
A Survey on Video Big Data Analytics: Architecture, Technologies, and Open Research Challenges


Abstract
1. Introduction
2. Literature Overview in VBDA
2.1. Evolution and Trends in VBDA
- (1)
- Centralized and On-Premises VBDA (2010–2012)
- (2)
- Cloud-Based Batch Processing VBDA (2013–2016)
- (3)
- Streaming Video Analytics and Edge Computing (2017–2019)
- (4)
- Hybrid Cloud-Edge AI and FL (2020–2022)
- (5)
- AI-Driven Autonomous Video Processing (2023–2025)
2.2. Evolution of Architectural Paradigms in VBDA
2.3. Technologies and AI Enhancements in VBDA
2.3.1. Enabling Technologies in VBDA
2.3.2. AI Capabilities and Integration
2.4. Problem Taxonomy and Applications of Video Processing in VBDA
2.4.1. Object Detection and Tracking
2.4.2. Activity and Behavior Analysis
2.4.3. Anomaly Detection
2.4.4. Crowd Analysis and Management
2.4.5. Content-Based Video Retrieval and Understanding
2.4.6. Video Summarization and Captioning
3. VBDA Architectures and Core Technologies
3.1. System-Level Architectural Models in VBDA
3.2. VBDA Core Technologies
3.2.1. Scalable Big Data Processing Frameworks
3.2.2. AI-Driven Video Analytics
3.2.3. Federated Intelligence and Edge AI for Distributed VBDA
3.2.4. Storage and Indexing in VBDA Systems
3.2.5. Visualization and Interpretability
- Latency and Scalability: Centralized cloud-centric designs often struggle with real-time analytics under high video throughput and geographically dispersed deployments.
- Data Heterogeneity: ulti-source video data varies in encoding formats, resolutions, frame rates, and modalities (e.g., visual, thermal, audio), posing standardization and fusion challenges.
- Privacy and Federated Learning: FL adoption in video domains remains limited due to non-IID data distribution, communication overhead, and explainability concerns.
- Semantic Understanding: While progress has been made in video understanding using AI models, semantic indexing, multimodal fusion, and real-time reasoning remain underdeveloped in practice.
- Deployment and Resource Management: Lack of modular, open source reference platforms hinders rapid deployment, especially in resource-constrained edge settings.
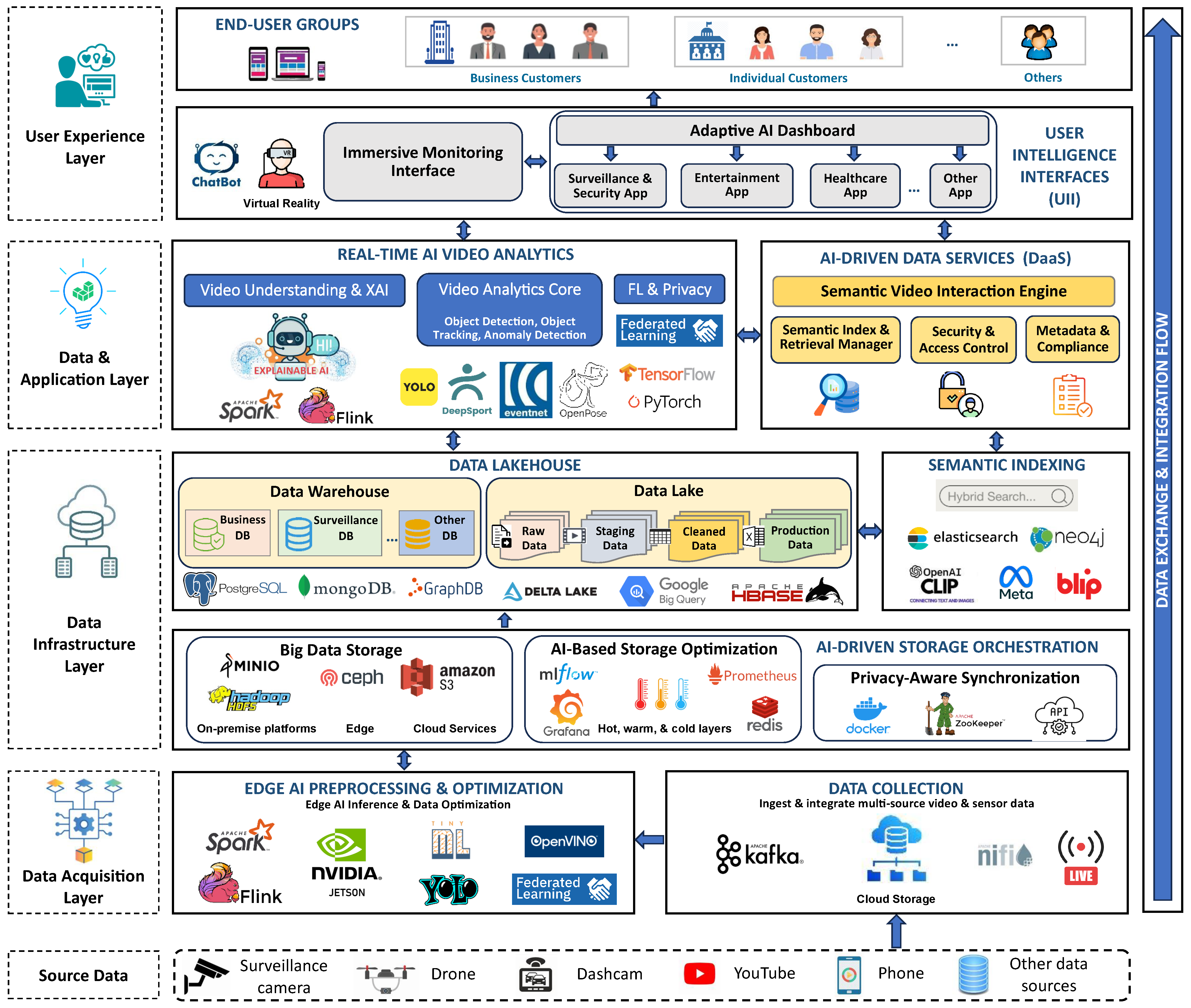
4. ViMindXAI: A Scalable and Cognitive AI Platform for VBDA
4.1. Overview of the Proposed Platform Architecture
4.2. Layered Architecture and Functional Components
4.2.1. Data Acquisition Layer (DAL)
4.2.2. Data Infrastructure Layer (DIL)
- (1)
- AI-Driven Storage Orchestration
- Big Data Storage: establishes a hybrid, fault-tolerant infrastructure for ingesting and managing video data across diverse environments. Cloud services like Amazon S3 offer elastic scalability, while on-premise platforms such as MinIO, and Hadoop HDFS ensure secure, policy-compliant storage. At the edge, Ceph supports low-latency buffering and ingestion. Efficient video encoding formats such as MPEG-4, H.264, and H.265 are integrated into the pipeline to reduce transmission load and long-term storage costs, especially in surveillance and healthcare contexts [150]. Adaptive compression is employed to align bitrate with network and storage constraints [151]. This multi-layered storage backbone supports lifecycle management, distributed retention, and efficient data provisioning for downstream analytics within Lakehouse architectures.
- AI-Based Storage Optimization: leverages reinforcement learning to automate storage tiering decisions, guided by observed usage patterns and anticipated access frequency. This enables dynamic tiering across hot, warm, and cold layers, balancing performance and cost-efficiency. High-speed caching with Redis accelerates access to frequently queried data, while observability tools like Grafana, MLFlow, and Prometheus monitor system performance and guide optimization. To enable intelligent storage tiering, we integrate a Deep Q-Network (DQN)-based reinforcement learning agent [152]. The agent interacts with the environment to learn optimal retention policies, adapting dynamically to changes in data access frequency, latency requirements, and cost-performance trade-offs. This allows ViMindXAI to proactively allocate resources across hot, warm, and cold tiers under varying workload conditions.
- Privacy-Aware Synchronization: facilitates secure and regulation-compliant data transfers across distributed environments, maintaining confidentiality and integrity in multi-tenant deployments. It employs federated synchronization to preserve data locality and prevent unnecessary exposure of sensitive content. Containerized deployment via Docker and Kubernetes ensures portability and scalability, while Apache Zookeeper and secure API gateways manage access control and coordination in multi-tenant setups. This layer is instrumental in ensuring compliance with data protection regulations, including GDPR and HIPAA.
