

Enhancing Propaganda Detection in Arabic News Context Through Multi-Task Learning



Abstract
1. Introduction
- We introduce the first MTL models that effectively enhance Arabic propaganda detection by incorporating sentiment analysis and emotion detection tasks.
- We develop two MTL models: PSMTL, which combines propaganda and sentiment tasks, and PEMTL, which integrates propaganda and emotion tasks. The main objective is to investigate how incorporating sentiment and emotion can enhance propaganda detection models’ effectiveness.
- We propose utilizing seven distinct task-weighting techniques and provide empirical evidence supporting their effective implementation in MTL models.
2. Related Work
2.1. STL for Propaganda Detection
2.2. MTL for Propaganda Detection
2.3. Discussion
- MTL vs. STL: MTL has demonstrably advanced propaganda detection in both English and Arabic through diverse methodological innovations, including parallel binary classifiers for technique identification, span-based hierarchical pipelines, auxiliary genre classification tasks, and joint training paradigms. By contrast, most existing studies rely on STL for propaganda detection, which lacks the benefits of shared knowledge across related tasks. This isolated approach often limits model generalization, particularly in low-resource settings such as Arabic.
- Sentiment and emotions feature: A critical limitation persists across the reviewed MTL frameworks, whether designed in English or Arabic. No framework has yet integrated sentiment or emotion analysis as auxiliary learning objectives, despite affective manipulation’s well-documented role in propaganda. This oversight is particularly notable because propaganda frequently relies on emotional appeal and polarized sentiment to influence audiences. Incorporating such affective dimensions can provide valuable supervisory signals to regularize shared representations and improve model discriminability.
- Language: English was the dominant language in most of the previous studies. Although Arabic research has made remarkable progress, especially in shared tasks, to the best of our knowledge, few studies in Arabic have explored propaganda detection. This research area is in its early stages, and Arabic researchers have only recently started to explore it. The MTL framework is particularly valuable for Arabic propaganda detection, where data scarcity and linguistic complexity pose significant challenges. By leveraging shared knowledge across tasks, MTL enhances generalization, reduces overfitting, and improves model robustness in low-resource scenarios. For Arabic specifically, MTL addresses two critical gaps: achieving data efficiency, where parameter sharing across tasks mitigates the need for large, labeled datasets; and addressing the scarcity of annotated Arabic propaganda corpora. Additionally, contextual awareness is where auxiliary tasks, such as emotion or intent prediction, help decode culturally embedded persuasion tactics. However, challenges remain, including task imbalance (e.g., subtasks with noisier labels) and the need for architectures that better balance shared and task-specific learning.
3. Methodology
| Algorithm 1: The Proposed MTL for Arabic Propaganda Detection |
| Input: D: A raw dataset containing Arabic documents, Tasks: A set {Propaganda Detection, Sentiment Detection, Emotion Detection}, w: Initial weights for task losses |
| Output: Preds: Predictions for propaganda labels 1: Preds ← ∅ 2: for all d ∈ D do 3: cleaned_d ← preprocess(d) // Cleaning and normalization 4: tokens_d ← tokenize(cleaned_d) // Tokenization via AraBERT tokenizer 5: input_ids, attention_masks, token_type_ids ← tokens_d 6: for task ∈ Tasks do 7: Ytask ← generate_labels(d, task) // Propaganda, Sentiment, Emotion labels 8: Task_ID ← assign_taskID(task) // e.g., Propaganda:0, Sentiment:1, Emotion:2 9: end for 10: batch ← create_batches(input_ids, attention_masks, token_type_ids, Task_ID, Ytask) 11: encoded_batch ← AraBERT_encoder(batch) // Shared AraBERT encoder 12: θ_shared ← extract_pooled_output(encoded_batch) // Shared features extraction 13: for task ∈ Tasks do 14: task_embedding ← get_task_embedding(Task_ID) 15: combined_representation ← θ_shared ⊕ task_embedding 16: task_preds ← task_specific_head(combined_representation, task) 17: Lt ← compute_task_loss(task_preds, Ytask) 18: end for 19: Lglobal ← w1 × Lpropaganda + w2 × Lsentiment + w3 × Lemotion // Weighted sum 20: update_weights(encoder, task_heads, Lglobal) // Backpropagation 21: preds ← predict(encoded_batch, propaganda_head) 22: Preds ← Preds ∪ preds 23: end for 24: Return Preds |
3.1. Mathematical Notations of the Problem
- Let be the data from the task set. Specifically,
- Dt represents the training data for task.
- N represents the number of examples in Dt.
- xi represents the input text (news text).
- yi represents the corresponding label of task t. The label for each task is associated with the input , where denotes the label for the task. For example, may represent the label for propaganda detection (1—propaganda, 2—nonpropaganda), may represent sentiment analysis labels (1—positive, 2—negative, 3—neutral), and may represent emotion detection labels (1—happiness, 2—sadness, 3—anger, 4—fear, 5—none).
- T represents the total number of tasks. Each task corresponds to a specific task such as propaganda detection, sentiment analysis, or emotion detection.
- Each pair (, is used for training.
- H represents the set of shared hidden layers across all tasks. These layers are responsible for extracting generalized features from the input text that are relevant to all tasks.
- represents the task descriptor, or task-specific dictionary, generated in the shared layers for task t, where ∈ {1, 2, 3, …, T} denotes each task in the MTL framework, as described earlier. Specifically, is a task-specific feature vector that captures the relevant information for task derived from the shared representations learned in the shared layers. This descriptor is then passed to the task-specific layers, where it guides the model’s learning process for the corresponding task.
- Lt represents the loss function for task . This loss measures the discrepancy between the predicted label and the true label for task .
- represents the set of parameters shared across the MTL model during the encoding process.
- n represents the total number of shared parameters in the encoding stage.
- represents the task-specific parameters for the output decoder heads corresponding to task t. These parameters are unique to each task and are used to generate final predictions for each task.
- m represents the total number of parameters specific to task t in the output decoder.
