
User Profile Construction Based on High-Dimensional Features Extracted by Stacking Ensemble Learning


Abstract
1. Introduction
- It proposes the 3Cs principle for the risk assessment of social network users, categorizing raw datasets into three foundational attributes based on behavioral patterns and constructing OSN user profiles accordingly.
- It analyzes and compares the strengths and weaknesses of various supervised learning algorithms in extracting high-dimensional attributes, identifying the most suitable classifiers for profiling tasks.
- It improves traditional stacking methods by integrating diverse machine learning algorithms to extract high-dimensional user attributes, enhancing the accuracy and robustness of user profiles by leveraging basic attribute information.
2. Related Works
2.1. ML-Based User Profiling Research
2.2. DL-Based User Profiling Research
2.3. Applications of User Profiling in Network Community Environment Governance
3. Method
3.1. Basic Attributes for User Profiling
- (1)
- Capacity:
- (2)
- Character:
- (3)
- Conditions:
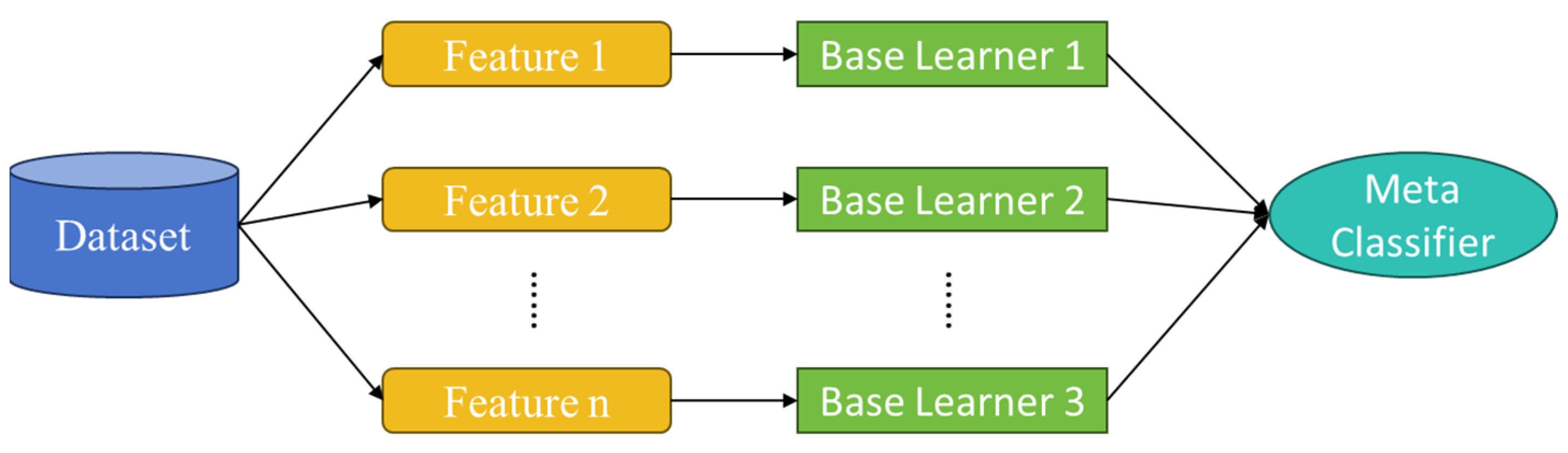
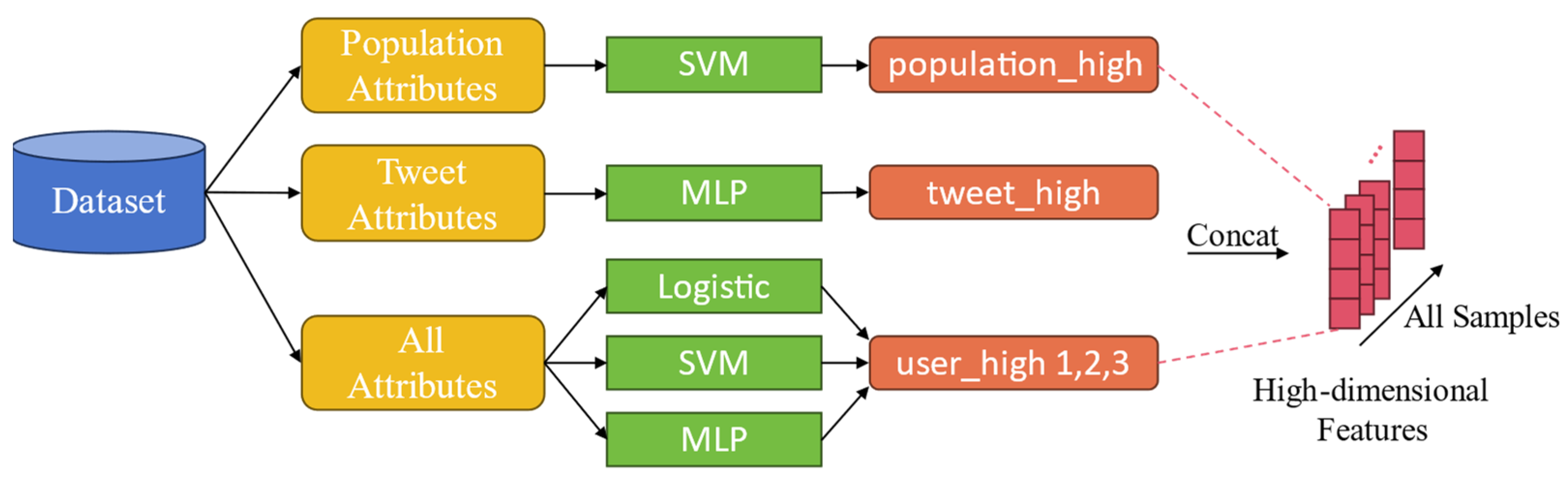
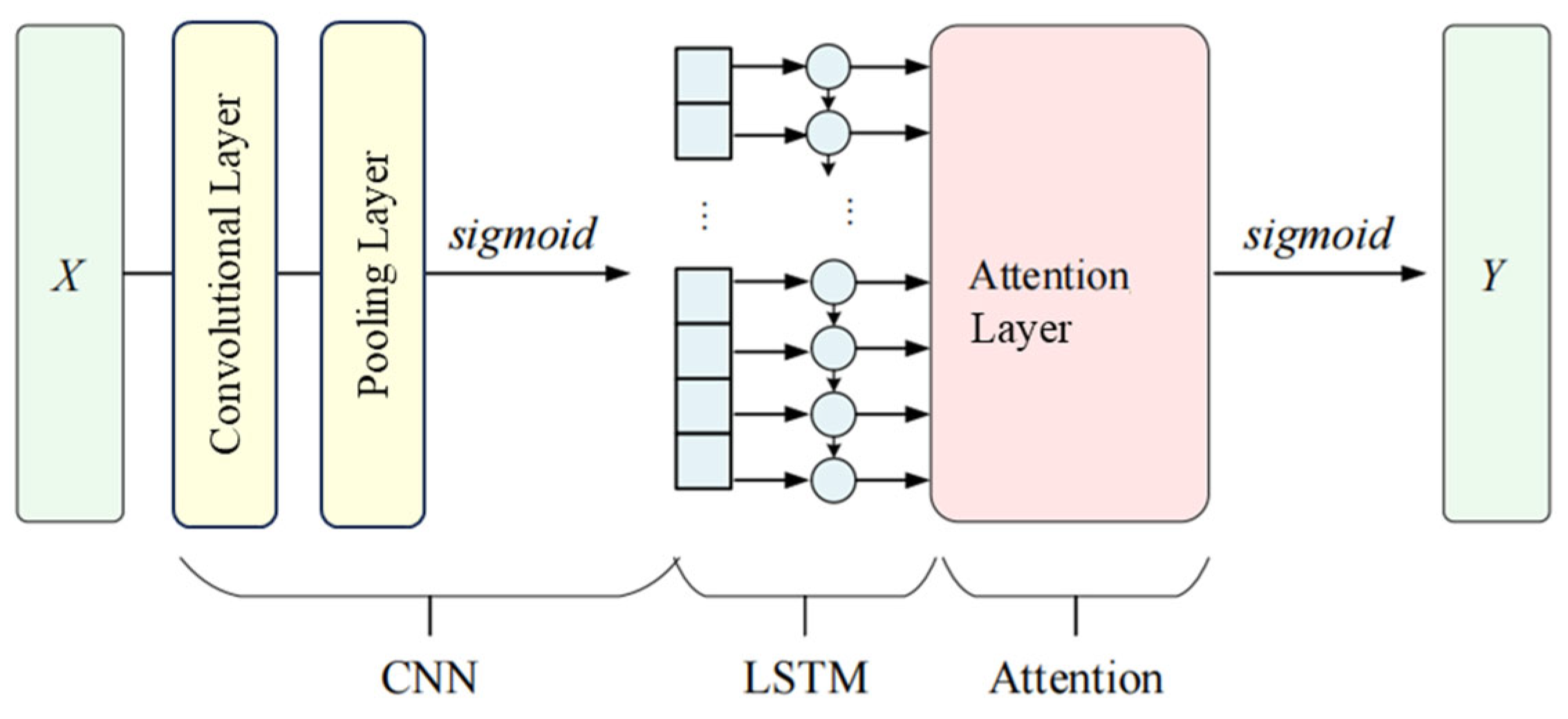
3.2. High-Dimensional Feature Extraction Using Stacking Learning
4. Experiment
4.1. Implementation Details
4.2. Stacking Base Classifier Performance Analysis
4.3. Performance Evaluation of User Profiling with Integrated High-Dimensional Features
4.4. Robustness Analysis
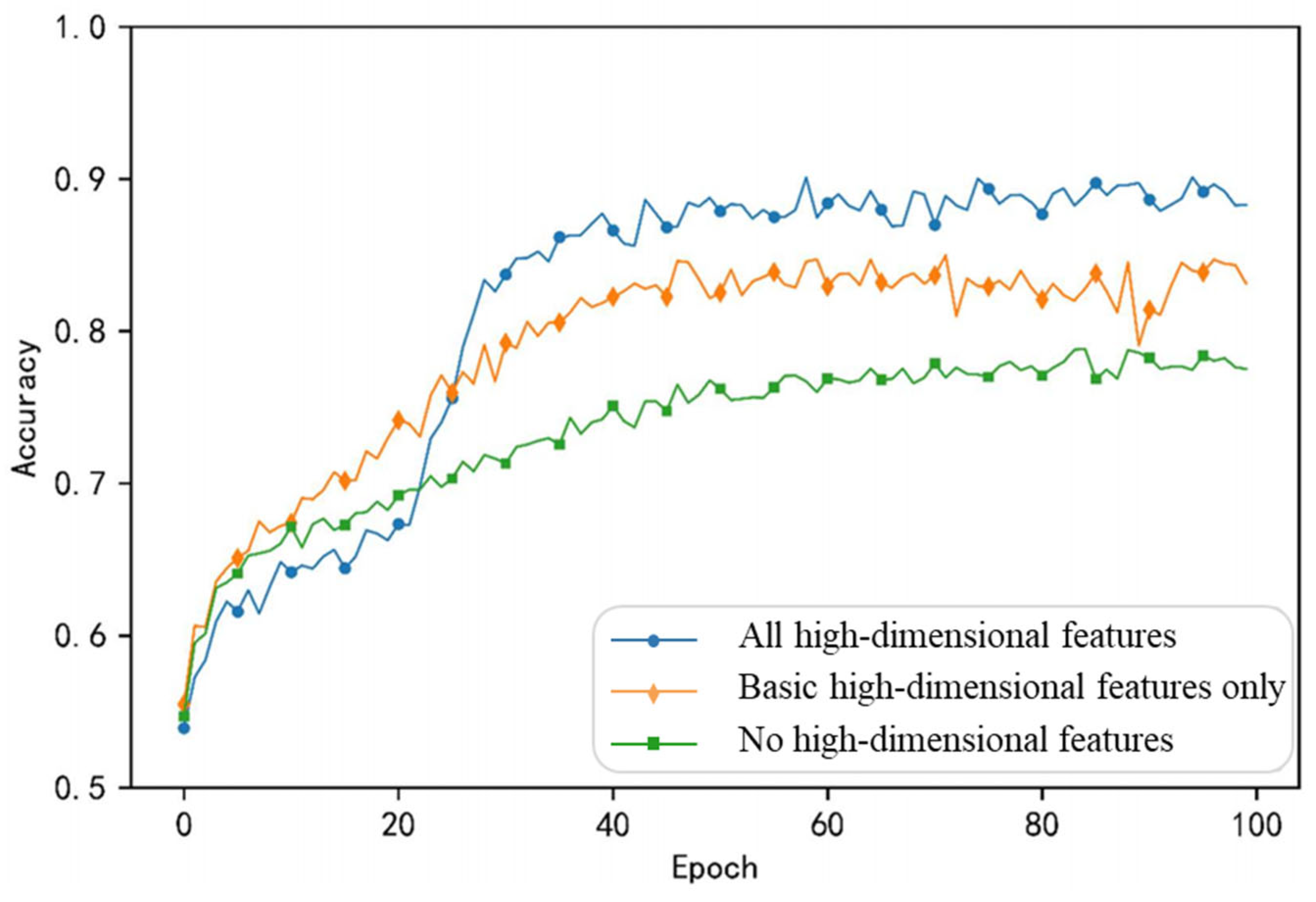
- When all high-dimensional features are integrated, the training curve fluctuates at a high level, indicating that the profiling model performs well even when incorporating all potential high-dimensional features as input.
- When only basic high-dimensional features are added, the curve closely follows the blue curve (all features) with similar fluctuations. The profiling model’s performance remains relatively good in this case, but it may lose some information, leading to a slight decline in performance.