- (2)
- Data Lakehouse
- (3)
- Semantic Indexing
4.2.3. Data and Application Layer (DaAL)
- (1)
- Real-Time AI Video Analytics
- Video Analytics Core: Executes real-time tasks such as object detection, tracking, and activity recognition using models like YOLOv11, DeepSORT, and EventNet.
- Video Understanding and XAI: Generates contextual summaries and explainable insights through captioning and attention visualization using models such as VideoBERT, BLIP, and GradCAM.
- FL and Privacy: Coordinates distributed model training and aggregation from edge devices, while preserving privacy using frameworks like FedAvg, TFF, and NVIDIA FLARE. To address non-IID data and client drift challenges in federated learning, an asynchronous FedAvg scheme enhanced with FedProx regularization is adopted as the coordination strategy. Model updates are managed through TFF, while edge orchestration is supported via KubeEdge. Privacy guarantees are reinforced using secure aggregation protocols and optional differential privacy, depending on the application context. While FedAvg and FedProx remain effective for scalable and moderately heterogeneous environments, we also evaluate more recent algorithms: MOON [153], which applies contrastive learning to enhance client representation consistency; SCAFFOLD [154], which uses control variates to mitigate client drift; and FedNova [155], which normalizes local updates to address training time imbalance. These methods are currently under consideration for integration into ViMindXAI’s FL stack, particularly in deployments with high skew or dynamic data heterogeneity.
- (2)
- AI-Driven Data Services (DaaS)
- Semantic Video Interaction Engine (SVIE): This module supports natural language-based interaction, semantic summarization, and retrieval using foundation models such as CLIP, Whisper, GPT, BLIP, and VideoBERT. SVIE transforms video and audio streams into deep semantic representations, enabling users to query video segments through conversational language or multimodal prompts. By integrating with the semantic index, SVIE enables contextual exploration, smart captioning, and voice-assisted scene navigation, operating as the AI-logic bridge between data and user queries.
- Semantic Index and Retrieval Manager: Responsible for embedding extraction, indexing, and query resolution, this manager leverages multimodal encoders such as CLIP, and BLIP to generate dense vector embeddings from raw data streams. Indexing frameworks such as FAISS or Elasticsearch support approximate nearest neighbor search and multimodal retrieval, which are crucial for rapid access, recommendation, and cross-modal exploration. Through standard APIs (REST, GraphQL), the module enables scalable semantic video search.
- Security and Access Control: Sensitive data is safeguarded through robust security mechanisms, including OAuth2, JWT, and RBAC, which enable fine-grained authentication and access control. It adopts a Zero Trust Security (ZTS) model and optionally uses hardware-based protections like Intel SGX for secure execution. Comprehensive audit logging ensures transparency, while access policies safeguard against misuse and ensure compliance.
- Metadata and Compliance: This submodule oversees metadata tagging, contextual annotations (e.g., object type, location, identity), and regulatory adherence. It manages sensitive content through automated tagging and enforces data privacy standards such as GDPR, HIPAA, and CCPA. Tools like Apache Atlas and policy-based engines provide lineage tracking, compliance auditing, and enforcement of fine-grained access rules.
4.2.4. User Experience Layer (UEL)
- (1)
- User Intelligence Interfaces (UII)
- Immersive Monitoring Interface: The Immersive Monitoring Interface provides real-time AR/VR-based visualizations for operational monitoring and training, utilizing platforms such as Unity, Meta Quest, and HoloLens. It supports environments that demand high spatial and contextual awareness.
- Adaptive AI Dashboard: Presents personalized, role-specific dashboards with real-time updates and explainability features such as GradCAM and SHAP. Integrates with standard BI tools like Tableau, Grafana, Kibana, and Power BI.
- (2)
- End-User Groups
4.3. Real-World Application Scenarios of ViMindXAI
4.3.1. Case Study 1: Smart Building Surveillance and Access Management
4.3.2. Case Study 2: Healthcare Monitoring and Patient Safety
4.3.3. Case Study 3: Industrial Safety and Compliance Monitoring
4.4. Deployment Considerations and Solutions
4.4.1. Practical Deployment Challenges
4.4.2. Proposed Optimization Strategies
- Model Compression for Edge Inference: Techniques such as pruning, quantization, and knowledge distillation are applied to compress models without compromising accuracy. This enables real-time inference on edge hardware like NVIDIA Jetson and Intel Movidius for tasks such as anomaly detection and object tracking [100,134].
- Tiered and Intelligent Storage Architecture: The platform combines edge-level buffering, AI-driven caching, and cloud-based archiving. Semantic indexing using models like CLIP, FAISS, and VideoBERT enables rapid, context-aware retrieval [30,144,145], while tiered orchestration minimizes redundancy and optimizes bandwidth usage.
- Metadata Optimization and Context-Aware Allocation: Rich metadata, including object categories, spatial context, and scene attributes, is used to prioritize content for storage and retrieval. This improves responsiveness and reduces data transfer volumes, especially in bandwidth-constrained scenarios [11,142].
4.5. Comparative Analysis with Existing VBDA Platforms
5. Open Research Challenges and Future Directions
5.1. Scalability and Real-Time Processing
5.2. Security, Privacy, and Ethical AI
5.3. Integration of Emerging Technologies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Statista Research Department. Global Internet Video Traffic as a Share of Total Internet Traffic Worldwide from 2017 to 2023. 2023. Available online: https://www.statista.com/statistics/871513/worldwide-video-traffic-as-share-of-internet-traffic/ (accessed on 27 March 2025).
- Sumalee, A.; Ho, H.W. Smarter and more connected: Future intelligent transportation system. Iatss Res. 2018, 42, 67–71. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, F.; Yu, F.; Zhou, Y.; Hu, J.; Min, G. Federated Continual Learning for Edge-AI: A Comprehensive Survey. arXiv 2024. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, T. Toward an online continual learning architecture for intrusion detection of video surveillance. IEEE Access 2022, 10, 89732–89744. [Google Scholar] [CrossRef]
- Badidi, E.; Moumane, K.; El Ghazi, F. Opportunities, applications, and challenges of edge-AI enabled video analytics in smart cities: A systematic review. IEEE Access 2023, 11, 80543–80572. [Google Scholar] [CrossRef]
- Wu, X.; Yan, G.; Xie, X.; Bao, Y.; Zhang, W. Construction and Application of Video Big Data Analysis Platform for Smart City Development. Adv. Math. Phys. 2022, 2022, 7592180. [Google Scholar] [CrossRef]
- Zhai, Y. Design and Optimization of Smart Fire IoT Cloud Platform Based on Big Data Technology. In Proceedings of the 2024 International Conference on Electrical Drives, Power Electronics & Engineering (EDPEE), Athens, Greece, 27–29 February 2024; pp. 843–846. [Google Scholar]
- Su, C.; Wen, J.; Kang, J.; Wang, Y.; Su, Y.; Pan, H.; Zhong, Z.; Hossain, M.S. Hybrid RAG-Empowered Multi-Modal LLM for Secure Data Management in Internet of Medical Things: A Diffusion-Based Contract Approach. IEEE Internet Things J. 2024, 12, 13428–13440. [Google Scholar] [CrossRef]
- Pandya, S.; Srivastava, G.; Jhaveri, R.; Babu, M.R.; Bhattacharya, S.; Maddikunta, P.K.R.; Mastorakis, S.; Piran, M.J.; Gadekallu, T.R. Federated learning for smart cities: A comprehensive survey. Sustain. Energy Technol. Assess. 2023, 55, 102987. [Google Scholar] [CrossRef]
- Abusalah, B.; Qadah, T.M.; Stephen, J.J.; Eugster, P. Interminable Flows: A Generic, Joint, Customizable Resiliency Model for Big-Data Streaming Platforms. IEEE Access 2023, 11, 10762–10776. [Google Scholar] [CrossRef]
- Alam, A.; Ullah, I.; Lee, Y.K. Video big data analytics in the cloud: A reference architecture, survey, opportunities, and open research issues. IEEE Access 2020, 8, 152377–152422. [Google Scholar] [CrossRef]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge intelligence: The confluence of edge computing and artificial intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef]
- Das, A.; Roopaei, M.; Jamshidi, M.; Najafirad, P. Distributed ai-driven search engine on visual internet-of-things for event discovery in the cloud. In Proceedings of the 2022 17th Annual System of Systems Engineering Conference (SOSE), Rochester, NY, USA, 7–11 June 2022; pp. 514–521. [Google Scholar]
