Abstract
Accurate re-identification of individual cows is crucial for effective herd management in precision cattle farming. However, this task is challenging in real-world scenarios due to variability in cow appearances and environmental conditions as well as the limited number of reference images available for re-identification. This paper addresses the problem of cow re-identification under open-set and few-shot conditions, where the system must recognize previously unseen individuals with limited annotated data. Metric learning was used to train a neural network for re-identification and its performance was evaluated using K-nearest neighbors (KNN). The neural network is applied to two datasets: OpenSetCows2020 and MultiCamCows2024 captured on different farms. Four testing variants are proposed that resemble different real-life situations: initial deployment, barn change, addition of new cows and cross-farm generalization. The results show that the applied model achieves >90% accuracy with 10 reference images on the same-farm dataset, while cross-farm performance either requires 60 or more reference images to reach similar levels or remains below 63% across metrics. The proposed framework directly addresses the challenges in real-world cattle farming, and allows for a more in-depth analysis of the characteristics and applicability of re-identification methods from a practical perspective than existing evaluation metrics.
1. Introduction
Accurate identification of individual animals is a key component in precision livestock farming, allowing automated health monitoring, behavior analysis and traceability. In dairy farming, identifying cows across time and locations is especially important for herd management, but remains a challenging task due to the large number of individual cows typically present on farms, as well as appearance similarity, varying viewpoints and environmental noise.
Visual re-identification (re-ID) offers a non-invasive solution for individual recognition using standard camera systems; however, most existing pipelines are trained and evaluated under closed-set assumptions, presuming that all identities are known during training and that many labeled images are available per cow. In practice, farms are dynamic: new cows enter or leave the herd, labeling at scale is costly and retraining is impractical. Despite progress from datasets such as MultiCamCows2024 [1] (multi-camera, more realistic footage) and methods like ResSTN [2] (pose normalization with attention and ArcFace), as well as hybrid/metric-loss pipelines with k-NN [3,4], evaluations typically remain closed-set and data-rich. They rarely isolate new class enrollment and quantify the sensitivity to the number of reference images, with limited cross-farm testing. These gaps motivate the present study.
In this paper, we investigate whether a single embedding model, once trained, allows reliable open-set, few-shot cow re-identification across multiple farms and cameras without re-training. We identify cows by comparing incoming (query) images to a labeled reference set built from seed images of enrolled cows. We treat the problem as open-set through novel-class enrollment: some enrolled cows are absent from training, and the system must recognize them from their seed images without retraining. The setting is few-shot because each cow is represented by only a small set of seeds (e.g., 1, 2, 5, 10). For our research, we propose an evaluation framework consisting of the following four protocols:
- (1)
- Within-farm, incremental enrollment: new (previously unseen) cows are enrolled post-training by adding their seed images to the reference set, and queries contain both previously seen and newly enrolled cows.
- (2)
- Within-farm, novel-only: the reference set and the query set contain only cows that were unseen during training.
- (3)
- Within-farm, mixed-reference/novel-query: the reference set includes both seen and unseen cows, while the query set contains only unseen cows.
- (4)
- Cross-farm generalization: training is performed on one farm, whereas enrollment (seed images) and testing are performed on a different farm.
Our hypotheses are as follows: (i) Evaluations that mix cows seen during training with new cows in the test queries inflate re-ID performance; hence, protocols (2) and (3), where known cows are excluded from the query set, are designed to provide more realistic assessment. (ii) k-NN identification degrades when a small number of seed images, e.g., less than 10, are available per cow. To test these hypotheses, we train a convolutional neural network with a hybrid loss (softmax classification + triplet) to learn a discriminative, distance-aware embedding. At inference, we project seed and query images into the learned embedding and label each query by k-nearest neighbors (e.g., Euclidean distance) to the seed embeddings.
This workflow aligns with operational constraints in modern dairy production: new cows can be enrolled by adding a handful of seed images to the reference set; the reference set can be expanded without retraining; and the system operates with existing barn cameras rather than specialized sensors. This reduces annotation load and system downtime, maintains identity-consistent records for each cow across cameras and days as herd size grows and enables early-warning applications (e.g., health or mobility anomalies) that depend on consistent individual tracking.
The contributions of this paper are as follows:
- We propose an evaluation method that gives a better insight into the performance of a re-identification system when introducing new cows.
- We provide a thorough analysis of the impact of the number of annotated (seed) images per identity on re-identification accuracy.
2. Related Research
Early approaches to cow re-identification relied on traditional computer vision techniques to extract visual features, which were then classified using models such as SVMs [5] or FLANN-based matchers [6]. For example, ref. [7] combined YOLO-based cow detection with a fine-tuned CNN classifier to identify individual cows in side-view images.
More recent efforts have explored lightweight and few-shot learning-based approaches to improve efficiency and generalization. In [8], a CNN classifier is fine-tuned using few-shot transfer learning to identify cows from images of their muzzles, achieving high accuracy with minimal per-animal data. Similarly, ref. [9] proposes a lightweight CNN designed for fast identification from side views, targeting real-time deployment in farm settings.
Modern cow re-identification methods increasingly rely on deep metric learning due to the open-set nature of the task, where new identities may appear after training. Instead of producing class probabilities, metric learning models output embeddings in a latent space, where intra-class samples are close together and inter-class samples are far apart. This formulation is naturally suited for distance-based classification and generalization to unseen classes.
