
Image-Level Anti-Personnel Landmine Detection Using Deep Learning in Long-Wave Infrared Images



Abstract
1. Introduction
2. Dataset
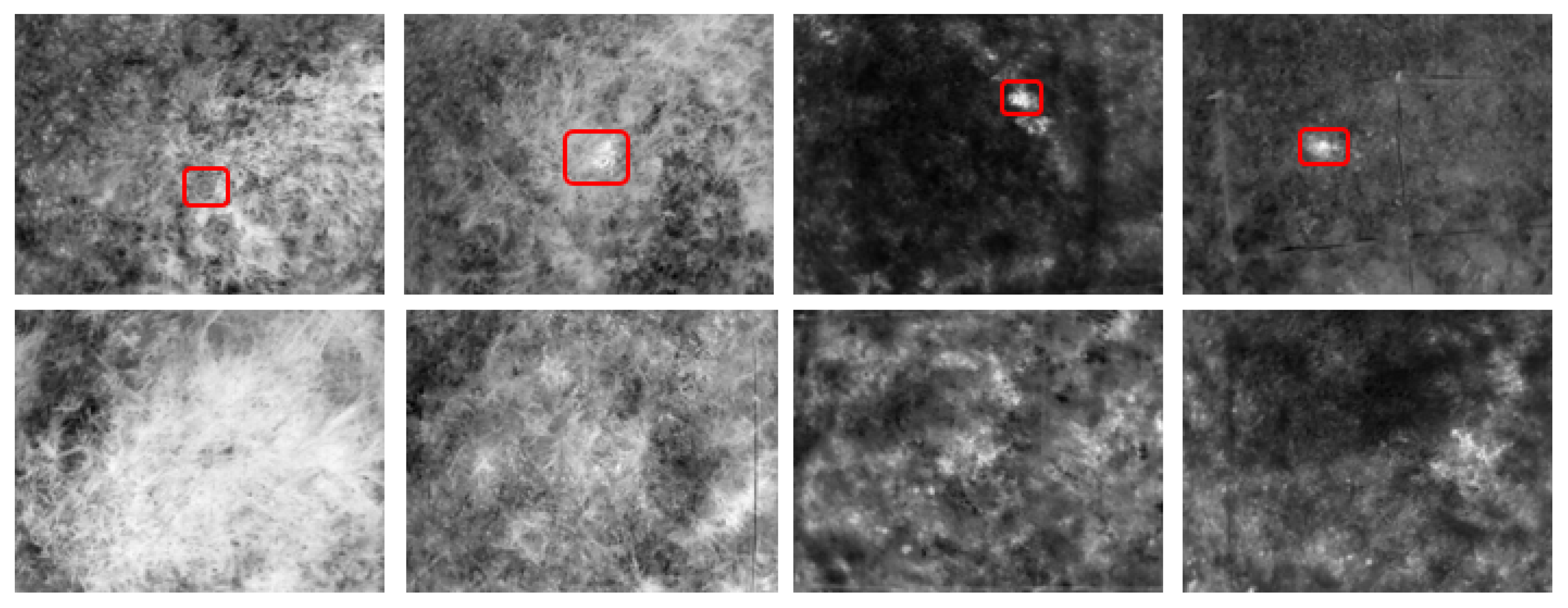
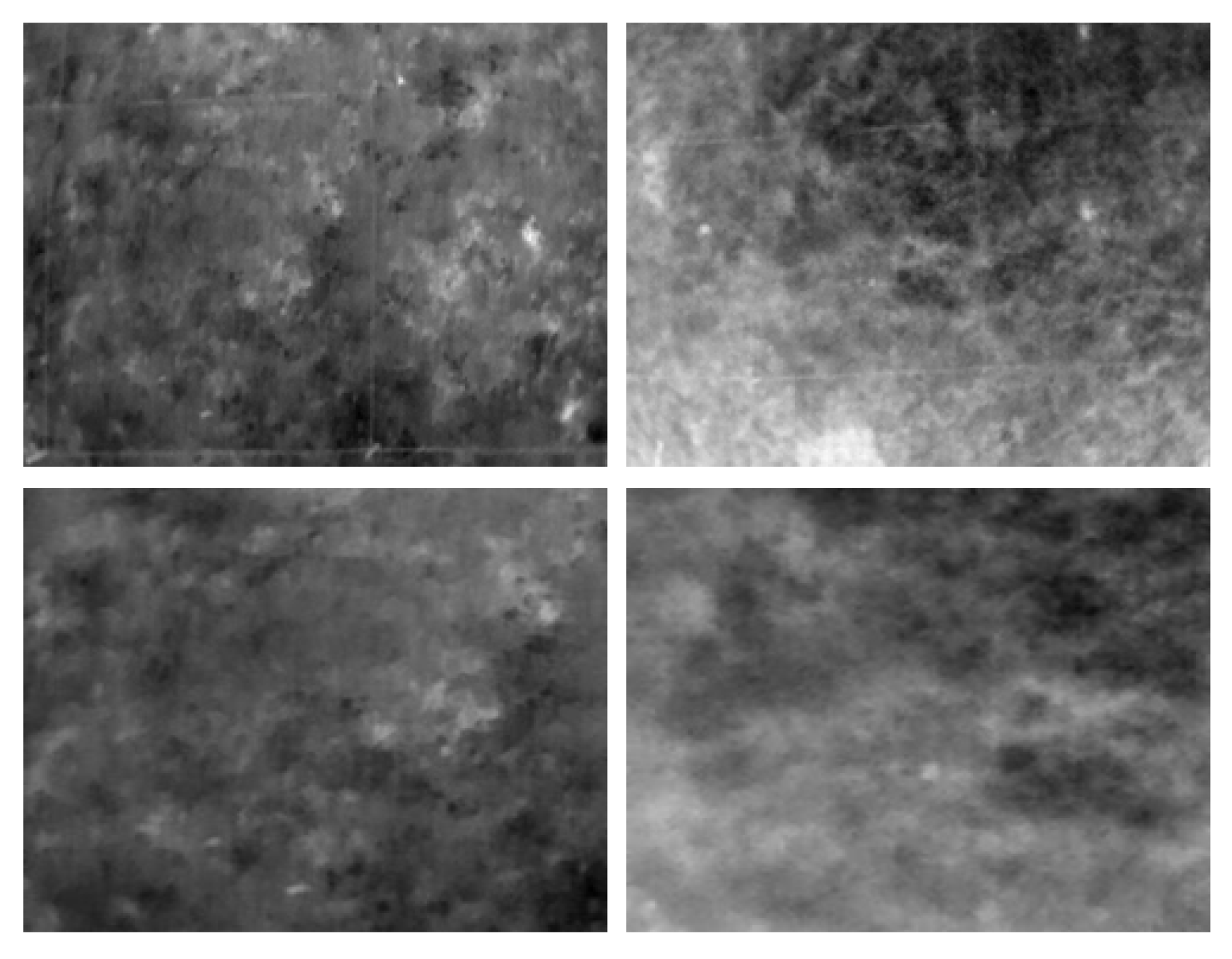
2.1. AP Landmine Dataset
2.2. MASATI (MAritime SATellite Imagery) Dataset
3. Methods
3.1. Transfer Learning
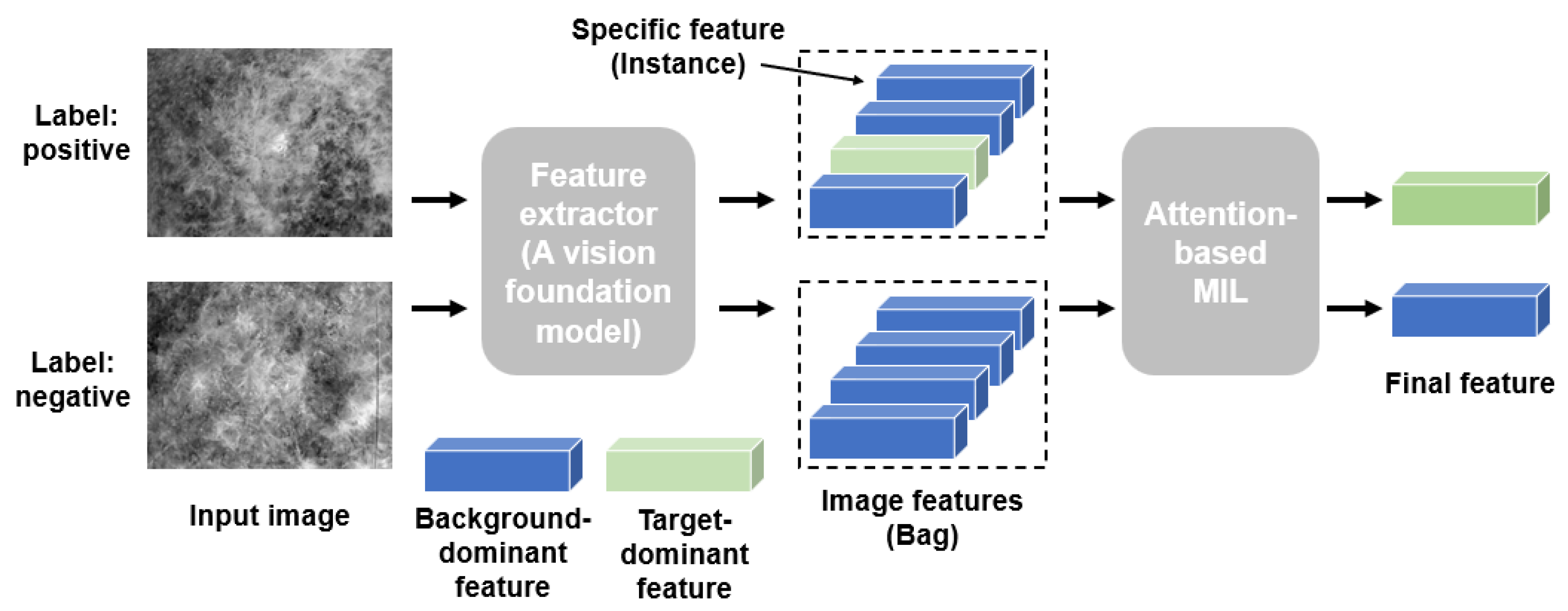
3.2. Multiple Instance Learning
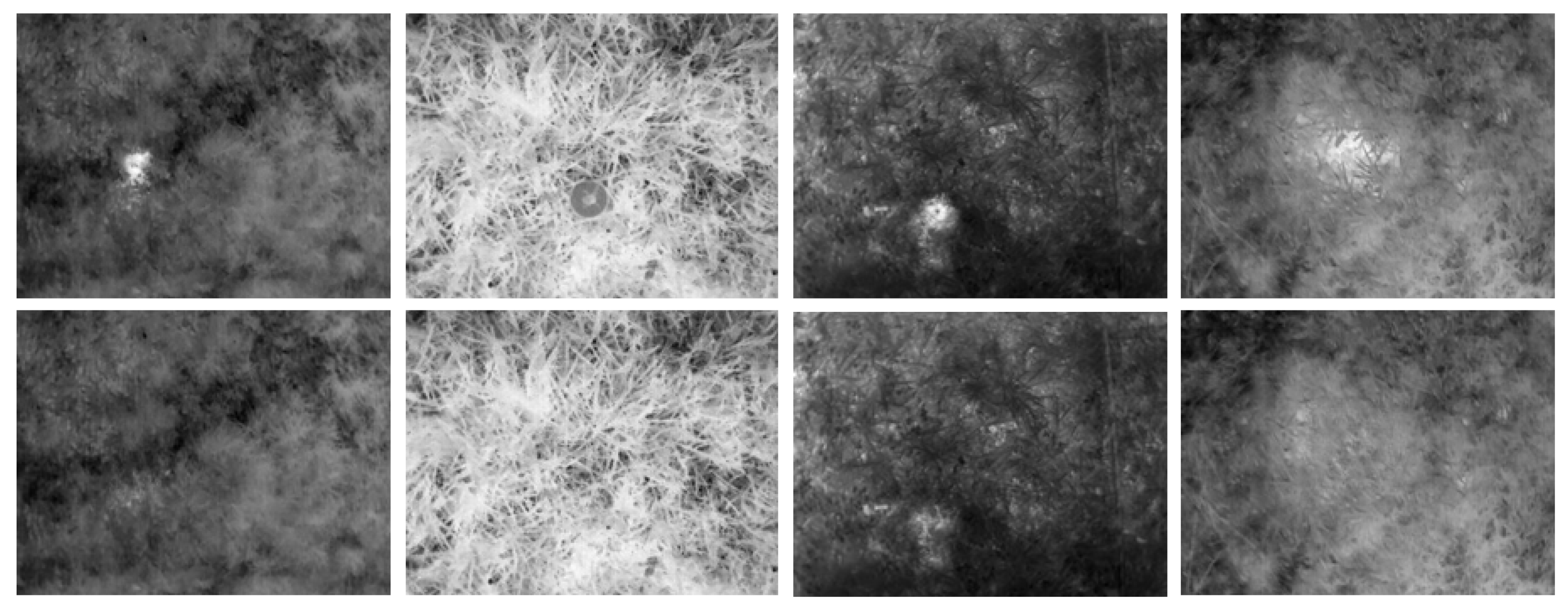
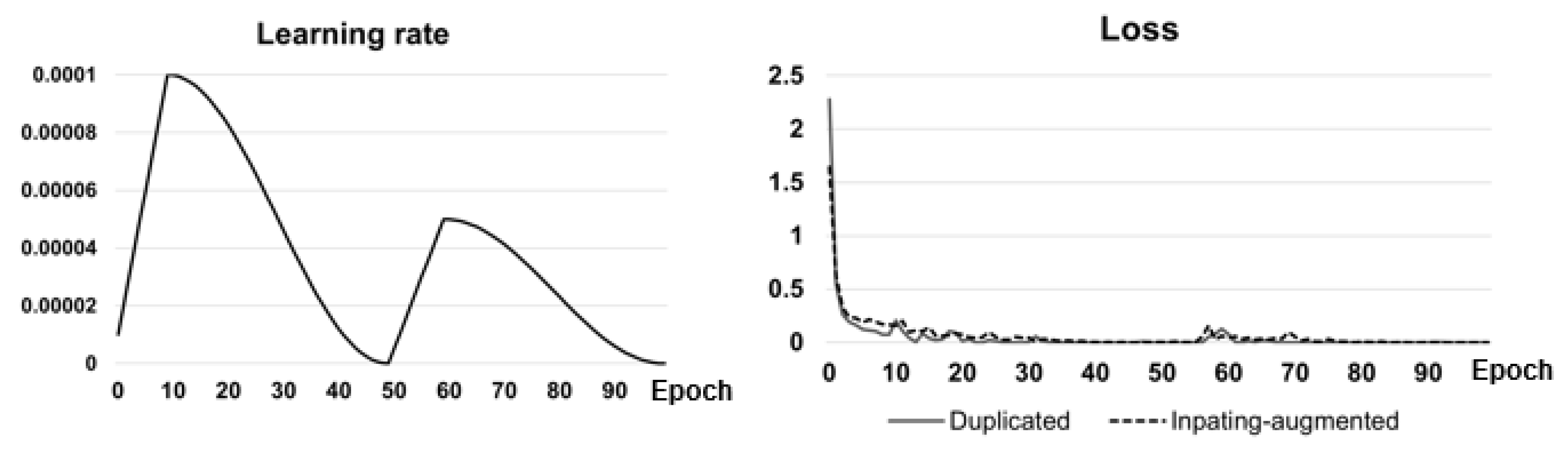
3.3. Mitigating Spurious Features via Image Inpainting Augmentation
4. Experimental Results
4.1. Experimental Setup
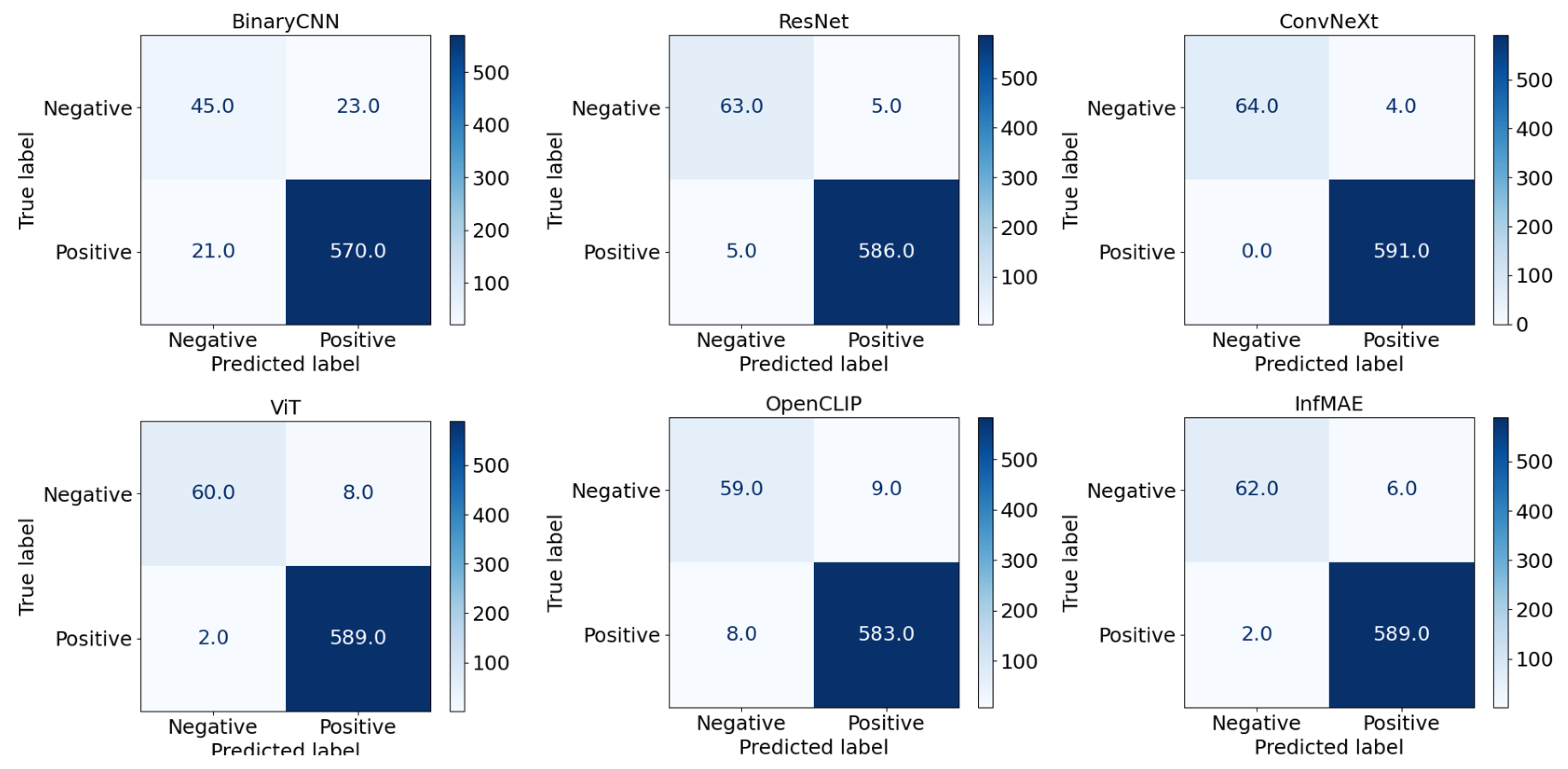
4.2. Results with Duplicated Train Set
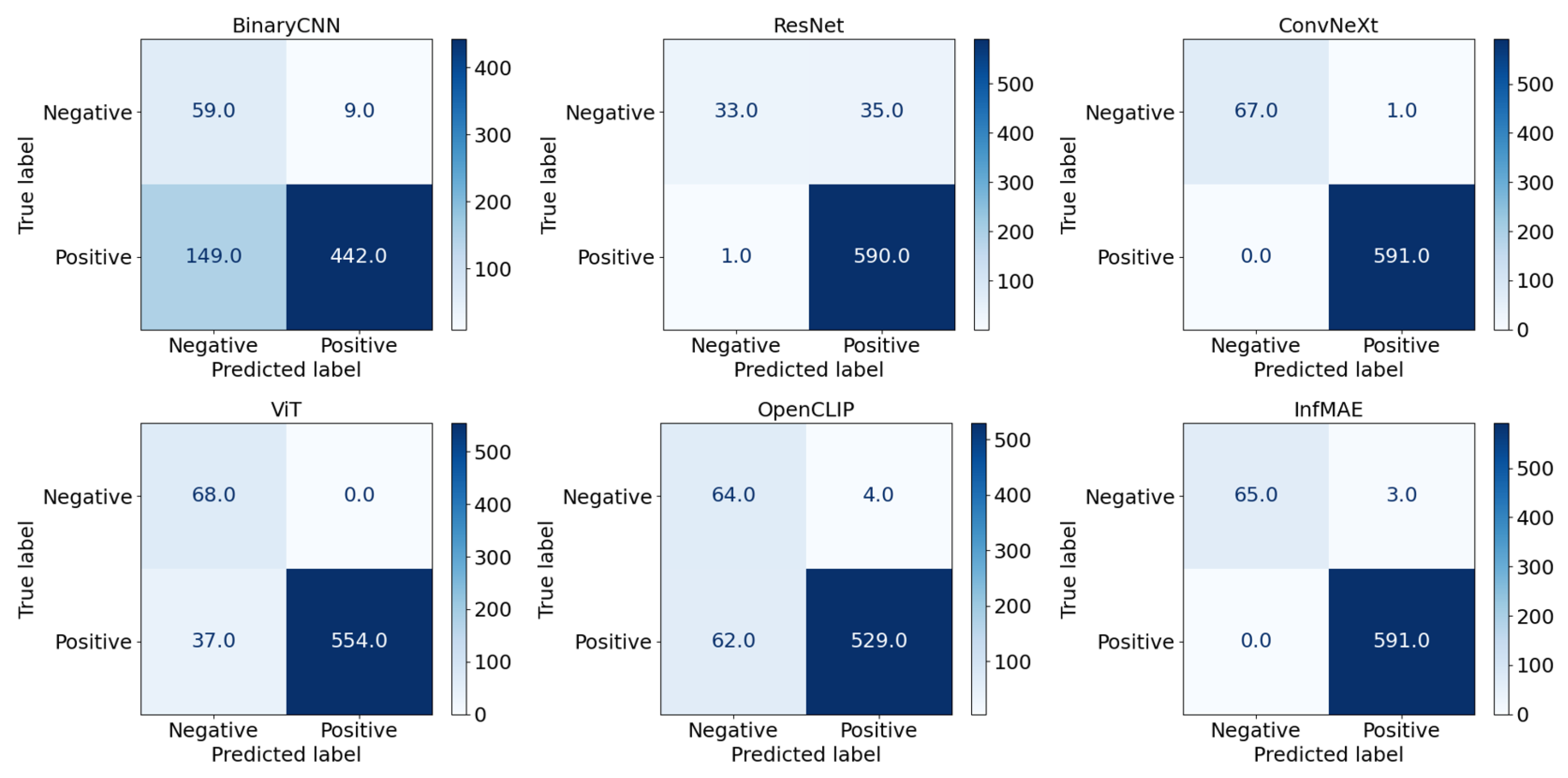
4.3. Results with Inpainting-Augmented Train Set
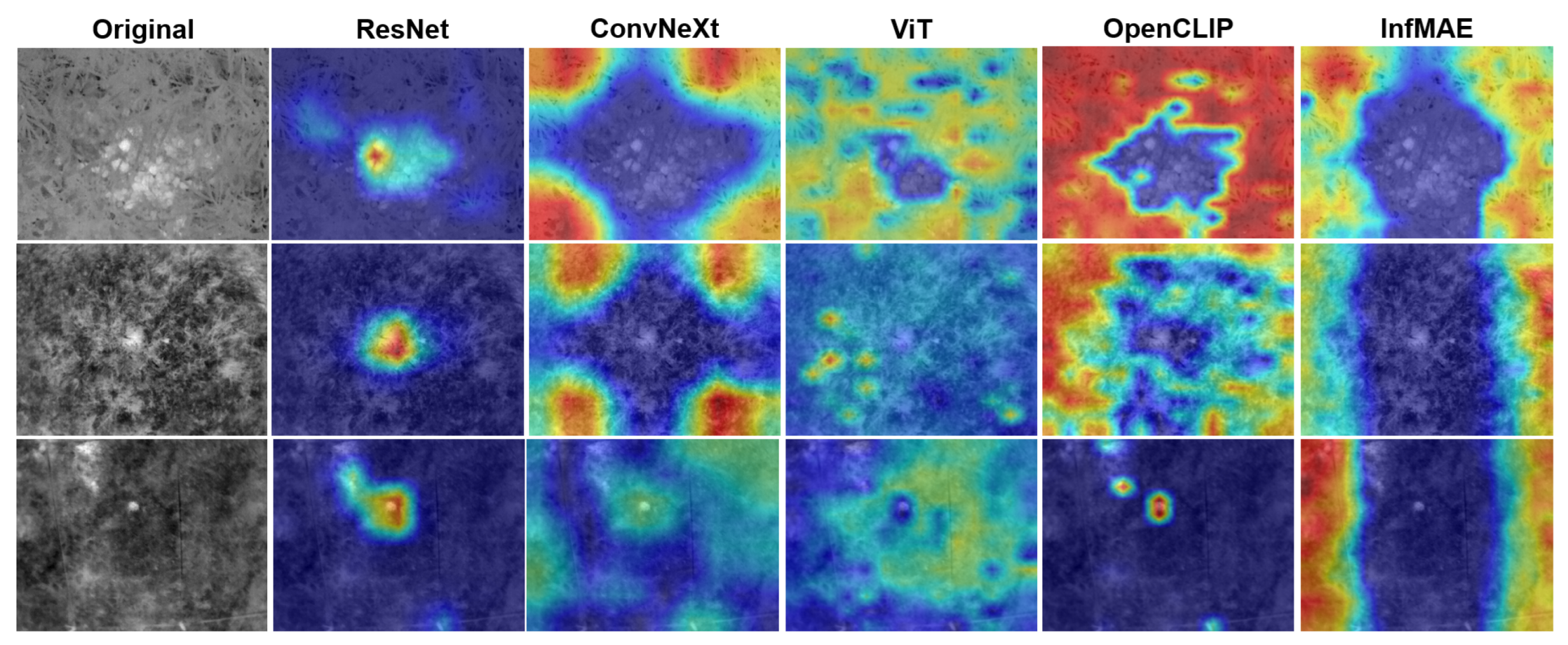
4.4. Ablation Studies
4.5. Results with MASATI Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Núñez-Nieto, X.; Solla, M.; Gómez-Pérez, P.; Lorenzo, H. GPR signal characterization for automated landmine and UXO detection based on machine learning techniques. Remote Sens. 2014, 6, 9729–9748. [Google Scholar] [CrossRef]
- Vivoli, E.; Bertini, M.; Capineri, L. Deep learning-based real-time detection of surface landmines using optical imaging. Remote Sens. 2024, 16, 677. [Google Scholar] [CrossRef]
- Forero-Ramírez, J.C.; García, B.; Tenorio-Tamayo, H.A.; Restrepo-Girón, A.D.; Loaiza-Correa, H.; Nope-Rodríguez, S.E.; Barandica-López, A.; Buitrago-Molina, J.T. Detection of “legbreaker” antipersonnel landmines by analysis of aerial thermographic images of the soil. Infrared Phys. Technol. 2022, 125, 104307. [Google Scholar] [CrossRef]
