
Predicting Wastewater Characteristics Using Artificial Neural Network and Machine Learning Methods for Enhanced Operation of Oxidation Ditch



Abstract
1. Introduction
2. Materials and Methods
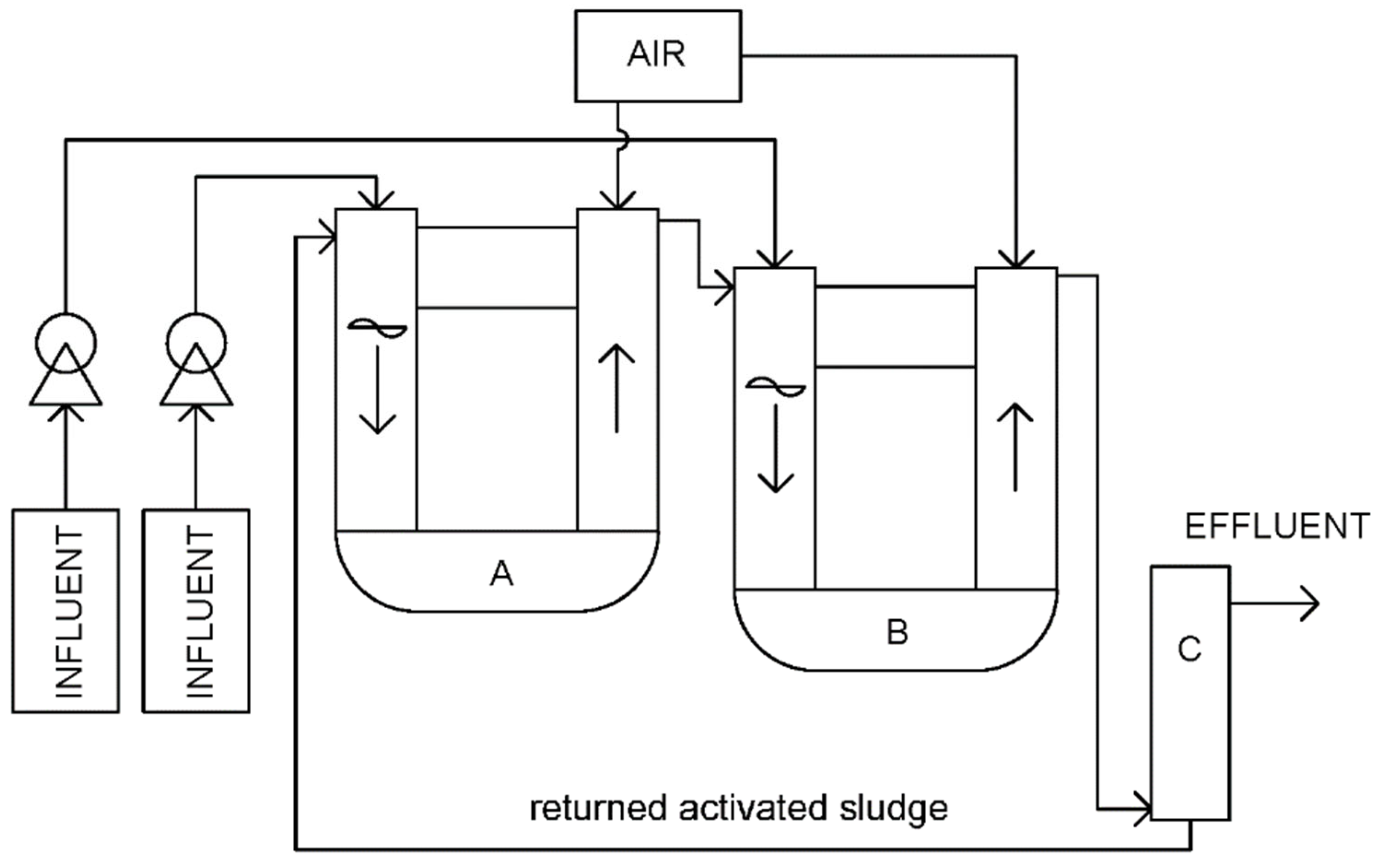
2.1. Experimental Setup
2.2. Chemicals
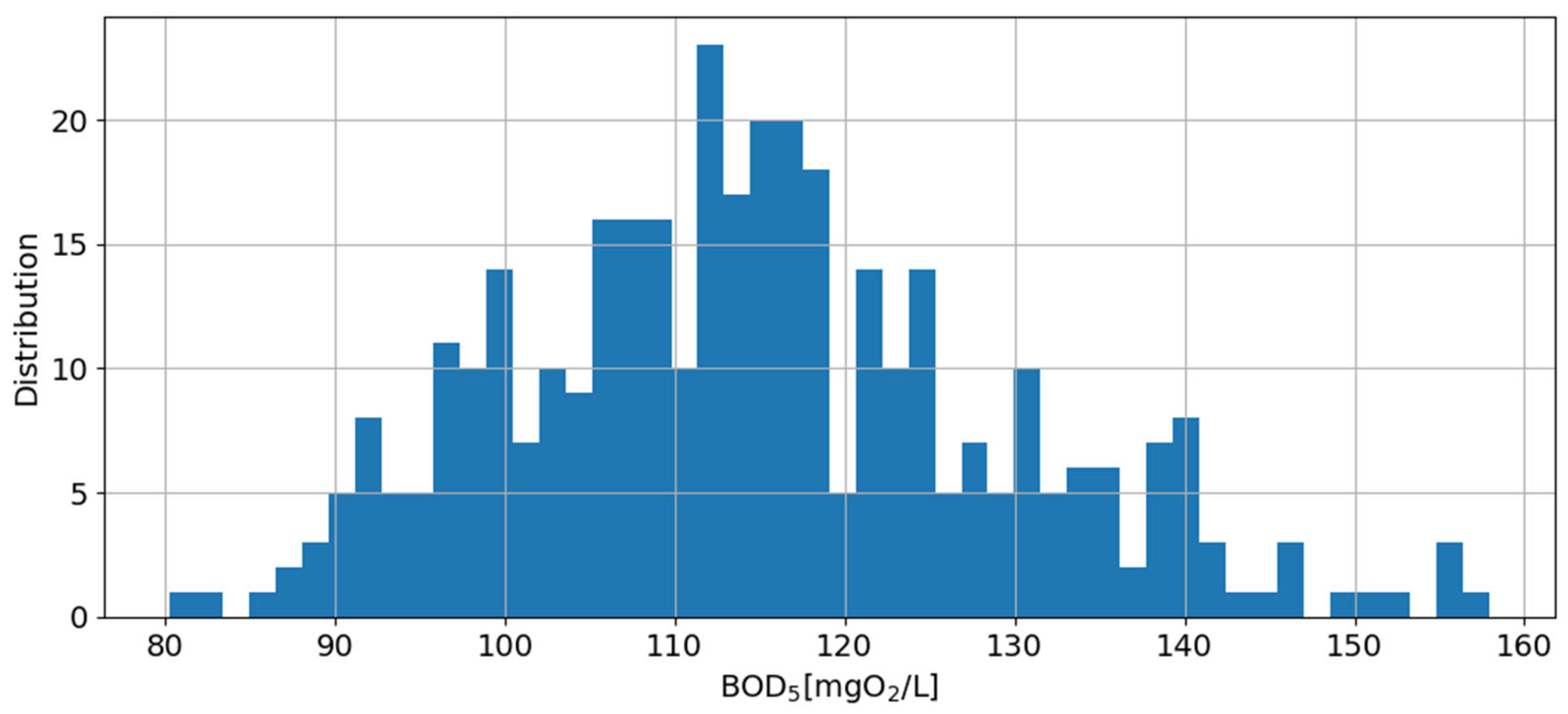
2.3. Wastewater Characteristics
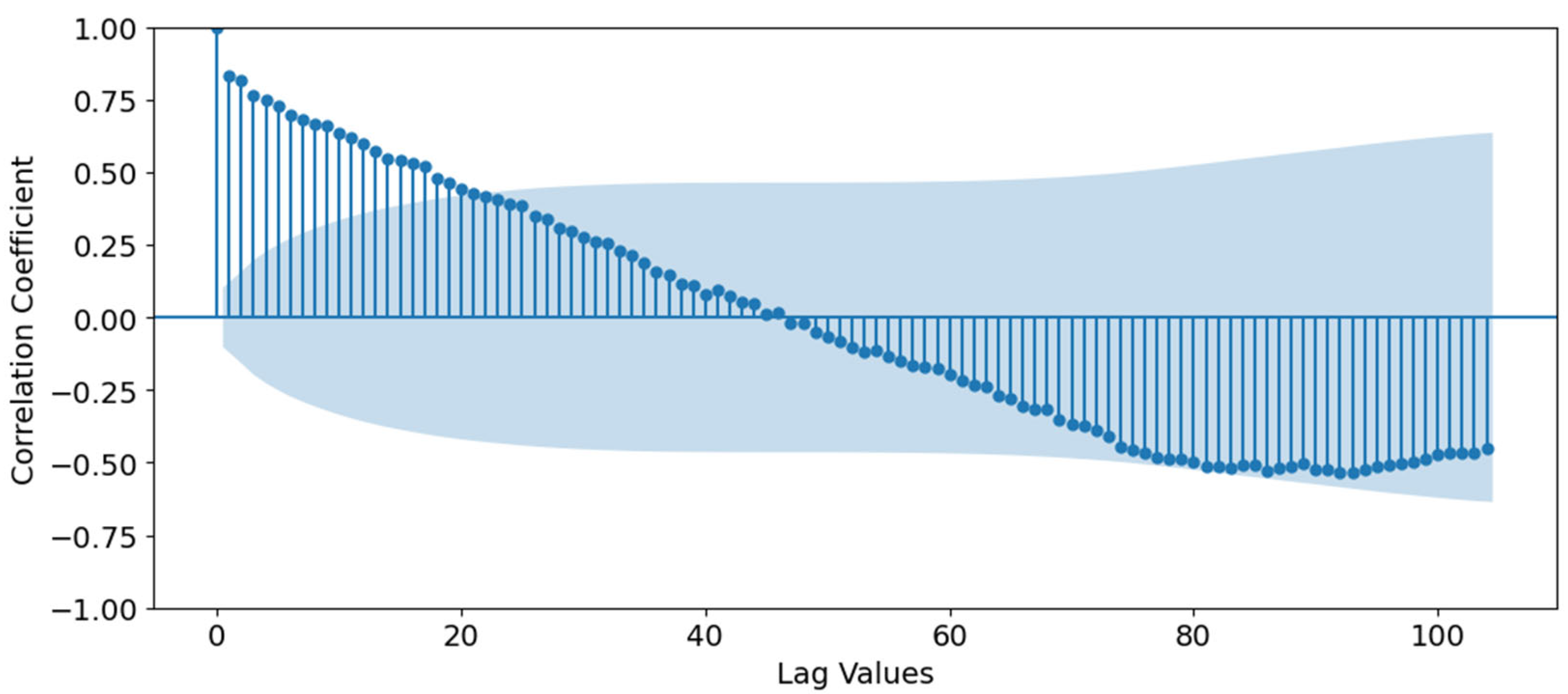
2.4. Data Description and Analysis
2.5. Methodology
- First Layer: An LSTM layer with 50 units and the parameter “return_sequences = True”, allowing the sequences to be passed to subsequent layers;
- Dropout Layer: Following the first LSTM layer, a Dropout layer was applied with a neuron dropout rate of 20% (0.2) to prevent overfitting;
- Second Layer: Another LSTM layer with 50 units, where “return_sequences = False”, ensuring that only the final output sequence is passed to the next layer;
- Second Dropout Layer: Another Dropout layer with a 20% probability of stabilizing the training process;
- Dense Layer: A fully connected (Dense) layer with 25 neurons to provide additional representation and transformation of features following the LSTM layers;
- Output Layer: A final Dense layer with one neuron for predicting the target value, as the task involves forecasting a single output parameter;
- Compilation: This model was compiled using the Adam optimizer and the Mean Squared Error (MSE) loss function, which ensured the optimization of prediction accuracy for regression tasks;
- Training Parameters: A batch size of 32 samples and 100 epochs were selected for model training. The data were divided into training and testing sets in an 80/20 ratio using the “train_test_split” function. This model was trained on the training set, while the quality was assessed on the testing set;
- Normalization: All input features and target values were normalized to a range of 0 to 1 using “MinMaxScaler” to enhance the quality of training.