Top-down images of Holstein–Friesian cattle have been widely used for training metric learning models [1,2,3,4]. In [4], the authors compare several loss functions including ArcFace [10], supervised contrastive loss [11], triplet loss and cross-entropy loss. Cosine distance is used for inference, and ArcFace yields the best results, achieving results on par with RFID-based identification systems, with F1 score of 0.927, 0.942 and 0.937 on three different farms.
In [3], a combination of reciprocal triplet loss [12] and softmax loss is used to train a CNN that outputs identity embeddings. A classification head is included during training but removed at inference, where a k-nearest neighbor (k-NN) classifier is applied for identity prediction. They achieved 92.45% accuracy when using 90% of the cows for training, and 87.55% when using only 10% of the cows for training.
The framework proposed in [2] introduces a spatial transformer module (ResSTN) to normalize cow orientations. The study evaluates multiple loss functions, attention mechanisms and distance metrics, and includes robustness tests on cropped and occluded images. The best performance, 94.58% accuracy, is achieved using the SimAM attention module [13] in combination with ResSTN, training with ArcFace loss [10] and cosine distance for classification.
Other metric learning approaches focus on efficiency or contrastive training objectives. In [14], a lightweight model using triplet and cross-entropy losses is developed for side-view cow identification, enabling deployment on resource-constrained systems. Meanwhile, ref. [1] applies NTXentLoss [15,16], a contrastive learning objective, in a multi-camera setup for training. They achieved 91.70% mean accuracy in self-supervised setting with multiple cameras, and 82.7%, 84.36% and 52.95% mean accuracy when using only one camera.
To improve generalization across domains, ref. [17] proposes cumulative unsupervised multi-domain adaptation (CUMDA), which incrementally adapts a source model to multiple target farms without labeled data, preserving performance across all domains.
Self-supervised learning has also been explored to reduce annotation requirements. In [18], the authors introduce a video-based self-supervised approach using top-down footage, where cows are tracked across frames to generate positive training pairs. These are used alongside random negative pairs to train a network with reciprocal triplet loss. Final cow identities are recovered via clustering on the learned embedding space. They achieved 57.0% Top-1 accuracy and 76.9% Top-4 accuracy.
Finally, ref. [19] introduces a universal cattle re-identification system based on top-down depth imagery, using either CNNs or PointNet to embed cows based on 3D body shape rather than coat pattern. A k-NN classifier is used on the learned embeddings, making the system broadly applicable across cattle breeds and visual conditions.
Despite the progress made by previous work, several gaps remain. Most existing cow re-identification methods are evaluated under relatively fixed or closed settings, with limited analysis of how performance changes as the number of reference images per identity is reduced. Few studies explicitly assess re-identification under both few-shot and open-set conditions using a consistent and transparent evaluation protocol. Although hybrid learning and learning functions have been adopted, their performance is often reported under favorable assumptions, such as access to abundant training data or consistent domains. Our work addresses these gaps by systematically analyzing re-ID performance as a function of seed image availability and by testing generalization across datasets using a simple, scalable embedding-based pipeline.
3. Datasets
Two datasets containing images of Holstein–Friesian cows captured in farm environments are used in this work. Each dataset contains annotated cow images in a top-down view, which form a basis for the evaluation of the re-identification system used in this work. Images from the dataset are divided into seed and query sets. The seed set represents training data, while the query set represents testing data. This naming approach is explained in more detail in Section 5.
The OpenSetCows2020 dataset presented in [3] is a combination of datasets presented in [5,20,21]. Indoor footage was taken using fixed cameras, while the outdoor images were taken on board an unmanned aerial vehicle (UAV). The dataset is divided into two components: for detection and localization and for open-set identification. In this work, only the set for identification was used. The identification component consists of images representing regions of interest obtained from the detection component using a generic cross-breed cattle detector. In [3], the authors compared the architectures of RetinaNet [22], Faster R-CNN [23] and YOLOv3 [24]. These images are oriented so that the cows always look to the right and their heads and tails are not visible. All images have a resolution of . The dataset contains 46 unique cows with a total number of 4 736 images. The images are split into seed and query sets, in a ratio of 89.5% to 10.5%. Each cow in the seed set contains between 18 and 316 images, with an average of 92 images per cow and a total of 4240 images. The query set contains between 2 and 36 images, with an average of 10 images per cow and a total of 496 images.
The MultiCamCows2024 dataset, presented in [1], contains surveillance videos of cows recorded by three cameras on a farm over 7 days. Using ResNet-152 [25], the authors extracted the cows’ locations (region of interest) from the videos and performed head-oriented rotated bounding box detection, which was also normalized so that all cows face to the right. In addition, these bounding boxes were grouped into tracklets covering individual cows passing all three cameras. The authors assumed one tracklet per cow per day. In total, there are 90 individual cows, but not all cows are seen every day. There are a minimum of 4 tracklets per cow and a maximum of 7. The average size of the cropped images is and there are 101 329 images in total. Since the first and second cameras are positioned at a narrow passageway, there are much fewer images from these cameras than from the third camera, where there are multiple exits and the cows tend to linger longer in this area, generating more images. To test the method provided in [3], this dataset is split in the same way as OpenSetCows2020, i.e., the images are split into seed and query sets, in a ratio of 90%/10%. Given the sheer size of the dataset and the intensive testing presented in this paper, this dataset is thinned out to avoid the training and testing processes taking too long. For this reason, the dataset is reduced to a total of only 15,736 images and the distribution 90%/10% is retained. To achieve this, up to 10 random images per cow, per camera and per day were selected where possible. If fewer than 10 images were available, all were retained. This ensured that no cows, cameras or days were excluded, while still preserving the natural class imbalance observed in the OpenSetCows2020 dataset. The seed set contains 14,178 images, with a minimum of 54 and a maximum of 189 images and an average of 158 images per cow. The query set then contains a total of 1558 images, with each cow having between 6 and 21 images, with an average of 17 images.