- Kaya, S.; Leloglu, U.M. Buried and surface mine detection from thermal image time series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4544–4552. [Google Scholar] [CrossRef]
- Özdeğer, T.; Davidson, J.L.; Van Verre, W.; Marsh, L.A.; Lionheart, W.R.; Peyton, A.J. Measuring the magnetic polarizability tensor using an axial multi-coil geometry. IEEE Sens. J. 2021, 21, 19322–19333. [Google Scholar] [CrossRef]
- García-Fernández, M.; López, Y.Á.; Andrés, F.L.H. Airborne multi-channel ground penetrating radar for improvised explosive devices and landmine detection. IEEE Access 2020, 8, 165927–165943. [Google Scholar] [CrossRef]
- García-Fernández, M.; Álvarez-Narciandi, G.; López, Y.Á.; Andrés, F.L.H. Improvements in GPR-SAR imaging focusing and detection capabilities of UAV-mounted GPR systems. ISPRS J. Photogramm. Remote Sens. 2022, 189, 128–142. [Google Scholar] [CrossRef]
- Makki, I.; Younes, R.; Francis, C.; Bianchi, T.; Zucchetti, M. A survey of landmine detection using hyperspectral imaging. ISPRS J. Photogramm. Remote Sens. 2017, 124, 40–53. [Google Scholar] [CrossRef]
- Khodor, M.; Makki, I.; Younes, R.; Bianchi, T.; Khoder, J.; Francis, C.; Zucchetti, M. Landmine detection in hyperspectral images based on pixel intensity. Remote Sens. Appl. Soc. Environ. 2021, 21, 100468. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, J.; Joung, J. Siamese hyperspectral target detection using synthetic training data. Electron. Lett. 2020, 56, 1116–1118. [Google Scholar] [CrossRef]
