Abstract
The widespread integration of third-party components (TPCs) in Internet of Things (IoT) firmware significantly increases the risk of software vulnerabilities, especially in resource-constrained devices deployed in sensitive environments. Binary Code Similarity Detection (BCSD) techniques, particularly those based on deep neural networks, have emerged as powerful tools for identifying vulnerable functions without access to source code. However, individual models, such as Graph Neural Networks (GNNs), Convolutional Neural Networks (CNNs), and Transformer-based methods, often exhibit limitations due to their differing focus on structural, spatial, or semantic features. To address this, we propose VoteSim, a novel ensemble framework that integrates multiple BCSD models using an inverse average rank voting mechanism. VoteSim combines the strengths of individual models while reducing the impact of model-specific false positives, leading to more stable and accurate vulnerability detection. We evaluate VoteSim on a large-scale real-world IoT firmware dataset comprising over 800,000 binary functions and 10 high-risk CVEs. Experimental results show that VoteSim consistently outperforms state-of-the-art BCSD models in both Recall@10 and Mean Reciprocal Rank (MRR), achieving improvements of up to 14.7% in recall. Our findings highlight the importance of model diversity and rank-aware aggregation for robust binary-level vulnerability detection in heterogeneous IoT firmware.
1. Introduction
IoT has rapidly become an integral part of modern society, with applications spanning sectors such as healthcare, industrial control, and smart homes [1]. IoT devices offer substantial benefits in terms of convenience, automation, and efficiency. According to industry projections, the global number of IoT devices is expected to surpass 29 billion by 2030 [2]. However, this explosive growth introduces serious security risks, as many IoT devices rely on TPCs that often undergo limited security auditing. This dependency on unverified components not only exposes devices to vulnerabilities but also widens the attack surface, drawing considerable attention from both the research community and the public [3].
In this context, BCSD has emerged as a critical technique for discovering vulnerabilities in IoT firmware [4]. BCSD works by extracting features from vulnerable functions, converting them into embeddings, and then comparing the similarity between these embeddings and the functions in the firmware. By measuring the semantic similarity between binary functions, BCSD enables tasks such as vulnerability detection, patch analysis, and malware identification [5]. For example, when firmware lacks symbol tables, BCSD can match binary functions to known vulnerable implementations, thereby facilitating the recovery of function names, source-level semantics, and other metadata. This process greatly aids reverse engineering efforts and improves vulnerability localization, ultimately enhancing the security of IoT devices [6].
In comparison to traditional BCSD approaches, which rely on methods such as symbolic execution [7], graph matching [8], and hashing techniques [9], recent research has increasingly focused on deep learning-based BCSD methods, which effectively address many of the limitations inherent in traditional approaches, such as issues with scalability and accuracy. These include GNNs [10,11,12,13,14], which extract structural features from function graphs; CNNs [15,16], which learn from binary matrix representations; and Transformer-based models [17,18,19], which leverage Natural Language Processing (NLP) techniques to model instruction semantics. These methods extract features from binary code and use neural networks to transform these features into meaningful embeddings, which can then be compared for similarity. For instance, GNNs are particularly useful for extracting structural features from function graphs, CNNs focus on binary matrix representations, and Transformers model instruction semantics using NLP techniques.
Despite their strengths, these deep learning-based approaches exhibit limitations that impact their accuracy and efficiency. GNNs may suffer from “embedding collision” due to simplistic aggregation of node embeddings [20]; CNN-based methods often overfit due to highly repetitive local patterns in sparse binary adjacency matrices; Transformer-based models, while effective at capturing long-range dependencies, may over-concentrate attention on repetitive code regions and consequently miss subtle semantic variations as well as important structural information encoded in the control flow or call graphs [21]. These limitations pose a significant challenge to the robustness and scalability of BCSD in real-world scenarios, particularly in the context of IoT firmware, which spans diverse architectures and includes numerous third-party components. Existing methods fail to achieve optimal performance across different compilers and architectures, limiting their practical applicability.
To address these challenges, we propose a hybrid BCSD framework, tentatively named VoteSim, which integrates the outputs of multiple neural architectures—GNNs, CNNs, and Transformers—through a voting-based ensemble mechanism. By leveraging the complementary strengths of each model, VoteSim effectively mitigates the individual limitations of these approaches, leading to more accurate and robust binary similarity detection. While traditional rank aggregation techniques, such as Borda count and majority voting, have been explored in other domains [22,23,24], VoteSim’s inverse average rank method specifically targets reducing the impact of false positives while enhancing true positive identification in the context of IoT firmware vulnerability detection. This enhanced capability allows VoteSim to better handle the diversity of IoT firmware, offering a scalable solution for vulnerability detection across various hardware architectures and third-party components.
Our contributions can be summarized as follows:
- We design a novel ensemble framework (VoteSim) that integrates diverse neural representations through a voting-based retrieval ranking mechanism.
