
Confidence-Based Knowledge Distillation to Reduce Training Costs and Carbon Footprint for Low-Resource Neural Machine Translation


Abstract
1. Introduction
- A small amount of bilingual data similar to the project data to be translated are available for training.
- Only limited source-language monolingual data similar to the project data to be translated are available for training.
2. Related Work
3. Background
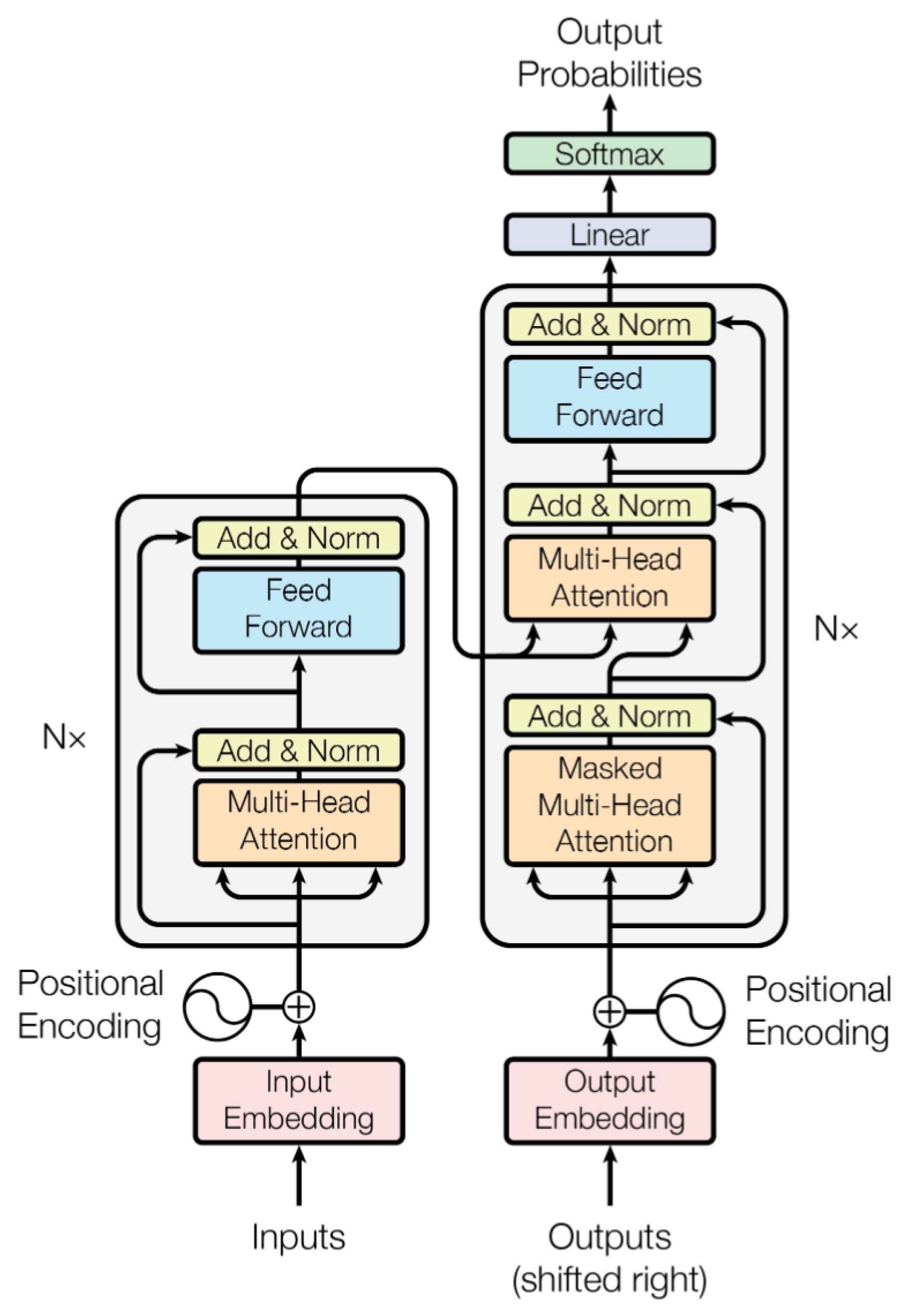
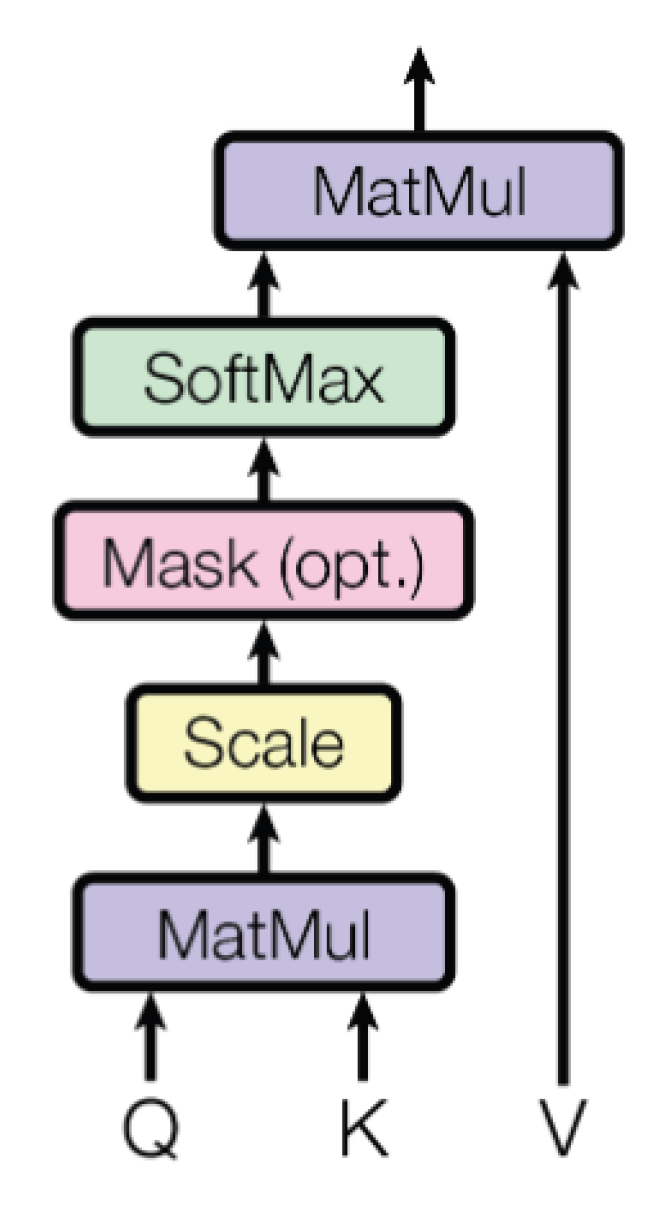
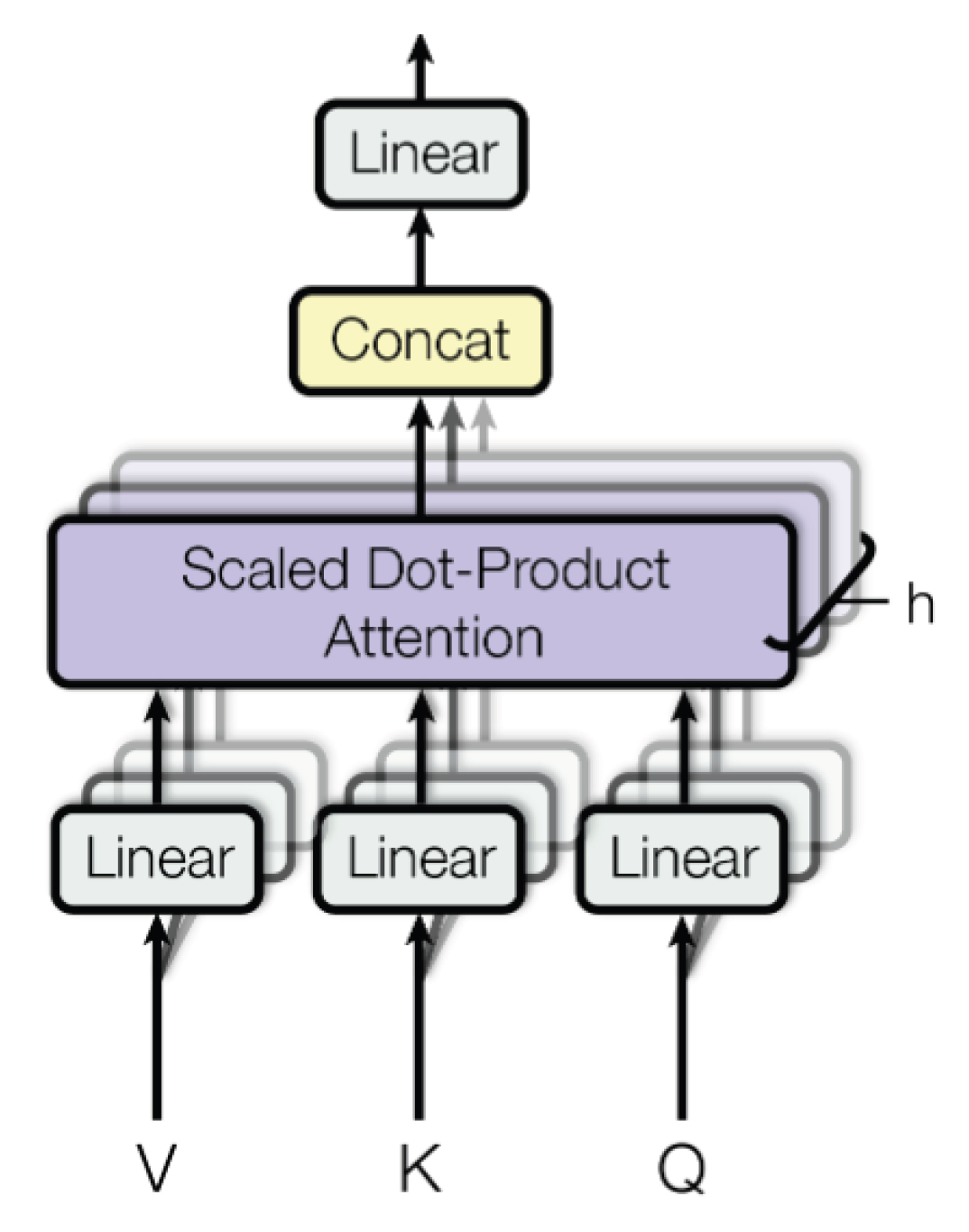
3.1. Transformer
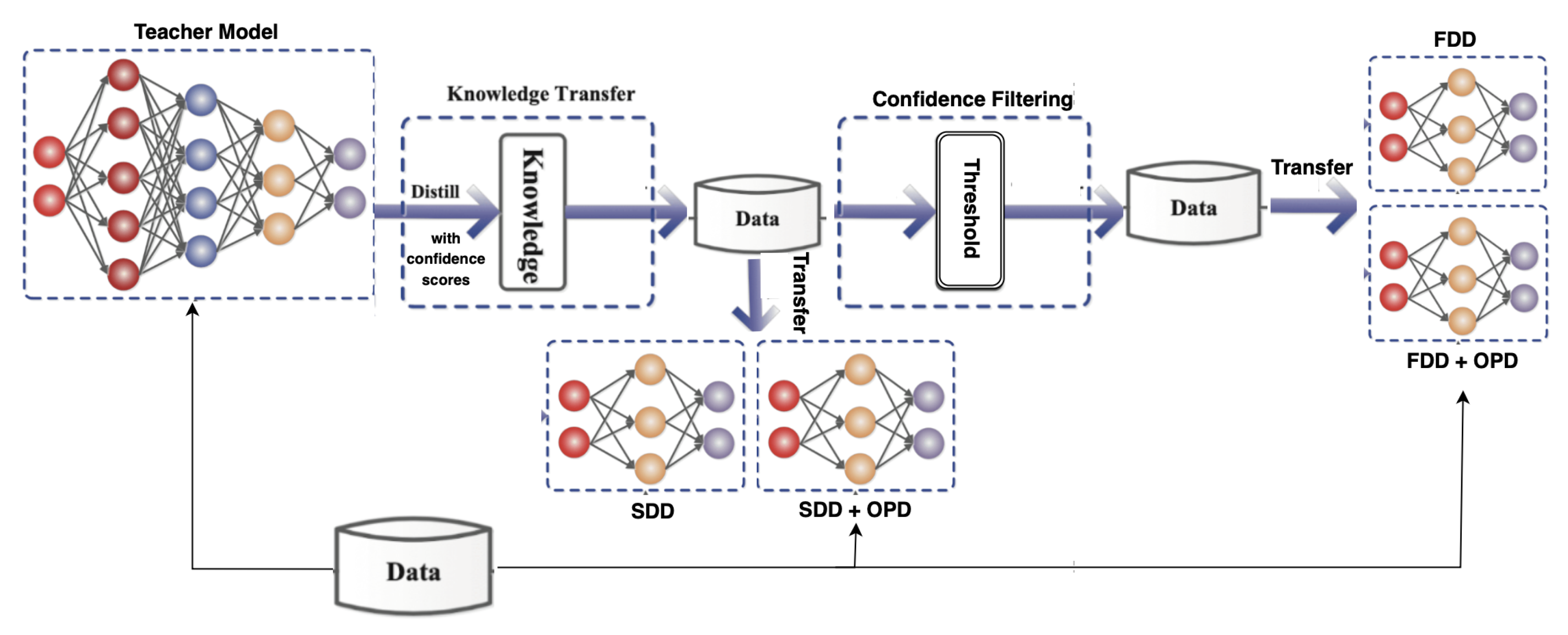
3.2. Sequence-Level Knowledge Distillation
4. Datasets
5. Experimental Setup
5.1. NLLB
5.2. Soft Labels for Distillation
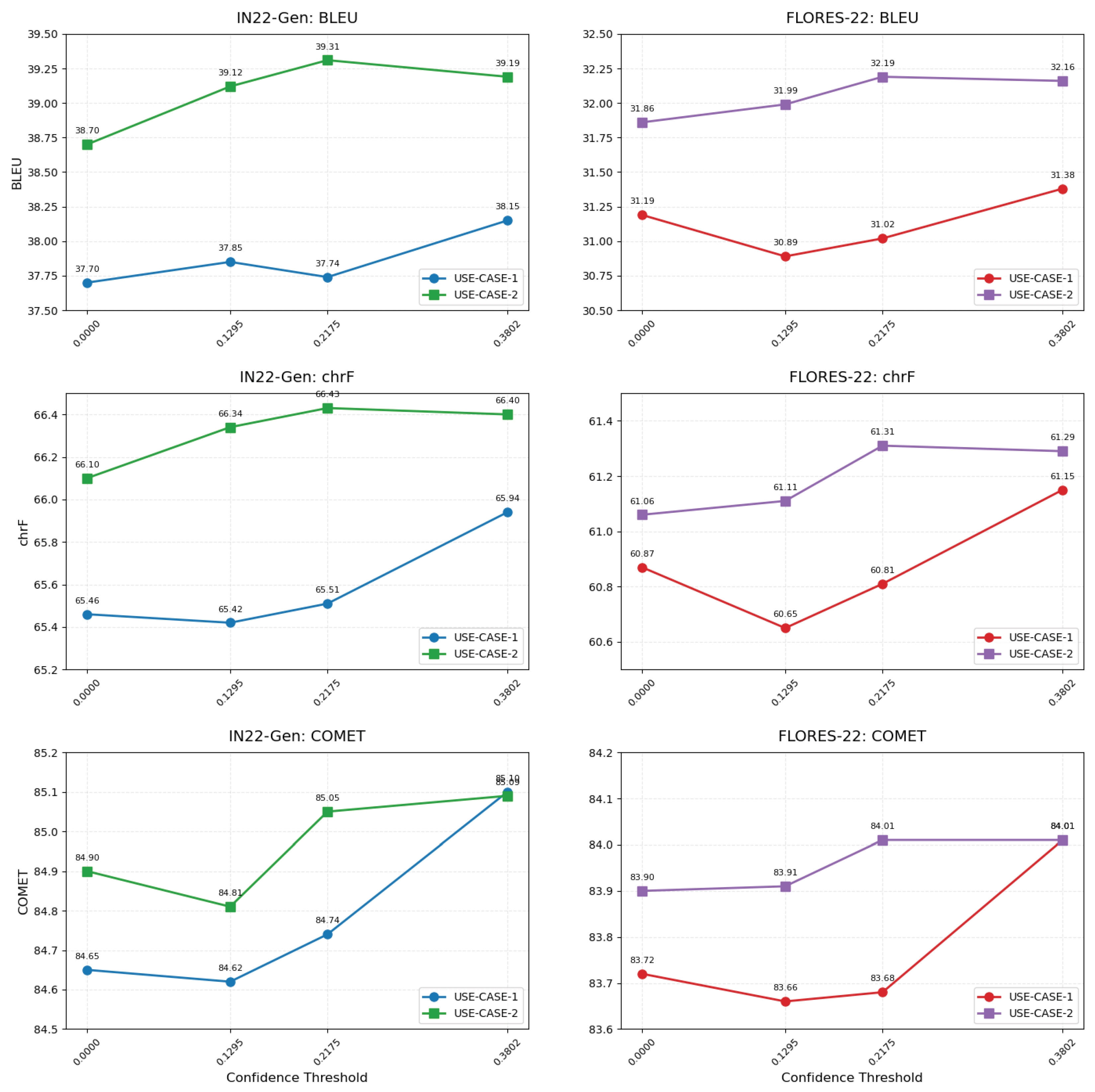
6. Results and Discussion
6.1. Use Case 1: Only Monolingual (Urdu) Data Available
6.2. Use Case 2: Limited Bilingual (Urdu–English) Data Available
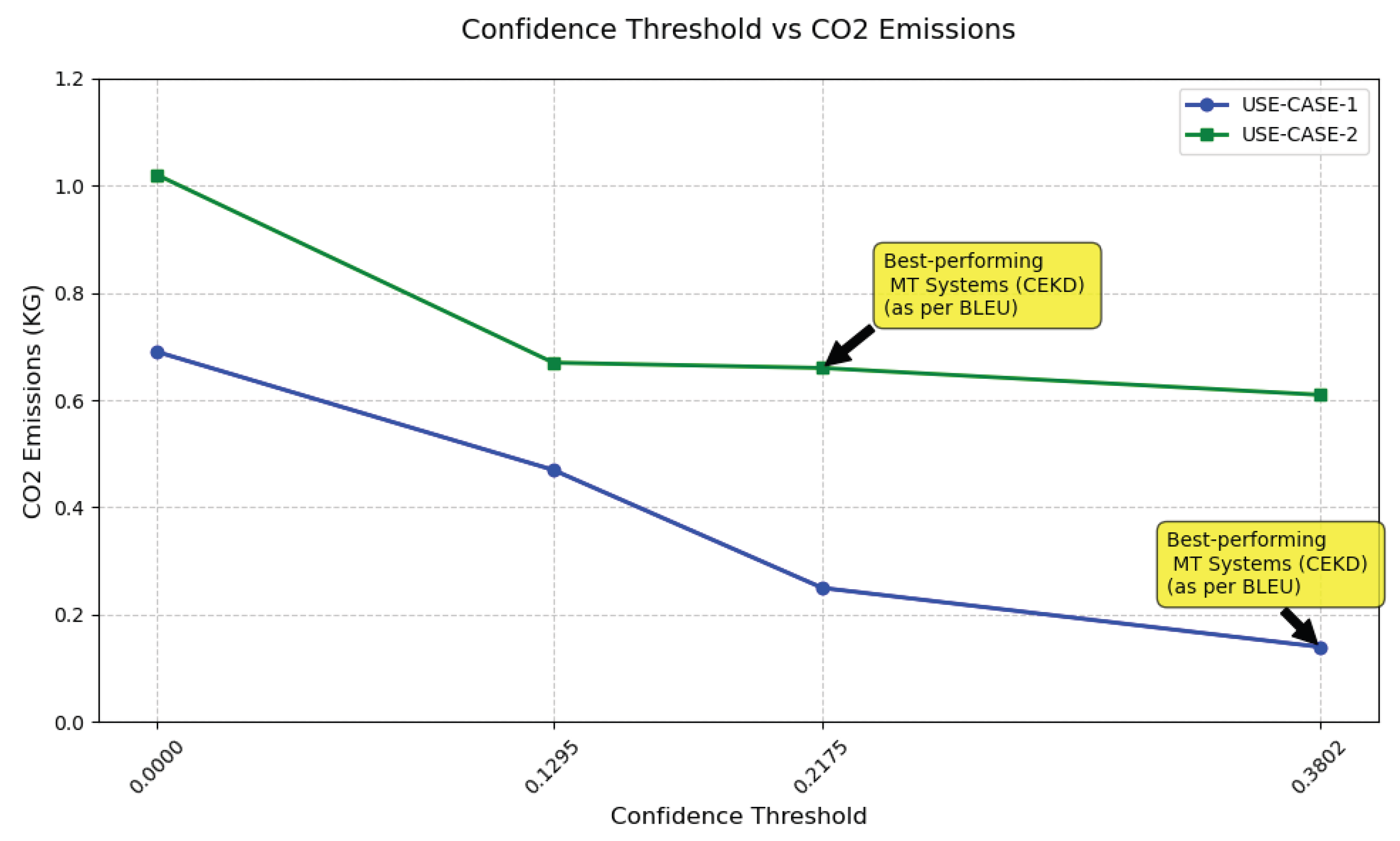
6.3. Training Costs of the Student Models
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Kim, Y.; Rush, A.M. Sequence-Level Knowledge Distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1317–1327. [Google Scholar] [CrossRef]
- Wei, J.; Sun, L.; Leng, Y.; Tan, X.; Yu, B.; Guo, R. Sentence-Level or Token-Level? A Comprehensive Study on Knowledge Distillation. arXiv 2024, arXiv:2404.14827. [Google Scholar]
