Abstract
Deepfake audio refers to speech that has been synthetically generated or altered through advanced neural network techniques, often with a degree of realism sufficient to convincingly imitate genuine human voices. As these manipulations become increasingly indistinguishable from authentic recordings, they present significant threats to security, undermine media integrity, and challenge the reliability of digital authentication systems. In this study, a robust detection framework is proposed, which leverages the power of self-supervised learning (SSL) and attention-based modeling to identify deepfake audio samples. Specifically, audio features are extracted from input speech using two powerful pretrained SSL models: HuBERT-Large and WavLM-Large. These distinctive features are then integrated through an Attentional Multi-Feature Fusion (AMFF) mechanism. The fused features are subsequently classified using a NeXt-Time Delay Neural Network (NeXt-TDNN) model enhanced with Efficient Channel Attention (ECA), enabling improved temporal and channel-wise feature discrimination. Experimental results show that the proposed method achieves a 0.42% EER and 0.01 min-tDCF on ASVspoof 2019 LA, a 1.01% EER on ASVspoof 2019 PA, and a pooled 6.56% EER on the cross-channel ASVspoof 2021 LA evaluation, thus highlighting its effectiveness for real-world deepfake detection scenarios. Furthermore, on the ASVspoof 5 dataset, the method achieved a 7.23% EER, outperforming strong baselines and demonstrating strong generalization ability. Moreover, the macro-averaged F1-score of 96.01% and balanced accuracy of 99.06% were obtained on the ASVspoof 2019 LA dataset, while the proposed method achieved a macro-averaged F1-score of 98.70% and balanced accuracy of 98.90% on the ASVspoof 2019 PA dataset. On the highly challenging ASVspoof 5 dataset, which includes crowdsourced, non-studio-quality audio, and novel adversarial attacks, the proposed method achieves macro-averaged metrics exceeding 92%, with a precision of 92.07%, a recall of 92.63%, an F1-measure of 92.35%, and a balanced accuracy of 92.63%.
1. Introduction
In recent years, with the development of deep learning-based speech synthesis and transformation, synthesized speech is now almost indistinguishable from genuine human voices. With the advent of text-to-speech (TTS) systems as well as Voice Conversion (VC) techniques, more natural sounds have been generated, which have potential applications in fields such as accessibility, entertainment, and communication [1]. But they have also enabled bad actors to impersonate particular people in an effort to pull off advanced disinformation campaigns, commit identity theft, and create fake recordings. These advancements obviously pose a risk to media integrity, digital identity, and security in general.
The reliable detection of deepfake audio is therefore of paramount importance for both academic research and industrial deployment. Traditional approaches—whether based on handcrafted acoustic features or simple spectral comparisons—struggle to generalize its capabilities against the complex variations introduced by state-of-the-art generative models. Moreover, the requirement for real-time or low-latency inference often precludes the use of highly complex architectures in practical scenarios [2].
In this paper, a strong framework for deepfake audio detection is presented, and it uses complementary representations of two state-of-the-art self-supervised learning (SSL) models: HuBERT-Large and WavLM-Large. Recent studies have shown that SSL-based speech representations generalize well across different languages and attack scenarios, making them particularly suitable for robust deepfake detection tasks [3]. Features from these pretrained models are adaptively fused through an Attentional Multi-Feature Fusion (AMFF) architecture that learns to assign feature attention to each stream with different importance for synthetic speech detection.
As HuBERT introduces noise sensitivity to the vocoder via the induced micro-phonetic artifacts because of the masked-unit prediction objective, and as WavLM focuses on speaker-specific and paralinguistic cues with extra denoising and multi-speaker supervision, they contribute complementary evidence necessary for robust deepfake audio detection. Based on these complementary representations, the method fuses these representations to increase the discriminative power of the following classifier. The fused features are later fed into a NeXt-Time Delay Neural Network (NeXt-TDNN) structure, enriched with an Efficient Channel Attention (ECA) module.
The core backbone structure of NeXt-TDNN consists of TS-ConvNeXt blocks, multi-layer feature aggregation, and attention statistics pooling. In the proposed method, it is integrated with an Efficient Channel Attention (ECA) module, which adaptively recalibrates channel saliency without significant computational cost. Additionally, the NeXt-TDNN unit is efficient for modeling long-term temporal dependencies, and the ECA module adaptively enhances inter-channel feature selection to make the difference between original and fake audio more distinguishable.
Extensive experiments on several public deepfake audio datasets demonstrate that our proposed method achieves state-of-the-art detection performance while maintaining good computational efficiency, which is beneficial for online operations.
The main contributions of this paper are as follows:
- Embeddings extracted from the 8th Transformer layer of the pre-trained HuBERT-Large and WavLM-Large are employed. These embeddings capture complementary frequency- and time-domain information, enabling strong cross-domain generalization due to the extensive pre-training of the models.
- An AMFF-based fusion approach is proposed, which integrates HuBERT’s sensitivity to microphonetic cues with WavLM’s speaker-specific and paralinguistic representations. This fusion effectively unifies acoustic perspectives from both the frequency and time domains, significantly enhancing discriminative performance.
- The classification stage is enhanced by employing a NeXt-TDNN network augmented with an Efficient Channel Attention (ECA) module, further improving deep fake audio detection accuracy.
- We demonstrate that the proposed system outperforms current state-of-the-art baselines on the ASVspoof 2019 LA, ASVspoof 2019 PA, and ASVspoof 2021 LA benchmarks.
The rest of this paper is structured as follows. In Section 2, deepfake audio generation and detection techniques in related works are introduced. Section 3 presents the architecture of our SSL-based feature extraction, AMFF fusion, and enhanced NeXt-TDNN classifier. Section 4 describes the experimental setup and a performance comparison between the proposed approach and the state-of-the-art algorithms. Section 5 gives the discussion about the study. Finally, Section 6 concludes and discusses the results and the future direction of study in deepfake audio detection.
2. Related Work
In the literature, research on audio deepfake detection can be categorized into three principal groups: (i) handcrafted acoustic feature-based methods; (ii) end-to-end model-based methods; (iii) more recently, self-supervised learning (SSL) speech model-based methods. Below, representative studies from each group and their key contributions are summarized.
2.1. Handcrafted Acoustic Feature-Based Methods
Early counter-measures convert speech into cepstral descriptors and apply generative or margin-based classifiers. One of the pioneering studies in this field extracted audio representations using the Constant-Q Cepstral Coefficients (CQCC) approach and classified them with a Gaussian Mixture Model (GMM) [1].
DNN-FBCC replaced the fixed mel filter bank with a trainable bank, lowering EER by 26% relative to LFCC-GMM and bridging manual and learned front-ends [4].
Alzantot et al. (2019) [5] employed a ResNet-based framework to systematically benchmark Log-STFT, MFCC, and Constant-Q Cepstral Coefficient (CQCC) representations, reporting the performance metrics for each feature set separately.
Leveraging a feature genuinization scheme, Wu et al. [6] introduced an LCNN architecture, whereas Wang et al. [7] evaluated the efficacy of MFCC, spectral, and Constant-Q Transform (CQT) representations within a DenseNet framework. Xue et al. [8] implemented a multimodal scheme that concatenates LFCC descriptors with facial information within an SE-DenseNet backbone [9], subsequently applied an A-softmax margin for classification. Ref. [10] assessed the complementary use of Multi-scale Permutation Entropy (MPE) and LFCC representations, deploying both SENet and LCNN architectures. Furthermore, Chaiwongyen et al. [11] introduced an approach that integrates pathological features (PF) with Mel-spectrogram inputs, leveraging a ResNet18 network. The recent Two-Path GMM-ResNet projects per-Gaussian scores onto a 2D map and refines them with ResNet/SENet blocks, reducing min-tDCF by up to 95% on ASVspoof19 [12].
