
Multimodal Fusion Multi-Task Learning Network Based on Federated Averaging for SDB Severity Diagnosis



Abstract
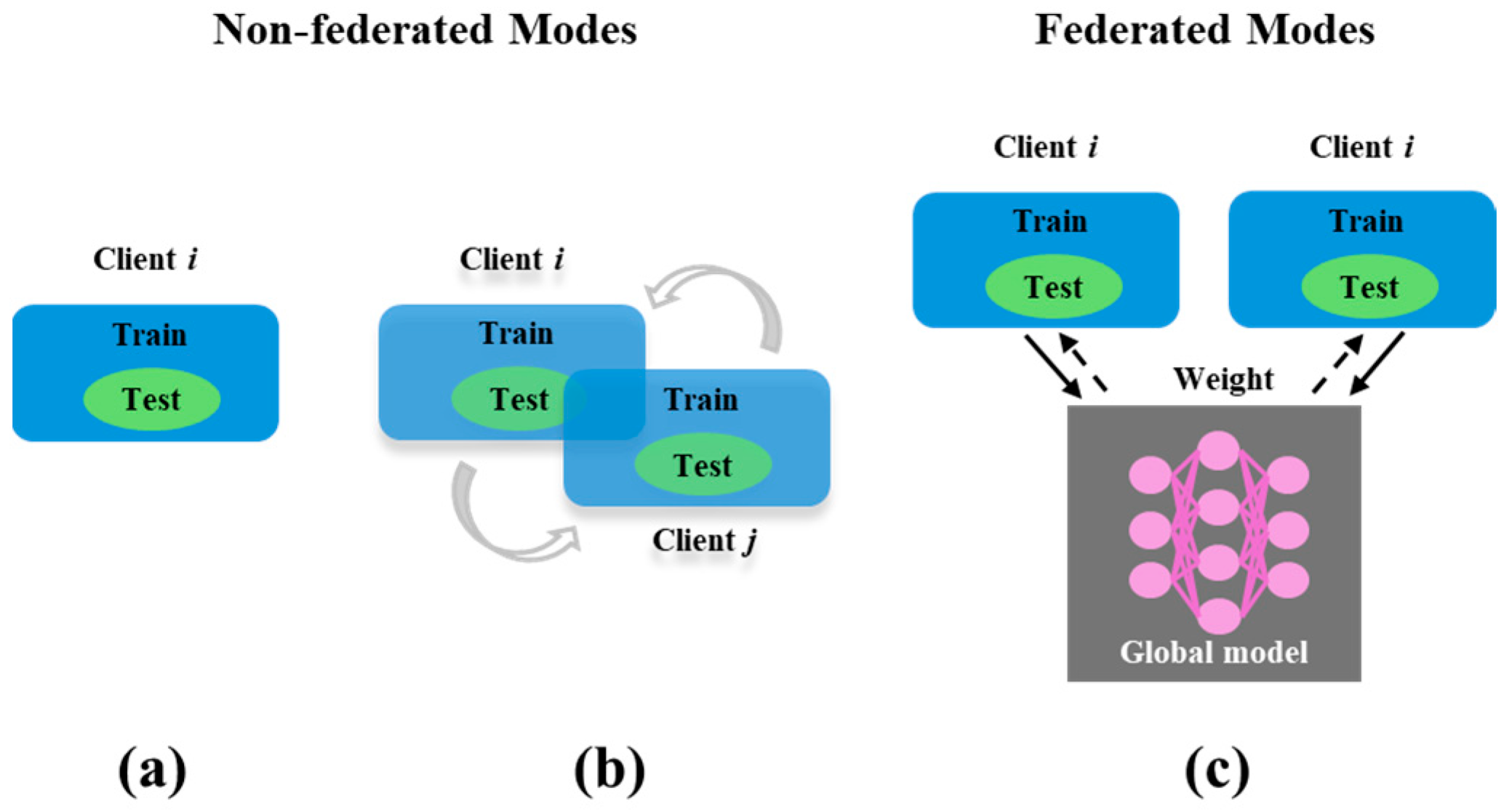
1. Introduction
- To develop a unified multi-task framework that leverages multimodal PSG signals, including EEG, respiration, ECG, snoring, and SpO2, for joint sleep staging and SDB severity classification, thereby enhancing diagnostic accuracy and efficiency.
- To address the non-IID challenge inherent in real-world sleep data through federated learning, enabling decentralized model training across clinical centers while protecting patient privacy and improving cross-site generalization.