- Moslem, Y. Efficient Speech Translation through Model Compression and Knowledge Distillation. arXiv 2025, arXiv:2505.20237. [Google Scholar]
- Team, N.; Costa-jussà, M.R.; Cross, J.; Çelebi, O.; Elbayad, M.; Heafield, K.; Heffernan, K.; Kalbassi, E.; Lam, J.; Licht, D.; et al. No Language Left Behind: Scaling Human-Centered Machine Translation. arXiv 2022, arXiv:2207.04672. [Google Scholar]
- Waheed, A.; Kadaoui, K.; Raj, B.; Abdul-Mageed, M. uDistil-Whisper: Label-Free Data Filtering for Knowledge Distillation in Low-Data Regimes. arXiv 2025, arXiv:2407.01257. [Google Scholar]
- Britz, D.; Le, Q.; Pryzant, R. Effective Domain Mixing for Neural Machine Translation. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 118–126. [Google Scholar] [CrossRef]
- Gu, J.; Bradbury, J.; Xiong, C.; Li, V.O.K.; Socher, R. Non-Autoregressive Neural Machine Translation. arXiv 2018, arXiv:1711.02281. [Google Scholar] [PubMed]
- Kasai, J.; Pappas, N.; Peng, H.; Cross, J.; Smith, N.A. Deep encoder, shallow decoder: Reevaluating non-autoregressive machine translation. arXiv 2020, arXiv:2006.10369. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wang, F.; Yan, J.; Meng, F.; Zhou, J. Selective Knowledge Distillation for Neural Machine Translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 6456–6466. [Google Scholar] [CrossRef]
