
LHB-YOLOv8: An Optimized YOLOv8 Network for Complex Background Drop Stone Detection



Abstract
1. Introduction
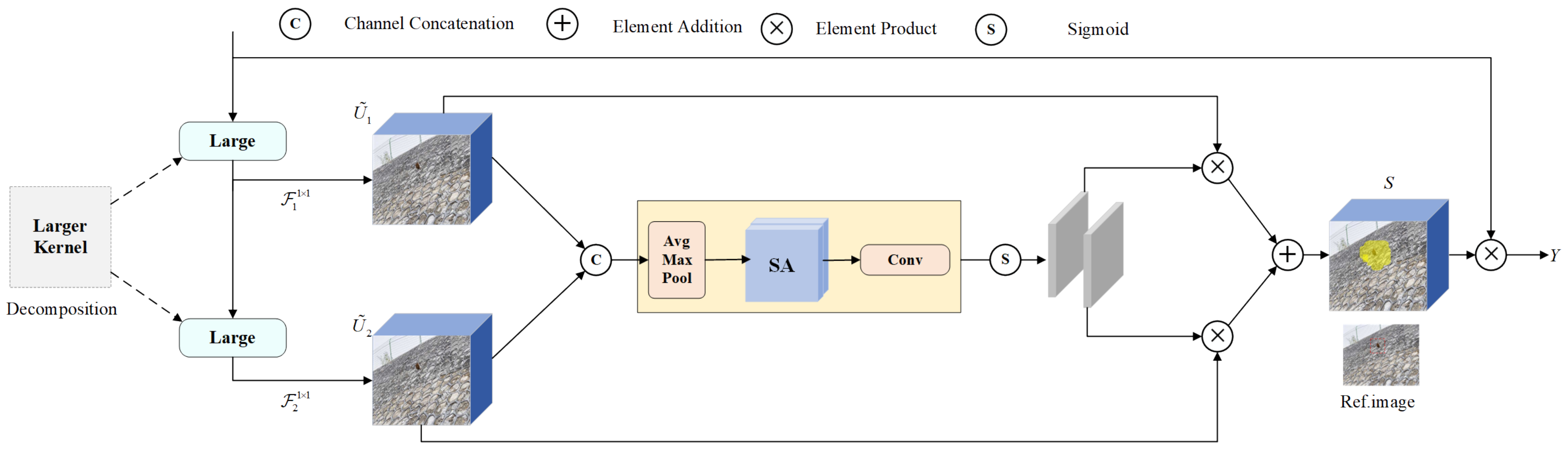
- In order to improve the model’s ability to balance the processing of global and local information and to enhance the model’s accuracy and generalization ability, the LSKAttention mechanism is chosen to be placed in the backbone part. Its ability to enhance the model’s perception of global features is enhanced by using a large convolutional kernel to capture a larger range of contextual information.