2. Methods: FMTL Framework
2.1. FedAvg Algorithm
| Algorithm 1. Federated multi-task training loop (FedAvg). |
| Input: Global shared encoder , client datasets , number of rounds , local epochs , batch size for to do Server selects random subset (20% of clients) for each client in parallel do Receive from server Update local model via multi-task training for E epochs: Upload to server if training completed within end for Server aggregates: end for Return: Final global encoder |
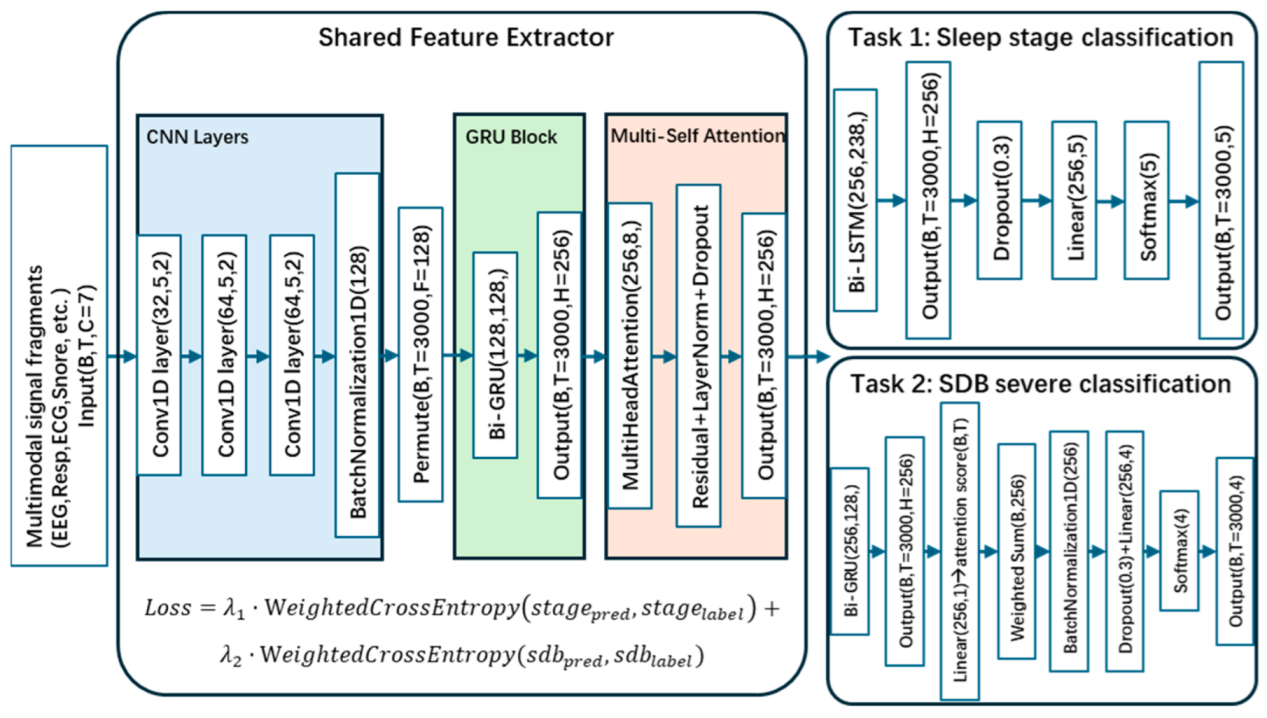
2.2. Multi-Task Learning Framework
3. Materials and Experiment Design
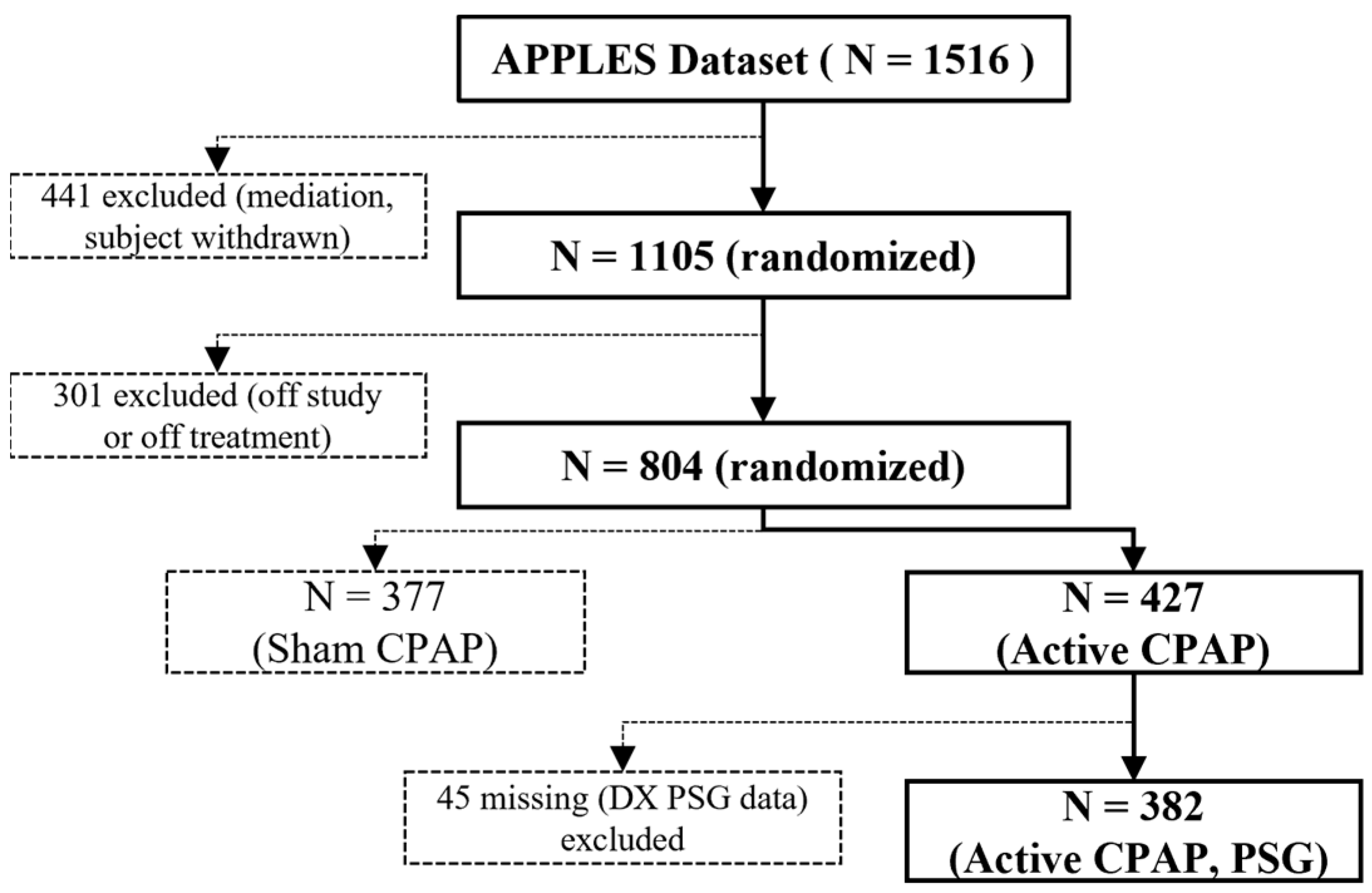
3.1. Dataset Description
3.1.1. APPLES Dataset [33,34]
3.1.2. SHHS Dataset [33,35]
3.1.3. HMC Dataset [36,37,38]
3.2. Experiment Design
3.3. Evaluation Metrics
4. Results
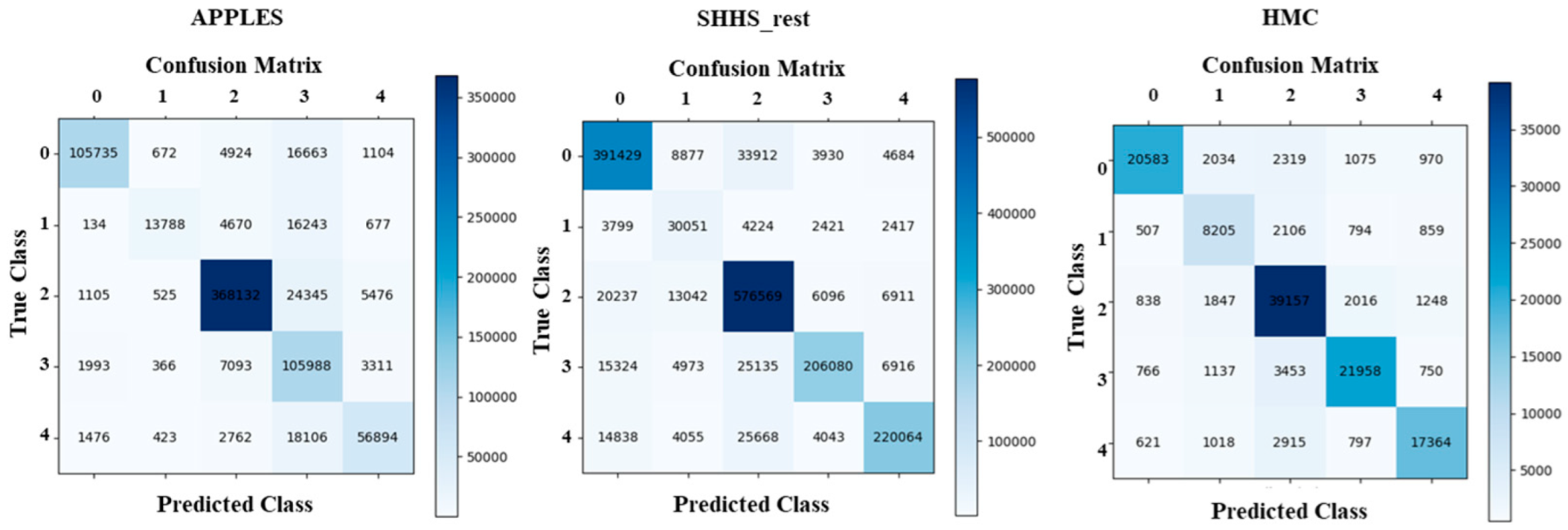
4.1. Sleep Staging Performance
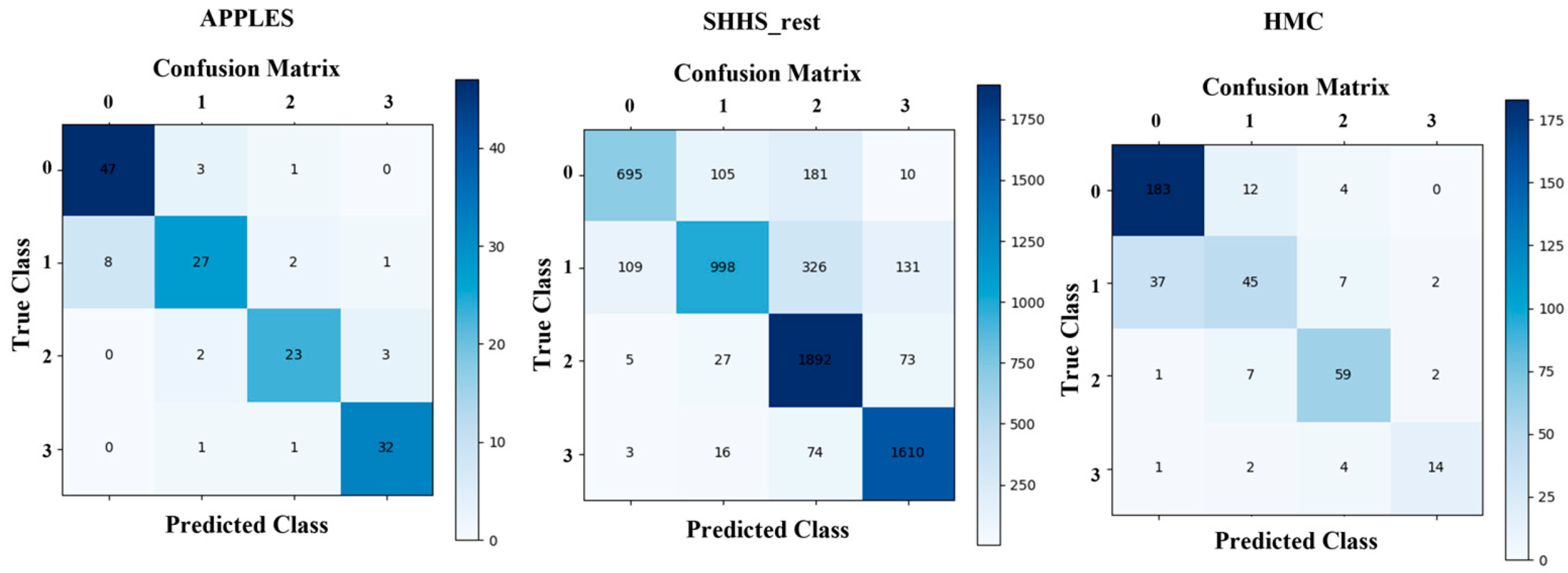
4.2. SDB Severity Classification Performance
4.3. FMTL Framework Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alimova, M.; Djyanbekova, F.; Meliboyeva, D.; Safarova, D. Benefits of sleep. Mod. Sci. Res. 2025, 4, 780–789. [Google Scholar]
- Moosavi-Movahedi, A.A.; Moosavi-Movahedi, F.; Yousefi, R. Good sleep as an important pillar for a healthy life. In Rationality and Scientific Lifestyle for Health; Springer: Cham, Switzerland, 2021; pp. 167–195. [Google Scholar]
- Ioachimescu, O.C.; Collop, N.A. Sleep-disordered breathing. Neurol. Clin. 2012, 30, 1095–1136. [Google Scholar] [CrossRef] [PubMed]
- Quan, S.F.; Gersh, B.J. Cardiovascular consequences of sleep-disordered breathing: Past, present and future: Report of a workshop from the National Center on Sleep Disorders Research and the National Heart, Lung, and Blood Institute. Circulation 2004, 109, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Leng, Y.; McEvoy, C.T.; Allen, I.E.; Yaffe, K. Association of sleep-disordered breathing with cognitive function and risk of cognitive impairment: A systematic review and meta-analysis. JAMA Neurol. 2017, 74, 1237–1245. [Google Scholar] [CrossRef] [PubMed]