- Brecko, A.; Kajati, E.; Koziorek, J.; Zolotova, I. Federated learning for edge computing: A survey. Appl. Sci. 2022, 12, 9124. [Google Scholar] [CrossRef]
- Rahman, K.J.; Ahmed, F.; Akhter, N.; Hasan, M.; Amin, R.; Aziz, K.E.; Islam, A.M.; Mukta, M.S.H.; Islam, A.N. Challenges, applications and design aspects of federated learning: A survey. IEEE Access 2021, 9, 124682–124700. [Google Scholar] [CrossRef]
- Janaki, G.; Umanandhini, D. Federated Learning Approaches for Decentralized Data Processing in Edge Computing. In Proceedings of the 2024 5th International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 18–20 September 2024; pp. 513–519. [Google Scholar]
- Xu, R.; Razavi, S.; Zheng, R. Edge video analytics: A survey on applications, systems and enabling techniques. IEEE Commun. Surv. Tutor. 2023, 25, 2951–2982. [Google Scholar] [CrossRef]
- Wang, D.; Shi, S.; Zhu, Y.; Han, Z. Federated analytics: Opportunities and challenges. IEEE Netw. 2021, 36, 151–158. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S. A review of video surveillance systems. J. Vis. Commun. Image Represent. 2021, 77, 103116. [Google Scholar] [CrossRef]
- Cao, L. AI and data science for smart emergency, crisis and disaster resilience. Int. J. Data Sci. Anal. 2023, 15, 231–246. [Google Scholar] [CrossRef] [PubMed]
- Alam, A.; Lee, Y.K. Tornado: Intermediate results orchestration based service-oriented data curation framework for intelligent video big data analytics in the cloud. Sensors 2020, 20, 3581. [Google Scholar] [CrossRef] [PubMed]
- Wefelscheid, C. Monocular Camera Path Estimation Cross-linking Images in a Graph Structure. Ph.D. Thesis, TU Berlin, Berlin, Germany, 2013. [Google Scholar]
- Farahbakhsh, R. D2.2 State of the Art Analysis Report; TWIRL Project, ITEA3 Programme. 2023. Available online: https://itea3.org/project/workpackage/document/download/5794/TWIRL_D2.2_SOTA_Report.pdf (accessed on 3 June 2025).
- Zhang, W.; Xu, L.; Duan, P.; Gong, W.; Lu, Q.; Yang, S. A video cloud platform combing online and offline cloud computing technologies. Pers. Ubiquitous Comput. 2015, 19, 1099–1110. [Google Scholar] [CrossRef]
- Serrano, D.; Zhang, H.; Stroulia, E. Kaleidoscope: A Cloud-Based Platform for Real-Time Video-Based Interaction. In Proceedings of the 2016 IEEE World Congress on Services (SERVICES), San Francisco, CA, USA, 27 June–2 July 2016; pp. 107–110. [Google Scholar]
- Ara, A.; Ara, A. Cloud for big data analytics trends. IOSR J. Comput. Eng. 2016, 18, 01–06. [Google Scholar] [CrossRef]
- Gao, G.; Liu, C.H.; Chen, M.; Guo, S.; Leung, K.K. Cloud-based actor identification with batch-orthogonal local-sensitive hashing and sparse representation. IEEE Trans. Multimed. 2016, 18, 1749–1761. [Google Scholar] [CrossRef]
- Subudhi, B.N.; Rout, D.K.; Ghosh, A. Big data analytics for video surveillance. Multimed. Tools Appl. 2019, 78, 26129–26162. [Google Scholar] [CrossRef]
- Geng, D.; Zhang, C.; Xia, C.; Xia, X.; Liu, Q.; Fu, X. Big data-based improved data acquisition and storage system for designing industrial data platform. IEEE Access 2019, 7, 44574–44582. [Google Scholar] [CrossRef]
- Dai, J.J.; Wang, Y.; Qiu, X.; Ding, D.; Zhang, Y.; Wang, Y.; Jia, X.; Zhang, C.L.; Wan, Y.; Li, Z.; et al. Bigdl: A distributed deep learning framework for big data. In Proceedings of the ACM Symposium on Cloud Computing, Santa Cruz, CA, USA, 20–23 November 2019; pp. 50–60. [Google Scholar]
- Zhao, P.; Zhang, H.; Yu, Q.; Wang, Z.; Geng, Y.; Fu, F.; Yang, L.; Zhang, W.; Jiang, J.; Cui, B. Retrieval-augmented generation for ai-generated content: A survey. arXiv 2024, arXiv:2402.19473. [Google Scholar]
- Liang, C.; Du, H.; Sun, Y.; Niyato, D.; Kang, J.; Zhao, D.; Imran, M.A. Generative AI-driven semantic communication networks: Architecture, technologies and applications. IEEE Trans. Cogn. Commun. Netw. 2024, 11, 27–47. [Google Scholar] [CrossRef]
- Na, D.; Park, S. Blockchain-based dashcam video management method for data sharing and integrity in v2v network. IEEE Access 2022, 10, 3307–3319. [Google Scholar] [CrossRef]
- Simoens, P.; Xiao, Y.; Pillai, P.; Chen, Z.; Ha, K.; Satyanarayanan, M. Scalable crowd-sourcing of video from mobile devices. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 139–152. [Google Scholar]
- Xu, H.; Wang, L.; Xie, H. Design and experiment analysis of a Hadoop-based video transcoding system for next-generation wireless sensor networks. Int. J. Distrib. Sens. Netw. 2014, 10, 151564. [Google Scholar] [CrossRef]
- Chen, H.; Niu, D.; Lai, K.; Xu, Y.; Ardakani, M. Separating-plane factorization models: Scalable recommendation from one-class implicit feedback. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 669–678. [Google Scholar]
- Zhang, Y.; Xu, F.; Frise, E.; Wu, S.; Yu, B.; Xu, W. DataLab: A version data management and analytics system. In Proceedings of the 2016 IEEE/ACM 2nd International Workshop on Big Data Software Engineering (BIGDSE), Austin, TX, USA, 16 May 2016; pp. 12–18. [Google Scholar]
- Li, L.; Ota, K.; Dong, M. Humanlike driving: Empirical decision-making system for autonomous vehicles. IEEE Trans. Veh. Technol. 2018, 67, 6814–6823. [Google Scholar] [CrossRef]
- Trigka, M.; Dritsas, E. Edge and Cloud Computing in Smart Cities. Future Internet 2025, 17, 118. [Google Scholar] [CrossRef]
- Alghamdi, A.M.; Al Shehri, W.A.; Almalki, J.; Jannah, N.; Alsubaei, F.S. An architecture for COVID-19 analysis and detection using big data, AI, and data architectures. PLoS ONE 2024, 19, e0305483. [Google Scholar] [CrossRef] [PubMed]
- Syafrudin, M.; Alfian, G.; Fitriyani, N.E.; Rhee, J.Y. Performance analysis of IoT-based sensor, big data processing, and machine learning model for real-time monitoring system in automotive manufacturing. Sensors 2018, 18, 2946. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Li, J.; Wang, X.; Gu, Y.; Xu, L.; Hu, Y.; Zhu, L. Online internet traffic monitoring system using spark streaming. Big Data Min. Anal. 2018, 1, 47–56. [Google Scholar] [CrossRef]
- Simakovic, M.; Cica, Z.; Drajic, D. Big-Data Platform for Performance Monitoring of Telecom-Service-Provider Networks. Electronics 2022, 11, 2224. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, K.; Wang, L.; Wu, H.; Wang, Y.; Chen, C. SQLFlow: An Extensible Toolkit Integrating DB and AI. J. Mach. Learn. Res. 2023, 24, 1–9. [Google Scholar]
- Kothandapani, H.P. Emerging trends and technological advancements in data lakes for the financial sector: An in-depth analysis of data processing, analytics, and infrastructure innovations. Q. J. Emerg. Technol. Innov. 2023, 8, 62–75. [Google Scholar]
- Ranasinghe, K.; Ryoo, M.S. Language-based action concept spaces improve video self-supervised learning. Adv. Neural Inf. Process. Syst. 2023, 36, 74980–74994. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, H.; Ke, Q.; Gong, M.; Zhang, R. Video joint modelling based on hierarchical transformer for co-summarization. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3904–3917. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lu, T.; Li, L.; Huang, D. Enhancing personalized search with ai: A hybrid approach integrating deep learning and cloud computing. J. Adv. Comput. Syst. 2024, 4, 1–13. [Google Scholar] [CrossRef]
- Prangon, N.F.; Wu, J. AI and computing horizons: Cloud and edge in the modern era. J. Sens. Actuator Netw. 2024, 13, 44. [Google Scholar] [CrossRef]
- Sathupadi, K.; Achar, S.; Bhaskaran, S.V.; Faruqui, N.; Abdullah-Al-Wadud, M.; Uddin, J. Edge-cloud synergy for AI-enhanced sensor network data: A real-time predictive maintenance framework. Sensors 2024, 24, 7918. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Yang, S.; Zhao, C. SurveilEdge: Real-time video query based on collaborative cloud-edge deep learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 2519–2528. [Google Scholar]
- Kumar, Y.; Marchena, J.; Awlla, A.H.; Li, J.J.; Abdalla, H.B. The AI-Powered Evolution of Big Data. Appl. Sci. 2024, 14, 10176. [Google Scholar] [CrossRef]
- Hassan, A.; Prasad, V.; Bhattacharya, P.; Dutta, P.; Damaševičius, R. Federated Learning and AI for Healthcare 5.0; IGI Global: Hershey, PA, USA, 2024. [Google Scholar]
- Feuerriegel, S.; Hartmann, J.; Janiesch, C.; Zschech, P. Generative ai. Bus. Inf. Syst. Eng. 2024, 66, 111–126. [Google Scholar] [CrossRef]
- Akram, F.; Sani, M. Real-Time AI Systems: Leveraging Cloud Computing and Machine Learning for Big Data Processing. 2025. Available online: https://www.researchgate.net/publication/388526113_Real-Time_AI_Systems_Leveraging_Cloud_Computing_and_Machine_Learning_for_Big_Data_Processing (accessed on 8 June 2025).