- This model begins with a multi-head attention layer featuring four heads. The size of the keys for each head is equal to the number of input features (22), allowing each head to focus on different aspects of the input data. This architecture enables the network to identify important dependencies among features across various time steps, thereby enhancing the extraction of temporal relationships;
- Following the multi-head attention layer, a Dropout layer with a dropout rate of 20% is included to prevent overfitting and improve the model’s generalization capability. Additionally, layer normalization with a small epsilon value (1 × 10−6) is applied to stabilize the network by normalizing the output of the attention layer;
- This model incorporates a residual connection that adds the original input data to the attention layer’s input. This retains the original representation of the data while complementing it with the attention results to enhance feature characteristics;
- Two consecutive GRU layers, each with 64 units, are utilized for further processing of the temporal sequence. The first GRU layer returns sequences (“return_sequences = True”), while the second GRU layer outputs only the final hidden state. Both GRU layers are accompanied by Dropout layers with a 20% dropout rate to mitigate overfitting;
- After the GRU layers, a fully connected (Dense) layer with 32 neurons and ReLU activation is used to form higher-level representations of the data. This is followed by a Dense output layer with a single neuron to predict the target value;
- This model was compiled using the Adam optimizer and the Mean Squared Error (MSE) loss function. MSE is suitable for regression tasks as it minimizes the mean squared deviation between the predicted and actual values, thereby enhancing forecasting accuracy. To improve model robustness, Dropout is applied after the attention layer and each GRU layer with a probability of 20%. This reduces the likelihood of overfitting, particularly when handling complex temporal data.
- In the initial phase, the ARIMA model is applied separately to each feature of the time series. The use of ARIMA facilitates the extraction of trend and seasonal components, highlighting their linear dependencies. The residuals obtained from the ARIMA model for each feature are then calculated, forming a time series that will be further trained in the LSTM neural network. In this study, the parameters of the ARIMA model are empirically selected for each series;
- The typical order of the ARIMA model used for trend analysis was (5, 1, 0), where 5 represents the autoregressive order; 1 indicates the order of differencing, and 0 signifies the order of the moving average;
- In the second phase, the ARIMA residuals are fed into the LSTM neural network to identify remaining nonlinear dependencies. The data were normalized to a range of 0 to 1 using “MinMaxScaler” to accelerate training and enhance the model’s robustness;
- The first LSTM layer consists of 64 units, returning sequences (return_sequences = True) for the subsequent layer. A Dropout layer with a probability of 0.2 is included to prevent overfitting;
- The second LSTM layer also contains 64 units but returns only the final hidden state (“return_sequences = False”);
- A fully connected (Dense) layer with 32 neurons and ReLU activation is applied to enhance nonlinear representations of the data. The output Dense layer contains 22 neurons, corresponding to the number of forecasted features;
- This model was compiled using the Adam optimizer and the Mean Squared Error (MSE) loss function, which is a standard approach for regression tasks. Training was conducted for 100 epochs with a batch size of 32.