- Rundo, J.V.; Downey, R., III. Polysomnography. Handb. Clin. Neurol. 2019, 160, 381–392. [Google Scholar] [PubMed]
- Gonzalez-Bermejo, J.; Perrin, C.; Janssens, J.; Pepin, J.; Mroue, G.; Léger, P.; Langevin, B.; Rouault, S.; Rabec, C.; Rodenstein, D. Proposal for a systematic analysis of polygraphy or polysomnography for identifying and scoring abnormal events occurring during non-invasive ventilation. Thorax 2012, 67, 546–552. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.-Y.; Wu, H.-T.; Hsu, C.-A.; Huang, P.-C.; Huang, Y.-H.; Lo, Y.-L. Sleep apnea detection based on thoracic and abdominal movement signals of wearable piezoelectric bands. IEEE J. Biomed. Health Inform. 2016, 21, 1533–1545. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Fonseca, P.; van Dijk, J.; Overeem, S.; Long, X. A multi-task learning model using RR intervals and respiratory effort to assess sleep disordered breathing. Biomed. Eng. OnLine 2024, 23, 45. [Google Scholar] [CrossRef] [PubMed]
- Campbell, A.J.; Neill, A.M. Home set-up polysomnography in the assessment of suspected obstructive sleep apnea. J. Sleep Res. 2011, 20, 207–213. [Google Scholar] [CrossRef] [PubMed]
- Portier, F.; Portmann, A.; Czernichow, P.; Vascaut, L.; Devin, E.; Benhamou, D.; Cuvelier, A.; Muir, J.F. Evaluation of home versus laboratory polysomnography in the diagnosis of sleep apnea syndrome. Am. J. Respir. Crit. Care Med. 2000, 162, 814–818. [Google Scholar] [CrossRef] [PubMed]
- Zancanella, E.; do Prado, L.F.; de Carvalho, L.B.; Machado Júnior, A.J.; Crespo, A.N.; do Prado, G.F. Home sleep apnea testing: An accuracy study. Sleep Breath. 2022, 26, 117–123. [Google Scholar] [CrossRef] [PubMed]
- Golpe, R.; Jime, A.; Carpizo, R. Home sleep studies in the assessment of sleep apnea/hypopnea syndrome. Chest 2002, 122, 1156–1161. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez-Tobal, G.C.; Hornero, R.; Álvarez, D.; Marcos, J.V.; Del Campo, F. Linear and nonlinear analysis of airflow recordings to help in sleep apnoea–hypopnoea syndrome diagnosis. Physiol. Meas. 2012, 33, 1261. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lin, Y.; Wang, J. A RR interval based automated apnea detection approach using residual network. Comput. Methods Programs Biomed. 