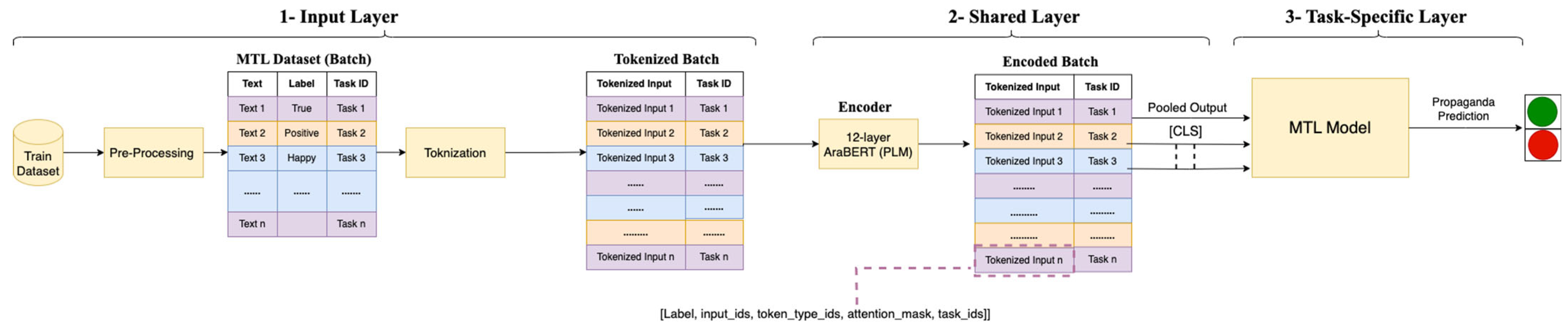
3.2. Input Layer
3.3. Shared Layer
3.4. Task-Specific Layer
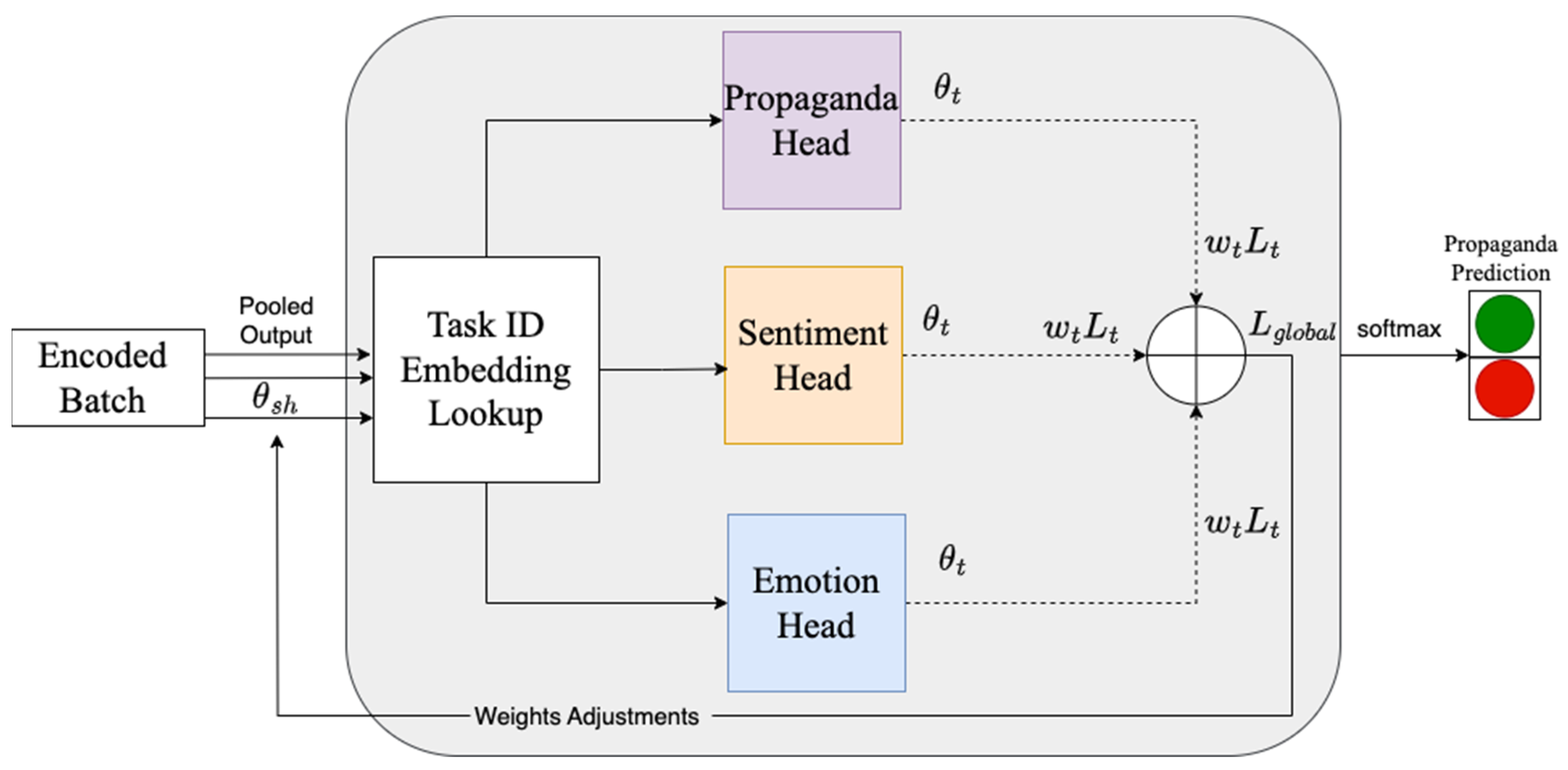
3.5. MTL Architecture
3.6. Task-Weighting
3.6.1. MTO Weighting Schemes
- Equal weighting: This approach involves assigning uniform and constant weights to each task’s loss function throughout the training process. Although conceptually straightforward and easy to implement, it inherently assumes that all tasks hold equal importance.
- Proportional weighting: This approach involves a domain expert or heuristic approach because it assigns weights to each task loss in proportion to its relative importance.
- Uncertainty weighting (UW): This approach involves learning to estimate homoscedastic noise terms (uncertainty) associated with each task’s loss and rescaling each loss inversely to its estimated noise. Therefore, tasks with higher uncertainty (i.e., those that are more difficult to learn) are assigned lower weights, and tasks with lower uncertainty (i.e., those that are easier to learn) are assigned higher weights. This scheme aims to minimize the overall uncertainty in the learning process, effectively prioritize more stable tasks, and down-weight those that contribute more noise or variance.