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alali, Y.; Harrou, F.; Sun, Y. Unlocking the potential of wastewater treatment: Machine learning based energy consumption prediction. Water 2023, 15, 2349. [Google Scholar] [CrossRef]
- Halalsheh, N.; Alshboul, O.; Shehadeh, A.; Al Mamlook, R.E.; Al-Othman, A.; Tawalbeh, M.; Almuflih, A.S.; Papelis, C. Breakthrough curves prediction of selenite adsorption on chemically modified zeolite using boosted decision tree algorithms for water treatment applications. Water 2022, 14, 2519. [Google Scholar] [CrossRef]
- Sundui, B.; Ramirez Calderon, O.A.; Abdeldayem, O.M.; Lázaro-Gil, J.; Rene, E.R.; Sambuu, U. Applications of machine learning algorithms for biological wastewater treatment: Updates and perspectives. Clean Technol. Environ. Policy. 2021, 23, 127–143. [Google Scholar] [CrossRef]
- Gulshin, I.; Kuzina, O. Machine Learning Methods for the Prediction of Wastewater Treatment Efficiency and Anomaly Classification with Lack of Historical Data. Appl. Sci. 2024, 14, 10689. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, H.; Xu, R.; Wang, Y.; Chen, L.; Wei, C. Machine learning modeling for the prediction of phosphorus and nitrogen removal efficiency and screening of crucial microorganisms in wastewater treatment plants. Sci. Total Environ. 2024, 907, 167730. [Google Scholar] [CrossRef]
- El-Rawy, M.; Abd-Ellah, M.K.; Fathi, H.; Ahmed, A.K.A. Forecasting effluent and performance of wastewater treatment plant using different machine learning techniques. J. Water Process Eng. 2021, 44, 102380. [Google Scholar] [CrossRef]
- Asadi, A.; Verma, A.; Yang, K.; Mejabi, B. Wastewater treatment aeration process optimization: A data mining approach. J. Environ. Manag. 2017, 203, 630–639. [Google Scholar] [CrossRef]
- Elsayed, A.; Siam, A.; El-Dakhakhni, W. Machine learning classification algorithms for inadequate wastewater treatment risk mitigation. Process Saf. Environ. Prot. 2022, 159, 1224–1235. [Google Scholar] [CrossRef]
- Zaghloul, M.S.; Achari, G. Application of machine learning techniques to model a full-scale wastewater treatment plant with biological nutrient removal. J. Environ. Chem. Eng. 2022, 10, 107430. [Google Scholar] [CrossRef]
- Sakiewicz, P.; Piotrowski, K.; Ober, J.; Karwot, J. Innovative artificial neural network approach for integrated biogas–wastewater treatment system modelling: Effect of plant operating parameters on process intensification. Renew. Sustain. Energy Rev. 2020, 124, 109784. [Google Scholar] [CrossRef]
- Jawad, J.; Hawari, A.H.; Zaidi, S.J. Artificial neural network modeling of wastewater treatment and desalination using membrane processes: A review. Chem. Eng. J. 2021, 419, 129540. [Google Scholar] [CrossRef]
- Warren-Vega, W.M.; Montes-Pena, K.D.; Romero-Cano, L.A.; Zarate-Guzman, A.I. Development of an artificial neural network (ANN) for the prediction of a pilot scale mobile wastewater treatment plant performance. J. Environ. Manag. 2024, 366, 121612. [Google Scholar] [CrossRef]
- Waqas, S.; Harun, N.Y.; Sambudi, N.S.; Arshad, U.; Nordin, N.A.H.M.; Bilad, M.R.; Saeed, A.A.H.; Malik, A.A. SVM and ANN modelling approach for the optimization of membrane permeability of a membrane rotating biological contactor for wastewater treatment. Membranes 2022, 12, 821. [Google Scholar] [CrossRef]
- Wang, M.; Xu, X.; Yan, Z.; Wang, H. An online optimization method for extracting parameters of multi-parameter PV module model based on adaptive Levenberg-Marquardt algorithm. Energy Convers. Manag. 2021, 245, 114611. [Google Scholar] [CrossRef]
