1. Introduction
The proliferation of mobile smart devices has made video recording an essential part of daily life. However, it is recognized that captured videos can experience blur as a result of camera shake and object motion. Therefore, the development and application of effective video deblurring algorithms are highly beneficial for improving video quality and enhancing the overall viewing experience. Moreover, video deblurring serves as a crucial preprocessing step for high-level vision tasks, such as action recognition [
1], object detection [
2], and visual tracking [
3], where the quality of input videos significantly impacts the downstream performance.
Video deblurring remains a challenging restoration task, with its core difficulty lying in effectively utilizing temporal information from video sequences. Research [
4] has shown that appropriate feature alignment strategies are vital for improving deblurring performance. Early methods primarily employed optical flow [
5,
6,
7] for explicit alignment, but blur-induced inaccuracies in flow estimation propagated errors that compromised reconstruction quality. To address this limitation, researchers developed adaptive feature alignment schemes based on deformable convolution [
8,
9,
10]. Recently, transformers have emerged as a promising solution [
11,
12,
13] for video deblurring, demonstrating superior performance in complex scenarios through their powerful self-attention mechanisms and long-range dependency modeling capabilities.
However, video deblurring faces unique challenges compared to other video restoration tasks, like super-resolution. Blur not only results in the loss of high-frequency details but also significantly distorts the fundamental image structure. While existing methods have achieved remarkable progress in detail recovery, they often overlook the equally important aspect of structural information reconstruction. Therefore, effectively addressing the simultaneous management of high-frequency details and low-frequency structural information in video deblurring continues to pose a significant challenge within the field of research.
To address these issues, this paper proposes a wavelet-based, blur-aware decoupled network (WBDNet) that decouples structure recovery from detail enhancement. Unlike previous approaches [
14,
15,
16] that merely used wavelet transforms for multi-scale feature extraction, we design specialized recovery strategies for different frequency bands. Specifically, we introduce a multi-scale progressive fusion (MSPF) module and a blur-aware detail enhancement (BADE) module. In the low-frequency domain, the MSPF module operates in several steps. It first employs optical flow for coarse alignment. Then, it constructs multi-scale feature pyramids and uses bottom-up progressive feature fusion to reconstruct the main image structure. In the high-frequency domain, the BADE module takes a different approach. It integrates blur-aware attention mechanisms with deformable convolution. This integration enhances features in sharp regions, thereby enabling more refined alignment. As a result, this approach enables the effective extraction and integration of valuable detailed information from multiple frames.
Our main contributions can be summarized as follows:
We propose a novel multi-scale progressive fusion (MSPF) module that effectively reconstructs structural information through multi-scale feature fusion, significantly improving the restoration of low-frequency components.
We design an innovative blur-aware detail enhancement module (BADE) that adaptively perceives and extracts sharp features across multiple frames for precise detail recovery, enabling more effective high-frequency information restoration.
Experimental results on benchmark datasets demonstrate that our proposed method achieves significant performance improvements over state-of-the-art approaches, particularly in preserving both structural integrity and detail fidelity.
The remainder of this paper is organized as follows:
Section 2 presents a comprehensive review of related work.
Section 3 details the design of the proposed network architecture.
Section 4 provides a comparative analysis with existing methods and experimental results on benchmark datasets.
Section 5 conducts an in-depth investigation into the effectiveness of each network module. Finally,
Section 6 concludes the paper with a summary of our findings.
