Abstract
In novels, readers encounter a variety of characters with distinct personalities, and their satisfaction tends to increase when each character’s utterances consistently reflect their unique traits. Recent advances in large language model (LLM) technology have made it possible to perform complex tasks such as generating long-form narratives and adapting writing styles. However, research on generating character utterances that reflect individual personalities remains limited. In this paper, we identify a key challenge in this task, namely the unconscious influence of the author’s writing style, and propose a novel clustering-based method to mitigate this problem by tuning large language models. We manually annotated Big Five personality trait scores for characters appearing in selected novels and designed prompts to generate examples for instruction-tuning. Experimental results demonstrate that language models trained using our proposed method produce utterances that more consistently reflect character personalities compared to untuned models.
1. Introduction
Large language models are pre-trained on vast amounts of data and are utilized for various tasks such as machine translation, sentiment analysis, and document summarization. Generative language models, such as GPT-3 [1] and LLaMA [2], in particular, have played a central role in the field of natural language processing and have made significant progress in recent years. However, despite the rapid progress of LLMs, their general-purpose nature can lead to suboptimal performance compared to models specialized for specific domains or tasks (e.g., code generation [3], medical applications [4,5], and style-based literature writing [6]).
While current research on novel generation using LLMs primarily focuses on maintaining consistent story plots [7]. In contrast, relatively little research has focused on the consistency of character presentation. Existing approaches to character-centered storytelling focus only on aligning character actions with consistent character presentation [8], and do not consider personality-level consistency in character utterances.
When reading a novel, if the characters speak consistently with their personalities, it enhances the sense of realism; otherwise, the reader’s satisfaction may decrease. Writers strive to create realistic characters for their readers, but often characters with different personalities speak in similar ways. Prior studies have shown that an individual’s linguistic style (idiolect) tends to be consistently reflected in their writing [9], and that an author’s stylistic tendencies appear throughout a text, whether consciously or unconsciously [10]. It has also been reported that an author’s stylistic tendencies may unintentionally manifest in character utterances, potentially weakening the unique characteristics of the characters [11]. We call this “unconscious author style,” that the writer unconsciously influences the character’s thoughts, emotions, and utterances [12,13]. That is, “unconscious author style” refers to the phenomenon in which an author’s linguistic style unintentionally intrude upon the utterances of characters, thereby blurring or diluting their personalities. Minimizing such interference would facilitate the generation of utterances that align more closely with each character’s personality traits, resulting in more plausible and consistent dialogue.
As far as we know, there have been no studies aimed at reducing the “unconscious author style” on characters’ utterances. Some previous studies have tried to generate character utterances, but they were only for free conversation, drama or games, without considering the “unconscious author style” issue [14,15]. In this paper, we focus on the way of speaking (i.e., linguistic style) of characters in novels. Specifically, based on previous findings that the linguistic style has a strong relationship with personality [16], we design a new method that generates personality-consistent utterances of characters in novels. To achieve this goal, we use instruction-tuning to construct a new language model that is tuned to generate utterances that reflect the personalities of the target characters, while suppressing the influence of “unconscious author style” on their dialogue.
To handle the personality of the characters, we adopt the Five-Factor Model of Personality (FFM), also known as the “Big Five” or OCEAN traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism [17]. Based on the theory of OCEAN traits, we assume that the characters’ utterances reflect their distinct personalities even though they are not real people. To validate this, we manually annotated the OCEAN trait scores of novel characters, and generated two different character clusters: word-based clusters and personality-based clusters. The word-based clusters are obtained from the words of the characters’ utterances, while the personality-based clusters are created from the characters’ OCEAN trait scores. We observed that the word-based clusters show a similar trend to the personality-based clusters, i.e., the characters with similar personality traits have similar word distributions in their utterances.
Based on the finding of the above assumption, our hypothesis is that a language model trained on utterances of character clusters can translate a given utterance into a new utterance that better reflects the personality of a target character cluster. That is, even though a character’s utterances may reflect the “unconscious author style” (i.e., linguistic patterns of the author), using the utterances of numerous similar characters from different novels will reduce the impact of the “unconscious author style.” This study does not aim to prevent changes in a character’s personality, but rather focuses on addressing the problem of the unconscious author style unintentionally influencing character utterances. If this hypothesis holds, then the language model will contribute greatly to the novel-writing process.
Suppose that a novelist has defined the personality of a main character in her/his novel, and she/he has found that the personality of the main character is close to the character cluster ‘A’. When the main character needs to deliver a line like “I never want to go back to my hometown,” the language model is prompted to generate a translated version of the line that matches the personality of the cluster ‘A’, so that the translated utterance will better reflect the personality that the novelist intended.
