, L.M.; Landau, L.I. Pediatric Respiratory Medicine E-Book; Elsevier Health Sciences: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Chen, M.; Zhu, Q.; Zhang, H.; Wu, M.; Wang, Q. Respiratory rate estimation from face videos. In Proceedings of the 2019 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Chicago, IL, USA, 19–22 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–4. [Google Scholar]
- Rehouma, H.; Noumeir, R.; Essouri, S.; Jouvet, P. Quantitative assessment of spontaneous breathing in children: Evaluation of a depth camera system. IEEE Trans. Instrum. Meas. 2019, 69, 4955–4967. [Google Scholar] [CrossRef]
- Fiedler, M.A.; Rapczyński, M.; Al-Hamadi, A. Fusion-based approach for respiratory rate recognition from facial video images. IEEE Access 2020, 8, 130036–130047. [Google Scholar] [CrossRef]
- Cheng, J.; Liu, R.; Li, J.; Song, R.; Liu, Y.; Chen, X. Motion-Robust Respiratory Rate Estimation from Camera Videos via Fusing Pixel Movement and Pixel Intensity Information. IEEE Trans. Instrum. Meas. 2023, 72, 4008611. [Google Scholar] [CrossRef]
- Fiedler, M.A.; Werner, P.; Rapczyński, M.; Al-Hamadi, A. Deep face segmentation for improved heart and respiratory rate estimation from videos. J. Ambient Intell. Humaniz. Comput. 2023, 14, 9383–9402. [Google Scholar] [CrossRef]
- Gupta, P.; Bhowmick, B.; Pal, A. Accurate heart-rate estimation from face videos using quality-based fusion. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York, NY, USA, 2017; pp. 4132–4136. [Google Scholar]
- Pilz, C.S.; Zaunseder, S.; Krajewski, J.; Blazek, V. Local Group Invariance for Heart Rate Estimation From Face Videos in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sabokrou, M.; Pourreza, M.; Li, X.; Fathy, M.; Zhao, G. Deep-hr: Fast heart rate estimation from face video under realistic conditions. Expert Syst. Appl. 2021, 186, 115596. [Google Scholar] [CrossRef]
- Gao, H.; Wu, X.; Geng, J.; Lv, Y. Remote heart rate estimation by signal quality attention network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2122–2129. [Google Scholar]
- Su, L.; Wang, Y.; Zhai, D.; Shi, Y.; Ding, Y.; Gao, G.; Li, Q.; Yu, M.; Wu, H. Spatiotemporal Sensitive Network for Non-Contact Heart Rate Prediction from Facial Videos. Appl. Sci. 2024, 14, 9551. [Google Scholar] [CrossRef]
- Yuthong, A.; Duangsoithong, R.; Booranawong, A.; Chetpattananondh, K. Monitoring of volume of air in inhalation from Triflo using video processing. IEEE Trans. Instrum. Meas. 2019, 69, 4334–4347. [Google Scholar] [CrossRef]
- Hurtado, D.E.; Chavez, J.A.; Mansilla, R.; Lopez, R.; Abusleme, A. Respiratory volume monitoring: A machine-learning approach to the non-invasive prediction of tidal volume and minute ventilation. IEEE Access 2020, 8, 227936–227944. [Google Scholar] [CrossRef]
- Addison, P.S.; Smit, P.; Jacquel, D.; Addison, A.P.; Miller, C.; Kimm, G. Continuous non-contact respiratory rate and tidal volume monitoring using a Depth Sensing Camera. J. Clin. Monit. Comput. 2022, 36, 657–665. [Google Scholar] [CrossRef]
- Rehouma, H.; Noumeir, R.; Bouachir, W.; Jouvet, P.; Essouri, S. 3D imaging system for respiratory monitoring in pediatric intensive care environment. Comput. Med. Imaging Graph. 2018, 70, 17–28. [Google Scholar] [CrossRef] [PubMed]
- Rehouma, H.; Noumeir, R.; Masson, G.; Essouri, S.; Jouvet, P. Visualizing and quantifying thoraco-abdominal asynchrony in children from motion point clouds: A pilot study. IEEE Access 2019, 7, 163341–163357. [Google Scholar] [CrossRef]