To the best of our knowledge these datasets are the only publicly available collections of top-down images of individually labeled cows, where each cow has a unique ID and all images corresponding to that individual are grouped under that class. OpenSetCows2020 contains mainly indoor and drone images captured with fixed cameras under controlled conditions, while MultiCamCows2024 contains large-scale surveillance images from multiple cameras in a farm environment, capturing variations in lighting and corridor layout over several days.
A concise table with the metadata of the two datasets used is shown in Table 1. A bar plot showing number of images per split in both datasets is shown in Figure 1, while the distribution of images per cow class is shown in Figure 2.

Table 1.
Comparison of the OpenSetCows2020 and MultiCamCows2024 datasets.
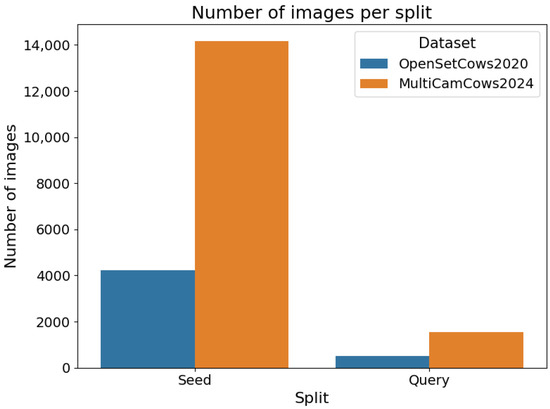
Figure 1.
Seed and query splits for OpenSetCows2020 and MultiCamCows2024 datasets.
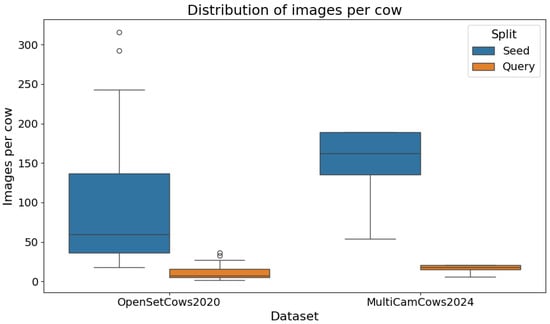
Figure 2.
Distribution of images per class in OpenSetCows2020 and MultiCamCows2024 datasets.

Figure 3.
Representative images for the OpenSetCows dataset.

Figure 4.
Representative images for the MultiCamCows dataset.
4. Method
In this work, the re-identification neural network proposed in [3] is used. The aim of this method is to distinguish individual cows based on the detected regions containing cattle, including those not seen during training, without manual labeling or retraining. This is achieved through metric learning, where a mapping from images into a class-distinguishing latent space is the key idea. Such a latent space contains feature vectors that describe images, so-called embeddings. One or more embeddings are created for each individual cow. The embeddings created from the images of all cows form an embedding set that is used to recognize individual cows. A cow represented by a query image is identified by comparing the embedding generated by that image with the embeddings in said embedding set. The result is that the query image is assigned to the cow represented by the embedding from the embedding set that is most similar to the embedding generated from the query image. The similarity between embeddings is defined by their distance in latent space, hence the term metric learning. This approach also reduces the dimensionality of the image space () to a latent space of dimensionality of , where n is the vector length. During training, the neural network with a ResNet50 backbone learns to generate these embeddings such that images of the same cow generate similar vectors, while images of different cows generate vectors that are further apart in the latent space. All input images were resized to 244 × 244 pixels, and training was performed with a batch size of 32 randomly shuffled samples. Optimization employed stochastic gradient descent (SGD) with the hyperparameters specified in Section 6, and no learning rate scheduling was applied. To achieve the desired separation in the latent space, a type of triplet loss function is used where each embedding (anchor) is compared to a positive (embedding of the same cow) and a negative (embedding of a different cow) example. The type of triplet loss function used is called reciprocal triplet loss and its formula is given by:
In [26], the authors show improvements in open-set recognition with the inclusion of a SoftMax term in the triplet loss formulation. The SoftMax term is given by:
Finally, in [3], the authors combined the two terms in (1) and (2) and proved a further improvement in open-set recognition. The combined term is given by:
where is a constant weighting hyperparameter and its value is , as proposed in [26]. The loss function defined by (3) is used for all results in this paper.
