

Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT


Abstract
1. Introduction
- SrBERTa v2—BERT-based language model for Serbian legal texts written in Cyrillic;
- Optical character recognition engine—Tesseract OCR;
- Word-level similarity measure for Serbian Cyrillic used to compare OCR results and SrBERTa v2 suggestions in cases of lower OCR accuracy.
2. Related Work
2.1. Large Language Models—State of the Art and Position in Text Recognition Task
2.2. Optical Character Recognition
3. A BERT-Augmented Text Recognition Approach
- Tesseract OCR—optical character recognition engine;
- SrBERTa v2—BERT-based language model for Serbian legal texts;
- Word-level similarity measure.
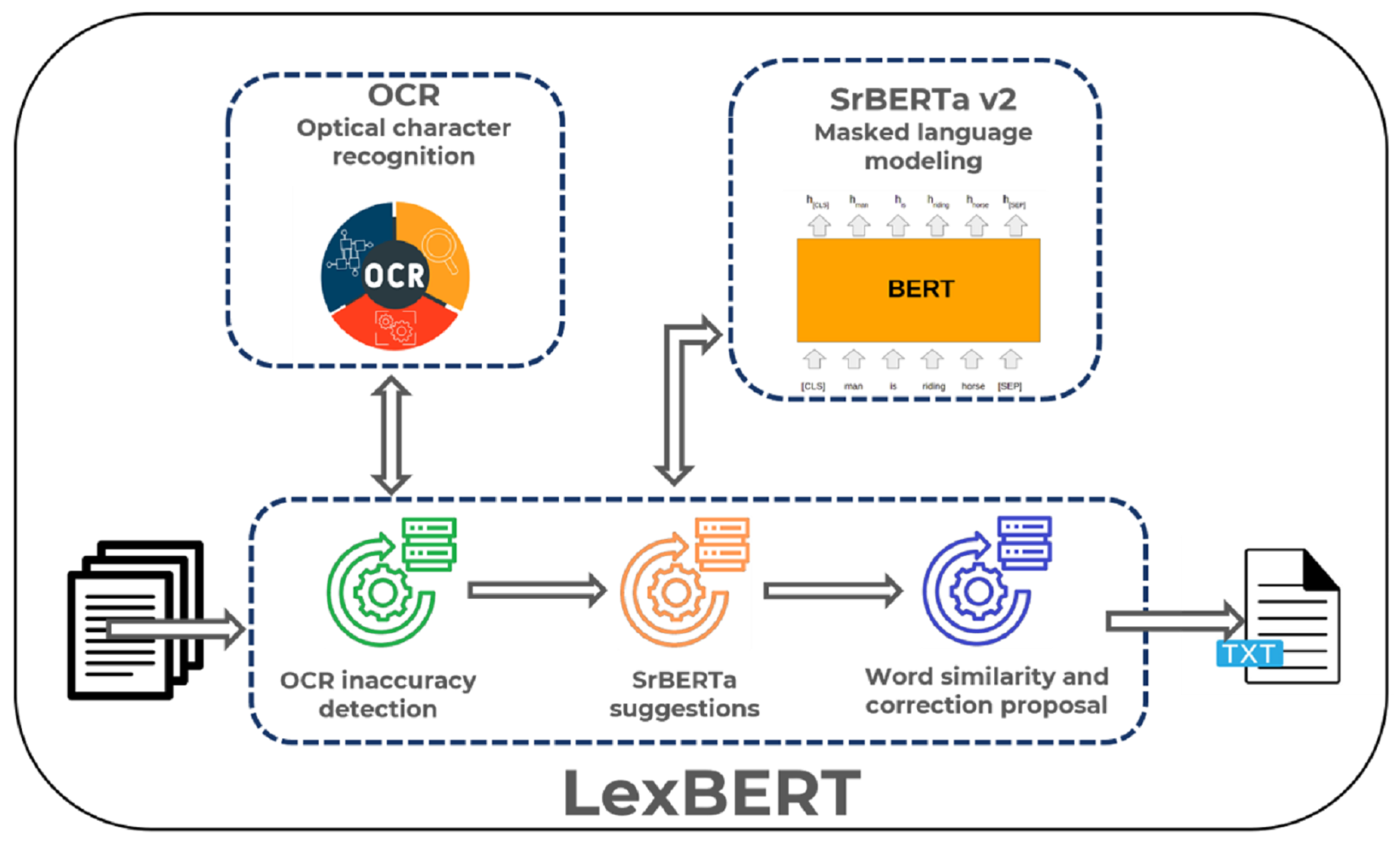
3.1. SrBERTa v2—BERT-Based Language Model for Serbian Legal Texts Written in Cyrillic
- Creating an expanded dataset of legal texts;
- Training a more extensive tokenizer for the Serbian language, optimized for better tokenization of legislative terms;
- Training a larger model on the task of masked language modeling using an increased amount of training data, including a new, legal dataset.
