1. Introduction
Low-light image enhancement attracts considerable attention in optical target detection applications across diverse fields, including autonomous driving, military reconnaissance, and public safety, owing to its pivotal role in improving the accuracy and reliability of detection systems under challenging lighting conditions. However, during actual shooting in special scenarios like nighttime, severe weather conditions, or enclosed environments, high-quality images are often unobtainable due to external natural factors and the limitations of shooting equipment [
1]. The captured images frequently exhibit low contrast, blurred details, and color distortion [
2], making it difficult to distinguish between targets and backgrounds. Furthermore, target edges and texture features are weakened, and noise interference is significantly increased, severely impacting the accuracy of optical target detection. Hence, the enhancement of low-light images is indispensable for ensuring optimal performance in various applications.
The primary task of low-light image enhancement is to improve image visibility and contrast [
3,
4], while simultaneously addressing complex degradation patterns such as noise, artifacts, and color distortion introduced by brightness enhancement. Researchers have introduced a multitude of algorithms for enhancing low-light images, which can be comprehensively categorized into three distinct groups: those grounded in traditional image processing theory, those built upon physical models, and those leveraging advanced deep learning techniques. Among them, algorithms grounded in traditional image theory focus on improving image quality by adjusting image grayscale values. They primarily encompass classic traditional image enhancement techniques such as histogram equalization [
5,
6], gradient domain methods [
7], homomorphic filtering [
8], and image fusion [
9]. Histogram equalization enhances contrast through the redistribution of pixels, with main approaches including standard histogram equalization (HE) [
10], adaptive histogram equalization (AHE) [
11], and contrast-limited adaptive histogram equalization (CLAHE) [
12]. However, these methods largely ignore illumination factors, potentially leading to over-enhancement, artifacts, and unexpected local overexposure [
13]. Gradient domain image enhancement algorithms are generally limited to the enhancement of single images or images captured in the same scene [
14]. Meanwhile, homomorphic filtering algorithms enhance the high-frequency details of an image by attenuating its low-frequency components, but the cutoff frequency is not fixed and requires extensive experimentation based on specific images.
Algorithms for enhancing low-light images based on physical models process these images by simulating the imaging principles of the human visual system. They primarily encompass the following two approaches: First, algorithms based on the Retinex theory [
15], including Single-Scale Retinex (SSR) [
16,
17], Multi-Scale Retinex (MSR) [
18], and Multi-Scale Retinex with Color Restoration (MSRCR), are utilized [
19]. These algorithms leverage human visual color constancy, simulating the human eye’s perception mechanism of object colors, to separate color images into illumination and reflection components, thereby effectively enhancing the images. Such algorithms perform well in terms of illumination invariance, but if noise and other factors are not carefully considered, they may lead to unrealistic images or localized color distortions. To address this issue, Kimmel et al. [
20] transformed the approximate illumination problem into a quadratic programming problem to find an optimal solution, which improved the enhancement effect of low-light images to a certain extent. Wang et al. [
21] refined the Retinex algorithm by incorporating nonlocal bilateral filtering into the luminance component within the HIS color space. By subtracting the resultant image, via post-Laplacian filtering, from the original image, they achieved commendable enhancement results. However, this approach inadvertently introduced noise and resulted in some degree of edge blurring. Ji et al. [
22] used guided filtering to estimate the illumination of the image’s luminance component and used combined gamma correction [
23] to adjust the incident and reflection components. This reserved the image’s colors to a certain extent but still resulted in an overall darker image. Second, the atmospheric scattering model is utilized to defog inverted low-light images. This method leverages the similarity between inverted low-light images and hazy images, integrating prior knowledge, such as the dark channel prior [
24], to effectively eliminate haze from the image and consequently enhance the quality of the low-light image. Dong et al. [
25] introduced an innovative algorithm, grounded in the atmospheric scattering model, to directly apply channel-wise prior dehazing techniques after inverting the low-light images. However, this algorithm introduces excessive noise, making the overall image appear unnatural. Li et al. [
26] used Block Matching and 3D filtering (BM3D) [
27] for denoising in order to separate the base layer and enhancement layer of the image, adjusting each layer separately to achieve better results. These methods have achieved certain effects in low-light image enhancement, but they lack a physical basis and may introduce excessive noise, resulting in a certain degree of blurring and making the overall image appear unnatural.