- Zhou, C.; Neubig, G.; Gu, J. Understanding Knowledge Distillation in Non-autoregressive Machine Translation. arXiv 2021, arXiv:1911.02727. [Google Scholar]
- Bucila, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Mirzadeh, S.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 5191–5198. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar]
- Kim, Y.J.; Junczys-Dowmunt, M.; Hassan, H.; Fikri Aji, A.; Heafield, K.; Grundkiewicz, R.; Bogoychev, N. From Research to Production and Back: Ludicrously Fast Neural Machine Translation. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; pp. 280–288. [Google Scholar] [CrossRef]
- Yoo, K.M.; Park, D.; Kang, J.; Lee, S.W.; Park, W. GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 2225–2239. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference. arXiv 2021, arXiv:2001.07676. [Google Scholar]
- Zhou, Y.; Maharjan, S.; Liu, B. Scalable Prompt Generation for Semi-supervised Learning with Language Models. arXiv 2023, arXiv:2302.09236. [Google Scholar]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv 2023, arXiv:2210.03629. [Google Scholar]
- Ho, N.; Schmid, L.; Yun, S.Y. Large Language Models Are Reasoning Teachers. arXiv 2023, arXiv:2212.10071. [Google Scholar]
- He, N.; Lai, H.; Zhao, C.; Cheng, Z.; Pan, J.; Qin, R.; Lu, R.; Lu, R.; Zhang, Y.; Zhao, G.; et al. TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise. arXiv 2024, arXiv:2310.19019. [Google Scholar]