2.2. End-to-End Model-Based Methods
Abandoning explicit feature engineering, this line feeds the 1D waveform directly to deep neural network back-ends.
RawNet pioneered raw-waveform anti-spoofing with a CNN+GRU backbone, achieving 3.8% EER and popularizing end-to-end learning [13]. RawNet2 introduced inter-frame normalization and SE-attention, pushing EER to 1.06% on ASVspoof-19 LA [14]. RawGAT-ST embeds spectro-temporal relations via a graph-attention layer, yielding a further 12% relative gain over RawNet2 [15]. RawNetLite combines domain-mix training, codec augmentation, and focal loss, reaching 0.25% EER in-domain while remaining portable to mobile hardware [16].
2.3. Self-Supervised Learning (SSL) Model-Based Methods
Leveraging large self-supervised encoders pretrained on thousands of hours of speech, these methods exhibit unmatched open-world robustness.
One of these methods, HuRawNet2, fuses HuBERT layers with a RawNet2 back-end, delivering 2.1% EER on the ADD-23 benchmark and illustrating hybrid SSL + raw-waveform success [17]. A wav2vec 2.0 + Variational-Information-Bottleneck transfer approach compresses latent speech representations, cutting min-tDCF by 47% in low-resource settings [18]. An ensemble of four WavLM models, fine-tuned and fused late, secured 6.56%/17.08% EER on the two ASVspoof-5 evaluations, topping the 2024 challenge leaderboard [19]. AntiDeepfake post-training adapts wav2vec 2.0 and HuBERT on 56 kh genuine + 18 k h artifact speech across 100 + languages; even zero-shot, the models score <3% EER [20].
In light of the findings in the literature, this study proposes a novel approach for detecting speech spoofing, which enhances generalization by attentively fusing multiple self-supervised learning (SSL) representations and employing an improved NeXt-TDNN architecture. Recent studies demonstrate that pretrained SSL models yield superior performance in audio forgery detection, as their mid-level embeddings effectively capture both phonetic-level artifacts and higher-order contextual cues. Motivated by this, our method leverages HuBERT-Large and WavLM-Large mid-level embeddings, which are fused through an Attentional Multi-Feature Fusion (AMFF) strategy to strengthen discriminative capacity. Moreover, although the NeXt-TDNN model has been widely adopted in speaker verification, its utility for deepfake audio detection has not been systematically explored. In this work, the NeXt-TDNN backbone is extended with an Efficient Channel Attention (ECA) layer, which enhances inter-channel feature selection and makes the differences between genuine and spoofed audio more distinguishable.
3. Proposed Method
The objective of this study is to propose a novel method capable of distinguishing original audio recordings from synthetically generated ones. To this end, the raw time-domain waveform from the input utterance is first transformed into frame-level acoustic representations by pretrained self-supervised learning (SSL) models. In particular, two distinct embeddings are extracted: a 1024-dimensional vector from the HuBERT-Large model and a 1024-dimensional vector from the WavLM-Large model, both pretrained SSL architectures, to represent the audio signal in a high-level latent feature space. These embeddings capture the essential “active ingredients” of the signal by encoding phonetic, prosodic, and contextual characteristics that are most informative for discriminating between genuine and synthetic audio. The two embeddings are then concatenated and processed by the AMFF fusion strategy, yielding a single fused 1024-dimensional feature vector. This vector serves as the input to the proposed NeXt-TDNN model with Efficient Channel Attention (ECA), which is trained to classify each utterance. Finally, the network outputs a binary classification score that indicates whether the input is spoofed or bona fide, thereby providing a clear judgment method for audio signal determination.
The general architecture of the proposed method is illustrated in Figure 1. It consists of two main components: (1) multi-fused supervised feature extraction; (2) improved NeXt-TDNN-based classification. The details of each component are provided in the following subsections.
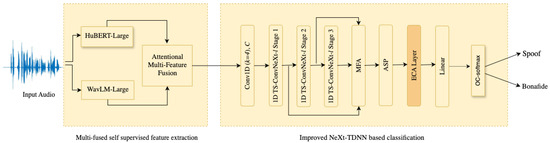
Figure 1.
The overview of the proposed method where raw audio is processed through HuBERT-Large and WavLM-Large feature extractors, fused via attentional multi-feature fusion, and classified by an improved NeXt-TDNN into bona fide or spoof.
3.1. Multi-Fused Supervised Feature Extraction
This part gives the methodology of the feature extraction with three subsections.
3.1.1. Feature Extraction with Pretrained HuBERT-Large Models
HuBERT (Hidden-Unit BERT) is a family of self-supervised speech encoders that combines a strided convolutional feature extractor with a deep Transformer network to predict discrete hidden-unit labels at masked time steps [21]. The main structure is given in Figure 2. X represents the acoustic feature vector produced by the Convolutional Neural Network (CNN) encoder. To obtain the corrupted representation, the feature vectors within the masked intervals are replaced with the corresponding masked embeddings, . This corrupted input, is subsequently processed by the transformer block to estimate the posterior probability for each time frame. More details on the model are as follows.
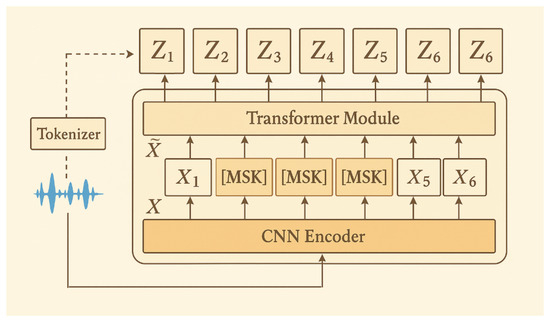
Figure 2.
The HuBERT model architecture.
Given a waveform , the convolutional stem produces a latent sequence
where L is the number of audio samples. HuBERT selects mask-span start indices with probability = 0.08; each span has length = 10. Masked positions are replaced by a learned vector and the Transformer encoder yields contextual representations
Only the masked frames incur Masked Hidden-Unit Prediction (MHUP) loss:
where denotes the cluster ID produced by an offline iterative K-means pipeline, and is a learnable projection.
The clustering procedure during pre-training follows a three-stage, incremental self-labeling scheme:
Concretely, it is applied clustering to MFCCs from the LibriSpeech 960 h corpus, then recluster HuBERT(0) activations with , and finally cluster H.
In the proposed method, the publicly available pretrained HuBERT-Large model is used, comprising 24 Transformer layers with a model dimension of 1024, a feed-forward dimension of 4096, and approximately 316 million parameters. Pretraining was conducted in three stages: first, K-means clustering (K = 100) over MFCCs extracted from the LibriSpeech960h corpus; second, K = 500 over intermediate activations; and third, K = 1000 over further activations from the Libri-Light60kh dataset, all optimizing a masked hidden-unit prediction objective. In the proposed method, embeddings are extracted from the 8th Transformer layer. This choice is grounded in recent empirical evidence showing that mid-level representations, particularly around the 8th–12th layers in large SSL models, achieve the best trade-off between detailed phonetic cues and higher-level contextual semantics for audio deepfake detection. In particular, Kheir et al. (2025) conducted a comprehensive layer-wise analysis of HuBERT and WavLM, and reported that lower-to-mid layers consistently provide the most discriminative features across diverse datasets and attack scenarios [3]. Following these findings, and confirming them with the method’s own preliminary experiments, the 8th layer is adopted as it offers both robust discriminative power and computational efficiency.