2019, 176, 93–104. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Wang, Y.; Wang, Z. An Automatic Multi-Head Self-Attention Sleep Staging Method Using Single-Lead Electrocardiogram Signals. Comput. Cardiol. 2024, 51, 1–4. [Google Scholar]
- Lin, S.; Wang, Z.; van Gorp, H.; Xu, M.; van Gilst, M.; Overeem, S.; Linnartz, J.-P.; Fonseca, P.; Long, X. SSC-SleepNet: A Siamese-Based Automatic Sleep Staging Model with Improved N1 Sleep Detection. IEEE J. Biomed. Health Inform. 2025, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Li, J.; Guo, Y. Sequence signal reconstruction based multi-task deep learning for sleep staging on single-channel EEG. Biomed. Signal Process. Control 2024, 88, 105615. [Google Scholar] [CrossRef]
- Shi, L.; Gui, R.; Wang, L.; Li, P.; Niu, Q. A Multi-Task Deep Learning Approach for Simultaneous Sleep Staging and Apnea Detection for Elderly People. Interdiscip. Sci. Comput. Life Sci. 2025, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Cacioppo, J.T.; Tassinary, L.G. Inferring psychological significance from physiological signals. Am. Psychol. 1990, 45, 16. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Guo, J.; Zhao, S.; Fu, M.; Duan, L.; Wang, G.-H.; Chen, Q.-G.; Xu, Z.; Luo, W.; Zhang, K. Unified multimodal understanding and generation models: Advances, challenges, and opportunities. arXiv 2025, arXiv:250502567. [Google Scholar]
- Aggarwal, N.; Ahmed, M.; Basu, S.; Curtin, J.J.; Evans, B.J.; Matheny, M.E.; Nundy, S.; Sendak, M.P.; Shachar, C.; Shah, R.U. Advancing artificial intelligence in health settings outside the hospital and clinic. NAM Perspect. 2020, 2020. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:190702189. [Google Scholar]
- Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; Qin, Y. A state-of-the-art survey on solving non-iid data in federated learning. Future Gener. Comput. Syst. 2022, 135, 244–258. [Google Scholar] [CrossRef]