- We evaluate VoteSim on real-world IoT firmware datasets, demonstrating that our method outperforms state-of-the-art BCSD techniques in both MRR and recall, achieving improvements of up to 14.7% in recall.
- We fill the gap in the literature by presenting a hybrid approach that combines the strengths of multiple neural networks, enabling better BCSD performance through complementary insights from each model.
The remainder of the paper is organized as follows: Section 2 discusses the motivation behind our research, Section 3 details the methodology and design of the VoteSim framework, Section 4 presents the experimental results, Section 5 provides a discussion of our findings, and Section 6 outlines the limitations of our approach and suggests directions for future research.
2. Motivation
DNN-based BCSD approaches typically involve extracting features from binary code, which are then used as inputs for neural networks. Various neural network architectures, such as GNNs, CNNs, and Transformers, are employed to transform these features into meaningful embeddings. However, the features extracted from binary code for representation learning are often too coarse, leading to a loss of semantic information that is critical for accurate similarity detection [25,26].
To address this limitation, we propose VoteSim, which leverages the complementary strengths of multiple neural architectures. To further clarify the methodological rigor and the rationale behind the choice of different base models, Table 1 summarizes representative DNN-based BCSD approaches adopted in our framework. The comparison highlights the diversity in feature extraction, embedding networks, and analysis granularities, which complement each other in VoteSim. Specifically, Gemini leverages manual statistical features with a GNN-based embedding (PStructure2Vec), BinaryAI integrates CNN and MPNN embeddings with BERT-based instruction representations, while jTrans employs a Transformer encoder to directly capture long-range semantic dependencies. By combining these heterogeneous strengths through our inverse average rank aggregation, VoteSim effectively mitigates the limitations of individual models and achieves more robust vulnerability detection.

Table 1.
Comparison of representative DNN-based BCSD approaches. Func denote function-level granularities. AE = Assembly Extraction; MFE = Manual Feature Extraction; PStructure2Vec = Parameterized Structure2Vec Network; CNN = Convolutional Neural Network; MPNN = Message Passing Neural Network; BERT = Bidirectional Encoder Representations from Transformers.
Beyond this theoretical complementarity, we also observe practical evidence that different models excel in different scenarios. Existing DNN-based BCSD methods tend to focus on different types of information. For instance, GNN-based methods primarily emphasize structural differences in function graphs, while Transformer-based methods are more concerned with contextual semantic information. This divergence in focus results in varying retrieval performance for different query functions, as demonstrated in Figure 1. We observe this divergence clearly in the retrieval task for the vulnerability CVE-2014-3511. The function ssl23_get_client_hello, when analyzed across different optimization levels and architectures, exhibits a stable control flow graph (CFG) structure. As a result, methods like Gemini, which focus on graph structures, achieve superior retrieval results. Notably, Gemini’s top 10 true positive (TP) count exceeds that of jTrans by more than 50%. On the other hand, in the case of CVE-2015-1788 and the function BN_GF2m_mod_inv, recognizing contextual semantics and jump instructions proves to be more effective. This indicates that the assembly semantics and jump instructions of this function maintain better stability across different architectures and optimization levels, allowing Transformer-based models like jTrans to perform better in this retrieval task.
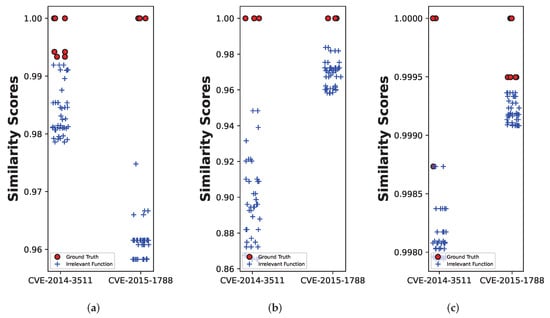
Figure 1.
The comparison of different models on vulnerability detection for CVE-2014-3511 and CVE-2015-1788. Each point in (a–c) represents the similarity score of each function pair in the dataset. We selected the top 50 function pairs. (a) Gemini [27], (b) BinaryAI [16], (c) jTrans [17].
This motivates the design of an ensemble framework. By combining multiple models, it is possible to leverage the structural sensitivity of GNNs together with the semantic awareness of Transformers. Our proposed framework, VoteSim, is a voting-based ensemble that integrates diverse model predictions to consistently elevate true positives and reduce false matches. The significance of this work lies in (1) addressing the performance instability of individual BCSD models, (2) improving robustness and generalization in vulnerability detection across heterogeneous IoT firmware, and (3) demonstrating that cross-model diversity can be systematically exploited to surpass the limitations of any single method.