- Without high-dimensional features, the model performs the worst.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Contri, M.; Fissi, S.; Gori, E. Citizen engagement and dialogic accounting through social media: A study of Italian regions. Accounting. Audit. Account. 2023, 37, 866–892. [Google Scholar] [CrossRef]
- Stone, J.A.; Flanders, K.J.; Robles, P.; Can, S.H. Strategic measurement and evaluation of municipal social media: Insight from front-line personnel in the United States. Transform. Gov. People Process Policy 2023, 18, 103–117. [Google Scholar] [CrossRef]
- Ordóñez, A.G.; Cañada, F.J.A.; Lasso, E.; Sánchez-Torres, J.A.; Escobar-Sierra, M. Analytical model to measure the effectiveness of content marketing on Twitter: The case of governorates in Colombia. J. Mark. Anal. 2023, 12, 962–978. [Google Scholar] [CrossRef]
- Bonsón, E.; Perea, D.; Bednárová, M. Twitter as a tool for citizen engagement: An empirical study of the andalusian municipalities. Gov. Inf. Q. 2019, 36, 480–489. [Google Scholar] [CrossRef]
- Lincy, N.L.; Midhunchakkaravarthy. The investigation of network security, including penetrating threats and potential security measures. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2022; pp. 107–117. [Google Scholar]
- Shang, P. Artificial Intelligence and Criminal Investigation: Historical changes, technical classifications, and future prospects. J. People’s Public Secur. Univ. China (Soc. Sci. Ed.) 2020, 36, 46–54. (In Chinese) [Google Scholar]
- Roy, K.P.; Tripathy, K.A. Cybercrime in Social Media: Theory and Solutions; Chapman and Hall/CRC: New York, NY, USA, 2023; p. 276. [Google Scholar]
- Anjum; Katarya, R. Hate speech; toxicity detection in online social media: A recent survey of state of the art and opportunities. Int. J. Inf. Secur. 2023, 23, 577–608. [Google Scholar] [CrossRef]
- Yiouli, K.; Demestichas, P.; Adamopoulou, E.; Demestichas, K.P.; Theologou, M.; Paradia, M. User Profile Modeling in the context of web-based learning management systems. J. Netw. Comput. Appl. 2008, 31, 603–627. [Google Scholar]