- Di Tocco, J.; Massaroni, C.; Bravi, M.; Miccinilli, S.; Sterzi, S.; Formica, D.; Schena, E. Evaluation of thoraco-abdominal asynchrony using conductive textiles. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Ottaviani, V.; Veneroni, C.; Dellaca, R.L.; Lavizzari, A.; Mosca, F.; Zannin, E. Contactless monitoring of breathing pattern and thoracoabdominal asynchronies in preterm infants using depth cameras: A feasibility study. IEEE J. Transl. Eng. Health Med. 2022, 10, 4900708. [Google Scholar] [CrossRef]
- Nawaz, W.; Jouvet, P.; Noumeir, R. Automated Detection of Acute Respiratory Distress Using Temporal Visual Information. IEEE Access 2024, 12, 142071–142082. [Google Scholar] [CrossRef]
- Mateu-Mateus, M.; Guede-Fernandez, F.; Angel Garcia-Gonzalez, M.; Ramos-Castro, J.J.; Fernández-Chimeno, M. Camera-based method for respiratory rhythm extraction from a lateral perspective. IEEE Access 2020, 8, 154924–154939. [Google Scholar] [CrossRef]
- Merler, M.; Ratha, N.; Feris, R.S.; Smith, J.R. Diversity in faces. arXiv 2019, arXiv:1901.10436. [Google Scholar]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, PMLR, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Khalid, M.U.; Yu, J. Multi-Modal Three-Stream Network for Action Recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3210–3215. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Islam, M.M.; Iqbal, T. Hamlet: A hierarchical multimodal attention-based human activity recognition algorithm. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: New York, NY, USA, 2020; pp. 10285–10292. [Google Scholar]
- Das, S.; Sharma, S.; Dai, R.; Bremond, F.; Thonnat, M. Vpn: Learning video-pose embedding for activities of daily living. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 72–90. [Google Scholar]
- Joze, H.R.V.; Shaban, A.; Iuzzolino, M.L.; Koishida, K. MMTM: Multimodal transfer module for CNN fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13289–13299. [Google Scholar]
- Hu, J.F.; Zheng, W.S.; Pan, J.; Lai, J.; Zhang, J. Deep bilinear learning for rgb-d action recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Xu, W.; Wu, M.; Zhao, M.; Xia, T. Fusion of skeleton and RGB features for RGB-D human action recognition. IEEE Sens. J. 2021, 21, 19157–19164. [Google Scholar]
- Kini, J.; Fleischer, S.; Dave, I.; Shah, M. Ensemble Modeling for Multimodal Visual Action Recognition. arXiv 2023, arXiv:2308.05430. [Google Scholar]
- Wang, X.; Hu, J.F.; Lai, J.H.; Zhang, J.; Zheng, W.S. Progressive teacher-student learning for early action prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3556–3565. [Google Scholar]
- Popescu, A.C.; Mocanu, I.; Cramariuc, B. Fusion mechanisms for human activity recognition using automated machine learning. IEEE Access 2020, 8, 143996–144014. [Google Scholar] [CrossRef]
- Keskes, O.; Noumeir, R. Vision-based fall detection using st-gcn. IEEE Access 2021, 9, 28224–28236. [Google Scholar] [CrossRef]
- Khalid, N.; Ghadi, Y.Y.; Gochoo, M.; Jalal, A.; Kim, K. Semantic recognition of human-object interactions via Gaussian-based elliptical modeling and pixel-level labeling. IEEE Access 2021, 9, 111249–111266. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A modern library for 3D data processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]
- Tsou, Y.Y.; Lee, Y.A.; Hsu, C.T.; Chang, S.H. Siamese-rPPG network: Remote photoplethysmography signal estimation from face videos. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Online, 30 March–3 April 2020; pp. 2066–2073. [Google Scholar]