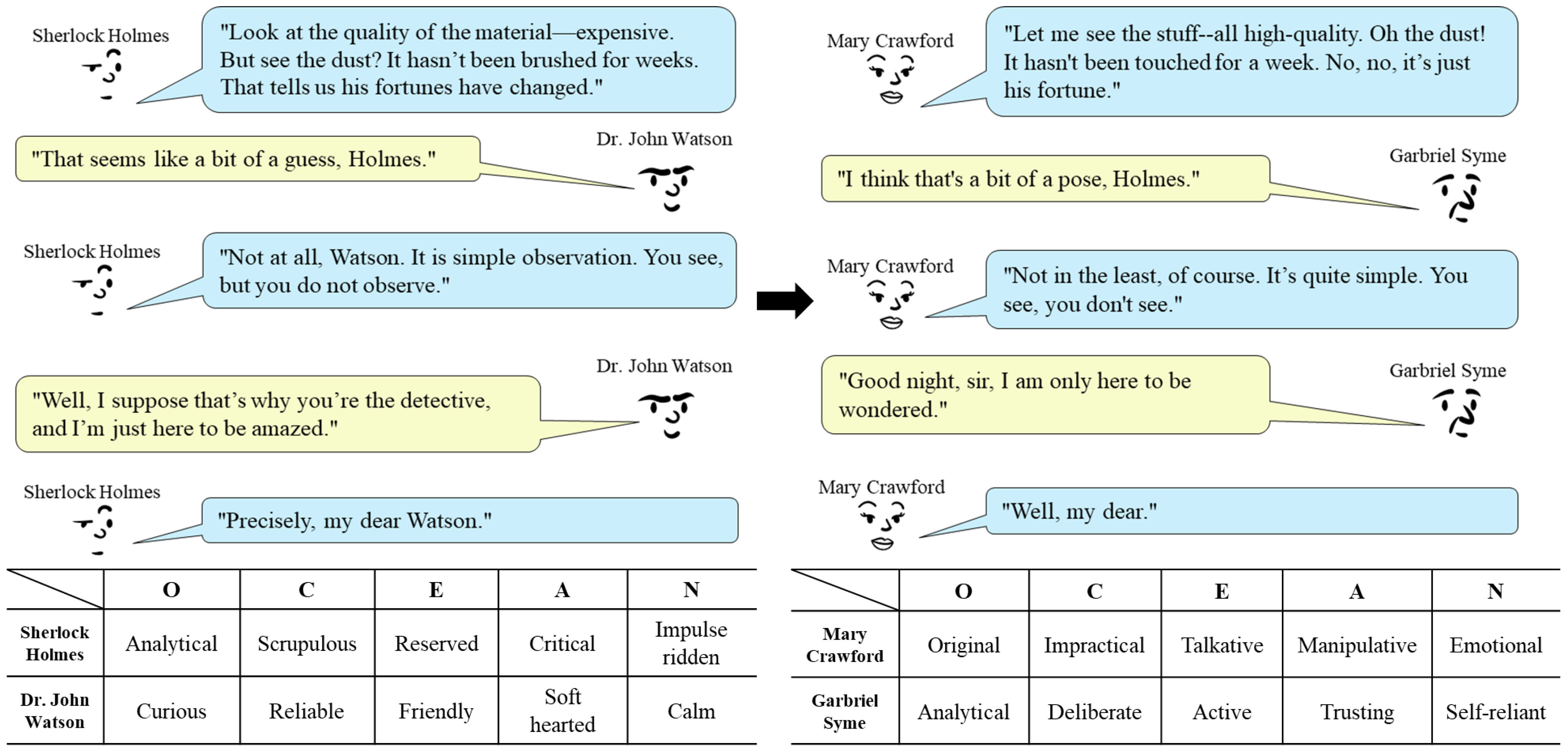
Figure 1 shows an example of such a translation, where the left conversation is adapted from the Sherlock Holmes stories “The Adventure of the Blue Carbuncle” [18] and “A Scandal in Bohemia” [19] and the right conversation is a translated version using our language model. The bottom of Figure 1 shows the personality difference between the characters by representative per-trait keywords [20]. Note that we have two target character clusters in the right conversation, each represented by Mary Crawford (Mansfield Park) and Gabriel Syme (The Man Who Was Thursday). The translated version is created by prompting our language model to translate the utterances of Holmes and Watson into the utterances of Crawford and Syme, respectively. As shown in the translated conversation, the translated utterances seem to successfully reflect the personality of Crawford and Syme.
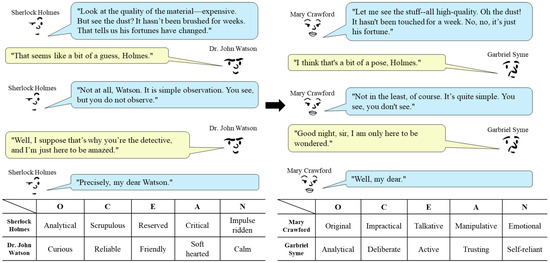
Figure 1.
An example of utterance translation. The conversation between Holmes and Watson adapted from the Sherlock Holmes stories [18,19] (left) is translated into a conversation between two different characters (right). The lower table describes the personalities of the four characters by their per-trait keywords (all keywords can be found in Table 1).
This study addresses the following research question: Can we generate character utterances that better reflect their personality by using language models to mitigate the influence of the unconscious author style? Our contributions can be summarized as follows.
- 1.
- We present a language model that is tuned for translating a given utterance into a new utterance that better reflects a desired personality in novel. As far as we know, this is the first language model designated for generating utterances reflecting personality in novels.
- 2.
- We propose a method for building our language model. It involves (1) clustering characters using utterance words, and (2) prompt design for instruction-tuning data preparation using the character clusters.
2. Related Work
2.1. Transformer Decoder-Based Language Models
Since Transformer, many Transformer decoder-based language models have appeared and demonstrated their superior performance in natural language generation (NLG) tasks [21]. Previous studies have found that larger decoder-based models achieve better performance in many tasks, and such large language models (LLMs) can be divided into two groups: open-source LLMs and closed-source LLMs. The closed-source LLMs do not disclose their specification and parameter weights, and representative models include the GPT series [1,22,23] and Gemini [24]. On the other hand, the open-source LLMs provide publicly available source code, allowing community collaboration, customization, and transparency. Some models even provide training datasets. Representative open-source LLMs include the Llama series [2,25], Falcon [26], Gemma series [27,28], Pythia [29], and Mistral [30].
Because of their greater accessibility, the open-source LLMs are more widely used as backbone models for research purposes. Despite recent advances in training methods for decoder-based LLMs, domain- and task-specific models often outperform general-purpose models. This is because decoder-based LLMs are typically trained to be broadly applicable, and as a result, they tend to exhibit weaknesses in some domains. For example, as highlighted in a recent study by Gu et al. (2023), LLMs trained on general-purpose datasets often struggle to handle domain-specific elements such as frequently used APIs and libraries [3]. A representative example of a domain-specific model is Med-PaLM 2, which shows significantly better performance in the medical domain compared to models such as GPT-3.5 and PaLM [5,31]. Furthermore, existing studies on character utterance generation have focused solely on reflecting the personality of the character, without considering the issue of “unconscious author style.” There are several ways to tune the decoder-based LLMs. Few-shot learning demonstrates strong performance with only a small number of examples by leveraging their pre-trained knowledge. In particular, instruction-tuning is an effective prompt-based approach that trains models on explicit instruction-response pairs, enabling them to understand and execute complex and abstract commands. This method allows the model to be applied to different downstream tasks without requiring full parameter fine-tuning, while still achieving strong generalization performance. Furthermore, it is a parameter-efficient strategy that is well-suited for decoder-based LLMs, as it can yield competitive results even with limited training data. Thus, we construct a specialized LLM through the instruction-tuning that mitigates the influence of the “unconscious author style” while generating sentences that reflect the character’s personality.
2.2. The Big Five Personality Traits (OCEAN)
The Five Factor Model of Personality (FFM), also known as the “Big Five,” is a widely used theoretical model of human personality in recent psychology. It includes the OCEAN traits: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. These traits are known to include various personality-related factors such as happiness, health, religion, identity, job satisfaction, political beliefs, etc. [32]. Each trait can be represented as a score (e.g., an integer value between −3 and 3), where the magnitude of the value indicates the strength of the corresponding trait. In addition, the traits can be represented by personality-related keywords, as described in Table 1 [20]. In this paper, we manually annotated OCEAN trait scores for characters from selected classic English novels and used them to test a correlation between character utterances and their personality. Details about the dataset annotation process and result are provided in the next section.

Table 1.
Keywords representing low and high OCEAN traits scores [20].
3. Materials and Methods
3.1. Validity of Using Character Utterances
Before developing our language model for utterance translation, we investigated whether the use of utterances really reflects the personality of characters. That is, although the previous studies have already found that linguistic style in novels has a strong relationship with personality [16], we wanted to answer the question “Do the characters who are similar in terms of personality really talk in a similar way?” because the characters are not real people, but only fictional characters.