- Dynamic weighting: This approach involves reweighting tasks according to recent loss function values. Tasks that improve rapidly (i.e., those whose loss decreases quickly) may be down-weighted to prevent them from dominating the learning process, whereas tasks that improve more slowly (i.e., those whose loss decreases slowly) may be up-weighted to accelerate their learning. This scheme aims to dynamically balance each task’s contribution, ensuring that the model gives more attention to still-underperforming tasks, thus enhancing the overall task learning efficiency.
3.6.2. MTL Training Objective
3.6.3. Task-Weighting Schemes
- Uniform Averaging Weighting (UAW)
- represents the total number of tasks.
- represents each individual task in the summation.
- represents the loss function for the task.
- represents the normalization of the total loss across tasks.
- , and represent propaganda, sentiment, and emotion loss, respectively, and calculated as in Equation (10):
- t is the true label (either 0 or 1).
- p is the sigmoid probability output of the positive class. The sigmoid activation function applies an independent probability estimation to each class by mapping the output scores to the range (0, 1). Thus, it allows each class to be predicted independently. The probability for class is computed as seen in Equation (12):
- K is the total number of classes.
- ti represents the true category distribution in one-hot encoding, where 1 represents the correct class and 0 represents the others.
- is the softmax probability distribution for class i.
- The negative sum ensures that incorrect predictions are penalized by minimizing the negative log-likelihood of the correct prediction.
- 2
- Linear Scalarization (LS)
- 3.
- Dynamic Difficulty Weighting (DDW)
- represents a constant propaganda weighting that ensures that the propaganda task remains prioritized even if its loss decreases over time.
- represents the difficulty score of the propaganda task, which is based on its loss.
- and represent a constant scaling factor for the sentiment and emotion task, respectively.
- and represent difficulty scores for the sentiment and emotion tasks, respectively.
- 4.
- Priority-Guided Random Weighting (PGRW)
- T represents the total number of tasks.
- t represents each individual task in the summation.
- Lt represents loss function for the task.
- represents priority-guided parameter.
- represents the randomly sampled task weight for task t.
- represents the indicator function (1 if t = propaganda, and 0 otherwise).
- represents the final normalized task weight.
- j represents a variable that iterates through all the tasks in T when computing the sum (softmax denominator).
- 5.
- Hierarchical Weighting (HW)
- 6.
- UW
- 7.
- Priority-Aware Softmax-Based UW (PASUW)
4. Experiments
4.1. Dataset
4.2. Models
4.3. Experimental Setup
| Algorithm 2: Grid-search tuning of weighting-scheme hyperparameters |
| Input: train: Training set (75%), dev: Development set (8.5%) G: Search grids G1 … Gn |
| Output: Optimal hyperparameter vector θ⋆ 1: bestScore ← −∞; θ⋆ ← ∅ 2: for θ in G1 × … × Gn //Cartesian product 3: train model Mθ on train for ≤ 5 epochs 4: apply early stopping (patience = 2) 5: score ← macroF1(Mθ(dev)) 6: if score > bestScore then 7: bestScore ← score 8: θ⋆ ← θ 9: end for 10: Return θ⋆ |
4.4. Evaluation Measurements
5. Results and Discussion
5.1. Ablation Experiments on the Proposed MTL Models
5.2. Experimental Results on the Proposed Task-Weighting
5.3. Comparisons with Previous Studies
- AraBERT [22]: AraBERT is a single-task model that extends the pretrained BERT language model by incorporating a linear classification layer into the hidden representation of the special [CLS] token. Notably, this model follows the same approach as the backbone model, making it an appropriate point for comparison.
- AraBERT with Features [25]: This single-task model extends the pretrained BERT language model by adding a linear classification layer to the hidden representation of the [CLS] token, along with several additional features. These features enhance the model’s propaganda detection performance.
- ML with Features [25]: This is a single-task model that integrates multiple ML classifiers, each utilizing various features for improved performance in propaganda detection.
- AraBERT [23]: AraBERT is a single-task model that extends the pretrained BERT language model by appending a linear classification layer to the hidden representation of the [CLS] token. This model serves as a baseline for propaganda detection.
- LlamaLens [24]: LlamaLens is a specialized multilingual LLM designed for the analysis of propaganda content in news. This single-task model utilizes multilingual capabilities to assess and detect propaganda in diverse linguistic contexts.
- MARBERT [6]: MARBERT is a multi-task model that extends the pretrained BERT language model by incorporating a linear classification layer into the hidden representation of the [CLS] token. This model was specifically designed for the detection of abusive content in Arabic tweets, showcasing its versatility in MTL settings.
5.4. Discussion
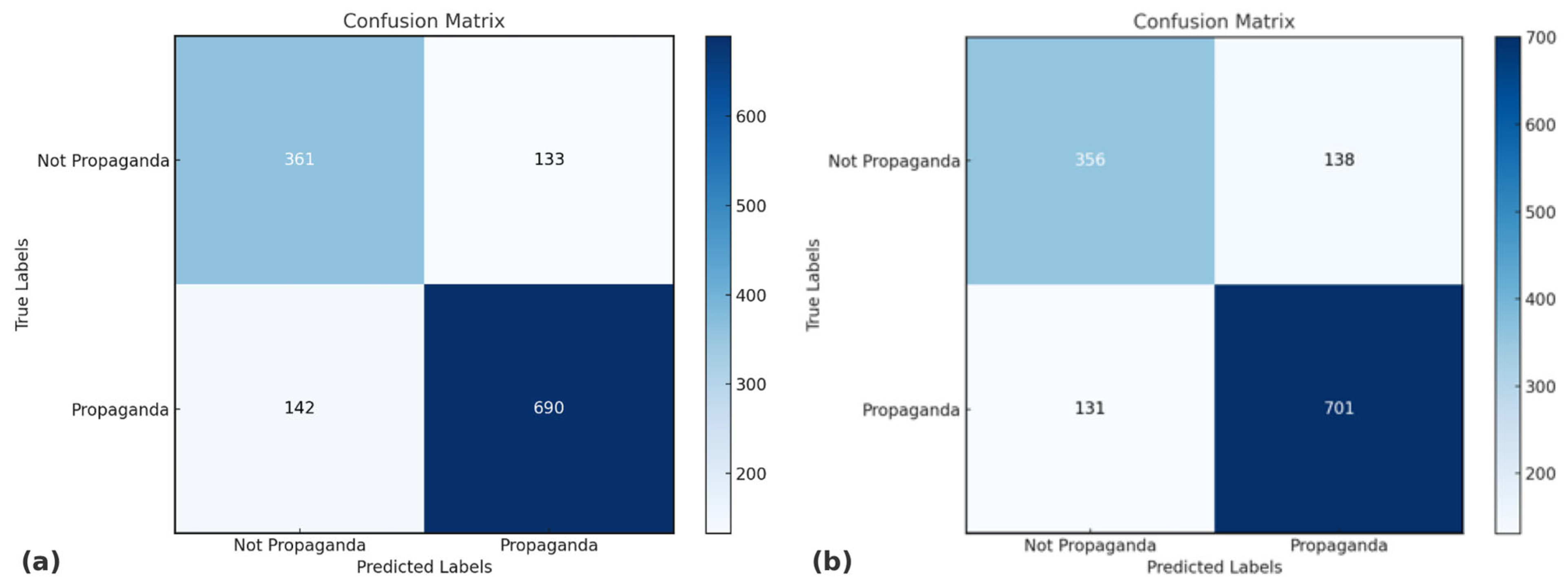
6. Error Analysis
6.1. Per-Class Performance
6.2. Correct and Error Distribution
- Type-1: TP—A news text containing propaganda is correctly classified as propaganda.