3. Design of VoteSim
This section presents the design of VoteSim, a voting-based ensemble framework that integrates the ranking results from multiple types of BCSD methods to improve the accuracy and robustness of vulnerability identification in IoT firmware, as shown in Figure 2. Given an input vulnerable function and IoT firmware, different BCSD models—such as GNNs, CNNs, and Transformer-based models—independently return a ranked list of candidate similar functions. Each model captures different semantic and structural aspects of binary code, thus producing complementary ranking results. To improve the robustness and accuracy of the detection, VoteSim integrates the results from these methods using a voting mechanism. VoteSim first collects the search results from each BCSD method. Then, it computes the inverse average ranking of the functions returned by these methods, creating a comprehensive ranking. Finally, the functions are reordered based on this integrated ranking score, resulting in a more reliable and stable final retrieval outcome.
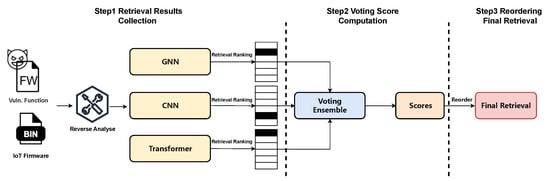
Figure 2.
Overview of the proposed VoteSim approach, consisting of 3 main steps. Step 1: Three representative types of neural network methods are employed to decompose binary code, extract semantic information, and perform vulnerability detection. Step 2: The rankings retrieved by each model are aggregated using a voting mechanism and output scores. Step 3: Candidate functions are reordered based on the aggregated voting scores, with higher-ranked functions representing the most likely vulnerable targets.
3.1. Retrieval Results Collection
To cover a variety of methods, we selected three representative BCSD approaches: Gemini [27], a GNN-based method; BinaryAI [16], a CNN-based method; and jTrans [17], a Transformer-based method. It is important to note that our approach is not limited to these three methods; users can choose alternative methods based on their specific needs. To ensure standardization and reproducibility, we strictly followed the descriptions provided in the respective papers and utilized their open-source code implementations.
The process begins with disassembling binary code into either assembly language or an intermediate representation (IR). To collect and analyze the data, reverse engineering tools were employed to extract necessary information from the firmware binaries. These tools enable the disassembly and analysis of binary code, producing IR and assembly language for further processing. Specifically, Binwalk (https://github.com/ReFirmLabs/binwalk, accessed on 1 September 2025) was used to extract raw binary code and relevant components from firmware images, allowing for a focused examination of embedded functions. Additionally, Radare2 (https://www.radare.org, accessed on 1 September 2025), a powerful open-source reverse engineering framework, was utilized to disassemble the binaries and generate function-level IRs, which were then input into the neural networks. Trained neural networks are then employed to extract semantic information from functions and embed this information into high-dimensional representations. Function matching is subsequently performed by evaluating the similarity of these embeddings. Finally, based on the similarity scores, we collect the retrieval results corresponding to the target vulnerable functions.
3.2. Voting Score Computation
To leverage the strengths of each method’s feature recognition for enhanced vulnerability detection, we adopt a voting mechanism to aggregate the results from all models and determine the final outcome.
Unlike traditional ensemble methods such as Borda count or majority voting, which treat all ranks equally or rely on simple vote aggregation, VoteSim introduces an inverse average rank aggregation strategy specifically tailored for BCSD. This approach prioritizes candidates consistently ranked highly across models, thereby amplifying confident true positive matches, while simultaneously downweighting scattered false positives that rarely achieve high consensus. By leveraging redundancy in TP predictions and diversity in false positive (FP) noise, VoteSim provides a more accurate and robust ensemble solution. To the best of our knowledge, this is the first rank-aggregation method explicitly designed for the characteristics of BCSD, representing a key methodological contribution of this work.
For a given vulnerable target function that needs detection, we treat all functions in the firmware libraries as candidate functions and search for the most similar function in the built vulnerability repository. For each candidate function c, each model m assigns a similarity score or rank. To standardize the rankings across different models, we convert the rank positions into normalized scores. We choose rank-based values instead of cosine similarity scores because the cosine similarity distributions across methods can differ significantly due to variations in training and model design (as shown in Figure 1). Cross-model cosine similarity comparison may therefore lack meaningful interpretation. In contrast, ranks provide a unified metric that better reflects the retrieval performance of different methods.
To emphasize the importance of rank, we use the inverse average rank as the basis for the voting mechanism, as expressed by the following formula:
where M is the total number of models, is the rank of candidate c assigned by model m.
The rationale is that inverse average rank emphasizes confident predictions, placing more weight on higher-ranked true positives and reducing the impact of false positives, which are often inconsistently ranked across models. This approach allows us to aggregate the strengths of multiple methods in a consistent manner, improving the overall vulnerability detection accuracy.
3.3. Reordering and Final Retrieval
After computing the aggregated voting scores for each candidate function, the next step is to reorder all candidates based on these scores in descending order. This ensures that the most relevant functions, with the highest similarity to , are placed at the top of the retrieval list.