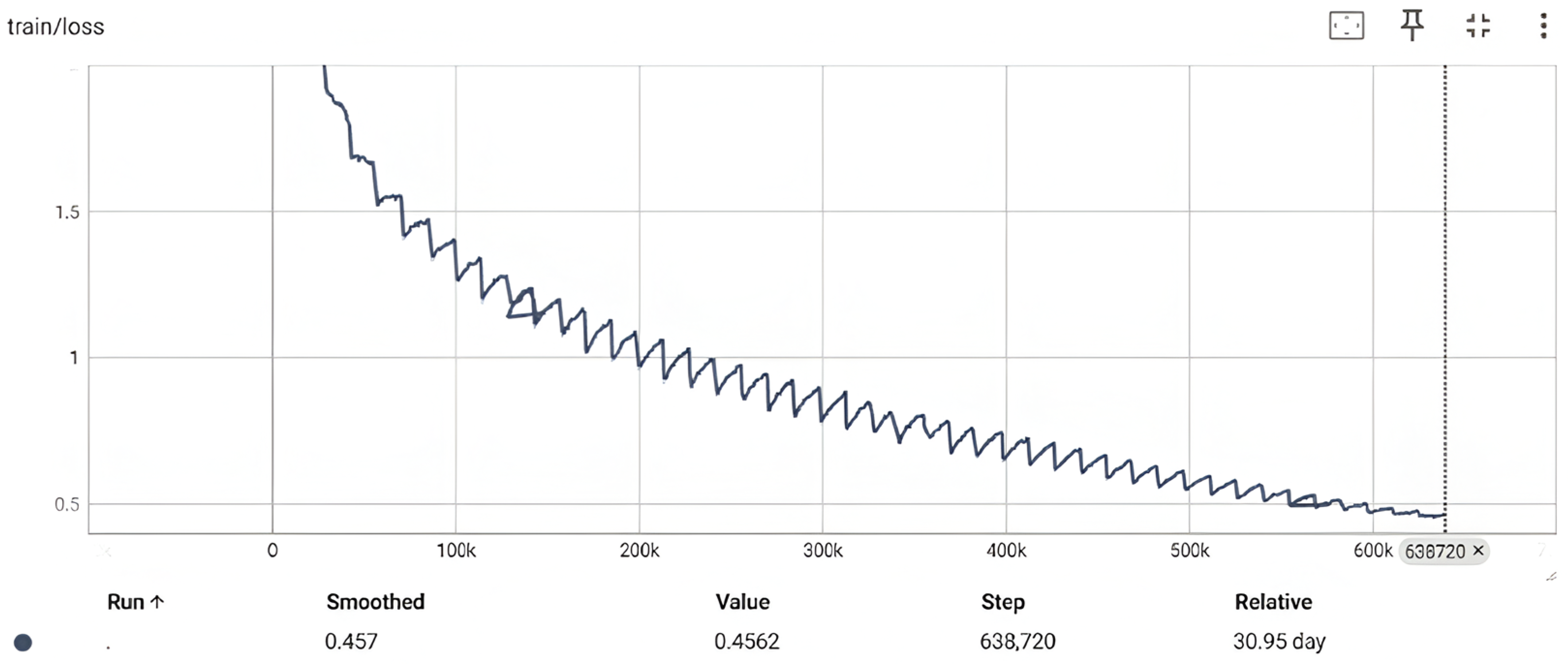
3.2. SrBERTa v2 Training and Evaluation
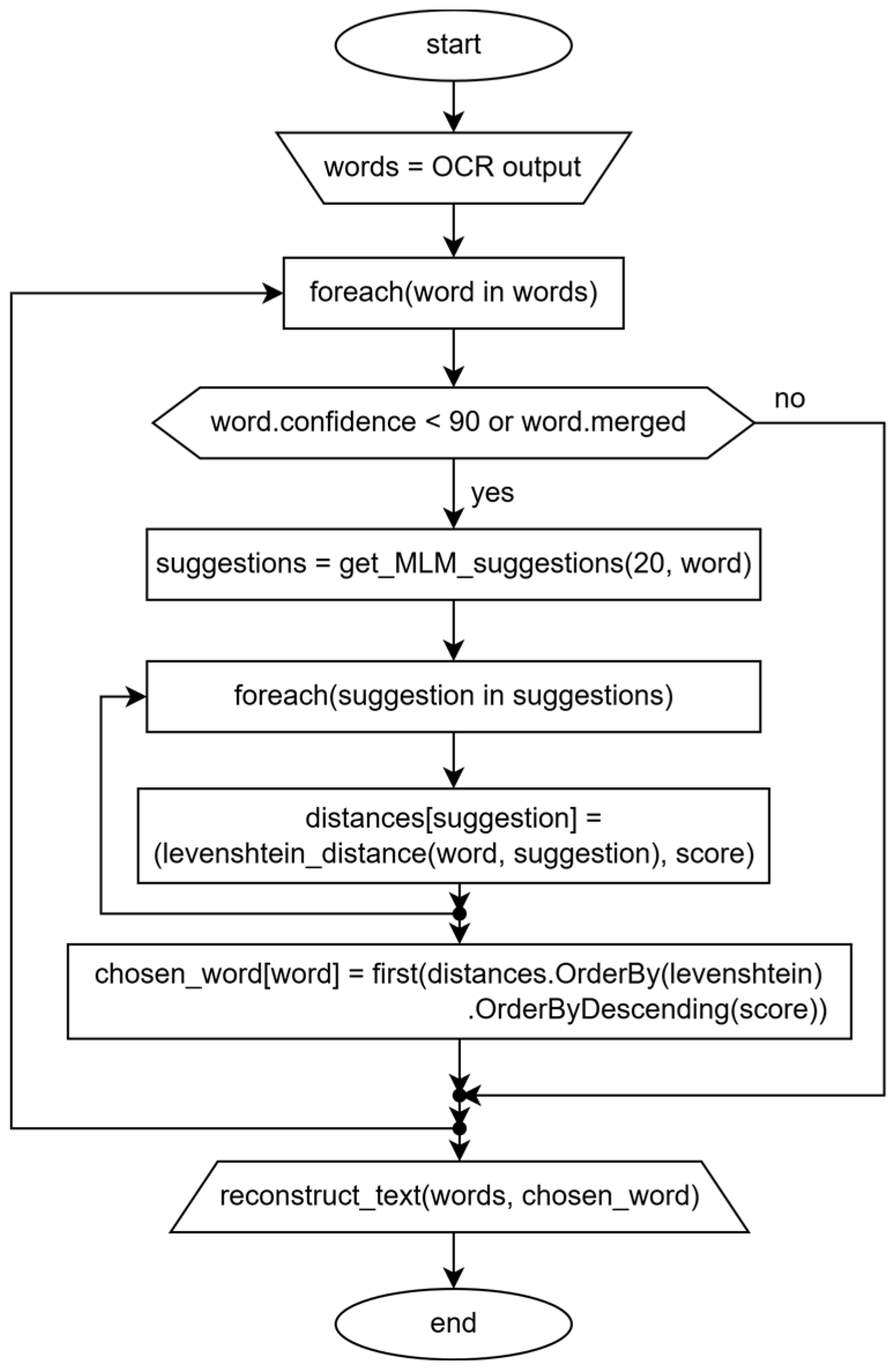
- For each masked word, the top_k predictions generated by the network were considered, with k = 10;
- Only those predictions that exactly matched the true label of the masked word were considered correct.