- Baur, J.; Steinberg, G.; Nikulin, A.; Chiu, K.; de Smet, T.S. Applying deep learning to automate UAV-based detection of scatterable landmines. Remote Sens. 2020, 12, 859. [Google Scholar] [CrossRef]
- Qiu, Z.; Guo, H.; Hu, J.; Jiang, H.; Luo, C. Joint fusion and detection via deep learning in UAV-borne multispectral sensing of scatterable landmine. Sensors 2023, 23, 5693. [Google Scholar] [CrossRef]
- Deans, J.; Gerhard, J.; Carter, L. Analysis of a thermal imaging method for landmine detection, using infrared heating of the sand surface. Infrared Phys. Technol. 2006, 48, 202–216. [Google Scholar] [CrossRef]
- Tenorio-Tamayo, H.A.; Forero-Ramírez, J.C.; García, B.; Loaiza-Correa, H.; Restrepo-Girón, A.D.; Nope-Rodríguez, S.E.; Barandica-López, A.; Buitrago-Molina, J.T. Dataset of thermographic images for the detection of buried landmines. Data Brief 2023, 49, 109443. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28; NeurIPS: San Diego, CA, USA, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Solawetz, J. What is YOLOv8? A Complete Guide; Technical Report; Ultralytics: Frederick, MD, USA, 2024. [Google Scholar]
- Kaya, S.; Leloglu, U.M.; Tumuklu Ozyer, G. Robust landmine detection from thermal image time series using Hough transform and rotationally invariant features. Int. J. Remote Sens. 2020, 41, 725–739. [Google Scholar] [CrossRef]
- Tenorio-Tamayo, H.A.; Nope-Rodríguez, S.E.; Loaiza-Correa, H.; Restrepo-Girón, A.D. Detection of anti-personnel mines of the “leg breakers” type by analyzing thermographic images captured from a drone at different heights. Infrared Phys. Technol. 2024, 142, 105567. [Google Scholar] [CrossRef]