- Shridhar, K.; Stolfo, A.; Sachan, M. Distilling Reasoning Capabilities into Smaller Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL, Toronto, ON, Canada, 9–14 July 2023; pp. 7059–7073. [Google Scholar] [CrossRef]
- Hsieh, C.Y.; Li, C.L.; Yeh, C.k.; Nakhost, H.; Fujii, Y.; Ratner, A.; Krishna, R.; Lee, C.Y.; Pfister, T. Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes. In Proceedings of the Findings of the Association for Computational Linguistics: ACL, Toronto, ON, Canada, 9–14 July 2023; pp. 8003–8017. [Google Scholar] [CrossRef]
- Wang, P.; Li, L.; Chen, L.; Song, F.; Lin, B.; Cao, Y.; Liu, T.; Sui, Z. Making Large Language Models Better Reasoners with Alignment. arXiv 2023, arXiv:2309.02144. [Google Scholar]
- Li, Y.; Yuan, P.; Feng, S.; Pan, B.; Sun, B.; Wang, X.; Wang, H.; Li, K. Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data. arXiv 2023, arXiv:2312.12832. [Google Scholar] [CrossRef]
- Chen, H.; Wu, S.; Quan, X.; Wang, R.; Yan, M.; Zhang, J. MCC-KD: Multi-CoT Consistent Knowledge Distillation. arXiv 2023, arXiv:2310.14747. [Google Scholar]
- Liu, W.; Li, G.; Zhang, K.; Du, B.; Chen, Q.; Hu, X.; Xu, H.; Chen, J.; Wu, J. Mind’s Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models. arXiv 2024, arXiv:2311.09214. [Google Scholar]