- Moolikagedara, K.; Nguyen, M.; Yan, W.Q.; Li, X.J. Video Blockchain: A decentralized approach for secure and sustainable networks with distributed video footage from vehicle-mounted cameras in smart cities. Electronics 2023, 12, 3621. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6, 737–744. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Şengönül, E.; Samet, R.; Abu Al-Haija, Q.; Alqahtani, A.; Alturki, B.; Alsulami, A.A. An analysis of artificial intelligence techniques in surveillance video anomaly detection: A comprehensive survey. Appl. Sci. 2023, 13, 4956. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Graves, A.; Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Berroukham, A.; Housni, K.; Lahraichi, M.; Boulfrifi, I. Deep learning-based methods for anomaly detection in video surveillance: A review. Bull. Electr. Eng. Inform. 2023, 12, 314–327. [Google Scholar] [CrossRef]
- Wang, S.; Miao, Z. Anomaly detection in crowd scene. In Proceedings of the IEEE 10th International Conference on Signal Processing Proceedings, Beijing, China, 24–28 October 2010; pp. 1220–1223. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Alotaibi, S.R.; Mengash, H.A.; Maray, M.; Alotaibi, F.A.; Alkharashi, A.; Alzahrani, A.A.; Alotaibi, M.; Alnfiai, M.M. Integrating Explainable Artificial Intelligence with Advanced Deep Learning Model for Crowd Density Estimation in Real-world Surveillance Systems. IEEE Access 2025, 13, 20750–20762. [Google Scholar] [CrossRef]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 532–546. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; Schmid, C. Videobert: A joint model for video and language representation learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7464–7473. [Google Scholar]
- Bain, M.; Nagrani, A.; Varol, G.; Zisserman, A. Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1728–1738. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. Youtube-8m: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Gygli, M.; Grabner, H.; Riemenschneider, H.; Van Gool, L. Creating summaries from user videos. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part VII 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 505–520. [Google Scholar]
- Song, Y.; Vallmitjana, J.; Stent, A.; Jaimes, A. Tvsum: Summarizing web videos using titles. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5179–5187. [Google Scholar]
- Kushwah, J.S.; Dave, M.H.; Sharma, A.; Shrivastava, K.; Sharma, R.; Ahmed, M.N. AI-Enhanced Tracksegnet an Advanced Machine Learning Technique for Video Segmentation and Object Tracking. ICTACT J. Image Video Process. 2024, 15, 3384–3394. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022, Proceedings, Part XXII; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Patel, A.S.; Vyas, R.; Vyas, O.; Ojha, M.; Tiwari, V. Motion-compensated online object tracking for activity detection and crowd behavior analysis. Vis. Comput. 2023, 39, 2127–2147. [Google Scholar] [CrossRef] [PubMed]
- Vora, D.; Kadam, P.; Mohite, D.D.; Kumar, N.; Kumar, N.; Radhakrishnan, P.; Bhagwat, S. AI-driven video summarization for optimizing content retrieval and management through deep learning techniques. Sci. Rep. 2025, 15, 4058. [Google Scholar] [CrossRef] [PubMed]
- Morshed, M.G.; Sultana, T.; Alam, A.; Lee, Y.K. Human Action Recognition: A Taxonomy-Based Survey, Updates, and Opportunities. Sensors 2023, 23, 2182. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, A.M.; Kiani, K.; Rastgoo, R. A Transformer-based model for abnormal activity recognition in video. J. Model. Eng. 2024, 22, 213–221. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Bendali-Braham, M.; Weber, J.; Forestier, G.; Idoumghar, L.; Muller, P.A. Recent trends in crowd analysis: A review. Mach. Learn. Appl. 2021, 4, 100023. [Google Scholar] [CrossRef]
- Liao, Y.; Xie, J.; Geiger, A. KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3292–3310. [Google Scholar] [CrossRef] [PubMed]
- Kadam, P.; Vora, D.; Patil, S.; Mishra, S.; Khairnar, V. Behavioral Profiling for Adaptive Video Summarization: From Generalization to Personalization. MethodsX 2024, 13, 102780. [Google Scholar] [CrossRef] [PubMed]
- Hussain, T.; Muhammad, K.; Ding, W.; Lloret, J.; Baik, S.W.; De Albuquerque, V.H.C. A comprehensive survey of multi-view video summarization. Pattern Recognit. 2021, 109, 107567. [Google Scholar] [CrossRef]
- Wang, S.; Zhong, Y.; Wang, E. An integrated GIS platform architecture for spatiotemporal big data. Future Gener. Comput. Syst. 2019, 94, 160–172. [Google Scholar] [CrossRef]
- Chen, H.; Zi, X.; Zhang, Q.; Zhu, Y.; Wang, J. Computer big data technology in Internet network communication video monitoring of coal preparation plant. J. Phys. Conf. Ser. 2021, 2083, 042067. [Google Scholar] [CrossRef]
- Xu, C.; Du, X.; Yan, Z.; Fan, X. ScienceEarth: A big data platform for remote sensing data processing. Remote Sens. 2020, 12, 607. [Google Scholar] [CrossRef]
- Zhu, L.; Yu, F.; Wang, Y.; Ning, B. Big data analytics in intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2018, 20, 383–398. [Google Scholar] [CrossRef]
- Liu, W.; Long, Z.; Yang, G.; Xing, L. A self-powered wearable motion sensor for monitoring volleyball skill and building big sports data. Biosensors 2022, 12, 60. [Google Scholar] [CrossRef] [PubMed]
- Sharshar, A.; Eitta, A.H.A.; Fayez, A.; Khamis, M.A.; Zaky, A.B.; Gomaa, W. Camera coach: Activity recognition and assessment using thermal and RGB videos. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Fenil, E.; Dinesh Jackson Samuel, R.; Manogaran, G.; Vivekananda, G.N.; Thanjaivadivel, T.; Jeeva, S.; Ahilan, A. Real time violence detection framework for football stadium comprising of big data analysis and deep learning through bidirectional LSTM. Comput. Netw. 2019, 151, 191–200. [Google Scholar]