To make the triplet loss and thus the reciprocal triplet loss effective during training, it is not preferable to choose triplet pairs where the positive and negative examples are already dissimilar. In most cases, triplet loss is most effective when choosing hard negative pairs. These pairs are defined as triplets that are not in the correct configuration, i.e., when the anchor-negative similarity is greater than the anchor-positive similarity [27]. Pairs that are not hard triplets are called easy triplets. The choice of the triplet to be used during training is called triplet mining, and a mining strategy is often required to increase effectiveness during training. In [3], the authors chose the “batch hard” online mining strategy proposed in [28] for all tested loss functions to avoid costly offline search before training. This formulation selects overall moderate triplets as they are the hardest examples within each mini-batch. In practice, this means that for each anchor in the batch, the hardest positive (the most dissimilar image of the same cow) and the hardest negative (the most similar image of a different) are selected to form triplets. This ensures that the network learns from the hardest examples in each batch.
Minimizing the distance to a positive example and maximizing the distance to a negative example produces embeddings that are distinct from each other and from their own clusters. A simple clustering algorithm can then be used to classify the inputs, with each cluster representing a single individual. To increase the robustness of the method and reduce overfitting, image augmentation was used, specifically Albumentations [29]. This is done by applying various transformations such as rotations, flips, brightness adjustments or adding noise. Specifically, the following augmentations were used in this work, all with a probability of 0.5:
- translation with a maximum factor of 0.05,
- scaling with a maximum factor of 0.05,
- rotation with a maximum angle of 15° and
- color shift with a maximum value change of 15 for each color
This augmentation step, which is not applied in [3], increases the size of the training dataset by creating modified versions of the images, which improves the performance of Deep Convolutional Neural Networks. Default ranges for these transformations were applied, consistent with standard practices in image-based CNN training. In addition, the images were normalized to the ImageNet [30] standard for both training and testing.
5. Evaluation Strategy
In [3], the neural network is trained to generate embeddings using a set of images of cows. The cows used for training are referred to as known cows, while the cows used for testing that were not seen during training are referred to as unknown cows. To investigate the influence of the ratio of known to unknown cows on the performance of the method, the authors carried out experiments with different known-unknown splits: 10-90, 20-80, 30-70, 40-60, 50-50, 67-33, 75-25, 83-17 and 90-10. With an increasing percentage of unknown cows, an increasingly open problem is reached. Unknown cows are randomly selected and 10 repetitions of each ratio are randomly generated to obtain a more accurate picture of model performance at that ratio of known to unknown cows. This choice of 10 repetitions, following the methodology of [3], allows for variance stabilization across splits, and provides a practical balance between robustness of evaluation and computational cost. For OpenSetCows2020, overlap in background and lighting is relatively limited, as some cows were recorded indoors with fixed cameras while others were captured outdoors from UAV footage. For MultiCamCows2024, background, lighting and time of acquisition are largely consistent, as all cows are observed across multiple cameras and days within the same farm environment.
To address the limitations of previous approaches, which often relied heavily on training data and did not adequately test generalization, this paper introduces a different testing methodology. In previous work, methods were often evaluated using data, from known and unknown cows, already seen during training, which can skew results and obscure the ability of the system to generalize to new individuals. In contrast, our goal is to simulate real-world conditions where the cow re-identification system may encounter new individuals, unseen environments or redundant data. For this reason, the terms seed images and query images are introduced. Seed images (Seed) are images of cows that are used by the network to generate embeddings that together form the embedding set. To investigate the effect of the number of seed images per identity on re-identification performance, experiments were conducted with 1, 2, 3, 5, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90 and all available images per cow. Query images (Query) are images of cows from which the network generates embeddings and places them in the latent space for comparison. The metrics are then calculated based on the cosine distance between the query embedding and the seed embeddings, using K-nearest neighbors (KNN). Each seed embedding is treated individually, rather than averaging embeddings per identity. This grouping algorithm was used by the authors of [3] and is also used in this work. In KNN, classification is based on a majority vote among the k nearest neighbors in the embedding space, where the predicted class corresponds to the most frequently occurring label among these neighbors. In this work, a value of is used, as this is a standard choice in the literature for re-identification tasks, providing a balance between robustness to noisy embeddings and sensitivity to individual seed images. Using this algorithm, the embedding of the query is classified and the predicted identity is compared with the ground-truth label to calculate the following classification metrics: accuracy, precision, recall and F1 score. As both datasets used in this work show class imbalance and to treat all classes equally, macro metrics were selected for calculation, with the exception of accuracy, for which both micro and macro metrics were calculated. Macro metrics are calculated by first calculating the metric separately for each class based on individual query images, and then averaging these values across all classes, giving each class the same weight regardless of the number of instances.
The images of both known and unknown cows are divided into two subsets: the seed subset and the query subset. The system is trained on known cows from the seed subset to generate embeddings that are then used in the test phase to re-identify individual cows using KNN. Figure 5 illustrates the distribution of seed and query images across known and unknown cow individuals. The test phase consists of four test variants, which are described below. In each variant, the seed subset is used to generate seed embeddings, while the query subset is used to generate query embeddings. Depending on the test variant, seed and query images of known cows, unknown cows or both are used. Each variant represents a different type of real-world situation in which the considered may be deployed:
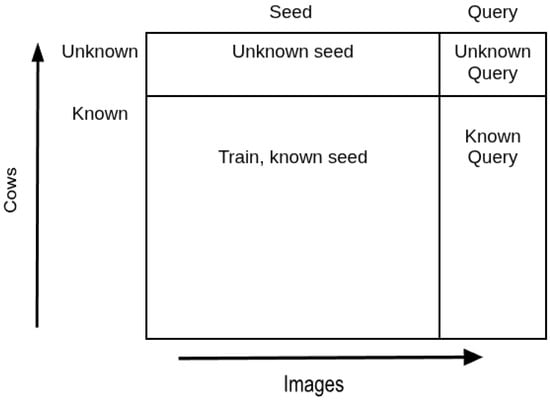
Figure 5.