- Type-2: TN—A news text not containing propaganda is correctly classified as nonpropaganda.
- Type-3: FP—A news text not containing propaganda is incorrectly classified as propaganda.
- Type-4: FN—A news text containing propaganda is incorrectly classified as nonpropaganda.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Digital Around the World. DataReportal—Global Digital Insights. Available online: https://datareportal.com/global-digital-overview (accessed on 13 February 2024).
- PROPAGANDA|English Meaning—Cambridge Dictionary. Available online: https://dictionary.cambridge.org/dictionary/english/propaganda (accessed on 13 February 2024).
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. Available online: http://arxiv.org/abs/1504.08083 (accessed on 17 February 2024). [CrossRef]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-Task Deep Neural Networks for Natural Language Understanding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Vienna, Austria, 2019; pp. 4487–4496. [Google Scholar] [CrossRef]
- Alrashidi, B.; Jamal, A.; Alkhathlan, A. Abusive Content Detection in Arabic Tweets Using Multi-Task Learning and Transformer-Based Models. Appl. Sci. 2023, 13, 5825. [Google Scholar] [CrossRef]
- Fadel, A.; Saleh, M.; Salama, R.; Abulnaja, O. MTL-AraBERT: An Enhanced Multi-Task Learning Model for Arabic Aspect-Based Sentiment Analysis. Computers 2024, 13, 98. [Google Scholar] [CrossRef]
- Mahdaouy, A.E.; Mekki, A.E.; Essefar, K.; Mamoun, N.E.; Berrada, I.; Khoumsi, A. Deep Multi-Task Model for Sarcasm Detection and Sentiment Analysis in Arabic Language. arXiv 2021, arXiv:2106.12488. [Google Scholar] [CrossRef]
- Ruder, S. Neural Transfer Learning for Natural Language Processing. Ph.D. Thesis, NUI Galway, Galway, Ireland, 2019. [Google Scholar]
- Niehues, J.; Cho, E. Exploiting Linguistic Resources for Neural Machine Translation Using Multi-task Learning. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; Association for Computational Linguistics: Vienna, Austria, 2017; pp. 80–89. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. arXiv 2021, arXiv:1707.08114. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar] [CrossRef]
- Top Ten Internet Languages in The World—Internet Statistics. Available online: https://www.internetworldstats.com/stats7.htm#google_vignette (accessed on 17 February 2024).
- Darwish, K.; Habash, N.; Abbas, M.; Al-Khalifa, H.; Al-Natsheh, H.T.; Bouamor, H.; Bouzoubaa, K.; Cavalli-Sforza, V.; El-Beltagy, S.R.; El-Hajj, W.; et al. A Panoramic Survey of Natural Language Processing in the Arab World. arXiv 2021, arXiv:2011.12631. Available online: http://arxiv.org/abs/2011.12631 (accessed on 5 February 2024). [CrossRef]
- Kaczyński, K.; Przybyła, P. HOMADOS at SemEval-2021 Task 6: Multi-Task Learning for Propaganda Detection. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Bangkok, Thailand, 5–6 August 2021; Association for Computational Linguistics: Vienna, Austria, 2021; pp. 1027–1031. [Google Scholar] [CrossRef]
- Baraniak, K.; Sydow, M. Kb at SemEval-2023 Task 3: On Multitask Hierarchical BERT Base Neural Network for Multi-label Persuasion Techniques Detection. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Toronto, ON, Canada, 13–14 July 2023; Association for Computational Linguistics: Vienna, Austria, 2023; pp. 1395–1400. [Google Scholar] [CrossRef]
- Attieh, J.; Hassan, F. Pythoneers at WANLP 2022 Shared Task: Monolingual AraBERT for Arabic Propaganda Detection and Span Extraction. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates (Hybrid), 8 December 2022; Association for Computational Linguistics: Vienna, Austria, 2022; pp. 534–540. [Google Scholar] [CrossRef]
- Hadjer, K.; Bouklouha, T. HTE at ArAIEval Shared Task: Integrating Content Type Information in Binary Persuasive Technique Detection. In Proceedings of the ArabicNLP 2023, Singapore, 23 November 2023; Association for Computational Linguistics: Vienna, Austria, 2023; pp. 502–507. [Google Scholar] [CrossRef]
- Shukla, U.; Vyas, M.; Tiwari, S. Raphael at ArAIEval Shared Task: Understanding Persuasive Language and Tone, an LLM Approach. In Proceedings of the ArabicNLP 2023, Singapore, 23 November 2023; Association for Computational Linguistics: Vienna, Austria, 2023; pp. 589–593. [Google Scholar] [CrossRef]
- Li, Y.; Tian, X.; Liu, T.; Tao, D. Multi-Task Model and Feature Joint Learning. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Mahabadi, R.K.; Ruder, S.; Dehghani, M.; Henderson, J. Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Vienna, Austria, 2021; pp. 565–576. [Google Scholar] [CrossRef]
- Al-Henaki, L.; Al-Khalifa, H.; Al-Salman, A.; Alqubayshi, H.; Al-Twailay, H.; Alghamdi, G.; Aljasim, H. MultiProSE: A Multi-label Arabic Dataset for Propaganda, Sentiment, and Emotion Detection. arXiv 2025, arXiv:2502.08319. [Google Scholar] [CrossRef]
- Hasanain, M.; Ahmad, F.; Alam, F. Can GPT-4 Identify Propaganda? Annotation and Detection of Propaganda Spans in News Articles. arXiv 2024, arXiv:2402.17478. [Google Scholar] [CrossRef]
- Kmainasi, M.B.; Shahroor, A.E.; Hasanain, M.; Laskar, S.R.; Hassan, N.; Alam, F. LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content. arXiv 2024, arXiv:2410.15308. [Google Scholar] [CrossRef]
- Al-Henaki, L.; Al-Khalifa, H.; Al-Salman, A. Enhancing Arabic Propaganda Detection through Hybrid Learning and Lexicon-Based Feature Engineering. Computation 2025. submitted. [Google Scholar]