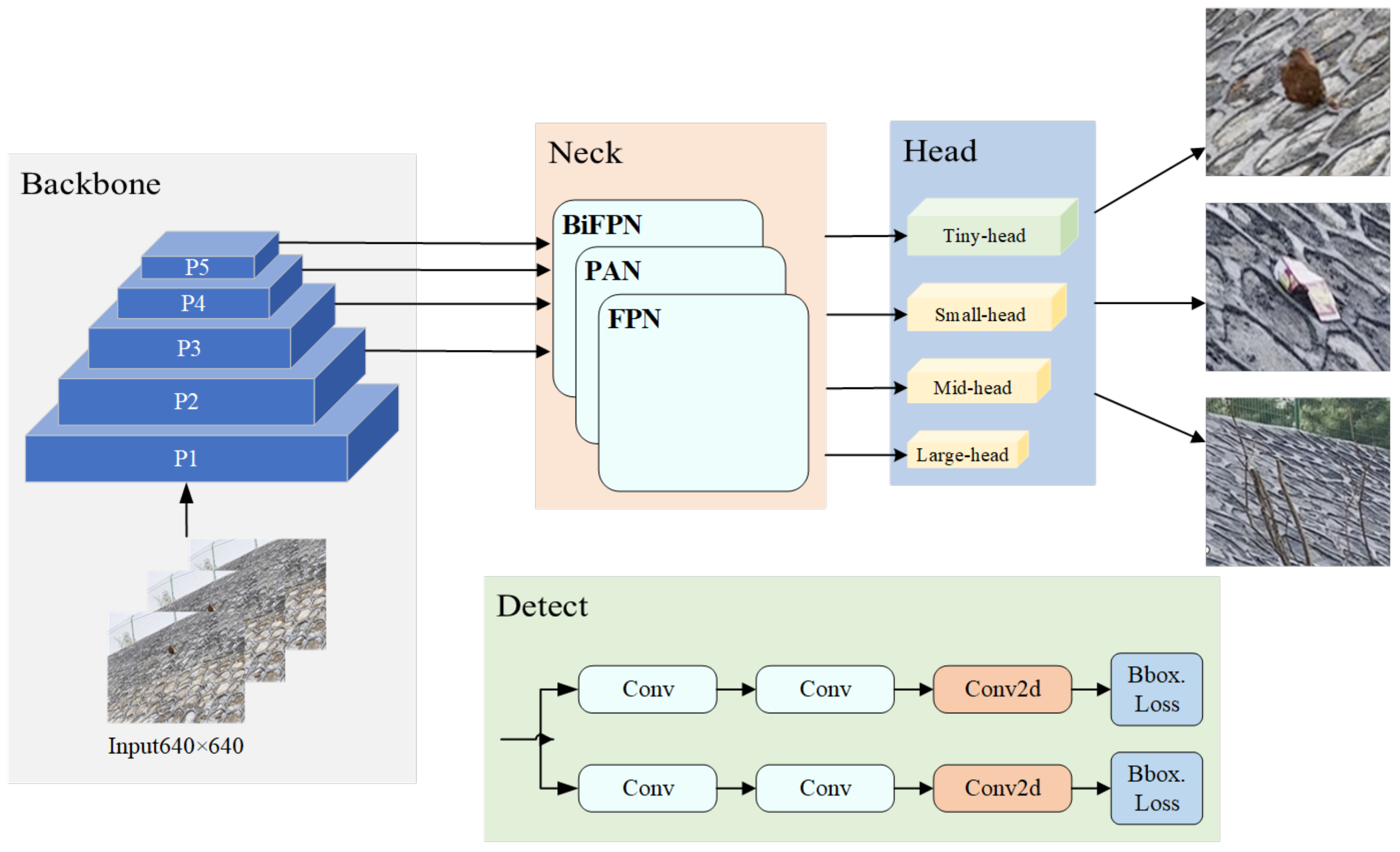
- We add a small-target detection head to the head, improving the capture of smaller rocks. Especially for cases of dense targets and mutual occlusion in complex scenes, it improves the accuracy and inference speed of the model and, thus, performs better in real-time applications.