- Mammen, P.M. Federated learning: Opportunities and challenges. arXiv 2021, arXiv:210105428. [Google Scholar]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Smith, V.; Chiang, C.-K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Marfoq, O.; Neglia, G.; Bellet, A.; Kameni, L.; Vidal, R. Federated multi-task learning under a mixture of distributions. Adv. Neural Inf. Process. Syst. 2021, 34, 15434–15447. [Google Scholar]
- Fusco, P.; Errico, P.; Venticinque, S. Federated Learning Algorithm for Identification of Apnea Sleeping Disorder. In International Conference on Advanced Information Networking and Applications; Springer: Berlin/Heidelberg, Germany, 2025; pp. 253–261. [Google Scholar]
- Lebeña, N.; Blanco, A.; Casillas, A.; Oronoz, M.; Pérez, A. Clinical Federated Learning for Private ICD-10 Classification of Electronic Health Records from Several Spanish Hospitals. Proces. Leng. Nat. 2025, 74, 33–42. [Google Scholar]
- Sun, T.; Li, D.; Wang, B. Decentralized federated averaging. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4289–4301. [Google Scholar] [CrossRef] [PubMed]
- Eldele, E.; Chen, Z.; Liu, C.; Wu, M.; Kwoh, C.-K.; Li, X.; Guan, C. An attention-based deep learning approach for sleep stage classification with single-channel EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 809–818. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.-Q.; Cui, L.; Mueller, R.; Tao, S.; Kim, M.; Rueschman, M.; Mariani, S.; Mobley, D.; Redline, S. The National Sleep Research Resource: Towards a sleep data commons. J. Am. Med. Inform. Assoc. 2018, 25, 1351–1358. [Google Scholar] [CrossRef] [PubMed]
- Quan, S.F.; Chan, C.S.; Dement, W.C.; Gevins, A.; Goodwin, J.L.; Gottlieb, D.J.; Green, S.; Guilleminault, C.; Hirshkowitz, M.; Hyde, P.R. The association between obstructive sleep apnea and neurocognitive performance—The Apnea Positive Pressure Long-term Efficacy Study (APPLES). Sleep 2011, 34, 303–314. [Google Scholar] [CrossRef] [PubMed]
- Quan, S.F.; Howard, B.V.; Iber, C.; Kiley, J.P.; Nieto, F.J.; O’Connor, G.T.; Rapoport, D.M.; Redline, S.; Robbins, J.; Samet, J.M. The sleep heart health study: Design, rationale, and methods. Sleep 1997, 20, 1077–1085. [Google Scholar] [CrossRef] [PubMed]