- Bui, T.-H. Estimating bounding box for point of interest using social media geo-tagged photos. IEEE Access 2023, 11, 7387–7849. [Google Scholar] [CrossRef]
- Yang, X.; Gao, J.; Zheng, X.; Fang, M.; Tang, L.; Zhang, X. Point-of-interest detection from Weibo data for map updating. Trans. GIS 2022, 26, 2716–2738. [Google Scholar] [CrossRef]
- Chew, R.; Kery, C.; Baum, L.; Bukowski, T.; Kim, A.; Navarro, M. Predicting age groups of reddit users based on posting behavior and metadata: Classification model development and validation. JMIR Public Health Surveill 2021, 7, e25807. [Google Scholar] [CrossRef]
- Emad, E.A.; Jamil, R.A.; Muath, A. Age and gender prediction in open domain text. Procedia Comput. Sci. 2020, 170, 563–570. [Google Scholar]
- Tsao, S.; MacLean, A.; Chen, H.; Li, L.; Yang, Y.; Butt, Z.A. Public attitudes during the second lockdown: Sentiment and topic analyses using Tweets from Ontario, Canada. Int. J. Public Health 2022, 67, 82. [Google Scholar] [CrossRef] [PubMed]
- Alejandro, H.H.; Mónica, D.R.T.; Esteban, R.S.; Lorenzo, C.; Lencinas, M.V.; Pastur, G.M. Social media reveal visitors’ interest in flora and fauna species of a forest region. Ecosyst. People 2023, 19, 2155248. [Google Scholar]
- Alsaqer, M.; Alelyani, S.; Mohana, M.; Alreemy, K.; Alqahtani, A. Predicting location of Tweets using machine learning approaches. Appl. Sci. 2023, 13, 3025. [Google Scholar] [CrossRef]
- Roberto, S.; Ludovico, B.; Salvatore, C. Semantic coherence-based user profile modeling in the recommender systems context. In International Conference on Knowledge Discovery and Information Retrieval; SciTePress: Setúbal, Portugal, 2014; Volume 2, pp. 154–161. [Google Scholar]
- Roy, P.K.; Chahar, S. Fake profile detection on social networking websites: A comprehensive review. IEEE Trans. Artif. Intell. 2020, 13, 271–285. [Google Scholar] [CrossRef]
- Zhaoyang, W.; Li, L.; Ketai, H. Deep User Profile Construction and Behavior Prediction Based on Multimodal Heterogeneous Feature Fusion. In Proceedings of the 2024 IEEE 19th Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 5–8 August 2024; pp. 1–6. [Google Scholar]