By sorting the candidates in this manner, we can prioritize the functions that are most likely to be vulnerable, leading to more accurate and efficient detection of vulnerabilities in the firmware. The final retrieval list, therefore, represents a ranked order of functions, where higher-ranked functions are the ones most likely to correspond to the target vulnerable function . Through this ensemble, VoteSim achieves more precise and stable vulnerability detection performance compared to any single BCSD approach.
3.4. Computational Complexity
While VoteSim improves detection accuracy, it does introduce additional computational overhead compared to individual models. The ensemble method aggregates the similarity scores from each base model using an inverse average rank strategy, leading to a time complexity of , where N is the number of functions and n is the number of base models. However, this additional time consumption is relatively insignificant compared to the computational cost of running each individual base model, making the extra overhead for the ensemble approach negligible in practical applications.
4. Evaluation
In this section, we present a comprehensive evaluation of VoteSim by comparing it with three representative BCSD models, which serve as the individual voters in our voting-based ensemble approach. This comparison highlights the stable performance of our model and the improvements achieved through voting-based integration. To this end, we perform vulnerability detection on multiple real-world IoT firmware datasets and evaluate the results using various performance metrics. Our evaluation is structured as follows: we first describe the experimental setup, followed by the datasets used, the metrics employed, the selection of baselines, and the results of the performance comparison.
4.1. Evaluation Setup
All the experiments are run on a Linux server running Ubuntu 20.04.6 equipped with an Intel(R) Xeon(R) Platinum 8468 processor and 1 TB of RAM and 8 Nvidia A100 GPUs.
IoT-dataset. This dataset builds upon previously established datasets used in the field [20], enabling comparisons and validation of our results against well-established benchmarks in the research community. The dataset includes 90 IoT firmware images, comprising a total of 9034 ELF files and 815,689 functions. The corresponding devices for these firmware images span multiple categories, including routers, wireless access points (e.g., COVR-2600R and DAP2610), network video recorders (e.g., FW_TV-NVR104), and network storage devices (e.g., TRENDNET_TN200), showcasing the dataset’s wide applicability. Furthermore, some firmware in the dataset (such as DES-1210-28_A1_2_03_B016_BETA) are beta versions, which typically include new features or fixes for vulnerabilities found in previous versions. We ensure that their inclusion does not introduce bias, as they are handled similarly to stable releases, and their impact on model performance is minimal. Moreover, the dataset encompasses firmware from over ten leading IoT vendors, including D-Link, TP-Link, Tuya, and Trendnet.
The dataset is split into training, validation, and test sets according to each base method, ensuring a balanced distribution of vulnerabilities across these sets. Ground truth labels were manually curated based on known CVE vulnerabilities and their associated functions in the firmware. We also mention that the dataset reflects a broad diversity of IoT firmware, including various vendors and device types, such as routers, network storage, and video recorders, to ensure real-world relevance.
4.2. Evaluation Metrics
Most recent BCSD approaches are evaluated in the context of vulnerability detection [10,11,15,28,29]. These methods aim to identify functions in a firmware binary that are vulnerable and correspond to a given target vulnerability. The vulnerability detection task can be likened to information retrieval. Given a target vulnerability function and a repository of candidate functions , BCSD methods retrieve the top k most relevant candidate functions. In this case, we use various performance metrics to evaluate the effectiveness of VoteSim.
Let there be a repository of candidate functions and a target vulnerability function . denotes the number of ground truth matches for the target function among the top k retrieved functions and N is the total number of ground truth functions . On the other hand, indicates the number of ground truth matches that are not present within the top k list. represents the ground truth rank in the query’s returned results corresponds to .
Recall@k indicates the proportion of relevant instances retrieved in the top k results, averaged over all queries. It is defined as follows:
MRR evaluates the rank of the correct match for each query. It measures the average of the reciprocal ranks of the relevant result for a set of queries. It is defined as follows:
4.3. Baselines
To assess the effectiveness and stability of VoteSim, we selected three representative BCSD methods for comparison, each utilizing different types of neural networks. The results from these methods are also used as individual voters for VoteSim, allowing us to evaluate whether VoteSim can effectively consolidate the strengths of these BCSD methods and produce better outcomes. It is important to reiterate that VoteSim can incorporate the results of any model as independent voters, depending on the user’s needs. As noted, there are currently very few ensemble or voting-based frameworks specifically applied to BCSD for IoT firmware. To the best of our knowledge, ensemble or voting-based frameworks have rarely been applied to BCSD for IoT firmware. Consequently, our comparisons are limited to representative individual methods rather than ensemble frameworks.
Gemini [27]. This method uses GNN to learn the CFG representations of binary functions. We reproduced the method using the official code provided by the authors (https://github.com/xiaojunxu/dnn-binary-code-similarity, accessed on 1 September 2025).
jTrans [17]. jTrans employs a Transformer-based model to capture control flow information within the binary. We reproduced the method using the official code provided by the authors (https://github.com/vul337/jTrans/tree/main, accessed on 1 September 2025).