3.1.2. Feature Extraction with Pretrained WavLM-Large Model
In this study, the other self-supervised speech representations were extracted from the WavLM model. WavLM is a self-supervised framework for learning noise-robust speech representations from raw waveforms. As shown in Figure 3, it follows a two-stage architecture: (i) a 7-layer convolutional feature encoder that converts the input waveform x into frame-level features X; (ii) a Transformer encoder equipped with Gated Relative Position Bias (GRPB) that refines the sequence after random time-masking [22].
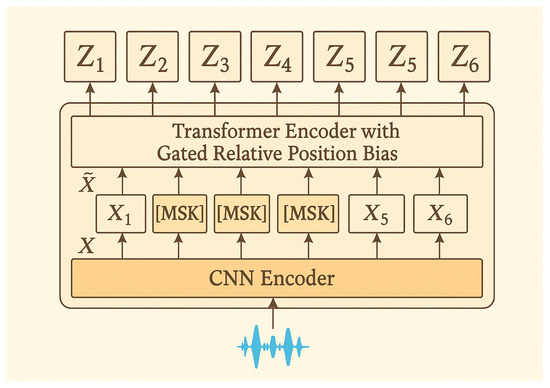
Figure 3.
The WavLM-Large model architecture.
Let denote the query and key at time indices i and j. GRPB augments the scaled dot-product attention with a learned, content-dependent distance term:
where
is the base relative bias for offset , are learned vectors, and is the logistic sigmoid. Equation (2) allows the model to combine positional information with query-dependent gates, yielding sharper and more context-aware attention patterns that benefit downstream tasks such as speaker verification and spoof detection [22].
The WavLM family has three different versions:
- WavLM-Base (95 M parameters, 12 Transformer layers, ),
- WavLM-Base+ (94 M parameters, identical depth but trained longer with more data),
- WavLM-Large (316 M parameters, 24 Transformer layers, , attention heads).
All variants are pre-trained for 400k steps on roughly 94 k h of unlabeled English audio—60 k h LibriLight, 10 k h GigaSpeech, and 24 k h VoxPopuli—using a joint objective that combines masked speech prediction with a denoising task. During pre-training, synthetic background noise or additional speakers are mixed into the input to simulate low-SNR and overlapped-speech conditions, driving the network to learn noise-robust hidden units [22].
The proposed spoof-detection system employs the WavLM-Large configuration. WavLM-Large is pre-trained for 400k steps on approximately 94 k h of unlabeled English audio-60 k hLibriLight, 10 k h GigaSpeech, and 24 k h VoxPopuli—with masked speech prediction and denoising learned jointly [22]. During pre-training, synthetic background noise or additional speakers are mixed into the input to simulate low-SNR and overlapped-speech scenarios, encouraging the network to produce noise-robust hidden units that prove to be beneficial for spoof detection.
The Large configuration comprises Transformer blocks, hidden size , and attention heads, for a total of 316 M parameters.
For feature extraction, the hidden states are pooled from the 8th Transformer layer,
because middle layers strike a balance between low-level acoustics and high-level semantics, a property shown to enhance artifact discrimination in synthetic speech.
3.1.3. Extracted Feature Fusion with AMFF
In the proposed method, the extracted HuBERT-Large and WavLM-Large embeddings are input into one of the AMFF framework’s strategies, the Parallel–Supplementary Weighted Fusion (P–SWF) strategy [23], as presented in Figure 4.
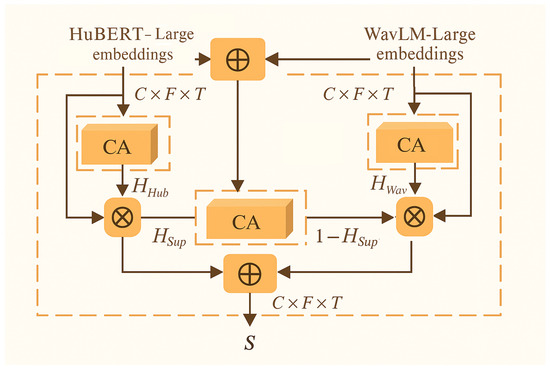
Figure 4.
The fusion strategy used.
Let denote the hidden representations extracted from HuBERT-Large and WavLM-Large, respectively, where B is the mini-batch size, the channel dimension and T the sequence length.
Each 1-D Coordinate Attention (CA) block first performs global average pooling along the temporal axis,
and then computes a channel gate where are learnable weights, is ReLU, and is the sigmoid. The gate is broadcast over time and applied via
Three independent CA modules are instantiated:
The first two refine each stream individually, while the third derives a supplementary gate from their sum:
The final fused tensor is obtained by
where is an all-ones tensor. Equation (11) yields channel-selective weighting: large gate values promote HuBERTLarge, whereas small values favor WavLMLarge.
3.2. Improved NeXt-TDNN Based Classification
In the proposed method, the fused features F are classified with the NeXt-TDNN-based framework, a modernized TDNN that substitutes the Res2Net-SE backbone of ECAPA-TDNN with the two-step ConvNeXt block (TS-ConvNeXt). Figure 5 gives a schematic overview of the NeXt-TDNN with the ECA layer. For computational efficiency, its light variant, TS-ConvNeXt-l, is adopted, which keeps the frame-wise feed-forward sub-module (FFN) unchanged but replaces the multi-scale convolution (MSC) with a single depth-wise temporal convolution of kernel size K.
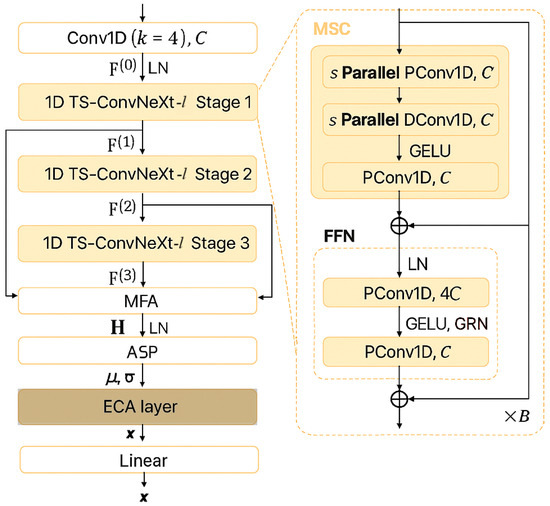
Figure 5.
Improved NeXt-TDNN model with ECA layer.
Given a frame sequence , three TS-ConvNeXt-l stages produce representations
where B denotes the number of blocks per stage and C the channel width. Layer normalization (LN) and global response normalization (GRN) inside each block enhance optimization stability and channel selectivity.
The deepest outputs are concatenated and compressed by a point-wise convolution to (multi-layer feature aggregation, MFA). The temporal statistics are then summarized with attention statistics pooling (ASP): letting ,
where ⊙ is the Hadamard product and is the t-th column of H.
Before projection to the embedding space, an Efficient Channel Attention (ECA) layer is inserted to recalibrate channel saliency without heavy parameter overhead. The ASP statistics are concatenated as , reshaped to and processed by a fast 1-D convolution,
where is the sigmoid, k is an odd kernel size computed from channel width ( = 2, b = 1 in all experiments), and ensures as suggested in [24]. The embedding fed to the classifier is hence
with a trainable projection and .
Using the Additive-Margin Softmax (AM-Softmax) formulation, the system learns embeddings that detect audio spoofing. Let be the j-th class weight normalized to unit length and the angle between and . The loss for a mini-batch of N samples is
where s is a scale (40) and m an angular margin (0.3). This objective enforces a fixed geodesic margin between genuine and counterfeit speech embeddings, yielding calibration-friendly score distributions.
The combination of TS-ConvNeXt-l and ECA provides complementary temporal modeling: depth-wise convolutions capture broad contextual patterns, while channel-wise attention highlights task-relevant information distilled from HuBERT and WavLM features. The Table 1 gives the layer-wise details of the model.