3. Wavelet-Based, Blur-Aware Decoupled Network
3.1. Network Overview
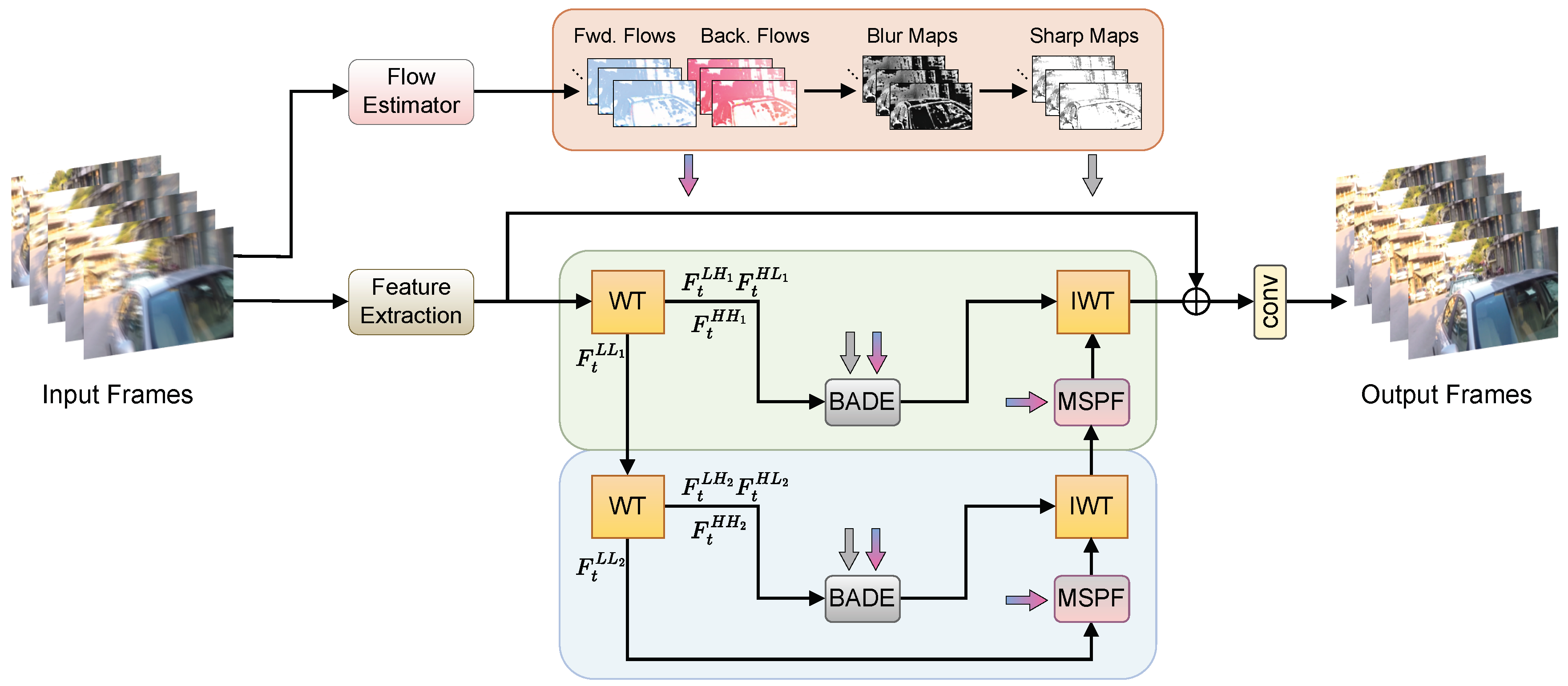
As shown in
Figure 1, given a sequence of blurred video frames (
), our goal is to reconstruct the corresponding sharp video frames (
). The proposed network architecture consists of two main branches: a preprocessing branch and a feature reconstruction branch. The preprocessing branch estimates inter-frame optical flow and sharp maps to provide prior information for subsequent deblurring. In contrast, the feature reconstruction branch employs a wavelet transform-based design to recover structure and detail information from low-frequency and high-frequency sub-bands, respectively.
In the preprocessing branch, we first utilize an optical flow estimation network [
43] to compute motion information between adjacent frames in a video sequence. Specifically, for any frame (
), we calculate the optical flow (
) between this frame and others. Considering that motion is the primary cause of blur, with higher motion corresponding to increased blur, we use optical flow between adjacent frames to estimate the blur map (
) for video frame
:
For the first and last frames of the video sequence, we set
and
, respectively. Subsequently, we normalize the blur map (
) to the
interval to obtain the normalized blur map (
) and corresponding sharp map (
):
In the feature reconstruction branch, we first extract shallow features () from video frames through several residual blocks. We then use wavelet transform to decompose these features into one low-frequency sub-band () and three high-frequency sub-bands (, , and ). To achieve multi-scale feature representation, we further decompose the low-frequency sub-band () into corresponding low-and high-frequency sub-bands.
We design specialized processing modules based on the characteristics of different frequency band features. For low-frequency features, we develop the multi-scale progressive fusion (MSPF) module to handle structural reconstruction. For high-frequency features, we create the blur-aware detail enhancement (BADE) module to focus on detail recovery. This decoupled design enables the network to process frame features at different scales more specifically.
3.2. Multi-Scale Progressive Fusion Module
The low-frequency sub-bands obtained through wavelet transform carry the main structural information of the frames. Unlike other video restoration tasks, video deblurring requires not only detailed recovery but also reconstruction of structure distortions caused by blur. Based on this characteristic, we designed the multi-scale progressive fusion (MSPF) module specifically to address structural information reconstruction in low-frequency sub-band features.