BinaryAI [16]. This approach uses BERT for pre-training at the token and block levels and employs a CNN on the CFG to generate the second type of embedding. Since the original method is not open-source, we implemented the method ourselves based on the configurations outlined in the original paper.
4.4. Vulnerability Detection
To facilitate the vulnerability detection process, we selected 10 highly exploitable vulnerable functions from commonly used third-party libraries, such as OpenSSL and Pop3client. These include high-risk vulnerabilities like CVE-2015-0288, which allows remote code execution through buffer overflow in OpenSSL, CVE-2008-1672, which exposes a vulnerability in Pop3client that can be exploited to execute arbitrary commands, and CVE-2021-3156, a heap-based buffer overflow vulnerability in Sudo that allows unauthorized privilege escalation. These vulnerabilities are widely present across various IoT firmware platforms, and their representation in our dataset is shown in Table 2.
Table 2.
The vulnerabilities involved in IoT-dataset.
First, we gather the results from the BCSD models for vulnerability detection. Then, VoteSim is employed to compute the inverse average of the ranks for the collected results, effectively combining the predictions from different models. Based on these aggregated scores, we re-rank the results and finalize the most relevant matches for the target vulnerabilities.
Findings. Table 3 presents the comparative performance of three cutting-edge BCSD models—Gemini, BinaryAI, and jTrans—alongside our ensemble approach, VoteSim. The results demonstrate that VoteSim consistently outperforms individual models in both Recall@10 and MRR metrics. Specifically, VoteSim achieves an average Recall@10 of 0.520, compared to Gemini (0.440), BinaryAI (0.367), and jTrans (0.453). Similarly, it obtains the highest average MRR of 0.213, outperforming Gemini (0.195), BinaryAI (0.180), and jTrans (0.193). These improvements demonstrate the effectiveness of our aggregation strategy in leveraging the strengths of multiple DNN-based BCSD models. By reducing individual prediction bias and enhancing robustness, VoteSim improves both vulnerability detection accuracy and ranking consistency across diverse IoT firmware.
Table 3.
Comparison of individual BCSD models and VoteSim on vulnerability detection.
Given the small number of CVEs (n = 10) and the high variance across cases, confidence intervals are relatively wide and some pairwise improvements do not pass two-sided significance at = 0.05. This reflects sample-size limitations rather than a methodological flaw. To address this concern, we additionally evaluated VoteSim on the complete test set comprising 187 CVEs. We further conducted paired t-tests across the full dataset, which showed that the improvements in Recall@10 and MRR are statistically significant (p < 0.01). These results confirm that the observed gains are robust and not due to random variation.
Case Analysis. In high-impact vulnerabilities such as CVE-2015-1791, which involves a heap-based buffer overflow in Sudo that allows unauthorized privilege escalation, VoteSim achieves perfect recall@10 (1.000) and the highest MRR (0.408), demonstrating its ability to accurately rank the correct vulnerable function at the top. This vulnerability is particularly severe due to its potential for full root access, and VoteSim’s precise identification underscores its practical utility in real-world scenarios.
In more nuanced cases, the comparative behavior of VoteSim with respect to individual models further validates its advantage. For example, in CVE-2014-3511, a denial-of-service vulnerability triggered by crafted DTLS packets in OpenSSL, VoteSim achieves a Recall@10 of 0.412—closer to Gemini (0.412) than BinaryAI or jTrans (both 0.176). This suggests that in instances where one model excels while others underperform, VoteSim successfully preserves the stronger signal through aggregation. Similarly, in CVE-2008-1672, a command execution vulnerability in Pop3client caused by improper input handling, VoteSim’s Recall@10 reaches 0.600, aligning more with jTrans (0.700) rather than Gemini and BinaryAI (both 0.300). This illustrates that VoteSim can flexibly shift alignment based on which individual model performs better in each context.
The superior performance of VoteSim can be attributed to its use of the inverse average rank aggregation strategy [22,30]. This method places greater emphasis on functions that appear near the top of individual model rankings. Specifically, when at least two out of the three base models (Gemini, BinaryAI, and jTrans) rank the ground truth vulnerable function near the top, the inverse averaging mechanism assigns it a low aggregated rank. This technique effectively amplifies agreement on TPs while suppressing disagreement on FPs.
Furthermore, FPs are often scattered and inconsistent across models [31,32]. It is rare for multiple models to rank the same incorrect function highly. VoteSim downweights these outliers, leading to fewer top-ranked FPs. As a result, TPs are more accurately ranked higher. Essentially, VoteSim turns model disagreements into a filtering mechanism, improving reliability by leveraging the redundancy in TP predictions and the diversity in FP noise.
In summary, the key results from the experiments are as follows:
- VoteSim outperforms individual models in both Recall@10 and MRR, showing the effectiveness of its aggregation strategy.
- For high-impact vulnerabilities like CVE-2014-3511 and CVE-2008-1672, VoteSim outperforms individual models by preserving the stronger signals through aggregation, highlighting its flexibility and robustness.