Table 1.
Layer-wise specification of the NeXt-TDNN architecture with default hyper-parameters (depths = , dims = ).
4. Experimental Results
This section presents a thorough examination of the experimental procedures undertaken to assess the efficacy of the proposed methodology. In addition, a comparative performance analysis is conducted to benchmark the proposed approach against contemporary state-of-the-art techniques reported in the existing literature.
The architecture was implemented using the PyTorch 1.8 deep learning library. The Adam optimizer was used for model training with a learning rate of and a batch size of 32. The training continued for 100 epochs, and the model checkpoint with the lowest validation Equal Error Rate (EER) was chosen for final evaluation. All experiments were carried out on a laptop machine with an Intel i7 CPU, 64 GB of RAM, and a GeForce RTX 3060.
4.1. Datasets
The performance of the proposed method was evaluated on three benchmark datasets: the ASVspoof 2019 Logical Access (LA), Physical Access (PA) [25], the ASVspoof 2021 LA [26] and the ASVspoof 5 (Track 1) datasets [27].
Table 2 presents the distribution of spoofed and bona-fide trials in the ASVspoof 2019 LA and PA corpora, together with the ASVspoof 2021 LA corpus and ASVspoof 5 (Track 1). The 2021 LA corpus was released solely for evaluation, providing 137,457 spoofed and 7355 bona-fide trials; this design poses a more challenging cross-corpus generalization scenario, as systems trained on earlier corpora must transfer to unseen spoofing attacks encountered only at test time.
Table 2.
Number of utterances in ASVspoof 2019 LA, ASVspoof 2019 PA, ASVspoof 2021 LA and ASVspoof 5 (Track 1) datasets.
The ASVspoof 2019 LA corpus comprises a comprehensive suite of spoofing-attack algorithms engineered to reproduce a variety of audio-spoofing scenarios, shown in Table 3. These algorithms are classified into three principal groups: text-to-speech (TTS), voice-conversion (VC), and hybrid methods. Hybrid methods integrate both TTS and VC paradigms to further elevate the realism and variety of the generated spoofs.
Table 3.
Overview of spoofing attack techniques in the ASVSpoof 2019 LA dataset.
By using different neural architectures and complex signal-processing pipelines, these methods can produce high-quality impersonations. Overall, the ASVspoof 2019 LA dataset includes 19 attack variants (A01–A19). The training and development subsets include attacks A01–A06, and the evaluation subset includes attacks A07–A19.
Within the evaluation subset of the ASVspoof 2019 LA corpus, attacks A16 and A19 are designated as "known" because they are produced using the identical core algorithms (A04 and A06) encountered in the training and development subsets, although instantiated with different speaker identities and audio samples. In contrast, attacks A10–A15 and A18 are classified as "unknown", since their generative mechanisms do not appear in any of the preceding data. Attacks A07–A09 and A17 occupy an intermediate status of "partially known", as they stem from modified or closely related variants of algorithms that were present during the training and development phases.
The ASVspoof 2019 Physical Access (PA) corpus comprises replay-attack trials recorded with a fixed microphone in a purpose-built acoustic chamber. Each replay instance is defined by two key variables: (i) the separation between the attacker’s loudspeaker and the ASV microphone; (ii) the playback and recording hardware quality. These two factors are jointly encoded as paired labels (e.g., “AA,” “AB,” …, “CB,” “CC”), where the first character denotes the device-microphone distance tier and the second character denotes the combined fidelity class of the playback/recording chain as shown in Table 4.
Table 4.
Replay attack definition in the ASVSpoof 2019 PA dataset.
In the ASVspoof 2021 Logical Access (LA) corpus, only the evaluation partition is included, and an additional transmission-variability factor is introduced to better reflect real-world deployment scenarios. Both bona fide and spoofed utterances are propagated over telephony channels—namely, public switched telephone networks (PSTN) and Voice over IP (VoIP)—and subjected to a variety of codecs, sampling frequencies, and bitrate settings. These diverse channel–codec configurations are systematically indexed from C1 to C7, thereby enabling a comprehensive evaluation of system resilience to mismatches in transmission path and encoding parameters.
Another dataset used for training and evaluating the model is the ASVspoof 5 corpus, which is the fifth edition of the ASVspoof challenge series [27]. The dataset has been designed to advance research on the detection of spoofing, deepfakes, and adversarial attacks against ASV systems. It is incorporated with crowdsourced data from nearly 2000 speakers recorded in diverse acoustic environments beyond studio conditions. The corpus includes spoofed speech generated by 32 different algorithms, covering both conventional and state-of-the-art TTS and VC methods, as well as adversarial attacks. The protocols are organized into seven speaker-disjoint partitions for training, development, and evaluation. In addition, a large-scale support dataset comprising approximately 30,000 speakers has been released to facilitate the development of spoofing algorithms. The number of utterances is shown in Table 2. ASVspoof 5 thus provides a comprehensive and challenging benchmark that not only supports the development of counter-spoofing systems but also promotes progress toward spoofing-robust ASV technologies [27].
4.2. Metrics
For the assessment of the proposed framework’s effectiveness, two standard evaluation criteria are employed: the Equal Error Rate (EER) and the minimum tandem Detection Cost Function (min-tDCF). The EER provides a single-figure summary of verification performance by identifying the operating threshold at which the false acceptance rate (FAR) and false rejection rate (FRR) coincide [25]. Although widely adopted, EER does not fully reflect the interplay between spoof detection and speaker verification in a deployed system. To address this, min-tDCF is also reported, which quantifies the joint cost incurred by errors in both the ASV subsystem and its anti-spoofing countermeasure. By modeling the weighted contributions of false accepts and false rejects across the combined pipeline, min-tDCF offers a more application-relevant measure of overall system robustness.
At a decision threshold , the False Rejection Rate and False Acceptance Rate are defined as follows:
In this context, the classifier’s output score quantifies its confidence: higher values signify a greater probability that the sample is bona fide audio, whereas lower values indicate an increased likelihood of spoofed audio.
To evaluate the proposed method, in addition to the EER and min-tDCF metrics, commonly used machine learning evaluation metrics such as accuracy, precision, recall, and F-measure are not directly suitable due to the class imbalance in these datasets [28]. Since accuracy alone can be misleading, the literature suggests the use of balanced accuracy [29] as well as macro-averaged precision, recall, and F1 metrics [30]. These metrics assign equal weight to both classes, thereby preventing the performance on the minority class (e.g., bona fide) from being masked by the majority class. In this study, the proposed method is also evaluated using balanced accuracy, macro-averaged precision, recall, and F1 metrics. The formulations of these metrics are as follows. Let C denote the number of classes, and represent the confusion matrix values for class c.
Balanced accuracy is defined as the average of recall across all classes:
4.3. Ablation Studies
This section presents performance evaluations of different versions of classification models and fusion techniques. The experiments were carried out on the ASVspoof 2019 LA dataset.
Table 5 presents the results of the first ablation study, in which all deepfake audio detection systems are trained on WavLM embeddings, while the baseline architecture is progressively replaced and lightweight channel attention is incorporated. Using WavLM features, the ECAPA-TDNN baseline achieves an EER of 1.26% and a minimum t-DCF of 0.034. Substituting the backbone with NeXt-TDNN (channel width C = 256, depthwise-conv kernel K = 7, block repetition B = 3) lowers the EER to 0.96% and nearly halves the t-DCF. To investigate parameter efficiency, the light variant, NeXt-TDNN-l, is evaluated, which trims the model to 5.9M parameters yet still surpasses the baseline with an EER of 0.82%. The improved NeXt-TDNN-l with an ECA layer adds only three additional parameters but delivers the best overall performance—an EER of 0.64% while retaining the same minimum t-DCF of 0.020. These results demonstrate that NeXt-TDNN, particularly its lightweight attention-enhanced configuration, offers a more accurate and parameter-efficient alternative to ECAPA-TDNN.