In recent years, with the surge of interest in deep learning, several deep learning models have emerged that are tailored for low-light image enhancement. Existing deep learning models can be broadly categorized into supervised and unsupervised types. Supervised learning models are designed to automatically discern and learn the intricate mapping relationship between low-light and normal-light images. By deeply analyzing and exploring the inherent characteristics of low-light images, these models are capable of achieving high-quality image enhancement and restoration. Hu et al. [
28] proposed the Pyramid Enhancement Network (PE-Net), utilizing a Detail Processing Module (DPM) to enhance image details and validate the algorithm’s utility in nighttime object detection tasks in conjunction with YOLOv3. Liu et al. [
29] introduced a Differentiable Image Processing (DIP) module to improve the object detection performance under adverse conditions, enhancing images through a weakly supervised approach for object detection. This enabled adaptive image processing under both normal and unfavorable weather conditions, albeit with limited image enhancement effects. Kalwar et al. [
30] introduced a pioneering Gated Differentiable Image Processing (GDIP) mechanism, which facilitated the concurrent execution of multiple DIP operations, thereby enhancing the efficiency and flexibility of image processing tasks. Inspired by the Retinex theory, Wei et al. [
31] presented RetinexNet, which achieved remarkable results under low-light conditions but exhibited limitations in processing color information and edge details, resulting in blurred edge areas and distorted edge details during the smooth denoising of the reflectance image. To address color deviation issues, Cai et al. [
32] introduced Retinexformer, composed of illumination estimation and image restoration, using an illumination-guided Transformer in order to suppress noise and color distortion. However, this algorithm failed to balance brightness adjustment between bright and dark areas, easily causing overexposure in the originally brighter regions of the image. Zhang et al. [
33] established the KinD++ network, which not only enhanced the brightness of dark areas but also effectively removed artifacts by separately adjusting illumination and removing degradation in the reflectance map.
Unsupervised deep learning models, which do not require labeled data, exhibit strong generalization capabilities. However, due to the lack of direct supervision, their enhancement effects may be less stable. Drawing upon the principles of the Retinex theory, Zhang et al. [
34] devised a novel Generative Adversarial Network (GAN) approach that did not necessitate the use of paired datasets. This method achieves remarkable low-light image enhancement through the judicious utilization of controlled discriminator architectures, self-regularized perceptual fusion techniques, and sophisticated self-attention mechanisms. Yet, due to the neglect of physical principles, artifact phenomena can easily arise. Subsequently, Shi et al. [
35] presented the RetinexGAN network, a sophisticated framework that is meticulously divided into two distinct components for image decomposition and enhancement. However, it is noteworthy that an overemphasis on distribution during the enhancement process may inadvertently result in unnatural-looking enhanced images. Jiang et al. [
36] proposed an efficient unsupervised generative adversarial network (EnlightGAN), which utilizes an unsupervised generative adversarial network combined with an attention-guided U-Net generator and a global–local discriminator to enhance low-light images, demonstrating good domain adaptability. Liang et al. [
37] introduced an innovative unsupervised backlit image enhancement technique, CLIP-LIT. This method leverages the robust capabilities of the CLIP model and achieves the effective enhancement of backlit images through a prompt learning framework and iterative fine-tuning strategies. However, it is worth noting that this method relies on a pre-trained CLIP model and may fail in some extreme cases, such as when information is missing in overexposed or underexposed areas. Yang et al. [
38] pioneered the utilization of the controllable fitting capability of neural representations, proposing an implicit neural representation method named NeRCo for low-light image enhancement, which demonstrates exceptional performance in restoring authentic tones and contrast. Chobola et al. [
39] presented an algorithm that reconstructs images in the HSV space using implicit neural functions and embedded guided filtering, effectively improving image quality and scene adaptability, although overexposure can still occur in highlight areas. Guo et al. [
40] converted low-light image enhancement into a deep curve estimation problem, proposing a zero-reference deep curve estimation (Zero-DCE) network. By setting a series of reference-free loss functions, the network achieves end-to-end training without any reference images. Although brightness is significantly improved, contrast remains low, and processing directly on the RGB channels of the image can easily lead to color distortion. Li et al. [
41] improved upon this by proposing Zero-DCE++, which uses downsampling to input images and learn mapping parameters, followed by upsampling and final image processing with the learned parameters to enhance low-light images. This results in good performances in color preservation and overall smoothness, but may cause overexposure in originally well-exposed areas. Compared with traditional algorithms, deep learning algorithms have more stringent data requirements, and low-light images typically suffer from poor quality, with minimal differences between targets and backgrounds. This leads to the ineffective enhancement of dark areas by deep learning algorithms and insufficient robustness.