- The inverse average rank aggregation strategy significantly enhances the model’s ability to detect true positives while reducing the impact of false positives.
Overall, these findings demonstrate that VoteSim not only improves the average performance metrics but also offers more stable and reliable results, making it a powerful tool for vulnerability detection in IoT firmware.
5. Discussion
Model Complementarity and Ensemble Strength. Our findings show that different BCSD models (Gemini, BinaryAI, jTrans) exhibit complementary strengths when dealing with varying code structures and semantics. By aggregating their predictions through VoteSim, we effectively capture and leverage this complementarity. The ensemble consistently demonstrates more stable performance across diverse CVEs, especially in cases where one or two models identify the correct vulnerable function but others fail. VoteSim’s ability to adaptively reflect the best-performing model in each case highlights the value of ensemble strategies in vulnerability detection tasks.
Rank-Aware Aggregation Reduces False Positives. The inverse average rank mechanism used by VoteSim plays a critical role in its effectiveness. Unlike simple majority voting [33,34,35,36], this method emphasizes agreement among models at higher ranks, making the final decision more sensitive to confident predictions. Since FPs tend to be inconsistently ranked across models, this approach naturally downweights them, thereby increasing the ranking of TPs. As demonstrated in our results, this strategy not only improves top k precision but also makes the system more practical for real-world use, where developers prioritize the most likely matches.
Comparison with Existing Literature. The performance improvements observed with VoteSim are consistent with trends observed in the literature, where deep learning models have shown great promise in binary code analysis tasks. Models such as Gemini and BinaryAI have demonstrated success in their respective domains, but often exhibit limited generalization across varying compilers and architectures [10,20]. Similarly, methods like jTrans have made significant strides in capturing semantic information but struggle with repetitive or low-level code features. Our study confirms these findings and shows that ensemble approaches, like VoteSim, can significantly improve accuracy by combining models with complementary strengths, addressing gaps in individual methods. By contrast, most current studies focus on optimizing single-model performance, often neglecting the value of integrating diverse model architectures [11,14].
Implications of the Study. The implications of our study are twofold. First, it provides empirical evidence supporting the efficacy of ensemble methods in the domain of BCSD, specifically for IoT firmware. By demonstrating that VoteSim can improve accuracy across multiple models, our results suggest that vulnerability detection systems can benefit from combining different detection strategies. This is particularly significant for IoT security, where firmware diversity and evolving attack vectors pose a major challenge to traditional detection systems. Second, our work highlights the importance of adaptive aggregation strategies in vulnerability detection tasks, showing that considering model performance at higher ranks can yield more practical, real-world results.
6. Limitation and Future Work
Despite the improvements, our study has several limitations. VoteSim still inherits some of the limitations of its component models. While VoteSim improves overall recall and MRR, it still inherits the collective limitations of its component models. In cases where none of the base models rank the correct function within the top candidates, the ensemble cannot compensate. This highlights the importance of improving base model performance, especially in edge cases where vulnerabilities are more subtle. Moreover, our current implementation assumes that all models are of equal importance, without considering their contextual confidence or prediction reliability. This could be addressed by dynamic weighting, where models with higher confidence or performance in specific scenarios are given more influence in the final decision. Additionally, the current ensemble is limited to three models, and expanding the ensemble with a more diverse set of models could enhance its coverage and robustness.
Future work could also explore incorporating score-aware aggregation [30] or confidence-based weighting to further improve the ensemble’s adaptability. Furthermore, testing VoteSim in real-world IoT environments and on more extensive datasets could provide deeper insights into its performance across different hardware architectures and compilers. Lastly, integrating unsupervised or semi-supervised learning techniques could allow VoteSim to detect previously unknown vulnerabilities, thus addressing the challenge of zero-day vulnerability detection in firmware analysis.
7. Conclusions
In this study, we introduced VoteSim, an ensemble framework that improves BCSD for vulnerability identification in IoT firmware. By combining multiple deep learning models—Gemini, BinaryAI, and jTrans—VoteSim leverages their complementary strengths through an inverse average rank aggregation mechanism. This enhances detection accuracy, reduces false positives, and improves Recall@10 and MRR. Our results demonstrate that VoteSim outperforms individual models, offering a more stable and robust approach to identifying vulnerabilities across diverse IoT firmware. This research contributes to the field by highlighting the benefits of ensemble methods and rank-aware aggregation in BCSD, which can enhance the scalability and accuracy of automated vulnerability detection systems. While VoteSim shows promising results, future work could explore dynamic weighting, the integration of additional models, and the application of semi-supervised learning for zero-day vulnerability detection. Overall, VoteSim represents a step forward in improving the security of IoT devices by providing a more reliable approach to vulnerability detection.