- Samuel, J.; Ali, G.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appllied Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public perception of the COVID-19 pandemic on Twitter: Sentiment analysis and topic modeling study. JMIR Public Health Surveill 2021, 6, e21978. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A large-scale benchmark Twitter data set for COVID-19 sentiment analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef]
- Tao, W.; Peng, Y. Differentiation and unity: A cross-platform comparison analysis of online posts’ semantics of the Russian–Ukrainian war based on Weibo and Twitter. Commun. Public 2023, 8, 105–124. [Google Scholar] [CrossRef]
- Ma, M.; Gao, Q.; Xiao, Z.; Hou, X.; Hu, B.; Jia, L.; Song, W. Analysis of public emotion on flood disasters in southern China in 2020 based on social media data. Nat. Hazards 2023, 118, 1013–1033. [Google Scholar] [CrossRef]
- Zhang, Y.; Ji, T. Youth are united online to fight against involution: A study of group cohesion on Weibo. Front. Psychol. 2023, 18, 1014331. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Zuo, Z.; Zhang, Y.; Wang, X. Exploring sentiment divergence on migrant workers through the lens of Sina Weibo. Internet Res. 2023, 33, 1331–1371. [Google Scholar] [CrossRef]
- Kanaparthi, S.D.; Patle, A.; Naik, K.J. Prediction and detection of emotional tone in online social media mental disorder groups using regression and recurrent neural networks. Multimed. Tools Appl. 2023, 82, 43819–43839. [Google Scholar] [CrossRef]
- Ni, W.; Du, Y.; Ma, X.; Lv, H. Research on Hybrid Recommendation Model for Personalized Recommendation Scenarios. Appl. Sci. 2023, 13, 7903. [Google Scholar] [CrossRef]
- Mubarak, H.; Abdaljalil, S.; Nassar, A.; Alam, F. Detecting and identifying the reasons for deleted tweets before they are posted. Front. Artif. Intell. 2023, 6, 1219767. [Google Scholar] [CrossRef]