Based on the Big Five traits, we first annotated the OCEAN scores of 28 novels from the Project Dialogism Novel Corpus (PDNC) [33]. PDNC was chosen for the data because it is a structured corpus of character utterances extracted from a variety of classic English and American novels, and because it is manually identified and annotated by experts in Western literature. Specifically, to control for factors such as genre and historical context, we used the PDNC dataset, which focuses on 19th- and early 20th-century English and American novels. It primarily includes works by authors like Jane Austen, E. M. Forster, and Henry James, whose writings center on domestic life and individual relationships, enabling experiments on a relatively cohesive and thematically consistent set of classic literary texts. The 28 novels include A Handful of Dust, A Passage to India, A Room with a View, Alice’s Adventures in Wonderland, Anne of Green Gables, Daisy Miller, Emma, Hard Times, Howards End, Mansfield Park, Night and Day, Northanger Abbey, Oliver Twist, Persuasion, Pride and Prejudice, Sense and Sensibility, The Age of Innocence, The Awakening, The Gambler, The Invisible Man, The Man Who Was Thursday, The Mysterious Affair at Styles, The Picture of Dorian Gray, The Sign of the Four, The Sport of the Gods, The Sun Also Rises, Where Angels Fear to Tread and Winnie-the-Pooh.
Each character in the novels is annotated with five scores ranging from −3 to 3, each corresponding to one of the five traits O, C, E, A, and N. The annotation was performed by five graduate assistants trained in literary studies. Each character was annotated by two annotators. Personality can be assessed through either self-report or report-by-others methods. Since the process of constructing a personality annotated dataset is inherently challenging, a recent study that released a new dataset for over 1000 individuals also adopted the report-by-others method for personality annotation [34]. We adopted the report-by-others method in this study, as the subjects of personality measurement are fictional rather than real individuals. We filtered characters that did not have enough utterances and obtained 139 characters. Pearson correlation coefficients are 0.51, 0.43, 0.30, 0.51, and 0.36, for O, C, E, A, and N.
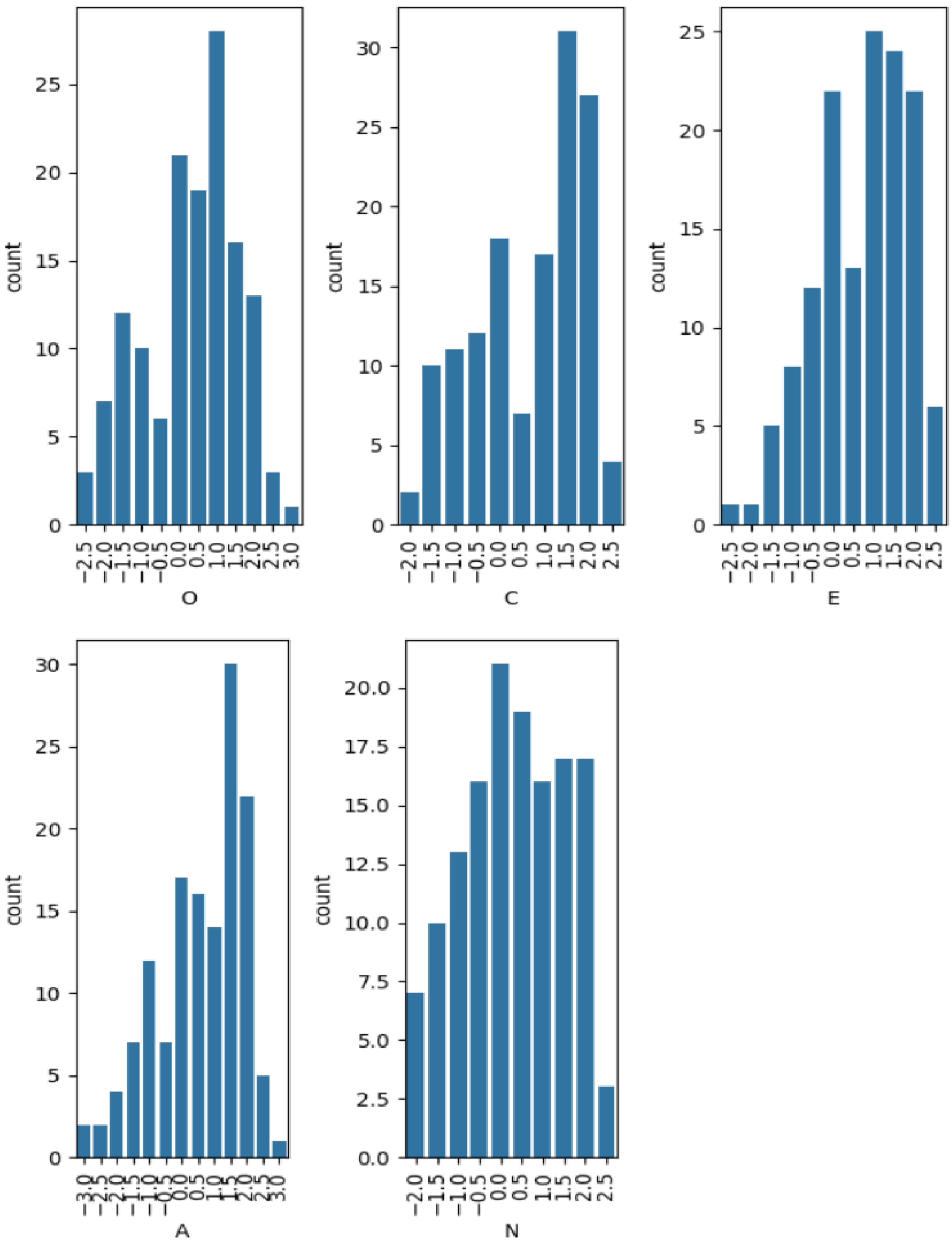
According to [35], these coefficients are regarded as medium or large. We also computed Intraclass Correlation Coefficient (ICC) to assess the reliability of the scores annotated by the annotators for O, C, E, A, and N. ICC(3,1) [36], which measures the consistency of ratings for a single measurement, yielded the following values in our study: O = 0.50, C = 0.42, E = 0.31, A = 0.51, and N = 0.35. These generally showed fair levels of agreement (0.42) [37] with lower consistency observed for E and N. On the other hand, ICC(3,2), which assesses the reliability of the average of two raters, showed generally higher values in our study: O = 0.66, C = 0.59, E = 0.47, A = 0.67, and N = 0.52. These results suggest that the personality trait scores used in this paper provide a reasonable level of reliability. Examples of the annotated characters are shown in Table 2. The OCEAN distributions are shown in Figure 2.
Table 2.
Samples of OCEAN scores on novel characters.