Known, unknown, seed and query images distribution across cows.
- Variant 1: First deployment on a farmBoth known and unknown cows appear in the seed and query sets. The system has seen some cows during training (known cows), but not all (unknown cows). This reflects a typical scenario where the farm contains both previously observed and newly introduced cows, requiring the system to identify both familiar and unfamiliar individuals.
- Variant 2: Deployment in a different barn within the same farmNeither the seed nor the query cows were seen during training. The environment remains similar, including lighting, background and barn layout. This tests the system’s ability to generalize to completely new cows while leveraging familiar surroundings to maintain accuracy.
- Variant 3: Adding new cows to an existing deploymentThe seed set includes both previously known cows and newly added cows, while the query set contains only the new cows. This scenario evaluates the system’s ability to incorporate new individuals into its knowledge base and accurately identify them over time.
- Variant 4: Deployment on a different farmTraining is performed on one dataset (e.g., MultiCamCows) and testing on another (e.g., OpenSetCows), with roles switchable. Both seed and query sets consist of unknown cows, and environmental conditions differ, including lighting, camera setup and background. This variant assesses the system’s robustness and ability to generalize across farms and domains.
6. Results
In this work, for each ratio of known to unknown cows, and for both datasets, a new model was trained. Furthermore, each training was cross validated 10 times, and the best model from 100 training epochs was saved for each fold. Then, each model was tested using testing variants proposed in Section 5, and the results are averaged across folds. Training hyperparameters are visible in Table 2. Training was done on 3 GPUs in parallel, with splits 10-90, 20-80, 30-70, 40-60 on Nvidia RTX 4000 ADA generation, splits 87-13 and 90-10 on another Nvidia RTX 4000 ADA generation and the ratios 50-50, 63-37 and 75-25 on Nvidia GeForce RTX 4060 Ti graphics card. Total training time for both datasets and all folds, as well as for testing all variants, was 92 h. The computational footprint of the models is shown in Table 3. Values are consistent across all dataset splits and folds.
Table 2.
Training hyperparameters.
Table 3.
Computational footprint of the trained models on MultiCamCows2024 and OpenSetCows2020.
Regarding training on MultiCamCows2024 dataset, the network is trained on random images from the thinned out version in order to have a more robust network which has access to many different images. This means that images are chosen randomly, and thus images from the same sequence and day could appear in both seed and query sets. For this reason, during testing, the dataset has a different distribution: the first available day for each cow was chosen to be in the query set (because some cows are not seen every day), while the rest go into seed set. This way, it is ensured that there is no data leakage, and no cow images from the same sequence, day or camera could appear in both seed and query for unknown cows. For known cows, however, data leakage could not be avoided. Nevertheless, more realistic results are obtained for variants 2, 3 and 4.
Since this is a multi-class classification and having an imbalanced dataset, for every model and every testing variant, the following macro metrics were calculated: accuracy, precision, recall and F1 score, as well as micro accuracy. Macro metrics first calculate metrics for each class, and then averages them out across all classes thus giving equal weight to each class, regardless of how many instances an individual class has.
Figure 6 shows the macro accuracy and F1 score for Variant 1 on both datasets. Variant 1 reflects a deployment scenario in which the system encounters a mixture of known and unknown cow identities, simulating the first deployment on a farm. In this variant, both the seed and query sets contain images of cows that were seen during training (known) and cows that were not seen during training (unknown). The higher the ratio of known to unknown cows, the higher the accuracy and F1 values. In addition, for a higher ratio of known to unknown cows, fewer seed images are required to achieve effective identification, as can be seen in all Figures in Figure 6. Splits 90-10, 83-17 and 75-25 all achieve >90% in both accuracy and F1 scores with only 3 seed images and do not show much improvement after 10 seed images. In contrast, a lower ratio of known to unknown images shows that not even 90% is achieved even when using all seed images. The discrepancy between the lower ratio splits is even larger for the MultiCamCows dataset, suggesting that the greater number of cows and increased visual variability across images reduce the overall performance of the model. Performance stagnates after 10 seed images because the model has already experienced enough variation between cows to generate stable and representative embeddings for each identity. Since each additional seed image requires manual labeling effort, using more than 10 for higher known to unknown splits is unnecessary and only increases labor costs with a marginal increase in performance. Variants 2 and 3 provide an assessment of the system’s generalization ability, as they focus on the case where the system must recognize or distinguish previously unknown identities.
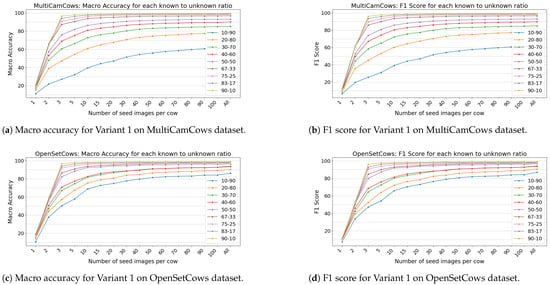
Figure 6.