- Rashkin, H.; Choi, E.; Jang, J.Y.; Volkova, S.; Choi, Y. Truth of Varying Shades: Analyzing Language in Fake News and Political Fact-Checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Association for Computational Linguistics: Vienna, Austria, 2017; pp. 2931–2937. [Google Scholar] [CrossRef]
- Khanday, A.M.U.D.; Khan, Q.R.; Rabani, S.T. Detecting Textual Propaganda Using Machine Learning Techniques. Baghdad Sci. J. 2021, 18, 0199. [Google Scholar] [CrossRef]
- Barrón-Cedeño, A.; Jaradat, I.; Da San Martino, G.; Nakov, P. Proppy: Organizing the news based on their propagandistic content. Inf. Process. Manag. 2019, 56, 1849–1864. [Google Scholar] [CrossRef]
- Khanday, A.M.U.D.; Khan, Q.R.; Rabani, S.T. SVMBPI: Support Vector Machine-Based Propaganda Identification. In Cognitive Informatics and Soft Computing; Mallick, P.K., Bhoi, A.K., Marques, G., de Albuquerque, V.H.C., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2021; Volume 1317, pp. 445–455. [Google Scholar] [CrossRef]
- Gupta, P.; Saxena, K.; Yaseen, U.; Runkler, T.; Schütze, H. Neural Architectures for Fine-Grained Propaganda Detection in News. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Vienna, Austria, 2019; pp. 92–97. [Google Scholar] [CrossRef]
- Li, J.; Ye, Z.; Xiao, L. Detection of Propaganda Using Logistic Regression. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Vienna, Austria, 2019; pp. 119–124. [Google Scholar] [CrossRef]
- Khanday, A.M.U.D.; Wani, M.A.; Rabani, S.T.; Khan, Q.R.; El-Latif, A.A.A. HAPI: An efficient Hybrid Feature Engineering-based Approach for Propaganda Identification in social media. PLoS ONE 2024, 19, e0302583. [Google Scholar] [CrossRef]
- Samir, A.; Soliman, A.B.; Ibrahim, M.; Hesham, L.; El-Beltagy, S.R. NGU_CNLP at WANLP 2022 Shared Task: Propaganda Detection in Arabic. In Proceedings of the Seventh Arabic Natural Language Processing; WANLP: Abu Dhabi, United Arab Emirates, 2022. [Google Scholar]
- Kausar, S.; Tahir, B.; Mehmood, M.A. ProSOUL: A Framework to Identify Propaganda From Online Urdu Content. IEEE Access 2020, 8, 186039–186054. [Google Scholar] [CrossRef]
- Wang, L.; Shen, X.; de Melo, G.; Weikum, G. Cross-Domain Learning for Classifying Propaganda in Online Contents. arXiv 2020, arXiv:2011.06844. [Google Scholar] [CrossRef]
- Polonijo, B.; Suman, S.; Simac, I. Propaganda Detection Using Sentiment Aware Ensemble Deep Learning. In Proceedings of the 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 27 September–1 October 2021; IEEE: New York City, NY, USA, 2021; pp. 199–204. [Google Scholar] [CrossRef]
- Tiwari, P.; Eswari, R. An LSTM based Propaganda Detection System for News Articles. In Proceedings of the 2023 International Conference on Computational Intelligence, Communication Technology and Networking (CICTN), Ghaziabad, India, 20–21 April 2023; pp. 728–733. [Google Scholar] [CrossRef]
- Da San Martino, G.; Barrón-Cedeño, A.; Wachsmuth, H.; Petrov, R.; Nakov, P. SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; International Committee for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1377–1414. [Google Scholar] [CrossRef]
- Pauli, A.; Derczynski, L.; Assent, I. Modelling Persuasion through Misuse of Rhetorical Appeals. In Proceedings of the Second Workshop on NLP for Positive Impact (NLP4PI), Abu Dhabi, United Arab Emirates, 7 December 2022; Association for Computational Linguistics: Vienna, Austria, 2022; pp. 89–100. [Google Scholar] [CrossRef]
- Abdullah, M.; Abujaber, D.; Al-Qarqaz, A.; Abbott, R.; Hadzikadic, M. Combating propaganda texts using transfer learning. IAES Int. J. Artif. Intell. IJ-AI 2023, 12, 956. [Google Scholar] [CrossRef]
- Chavan, T.; Kane, A.M. ChavanKane at WANLP 2022 Shared Task: Large Language Models for Multi-label Propaganda Detection. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 8 December 2022; Association for Computational Linguistics: Vienna, Austria, 2022; pp. 515–519. [Google Scholar] [CrossRef]
- Gaanoun, K.; Benelallam, I. SI2M & AIOX Labs at WANLP 2022 Shared Task: Propaganda Detection in Arabic, A Data Augmentation and Named Entity Recognition Approach. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 8 December 2022. [Google Scholar]
- Laskar, S.R.; Singh, R.; Khilji, A.F.U.R.; Manna, R.; Pakray, P.; Bandyopadhyay, S. CNLP-NITS-PP at WANLP 2022 Shared Task: Propaganda Detection in Arabic using Data Augmentation and AraBERT Pre-trained Model. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 8 December 2022; Association for Computational Linguistics: Vienna, Austria, 2022; pp. 541–544. [Google Scholar] [CrossRef]
- Lamsiyah, S.; Mahdaouy, A.; Alami, H.; Berrada, I.; Schommer, C. UL & UM6P at ArAIEval Shared Task: Transformer-based model for Persuasion Techniques and Disinformation detection in Arabic. In Proceedings of the ArabicNLP 2023, Singapore, 23 November 2023; Association for Computational Linguistics: Vienna, Austria, 2023; pp. 558–564. [Google Scholar] [CrossRef]
- Nabhani, S.; Borg, C.; Micallef, K.; Al-Khatib, K. Integrating Argumentation Features for Enhanced Propaganda Detection in Arabic Narratives on the Israeli War on Gaza. In Proceedings of the first International Workshop on Nakba Narratives as Language Resources, Online, 20 January 2025; Jarrar, M., Habash, H., El-Haj, M., Eds.; Association for Computational Linguistics: Vienna, Austria, 2025; pp. 127–149. Available online: https://aclanthology.org/2025.nakbanlp-1.14/ (accessed on 3 May 2025).