- Ridha, H.M.; Hizam, H.; Mirjalili, S.; Othman, M.L.; Ya’acob, M.E.; Ahmadipour, M.; Ismaeel, N.Q. On the problem formulation for parameter extraction of the photovoltaic model: Novel integration of hybrid evolutionary algorithm and Levenberg Marquardt based on adaptive damping parameter formula. Energy Convers. Manag. 2022, 256, 115403. [Google Scholar] [CrossRef]
- Ranade, N.V.; Nagarajan, S.; Sarvothaman, V.; Ranade, V.V. ANN based modelling of hydrodynamic cavitation processes: Biomass pre-treatment and wastewater treatment. Ultrason. Sonochem. 2021, 72, 105428. [Google Scholar] [CrossRef]
- Sibiya, N.P.; Amo-Duodu, G.; Tetteh, E.K.; Rathilal, S. Model prediction of coagulation by magnetised rice starch for wastewater treatment using response surface methodology (RSM) with artificial neural network (ANN). Sci. Afr. 2022, 17, e01282. [Google Scholar] [CrossRef]
- Wang, K.; Mao, Y.; Wang, C.; Wang, Q. Application of a combined response surface methodology (RSM)-artificial neural network (ANN) for multiple target optimization and prediction in a magnetic coagulation process for secondary effluent from municipal wastewater treatment plants. Environ. Sci. Pollut. Res. 2022, 29, 36075–36087. [Google Scholar] [CrossRef]
- Xu, B.; Pooi, C.K.; Tan, K.M.; Huang, S.; Shi, X.; Ng, H.Y. A novel long short-term memory artificial neural network (LSTM)-based soft-sensor to monitor and forecast wastewater treatment performance. J. Water Process Eng. 2023, 54, 104041. [Google Scholar] [CrossRef]
- Farhi, N.; Kohen, E.; Mamane, H.; Shavitt, Y. Prediction of wastewater treatment quality using LSTM neural network. Environ. Technol. Innov. 2021, 23, 101632. [Google Scholar] [CrossRef]
- Seshan, S.; Vries, D.; Immink, J.; van der Helm, A.; Poinapen, J. LSTM-based autoencoder models for real-time quality control of wastewater treatment sensor data. J. Hydroinformatics 2024, 26, 441–458. [Google Scholar] [CrossRef]
- Kow, P.Y.; Liou, J.Y.; Sun, W.; Chang, L.C.; Chang, F.J. Watershed groundwater level multistep ahead forecasts by fusing convolutional-based autoencoder and LSTM models. J. Environ. Manag. 2024, 351, 119789. [Google Scholar] [CrossRef]
- Zeng, L.; Jin, Q.; Lin, Z.; Zheng, C.; Wu, Y.; Wu, X.; Gao, X. Dual-attention LSTM autoencoder for fault detection in industrial complex dynamic processes. Process Saf. Environ. Prot. 2024, 185, 1145–1159. [Google Scholar] [CrossRef]
- Safder, U.; Kim, J.; Pak, G.; Rhee, G.; You, K. Investigating machine learning applications for effective real-time water quality parameter monitoring in full-scale wastewater treatment plants. Water 2022, 14, 3147. [Google Scholar] [CrossRef]
- Li, J.; Dong, J.; Chen, Z.; Li, X.; Yi, X.; Niu, G.; He, J.; Lu, S.; Ke, Y.; Huang, M. Free nitrous acid prediction in ANAMMOX process using hybrid deep neural network model. J. Environ. Manag. 2023, 345, 118566. [Google Scholar] [CrossRef]
- Xie, Y.; Mai, W.; Ke, S.; Zhang, C.; Chen, Z.; Wang, X.; Li, Y.; Dionysiou, D.D.; Huang, M. Artificial intelligence-implemented prediction and cost-effective optimization of micropollutant photodegradation using g-C3N4/Bi2O3 heterojunction. Chem. Eng. J. 2024, 499, 156029. [Google Scholar] [CrossRef]
- Wan, X.; Li, X.; Wang, X.; Yi, X.; Zhao, Y.; He, X.; Wu, R.; Huang, M. Water quality prediction model using Gaussian process regression based on deep learning for carbon neutrality in papermaking wastewater treatment system. Environ. Res. 2022, 211, 112942. [Google Scholar] [CrossRef]
- Du, X.; Yao, Y. FDA-SCN Network Based Soft Sensor for Wastewater Treatment Process. Pol. J. Environ. Stud. 2024, 33, 491–501. [Google Scholar] [CrossRef]