- Edwards, T.; Nibouche, M.; Withey, D. Deep learning-based detection of surface and buried landmines. In Proceedings of the 2024 30th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Leeds, UK, 3–5 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning From Noisy Labels with Deep Neural Networks: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8135–8153. [Google Scholar] [CrossRef]
- Rezvani, S.; Wang, X. A broad review on class imbalance learning techniques. Appl. Soft Comput. 2023, 143, 110415. [Google Scholar] [CrossRef]
- Alves, R.H.F.; de Deus Junior, G.A.; Marra, E.G.; Lemos, R.P. Automatic fault classification in photovoltaic modules using Convolutional Neural Networks. Renew. Energy 2021, 179, 502–516. [Google Scholar] [CrossRef]
- Yao, J.; Zhu, X.; Jonnagaddala, J.; Hawkins, N.; Huang, J. Whole slide images based cancer survival prediction using attention guided deep multiple instance learning networks. Med. Image Anal. 2020, 65, 101789. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Alashhab, S.; Gallego, A.J.; Pertusa, A.; Gil, P. Precise ship location with cnn filter selection from optical aerial images. IEEE Access 2019, 7, 96567–96582. [Google Scholar] [CrossRef]
- Gallego, A.J.; Pertusa, A.; Gil, P. Automatic ship classification from optical aerial images with convolutional neural networks. Remote Sens. 2018, 10, 511. [Google Scholar] [CrossRef]
- Aldoğan, C.F.; Aksu, K.; Demirel, H. Enhancement of Sentinel-2A Images for Ship Detection via Real-ESRGAN Model. Appl. Sci. 2024, 14, 11988. [Google Scholar] [CrossRef]