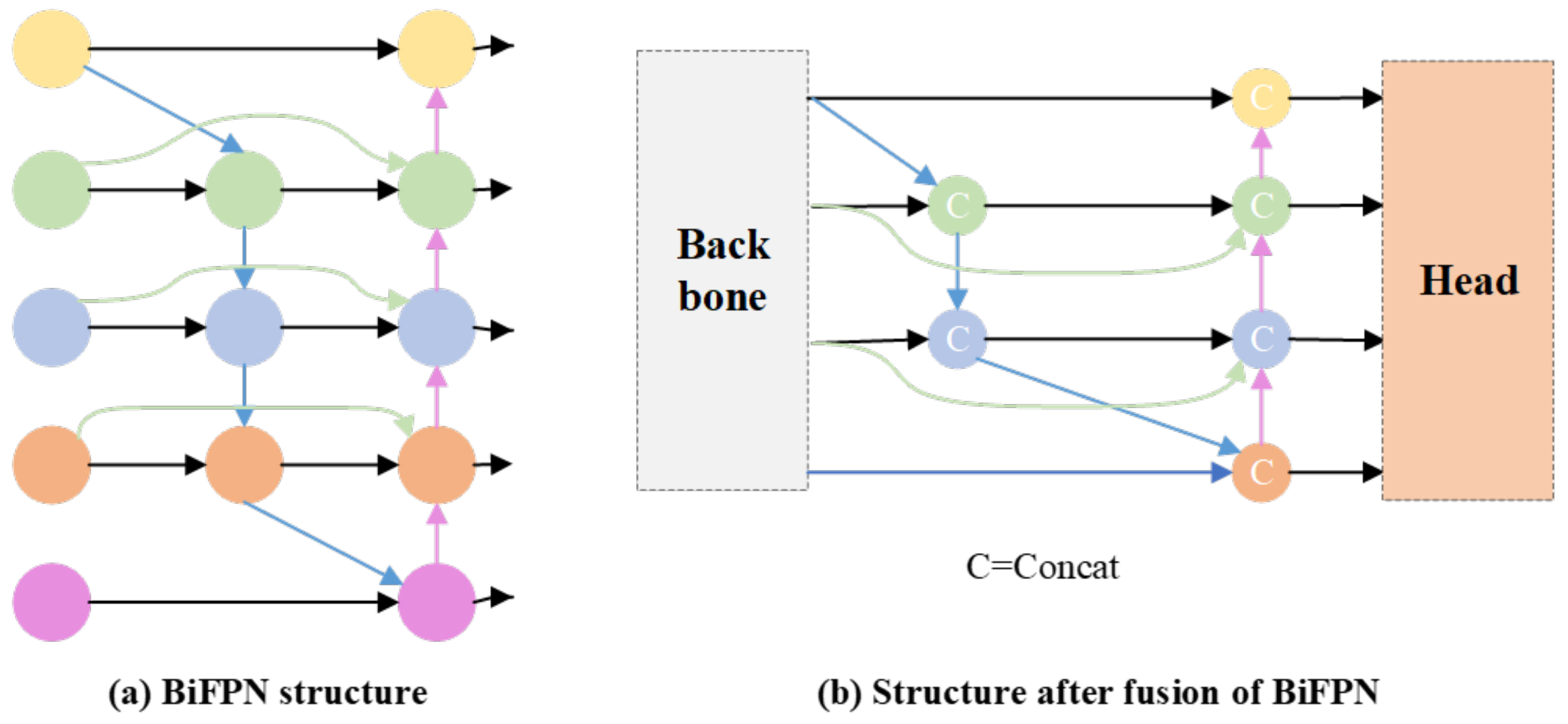
- In order to reduce the demand for computational resources, the feature pyramid is optimized to better capture multi-scale information and effectively improve model performance by reducing the number of model parameters and computational complexity.
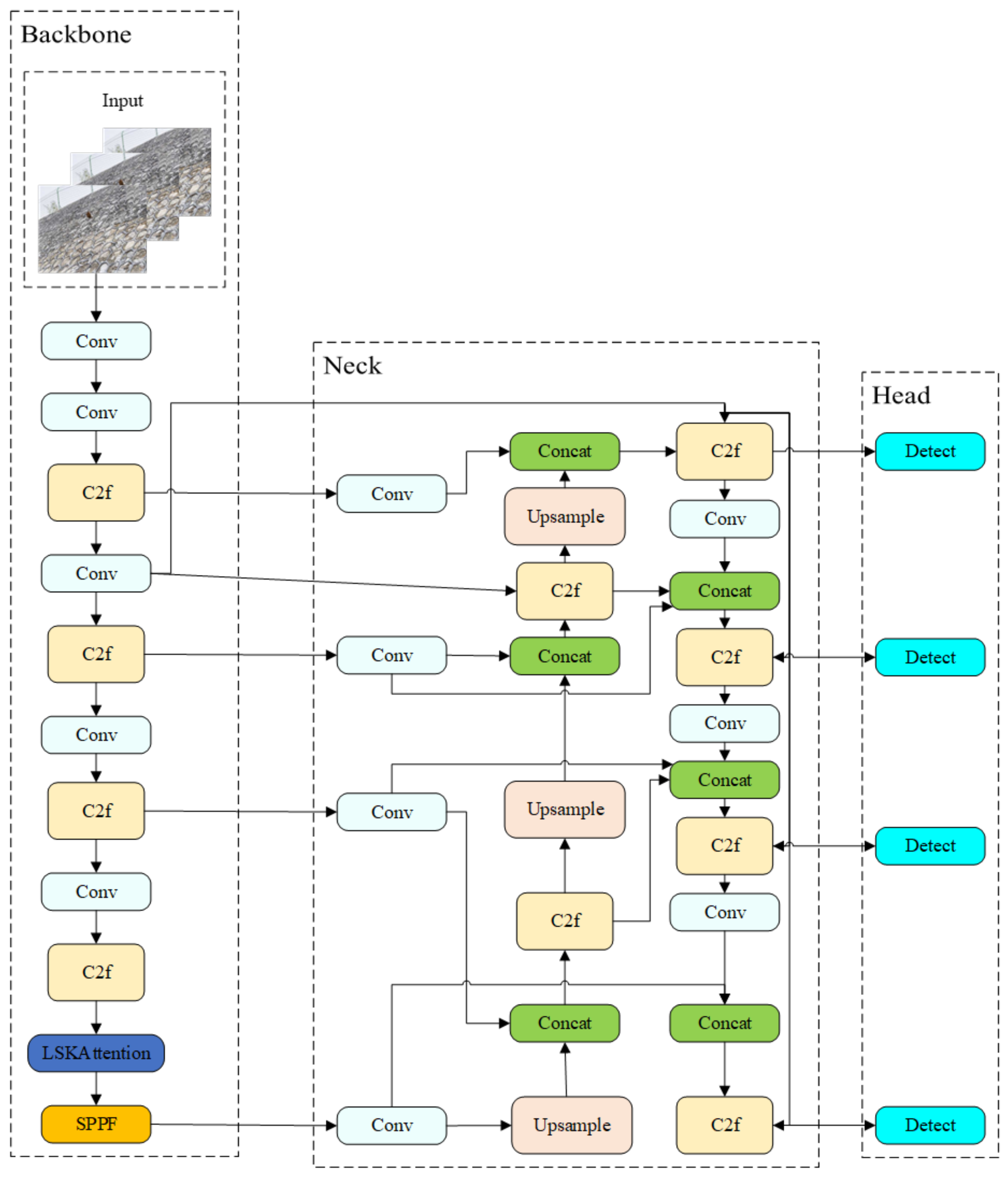
2. Methodology
2.1. Dynamic Large Convolutional Kernel Spatial Attention Mechanisms
2.2. Enhanced Detection Heads
2.3. Bidirectional Characteristic Pyramid
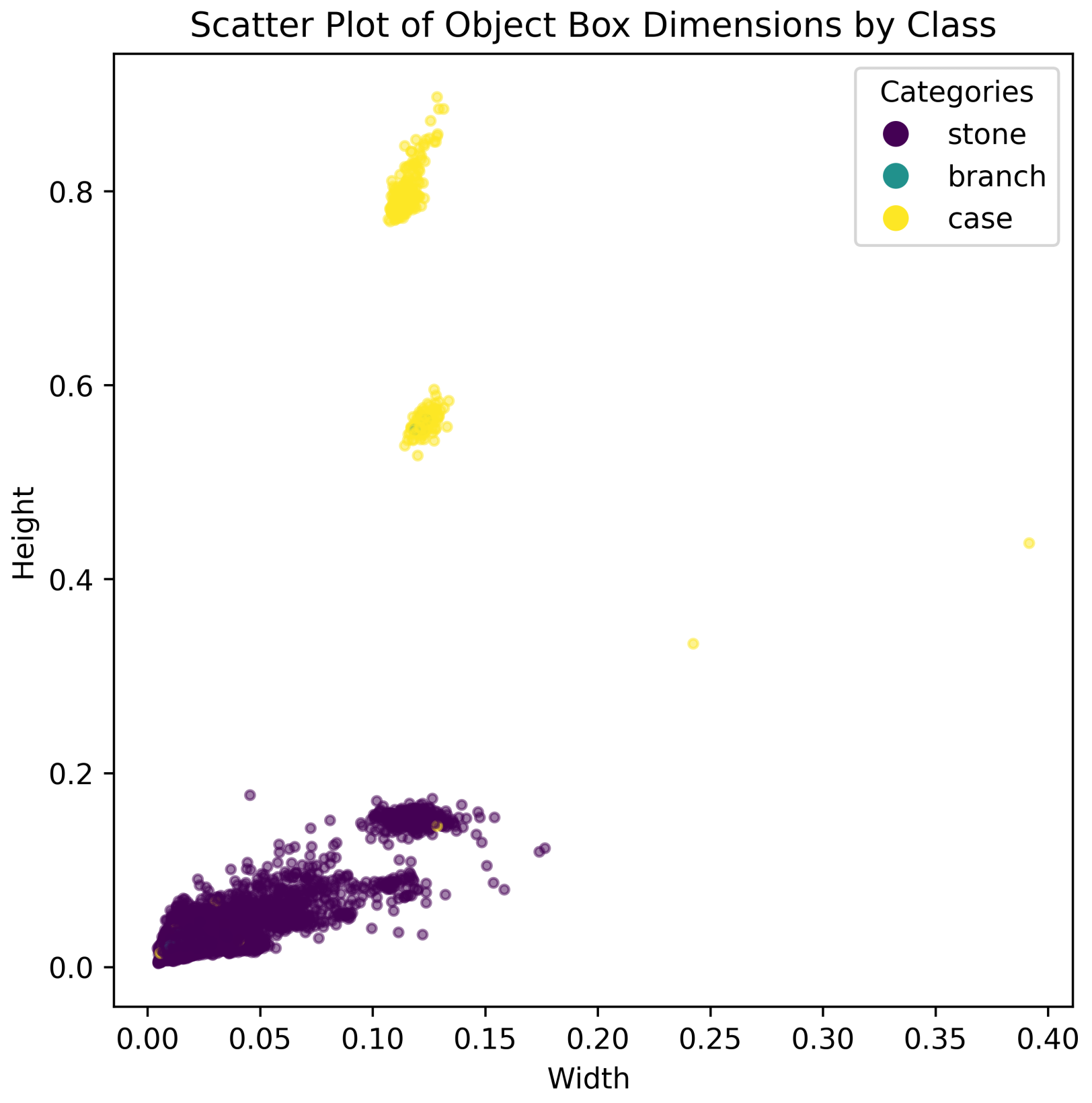
3. Dataset Construction
4. Results and Analysis
4.1. Experimental Environment
4.2. Evaluation Indicators
4.3. Comparison of the Effects of Different Attention Mechanisms
4.4. Ablation Experiments
4.5. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.W.; Chiu, C.F.; Chen, L.H.; Ho, C.C. Real-time dynamic intelligent image recognition and tracking system for rockfall disasters. J. Imaging 2024, 10, 78. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yang, Q.; Gu, X. Assessment of pavement structural conditions and remaining life combining accelerated pavement testing and ground-penetrating radar. Remote Sens. 2023, 15, 4620. [Google Scholar] [CrossRef]
- Jing, C.; Huang, G.; Li, X.; Zhang, Q.; Yang, H.; Zhang, K.; Liu, G. GNSS/accelerometer integrated deformation monitoring algorithm based on sensors adaptive noise modeling. Measurement 2023, 218, 113179. [Google Scholar] [CrossRef]
- Fiolleau, S.; Uhlemann, S.; Wielandt, S.; Dafflon, B. Understanding slow-moving landslide triggering processes using low-cost passive seismic and inclinometer monitoring. J. Appl. Geophys. 2023, 215, 105090. [Google Scholar] [CrossRef]