Table 5.
Comparative performance results of NeXt-TDNN version (, , ).
Table 6 compares the baseline NeXt-TDNN-l with its ECA-augmented variant across HuBERT, WavLM, and their fusion using AMFF as feature representations, revealing that the improved NeXt-TDNN-l consistently outperforms the original architecture: with HuBERT inputs, EER falls from 0.86% to 0.63% and min t-DCF from 0.022 to 0.021, while with WavLM inputs, EER drops from 0.74% to 0.64% and min t-DCF from 0.023 to 0.019, confirming the efficacy of Efficient Channel Attention in enhancing discriminative capacity across distinct self-supervised speech features, as also shown in Figure 6.
Table 6.
Comparative performance results of NeXt-TDNN and Improved NeXt-TDNN with ECA.
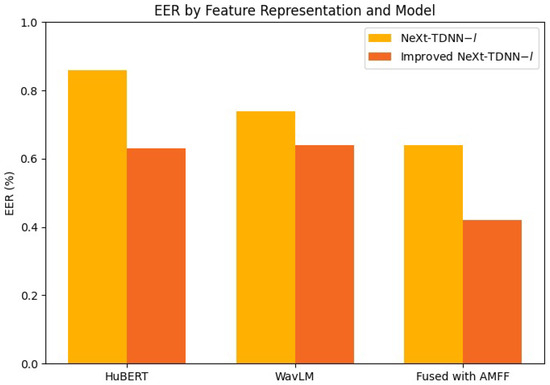
Figure 6.
Comparative analysis of the impact of NeXt-TDNN-l and Improved NeXt-TDNN-l.
In a complementary ablation study, three fusion strategies are evaluated—direct concatenation of WavLM and HuBERT embeddings, score-level fusion of independently trained WavLM- and HuBERT-based systems, and the proposed AMFF fusion framework—to determine how best to exploit the complementarity of these self-supervised representations. Table 7 demonstrates that naive combination schemes are insufficient for leveraging complementary self-supervised representations, whereas a trainable attention-based strategy is highly effective: the AMFF model, which jointly weighs HuBERT and WavLM embeddings, achieves the lowest EER (0.42%) and minimum t-DCF (0.012), surpassing the best single-feature baselines by about 33% and 37%, respectively. In contrast, simple feature concatenation actually degrades performance (EER = 0.89%), mean score fusion is catastrophically worse (EER = 1.72%), and even a more refined score fusion only matches the individual systems. This underscores the fact that effective cross-representation integration requires learned, context-aware weighting rather than fixed or heuristic merging. Consequently, the proposed method adopts the AMFF fusion strategy owing to its demonstrably superior performance, as further illustrated in Figure 7.
Table 7.
Comparison of different feature fusion techniques for spoof speech detection using HuBERT and WavLM embeddings.
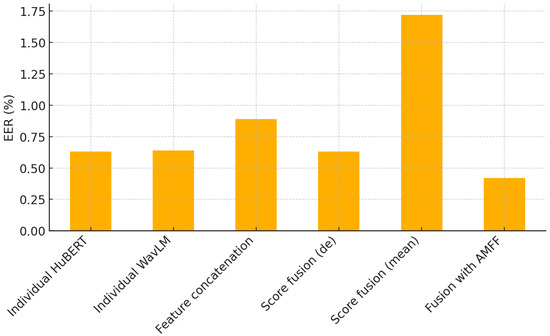
Figure 7.
Comparative EER (%) analysis of different self-supervised feature fusion strategies for spoof speech detection using HuBERT and WavLM embeddings.
4.4. Performance Evaluation and Comparative Analysis on the ASVspoof 2019 LA Dataset
This section reports the evaluation outcomes obtained on the ASVspoof 2019 LA dataset, positioning the proposed fusion-based approach against state-of-the-art methods in the literature to evaluate its performance.
Table 8 contrasts the detection performance of individual HuBERT, WavLM, and the proposed method over the thirteen spoofing attack types A07–A19 (whose signal characteristics are detailed in Table 3). In general, WavLM delivers the lowest EER on the majority of attacks (e.g., 0% for A09 and A13, and ≤0.08% for A07, A08, A12, A14–A16), while simultaneously achieving a near-zero min t-DCF. The proposed method is highly competitive, matching WavLM’s perfect detection on A13 and approaching it on most low-complexity attacks (A07, A09, A12, A14–A16), but it exhibits pronounced degradation on the more challenging vocoder-based attack A10 (4.39% EER, 0.052 min t-DCF). HuBERT lags behind the other two front-ends in both metrics, although its EER remains below 0.3% for eight of the thirteen attacks. Across all front-ends, the largest performance deficits are concentrated on attacks A10, A17, A18, and A19, indicating that these manipulations impose the greatest mismatch between bona fide and spoofed trials. Overall, as also shown in Figure 8, the results suggest that while WavLM provides the most robust and consistent protection, the proposed method offers comparable reliability for the majority of attack scenarios and maintains favorable min t-DCF values, thereby underscoring its potential as an effective, low-cost alternative in practical anti-spoofing deployments.
Table 8.
Detailed attack-level comparison of EER (%) and min-tDCF for competing feature extraction methods.
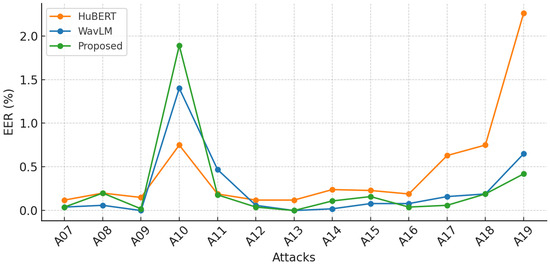
Figure 8.
Graphical representation of the attack evaluation with EER % across self-supervised front-ends.
The results in Table 9 demonstrate that the proposed method achieves consistently high performance across most attack types in the ASVspoof 2019 LA dataset, with macro-average precision, recall, F1, and balanced accuracy values generally exceeding 0.96. Notably, attacks A07, A08, A11, A12, A14, A15, and A19 exhibit near-perfect detection rates, with scores close to 1.0 in all metrics. However, attacks A13 and A17 represent significant outliers, yielding lower precision (0.5995) and accuracy (0.5995), despite perfect recall (1.000), indicating difficulty in distinguishing these specific spoofing attempts. The pooled results confirm the overall robustness of the method, with macro-averaged values of 0.9342 for precision, 0.9906 for recall, 0.9601 for F1-score, and 0.9906 for accuracy. These findings suggest that while the approach is highly reliable against most spoofing attacks, certain attack types remain challenging and require further refinement.
Table 9.
The macro-averaged precision, recall, F1 and balanced accuracy results of the proposed method under different attack types on ASVspoof 2019 LA dataset.
Table 10 consolidates system-level performance according to the broad spoofing families examined in the evaluation: TTS, VC, and their mixture (TTS-VC). It is worth recalling that the three broad spoofing families—TTS, VC, and their hybrid TTS-VC—are not arbitrary groupings: Table 3 summarizes their principal signal-processing characteristics. Figure 8 also presents the performance evaluation. A clear division of strengths emerges. HuBERT remains the most sensitive front-end to synthetic TTS speech, achieving the lowest TTS EER (0.25%) while matching WavLM on TTS min t-DCF (0.008). In contrast, its vulnerability to transformed speech is evident under VC, where both the error rate (1.21%) and the decision cost (0.098) are an order of magnitude higher than those of its competitors. WavLM offers the most balanced protection overall: although its TTS error (0.30%) is slightly higher than HuBERT’s, it delivers the best mixed-condition performance (TTS-VC EER = 0.03%, min t-DCF = 0.001) and maintains low cost on pure VC attacks (0.023). The proposed method excels specifically in the VC attack, reducing the EER to 0.22% and the min t-DCF to 0.010—both the lowest among the three systems—while remaining competitive for the combined scenario. Taken together, these findings underscore that no single front-end is universally optimal: the proposed method offers a robust defence against conversion-based attacks, WavLM affords the broadest overall resilience, and HuBERT retains an edge for purely text-generated speech, highlighting the potential benefits of system fusion or adaptive front-end selection in real-world anti-spoofing deployments.