- Alam, A.; Khan, M.N.; Khan, J.; Lee, Y.K. Intellibvr-intelligent large-scale video retrieval for objects and events utilizing distributed deep-learning and semantic approaches. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 28–35. [Google Scholar]
- Gayakwad, M. Real-Time Clickstream Analytics with Apache. J. Electr. Syst. 2024, 20, 1600–1608. [Google Scholar] [CrossRef]
- Mouradian, C.; Ebrahimnezhad, F.; Jebbar, Y.; Ahluwalia, J.K.; Afrasiabi, S.N.; Glitho, R.H.; Moghe, A. An IoT platform-as-a-service for NFV-based hybrid cloud/fog systems. IEEE Internet Things J. 2020, 7, 6102–6115. [Google Scholar] [CrossRef]
- Raptis, T.P.; Cicconetti, C.; Falelakis, M.; Kalogiannis, G.; Kanellos, T.; Lobo, T.P. Engineering resource-efficient data management for smart cities with Apache Kafka. Future Internet 2023, 15, 43. [Google Scholar] [CrossRef]
- Hlaing, N.N.; Nyunt, T.T.S. Developing Scalable and Lightweight Data Stream Ingestion Framework for Stream Processing. In Proceedings of the 2023 IEEE Conference on Computer Applications (ICCA), Yangon, Myanmar, 27–28 February 2023; pp. 405–410. [Google Scholar]
- Xu, B.; Jiang, J.; Ye, J. Information intelligence system solution based on Big Data Flink technology. In Proceedings of the 4th International Conference on Big Data Engineering, Beijing, China, 26–28 May 2022; pp. 21–26. [Google Scholar]
- Shafiyah, S.; Ahsan, A.S.; Asmara, R. Big Data Infrastructure Design Optimizes Using Hadoop Technologies Based on Application Performance Analysis. Sist. J. Sist. Inf. 2022, 11, 55–72. [Google Scholar] [CrossRef]
- Yang, C.T.; Chen, T.Y.; Kristiani, E.; Wu, S.F. The implementation of data storage and analytics platform for big data lake of electricity usage with spark. J. Supercomput. 2021, 77, 5934–5959. [Google Scholar] [CrossRef]
- Tripathi, V.; Gangodkar, D.; Singh, D.P.; Bordoloi, D. Using Apache Spark Streaming and Kafka to Perform Face Recognition on Live Video Streams of Pedestrians. Webology 2021, 18, 3416–3423. [Google Scholar]
- Melenli, S.; Topkaya, A. Real-time maintaining of social distance in COVID-19 environment using image processing and big data. In Trends in Data Engineering Methods for Intelligent Systems: Proceedings of the International Conference on Artificial Intelligence and Applied Mathematics in Engineering (ICAIAME 2020), Antalya, Turkey, 18–20 April 2020; Springer: Cham, Switzerland, 2021; pp. 578–589. [Google Scholar]
- Mendhe, C.H.; Henderson, N.; Srivastava, G.; Mago, V. A scalable platform to collect, store, visualize, and analyze big data in real time. IEEE Trans. Comput. Soc. Syst. 2020, 8, 260–269. [Google Scholar] [CrossRef]
- Khan, M.N.; Alam, A.; Lee, Y.K. Falkon: Large-Scale Content-Based Video Retrieval Utilizing Deep-Features and Distributed In-Memory Computing. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 36–43. [Google Scholar]
- Uddin, M.A.; Alam, A.; Tu, N.A.; Islam, M.S.; Lee, Y.K. SIAT: A distributed video analytics framework for intelligent video surveillance. Symmetry 2019, 11, 911. [Google Scholar] [CrossRef]
- Supangkat, S.H.; Hidayat, F.; Dahlan, I.A.; Hamami, F. The implementation of traffic analytics using deep learning and big data technology with Garuda Smart City Framework. In Proceedings of the 2019 IEEE Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 883–887. [Google Scholar]
- Zhang, W.; Sun, H.; Zhao, D.; Xu, L.; Liu, X.; Ning, H.; Zhou, J.; Guo, Y.; Yang, S. A streaming cloud platform for real-time video processing on embedded devices. IEEE Trans. Cloud Comput. 2019, 9, 868–880. [Google Scholar] [CrossRef]
- Lv, J.; Wu, B.; Liu, C.; Gu, X. Pf-face: A parallel framework for face classification and search from massive videos based on spark. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–7. [Google Scholar]
- Munshi, A.A.; Mohamed, Y.A.R.I. Data lake lambda architecture for smart grids big data analytics. IEEE Access 2018, 6, 40463–40471. [Google Scholar] [CrossRef]
- Yang, Q. Application of Recommendation System Technology and Architecture in Video Streaming Platforms. Preprints 2025. [Google Scholar] [CrossRef]
- Rahman, M.; Provath, M.A.M.; Deb, K.; Dhar, P.K.; Shimamura, T. CAMFusion: Context-Aware Multi-Modal Fusion Framework for Detecting Sarcasm and Humor Integrating Video and Textual Cues. IEEE Access 2025, 13, 42530–42546. [Google Scholar] [CrossRef]
- Ahamad, R.; Mishra, K.N. Hybrid approach for suspicious object surveillance using video clips and UAV images in cloud-IoT-based computing environment. Clust. Comput. 2024, 27, 761–785. [Google Scholar] [CrossRef]
- Jung, J.; Park, S.; Kim, H.; Lee, C.; Hong, C. Artificial intelligence-driven video indexing for rapid surveillance footage summarization and review. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, Jeju, Republic of Korea, 3–9 August 2024; pp. 8687–8690. [Google Scholar]
- Mon, S.L.; Onizuka, T.; Tin, P.; Aikawa, M.; Kobayashi, I.; Zin, T.T. AI-enhanced real-time cattle identification system through tracking across various environments. Sci. Rep. 2024, 14, 17779. [Google Scholar] [CrossRef] [PubMed]
- Liu, A.; Mahapatra, R.P.; Mayuri, A. Hybrid design for sports data visualization using AI and big data analytics. Complex Intell. Syst. 2023, 9, 2969–2980. [Google Scholar] [CrossRef]
- Wu, K.; Xu, L. Deep Hybrid Neural Network With Attention Mechanism for Video Hash Retrieval Method. IEEE Access 2023, 11, 47956–47966. [Google Scholar] [CrossRef]
- Alpay, T.; Magg, S.; Broze, P.; Speck, D. Multimodal video retrieval with CLIP: A user study. Inf. Retr. J. 2023, 26, 6. [Google Scholar] [CrossRef]
- Ul Haq, H.B.; Asif, M.; Ahmad, M.B.; Ashraf, R.; Mahmood, T. An effective video summarization framework based on the object of interest using deep learning. Math. Probl. Eng. 2022, 2022, 7453744. [Google Scholar] [CrossRef]
- Apostolidis, E.; Adamantidou, E.; Metsai, A.I.; Mezaris, V.; Patras, I. Video summarization using deep neural networks: A survey. Proc. IEEE 2021, 109, 1838–1863. [Google Scholar] [CrossRef]