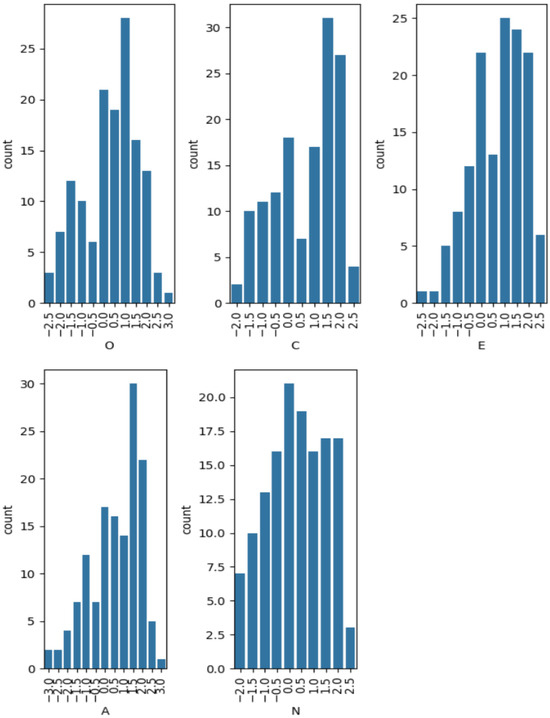
Figure 2.
Per-trait average OCEAN score distributions in our annotated dataset.
Based on the annotated data, we created two different clusters: personality-based clusters and word-based clusters. Since the degree to which a character’s personality is expressed in their utterances may be limited and such utterances may also be influenced by the author’s stylistic tendencies, we cluster utterances from similar characters appearing in different works by different authors, in order to extract more representative personality traits. For the word-based clusters, we removed all nouns and digits in the utterances and performed stemming using a Porter stemmer. The characters with utterances shorter than 100 letters are filtered out. The word-based clusters are created by a bag-of-words approach with TF-IDF on 8000 vocabulary (i.e., unique words), using the k-means algorithm, and the number of clusters is 2. We also get average personality trait scores and normalize the scores to a range between 0 and 1, and create the personality-based clusters using the k-means algorithm. If the personalities of the characters are well reflected in their utterances (i.e., words), those with similar personalities should show close linguistic patterns to each other. Figure 3 shows the t-SNE results of the two different clusters, where the dots are characters. Characters with similar linguistic patterns are shown as nearby dots in the figure, and the color of each dot indicates its arbitrary personality cluster; we do not specify the personalities of the orange and blue clusters here, because we intend to check if the personality-based clusters are consistent with the word-based clusters. The figure shows that the personality clusters (i.e., the orange and blue clusters) have their own distinct centroids even though they overlap somewhat, which means that the characters with similar linguistic patterns tend to have the same personality. Based on this finding, we designed our method for tuning a language model for utterance translation. In particular, we expected that using utterances from similar characters (i.e., characters in close proximity in Figure 3) would reduce the impact of the “unconscious author style” problem. Details of the method are given in the next subsection.

Figure 3.
Graphical representation of two different clusters, where the dots are characters, the colors indicate personality-based clusters, and the position of the dots represent linguistic patterns of the characters.
3.2. Generative Language Model for Character Utterances
Our method consists of 2 steps: (1) cluster generation using character utterances, and (2) instruction-tuning dataset preparation using prompt engineering. The following subsections describe these steps in detail.
3.2.1. Character Clustering Using Utterances
We adopted the Project Dialogism Novel Corpus (PDNC) dataset [33], which consists of 28 novels, to construct a language model. In the PDNC dataset, speakers (i.e., characters) and utterances are provided in a structured form, making it easy to use for our purpose. We have converted the PDNC dataset into a set of character documents. Assume that the original PDNC dataset can be represented as a set = {}, where and represent the i-th character name and an utterance, respectively. Let C be a set of unique characters; note that is not necessarily equal to . Given the original PDNC set, we created a set of character documents = {, ,…}, where denotes a set of all utterances of the j-th character in the character set C. Since this creates a document for each unique character, will be equal to .
Before clustering the character documents, the number of clusters is determined using Silhouette scores and the Elbow method. The character documents are represented in a document-word matrix, and the silhouette score s(·) is calculated using the Equation (1), where i is a data index, a(·) is a mean distance to the other data instances within the same cluster, b(·) is a mean distance to the other clusters. We got the optimal number of clusters is 2 using the silhouette score. We also used the elbow method, which finds the number of clusters using the sum of square errors (SSE), and found that the optimal number of clusters is 2 as shown in Figure 4. The K-means clustering algorithm with Euclidean distance is used to cluster the character documents into two groups. We denote the two clusters as and , and per-cluster character documents = {}.
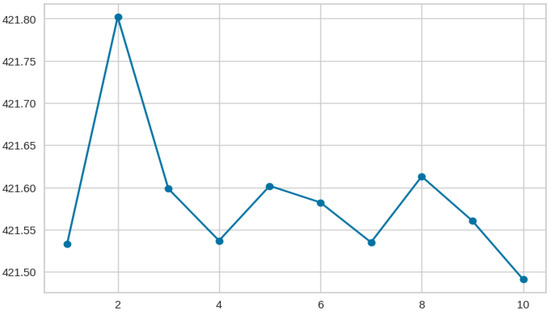
Figure 4.
The optimal number of clusters using the Elbow method, where the x-axis is the number of clusters, and the y-axis is the Within-Cluster Sum of Squares (WCSS).
For each character cluster, the characters at the center have the strongest personality traits of the cluster, while the characters at the outer edges have the weaker personality traits. Using only the strongest characters at the center is not preferable because it suffers from the “unconscious author style” problem. However, using all characters within a cluster is also not a good choice because the outer characters are weak in representing the related personality. Therefore, we selected the top-k center characters for each cluster using silhouette scores, and merged or concatenated the top-k character documents into a single document. We define as the resulting document from the top-k character documents in the cluster .
3.2.2. Instruction-Tuning Dataset Preparation
We use the instruction-tuning approach to tune a decoder-based language model for translating character utterances according to a given personality. In the instruction-tuning approach a dataset is fed to the language model, so that the model generates the desired responses by following the instruction. An example of our instruction-tuning data is shown in Table 3. The instruction-tuning data consists of four parts: instruction, input, representative characters, and response. The instruction provides a general role or rules for the model to follow. The input and response are a neutralized utterance and an original utterance. The original utterance comes from , so this utterance has the personality of the cluster . On the other hand, the neutralized utterance is supposed to have no personality, but the same content as the original utterance. The model will learn how to translate the neutralized utterance (input) into the original utterance (response).
Table 3.
Instruction-tuning data template.
The representative characters are used to inform the model of a desired personality (or a target cluster). That is, instead of using a number or a meaningless symbol (e.g., cluster-01), we use some representative character names to refer to a target cluster.
There are two challenging issues in preparing the instruction-tuning dataset. First, we need to determine the representative characters of each cluster (i.e., the third part of the instruction-tuning data in Table 3). We assume that the representative characters only refer to a target cluster, so we simply take a single character with the best silhouette score.