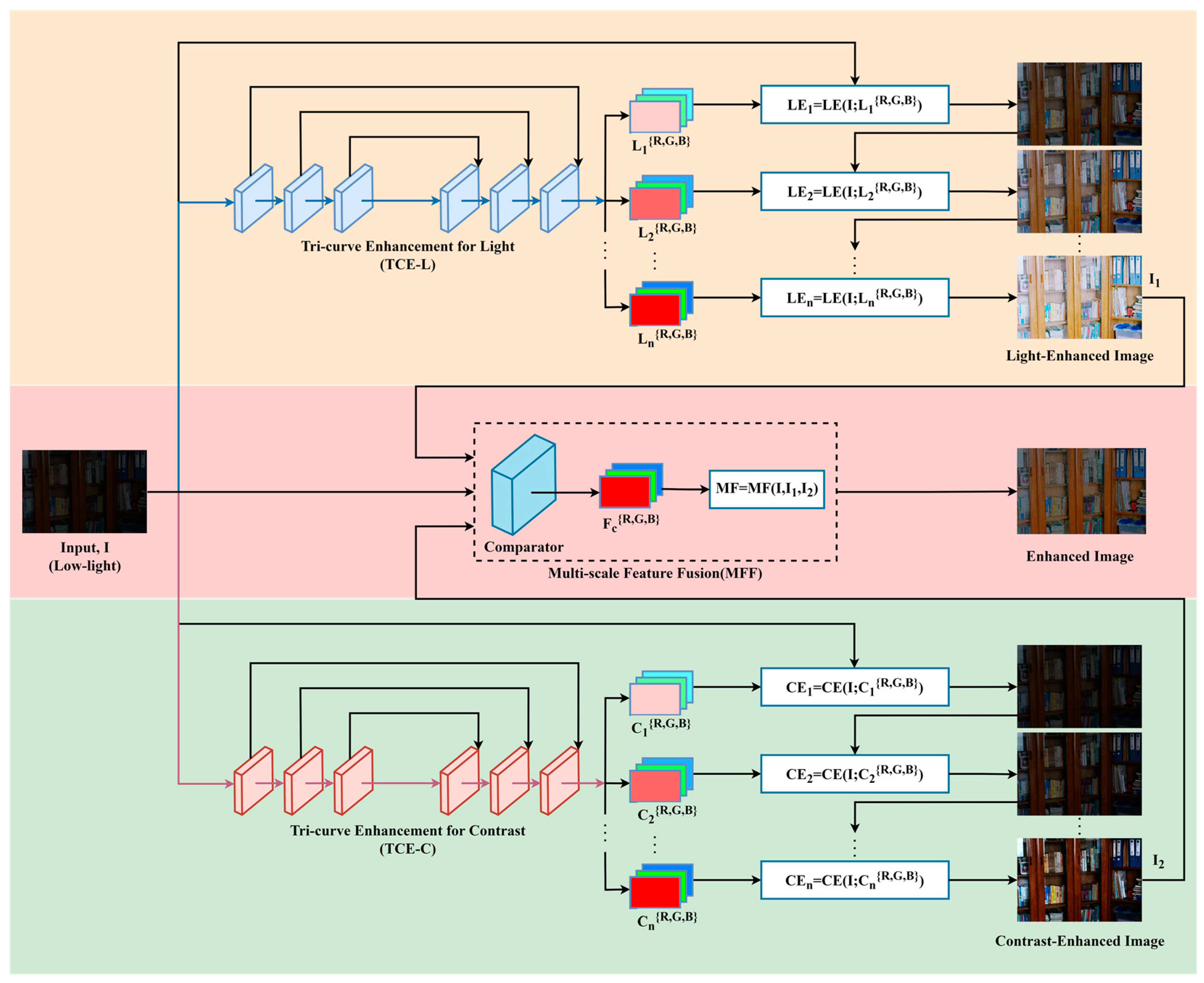
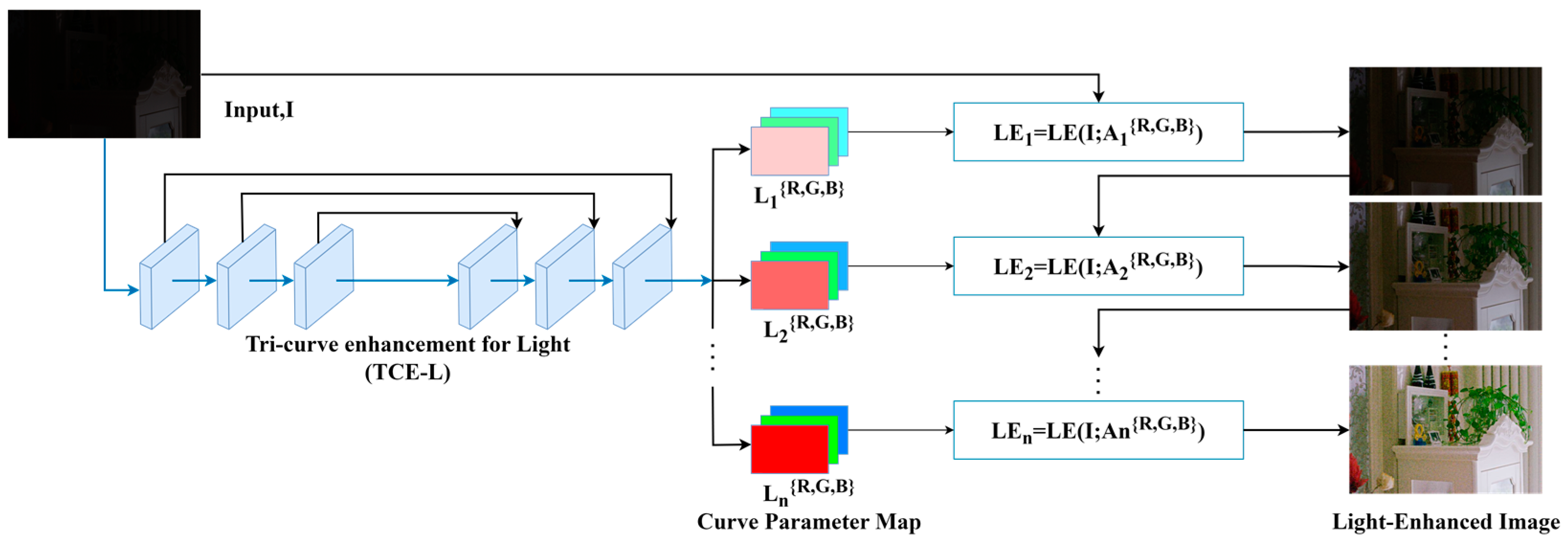
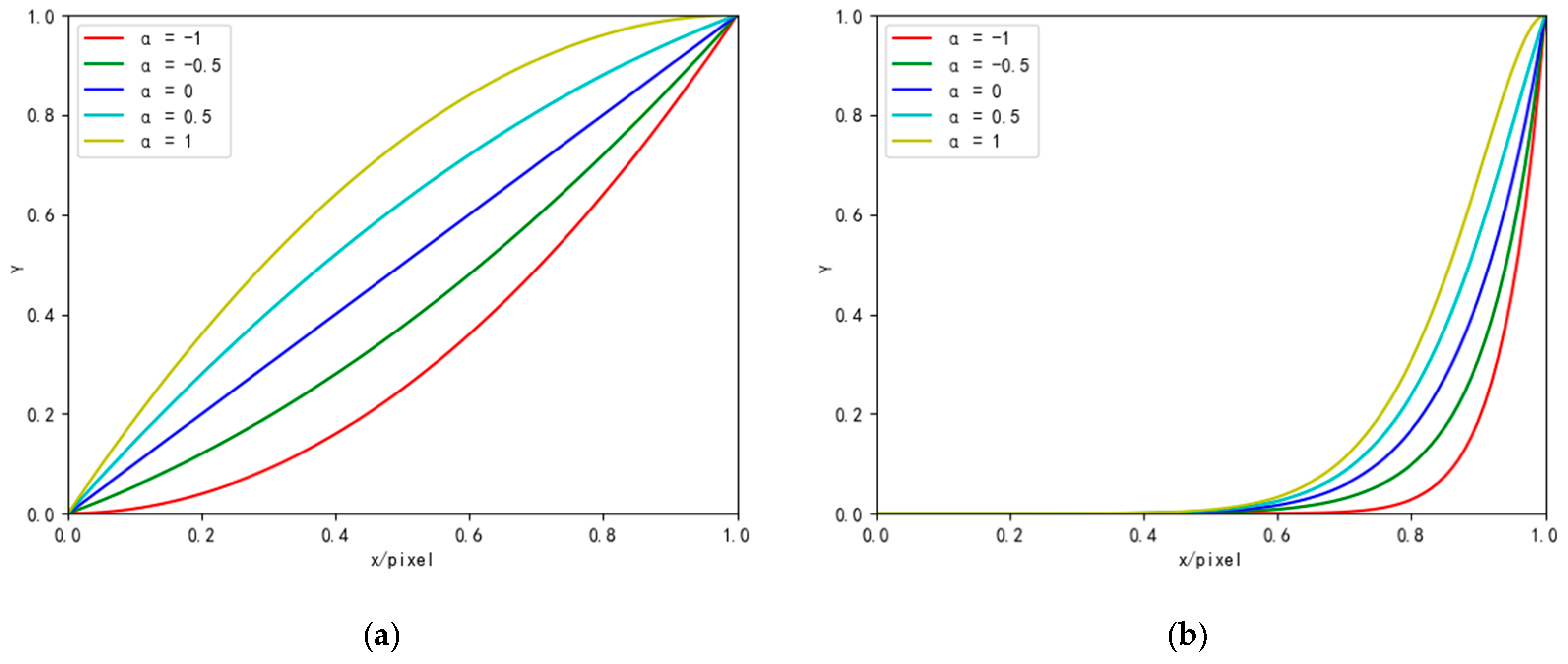
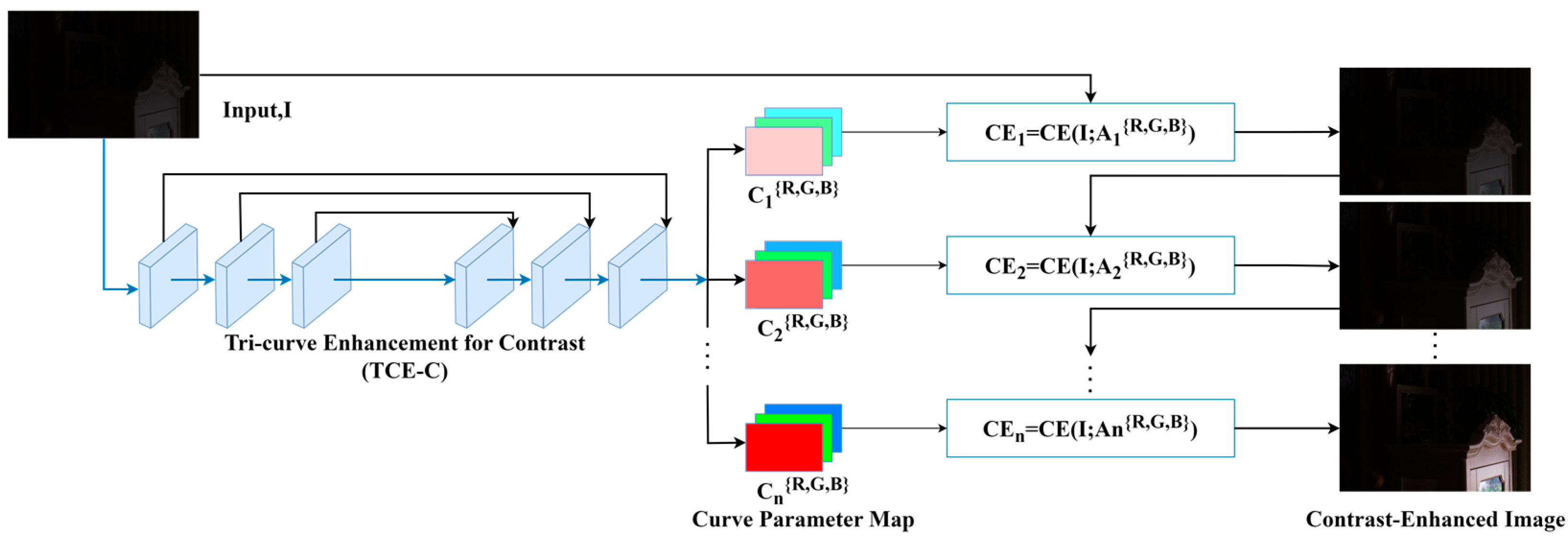
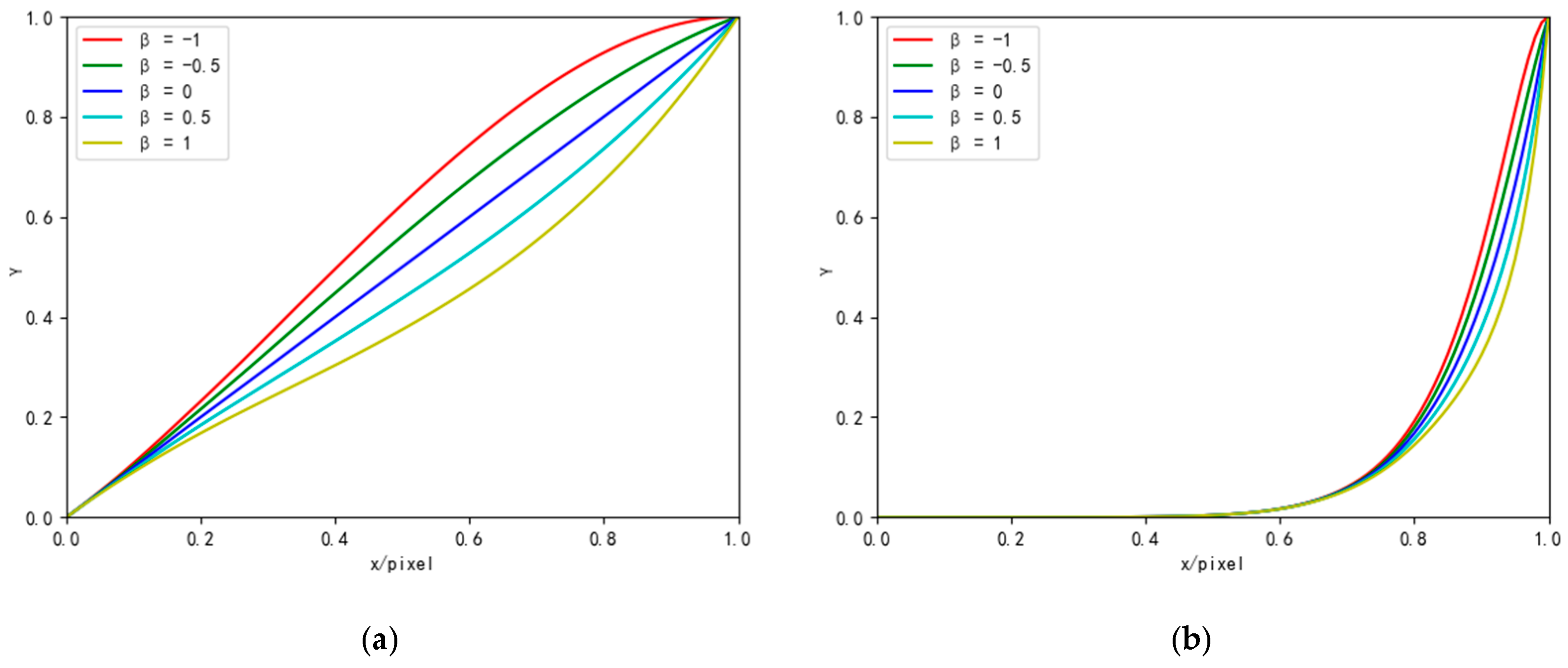
To address the challenges, we introduce the zero-reference triple-curve enhancement algorithm (Zero-TCE), a novel approach specifically designed to enhance low-light images. It possesses the capability to handle a diverse array of lighting conditions, encompassing backlight scenarios, uneven illumination, and insufficient lighting. By framing the task of low-light image enhancement as a unique curve estimation problem tailored to each individual image, Zero-TCE accepts a low-light image as an input and produces three high-order curves as