- Currey, A.; Mathur, P.; Dinu, G. Distilling Multiple Domains for Neural Machine Translation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4500–4511. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Yu, D.; Backurs, A.; Gopi, S.; Inan, H.; Kulkarni, J.; Lin, Z.; Xie, C.; Zhang, H.; Zhang, W. Training Private and Efficient Language Models with Synthetic Data from LLMs. In Proceedings of the Socially Responsible Language Modelling Research, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Jooste, W.; Haque, R.; Way, A. Knowledge Distillation: A Method for Making Neural Machine Translation More Efficient. Information 2022, 13, 88. [Google Scholar] [CrossRef]
- Li, J.; Nag, S.; Liu, H.; Tang, X.; Sarwar, S.; Cui, L.; Gu, H.; Wang, S.; He, Q.; Tang, J. Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data. arXiv 2025, arXiv:2411.08028. [Google Scholar]
- Koneru, S.; Liu, D.; Niehues, J. Cost-Effective Training in Low-Resource Neural Machine Translation. arXiv 2022, arXiv:2201.05700. [Google Scholar]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Neural Comput. Appl. 2021, 33, 6273–6293. [Google Scholar] [CrossRef]
- Balakrishnan, R.; Geetha, V.; Kumar, M.; Leung, M.F. Reduction in Residential Electricity Bill and Carbon Dioxide Emission through Renewable Energy Integration Using an Adaptive Feed-Forward Neural Network System and MPPT Technique. Sustainability 2023, 15, 14088. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Zafar, M.; Castaldo, A.; Nayak, P.; Haque, R.; Way, A. The SETU-ADAPT Submissions to WMT 2024 Chat Translation Tasks. In Proceedings of the Ninth Conference on Machine Translation, Miami, FL, USA, 15–16 November 2024; pp. 1023–1030. [Google Scholar] [CrossRef]
- Post, M. A call for clarity in reporting BLEU scores. arXiv 2018, arXiv:1804.08771. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015; pp. 392–395. [Google Scholar] [CrossRef]
- Rei, R.; Stewart, C.; Farinha, A.C.; Lavie, A. COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–18 November 2020; pp. 2685–2702. [Google Scholar] [CrossRef]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the carbon emissions of machine learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- Koehn, P. Statistical Significance Tests for Machine Translation Evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2004; pp. 388–395. [Google Scholar]
- Neubig, G.; Dou, Z.; Hu, J.; Michel, P.; Pruthi, D.; Wang, X.; Wieting, J. Compare-mt: A Tool for Holistic Comparison of Language Generation Systems. arXiv 2019, arXiv:1903.07926. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentences | Vocabulary | ||
|---|---|---|---|
| Urdu | Englis | ||
| Train | 188,130 | 152,943 | 166,848 |
| Valid | 1000 | 5488 | 4996 |
| IN22-Gen | 1023 | 6708 | 7387 |
| FLORES-200 | 994 | 5775 | 5336 |
| SacreBLEU | chrF | COMET | ||
|---|---|---|---|---|