Gabriel Syme (The Man Who Was Thursday) is chosen as the representative character for , and Mary Crawford (Mansfield Park) is for .
The second challenge is the neutralized utterance (i.e., the second part of the instruction-tuning data in Table 3). We design a few-shot prompt to ask a third-party generative language model, GPT-3.5-Turbo, to generate a neutralized utterance for a given utterance. Table 4 describes the prompt we design. Note that this prompt asks the third-party language model to work in exactly the opposite way that our model does; that is, the third-party language model converts original utterances (i.e., those with strong personality traits) into what we refer to as “neutralized” utterances. We use this term for convenience, but we do not claim that these outputs are truly neutral, only that they are comparatively less marked for personality traits than the originals. In the early stages of data transformation, no in-context examples were available; thus, we initially generated six utterances using a zero-shot prompting strategy. These initial outputs were then incorporated into the prompt as in-context examples, and the generation continued in a few-shot setting for the remaining data.
Table 4.
A prompt designed to generate the neutralized utterances.
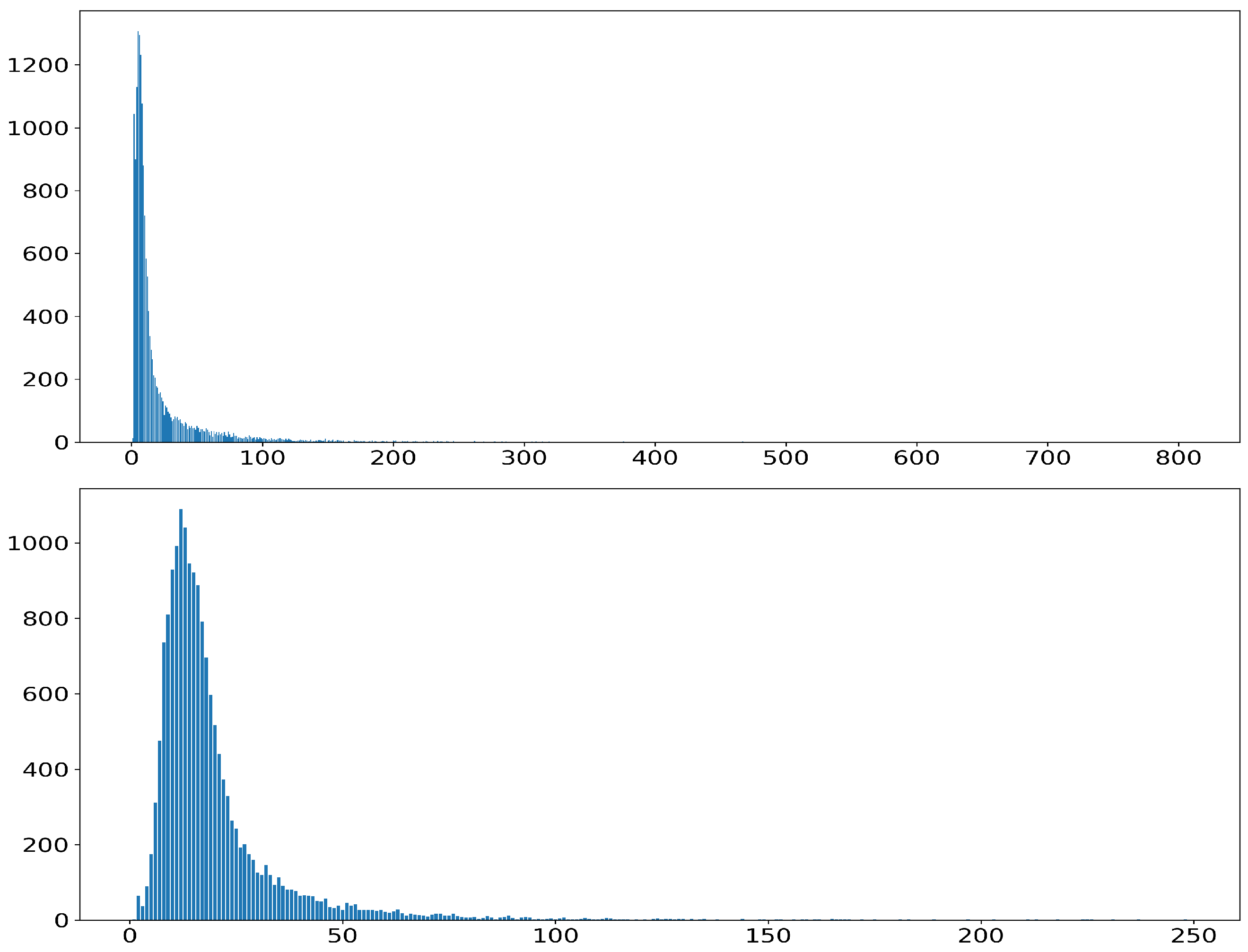
The preparation process for constructing the instruction-tuning dataset is as follows. As shown in Figure 5, an analysis of the word per sentence distribution revealed that sentences containing between 5~200 words accounted for the largest proportion, and we used data that fell within this range. We also chose this range because excessively short or long sentences were considered inappropriate for effectively conveying the character’s personality [38,39]. Figure 5 presents the following visualizations: the distribution of word counts for prompt sentences (top), the distribution of word counts for response sentences (bottom). Based on this, only the sentences with 5~200 words in were used, and the rest were filtered out. For each original sentence in , a neutralized utterance was generated using our designed prompt. We extracted representative character names of the character clusters, and the instruction-tuning dataset was created according to the format in Table 3.
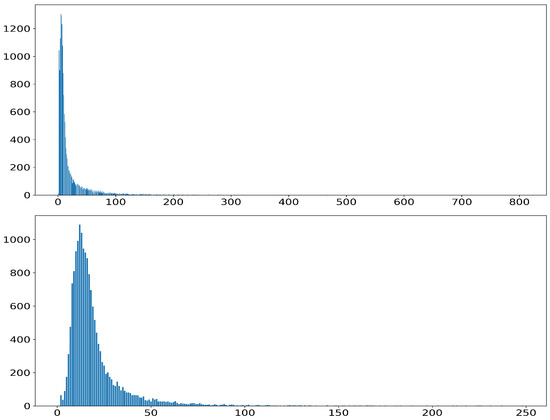
Figure 5.
The distribution of words per sentence, where the x-axis represents the word count per sentence and the y-axis indicates the number of sentences corresponding to each word count. Specifically: word count distribution of prompt sentences (top) word count distribution of response sentences (bottom).