Author Contributions
K.S.: writing—review editing, methodology, and investigation. S.Z.: conceptualization, software, data curation, and writing—original draft preparation. Y.M.: formal analysis, methodology, and conceptualization. W.R.: methodology, software, and project administration. L.C.: validation and formal analysis. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article; further inquiries can be directed to the corresponding author.
Conflicts of Interest
Author Keda Sun and Yuwei Meng were employed by the company Zhejiang Provincial Energy Group Company Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Mehdipour, F. A Review of IoT Security Challenges and Solutions. In Proceedings of the 2020 8th International Japan-Africa Conference on Electronics, Communications, and Computations (JAC-ECC), Online, 14–15 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Luo, Z.; Wang, P.; Xie, W.; Zhou, X.; Wang, B. IoTSim: Internet of things-oriented binary code similarity detection with multiple block relations. Sensors 2023, 23, 7789. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wu, L.; Yin, G.; Li, L.; Zhao, H. A Survey on Security and Privacy Issues in Internet-of-Things. IEEE Internet Things J. 2017, 4, 1250–1258. [Google Scholar] [CrossRef]
- Feng, X.; Zhu, X.; Han, Q.L.; Zhou, W.; Wen, S.; Xiang, Y. Detecting vulnerability on IoT device firmware: A survey. IEEE/CAA J. Autom. Sin. 2022, 10, 25–41. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, J.; Wang, Y.; Zhai, S.; Li, Z.; He, Y.; Sun, K.; Li, Q.; Zhang, N. Your firmware has arrived: A study of firmware update vulnerabilities. In Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, USA, 14–16 August 2024; pp. 5627–5644. [Google Scholar]
- Sun, H.; Zhou, W.; Fei, M. A Survey On Graph Matching in Computer Vision. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), IEEE, Chengdu, China, 17–19 October 2020; pp. 225–230. [Google Scholar] [CrossRef]
- Gao, D.; Reiter, M.K.; Song, D.X. BinHunt: Automatically finding semantic differences in binary programs. In Proceedings of the 10th International Conference on Information and Communications Security (ICICS), Birmingham, UK, 20–22 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 238–255. [Google Scholar] [CrossRef]
- Dullien, T.; Rolles, R. BinDiff: Finding similarities in binary code. In Proceedings of the Conference on Reverse Engineering, Pittsburgh, PA, USA, 7–11 November 2005. [Google Scholar]
- Rabin, M.O.; Broder, A.Z. Hashing for Similarity Search: An Empirical Evaluation. In Proceedings of the International Conference on Research and Development in Information Retrieval (SIGIR), New Orleans, LA, USA, 9–13 September 2001; ACM: New York, NY, USA, 2001; pp. 34–40. [Google Scholar]
- Fu, L.; Ji, S.; Liu, C.; Liu, P.; Duan, F.; Wang, Z.; Chen, W.; Wang, T. Focus: Function clone identification on cross-platform. Int. J. Intell. Syst. 2022, 37, 5082–5112. [Google Scholar] [CrossRef]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Sun, J. VulSeeker: A Semantic Learning Based Vulnerability Seeker for Cross-Platform Binary. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 896–899, ISSN 2643-1572. [Google Scholar] [CrossRef]
- Ling, X.; Wu, L.; Wang, S.; Ma, T.; Xu, F.; Liu, A.X.; Wu, C.; Ji, S. Multilevel graph matching networks for deep graph similarity learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 799–813. [Google Scholar] [CrossRef] [PubMed]
- Massarelli, L.; Di Luna, G.A.; Petroni, F.; Querzoni, L.; Baldoni, R. Investigating graph embedding neural networks with unsupervised features extraction for binary analysis. In Proceedings of the 2nd Workshop on Binary Analysis Research (BAR), San Diego, CA, USA, 24 February 2019; pp. 1–11. [Google Scholar]
- Yang, J.; Fu, C.; Liu, X.Y.; Yin, H.; Zhou, P. Codee: A tensor embedding scheme for binary code search. IEEE Trans. Softw. Eng. 2021, 48, 2224–2244. [Google Scholar] [CrossRef]
- Liu, B.; Huo, W.; Zhang, C.; Li, W.; Li, F.; Piao, A.; Zou, W. αDiff: Cross-version binary code similarity detection with DNN. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; ACM: New York, NY, USA, 2018; pp. 667–678. [Google Scholar] [CrossRef]
- Yu, Z.; Cao, R.; Tang, Q.; Nie, S.; Huang, J.; Wu, S. Order matters: Semantic-aware neural networks for binary code similarity detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1145–1152. [Google Scholar]