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. arXiv 2021, arXiv:2003.00104. Available online: http://arxiv.org/abs/2003.00104 (accessed on 1 May 2022).
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
- Vandenhende, S.; Georgoulis, S.; Proesmans, M.; Dai, D.; Gool, L. Revisiting Multi-Task Learning in the Deep Learning Era. arXiv 2020. Available online: https://www.semanticscholar.org/paper/6a248e075035cc6f17a64ed4336a507faad1f72e (accessed on 11 May 2025).
- Chen, S.; Zhang, Y.; Yang, Q. Multi-Task Learning in Natural Language Processing: An Overview. arXiv 2024, arXiv:2109.09138. [Google Scholar] [CrossRef]
- Liu, S.; Johns, E.; Davison, A.J. End-to-End Multi-Task Learning with Attention. arXiv 2019, arXiv:1803.10704. [Google Scholar] [CrossRef]
- Lin, B.; Ye, F.; Zhang, Y.; Tsang, I.W. Reasonable Effectiveness of Random Weighting: A Litmus Test for Multi-Task Learning. arXiv 2021, arXiv:2111.10603. [Google Scholar]
- Song, W.; Song, Z.; Liu, L.; Fu, R. Hierarchical Multi-task Learning for Organization Evaluation of Argumentative Student Essays. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, International Joint Conferences on Artificial Intelligence Organization, Yokohama, Japan, 11–17 July 2020; pp. 3875–3881. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. arXiv 2018, arXiv:1705.07115. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Vienna, Austria, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. Available online: http://arxiv.org/abs/1711.05101 (accessed on 10 September 2024). [CrossRef]
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009; p. 569. [Google Scholar]
- Sanh, V.; Wolf, T.; Ruder, S. A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks. arXiv 2018, arXiv:1811.06031. [Google Scholar] [CrossRef]
- Yu, T.; Kumar, S.; Gupta, A.; Levine, S.; Hausman, K.; Finn, C. Gradient Surgery for Multi-Task Learning. arXiv 2020, arXiv:2001.06782. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Language | Model Name | MTL Used? | Best Score | Limitation |
|---|---|---|---|---|---|
| [15] | English | BERT | ✓ | 0.4074 F1-Score | Marginal benefit from MTL due to insufficiently strong relationships between the main and auxiliary tasks. |
| [16] | English | BERT | ✓ | 0.4080 F1-Micro | Limited performance gains from MTL, constrained by dataset size and the weak interdependence between tasks; avoids considering the relationship between propaganda and other related tasks. |
| [17] | Arabic | AraBERT with CRF | ✓ | 0.396 F1-Score | Marginal performance due to limited data size, affecting span extraction and classification accuracy. Also, the relationship with other opinion dimensions is not taken into account. |
| [18] | Arabic | AraBERT, MARBERT | ✓ | 0.7634 F1-Micro | Limited by the reliance on content-type integration, which may not generalize well across domains. In addition, the analysis disregards any associations with additional opinion dimensions. |
| [19] | Arabic | GPT-3 | ✓ | 0.5347 F1-Micro | Performance is limited by dependence on prompt engineering and few-shot learning in the LLM-based approach. Moreover, interactions with other opinion dimensions are excluded from consideration. |
| [23] | Arabic | AraBERT | × | 0.750 F1-Macro | Considers only individual tasks without multi-task relationships. |
| [26] | English | Maximum entropy, Naive Bayes LSTM | × | 0.5600 F1-Score | Requires significant time and effort for feature extraction. |
| [27] | English | Naive Bayes, SVMs | × | 0.765, F1-Score | Generates a static embedding for each word without capturing the entire context of words used. |
| [28] | English | Maximum entropy, SVM | × | 97.15% accuracy | Requires explicit feature extraction methods and handles only single-task scenarios, missing multi-task learning advantages. |
| [29] | English | SVM | × | 0.81 F1-Score | Handles only individual tasks without considering related tasks. |
| [30] | English | Logistic Regression, CNN, BERT, LSTM-CRF | × | 0.6231 F1-Score | Avoids integrating related tasks, limiting performance due to task isolation. |
| [31] | English | Logistic regression | × | 0.6616 F1-Score | Limited by the simplicity of logistic regression, restricting its ability to model complex textual features. |
| [32] | English | SVM, Naïve Bayes, Decision Tree, Logistic Regression | × | 0.647 F1-Score | Limited by dependency on manual hybrid feature engineering, impacting generalization to other domains. |
| [33] | Arabic | SVM, Naïve Bayes, Stochastic Gradient Descent, Logistic Regression, Random Forests, K-nearest Neighbor, AraBERT | × | 0.649 F1-Score | Demands an extensive amount of data to effectively train the deep model Require feature extraction methods; considers only individual tasks without multi-task relationships. |
| [34] | Urdu | CNN and Logistic Regression | × | 91% accuracy | Limited by single-task focus without task interactions. |
| [35] | English | LSTM | × | 0.687 F1-Score | Demands an extensive amount of data to effectively train the deep model. |
| [36] | English | Gradient Boosting, LSTM | × | 96.00% Accuracy | Considers only individual tasks without multi-task relationships. |