4. Experiment
4.1. Experiment Setup
Open-source decoder-based models are adopted and the model size (i.e., the number of trainable parameters) ranges from 7B to 13B. The models are Llama3.1-8B, Llama2-7B, Llama2-13B, Gemma2-9B, Falcon3-7B, and Falcon3-10B. We employed the AdamW optimizer [40], the batch size is 2, and the number of epochs for tuning is 3. Given the limited training data and computational resources, we adopted LoRA (Low-Rank Adaptation) [41] for efficient fine-tuning. The detailed hyperparameter settings used for training are provided in Table 5. We used the PyTorch library (version 2.2.2+cu121) and Hugging Face open-source models for implementation and training [42,43]. We accessed GPT-3.5-Turbo and GPT-4o via the OpenAI API to generate neutral utterances and to perform automatic evaluation, respectively. Our machine is equipped with RTX 3090 Ti (4EA) and 256 GB RAM. We arbitrarily set the number of center characters k (i.e., cluster size) to be 50, and the representative characters of the two clusters are Mary Crawford and Gabriel Syme. For inference, we set the temperatures 0.7 and 1.1 for Gabriel Syme and Mary Crawford, respectively. The dataset statistics used for instruction-tuning and model evaluation are detailed in Table 6. The training dataset consists of 144 utterances, and the test dataset used for evaluation contains 50 utterances.
Table 5.
Hyperparameter settings used for instruction tuning with LoRA.
Table 6.
Statistics for word counts and standard deviations (Std.) of Prompts () and Responses () in the training and test datasets.
4.2. Evaluation Methodology
To evaluate the effectiveness of our language model tuned by the instruction-tuning, we compare our tuned language model with its base model. Specifically, for each base model (e.g., Llama3.1-8b), we created its tuned model through the instruction-tuning. Each test prompt, as shown in Table 3 without the response part, is given to and , and their responses and are obtained. Recent studies have reported high evaluation consistency between human judgments and LLM-based evaluations [44,45], leading many LLM-related works to adopt Judge LLMs. In line with this trend, we used a strong LLM (e.g., GPT series) as the judge model in our evaluation. Our judge model, GPT-4o, is given our designed prompt, and makes a decision about which response among and is better in terms of the target personality.
Table 7 shows an example of the pair of and for the base model Llama3.1-8b.
Table 7.
Example prompts and paired responses ( and ) generated by the instruction-tuned model and the base model , both based on Llama3.1-8b, to be judged by the GPT-4o model.
We tested whether the judge model knew the personality of the target or representative characters (e.g., Mary Crawford and Gabriel Syme) by simply asking the judge model in natural language (e.g., Do you know the personality and characteristics “The Policeman” from The Man Who Was Thursday?), and found that the judge model knows their personality. Table 8 shows the judge model’s response.
Table 8.
Verbatim answer regarding the character awareness of the judge model (GPT-4o).
We also randomly shuffled the order of and to deal with the position bias problem [46,47]. Another known issue in LLM-based evaluation is self-preference, where models tend to prefer responses they themselves have generated [48]. However, since this study uses a diverse set of models, it can be considered relatively free from this bias.
5. Results and Discussion
Table 9 summarizes the experimental results on four foundation models, averaged over three repeated trials. We observed that our tuned models, , were generally selected more often than the base models , suggesting that our models generated character utterances that better reflected the target character’s personality. There are two interesting observations here. First, our tuned Llama2-7B models showed the best performance, while the tuned Falcon3 models performed the worst, likely due to their primary training data source (i.e., RefinedWeb) [49] which is known to not contain full book or novel texts—potentially hindering their ability in literary domains. Second, the Mary Crawford cluster showed a relatively larger performance gap (i.e., Avg. #Win of vs. ) than the Gabriel Syme cluster. Table 10 shows this tendency more clearly. The reason may be that the Mary Crawford cluster has the personality that stands out more clearly; as shown in Figure 1, we see more noticeable changes in the translated utterances of Mary Crawford compared to the utterances of Gabriel Syme.
Table 9.
Experimental results for versus .
Table 10.
Total win counts and win rates (%) of and for each cluster.
Our hypothesis is that our language models trained on the utterances of character ‘clusters,’ can translate a given utterance into a new utterance that better reflects the personality of a target character cluster.
Although we have shown that our language models outperform the base language models as shown in Table 9, we further investigated the question: “Does cluster size affect performance?” Specifically, we conducted experiments by varying the cluster size (i.e., the number of center characters k of the top-k character document ) from 10 to 73, and the result is shown in Table 11. We adopted Gemma2-9B as the base model. As shown in Table 11, we observed the best performance when . This implies that using utterances with a small number of central characters (i.e., ) is not preferable because it may cause the “unconscious author style” problem, and using utterances with all characters (i.e., ) is also not a good choice because the outer characters are weak in representing the associated personality.
Table 11.
Evaluation results of Gemma2-9B, showing win counts for the tuned model () and base model () across different TopK values.
Limitations
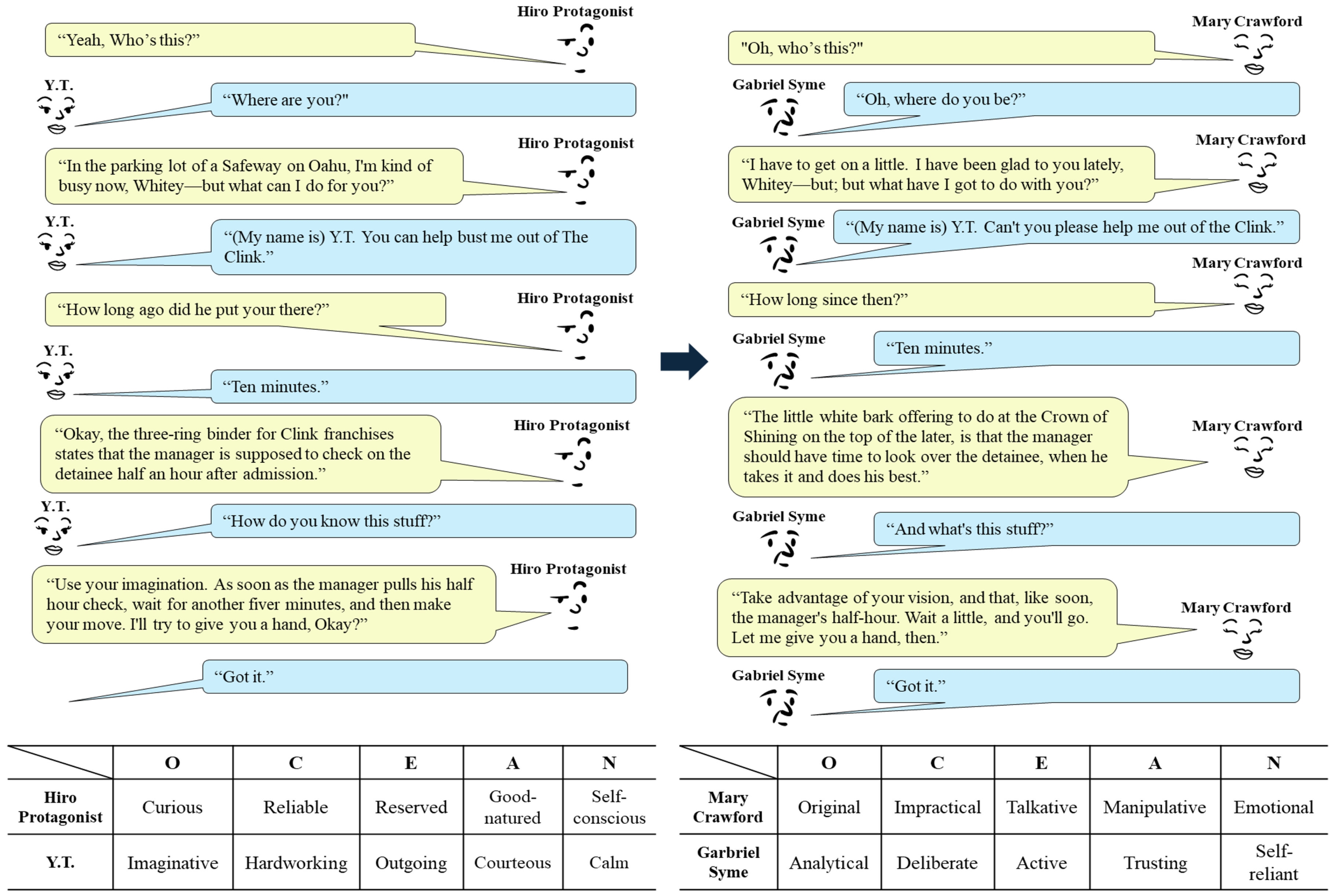
A limitation of our method is that the tuned models sometimes produced utterances that were poor in terms of fluency. Figure 6 shows an example of the translation of a science fiction, Snow Crash [50]. Note that some of the translated utterances (e.g., “Oh, where do you be?”) are grammatically incorrect. The fluency problem is probably related to the size of the language models [51], and this limitation will be resolved as we tune larger models with larger datasets.