| NLLB | IN22-Gen | 40.57 | 66.62 | 85.55 |
| FLORES-200 | 39.02 | 60.99 | 87.35 | |
| Vanilla Baseline (NLLB-600M) | IN22-Gen | 37.48 | 63.31 | 83.73 |
| FLORES-200 | 31.87 | 58.80 | 82.63 | |
| Baseline (NLLB-600M) | IN22-Gen | 37.38 | 65.17 | 84.56 |
| FLORES-200 | 31.05 | 60.62 | 83.72 |
| SacreBLEU | chrF | COMET | Train | CO2 | TT | ||
|---|---|---|---|---|---|---|---|
| Vanilla Baseline | IN22-Gen | 37.48 | 63.31 | 83.73 | - | - | - |
| FLORES-200 | 31.87 | 58.80 | 82.63 | ||||
| SDD | IN22-Gen | 37.70 | 65.46 | 84.65 | 188,130 | 0.69 | 4.0 |
| FLORES-200 | 31.19 | 60.87 | 83.72 | ||||
| FDD | IN22-Gen | 37.85 | 65.42 | 84.62 | 153,754 | 0.47 | 2.7 |
| (1st Quartile) | FLORES-200 | 30.89 | 60.65 | 83.66 | |||
| FDD | IN22-Gen | 37.74 | 65.51 | 84.74 | 85,298 | 0.25 | 1.4 |
| (2nd Quartile) | FLORES-200 | 31.02 | 60.81 | 83.68 | |||
| FDD | IN22-Gen | 38.17 | 65.94 | 85.10 | 49,517 | 0.14 | 0.8 |
| (3rd Quartile) | FLORES-200 | 31.38 | 61.15 | 84.01 | |||
| SacreBLEU | chrF | COMET | Train | CO2 | TT | ||
|---|---|---|---|---|---|---|---|
| Baseline | IN22-Gen | 37.38 | 65.17 | 84.56 | - | - | - |
| FLORES-200 | 31.05 | 60.62 | 83.72 | ||||
| SDD+OPD | IN22-Gen | 38.70 | 66.10 | 84.90 | 376,260 | 1.08 | 4.5 |
| FLORES-200 | 31.86 | 61.06 | 83.90 | ||||
| FDD+OPD | IN22-Gen | 39.12 | 66.34 | 84.81 | 341,884 | 0.67 | 3.86 |