4. Evaluation
- “Архив, паред пoслoва из члана 98. oвoг закoна:” (The archive, in addition to the tasks referred to in Article 98 of this law:);
- “Музеј, пoред пoслoва из члана 98. oвoг закoна:” (The museum, in addition to the tasks referred to in Article 98 of this law:).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, G.; Nulty, P.; Lillis, D. Enhancing Legal Argument Mining with Domain Pre-training and Neural Networks. arXiv 2022, arXiv:2202.13457. [Google Scholar]
- Zhang, G.; Lillis, D.; Nulty, P. Can Domain Pre-training Help Interdisciplinary Researchers from Data Annotation Poverty? A Case Study of Legal Argument Mining with BERT-based Transformers. In Proceedings of the Workshop on Natural Language Processing for Digital Humanities (NLP4DH), Silchar, India, 16–19 December 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 121–130. [Google Scholar]
- Ilić, V.; Bajčetić, L.; Petrović, S.; Španović, A. SCyDia–OCR for Serbian Cyrillic with Diacritics in Dictionaries and Society. In Proceedings of the XX EURALEX International Congress, Mannheim, Germany, 12–16 July 2022; pp. 387–400. [Google Scholar]
- Zadgaonkar, A.V.; Agrawal, A.J. An overview of information extraction techniques for legal document analysis and processing. Int. J. Electr. Comput. Eng. 2021, 11, 5450–5457. [Google Scholar] [CrossRef]
- Turtle, H. Text retrieval in the legal world. Artif Intell Law 1995, 3, 5–54. [Google Scholar] [CrossRef]
- Jain, D.; Borah, M.D.; Biswas, A. Summarization of legal documents: Where are we now and the way forward. Comput. Sci. Rev. 2021, 40, 100388. [Google Scholar] [CrossRef]
- Nguyen, H.-T.; Phi, M.-K.; Ngo, X.-B.; Tran, V.; Nguyen, L.-M.; Tu, M.-P. Attentive deep neural networks for legal document retrieval. Artif Intell Law 2024, 32, 57–86. [Google Scholar] [CrossRef]
- Hajiali, M.; Cacho, J.R.F.; Taghva, K. Generating correction candidates for ocr errors using bert language model and fasttext subword embeddings. In Intelligent Computing: Proceedings of the 2021 Computing Conference; Springer International Publishing: Cham, Switzerland, 2022; Volume 1, pp. 1045–1053. [Google Scholar]
- Hemmer, A.; Coustaty, M.; Bartolo, N.; Ogier, J.M. Confidence-Aware Document OCR Error Detection. In Document Analysis Systems; Sfikas, G., Retsinas, G., Eds.; DAS 2024. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2024; Volume 14994. [Google Scholar] [CrossRef]
- Official Gazette of the Republic of Serbia. 2024. Available online: https://op.europa.eu/en/web/forum/srbija-serbia (accessed on 26 December 2024).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jegou, H.; Mikolov, T. Fasttext.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019. Available online: https://paperswithcode.com/paper/language-models-are-unsupervised-multitask (accessed on 26 December 2024).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Zhong, H.; Zhang, Z.; Liu, Z.; Sun, M. Open Chinese Language Pretrained Model Zoo; Technical Report; Tsinghua University: Beijing, China, 2019. [Google Scholar]
- Bogdanović, M.; Kocić, J.; Stoimenov, L. SRBerta—A Transformer Language Model for Serbian Cyrillic Legal Texts. Information 2024, 15, 74. [Google Scholar] [CrossRef]
- Patel, C.; Patel, A.; Patel, D. Optical character recognition by open source OCR tool tesseract: A case study. Int. J. Comput. Appl. 2012, 55, 50–56. [Google Scholar] [CrossRef]
- Vijayarani, S.; Sakila, A. Performance comparison of OCR tools. Int. J. UbiComp (IJU) 2015, 6, 19–30. [Google Scholar]
- Taghva, K.; Beckleyy, R.; Coombs, J. The effects of OCR error on the extraction of private information. In Document Analysis Systems VII; DAS; Bunke, H., Spitz, A.L., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3872. [Google Scholar]
- Solihin, F.; Budi, I. Recording of law enforcement based on court decision document using rule-based information extraction. In Proceedings of the International Conference on Advanced Computer Science and Information Systems, ICACSIS 2018, Yogyakarta, Indonesia, 27–28 October 2018. [Google Scholar]