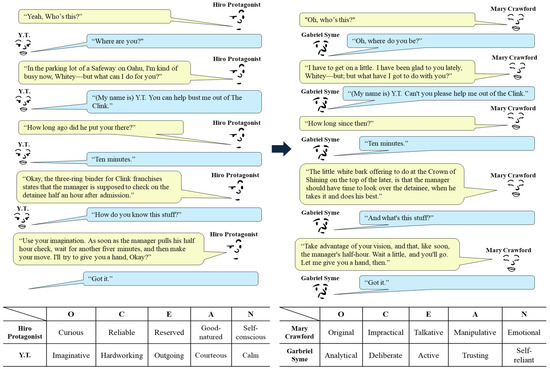
Figure 6.
An example of utterance translation. The conversation between Hiro Protagonist and Y.T in the novel Snow Crash [50] (left) is translated into a conversation between two different characters (right). The bottom table describes the personality of the four characters by their per-trait keywords (all keywords can be found in Table 1).
A further limitation is related to the clustering method used to represent character personality. While clustering based on personality trait annotations for each character would be ideal, it requires costly manual annotation. As a practical alternative, we adopted a word-based clustering approach. Notably, the resulting two clusters may reflect an implicit binary structure underlying character styles in the dataset. In future work, we plan to expand the dataset, explore a broader range of cluster numbers, and apply more sophisticated methods such as hierarchical clustering.
6. Conclusions
In this study, we aimed to address the problem of “unconscious author style” in order to build language models that generate character utterances more accurately reflecting a specific personality. To achieve this, we constructed the OCEAN-based character dataset in which trained literature experts annotated each character with scores on the five personality dimensions, an effort with significant academic value. In addition, we proposed a novel methodology and constructed a customized dataset that enables instruction-tuning using utterances from literary texts, providing a distinctive approach to character-centered language modeling. Through this approach, we also present a method for neutralizing the author’s unconsciously embedded stylistic tendencies while faithfully capturing the unique personality of each character. Based on this foundation, we fine-tuned several generative language models—including decoder-based models such as LLaMA 2, LLaMA 3, and Gemma 2—that have recently attracted considerable attention in the field of language modeling.
This study demonstrates the potential of using character utterances and instruction-tuned language models to effectively reflect the personality traits and individuality of fictional characters in literary texts. By combining novel-based utterance data with instruction-tuning for large language models (LLMs), we experimentally validate that character-specific expressions can be naturally generated in a manner consistent with their annotated personality traits. This work highlights the potential for interdisciplinary integration between natural language processing (NLP) and literary studies, and suggests meaningful directions in which language models can contribute to literary creativity and textual understanding. Moreover, this research serves as a practical example of how data-driven approaches yield tangible results in the convergence of the humanities and engineering. Future work will include extending the model to a wider range of novels to cover different writing styles and character profiles, as well as improving both quantitative and qualitative evaluation methods (e.g., stylistic consistency, literary realism, and etc.) for the generated text. Through such efforts, we expect to make meaningful contributions to AI-driven literary creation and the development of character-centered dialogue systems.
Author Contributions
Conceptualization, E.-J.K. and Y.-S.J.; methodology, Y.-S.J.; investigation, E.-J.K.; resources, M.Y. and C.-H.J.; writing—original draft preparation, E.-J.K.; writing—review and editing, E.-J.K., C.-H.J., M.Y. and Y.-S.J.; visualization, E.-J.K. and Y.-S.J.; supervision, Y.-S.J.; project administration, Y.-S.J.; funding acquisition, M.Y. and C.-H.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2022S1A5A2A03052880). This work was supported by the Hongik University new faculty research support fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
For inquiries regarding data sharing, please contact the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Gu, X.; Chen, M.; Lin, Y.; Hu, Y.; Zhang, H.; Wan, C.; Wei, Z.; Xu, Y.; Wang, J. On the effectiveness of large language models in domain-specific code generation. ACM Trans. Softw. Eng. Methodol. 2025, 34, 1–22. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Amin, M.; Hou, L.; Clark, K.; Pfohl, S.R.; Cole-Lewis, H.; et al. Toward expert-level medical question answering with large language models. Nat. Med. 2025, 31, 943–950. [Google Scholar] [CrossRef] [PubMed]
- Garrido-Merchán, E.C.; Arroyo-Barrigüete, J.L.; Gozalo-Brizuela, R. Simulating HP Lovecraft horror literature with the ChatGPT large language model. arXiv 2023, arXiv:2305.03429. [Google Scholar]
- Rashkin, H.; Celikyilmaz, A.; Choi, Y.; Gao, J. Plotmachines: Outline-conditioned generation with dynamic plot state tracking. arXiv 2020, arXiv:2004.14967. [Google Scholar]
- Liu, D.; Li, J.; Yu, M.H.; Huang, Z.; Liu, G.; Zhao, D.; Yan, R. A character-centric neural model for automated story generation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1725–1732. [Google Scholar]
- Zhu, J.; Jurgens, D. Idiosyncratic but not arbitrary: Learning idiolects in online registers reveals distinctive yet consistent individual styles. arXiv 2021, arXiv:2109.03158. [Google Scholar]
- Jafariakinabad, F.; Hua, K.A. Style-Aware Neural Model with Application in Authorship Attribution. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 325–328. [Google Scholar] [CrossRef]
- Leech, G.N.; Short, M. Style in Fiction: A linguistic Introduction to English Fictional Prose; Pearson Education: Harlow, UK, 2007; Number 13. [Google Scholar]
- Eisen, M.; Ribeiro, A.; Segarra, S.; Egan, G. Stylometric analysis of Early Modern period English plays. Digit. Scholarsh. Humanit. 2018, 33, 500–528. [Google Scholar] [CrossRef]
- Maslej, M.M.; Oatley, K.; Mar, R.A. Creating fictional characters: The role of experience, personality, and social processes. Psychol. Aesthet. Creat. Arts 2017, 11, 487. [Google Scholar] [CrossRef]
- Wu, W.; Wu, H.; Jiang, L.; Liu, X.; Hong, J.; Zhao, H.; Zhang, M. From role-play to drama-interaction: An LLM solution. arXiv 2024, arXiv:2405.14231. [Google Scholar]
- Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; Weston, J. Personalizing dialogue agents: I have a dog, do you have pets too? arXiv 2018, arXiv:1801.07243. [Google Scholar]
- Pennebaker, J.W.; King, L.A. Linguistic styles: Language use as an individual difference. J. Personal. Soc. Psychol. 1999, 77, 1296. [Google Scholar] [CrossRef] [PubMed]
- McCrae, R.R.; Costa Jr, P.T. Personality trait structure as a human universal. Am. Psychol. 1997, 52, 509. [Google Scholar] [CrossRef] [PubMed]
- Doyle, A.C. The Adventure of the Blue Carbuncle. In The Adventures of Sherlock Holmes; George Newnes: London, UK, 1892; Available online: https://www.gutenberg.org/ebooks/1661 (accessed on 29 April 2025).