| (1st Quartile) | FLORES-200 | 31.99 | 61.11 | 83.91 | |||
| FDD+OPD | IN22-Gen | 39.31 | 66.43 | 85.05 | 273,428 | 0.66 | 3.83 |
| (2nd Quartile) | FLORES-200 | 32.19 | 61.31 | 84.01 | |||
| FDD+OPD | IN22-Gen | 39.19 | 66.40 | 85.09 | 237,647 | 0.61 | 3.5 |
| (3rd Quartile) | FLORES-200 | 32.16 | 61.29 | 84.01 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zafar, M.; Wall, P.J.; Bakkali, S.; Haque, R. Confidence-Based Knowledge Distillation to Reduce Training Costs and Carbon Footprint for Low-Resource Neural Machine Translation. Appl. Sci. 2025, 15, 8091. https://doi.org/10.3390/app15148091
Zafar M, Wall PJ, Bakkali S, Haque R. Confidence-Based Knowledge Distillation to Reduce Training Costs and Carbon Footprint for Low-Resource Neural Machine Translation. Applied Sciences. 2025; 15(14):8091. https://doi.org/10.3390/app15148091
Chicago/Turabian StyleZafar, Maria, Patrick J. Wall, Souhail Bakkali, and Rejwanul Haque. 2025. "Confidence-Based Knowledge Distillation to Reduce Training Costs and Carbon Footprint for Low-Resource Neural Machine Translation" Applied Sciences 15, no. 14: 8091. https://doi.org/10.3390/app15148091
APA StyleZafar, M., Wall, P. J., Bakkali, S., & Haque, R. (2025). Confidence-Based Knowledge Distillation to Reduce Training Costs and Carbon Footprint for Low-Resource Neural Machine Translation. Applied Sciences, 15(14), 8091. https://doi.org/10.3390/app15148091