Table 10.
Performance comparison of HuBERT, WavLM, and the proposed method against different spoofing attack types in terms of EER(%) and min t-DCF.
Table 11 benchmarks the three front-ends under the known, unknown, and partially known attack partitions defined in Section 4.1 (where the precise attack IDs assigned to each partition are enumerated). Consistent with the per-attack analysis, the proposed method yields the most reliable detection on the attacks it saw during training: it records the lowest EER (0.23%) and the lowest min t-DCF (0.008) in the known set. That advantage largely carries over to the partially known condition—those attacks that share algorithmic similarities with the training set but differ in speaker or linguistic content—where the proposed method again posts the best min t-DCF (0.003) and an EER of 0.08%. By contrast, HuBERT shows the greatest robustness to the genuinely unknown attacks, attaining the lowest EER (0.28%) and min t-DCF (0.007) when confronted with spoofing techniques absent from training. WavLM delivers balanced performance across the three partitions, but never leads in any single category. These results suggest that the proposed method is highly effective when some prior knowledge of the spoofing pipeline is available.
Table 11.
Comparison of EER (%) and minimum t-DCF for HuBERT, WavLM, and the proposed method under different spoofing knowledge scenarios: Known, Unknown, and Partially Known attacks.
Table 12 offers a concise longitudinal perspective on the evolution of spoof-speech detection techniques evaluated on the ASVspoof 2019 Logical Access (LA) corpus. The earliest contributions—anchored in manually crafted spectral features combined with Gaussian mixture modeling (e.g., LFCC-GMM and CQCC-GMM)—reported Equal Error Rates approaching 10% alongside minimum t-DCF figures of roughly 0.22, thereby underscoring the inherent difficulty of the problem when addressed with conventional statistical paradigms. The first CNN-based systems—Log-STFT-ResNet and MCR-ResNet—more than halved the EER to 3.7%, illustrating the benefit of deep hierarchical feature extraction. Subsequent work exploited multi-resolution time–frequency cues (CQT/SCC/MCG-Res2Net50), densely connected or attention-enhanced backbones, and raw-waveform front-ends (RawNet2), pushing EERs into the 1.7–2.5% range while consistently lowering the minimum t-DCF. Transformer-centric designs such as AASIST and its large variant AASIST-L marked another step change, breaking the 1% barrier (0.80% EER) with a corresponding min-tDCF of 0.02. Against this backdrop, the proposed method—fusing self-supervised (SSL) speech representations with an improved NeXt-TDNN architecture—achieves an EER of just 0.42% and a min-tDCF of 0.01, outperforming the best prior system by relative margins of 47% and 50%, respectively. These results not only set a new state-of-the-art on the LA evaluation set but also demonstrate that coupling rich SSL embeddings with refined temporal aggregation yields substantial robustness to diverse spoofing attacks.
Table 12.
State-of-the-art methods and their performance on ASVspoof 2019 LA dataset.
4.5. Performance Evaluation and Comparative Analysis on the ASVspoof 2019 PA Dataset
In this section, the details of the performance of the proposed model on the ASVspoof 2019 PA dataset are given. This dataset is purposely constructed to replicate replay attacks, with all utterances captured by a fixed microphone inside an acoustically controlled environment. Although the training/development and evaluation splits of this corpus comprise the same nine spoofing categories (AA, AB, …, CB, CC), the loudspeaker models used for the training/development material are known, whereas those in the evaluation split are unknown, originating from independent device measurements. Hence, the evaluation set, although labeled with identical class codes, in practice introduces previously unseen attack instances.
Table 13 demonstrates the strong effectiveness of the proposed countermeasure across all nine presentation-attack scenarios. Error rates remain exceptionally low—EER ranges from only 0.48% to 1.36%, while the corresponding min t-DCF values lie between 0.0134 and 0.0397—underscoring the method’s robustness and practical suitability. Notably, attacks involving source C artifacts (AC, BC, CC) yield the best results, indicating that the model generalizes particularly well to these conditions. Even in the comparatively more challenging source A cases, the system maintains an impressively low operational risk across all attack types.
Table 13.
The EER, min t-DCF, macro-averaged precision, recall, F1-measure and balanced accuracy metric results of the proposed method under different attack types on ASVspoof 2019 PA dataset.
Table 14 traces the methodological trajectory of spoof-speech detection for the ASVspoof 2019 PA scenario, highlighting a steady shift from traditional statistical modeling to representation-rich deep architectures. The earliest baselines, which fused manually engineered cepstral cues with Gaussian mixture models (LFCC-GMM and CQCC-GMM), struggled with EERs of 13.5% and 11.0%, respectively, and minimum t-DCF values near 0.30. These figures expose the vulnerability of purely handcrafted pipelines in the presence of PA replay artifacts. Introducing convolutional backbones delivered an immediate dividend: a CQCC-ResNet dropped the EER to 4.4% (min-tDCF = 0.10), while subsequent DenseNet variants exploiting either CQCC or spectrogram inputs nudged performance below the 4% mark. More recent explorations of raw-waveform front ends (RawNet2) and multi-branch fusion schemes offered incremental gains but remained bounded above 7% EER. A notable inflection point arrived with the Face-SE-DenseNet augmented by A-softmax optimization, which compressed the error to 2.73% and pushed min-tDCF down to 0.07, establishing a strong pre-SSL baseline. Against this backdrop, the proposed system—integrating self-supervised speech embeddings with an enhanced NeXt-TDNN temporal encoder—achieves an EER of 1.01% and a min-tDCF of 0.03. Relative to the best prior result, this corresponds to a 63% reduction in EER and a 57% decrease in detection cost, underscoring the value of coupling rich SSL representations with refined long-context modeling for robust counterreplay protection.
Table 14.
State-of-the-art methods and their performance on ASVspoof 2019 PA dataset.
4.6. Performance Evaluation and Comparative Analysis on the ASVspoof 2021 LA Dataset
The performance of the proposed system is assessed on the ASVspoof 2021 LA benchmark. For a fair comparison, the results of the proposed method are contrasted with those of four contemporary SOTA baselines: CQCC-GMM [26], LFCC-GMM [26], LFCC-LCNN [43], and RawNet2 [33]. Evaluations are carried out under each of the seven protocol conditions (C1–C7) and on the pooled set that aggregates all spoofing attacks. The outcomes, together with the SOTA results reported in [44], are summarized in Table 15 for the ASVspoof 2021 LA evaluation partition.
Table 15.
EER (%) results of the methods over attacks on ASVspoof 2021 LA. SOTA results are gathered from [44] as reference.
Table 15 presents the EER of several front-end classifiers on the ASVspoof 2021 LA evaluation set and unequivocally demonstrates the superiority of the proposed system. Across six of the seven attack categories (C1–C7), the proposed method secures the lowest EER, most notably halving the error observed with traditional feature-plus-GMM pipelines (e.g., 4.10% vs. 10.57% for C1 and 5.25% vs. 14.76% for C2). Even in the notoriously difficult C3 scenario, the proposed approach (12.50%) remains competitive with the convolutional LFCC-LCNN baseline (12.02%). Crucially, the pooled EER drops to 6.56%, yielding a relative reduction of roughly 31% over the strongest prior end-to-end model, RawNet2 (9.50%), and almost 58% over the classical CQCC-GMM reference (15.62%). These consistent gains attest to the method’s robustness against diverse spoofing techniques and underscore its promise as a new state-of-the-art defense in automatic speaker verification.