- Kul, S.; Tashiev, I.; Şentaş, A.; Sayar, A. Event-based microservices with Apache Kafka streams: A real-time vehicle detection system based on type, color, and speed attributes. IEEE Access 2021, 9, 83137–83148. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning. PmLR, Virtual, 8–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the 39th International Conference on Machine Learning. PMLR, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 12888–12900. [Google Scholar]
- Zeng, L.; Ye, S.; Chen, X.; Zhang, X.; Ren, J.; Tang, J.; Yang, Y.; Shen, X.S. Edge Graph Intelligence: Reciprocally Empowering Edge Networks with Graph Intelligence. IEEE Commun. Surv. Tutor. 2025. early access. [Google Scholar] [CrossRef]
- Ramamoorthi, V. Applications of AI in Cloud Computing: Transforming Industries and Future Opportunities. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2023, 9, 472–483. [Google Scholar]
- Hridi, A.P.; Sahay, R.; Hosseinalipour, S.; Akram, B. Revolutionizing AI-Assisted Education with Federated Learning: A Pathway to Distributed, Privacy-Preserving, and Debiased Learning Ecosystems. In Proceedings of the AAAI Symposium Series, Stanford, CA, USA, 25–27 March 2024; Volume 3, pp. 297–303. [Google Scholar]
- Hakam, N.; Benfriha, K.; Meyrueis, V.; Liotard, C. Advanced Monitoring of Manufacturing Process through Video Analytics. Sensors 2024, 24, 4239. [Google Scholar] [CrossRef] [PubMed]
- Rocha Neto, A.; Silva, T.P.; Batista, T.; Delicato, F.C.; Pires, P.F.; Lopes, F. Leveraging edge intelligence for video analytics in smart city applications. Information 2020, 12, 14. [Google Scholar] [CrossRef]
- Zhang, J.; Tsai, P.H.; Tsai, M.H. Semantic2Graph: Graph-based multi-modal feature fusion for action segmentation in videos. Appl. Intell. 2024, 54, 2084–2099. [Google Scholar] [CrossRef]
- Divya, G.; Swetha, K.; Santhi, S. A Decentralized Fog Architecture for Video Preprocessing in Cloud-based Video Surveillance as a Service. In Proceedings of the 2024 International Conference on Cognitive Robotics and Intelligent Systems (ICC-ROBINS), Coimbatore, India, 17–19 April 2024. [Google Scholar]
- Abdallah, R.; Harb, H.; Taher, Y.; Benbernou, S.; Haque, R. CRIMEO: Criminal Behavioral Patterns Mining and Extraction from Video Contents. In Proceedings of the 2023 IEEE 10th International Conference on Data Science and Advanced Analytics (DSAA), Thessaloniki, Greece, 9–13 October 2023; pp. 1–8. [Google Scholar]
- Gu, M.; Zhao, Z.; Jin, W.; Hong, R.; Wu, F. Graph-based multi-interaction network for video question answering. IEEE Trans. Image Process. 2021, 30, 2758–2770. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2019, 7, 535–547. [Google Scholar] [CrossRef]
- Kadam, A.J.; Akhade, K. A Review on Comparative Study of Popular Data Visualization Tools. Alochana J. 2024, 13, 532–538. [Google Scholar]
- Kumar, A.; Shawkat Ali, A. Big Data Visualization Tools, Challenges and Web Search Popularity-An Update till Today. In Big Data Intelligence and Computing: International Conference, DataCom 2022, Denarau Island, Fiji, 8–10 December 2022, Proceedings; Springer: Singapore, 2022; pp. 305–315. [Google Scholar]
- Il-Agure, Z.; Dempere, J. Review of data visualization techniques in IoT data. In Proceedings of the 2022 8th International Conference on Information Technology Trends (ITT), Dubai, United Arab Emirates, 25–26 May 2022; pp. 167–171. [Google Scholar]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Jiang, X.; Yu, F.R.; Song, T.; Leung, V.C. A survey on multi-access edge computing applied to video streaming: Some research issues and challenges. IEEE Commun. Surv. Tutor. 2021, 23, 871–903. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; He, B.; Song, D. Model-contrastive federated learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10713–10722. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the 37th International Conference on Machine Learning. PMLR, Virtual, 3–18 July 2020; pp. 5132–5143. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Kingori, S.W.; Nderu, L.; Njagi, D. Variational Auto-Encoder and Speeded-Up Robust Features Hybrd Model for Anomaly Detection and Localization in Video SequenCE with Scale Variation. J. Comput. Commun. 2025, 13, 153–165. [Google Scholar] [CrossRef]
- Li, Z. Cross-Layer Optimization for Video Delivery on Wireless Networks. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2023. [Google Scholar]

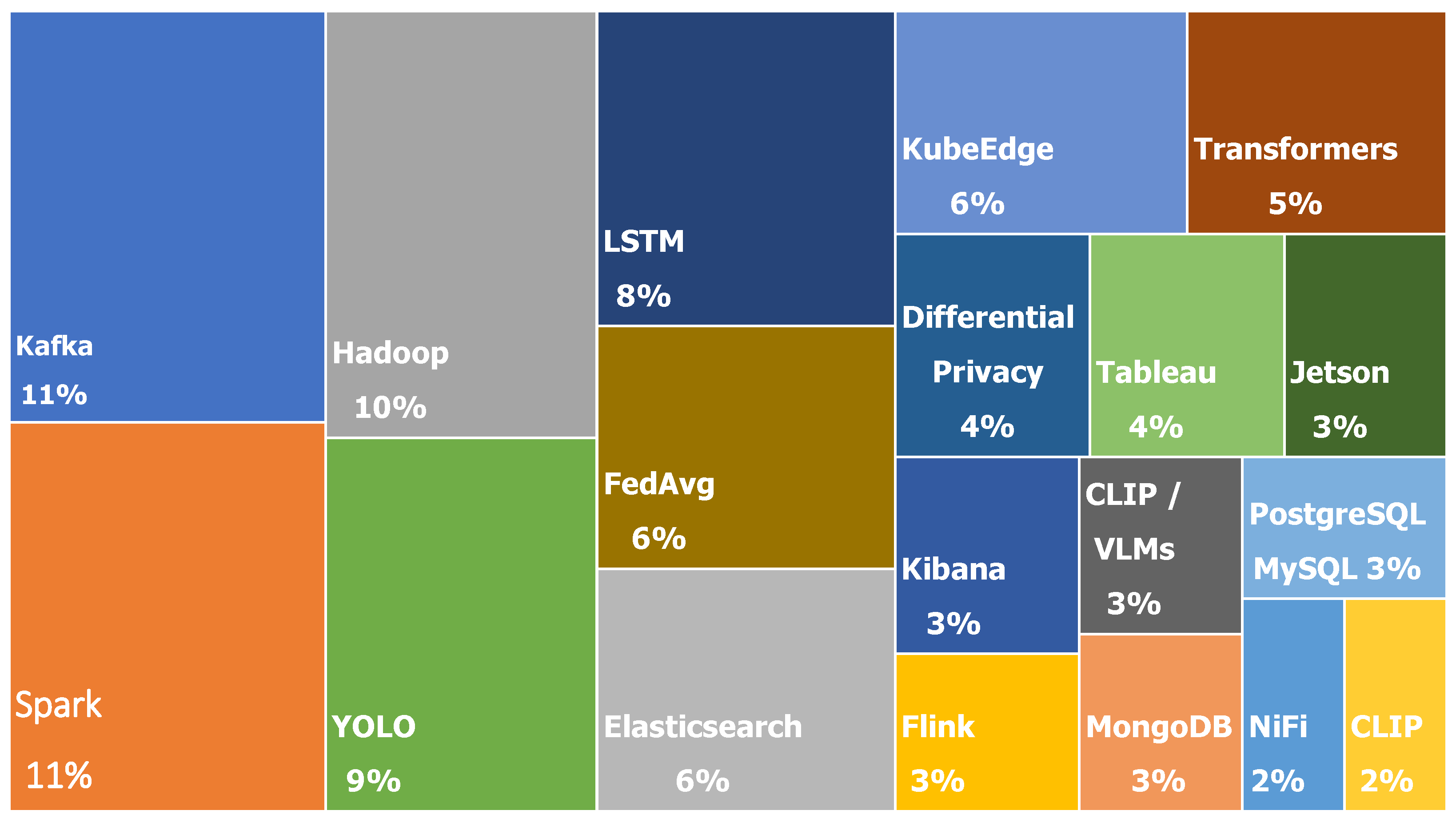

{kind=link}
{kind=link}
{kind=link}
| Problem Class | Representative Technologies | Benchmark Datasets | Applications | References |
|---|---|---|---|---|
| Object Detection and Tracking | YOLO, Faster R-CNN, SSD; DeepSORT, FairMOT; PointNet, VoxelNet | COCO, KITTI, VisDrone, AICity | Surveillance, Traffic Monitoring, Autonomous Driving, Sports | [88,89,90,91] |
| Activity and Behavior Analysis | 3D CNNs, LSTM, SlowFast, Transformers; OpenPose, HRNet; Multimodal Fusion | UCF-101, HMDB-51, NTU RGB+D, Kinetics | Healthcare, Human–Robot Interaction, Smart Spaces, Sports | [70,92,93,94] |
| Anomaly Detection | Autoencoders, Isolation Forest, GANs, GNNs, Transformers | UCSD, Avenue, ShanghaiTech | Intrusion Detection, Industrial Safety, Emergency Response | [5,74,95] |
| Crowd Analysis | CNN Density Maps, Optical Flow, YOLOv8, GNNs, Transformers | UCF-QNRF, ShanghaiTech, Mall | Event Safety, Urban Planning, Transit Optimization | [77,91,96] |
| Content-Based Retrieval and Understanding | VideoBERT, CLIP, FAISS, Pinecone, ElasticSearch | YouTube-8M, ActivityNet, MSR-VTT | Surveillance Forensics, Media Search, Smart Recommender | [82,93,97] |
| Video Summarization and Captioning | VST, ViViT, TimeSformer; BLIP-2, GPT-4V; Diffusion Models | TVSum, SumMe, Kinetics, Show and Tell | Surveillance Triage, Media Editing, Accessibility | [92,98,99] |