- Tufchi, S.; Yadav, A.; Ahmed, T. A comprehensive survey of multimodal fake news detection techniques: Advances, challenges, and opportunities. Int. J. Multimed. Inf. Retr. 2023, 12, 28. [Google Scholar] [CrossRef]
- Su, X.; Xiao, L.; Li, W.; Liu, X.; Li, K.-C.; Liang, W. DroidPortrait: Android Malware Portrait Construction Based on Multidimensional Behavior Analysis. Appl. Sci. 2020, 10, 3978. [Google Scholar] [CrossRef]
- Alarfaj, F.K.; Ahmad, H.; Khan, H.U.; Alomair, A.M.; Almusallam, N.; Ahmed, M. Twitter bot detection using diverse content features and applying machine learning algorithms. Sustainability 2023, 15, 6662. [Google Scholar] [CrossRef]
- Xuejian, H.; Gen-sheng, W.; Luo, Y.; Min, L.; Wu, X.-F.; Li, Z.-P. Weibo Rumors Real-time Detection Model Based on Fusion of Multi User Features and Content Features. J. Chin. Comput. Syst. 2021, 43, 1–12. (In Chinese) [Google Scholar]
- Ghosh, S.; Reilly, D.L. Credit card fraud detection with a neural-network. In Proceedings of the 27th Hawaii International Conference on System Sciences, Wailea, HI, USA, 4–7 January 1994; pp. 621–630. [Google Scholar]
- Rongrong, C.; Guohua, Z.; Zhihua, L. Research on credit card transaction fraud prediction based on XGBoost algorithm model. Appl. Res. Comput. 2020, 37, 111–112, 115. (In Chinese) [Google Scholar]
- Donat, B.S.; Onat, K.O. The roles of value preferences and cognitive emotion regulation strategies on prediction of dating violence. Int. J. Psychol. Educ. Stud. 2020, 7, 96–107. [Google Scholar] [CrossRef]
- Dinesh, M.; Azath, M.; Bayapa, R.N.; Ramakrishnan, J.; John, R.; Ravishankar, N.; Karthika, P. Deep convolutional neural network based real-time abnormal behavior detection in social networks. Comput. Electr. Eng. 2023, 111, 108987. [Google Scholar]
- Xu, Y.; Zhang, P.; Yu, H.; Zhang, F. Detecting group shilling attacks in recommender systems based on user multi-dimensional features and collusive behaviour analysis. Comput. J. 2023, 67, 604–616. [Google Scholar] [CrossRef]
- Rosenberg, E.; Gleit, A. Quantitative methods in credit management: A survey. Oper. Res. 1994, 42, 589613. [Google Scholar] [CrossRef]