- Alvarez-Estevez, D.; Rijsman, R. Haaglanden medisch centrum sleep staging database (version 1.1). PhysioNet 2022. [Google Scholar] [CrossRef]
- Alvarez-Estevez, D.; Rijsman, R.M. Inter-database validation of a deep learning approach for automatic sleep scoring. PLoS ONE 2021, 16, e0256111. [Google Scholar] [CrossRef] [PubMed]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Fonseca, P.; van Dijk, J.P.; Long, X.; Overeem, S. The use of respiratory effort improves an ECG-based deep learning algorithm to assess sleep-disordered breathing. Diagnostics 2023, 13, 2146. [Google Scholar] [CrossRef] [PubMed]
- Thakur, A.; Gupta, M.; Sinha, D.K.; Mishra, K.K.; Venkatesan, V.K.; Guluwadi, S. Transformative breast Cancer diagnosis using CNNs with optimized ReduceLROnPlateau and Early stopping Enhancements. Int. J. Comput. Intell. Syst. 2024, 17, 14. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:161005492. [Google Scholar]
- Luping, W.; Wei, W.; Bo, L. CMFL: Mitigating communication overhead for federated learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 954–964. [Google Scholar]
- Zheng, S.; Shen, C.; Chen, X. Design and analysis of uplink and downlink communications for federated learning. IEEE J. Sel. Areas Commun. 2020, 39, 2150–2167. [Google Scholar] [CrossRef]
- Ehrhart, J.; Ehrhart, M.; Muzet, A.; Schieber, J.; Naitoh, P. K-complexes and sleep spindles before transient activation during sleep. Sleep 1981, 4, 400–407. [Google Scholar] [CrossRef] [PubMed]
- Shahrbabaki, S.S. Sleep Arousal and Cardiovascular Dynamics. Ph.D. Thesis, The University of Adelaide, Adelaide, Australia, 2020. [Google Scholar]
- Perslev, M.; Darkner, S.; Kempfner, L.; Nikolic, M.; Jennum, P.J.; Igel, C. U-Sleep: Resilient high-frequency sleep staging. NPJ Digit. Med. 2021, 4, 72. [Google Scholar] [CrossRef] [PubMed]
- Phan, H.; Andreotti, F.; Cooray, N.; Chén, O.Y.; De Vos, M. SeqSleepNet: End-to-end hierarchical recurrent neural network for sequence-to-sequence automatic sleep staging. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 400–410. [Google Scholar] [CrossRef] [PubMed]