- Khozani, Z.S.; Banadkooki, F.B.; Ehteram, M.; Ahmed, A.N.; El-Shafie, A. Combining autoregressive integrated moving average with Long Short-Term Memory neural network and optimisation algorithms for predicting ground water level. J. Clean. Prod. 2022, 348, 131224. [Google Scholar] [CrossRef]
- Salamattalab, M.M.; Zonoozi, M.H.; Molavi-Arabshahi, M. Innovative approach for predicting biogas production from large-scale anaerobic digester using long-short term memory (LSTM) coupled with genetic algorithm (GA). Waste Manag. 2024, 175, 30–41. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, H.; Gupta, C.; Rao, A.R.; Khorasgani, H. A Non-Linear Function-on-Function Model for Regression with Time Series Data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 232–239. [Google Scholar] [CrossRef]
- Ly, Q.V.; Truong, V.H.; Ji, B.; Nguyen, X.C.; Cho, K.H.; Ngo, H.H.; Zhang, Z. Exploring potential machine learning application based on big data for prediction of wastewater quality from different full-scale wastewater treatment plants. Sci. Total Environ. 2022, 832, 154930. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Luo, Y.; Cheng, X.; Liu, X.; Wang, F.; Fang, F.; Cao, J.; Liu, W.; Xu, R. Prediction of biological nutrients removal in full-scale wastewater treatment plants using H2O automated machine learning and back propagation artificial neural network model: Optimization and comparison. Bioresour. Technol. 2023, 390, 129842. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Yu, J.; Tian, Y.; Ben, Y.; Cai, Z.; Zheng, C. Comparative Performance of Three Machine Learning Models in Predicting Influent Flow Rates and Nutrient Loads at Wastewater Treatment Plants. ACS EST Water 2023, 4, 1024–1035. [Google Scholar] [CrossRef]
- Li, L.; Lei, L.; Zheng, M.S.; Borthwick, A.G.L.; Ni, J.R. Stochastic evolutionary-based optimization for rapid diagnosis and energy-saving in pilot-and full-scale carrousel oxidation ditches. J. Environ. Inform. 2020, 35, 81–93. [Google Scholar] [CrossRef]
- Gogina, E.; Gulshin, I. Characteristics of low-oxygen oxidation ditch with improved nitrogen removal. Water 2021, 13, 3603. [Google Scholar] [CrossRef]
- Sardar, I.; Akbar, M.A.; Leiva, V.; Alsanad, A.; Mishra, P. Machine Learning and Automatic ARIMA/Prophet Models-Based Forecasting of COVID-19: Methodology, Evaluation, and Case Study in SAARC Countries. Stoch. Environ. Res. Risk Assess. 2023, 37, 345–359. [Google Scholar] [CrossRef]
- Jiang, J.; Xiang, X.; Zhou, Q.; Zhou, L.; Bi, X.; Khanal, S.K.; Wang, Z.; Chen, G.; Guo, G. Optimization of a Novel Engineered Ecosystem Integrating Carbon, Nitrogen, Phosphorus, and Sulfur Biotransformation for Saline Wastewater Treatment Using an Interpretable Machine Learning Approach. Environ. Sci. Technol. 2024, 58, 12989–12999. [Google Scholar] [CrossRef]
- Al Nuaimi, H.; Abdelmagid, M.; Bouabid, A.; Chrysikopoulos, C.V.; Maalouf, M. Classification of WatSan Technologies using machine learning techniques. Water 2023, 15, 2829. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Z.; Cai, J.; Zhang, M.; Liu, Z.; Xu, Y.; Li, R. Spatially adaptive machine learning models for predicting water quality in Hong Kong. J. Hydrol. 2023, 622, 129649. [Google Scholar] [CrossRef]
- Suryawan, I.G.T.; Putra, I.K.N.; Meliana, P.M.; Sudipa, I.G.I. Performance Comparison of ARIMA, LSTM, and Prophet Methods in Sales Forecasting. Sinkron. J. Penelit. Tek. Inform. 2024, 8, 2410–2421. [Google Scholar] [CrossRef]
- Uzel, Z. Comparative Analysis of LSTM, ARIMA, and Facebook’s Prophet for Traffic Forecasting: Advancements, Challenges, and Limitations. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2023. [Google Scholar]