- Costa, H.; Merschmann, L.H.; Barth, F.; Benevenuto, F. Pollution, bad-mouthing, and local marketing: The underground of location-based social networks. Inf. Sci. 2014, 279, 123–137. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3Cs Principles Summarized Based on Traditional Methods | Latent Behavior Pattern | Representative Features |
|---|---|---|
| Capacity | Economic stability | Age |
| Job | ||
| Activity | ||
| Well educated | Education | |
| Conditions | Be noticed | |
| Healthy living habits | Active time | |
| IP | ||
| Character | Creative Posting habits | Emotional polarity distribution |
| Emoji usage frequency | ||
| Sex | ||
| Length of original text | ||
| Prudent and responsible | Post similar content repeatedly | |
| URL chain |
| Attributes | Features |
|---|---|
| Population Attributes | name length, name letter count, name number count, name emoji count, age, sex, educate, IP, name_vec |
| Tweet Attributes | day, hour, origin, topic, topic_vec, url_count, emoji_count, emo, tweet_vec |
| Social Attributes | followers, followings, friend_fraction, forward, comment, like, reference, social_connect, exposure |
| Feature Name | Description |
|---|---|
| Population_high | High-dimensional feature obtained by using various classifiers from population attributes |
| Tweet_high | High-dimensional feature obtained by using various classifiers from tweet attributes |
| Social_high | High-dimensional feature obtained by using various classifiers from social attributes |
| User_high | High-dimensional feature obtained by using various classifiers from all attributes |
| Label | Classification | Count | Percent |
|---|---|---|---|
| Spam | Local marketer | 1063 | 15.1% |
| Polluter | 1716 | 24.2% | |
| Bad-mouther | 759 | 10.7% | |
| Non-spam | Non-spammer | 3538 | 50% |
| Total | 7076 | 100% |
| No. | Base Learner | Chi-Squared | p-Value | Pearson | Spearman |
|---|---|---|---|---|---|
| 1 | Logistic | 2008.42 | 0 | 5.33 × 10−1 | 5.33 × 10−1 |