The core idea of the MSPF module is to utilize redundant structural information from multiple frames to assist in target frame restoration. As shown in
Figure 2, we first align features from other frames to the target frame using optical flow information obtained from the preprocessing branch. Considering that low-frequency sub-bands mainly contain structural information, we adopt basic optical flow alignment instead of computationally intensive deformable convolution, maintaining effectiveness while improving computational efficiency. Denoting the target frame features as
and aligned features from other frames as
, where
represents the original scale, we construct a three-level feature pyramid (
) using strided convolution filters for two 2× downsampling operations to expand the network’s receptive field to capture broader structural information.
We employ a bottom-up fusion strategy, starting from the lowest scale (
) and proceeding level by level. At each scale level, we first concatenate the target frame features with other frame features along the channel dimension and input them into the structure feature fusion block (SFFB) for processing. The fusion process at
can be expressed as follows:
where
denotes the feature concatenation operation and
represents 2× upsampling. This process continues progressively until output features are obtained at the original scale (
).
In the SFFB, to emphasize common structural features and suppress interference, we first compute similarity maps between the target frame and other frame features, reflecting structural correlation at each position through similarity distances. By multiplying features with similarity maps, we obtain features with enhanced structural information. This process is represented as follows:
where
and
are feature embedding functions implemented through convolution layers, ⊙ denotes element-wise multiplication, and the sigmoid function normalizes similarity values to the
interval. The enhanced features are concatenated along the channel dimension and compressed through a convolution layer. To obtain more comprehensive structural representations, SFFB employs parallel convolution kernels of different sizes to extract multi-receptive field features, fusing structural information at different scales for complementary enhancement. This design ensures the network can comprehensively capture and integrate structural information in both temporal and scale domains.
3.3. Blur-Aware Detail Enhancement Module
High-frequency sub-bands, as crucial components of wavelet transform, contain rich, detailed information on frames. To effectively recover these details, we propose the blur-aware detail enhancement (BADE) module. The core design principle of this module is to fully utilize temporal information from video sequences while considering the impact of motion blur for precise detail recovery. We first concatenate high-frequency sub-band features (, , and ) along the channel dimension as input to the BADE module.
The specific details of the BADE module are shown in
Figure 3. Let
denote the target frame features and
denote features from other frames. Other frame features first pass through a blur-aware attention block (BAAB). In this block, we incorporate the sharp map (
) from the preprocessing branch. This sharp map provides crucial prior information about motion-blurred regions in the video. Using this information, we adaptively modulate inter-frame features to reduce the impact of blurred pixels. Specifically, the computation process of BAAB is expressed as follows:
where
represents the feature concatenation operation and ⊙ denotes element-wise multiplication. This design enables the network to dynamically adjust feature responses based on sharpness information, enhancing representations in sharp regions while suppressing the influence of blurred regions. The residual connection ensures the effective transmission of original feature information.
After obtaining enhanced feature representations, we adopt a residual-flow learning approach to obtain sampling offsets for deformable convolution, which aligns
to
individually through deformable convolution:
where
denotes a stack of convolutions, and
and
represent the offset and modulation factor for deformable convolution, respectively. This design offers two key advantages. The first advantage relates to feature enhancement. Through BAAB, detail features in sharp regions become more prominent, which leads to improved feature-matching accuracy. The second advantage concerns motion handling. By using residual-flow learning to guide the offset field estimation in deformable convolution, the network can better adapt to large-scale motion changes in complex scenes. Overall, this design facilitates the effective transmission of detailed information throughout the alignment process.
Finally, we concatenate all aligned frame features along the channel dimension, compress the channel dimension through one convolution layer, and use cascaded residual blocks for deep feature extraction. This enables the network to fully integrate multi-frame information, further enhancing the expressiveness of detail features.
6. Conclusions
In this paper, we propose a novel wavelet-based, blur-aware decoupled network (WBDNet). Through wavelet transform, we decompose the deblurring task into two subtasks: structure restoration and detail enhancement. For the low-frequency domain, we design a multi-scale progressive fusion (MSPF) module that effectively integrates multi-frame structural information through a multi-scale feature fusion strategy and structure feature fusion block. For the high-frequency domain, we introduce a blur-aware detail enhancement (BADE) module that combines a blur-aware attention block utilizing sharpness priors and deformable convolution alignment based on optical flow residuals to enhance detail reconstruction. Experimental results on benchmark datasets demonstrate that our proposed method achieves excellent performance in both objective metrics and subjective visual quality.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}