Macro accuracy and F1 scores for testing Variant 1 on both datasets: (a) MultiCamCows macro accuracy, (b) MultiCamCows F1 score, (c) OpenSetCows macro accuracy and (d) OpenSetCows F1 score. The legend shows different known–unknown splits.
To better understand the causes of lower performance in low known–unknown splits, we examined the misclassifications per class. For splits with many unknown cows, most errors occur for cows that the model did not see during training, while environmental factors such as lighting and camera angle are consistent. Misclassifications are more likely when unknown cows have similar patterns to known cows. This suggests that model confusion is primarily due to visual similarity rather than other factors in the dataset.
Table 4 and Table 5 show the performance metrics using all available seed images for the three testing variants in different dataset splits. As expected, the highest performance is achieved with the 90-10 split for both datasets, highlighting the advantage of training with a larger proportion of known cows. The results show a significant difference in performance between the 10-90 and 90-10 splits, highlighting the challenge of re-identification when only limited training data is available. For practical use in real-world scenarios, it is desirable to include as many known cows as possible in the training to maximize identification accuracy. However, such a high ratio of known cows is often impractical on large farms due to logistical and resource constraints. A high ratio of known to unknown cows can be achieved by regularly retraining the network when new individuals are added to the farm. However, maintaining a high ratio of known to unknown cows requires more frequent retraining as the number of new cows increases, which can become resource intensive over time. Based on the observed results, a split of 30-70 offers an acceptable compromise between performance and feasibility, providing robust accuracy while being realistic for use in commercial farming environments.
Table 4.
Performance metrics for MultiCamCows dataset across three variants using all seed images.
Table 5.
Performance metrics for OpenSetCows dataset across three variants using all seed images.
Figure 7 and Figure 8 illustrate the performance metrics for both datasets under test Variants 2 and 3. For the OpenSetCows dataset, the difference in performance between Variants 1 and 2 is marginal, suggesting that the model maintains strong generalization even when unknown cows are introduced during testing. In contrast, the MultiCamCows dataset shows a more gradual increase in performance across the different dataset splits, suggesting that a larger number of unknown classes in the query set affects generalization more strongly. This effect is particularly pronounced when the dataset is split into 10-90 cows, where only a small subset of cows are available during training, making it more difficult to identify new cows.
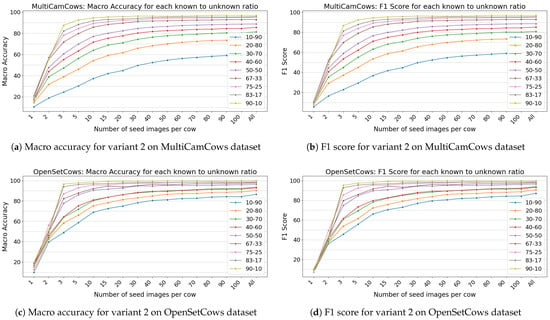
Figure 7.
Macro accuracy and F1 scores for testing variant 2 on both datasets.
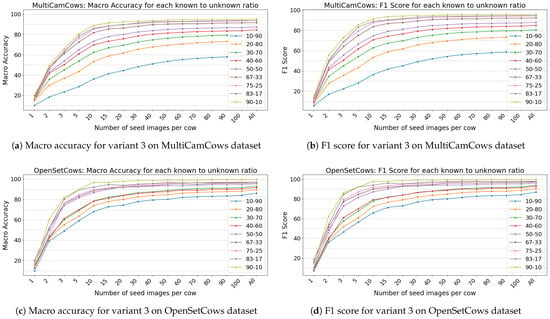
Figure 8.
Macro accuracy and F1 scores for testing variant 3 on both datasets.
As expected, the lowest performance is observed in Variant 3, which simulates the realistic scenario of new cows being added to a farm. In this variant, the query set consists exclusively of unknown cows (i.e., cows that the model has not seen during training), while the seed set contains both known and unknown cows. Consequently, the number of seed images becomes a crucial factor for the identification performance. In contrast to Variant 1, where the model has prior knowledge of all query cows, Variant 3 relies entirely on the discriminative power of the embedding space and the diversity of the seed examples in KNN-based classification. A larger number of seed images increases the chance of capturing representative features of unknown cows, which improves similarity detection and reduces misclassifications.
Interestingly, while the general trend shows that performance increases with a larger number of seed images, there is no sharp inflection point, suggesting that yield decreases beyond a certain threshold. However, only at 10 seed images does the model consistently exceed 90% accuracy at higher dataset splits, emphasizing the importance of adequate visual coverage for robust re-identification on open datasets.
A particularly notable case is the 10-90 split for the OpenSetCows dataset under variant 3. Although the model was trained on only 9 cows, it achieves an accuracy of 86.09% when all available images are in the seed set. This shows that the model is able to generalize effectively to unknown identities, provided that a sufficiently diverse and representative dataset is available. These results emphasize the critical role of the number and diversity of seed images in open identification scenarios, especially in dynamic agricultural environments where new animals are frequently introduced.
The Table 6 and Table 7 show the mean values together with the corresponding standard deviations. For reasons of readability, not all numbers of the seed images are included. Examination of the standard deviations across all numbers of seed images shows that the variability is greatest at lower numbers of seed images, while it stabilizes at numbers above 20. This pattern suggests that the model’s predictions are less consistent when fewer seed images are available, reflecting a higher tendency to guess. Mean values and their corresponding standard deviations for all splits are shown in Table A1 and Table A2 in the Appendix A.