4.7. Performance Evaluation and Comparative Analysis on the ASVspoof 5 Dataset
This section presents the performance result of the proposed method and a comparative evaluation of the proposed method against state-of-the-art approaches on the ASVspoof 5 dataset [27]. The Table 16 gives the metric results of the proposed method on the dataset. The proposed method yields a performance result with an Equal Error Rate (EER) of 7.23% and macro-averaged metrics for precision, recall, F1-measure, and balanced accuracy all exceeding 92%. It can be said that the method demonstrates a high degree of robustness and discrimination capability. The results are noteworthy, given that they were obtained on the highly challenging ASVspoof 5 dataset, which introduces unprecedented complexities, including crowdsourced, non-studio-quality audio and novel adversarial attacks. The proposed system’s scores suggest that it has learned to identify subtle artifacts inherent in spoofed speech, making it a competitive contribution to the field.
Table 16.
The performance results (%) of the proposed method with EER, min t-DCF, macro-averaged precision, recall, F1-measure, and balanced accuracy metrics on ASVspoof 5 dataset.
The performance of the proposed method is also evaluated with the recent studies on this dataset. The comparative EER results are given in the Table 17. As shown in the table, the results are benchmarked against various methods from the literature, including RawNet2, AASIST, WavLM, SSL-based approaches, Spectrogram+ResNet, and openSMILE. The reported EER values clearly demonstrate that the proposed method achieves highly competitive performance compared to existing works. In particular, the proposed Fused SSL feature + Improved NeXt-TDNN approach attains an EER of 7.23%, which outperforms even its closest competitor, WavLM (Combei et al., 2024 [45]). This outcome highlights the superiority of the proposed system over both traditional feature-based methods and modern self-supervised learning (SSL) approaches. The findings confirm that the proposed architecture not only offers enhanced effectiveness in spoofing detection but also exhibits stronger generalization capability. Consequently, this study provides not only a measurable performance improvement over existing approaches but also contributes to the development of more robust ASV systems against spoofing attacks.
Table 17.
State-of-the-art methods and their performance on ASVspoof 5 dataset.
5. Discussion
The experimental results confirm that using fused HuBERT-Large and WavLM-Large embeddings with the AMFF module, and classifying them with a lightweight, ECA-enhanced NeXt-TDNN, yields a new state-of-the-art performance of 0.42% EER and 0.01 min-tDCF on the ASVspoof 2019 LA corpus, outperforming the previous best AASIST family by roughly 49–50% relative. AMFF learns sample-specific channel weights, avoiding the performance collapse seen with naive concatenation (EER = 0.89%) or mean-score fusion (EER = 1.72%). The ECA layer further refines salient channels, trimming the model to 5.9M parameters while still surpassing a full ECAPA-TDNN by more than 40% relative.
On replay attacks evaluated with ASVspoof 2019 PA, the proposed system achieves an EER of 0.48–1.36% across nine device-distance conditions, halving the best published DenseNet-based and raw-waveform-based baselines.
In cross-channel tests on ASVspoof 2021 LA, it reaches a pooled 6.56% EER, representing a 31% relative reduction over RawNet2. Generalization is strongest when attack conditions resemble the training data, yet performance remains competitive even in unseen scenarios. On the more recent ASVspoof 5 dataset, the proposed method achieves an EER of 7.23%, surpassing strong baselines and other referenced works. These results indicate that the method not only delivers competitive performance under controlled conditions but also exhibits robustness and enhanced generalization across diverse spoofing scenarios, thereby validating its effectiveness in realistic and challenging evaluation settings.
Looking ahead, we plan to extend robustness to emerging neural vocoders, streaming codecs, and adversarial manipulations, and to integrate the detector more tightly with speaker verification back-ends for end-to-end audio-authentication security.
6. Conclusions
This study introduced a compact yet powerful deepfake audio detection method that extracts complementary HuBERT-Large and WavLM-Large embeddings, fuses them through an Attentional Multi-Feature Fusion module, and classifies the result with a channel-aware NeXt-TDNN. The approach achieves a state-of-the-art performance of 0.42% EER and 0.01 min-tDCF on ASVspoof 2019 LA, a 1.01% EER on the replay attacks of ASVspoof 2019 PA, and a pooled 6.56% EER in the cross-channel 2021 LA evaluation, thereby demonstrating that strategically fused self-supervised speech representations combined with lightweight temporal modeling can markedly narrow the gap between bona-fide and synthetic speech. Furthermore, when evaluated on the ASVspoof 5 dataset, the proposed method achieved an EER of 7.23%, outperforming recent state-of-the-art baselines and confirming its robustness and strong generalization capability across diverse spoofing scenarios.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The source code and trained models are available at https://github.com/gultahaoglu/Deepfake-audio-detection-SSLFeatures-NextTDNN (accessed on 25 August 2025).
Conflicts of Interest
The author declare no conflicts of interest.
References
- Todisco, M.; Delgado, H.; Evans, N.W.D. Constant Q Cepstral Coefficients: A Spoofing Countermeasure for Automatic Speaker Verification. Comput. Speech Lang. 2017, 45, 516–535. [Google Scholar] [CrossRef]
- Tahaoglu, G.; Baracchi, D.; Shullani, D.; Iuliani, M.; Piva, A. Deepfake audio detection with spectral features and ResNeXt-based architecture. Knowl.-Based Syst. 2025, 323, 113726. [Google Scholar] [CrossRef]
- Kheir, Y.E.; Samih, Y.; Maharjan, S.; Polzehl, T.; Möller, S. Comprehensive layer-wise analysis of ssl models for audio deepfake detection. arXiv 2025, arXiv:2502.03559. [Google Scholar]
- Yu, H.; Tan, Z.; Zhang, Y.; Ma, Z.; Guo, J. DNN Filter Bank Cepstral Coefficients for Spoofing Detection. IEEE Access 2017, 5, 4779–4787. [Google Scholar] [CrossRef]
- Alzantot, M.; Wang, Z.; Srivastava, M.B. Deep residual neural networks for audio spoofing detection. arXiv 2019, arXiv:1907.00501. [Google Scholar] [CrossRef]
- Wu, Z.; Das, R.K.; Yang, J.; Li, H. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks. arXiv 2020, arXiv:2009.09637. [Google Scholar] [CrossRef]
- Wang, Z.; Cui, S.; Kang, X.; Sun, W.; Li, Z. Densely connected convolutional network for audio spoofing detection. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020. [Google Scholar]
- Xue, J.; Zhou, H.; Song, H.; Wu, B.; Shi, L. Cross-modal information fusion for voice spoofing detection. Speech Commun. 2023, 147, 41–50. [Google Scholar] [CrossRef]