| [37] | English | Bi-LSTM | × | 0.7500 F1-Score | Limited scalability due to the training complexity of Bi-LSTM, especially with larger datasets. |
| [39] | English | ROBERTA | × | 88.32% Accuracy | Considers only individual tasks without multi-task relationships. |
| [40] | English | RoBERTa, BERT, DeBERTa | × | 0.6000 F1-Score | |
| [41] | Arabic | AraBERT, MARBERT, ARBERT, XLMRoBERTa, AraELECTRA. DeHateBERT | × | 0.565 F1-Score | Considers only individual tasks without multi-task relationships. |
| [42] | Arabic | AraBERT | × | 0.5850 F1-Micro | Relies on named entity recognition and data augmentation, limiting effectiveness across varying propaganda techniques. |
| [43] | Arabic | AraBERT | × | 0.6020 F1-Micro | Data augmentation may introduce noise, limiting the robustness of AraBERT in propaganda detection. |
| [44] | Arabic | AraBERT-Twitter-v2 | × | 0.5666 F1-Micro | Considers only individual tasks without multi-task relationships. |
| [45] | Arabic | GPT-4 | × | 0.4025 F1-Micro | Limited by GPT-4’s sensitivity to prompts, affecting performance consistency across varied narratives. |
| [24] | Arabic | LlamaLens | × | 0.747 F1-Micro | Performance is limited by multilingual capability constraints and domain-specific fine-tuning requirements. |
| Symbol | Explanation |
|---|---|
| T | Total number of tasks t = (1, …, T) |
| Dt | Training data for task t |
| N | Number of examples in Dt |
| Input text x = (x1, …, xN) | |
| Task descriptor generated in the shared layers | |
| Shared parameters during the encoding stage | |
| Task-specific parameters for output decoder heads |
| Feature | Single-Task Model | MTL Model |
|---|---|---|
| Dataset | ||
| Task Descriptor | Not used | |
| Loss Function | L | |
| Objective Function | ||
| Model |
| Task | Label | Train | Test |
|---|---|---|---|
| Propaganda | True | 62.99% | 62.9% |
| False | 37.01% | 37.1% | |
| Sentiment | Positive | 35.60% | 37.4% |
| Negative | 42.70% | 40.4% | |
| Neutral | 21.70% | 22.2% | |
| Emotion | Happiness | 29.80% | 31.5% |
| Sadness | 20.40% | 24.5% | |
| Anger | 16.50% | 14.4% | |
| Fear | 4.60% | 3.4% | |
| None | 28.60% | 26.2% |
| Model Categories | Model Name | Model Description |
|---|---|---|
| MTL Models | MTL-UAW | A parallel multi-task learning model that leverages three tasks, propaganda, sentiment, and emotion, and utilizes uniform averaging weighting. This model is shown in Figure 1. |
| MTL-LS | A parallel multi-task learning model that leverages three tasks, propaganda, sentiment, and emotion, and utilizes linear scalarization weighting. This model is shown in Figure 1. | |
| MTL-Sent-UAW (PSMTL-UAW) | An MTL model that leverages two tasks, propaganda and sentiment, and utilizes uniform averaging weighting. | |
| MTL-Sent-LS (PSMTL-LS) | An MTL model that leverages two tasks, propaganda and sentiment, and utilizes linear scalarization weighting. | |
| MTL-Emo-UAW (PEMTL-UAW) | An MTL model that leverages two tasks. propaganda and emotion, and utilizes uniform averaging weighting. | |
| MTL-Emo-LS (PEMTL-LS) | An MTL model that leverages two tasks, propaganda and emotion, and utilizes linear scalarization weighting. | |
| Proposed Task-Weighting | MTL-DDW | An MTL setting that utilizes dynamic difficulty weighting. |
| MTL-PGRW (NormalDist) | An MTL setting that utilizes priority-guided random weighting, based on a normal sampling distribution. | |
| MTL-PGRW (BernoulliDist) | An MTL setting that utilizes priority-guided random weighting, based on a Bernoulli sampling distribution. | |
| MTL-PGRW (UniformDist) | An MTL setting that utilizes priority-guided random weighting, based on a uniform sampling distribution. | |
| MTL-HW | An MTL setting that utilizes hierarchical weighting. | |
| MTL-UW | An MTL setting that utilizes uncertainty weighting. | |
| MTL-PASUW | An MTL setting that utilizes priority-aware softmax-based uncertainty weighting. | |
| MTL Models with the Best Proposed Task-Weighting | MTL-Sent-UW (PSMTL-UW) | An MTL model that leverages two tasks, propaganda and sentiment, and utilizes uncertainty weighting. |
| MTL-Emo-UW (PEMTL-UW) | An MTL model that leverages two tasks, propaganda and emotion, and utilizes uncertainty weighting |
| Hyperparameter | Value |
|---|---|
| Max. sequence length | 256 |
| Batch size | 8 |
| Number of epochs | 5 |
| Early stop patience | 2 |
| Optimizer | AdamW |
| Learning rate | 2 × 10−5 |
| Weight decay | 0.001 |
| Actual/Predicted | Propaganda (True) | Nonpropaganda (False) |
|---|---|---|
| Propaganda (True) | True Positive (TP) | False Negative (FN) |
| Nonpropaganda (False) | False Positive (FP) | True Negative (TN) |
| Model Categories | Model Name | Accuracy | Macro F1 | Micro F1 |
|---|---|---|---|---|
| MTL Models | MTL-LS | 79% | 0.775 | 0.790 |
| MTL- UAW | 77% | 0.763 | 0.777 | |
| MTL-Sent-LS | 79% | 0.778 | 0.792 | |
| MTL-Sent- UAW | 78% | 0.770 | 0.784 | |
| MTL-Emo- LS | 78% | 0.773 | 0.789 | |
| MTL-Emo- UAW | 79% | 0.775 | 0.791 |
| Model Categories | Model Name | Accuracy | Macro F1 | Micro F1 |
|---|---|---|---|---|
| Proposed Task-Weighting | MTL-DDW | 79% | 0.772 | 0.790 |