the output, thereby facilitating significant improvements in image quality. These curves are then utilized to adjust the dynamic range of the input image at the pixel level to obtain an enhanced image. These three curves are meticulously designed to boost image brightness while avoiding overexposure, preserving the highlight regions of the original image, and enhancing image contrast without excessive enhancement, making the image appear more realistic. More importantly, the proposed network is lightweight, enabling more robust and precise dynamic range adjustment.
Firstly, we design two modules based on DCE-Net, the TCE-L and TCE-C modules, which output two curves that are specifically for enhancing image brightness and contrast, respectively. Additionally, we develop a multi-scale feature fusion (MFF) module that integrates multi-scale features from both the original and preliminarily enhanced images, taking into account the brightness distribution characteristics of low-light images, to obtain the optimal enhanced image. The key advantage of the proposed algorithm lies in its zero-reference nature, meaning no paired or unpaired data are required during training. This is achieved by adopting a set of non-reference loss functions, including spatial consistency loss, exposure control loss, color constancy loss, and illumination smoothness loss, to ensure image quality and avoid issues such as artifacts and color distortion. Furthermore, we incorporate the structural similarity index measure loss to preserve accurate image textures. These loss functions are designed to capture high-level features of images, rather than just pixel-level differences, thereby helping to improve the model’s ability to adapt to new lighting conditions. The contributions of this study are as follows:
We propose Zero-TCE, a zero-reference dual-path network for low-light image enhancement based on multi-scale deep curve estimation. This network is independent of paired and unpaired training data, thereby mitigating the risk of overfitting.
We design three image-specific curves that collectively enable brightness enhancement, contrast improvement, and multi-scale feature fusion for low-light images.
We indirectly assess enhancement quality through task-specific non-reference loss functions, which preserve accurate image textures, enhance dark details, and avoid issues such as artifacts and color distortions.
The structure of the remainder of this paper is outlined as follows:
Section 2 delves into related work, providing an overview of the current approach in the field.
Section 3 presents a comprehensive description of the proposed Zero-TCE method, elucidating its intricacies in detail. In
Section 4, we present and discuss the experimental results obtained through the application of Zero-TCE. Lastly,
Section 5 concludes the paper by summarizing our findings and outlining potential directions for future research.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}