- Zuo, G.; Zhou, J.; Meng, Y.; Zhang, T.; Long, Z. Night-time vessel detection based on enhanced dense nested attention network. Remote Sens. 2024, 16, 1038. [Google Scholar] [CrossRef]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Zhang, J.; Huang, J.; Jin, S.; Lu, S. Vision-language models for vision tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5625–5644. [Google Scholar] [CrossRef] [PubMed]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Corley, I.; Robinson, C.; Dodhia, R.; Ferres, J.M.L.; Najafirad, P. Revisiting pre-trained remote sensing model benchmarks: Resizing and normalization matters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 3162–3172. [Google Scholar]
- Kim, J.H.; Kwon, G.R. Efficient Classification of Photovoltaic Module Defects in Infrared Images. IEEE Signal Process. Lett. 2025, 32, 2389–2393. [Google Scholar] [CrossRef]
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 2022, 7, 100198. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Liu, F.; Gao, C.; Zhang, Y.; Guo, J.; Wang, J.; Meng, D. InfMAE: A foundation model in the infrared modality. In Proceedings of the ECCV 2024: 18th European Conference, Milan, Italy, 29 September–4 October 2024; pp. 420–437. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5672–5683. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Cherti, M.; Beaumont, R.; Wightman, R.; Wortsman, M.; Ilharco, G.; Gordon, C.; Schuhmann, C.; Schmidt, L.; Jitsev, J. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2818–2829. [Google Scholar]