Table 6.
F1 score (mean ± std) for 90-10 split on MultiCamCows dataset.
Table 7.
F1 score (mean ± std) for 90-10 split on OpenSetCows dataset.
Table 8 and Table 9 show the evaluation results for test Variant 4, in which the robustness of the system is examined when it is trained on one farm and used on another farm and thus its generalization to previously unknown environments and completely different cattle populations is tested. The results show a clear trend: increasing the number of cows and training images consistently improves performance in this cross-farm environment. For the MultiCamCows dataset, performance only exceeds 90% when at least 60 seed images are used. This emphasizes the importance of sufficient data diversity and appropriate selection of the number of seed images.
Table 8.
Evaluation metrics for variant 4 (trained on MultiCamCows dataset, tested on OpenSetCows dataset).
Table 9.
Evaluation metrics for variant 4 (trained on OpenSetCows dataset, tested on MultiCamCows dataset).
However, the results for the OpenSetCows dataset are significantly lower for all metrics. In particular, no metric reaches 65% at any seed number and only the macro precision exceeds 60%. This suggests that while the system can occasionally predict certain cows correctly, it struggles to achieve consistent performance across all cows. These results indicate that the current system has limited ability to generalize to the OpenSetCows domain. This suggests that further methodological improvements are needed to deal with the variability introduced by new individuals and environments.
The asymmetric, cross-farm performance can be attributed to differences in the size and variability of the dataset. Training on the smaller OpenSetCows dataset provides limited intra-class variation and fewer cow identities, making generalization to the larger and more diverse MultiCamCows dataset difficult. In contrast, training on MultiCamCows allows the model to learn richer embeddings, that generalize better to the simpler OpenSetCows dataset. This shows that the cross-farm generalization is strongly influenced by the number of cows, the image diversity and the variability of visual patterns. Performance could potentially be improved by techniques that make the features of the model more consistent across farms — for example, by normalizing embeddings or adjusting training so that images from different farms produce similar representations. These performance asymmetries have practical implications: farms with fewer or less diverse training images may have lower identification accuracy, highlighting the need for additional seed images, periodic retraining or methods to reduce differences between farms to ensure reliable performance in new environments.
7. Conclusions
This study evaluated the robustness and generalization ability of a cattle re-identification system in a series of realistic deployment scenarios modeled as four testing variants:
- Variant 1 simulates the initial deployment of the system on a farm, where it was also trained. Both the seed set (reference images) and the query set contain a mixture of cows seen during training (known) and unknown cows. This reflects a common real-world environment where some cows are already known to the system and others are newly introduced.
- Variant 2 represents a change within the same farm, e.g., moving the system to a different barn. In this case, neither the seed nor the query cows were seen during training, but the environment remains similar. This tests how well the system generalizes to new individuals under familiar conditions.
- Variant 3 reflects incremental deployment, where new cows are gradually introduced to an active system. The seed set contains both known and unknown cows, while the query set contains only the newly introduced cows. In this way, the ability of the system to recognize new individuals over time is evaluated.
- Variant 4 tests cross-farm generalization by training on one farm and evaluating on another farm with different environment, light and camera setups. All cows in the seed and query sets are not seen during training. This is the most challenging scenario as it combines both identity and domain shifts.
While the system performs well in Variant 1, achieving over 99% accuracy where the conditions are the same as in training, the performance in variants 2, 3 and 4 deteriorates significantly under the changed conditions, especially in Variant 4 when trained on the OpenSetCows dataset, where it drops to 55.45%. The need for a large number of seed images to ensure high accuracy poses a major challenge in practice. For example, Variant 3 requires at least 10 seed images per cow to achieve 90% accuracy, while Variant 4 requires around 60 seed images to achieve similar performance when trained on MultiCamCows dataset.
This heavy reliance on extensive annotated reference data limits the usability of the system on commercial farms where rapid deployment and minimal manual labeling are critical. Furthermore, the macro precision, recall and F1 scores of the system in Variant 4 evaluated with the OpenSetCows dataset rarely exceed 50–55%. These results highlight the current limitations of cross-domain generalization and the need for improved methods that can perform reliably with fewer annotated (seed) images and in different deployment situations.
The study also provides a novel evaluation framework, incorporating a realistic testing protocol that systematically assesses the impact of seed images and evaluates performance across different deployment variants, offering insights into practical deployment scenarios. Future work should focus on methods to reduce annotation requirements and improve generalization, such as few-shot learning, incremental learning or domain-adaptation techniques.
Author Contributions
Conceptualization, M.D., R.C. and E.K.N.; methodology, A.B., M.D., R.C. and E.K.N.; software, A.B.; validation, A.B., M.D.; formal analysis, A.B., M.D., R.C. and E.K.N.; investigation, A.B. and M.D.; data curation, A.B. and M.D.; writing—original draft preparation, A.B. and M.D.; writing—review and editing, M.D., R.C. and E.K.N.; visualization, A.B. and M.D.; supervision, R.C. and E.K.N.; project administration, E.K.N.; funding acquisition, E.K.N. All authors have read and agreed to the published version of the manuscript.
Funding
This reserach was funded by European Uninon—NextGenerationEU within the project “NEXT GENERATION ANIMAL PRODUCTION” (grant number NPOO.C3.2.R3-I1.04.0141).