| MTL-PGRW (NormalDist) | 78% | 0.767 | 0.784 | |
| MTL-PGRW (BernoulliDist) | 77% | 0.765 | 0.778 | |
| MTL-PGRW (UniformDist) | 78% | 0.764 | 0.782 | |
| MTL-HW | 79% | 0.775 | 0.791 | |
| MTL-UW | 79% | 0.776 | 0.790 | |
| MTL-PASUW | 78% | 0.765 | 0.782 | |
| MTL Models with best Proposed Task-Weighting | MTL-Sent-UW | 79% | 0.778 | 0.791 |
| MTL-Emo-UW | 79% | 0.777 | 0.795 |
| Model | Accuracy | Macro-F1 | Micro-F1 |
|---|---|---|---|
| STL-AraBERT [22] | 77% | 0.756 | 0.769 |
| STL-AraBERT with Features [25] | 78% | 0.768 | 0.785 |
| STL-ML with Features [25] | 75% | 0.708 | 0.755 |
| STL-AraBERT [23] | NA | 0.750 | 0.767 |
| STL-LlamaLens: Specialized Multilingual LLM [24] | NA | NA | 0.747 |
| MTL-MARBERT [6] | 76% | 0.742 | 0.757 |
| MTL-Sent-LS (ours) | 79% | 0.778 | 0.792 |
| MTL-Sent-UW (ours) | 79% | 0.778 | 0.791 |
| Metric | MTL-Sent-LS Mean | MTL-MARBERT Mean | t-Statistic | p-Value | Significant (p < 0.05) |
|---|---|---|---|---|---|
| Accuracy | 0.79% | 0.76% | 9.285295 | 0.000748 | True |
| Macro F1 | 0.778 | 0.742 | 13.132868 | 0.000194 | True |
| Micro F1 | 0.791 | 0.757 | 9.285295 | 0.000748 | True |
| Model | FP | FN | Total Errors | Accuracy | Recall (Class Propaganda) |
|---|---|---|---|---|---|
| MTL-Sent-UW | 133 | 142 | 275 | 0.7926 | 0.8293 |
| MTL-Emotion-UW | 138 | 131 | 269 | 0.7971 | 0.8425 |
| Model | Type-1 | Type-2 | Type-3 | Type-4 |
|---|---|---|---|---|
| MTL-Sent-UW | 52% | 25% | 10% | 13% |
| MTL-Emotion-UW | 53% | 27% | 9% | 11% |
| Arabic Text | English Text | Predicted Label | TrueLabel | Justification |
|---|---|---|---|---|
| وجاء إعلان السلطات السورية لينفي معلومات نشرها موقع البعث ميديا نقل تصريحات لمدير صحة السويداء الدكتور نزار مهنا قال إن مواطنين دخلوا البلاد بطرق شرعية يلتزمون بالحجر الصحي في منازلهم المراقبة الصحية | The announcement by the Syrian authorities came to deny information published by the Al-Baath Media website, which reported statements by the Director of Health in Al-Suwayda, Dr. Nizar Muhanna, who said that citizens who entered the country through legal means are adhering to home quarantine and health monitoring. | Propaganda | Nonpropaganda | Neutral official denial misclassified as propaganda, likely due to formal tone and presence of official entities triggering propaganda cues. |
| واعتبرت جبهة بوليساريو أن العملية المغربية أنهت وقف إطلاق النار الموقع عام برعاية الأمم المتحدة، عاماً القتال. | The Polisario Front considered that the Moroccan operation ended the ceasefire agreement signed under the auspices of the United Nations, resuming the years of fighting. | Propaganda | Nonpropaganda | Factual political statement misclassified due to conflict-related terminology, causing false alarms. |
| التقى رئيس وزراء الاحتلال بنيامين نتنياهو الثلاثاء برئيس المجلس الوزاري التشادي عبد الكريم ديبي نجل الرئيس إدريس ديبي ورئيس المخابرات التشادية أحمد كغاري | The Israeli Prime Minister Benjamin Netanyahu met on Tuesday with the Chadian Ministerial Council President Abdel Karim Déby, the son of President Idriss Déby, and the Chadian Intelligence Chief Ahmed Kogri. | Nonpropaganda | Propaganda | Propaganda missed due to neutral diplomatic reporting and subtle framing, lacking explicit manipulative cues. |
| قالت المنظمة الكندية الحكومية إن ثمة تقارير حكومية مسربة تظهر بأن استشراء المرض يشمل انتشار صنف بلازموديوم فيفاكس العصِيّ على العلاج. | The Canadian governmental organization stated that there are leaked government reports indicating that the spread of the disease includes the proliferation of the Plasmodium vivax strain, which is resistant to treatment. | Propaganda | Nonpropaganda | Factual health news misclassified as propaganda because of alarming language (“leaked,” “spread”), resulting in false positives. |
| يملك لبنان تجهيزات لإدارة الكوارث وإمكانات تقنية متقدمة، وسارعت دول عدة إلى إرسال فرق إغاثة ومساعدات تقنية لمساعدته بعد الانفجار. | Lebanon possesses disaster management equipment and advanced technical capabilities, and several countries quickly sent relief teams and technical assistance to help it after the explosion. | Nonpropaganda | Propaganda | Positive news on disaster response may contain subtle persuasive framing missed by the model, leading to false negatives. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Henaki, L.; Al-Khalifa, H.; Al-Salman, A. Enhancing Propaganda Detection in Arabic News Context Through Multi-Task Learning. Appl. Sci. 2025, 15, 8160. https://doi.org/10.3390/app15158160
Al-Henaki L, Al-Khalifa H, Al-Salman A. Enhancing Propaganda Detection in Arabic News Context Through Multi-Task Learning. Applied Sciences. 2025; 15(15):8160. https://doi.org/10.3390/app15158160
Chicago/Turabian StyleAl-Henaki, Lubna, Hend Al-Khalifa, and Abdulmalik Al-Salman. 2025. "Enhancing Propaganda Detection in Arabic News Context Through Multi-Task Learning" Applied Sciences 15, no. 15: 8160. https://doi.org/10.3390/app15158160
APA StyleAl-Henaki, L., Al-Khalifa, H., & Al-Salman, A. (2025). Enhancing Propaganda Detection in Arabic News Context Through Multi-Task Learning. Applied Sciences, 15(15), 8160. https://doi.org/10.3390/app15158160