- Ilse, M.; Tomczak, J.; Welling, M. Attention-based deep multiple instance learning. In Proceedings of the 2018 International Conference on Machine Learning and Data Engineering, Stockholm, Sweden, 10–15 July 2018; pp. 2127–2136. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australian, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Moayeri, M.; Pope, P.; Balaji, Y.; Feizi, S. A comprehensive study of image classification model sensitivity to foregrounds, backgrounds, and visual attributes. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19087–19097. [Google Scholar]
- Kirichenko, P.; Izmailov, P.; Wilson, A.G. Last layer re-training is sufficient for robustness to spurious correlations. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Fatima, M.; Jung, S.; Keuper, M. Corner Cases: How Size and Position of Objects Challenge ImageNet-Trained Models. arXiv 2025, arXiv:2505.03569. [Google Scholar]
- Suvorov, R.; Logacheva, E.; Mashikhin, A.; Remizova, A.; Ashukha, A.; Silvestrov, A.; Kong, N.; Goka, H.; Park, K.; Lempitsky, V. Resolution-robust large mask inpainting with fourier convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 2149–2159. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 782–791. [Google Scholar]

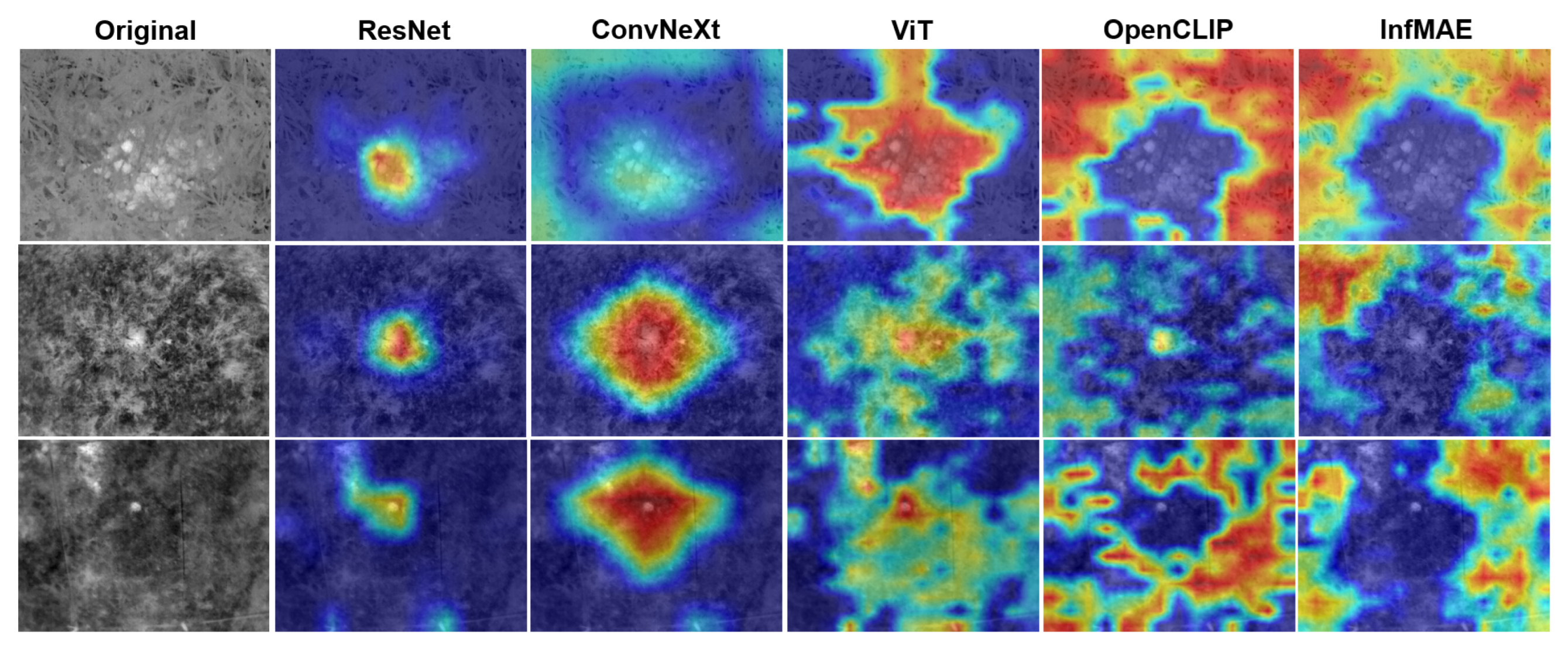

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | # of Param.(M) | Dataset | Sup./Self. | Modality |
|---|---|---|---|---|---|
| ResNet [16] | ResNet50 | 23.5 | IN1K | sup. | image |
| ConvNeXt [38] | ConvNext-Base | 87.6 | IN21K | sup. | image |