| 2 | SVM | 182.89 | 1.13 × 10−41 | 1.61 × 10−1 | 1.61 × 10−1 |
| 3 | MLP | 2823.05 | 0 | 7.01 × 10−1 | 7.01 × 10−1 |
| 4 | 1D-CNN | 3471.02 | 0 | 1.50 × 10−1 | 1.50 × 10−1 |
| 5 | Decision tree | 5512.86 | 0 | 8.83 × 10−1 | 8.83 × 10−1 |
| Non-Spam | Spam | |||||
|---|---|---|---|---|---|---|
| No. | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| 1 | 87.1% | 75.8% | 81.0% | 78.1% | 88.1% | 82.8% |
| 2 | 87.9% | 75.6% | 81.3% | 78.1% | 89.2% | 83.3% |
| 3 | 85.6% | 74.9% | 79.9% | 76.3% | 86.7% | 81.2% |
| 4 | 79.6% | 76.2% | 77.9% | 75.5% | 80.1% | 77.7% |
| 5 | 79.8% | 77.8% | 78.8% | 77.4% | 79.8% | 78.6% |
| No. | Base Learner | Chi-Squared | p-Value | Pearson | Spearman |
|---|---|---|---|---|---|
| 1 | Logistic | 2112.53 | 0 | 5.47 × 10−1 | 5.47 × 10−1 |
| 2 | SVM | 1010.21 | 1.07 × 10−221 | 3.78 × 10−1 | 3.78 × 10−1 |
| 3 | MLP | 3588.55 | 0 | 7.12 × 10−1 | 7.12 × 10−1 |
| 4 | 1D-CNN | 2959.66 | 0 | 6.47 × 10−1 | 6.47 × 10−1 |
| 5 | Decision tree | 5723.98 | 0 | 8.99 × 10−1 | 8.99 × 10−1 |
| Non-Spam | Spam | |||||
|---|---|---|---|---|---|---|
| No. | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| 1 | 82.1% | 79.2% | 80.6% | 79.4% | 82.1% | 80.7% |
| 2 | 82.3% | 82.1% | 82.2% | 81.9% | 82.0% | 82.0% |
| 3 | 82.4% | 79.8% | 81.1% | 79.8% | 82.3% | 81.1% |
| 4 | 75.8% | 74.9% | 75.3% | 74.2% | 75.1% | 74.6% |
| 5 | 78.3% | 75.8% | 77.0% | 75.8% | 78.6% | 77.2% |
| No. | Base Learner | Chi-Squared | p-Value | Pearson | Spearman |
|---|---|---|---|---|---|
| 1 | Logistic | 259.81 | 1.88 × 10−58 | 1.92 × 10−1 | 1.92 × 10−1 |
| 2 | SVM | 394.25 | 9.81 × 10−88 | 2.37 × 10−1 | 2.37 × 10−1 |
| 3 | MLP | 479.53 | 2.70 × 10−106 | 2.61 × 10−1 | 2.61 × 10−1 |
| 4 | 1D-CNN | 572.35 | 1.72 × 10−126 | 2.85 × 10−1 | 2.85 × 10−1 |
| 5 | Decision tree | 686.05 | 3.23 × 10−151 | 3.12 × 10−1 | 3.12 × 10−1 |
| Non-Spam | Spam | |||||
|---|---|---|---|---|---|---|
| No. | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| 1 | 57.3% | 94.5% | 71.3% | 81.2% | 27.8% | 41.4% |
| 2 | 57.1% | 93.7% | 71.0% | 80.1% | 28.2% | 41.7% |