- Xue, J.; Zhou, H. Physiological-physical feature fusion for automatic voice spoofing detection. Front. Comput. Sci. 2023, 17, 172318. [Google Scholar] [CrossRef]
- Wang, C.; He, J.; Yi, J.; Tao, J.; Zhang, C.Y.; Zhang, X. Multi-Scale Permutation Entropy for Audio Deepfake Detection. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1406–1410. [Google Scholar]
- Chaiwongyen, A.; Duangpummet, S.; Karnjana, J.; Kongprawechnon, W.; Unoki, M. Potential of Speech-pathological Features for Deepfake Speech Detection. IEEE Access 2024, 12, 121958–121970. [Google Scholar] [CrossRef]
- Lei, Z.; Yan, H.; Liu, C.; Ma, M.; Yang, Y. Two-Path GMM-ResNet and GMM-SENet for ASV Spoofing Detection. arXiv 2024, arXiv:2407.05605. [Google Scholar]
- Jung, J.; Heo, H.; Tak, H.; Kim, J.; Yoon, S.; Chung, J.S.; Kang, H. RawNet: Advanced End-to-End Deep Neural Network Using Raw Waveforms for Text-Independent Speaker Verification. arXiv 2019, arXiv:1904.08104. [Google Scholar]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-End Anti-Spoofing with RawNet2. arXiv 2021, arXiv:2011.01108. [Google Scholar]
- Tak, H.; Jung, J.W.; Patino, J.; Kamble, M.; Todisco, M.; Evans, N. End-to-End Spectro-Temporal Graph Attention Networks for Speaker Verification Anti-Spoofing and Speech Deepfake Detection. In Proceedings of the ASVspoof 2021 Workshop, Online, 16 September 2021. [Google Scholar]
- Pierno, A.D.; Guarnera, L.; Allegra, D.; Battiato, S. End-to-End Audio Deepfake Detection from Raw Waveforms: A RawNet-Based Approach with Cross-Dataset Evaluation. arXiv 2025, arXiv:2504.20923. [Google Scholar]
- Li, L.; Lu, T.; Ma, X.; Yuan, M.; Wan, D. Voice Deepfake Detection Using the Self-Supervised Pre-Training Model HuBERT. Appl. Sci. 2023, 13, 8488. [Google Scholar] [CrossRef]
- Eom, Y.; Lee, Y.; Um, J.S.; Kim, H. Anti-Spoofing Using Transfer Learning with Variational Information Bottleneck. In Proceedings of the Interspeech, 2022, Incheon, Republic of Korea, 18–22 September 2022; pp. 3568–3572. [Google Scholar] [CrossRef]
- Combei, D.; Stan, A.; Oneata, D.; Cucu, H. WavLM Model Ensemble for Audio Deepfake Detection. arXiv 2024, arXiv:2408.07414. [Google Scholar] [CrossRef]
- Ge, W.; Wang, X.; Liu, X.; Yamagishi, J. Post-Training for Deepfake Speech Detection. arXiv 2025, arXiv:2506.21090. [Google Scholar] [CrossRef]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Shen, Q.; Guo, M.; Huang, Y.; Ma, J. Attentional multi-feature fusion for spoofing-aware speaker verification. Int. J. Speech Technol. 2024, 27, 377–387. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection. arXiv 2019, arXiv:1904.05441. [Google Scholar] [CrossRef]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. In Proceedings of the ASVspoof 2021 Workshop-Automatic Speaker Verification and Spoofing Coutermeasures Challenge, Online, 16 September 2021. [Google Scholar]
- Wang, X.; Delgado, H.; Tak, H.; Jung, J.; Shim, H.; Todisco, M.; Kukanov, I.; Liu, X.; Sahidullah, M.; Kinnunen, T. ASVspoof 5: Design, collection and validation of resources for spoofing, deepfake, and adversarial attack detection using crowdsourced speech. Comput. Speech Lang. 2026, 95, 101825. [Google Scholar] [CrossRef]
- Asch, V. Macro-and Micro-Averaged Evaluation Measures [[Basic Draft]]. 2013; p. 1. Available online: https://cir.nii.ac.jp/crid/1370853567519937922 (accessed on 21 July 2025).
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, F.; Duan, Z. One-class learning towards synthetic voice spoofing detection. IEEE Signal Process. Lett. 2021, 28, 937–941. [Google Scholar] [CrossRef]
- Li, X.; Wu, X.; Lu, H.; Liu, X.; Meng, H. Channel-wise gated res2net: Towards robust detection of synthetic speech attacks. arXiv 2021, arXiv:2107.08803. [Google Scholar]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with rawnet2. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6369–6373. [Google Scholar]
- Hua, G.; Teoh, A.B.J.; Zhang, H. Towards end-to-end synthetic speech detection. IEEE Signal Process. Lett. 2021, 28, 1265–1269. [Google Scholar] [CrossRef]
- Jung, J.w.; Heo, H.S.; Tak, H.; Shim, H.j.; Chung, J.S.; Lee, B.J.; Yu, H.J.; Evans, N. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6367–6371. [Google Scholar]
- Grinberg, P.; Shikhov, V. RawSpectrogram: On the Way to Effective Streaming Speech Anti-Spoofing. IEEE Access 2023, 11, 109928–109938. [Google Scholar] [CrossRef]
- Zaman, K.; Samiul, I.J.; Sah, M.; Direkoglu, C.; Okada, S.; Unoki, M. Hybrid Transformer Architectures with Diverse Audio Features for Deepfake Speech Classification. IEEE Access 2024, 12, 149221–149237. [Google Scholar] [CrossRef]
- Mirza, A.R.; Al-Talabani, A.K. Spoofing Countermeasure for Fake Speech Detection Using Brute Force Features. Comput. Speech Lang. 2024, 90, 101732. [Google Scholar] [CrossRef]
- Sinha, S.; Dey, S.; Saha, G. Improving self-supervised learning model for audio spoofing detection with layer-conditioned embedding fusion. Comput. Speech Lang. 2024, 86, 101599. [Google Scholar] [CrossRef]
- Kulkarni, A.; Tran, H.M.; Kulkarni, A.; Dowerah, S.; Lolive, D.; Doss, M.M. Exploring generalization to unseen audio data for spoofing: Insights from SSL models. In Proceedings of the ASVSpoof Workshop 2024, Kos, Greece, 31 August 2024. [Google Scholar]
- Al-Tairi, H.; Javed, A.; Khan, T.; Saudagar, A.K.J. DeepLASD countermeasure for logical access audio spoofing. Sci. Rep. 2025, 15, 20839. [Google Scholar] [CrossRef]
- Pham, L.; Tran, D.; Lam, P.; Skopik, F.; Schindler, A.; Poletti, S.; Fischinger, D.; Boyer, M. DIN-CTS: Low-complexity depthwise-inception neural network with contrastive training strategy for deepfake speech detection. arXiv 2025, arXiv:2502.20225. [Google Scholar]
- Wang, X.; Qin, X.; Zhu, T.; Wang, C.; Zhang, S.; Li, M. The DKU-CMRI system for the ASVspoof 2021 challenge: Vocoder based replay channel response estimation. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 16–21. [Google Scholar]
- Chen, X.; Zhang, Y.; Zhu, G.; Duan, Z. UR channel-robust synthetic speech detection system for ASVspoof 2021. arXiv 2021, arXiv:2107.12018. [Google Scholar] [CrossRef]
- Combei, D.; Stan, A.; Oneata, D.; Cucu, H. WavLM model ensemble for audio deepfake detection. In Proceedings of the Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), Kos, Greece, 31 August 2024; pp. 170–175. [Google Scholar] [CrossRef]
- Schäfer, K.; Choi, J.E.; Neu, M. Robust Audio Deepfake Detection: Exploring Front-/Back-End Combinations and Data Augmentation Strategies for the ASVspoof5 Challenge. In Proceedings of the Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), Kos, Greece, 31 August 2024. [Google Scholar] [CrossRef]
- Tran, T.; Bui, T.D.; Simatis, P. ParallelChain Lab’s antispoofing systems for ASVspoof 5. In Proceedings of the Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), Kos, Greece, 31 August 2024; pp. 9–15. [Google Scholar]
- Pascu, O.; Oneata, D.; Cucu, H.; Müller, N.M. Easy, Interpretable, Effective: OpenSMILE for Voice Deepfake Detection. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).