- Cirillo, D.; Zappa, M.; Tangari, A.C.; Brozzetti, F.; Ietto, F. Rockfall analysis from UAV-based photogrammetry and 3D models of a cliff area. Drones 2024, 8, 31. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef]
- Ghazali, M.; Mohamad, H.; Nasir, M.; Aizzuddin, A.; Aiman, M. Slope Monitoring of a Road Embankment by Using Distributed Optical Fibre Sensing Inclinometer. IOP Conf. Ser. Earth Environ. Sci. 2023, 1249, 012004. [Google Scholar] [CrossRef]
- Chen, M.; Cai, Z.; Zeng, Y.; Yu, Y. Multi-sensor data fusion technology for the early landslide warning system. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 11165–11172. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, C.C.; Shi, B.; Chen, Z.; Zhang, Y. Integrating distributed acoustic sensing and computer vision for real-time seismic location of landslides and rockfalls along linear infrastructure. Landslides 2024, 21, 1941–1959. [Google Scholar] [CrossRef]
- Zhao, Y. Omnial: A unified cnn framework for unsupervised anomaly localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3924–3933. [Google Scholar]
- Cai, J.; Zhang, L.; Dong, J.; Guo, J.; Wang, Y.; Liao, M. Automatic identification of active landslides over wide areas from time-series InSAR measurements using Faster RCNN. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103516. [Google Scholar] [CrossRef]
- Noël, F.; Cloutier, C.; Jaboyedoff, M.; Locat, J. Impact-detection algorithm that uses point clouds as topographic inputs for 3D rockfall simulations. Geosciences 2021, 11, 188. [Google Scholar] [CrossRef]