- Phan, H.; Chén, O.Y.; Tran, M.C.; Koch, P.; Mertins, A.; De Vos, M. XSleepNet: Multi-view sequential model for automatic sleep staging. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5903–5915. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Fonseca, P.; van Dijk, J.; Overeem, S.; Long, X. Assessment of obstructive sleep apnea severity using audio-based snoring features. Biomed. Signal Process. Control 2023, 86, 104942. [Google Scholar] [CrossRef]
- Zarei, A.; Asl, B.M. Performance evaluation of the spectral autocorrelation function and autoregressive models for automated sleep apnea detection using single-lead ECG signal. Comput. Methods Programs Biomed. 2020, 195, 105626. [Google Scholar] [CrossRef] [PubMed]
- Olsen, M.; Mignot, E.; Jennum, P.J.; Sorensen, H.B.D. Robust, ECG-based detection of Sleep-disordered breathing in large population-based cohorts. Sleep 2020, 43, zsz276. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yuan, X.; Li, P. On convergence of fedprox: Local dissimilarity invariant bounds, non-smoothness and beyond. Adv. Neural Inf. Process. Syst. 2022, 35, 10752–10765. [Google Scholar]
- Jin, C.; Chen, X.; Gu, Y.; Li, Q. Feddyn: A dynamic and efficient federated distillation approach on recommender system. In Proceedings of the 2022 IEEE 28th International Conference on Parallel and Distributed Systems (ICPADS), Nanjing, China, 10–12 January 2023; pp. 786–793. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Subjects | Sampling Rate | Epochs (W/N1/N2/N3/R) | OSA Severity Segments (Normal/Mild/Moderate/Severe) |
|---|---|---|---|---|
| APPLES | 382 | 100 Hz | 110,443/15,670/388,581/191,345/67,642/ | 224/66/74/18 |
| SHHS | 329 | 125 Hz | 46,319/10,304/142,125/60,153/65,953 | 180/62/54/33 |
| 5463 | 125 Hz | 445,627/61,898/665,508/222,570/241,922 | 812/1146/2473/1824 | |
| HMC | 151 | 256 Hz | 23,315/15,441/49950/26,640/21,191 | 55/33/27/36 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Learning rate | 1 × 10−3 | Dropout rate | 0.3 |
| Optimizer | Adam | Weight decay | 1 × 10−4 |
| Batch size | 32 | Task loss weights (λ1, λ2) | 0.5, 0.5 |
| Local epochs (E) | 5 | Training time limit | Uniform [60, 180] seconds |