- Wang, H.; Qu, W.; Katz, G.; Zhu, W.; Gao, Z.; Qiu, H.; Zhuge, J.; Zhang, C. jTrans: Jump-Aware Transformer for Binary Code Similarity. arXiv 2022, arXiv:2205.12713. [Google Scholar]
- Wang, H.; Gao, Z.; Zhang, C.; Sha, Z.; Sun, M.; Zhou, Y.; Zhu, W.; Sun, W.; Qiu, H.; Xiao, X. CLAP: Learning Transferable Binary Code Representations with Natural Language Supervision. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2024), Vienna, Austria, 16–20 September 2024; pp. 503–515. [Google Scholar] [CrossRef]
- Wang, H.; Gao, Z.; Zhang, C.; Sun, M.; Zhou, Y.; Qiu, H.; Xiao, X. CEBin: A Cost-Effective Framework for Large-Scale Binary Code Similarity Detection. arXiv 2024, arXiv:2402.18818. [Google Scholar]
- Zhou, S.; Fu, L.; Liu, P.; Wang, W. BinEGA: Enhancing DNN-based Binary Code Similarity Detection through Efficient Graph Alignment. In Proceedings of the 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Montreal, QC, Canada, 4–7 March 2025; pp. 488–499. [Google Scholar]
- Fu, L.; Liu, P.; Meng, W.; Lu, K.; Zhou, S.; Zhang, X.; Chen, W.; Ji, S. Understanding the AI-powered Binary Code Similarity Detection. arXiv 2024, arXiv:2410.07537. [Google Scholar] [CrossRef]
- Dwork, C.; Kumar, R.; Naor, M.; Sivakumar, D. Rank aggregation methods for the web. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; ACM: New York, NY, USA, 2001; pp. 613–622. [Google Scholar]
- Lin, S. Rank aggregation methods. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 555–570. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Wang, H.; Ma, P.; Yuan, Y.; Liu, Z.; Wang, S.; Tang, Q.; Nie, S.; Wu, S. Enhancing DNN-Based Binary Code Function Search with Low-Cost Equivalence Checking. IEEE Trans. Softw. Eng. 2023, 49, 226–250. [Google Scholar] [CrossRef]
- Zhang, P.; Wu, C.; Wang, Z. BINCODEX: A comprehensive and multi-level dataset for evaluating binary code similarity detection techniques. BenchCouncil Trans. Benchmarks Stand. Eval. 2024, 4, 100163. [Google Scholar] [CrossRef]
- Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; Song, D. Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS’17, Dallas, TX, USA, 30 October–3 November 2017; pp. 363–376. [Google Scholar] [CrossRef]
- Schoonaert, B.; Kim, H.J.; Paek, Y.H. A Study on Binary Code Similarity Detection. In Proceedings of the Annual Conference of KIPS. Korea Information Processing Society, Jeju, Republic of Korea, 16–18 December 2024; pp. 216–219. [Google Scholar]
- Yang, S.; Cheng, L.; Zeng, Y.; Lang, Z.; Zhu, H.; Shi, Z. Asteria: Deep learning-based AST-encoding for cross-platform binary code similarity detection. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; pp. 224–236. [Google Scholar]
- Halder, A.; Dalal, A.; Gharami, S.; Wozniak, M.; Ijaz, M.F.; Singh, P.K. A fuzzy rank-based deep ensemble methodology for multi-class skin cancer classification. Sci. Rep. 2025, 15, 6268. [Google Scholar] [CrossRef]
- Rajora, K.; Abdulhussein, N.S. Reviews research on applying machine learning techniques to reduce false positives for network intrusion detection systems. Babylon. J. Mach. Learn. 2023, 2023, 26–30. [Google Scholar] [CrossRef] [PubMed]
- da Silveira Lopes, R.; Duarte, J.C.; Goldschmidt, R.R. False Positive Identification in Intrusion Detection Using XAI. IEEE Lat. Am. Trans. 2023, 21, 745–751. [Google Scholar] [CrossRef]
- Jiang, V.S.; Kandula, H.; Thirumalaraju, P.; Kanakasabapathy, M.K.; Cherouveim, P.; Souter, I.; Dimitriadis, I.; Bormann, C.L.; Shafiee, H. The use of voting ensembles to improve the accuracy of deep neural networks as a non-invasive method to predict embryo ploidy status. J. Assist. Reprod. Genet. 2023, 40, 301–308. [Google Scholar] [CrossRef] [PubMed]
- Ragab, M.; Alshammari, S.M.; Al-Ghamdi, A.S. Modified Metaheuristics with Weighted Majority Voting Ensemble Deep Learning Model for Intrusion Detection System. Comput. Syst. Sci. Eng. 2023, 47, 2497–2512. [Google Scholar] [CrossRef]
- Khan, S.A.; Rehman, A.U.; Arshad, A.; Alqahtani, M.H.; Mahmoud, K.; Lehtonen, M. Effective Voting-Based Ensemble Learning for Segregated Load Forecasting with Low Sampling Data. IEEE Access 2024, 12, 84074–84087. [Google Scholar] [CrossRef]
- Fu, G.; Li, B.; Yang, Y.; Li, C. Re-ranking and TOPSIS-based ensemble feature selection with multi-stage aggregation for text categorization. Pattern Recognit. Lett. 2023, 168, 47–56. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).