| ViT [39] | ViT-Base | 102.6 | IN21K | sup. | image |
| OpenCLIP [40] | ViT-Base | 86.6 | LAION400M | self. | image–text pair |
| InfMAE [41] | ConvViT-Base | 89.1 | Inf30 | self. | infrared image |
| Augmentation Method | Parameters |
|---|---|
| RandomHorizontalFlip | p = 0.5 |
| RandomVerticalFlip | p = 0.5 |
| RandomResizedCrop | size = (h,w),scale = (0.9, 1.0) |
| RandomRotation | degrees = 45 |
| ColorJitter | brightness = 0.1, contrast = 0.1 |
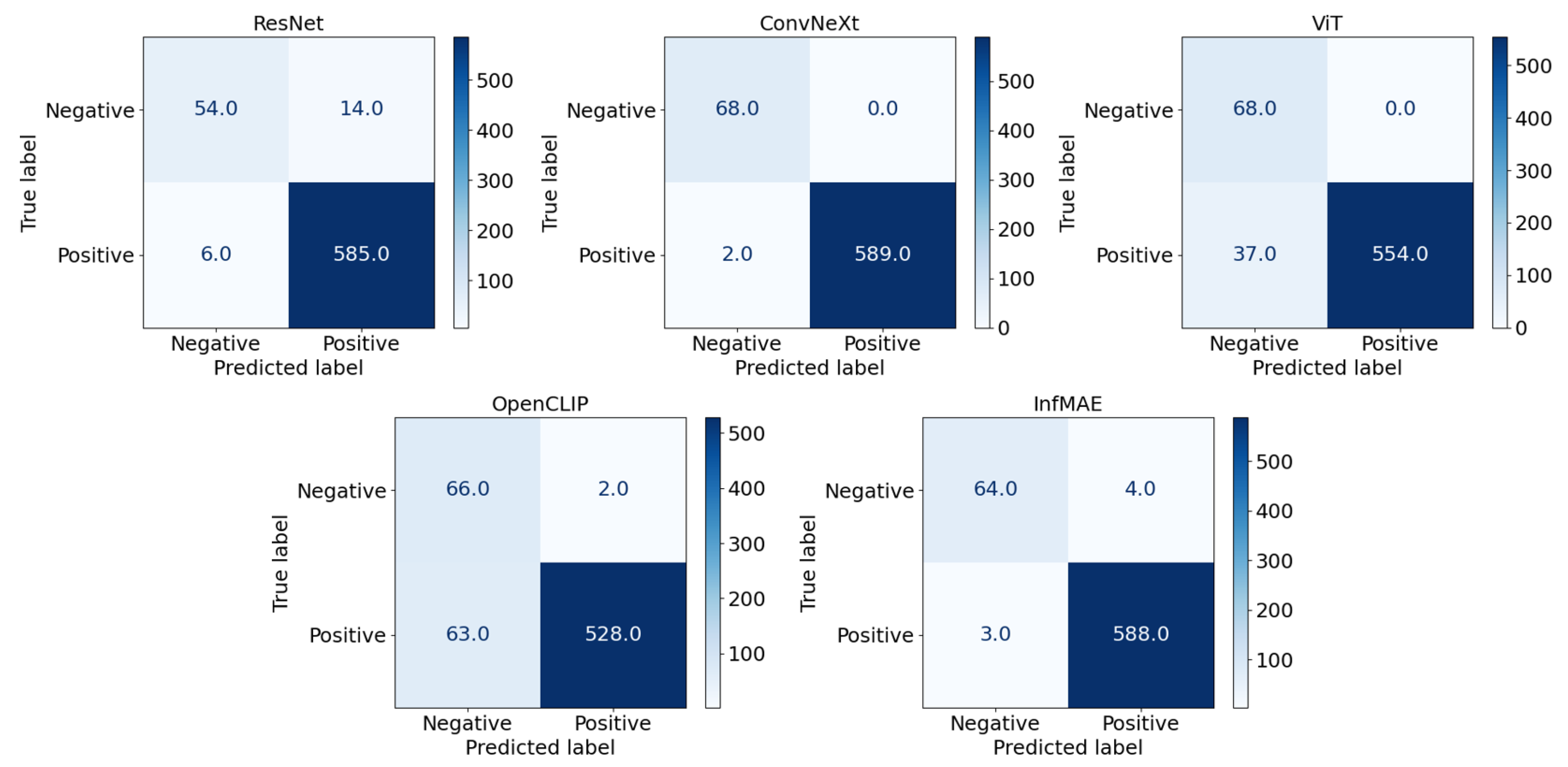
| Model | BinaryCNN | ResNet | ConvNeXt | ViT | OpenCLIP | InfMAE |
|---|---|---|---|---|---|---|
| Precision | 0.957 ± 0.004 | 0.989 ± 0.003 | 0.991 ± 0.002 | 0.985 ± 0.002 | 0.981 ± 0.004 | 0.987 ± 0.004 |
| Recall | 0.967 ± 0.007 | 0.993 ± 0.002 | 1.000 ± 0.000 | 0.998 ± 0.002 | 0.996 ± 0.006 | 0.997 ± 0.003 |
| F1-score | 0.962 ± 0.003 | 0.991 ± 0.001 | 0.995 ± 0.001 | 0.991 ± 0.001 | 0.989 ± 0.002 | 0.992 ± 0.003 |
| Model | BinaryCNN | ResNet | ConvNeXt | ViT | OpenCLIP | InfMAE |
|---|---|---|---|---|---|---|
| Number of false positives | 515 | 320 | 432 | 468 | 481 | 421 |
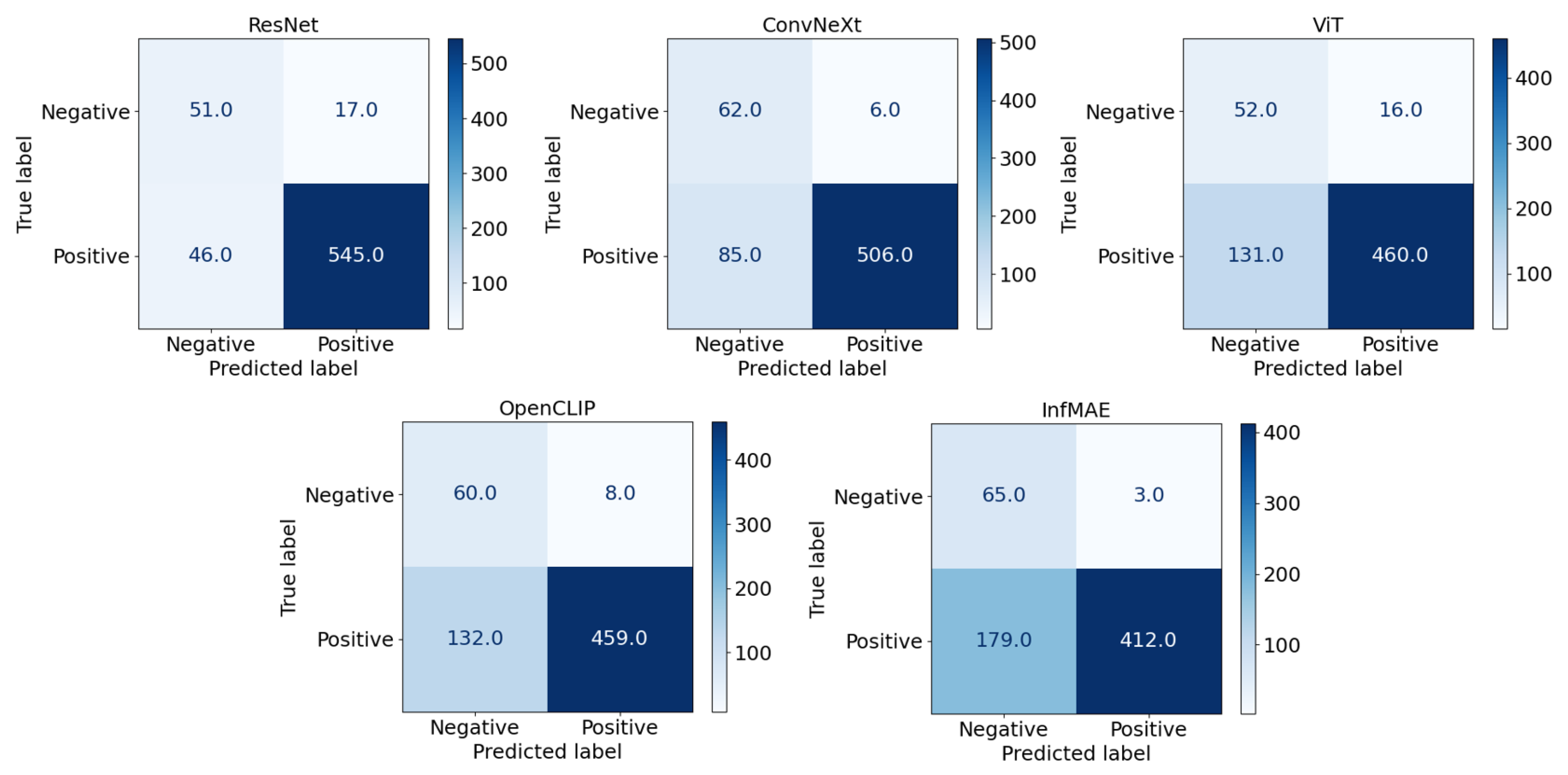
| Model | BinaryCNN | ResNet | ConvNeXt | ViT | OpenCLIP | InfMAE |
|---|---|---|---|---|---|---|
| Precision | 0.973 ± 0.009 | 0.933 ± 0.009 | 0.996 ± 0.003 | 1.000 ± 0.000 | 0.994 ± 0.004 | 0.990 ± 0.005 |
| Recall | 0.757 ± 0.008 | 0.999 ± 0.001 | 1.000 ± 0.000 | 0.928 ± 0.013 | 0.894 ± 0.013 | 1.000 ± 0.000 |
| F1-score | 0.851 ± 0.007 | 0.965 ± 0.004 | 0.998 ± 0.001 | 0.963 ± 0.007 | 0.941 ± 0.006 | 0.995 ± 0.002 |