- Doyle, A.C. A Scandal in Bohemia. In The Adventures of Sherlock Holmes; George Newnes: London, UK, 1892; Available online: https://www.gutenberg.org/ebooks/1661 (accessed on 29 April 2025).
- McCrae, R.R.; Costa, P.T. Validation of the five-factor model of personality across instruments and observers. J. Personal. Soc. Psychol. 1987, 52, 81. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. 2018. Available online: https://openai.com/index/language-unsupervised/ (accessed on 29 April 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Almazrouei, E.; Alobeidli, H.; Alshamsi, A.; Cappelli, A.; Cojocaru, R.; Debbah, M.; Goffinet, É.; Hesslow, D.; Launay, J.; Malartic, Q.; et al. The falcon series of open language models. arXiv 2023, arXiv:2311.16867. [Google Scholar]
- Team, G.; Mesnard, T.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Pathak, S.; Sifre, L.; Rivière, M.; Kale, M.S.; Love, J.; et al. Gemma: Open models based on gemini research and technology. arXiv 2024, arXiv:2403.08295. [Google Scholar]
- Team, G.; Riviere, M.; Pathak, S.; Sessa, P.G.; Hardin, C.; Bhupatiraju, S.; Hussenot, L.; Mesnard, T.; Shahriari, B.; Ramé, A.; et al. Gemma 2: Improving open language models at a practical size. arXiv 2024, arXiv:2408.00118. [Google Scholar]
- Biderman, S.; Schoelkopf, H.; Anthony, Q.G.; Bradley, H.; O’Brien, K.; Hallahan, E.; Khan, M.A.; Purohit, S.; Prashanth, U.S.; Raff, E.; et al. Pythia: A suite for analyzing large language models across training and scaling. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 2397–2430. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de Las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- John, O.P.; Robins, R.W.; Pervin, L.A. Handbook of Personality: Theory and Research, 3rd ed.; Guilford Press: New York, NY, USA, 2010. [Google Scholar]
- Vishnubhotla, K.; Hammond, A.; Hirst, G. The project dialogism novel corpus: A dataset for quotation attribution in literary texts. arXiv 2022, arXiv:2204.05836. [Google Scholar]
- Masumura, R.; Orihashi, S.; Ihori, M.; Tanaka, T.; Makishima, N.; Suzuki, S.; Mizuno, S.; Hojo, N. Multimodal Fine-Grained Apparent Personality Trait Recognition: Joint Modeling of Big Five and Questionnaire Item-level Scores. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 1456–1464. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Routledge: Oxfordshire, UK, 2013. [Google Scholar]
- Shrout, P.E.; Fleiss, J.L. Intraclass correlations: Uses in assessing rater reliability. Psychol. Bull. 1979, 86, 420. [Google Scholar] [CrossRef] [PubMed]
- Cicchetti, D.V. Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychol. Assess. 1994, 6, 284. [Google Scholar] [CrossRef]
- Nekvinda, T.; Dušek, O. AARGH! end-to-end retrieval-generation for task-oriented dialog. arXiv 2022, arXiv:2209.03632. [Google Scholar]
- Passali, T.; Chatzikyriakidis, E.; Andreadis, S.; Stavropoulos, T.G.; Matonaki, A.; Fachantidis, A.; Tsoumakas, G. From lengthy to lucid: A systematic literature review on NLP techniques for taming long sentences. arXiv 2023, arXiv:2312.05172. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Hu, E.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2022, arXiv:2106.09685. [Google Scholar]
- Paszke, A. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Dubois, Y.; Galambosi, B.; Liang, P.; Hashimoto, T.B. Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv 2024, arXiv:2404.04475. [Google Scholar]
- Peng, B.; Li, C.; He, P.; Galley, M.; Gao, J. Instruction tuning with gpt-4. arXiv 2023, arXiv:2304.03277. [Google Scholar]
- Liusie, A.; Manakul, P.; Gales, M.J.F. LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models. arXiv 2024, arXiv:2307.07889. [Google Scholar]
- Wang, P.; Li, L.; Chen, L.; Cai, Z.; Zhu, D.; Lin, B.; Cao, Y.; Liu, Q.; Liu, T.; Sui, Z. Large language models are not fair evaluators. arXiv 2023, arXiv:2305.17926. [Google Scholar]
- Panickssery, A.; Bowman, S.; Feng, S. Llm evaluators recognize and favor their own generations. Adv. Neural Inf. Process. Syst. 2024, 37, 68772–68802. [Google Scholar]
- Penedo, G.; Malartic, Q.; Hesslow, D.; Cojocaru, R.; Cappelli, A.; Alobeidli, H.; Pannier, B.; Almazrouei, E.; Launay, J. The Refined-Web dataset for Falcon LLM: Outperforming curated corpora with web data, and web data only. arXiv 2023, arXiv:2306.01116. [Google Scholar]
- Stephenson, N. Snow Crash; Penguin Books: London, UK, 1992; p. 73. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).