| 3 | 56.5% | 92.1% | 70.0% | 77.8% | 28.2% | 41.4% |
| 4 | 57.5% | 95.8% | 71.9% | 86.1% | 27.6% | 41.8% |
| 5 | 57.6% | 94.2% | 71.5% | 81.7% | 29.1% | 42.9% |
| No. | Base Learner | Chi-Squared | p-Value | Pearson | Spearman |
|---|---|---|---|---|---|
| 1 | Logistic | 2825.84 | 0 | 6.32 × 10−1 | 6.32 × 10−1 |
| 2 | SVM | 833.34 | 3.03 × 10−183 | 3.44 × 10−1 | 3.44 × 10−1 |
| 3 | MLP | 5983.71 | 0 | 9.20 × 10−1 | 9.20 × 10−1 |
| 4 | 1D-CNN | 3355.86 | 0.28 | 6.89 × 10−1 | 6.89 × 10−1 |
| 5 | Decision tree | 6260.92 | 0 | 9.41 × 10−1 | 9.41 × 10−1 |
| Non-Spam | Spam | |||||
|---|---|---|---|---|---|---|
| No. | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| 1 | 92.1% | 86.6% | 89.3% | 86.6% | 92.8% | 89.6% |
| 2 | 93.8% | 85.4% | 89.4% | 86.1% | 93.7% | 89.7% |
| 3 | 90.8% | 85.8% | 88.2% | 85.6% | 91.8% | 88.6% |
| 4 | 88.8% | 84.1% | 86.4% | 84.7% | 89.5% | 87.0% |
| 5 | 85.2% | 85.5% | 85.3% | 85.1% | 85.1% | 85.1% |
| Input | AUC | MCC |
|---|---|---|
| Original feature | 0.5665 | 0.1862 |
| Add basic high-dimensional features | 0.6013 | 0.2476 |
| Add all high-dimensional features | 0.6034 | 0.2514 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, L.; He, K.; Zhu, Z. User Profile Construction Based on High-Dimensional Features Extracted by Stacking Ensemble Learning. Appl. Sci. 2025, 15, 1224. https://doi.org/10.3390/app15031224
Wang Z, Li L, He K, Zhu Z. User Profile Construction Based on High-Dimensional Features Extracted by Stacking Ensemble Learning. Applied Sciences. 2025; 15(3):1224. https://doi.org/10.3390/app15031224
Chicago/Turabian StyleWang, Zhaoyang, Li Li, Ketai He, and Zhenyang Zhu. 2025. "User Profile Construction Based on High-Dimensional Features Extracted by Stacking Ensemble Learning" Applied Sciences 15, no. 3: 1224. https://doi.org/10.3390/app15031224
APA StyleWang, Z., Li, L., He, K., & Zhu, Z. (2025). User Profile Construction Based on High-Dimensional Features Extracted by Stacking Ensemble Learning. Applied Sciences, 15(3), 1224. https://doi.org/10.3390/app15031224