| Model | BinaryCNN | ResNet | ConvNeXt | ViT | OpenCLIP | InfMAE |
|---|---|---|---|---|---|---|
| Number of false positives | 52 | 2 | 0 | 15 | 25 | 0 |
| Model | ResNet | ConvNeXt | ViT | OpenCLIP |
|---|---|---|---|---|
| Precision | 0.976 | 0.986 | 0.986 | 0.956 |
| Recall | 0.961 | 0.986 | 0.990 | 0.937 |
| F1-score | 0.968 | 0.986 | 0.988 | 0.946 |
| # of false pos.(Sea) | 69 | 208 | 202 | 433 |
| # of false pos.(synthetic) | 113 | 177 | 187 | 184 |
| Model | ResNet | ConvNeXt | ViT | OpenCLIP |
|---|---|---|---|---|
| Precision | 0.989 | 0.980 | 0.984 | 0.927 |
| Recall | 0.908 | 0.947 | 0.884 | 0.792 |
| F1-score | 0.947 | 0.963 | 0.931 | 0.854 |
| # of false pos.(Sea) | 22 | 14 | 18 | 494 |
| # of false pos.(synthetic) | 16 | 14 | 39 | 164 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Kwon, G.-R. Image-Level Anti-Personnel Landmine Detection Using Deep Learning in Long-Wave Infrared Images. Appl. Sci. 2025, 15, 8613. https://doi.org/10.3390/app15158613
Kim J-H, Kwon G-R. Image-Level Anti-Personnel Landmine Detection Using Deep Learning in Long-Wave Infrared Images. Applied Sciences. 2025; 15(15):8613. https://doi.org/10.3390/app15158613
Chicago/Turabian StyleKim, Jun-Hyung, and Goo-Rak Kwon. 2025. "Image-Level Anti-Personnel Landmine Detection Using Deep Learning in Long-Wave Infrared Images" Applied Sciences 15, no. 15: 8613. https://doi.org/10.3390/app15158613
APA StyleKim, J.-H., & Kwon, G.-R. (2025). Image-Level Anti-Personnel Landmine Detection Using Deep Learning in Long-Wave Infrared Images. Applied Sciences, 15(15), 8613. https://doi.org/10.3390/app15158613