- Ouzar, Y.; Djeldjli, D.; Bousefsaf, F.; Maaoui, C. X-iPPGNet: A novel one stage deep learning architecture based on depthwise separable convolutions for video-based pulse rate estimation. Comput. Biol. Med. 2023, 154, 106592. [Google Scholar] [CrossRef] [PubMed]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Hedstrom, A.; Gove, N.; Mayock, D.; Batra, M. Performance of the Silverman Andersen Respiratory Severity Score in predicting PCO2 and respiratory support in newborns: A prospective cohort study. J. Perinatol. 2018, 38, 505–511. [Google Scholar] [CrossRef] [PubMed]
- Szymański, P.; Kajdanowicz, T. A Network Perspective on Stratification of Multi-Label Data. In Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications, Skopje, Macedonia, 22 September 2017; Volume 74, pp. 22–35. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Recall | Score | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Avg | Max | Min | Avg | Max | Min | Avg | Max | Min | Avg | Max | ||
| X3D | RGB | 0.783 | 0.822 | 0.870 | 0.818 | 0.872 | 0.95 | 0.72 | 0.777 | 0.833 | 0.783 | 0.821 | 0.864 |
| Depth | 0.696 | 0.757 | 0.826 | 0.639 | 0.716 | 0.808 | 0.840 | 0.910 | 0.958 | 0.750 | 0.799 | 0.840 | |
| CSN | RGB | 0.783 | 0.835 | 0.891 | 0.792 | 0.911 | 1.0 | 0.75 | 0.769 | 0.792 | 0.792 | 0.832 | 0.884 |
| Depth | 0.565 | 0.665 | 0.739 | 0.593 | 0.668 | 0.750 | 0.640 | 0.745 | 0.875 | 0.615 | 0.701 | 0.750 | |
| R(2+1)D | RGB | 0.717 | 0.796 | 0.826 | 0.7 | 0.793 | 0.84 | 0.792 | 0.835 | 0.875 | 0.764 | 0.812 | 0.857 |
| Depth | 0.565 | 0.730 | 0.804 | 0.559 | 0.729 | 0.826 | 0.792 | 0.808 | 0.833 | 0.655 | 0.763 | 0.809 | |
| Fusion Method | Accuracy | Precision | Recall | Score | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Avg | Max | Min | Avg | Max | Min | Avg | Max | Min | Avg | Max | |
| Baseline | 0.783 | 0.822 | 0.870 | 0.818 | 0.872 | 0.95 | 0.72 | 0.777 | 0.833 | 0.783 | 0.821 | 0.864 |
| CC | 0.696 | 0.765 | 0.848 | 0.667 | 0.762 | 0.870 | 0.792 | 0.818 | 0.833 | 0.741 | 0.788 | 0.851 |
| FCAT | 0.804 | 0.830 | 0.848 | 0.800 | 0.821 | 0.840 | 0.833 | 0.868 | 0.917 | 0.816 | 0.843 | 0.863 |
| SA | 0.804 | 0.830 | 0.848 | 0.759 | 0.808 | 0.846 | 0.875 | 0.893 | 0.917 | 0.830 | 0.847 | 0.863 |
| FCAT-F | 0.804 | 0.852 | 0.913 | 0.808 | 0.867 | 0.917 | 0.760 | 0.852 | 0.917 | 0.809 | 0.858 | 0.917 |
| Age Group | Accuracy | Precision | Recall | TP_Rate | TN_Rate |
|---|---|---|---|---|---|
| 1 | 0.788 | 0.863 | 0.767 | 0.767 | 0.820 |
| 2 | 0.744 | 0.166 | 0.400 | 0.400 | 0.796 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nawaz, W.; Albert, K.; Jouvet, P.; Noumeir, R. Acute Respiratory Distress Identification via Multi-Modality Using Deep Learning. Appl. Sci. 2025, 15, 1512. https://doi.org/10.3390/app15031512
Nawaz W, Albert K, Jouvet P, Noumeir R. Acute Respiratory Distress Identification via Multi-Modality Using Deep Learning. Applied Sciences. 2025; 15(3):1512. https://doi.org/10.3390/app15031512
Chicago/Turabian StyleNawaz, Wajahat, Kevin Albert, Philippe Jouvet, and Rita Noumeir. 2025. "Acute Respiratory Distress Identification via Multi-Modality Using Deep Learning" Applied Sciences 15, no. 3: 1512. https://doi.org/10.3390/app15031512
APA StyleNawaz, W., Albert, K., Jouvet, P., & Noumeir, R. (2025). Acute Respiratory Distress Identification via Multi-Modality Using Deep Learning. Applied Sciences, 15(3), 1512. https://doi.org/10.3390/app15031512