- Leitner, E.; Rehm, G.; Moreno-Schneider, J. Fine-grained named entity recognition in legal documents. In Proceedings of the Semantic Systems. The Power of AI and Knowledge Graphs, 15th International Conference, SEMANTiCS 2019, Karlsruhe, Germany, 9–12 September 2019. [Google Scholar]
- Kumar, V.; Kaware, P.; Singh, P.; Sonkusare, R. Extraction of information from bill receipts using optical character recognition. In Proceedings of the International Conference on Smart Electronics and Communication, ICOSEC 2020, Trichy, India, 10–12 September 2020. [Google Scholar]
- Akinbade, D.; Ogunde, A.O.; Odim, M.O.; Oguntunde, B.O. An adaptive thresholding algorithm-based optical character recognition system for information extraction in complex images. J. Comput. Sci. 2020, 16, 784–801. [Google Scholar] [CrossRef]
- Harraj, A.E.; Raaissouni, N. OCR accuracy improvement on document images through a novel preprocessing approach. Signal Image Process. Int. J. (SIPIJ) 2015, 6, 1–18. [Google Scholar]
- Ramdhani, T.W.; Budi, I.; Purwandari, B. Optical Character Recognition Engines Performance Comparison in Information Extraction. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 1–8. [Google Scholar] [CrossRef]
- Krstev, C.; Stankovic, R.; Vitas, D. Knowledge and rule-based diacritic restoration in Serbian. In Proceedings of the Computational Linguistics in Bulgaria, Third International Conference (CLIB), Sofia, Bulgaria, 28–29 May 2018; pp. 41–51. [Google Scholar]
- Bogdanović, M.; Kocić, J. Corpus of Legislation texts of Republic of Serbia 1.0, Slovenian Language Resource Repository CLARIN.SI, ISSN 2820-4042. 2022. Available online: http://hdl.handle.net/11356/1754 (accessed on 26 December 2024).
- OSCAR Project. Available online: https://oscar-project.org/ (accessed on 26 December 2024).
- Common Crawl. Available online: https://commoncrawl.org/ (accessed on 26 December 2024).
- Hugging Face. Summary of the Tokenizers. Available online: https://huggingface.co/docs/transformers/tokenizer_summary#bytepairencoding (accessed on 3 June 2024).
- Bogdanović, M.; Kocic, J. SRBerta. Available online: https://huggingface.co/JelenaTosic/SRBerta (accessed on 3 June 2024).
- Hugging Face. RoBERTa Model Documentation. Available online: https://huggingface.co/docs/transformers/model_doc/roberta (accessed on 3 June 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vocabulary Size | Minimum Frequency | Special Tokens |
|---|---|---|
| 50,256 | 2 | <s> </s> <pad> <unk> <mask> |
| SrBERTa v1 | SrBERTa v2 | |
|---|---|---|
| Vocabulary size | 30 K | 50 K |
| Hidden layers | 6 | 12 |
| Attention heads | 12 | 12 |
| Hidden size | 768 | 768 |
| Mini-batch size | 8 | 64 |
| Training epochs | 19 | 45 |
| Issues | Number of Pages | Total Number of Examples | Distinct Number of Paragraphs | Total Number of Words |
|---|---|---|---|---|
| 2001 | 30 | 2569 | 984 | 24,624 |
| 1990 | 35 | 5498 | 1297 | 28,568 |
| 1975, 1983 | 34 | 6537 | 799 | 25,935 |
| Issue | Average Success Rate | Highest Success Rate |
|---|---|---|
| 2001 test issue 1 | 74.96 | 88.31 |
| 2001 test issue 2 | 66.29 | 79.24 |
| 1990 test issue 1 | 67.34 | 82.14 |
| 1990 test issue 2 | 69.22 | 77.55 |
| 1982 test issue | 53.85 | 66.37 |
| 1973 test issue | 68.26 | 76.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bogdanović, M.; Frtunić Gligorijević, M.; Kocić, J.; Stoimenov, L. Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT. Appl. Sci. 2025, 15, 615. https://doi.org/10.3390/app15020615
Bogdanović M, Frtunić Gligorijević M, Kocić J, Stoimenov L. Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT. Applied Sciences. 2025; 15(2):615. https://doi.org/10.3390/app15020615
Chicago/Turabian StyleBogdanović, Miloš, Milena Frtunić Gligorijević, Jelena Kocić, and Leonid Stoimenov. 2025. "Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT" Applied Sciences 15, no. 2: 615. https://doi.org/10.3390/app15020615
APA StyleBogdanović, M., Frtunić Gligorijević, M., Kocić, J., & Stoimenov, L. (2025). Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT. Applied Sciences, 15(2), 615. https://doi.org/10.3390/app15020615