| Architecture | Key Characteristics | Advantages | Limitations | VBDA Suitability | Reference |
|---|---|---|---|---|---|
| Centralized | Single-node processing; local storage; no distribution. | Low deployment cost; simple management; consistent control. | High latency; poor scalability; privacy risks; SPOF. | Limited: Suitable for small-scale or archival VBDA. | Wu et al. (2022) [6] Wang et al. (2019) [100] Chen et al. (2021) [101] |
| Cloud-Centric | Compute and storage offloaded to cloud; centralized orchestration. | High scalability; deep learning support; elastic compute; lower hardware burden. | Latency from data upload; privacy concerns; higher recurring cost. | Moderate to High: Batch analytics, model training. | Chen et al. (2021) [101] Xu et al. (2020) [102] Zhu et al. (2018) [103] |
| Edge Computing | Local inference near data source; minimal cloud dependency. | Ultra-low latency; enhanced privacy; bandwidth-efficient; real-time response. | Limited compute; synchronization overhead; hardware heterogeneity. | High: Suitable for real-time apps (e.g., smart cities, surveillance). | Liu et al. (2022) [104] Sharshar et al. (2023) [105] Fenil et al. (2019) [106] |
| Hybrid Cloud–Edge | Edge handles real-time inference; cloud for training, storage, orchestration. | Balanced latency and scalability; privacy-aware; supports FL; adaptive workload distribution. | Complex deployment; resource orchestration challenges; higher initial setup cost. | Very High: Best for large-scale, real-time VBDA systems. | Alam et al. (2020) [107] Gayakwad et al. (2024) [108] Mouradian et al. (2020) [109] |
| Reference | Year | Hadoop (Map Reduce) | Kafka | Spark | Flink | NiFi | Hive | Impala | Pig | Storm |
|---|---|---|---|---|---|---|---|---|---|---|
| Gayakwad et al. [108] | 2024 | ✓ | ✓ | |||||||
| Hlaing et al. [111] | 2023 | ✓ | ✓ | |||||||
| Abusalah et al. [10] | 2023 | ✓ | ✓ | ✓ | ||||||
| Raptis et al. [110] | 2023 | ✓ | ✓ | |||||||
| Xu et al. [112] | 2022 | ✓ | ✓ | |||||||
| Shafiyah et al. [113] | 2022 | ✓ | ✓ | ✓ | ||||||
| Yang et al. [114] | 2021 | ✓ | ✓ | ✓ | ||||||
| Tripathi et al. [115] | 2021 | ✓ | ✓ | ✓ | ||||||
| Melenli et al. [116] | 2021 | ✓ | ✓ | ✓ | ✓ | |||||
| Alam et al. [21] | 2020 | ✓ | ✓ | ✓ | ||||||
| Alam et al. [107] | 2020 | ✓ | ✓ | |||||||
| Alam et al. [11] | 2020 | ✓ | ✓ | ✓ | ✓ | |||||
| Mendhe et al. [117] | 2020 | ✓ | ✓ | |||||||
| Khan et al. [118] | 2020 | ✓ | ✓ | |||||||
| Uddin et al. [119] | 2019 | ✓ | ✓ | |||||||
| Supangkat et al. [120] | 2019 | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Wang et al. [100] | 2019 | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Dai et al. [30] | 2019 | ✓ | ✓ | |||||||
| Zhang et al. [121] | 2019 | ✓ | ✓ | ✓ | ||||||
| Lv et al. [122] | 2018 | ✓ | ||||||||
| Munshi et al. [123] | 2018 | ✓ | ✓ | ✓ | ✓ | |||||
| Total | 6 | 17 | 16 | 4 | 3 | 6 | 3 | 1 | 3 |
| Reference | Year | YOLO | R-CNN Family | 3D-CNN/ SlowFast | LSTM | Transformers | GANs | CLIP/ VLMs | SSL Methods | Anomaly Models | MOT Trackers |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Yang et al. [124] | 2025 | ✓ | ✓ | ✓ | |||||||
| Rahman et al. [125] | 2025 | ✓ | ✓ | ✓ | |||||||
| Ahamad et al. [126] | 2024 | ✓ | ✓ | ||||||||
| Liang et al. [32] | 2024 | ✓ | ✓ | ✓ | ✓ | ||||||
| Jung et al. [127] | 2024 | ✓ | ✓ | ✓ | ✓ | ||||||
| Zhao et al. [31] | 2024 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Su et al. [8] | 2024 | ✓ | |||||||||
| Sathupadi et al. [51] | 2024 | ✓ | ✓ | ✓ | |||||||
| Mon et al. [128] | 2024 | ✓ | ✓ | ✓ | |||||||
| Hassan et al. [54] | 2024 | ✓ | ✓ | ✓ | ✓ | ||||||
| Liu et al. [129] | 2023 | ✓ | |||||||||
| Wu et al. [130] | 2023 | ✓ | ✓ | ||||||||
| Alpay et al. [131] | 2023 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Badidi et al. [5] | 2023 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Kwon et al. [4] | 2022 | ✓ | ✓ | ||||||||
| Wu et al. [6] | 2022 | ✓ | |||||||||
| Na et al. [33] | 2022 | ✓ | |||||||||
| Ulhaq et al. [132] | 2022 | ✓ | ✓ | ✓ | |||||||
| Apostolidis et al. [133] | 2021 | ✓ | ✓ | ✓ | |||||||
| Kul et al. [134] | 2021 | ✓ | ✓ | ||||||||
| Alam et al. [107] | 2020 | ✓ | |||||||||
| Khan et al. [118] | 2020 | ✓ | |||||||||
| Subudhi et al. [28] | 2019 | ✓ | |||||||||
| Dai et al. [30] | 2019 | ✓ | ✓ | ||||||||
| Geng et al. [29] | 2019 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Total | 14 | 11 | 2 | 13 | 8 | 5 | 4 | 3 | 4 | 3 |
| Reference | Year | FL Algorithms | FL Frameworks | Privacy | Model Optimization | Edge AI Hardware | Edge-Cloud Orchestration | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FedAvg | FedProx | FedML | TFF | Techs | Prun. | Quant. | KD | Jetson | Coral | Movidius | |||
| Zeng et al. [137] | 2025 | ✓ | ✓ | ||||||||||
| Hridi et al. [139] | 2024 | ✓ | ✓ | ||||||||||
| Hakam et al. [140] | 2024 | ✓ | ✓ | ✓ | |||||||||
| Su et al. [8] | 2024 | ✓ | ✓ | ||||||||||
| Wang et al. [3] | 2024 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Prangon et al. [50] | 2024 | ✓ | ✓ | ✓ | |||||||||
| Pandya et al. [9] | 2023 | ✓ | ✓ | ✓ | |||||||||
| Badidi et al. [5] | 2023 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| Ramamoorthi et al. [138] | 2023 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Brecko et al. [14] | 2022 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Das et al. [13] | 2022 | ✓ | ✓ | ✓ | |||||||||
| Kwon et al. [4] | 2022 | ✓ | ✓ | ✓ | ✓ | ||||||||
| Rocha et al. [141] | 2020 | ✓ | ✓ | ✓ | ✓ | ||||||||
| Total | 10 | 3 | 3 | 4 | 6 | 2 | 1 | 3 | 5 | 2 | 3 | 9 | |
| Reference | Year | Hadoop (HDFS) | Cloud Storages | NoSQL DBs | Graph DB | SQL DBs | Auxiliary Techs | AI-Driven Indexing and Retrieval | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Amazon S3 | Google Cloud | Azure Data Lake | HBase | Mongo DB | Cassandra | MySQL | Postgre SQL | ||||||