Data Availability Statement
Available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A
Tables showing F1 score for both datasets with the added standard deviation for all values.
Table A1.
F1 score for MultiCamCows dataset across three variants using selected seed images. Values are shown as mean +/− standard deviation.
Table A2.
F1 score for OpenSetCows dataset across three variants using selected seed images. Values are shown as mean +/− standard deviation.
References
- Yu, P.; Burghardt, T.; Dowsey, A.W.; Campbell, N.W. Holstein–Friesian Re-Identification using Multiple Cameras and Self-Supervision on a Working Farm. Comput. Electron. Agric. 2024, 237, 110568. [Google Scholar] [CrossRef]
- Wang, B.; Li, X.; An, X.; Duan, W.; Wang, Y.; Wang, D.; Qi, J. Open-Set Recognition of Individual Cows Based on Spatial Feature Transformation and Metric Learning. Animals 2024, 14, 1175. [Google Scholar] [CrossRef] [PubMed]
- Andrew, W.; Gao, J.; Mullan, S.; Campbell, N.; Dowsey, A.W.; Burghardt, T. Visual identification of individual Holstein–Friesian cattle via deep metric learning. Comput. Electron. Agric. 2021, 185, 106133. [Google Scholar] [CrossRef]
- Lennox, M.; McLaughlin, N.; Martinez-del Rincon, J. Visual re-identification within large herds of holstein friesian cattle. In Proceedings of the Visual Observation and Analysis of Vertebrate and Insect Behavior, Montreal, QC, Canada, 21 August 2022. [Google Scholar]
- Andrew, W.; Hannuna, S.; Campbell, N.; Burghardt, T. Automatic individual holstein friesian cattle identification via selective local coat pattern matching in RGB-D imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; Volume 9, pp. 484–488. [Google Scholar] [CrossRef]
- Zhao, K.; Jin, X.; Ji, J.; Wang, J.; Ma, H.; Zhu, X. Individual identification of Holstein dairy cows based on detecting and matching feature points in body images. Biosyst. Eng. 2019, 181, 128–139. [Google Scholar] [CrossRef]
- Shen, W.; Hu, H.; Dai, B.; Wei, X.; Sun, J.; Jiang, L.; Sun, Y. Individual identification of dairy cows based on convolutional neural networks. Multimed. Tools Appl. 2020, 79, 14711–14724. [Google Scholar] [CrossRef]
- Shojaeipour, A.; Falzon, G.; Kwan, P.; Hadavi, N.; Cowley, F.C.; Paul, D. Automated muzzle detection and biometric identification via few-shot deep transfer learning of mixed breed cattle. Agronomy 2021, 11, 2365. [Google Scholar] [CrossRef]
- Li, S.; Fu, L.; Sun, Y.; Mu, Y.; Chen, L.; Li, J.; Gong, H. Individual dairy cow identification based on lightweight convolutional neural network. PLoS ONE 2021, 16, e0260510. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Masullo, A.; Burghardt, T.; Damen, D.; Perrett, T.; Mirmehdi, M. Who goes there? exploiting silhouettes and wearable signals for subject identification in multi-person environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Wang, Y.; Xu, X.; Wang, Z.; Li, R.; Hua, Z.; Song, H. ShuffleNet-Triplet: A lightweight RE-identification network for dairy cows in natural scenes. Comput. Electron. Agric. 2023, 205, 107632. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. Adv. Neural Inf. Process. Syst. 2016, 29, 1857–1865. [Google Scholar]
- Dubourvieux, F.; Lapouge, G.; Loesch, A.; Luvison, B.; Audigier, R. Cumulative unsupervised multi-domain adaptation for Holstein cattle re-identification. Artif. Intell. Agric. 2023, 10, 46–60. [Google Scholar] [CrossRef]
- Gao, J.; Burghardt, T.; Andrew, W.; Dowsey, A.W.; Campbell, N.W. Towards Self-Supervision for Video Identification of Individual Holstein–Friesian Cattle: The Cows2021 Dataset. arXiv 2021, arXiv:2105.01938. [Google Scholar]
- Sharma, A.; Randewich, L.; Andrew, W.; Hannuna, S.; Campbell, N.; Mullan, S.; Dowsey, A.W.; Smith, M.; Hansen, M.; Burghardt, T. Universal bovine identification via depth data and deep metric learning. Comput. Electron. Agric. 2025, 229, 109657. [Google Scholar] [CrossRef]
- Andrew, W.; Greatwood, C.; Burghardt, T. Visual Localisation and Individual Identification of Holstein Friesian Cattle via Deep Learning. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2850–2859. [Google Scholar] [CrossRef]
- Andrew, W.; Greatwood, C.; Burghardt, T. Aerial Animal Biometrics: Individual Friesian Cattle Recovery and Visual Identification via an Autonomous UAV with Onboard Deep Inference. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Venetian Macao, Macau, 4–8 November 2019; pp. 237–243. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Lagunes-Fortiz, M.; Damen, D.; Mayol-Cuevas, W. Learning Discriminative Embeddings for Object Recognition on-the-fly. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2932–2938. [Google Scholar] [CrossRef]
- Xuan, H.; Stylianou, A.; Liu, X.; Pless, R. Hard Negative Examples are Hard, but Useful. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 126–142. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).