- Williams, J.G.; Rosser, N.J.; Hardy, R.J.; Brain, M.J. The importance of monitoring interval for rockfall magnitude-frequency estimation. J. Geophys. Res. Earth Surf. 2019, 124, 2841–2853. [Google Scholar] [CrossRef]
- Briones-Bitar, J.; Carrión-Mero, P.; Montalván-Burbano, N.; Morante-Carballo, F. Rockfall research: A bibliometric analysis and future trends. Geosciences 2020, 10, 403. [Google Scholar] [CrossRef]
- Wang, L.; Wang, S.; Xie, X.; Deng, Y.; Tian, W. An improved method for rockfall detection and tracking based on video stream. In Proceedings of the IET International Radar Conference (IRC 2023), Chongqing, China, 3–5 December 2023. [Google Scholar]
- Wang, S.; Jiao, H.; Su, X.; Yuan, Q. An Ensemble Learning Approach With Attention Mechanism for Detecting Pavement Distress and Disaster-Induced Road Damage. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13667–13681. [Google Scholar] [CrossRef]
- Shankar, K.; Akash, S.; Gokulakrishnan, K.; Gokulakrishnan, K.J. YOLOv8-Driven Integration of Advanced Detection Technologies for Enhanced Terrain Safety. In Proceedings of the 2024 5th International Conference on Mobile Computing and Sustainable Informatics (ICMCSI), Lalitpur, Nepal, 18–19 January 2024; IEEE: New York, NY, USA, 2024; pp. 344–351. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 16794–16805. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Hu, S.; Gao, F.; Zhou, X.; Dong, J.; Du, Q. Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 5504005. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Z.; Zou, Y.; Lu, M.; Chen, C.; Song, Y.; Zhang, H.; Yan, F. Channel prior convolutional attention for medical image segmentation. Comput. Biol. Med. 2024, 178, 108784. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Lv, W.; Zhao, Y.; Chang, Q.; Huang, K.; Wang, G.; Liu, Y. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv 2024, arXiv:2407.17140. [Google Scholar]
- Wang, S.; Xia, C.; Lv, F.; Shi, Y. RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision. arXiv 2024, arXiv:2409.08475. [Google Scholar]
- Mahaur, B.; Mishra, K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, H.; Zhao, Y. Yolov7-sea: Object detection of maritime uav images based on improved yolov7. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 233–238. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Parameter | Value |
|---|---|
| Operating system | Ubuntu 24.04 LTS |
| Deep learning framework | Pytorch |
| Programming language | Python3.8 |
| CPU | Intel(R) Core(TM) i9-10940X |
| GPU | RTX 2080 |
| RAM | 251 |
| Hyper-Parameterization | Value |
|---|---|
| Learning rate | 0.01 |
| Image size | 640 × 640 |
| Momentum | 0.937 |
| Optimizer | SGD |
| Batch size | 16 |
| Epochs | 300 |
| Weight decay | 0.0005 |
| Workers | 4 |
| Attention Mechanism | P (%) | R (%) | mAP@0.5 (%) | F1-Score (%) | Parameters (M) |
|---|---|---|---|---|---|
| CAFM | 90.6 | 84.2 | 87.0 | 87.0 | 2.6 |
| CBAM | 90.5 | 83.8 | 85.5 | 87.0 | 2.4 |
| CPCA | 91.0 | 84.1 | 86.3 | 87.5 | 2.4 |
| SEAttention | 91.1 | 84.0 | 87.4 | 87.0 | 2.3 |
| SimAM | 91.1 | 84.0 | 87.4 | 87.0 | 2.3 |
| Ours | 90.3 | 84.2 | 89.3 | 87.0 | 2.4 |
| LSK | BiFPN | P2 | P (%) | R (%) | mAP@0.5 (%) | F1-Score (%) | Parameters (M) |
|---|---|---|---|---|---|---|---|
| 86.0 | 82.0 | 84.5 | 86.0 | 3.0 | |||