- Long, B.; Tan, F.; Newman, M. Forecasting the Monkeypox Outbreak Using ARIMA, Prophet, NeuralProphet, and LSTM Models in the United States. Forecasting 2023, 5, 127–137. [Google Scholar] [CrossRef]
- Singh, N.K.; Yadav, M.; Singh, V.; Padhiyar, H.; Kumar, V.; Bhatia, S.K.; Show, P.L. Artificial intelligence and machine learning-based monitoring and design of biological wastewater treatment systems. Bioresour. Technol. 2023, 369, 128486. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Yang, S.; Li, J.; Oh, J.; Kang, H. Prediction model of sparse autoencoder-based bidirectional LSTM for wastewater flow rate. J. Supercomput. 2023, 79, 4412–4435. [Google Scholar] [CrossRef] [PubMed]
- Alvi, M.; Batstone, D.; Mbamba, C.K.; Keymer, P.; French, T.; Ward, A.; Dwyer, J.; Cardell-Oliver, R. Deep learning in wastewater treatment: A critical review. Water Res. 2023, 245, 120518. [Google Scholar] [CrossRef]
- Al Saleem, M.; Harrou, F.; Sun, Y. Explainable Machine Learning Methods for Predicting Water Treatment Plant Features under Varying Weather Conditions. Results Eng. 2024, 21, 101930. [Google Scholar] [CrossRef]
- Ekinci, E.; Özbay, B.; Omurca, S.İ.; Sayın, F.E.; Özbay, İ. Application of Machine Learning Algorithms and Feature Selection Methods for Better Prediction of Sludge Production in a Real Advanced Biological Wastewater Treatment Plant. J. Environ. Manag. 2023, 348, 119448. [Google Scholar] [CrossRef]
- Ching, P.M.L.; Zou, X.; Wu, D.; So, R.H.Y.; Chen, G.H. Development of a wide-range soft sensor for predicting wastewater BOD5 using an eXtreme gradient boosting (XGBoost) machine. Environ. Res. 2022, 210, 112953. [Google Scholar] [CrossRef]
- Cicceri, G.; Maisano, R.; Morey, N.; Distefano, S. A Machine Learning Approach for Anomaly Detection in Environmental IoT-Driven Wastewater Purification Systems. Int. J. Environ. Ecol. Eng. 2021, 15, 123–130. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Max. | Min. | Mean |
|---|---|---|---|
| BOD5, mgO2/L | 158 | 80 | 115 |
| NH4-N, mg/L | 81.8 | 18.5 | 37 |
| PO4-P, mg/L | 13.5 | 2.8 | 7.2 |
| TSS, mg/L | 194.15 | 89.88 | 115.36 |
| pH | 8.7 | 7.3 | 7.7 |
| Model | MSE | MAE | SMAPE | R2 |
|---|---|---|---|---|
| LSTM | 2.860 | 1.332 | 1.183 | 0.987 |
| ARIMA–LSTM | 2.754 | 1.224 | 1.052 | 0.991 |
| MAGRU | 2.799 | 1.289 | 1.091 | 0.986 |
| Prophet | 3.005 | 1.417 | 1.288 | 0.918 |
| CatBoost | 3.011 | 1.421 | 1.301 | 0.897 |
| XGBoost | 3.028 | 1.435 | 1.312 | 0.891 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gulshin, I.; Makisha, N. Predicting Wastewater Characteristics Using Artificial Neural Network and Machine Learning Methods for Enhanced Operation of Oxidation Ditch. Appl. Sci. 2025, 15, 1351. https://doi.org/10.3390/app15031351
Gulshin I, Makisha N. Predicting Wastewater Characteristics Using Artificial Neural Network and Machine Learning Methods for Enhanced Operation of Oxidation Ditch. Applied Sciences. 2025; 15(3):1351. https://doi.org/10.3390/app15031351
Chicago/Turabian StyleGulshin, Igor, and Nikolay Makisha. 2025. "Predicting Wastewater Characteristics Using Artificial Neural Network and Machine Learning Methods for Enhanced Operation of Oxidation Ditch" Applied Sciences 15, no. 3: 1351. https://doi.org/10.3390/app15031351
APA StyleGulshin, I., & Makisha, N. (2025). Predicting Wastewater Characteristics Using Artificial Neural Network and Machine Learning Methods for Enhanced Operation of Oxidation Ditch. Applied Sciences, 15(3), 1351. https://doi.org/10.3390/app15031351