| Gayakwad et al. [108] | 2024 | ✓ | AI Search | ||||||||||
| Zhang et al. [142] | 2024 | ✓ | Graph-based Retrieval | ||||||||||
| Divya et al. [143] | 2024 | ✓ | ✓ | ✓ | |||||||||
| Zhai et al. [7] | 2024 | ✓ | ✓ | ✓ | ✓ | Elasticsearch, Phoenix | FAISS | ||||||
| Abdallah et al. [144] | 2023 | ✓ | CLIP | ||||||||||
| Raptis et al. [110] | 2023 | ✓ | ✓ | ✓ | Zookeeper, Elasticsearch | ||||||||
| Shafiyah et al. [113] | 2022 | ✓ | ✓ | ✓ | Zookeeper, Elasticsearch | ||||||||
| Gu et al. [145] | 2021 | ✓ | RDF | VideoBERT | |||||||||
| Yang et al. [114] | 2021 | ✓ | ✓ | ✓ | Phoenix | ||||||||
| Meleni et al. [116] | 2021 | ✓ | ✓ | ✓ | Zookeeper Elasticsearch | ||||||||
| Kul et al. [134] | 2021 | ✓ | ✓ | Zookeeper Docker | |||||||||
| Alam et al. [21] | 2020 | ✓ | ✓ | Zookeeper Phoenix | |||||||||
| Khan et al. [118] | 2020 | ✓ | ✓ | Zookeeper Phoenix | |||||||||
| Xu et al. [102] | 2020 | ✓ | ✓ | Thrift Elasticsearch | |||||||||
| Mendhe et al. [117] | 2020 | ✓ | Elasticsearch | ||||||||||
| Alam et al. [107] | 2020 | ✓ | ✓ | RDF | |||||||||
| Alam et al. [11] | 2020 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| Uddin et al. [119] | 2019 | ✓ | ✓ | ✓ | ✓ | ✓ | Zookeeper Elasticsearch Phoenix | ||||||
| Dai et al. [30] | 2019 | ✓ | ✓ | Thrift | BLIP | ||||||||
| Wang et al. [100] | 2019 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Docker, Elasticsearch | |||||
| Zhang et al. [121] | 2019 | ✓ | ✓ | Zookeeper Docker | |||||||||
| Munshi et al. [123] | 2018 | ✓ | ✓ | Google Knowledge Graph | |||||||||
| Total | 16 | 5 | 5 | 5 | 11 | 4 | 1 | 3 | 3 | 3 | |||
| Reference | Year | Tableau | Power BI | Zeppelin | Qlik Sense | Grafana | Kibana |
|---|---|---|---|---|---|---|---|
| Gayakwad et al. [108] | 2024 | ✓ | |||||
| Kadam et al. [147] | 2024 | ✓ | ✓ | ||||
| Kumar et al. [148] | 2022 | ✓ | ✓ | ✓ | |||
| Xu et al. [112] | 2022 | ✓ | |||||
| Il et al. [149] | 2022 | ✓ | ✓ | ✓ | ✓ | ||
| Shafiyah et al. [113] | 2022 | ✓ | ✓ | ✓ | |||
| Mendhe et al. [117] | 2020 | ✓ | |||||
| Wang et al. [100] | 2019 | ✓ | ✓ | ||||
| Munshi et al. [123] | 2018 | ✓ | |||||
| Total | 6 | 3 | 2 | 1 | 1 | 5 |
| Components | Applicable Technologies |
|---|---|
| Edge Inference | YOLOv8-tiny, MobileNet, TensorRT, TFLite, OpenVINO, NVIDIA Jetson |
| FL Frameworks | TensorFlow Federated, NVIDIA FLARE, FedAvg, Secure Multi-Party Computation (SMPC) |
| Stream Processing | Apache Kafka, Apache Flink, Spark Streaming, Apache NiFi |
| Hybrid and AI-Optimized Storage | Hadoop HDFS, MinIO, AWS S3, Ceph, Redis |
| Structured and Semantic Storage | Delta Lake, PostgreSQL, MongoDB, HBase, GraphDB |
| Search and Indexing | FAISS, OpenAI CLIP, Pinecone, Whisper, Elasticsearch, VideoBERT |
| Privacy and Security | Homomorphic Encryption, Differential Privacy, Zero-Knowledge Proofs (ZKP), RBAC, Intel SGX |
| UI/UX and Visualization | Tableau, Kibana, Grafana, Power BI, Unity, Meta Quest, GPT, HoloLens, GradCAM, SHAP |
| Criteria/Layer | FALKON [115] | SIAT [116] | SurveilEdge [49] | VIDEX [130] | ViMindXAI (Proposed) |
|---|---|---|---|---|---|
| Architecture Type | Centralized | Cloud-Centric | Edge Computing | Hybrid Cloud–Edge | Hybrid Cloud–Edge (Cognitive) |
| Edge Preprocessing (DAL) | Basic edge input; limited model support | Standard ingestion (Kafka/NiFi) | YOLO-based detection + task allocation | Parallel object/anomaly threads | Edge AI (YOLOv8-tiny), denoising, ONNX models, FL at acquisition layer |
| Federated Learning and Privacy (DAL/DaAL) | Minimal FL, no privacy focus | FedAvg at cloud layer only | FL partially applied | Loosely coordinated FL logic | Full FL (FedAvg/Prox), PETs, Zero Trust sync |
| Lakehouse and Storage Orchestration (DIL) | HDFS-based batch storage | HDFS/HBase architecture | Local DB (SQLite) only | Unspecified backend storage | Delta Lake, Iceberg, Redis, hybrid S3/Ceph |
| Multimodal Semantic Indexing (DIL) | Basic temporal-spatial indexing | Partial Elastic-based indexing | Edge-level metadata tagging | Metadata-based object search | CLIP, VideoBERT, FAISS, GraphDB |
| Graph-Based Reasoning (DIL) | Not supported | Not supported | Not supported | Lightweight reasoning | Integrated graph-based modeling |
| Explainable AI (DaAL) | Not integrated | Some dashboard visualizations | Cloud-side reclassification logic | Parallel logic with minimal XAI | XAI tools (GradCAM, SHAP) throughout pipeline |
| Compliance and Security (DaAL) | Standard encryption only | Limited PETs in FL logic | Device-local privacy only | Basic authentication | GDPR/HIPAA compliance, Apache Atlas, Zero Trust |
| Immersive and Explainable UI (UEL) | Basic dashboard visualization | Grafana/Kibana UI | 2D dashboard UI | MVVM GUI with static views | Immersive monitoring, adaptive dashboards, XAI overlays |
| Natural Language Analytics (UEL) | Not supported | Not supported | Not supported | Not supported | Natural language querying via GPT and semantic video embeddings |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Do, T.-T.-T.; Huynh, Q.-T.; Kim, K.; Nguyen, V.-Q. A Survey on Video Big Data Analytics: Architecture, Technologies, and Open Research Challenges. Appl. Sci. 2025, 15, 8089. https://doi.org/10.3390/app15148089
Do T-T-T, Huynh Q-T, Kim K, Nguyen V-Q. A Survey on Video Big Data Analytics: Architecture, Technologies, and Open Research Challenges. Applied Sciences. 2025; 15(14):8089. https://doi.org/10.3390/app15148089
Chicago/Turabian StyleDo, Thi-Thu-Trang, Quyet-Thang Huynh, Kyungbaek Kim, and Van-Quyet Nguyen. 2025. "A Survey on Video Big Data Analytics: Architecture, Technologies, and Open Research Challenges" Applied Sciences 15, no. 14: 8089. https://doi.org/10.3390/app15148089
APA StyleDo, T.-T.-T., Huynh, Q.-T., Kim, K., & Nguyen, V.-Q. (2025). A Survey on Video Big Data Analytics: Architecture, Technologies, and Open Research Challenges. Applied Sciences, 15(14), 8089. https://doi.org/10.3390/app15148089