| ✓ | 86.9 | 81.4 | 84.6 | 84.0 | 3.1 | ||
| ✓ | 88.7 | 82.6 | 84.2 | 86.0 | 2.0 | ||
| ✓ | 90.2 | 84.2 | 85.3 | 87.0 | 2.9 | ||
| ✓ | ✓ | 88.4 | 82.5 | 85.0 | 86.0 | 2.1 | |
| ✓ | ✓ | 89.4 | 84.8 | 86.9 | 87.0 | 3.0 | |
| ✓ | ✓ | 88.4 | 84.3 | 86.9 | 86.0 | 2.2 | |
| ✓ | ✓ | ✓ | 90.3 | 84.2 | 89.3 | 87.0 | 2.4 |
| Method | P (%) | R (%) | mAP@0.5 (%) | F1 Score (%) | Parameters (M) |
|---|---|---|---|---|---|
| RT-DETR2 | 71.1 | 67.7 | 61.9 | 60.0 | 3.2 |
| RT-DETR3 | 89.2 | 84.1 | 83.8 | 83.0 | 3.2 |
| YOLOv5 | 90.7 | 82.2 | 83.3 | 86.0 | 1.8 |
| YOLOv7 | 77.4 | 79.9 | 75.8 | 81.0 | 6.0 |
| YOLOv9 | 83.3 | 74.3 | 80.0 | 79.0 | 2.6 |
| YOLOv10 | 87.3 | 83.6 | 83.0 | 86.0 | 2.7 |
| Ours | 90.3 | 84.2 | 89.3 | 87.0 | 2.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, A.; Fan, H.; Xiong, Y.; Wei, L.; She, J. LHB-YOLOv8: An Optimized YOLOv8 Network for Complex Background Drop Stone Detection. Appl. Sci. 2025, 15, 737. https://doi.org/10.3390/app15020737
Yu A, Fan H, Xiong Y, Wei L, She J. LHB-YOLOv8: An Optimized YOLOv8 Network for Complex Background Drop Stone Detection. Applied Sciences. 2025; 15(2):737. https://doi.org/10.3390/app15020737
Chicago/Turabian StyleYu, Anjun, Hongrui Fan, Yonghua Xiong, Longsheng Wei, and Jinhua She. 2025. "LHB-YOLOv8: An Optimized YOLOv8 Network for Complex Background Drop Stone Detection" Applied Sciences 15, no. 2: 737. https://doi.org/10.3390/app15020737
APA StyleYu, A., Fan, H., Xiong, Y., Wei, L., & She, J. (2025). LHB-YOLOv8: An Optimized YOLOv8 Network for Complex Background Drop Stone Detection. Applied Sciences, 15(2), 737. https://doi.org/10.3390/app15020737