| Communication rounds (T) | 100 | Bandwidth | Uniform [50, 500] KB/s |
| Client participation (C) | 0.2 | Dropout probability | 0.1 |
| Dataset | Per-Class F1 Score | Overall Metrics | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| W (%) | N1 (%) | N2 (%) | N3 (%) | REM (%) | Recall (%) | Specificity (%) | Acc (%) | MF1 (%) | MGm (%) | κ | |
| APPLES | 88.3 | 53.7 | 93.5 | 70.6 | 77.3 | 74.7 | 96.1 | 85.3 | 76.7 | 83.7 | 0.71 |
| SHHS_rest | 88.1 | 57.8 | 89.5 | 85.6 | 86.4 | 82.5 | 96.4 | 87.1 | 81.5 | 89.0 | 0.86 |
| HMC | 81.9 | 61.4 | 82.4 | 80.3 | 79.1 | 76.7 | 94.6 | 79.3 | 77.0 | 85.0 | 0.72 |
| Per-Class Macro-AUC | Overall Metrics | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Normal | Mild | Moderate | Severe | Recall (%) | Specificity (%) | Acc (%) | MF1 (%) | MAUC (%) | |
| APPLES | 85.2 | 71.1 | 90.3 | 82.8 | 73.4 | 91.3 | 79.2 | 74.6 | 82.4 |
| SHHS | 86.7 | 82.2 | 90.6 | 94.9 | 82.7 | 94.5 | 84.5 | 83.8 | 88.6 |
| HMC | 92.1 | 82.9 | 89.5 | 95.4 | 84.8 | 95.0 | 85.4 | 85.0 | 89.9 |
| Client (Dataset) | Sleep Stages (%) | OSA Severity (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Specificity | Acc | MF1 | MGm | κ | Recall | Specificity | Acc | MF1 | MAUC | ||
| APPLES | Single | 66.8 | 80.2 | 78.2 | 69.1 | 79.9 | 0.68 | 67.5 | 82.1 | 70.0 | 69.2 | 78.5 |
| Mix | 71.0 | 85.3 | 83.5 | 72.2 | 81.6 | 0.69 | 69.4 | 88.0 | 74.2 | 70.8 | 79.9 | |
| FMTL | 74.7 | 96.1 | 85.3 | 76.7 | 83.7 | 0.71 | 73.4 | 91.3 | 79.2 | 74.6 | 82.4 | |
| SHHS | Single | 76.4 | 94.5 | 78.9 | 75.2 | 84.3 | 0.78 | 77.2 | 81.9 | 78.4 | 77.2 | 80.6 |
| Mix | 81.4 | 95.7 | 85.1 | 79.4 | 88.2 | 0.82 | 82.1 | 94.4 | 83.9 | 83.5 | 85.1 | |
| FMTL | 82.5 | 96.4 | 87.1 | 81.5 | 89.0 | 0.86 | 82.7 | 94.5 | 84.5 | 83.8 | 88.6 | |
| HMC | Single | 68.2 | 84.1 | 72.5 | 73.9 | 80.6 | 0.69 | 79.4 | 83.9 | 82.5 | 83.8 | 85.1 |
| Mix | 73.1 | 90.5 | 77.4 | 73.2 | 82.1 | 0.70 | 80.0 | 88.2 | 83.1 | 83.9 | 86.7 | |
| FMTL | 76.7 | 94.6 | 79.3 | 77.0 | 85.0 | 0.72 | 84.8 | 95.0 | 85.4 | 85.0 | 89.9 | |
| Authors/Network Name | Method | Input | Output | Dataset | Results |
|---|---|---|---|---|---|
| U-Sleep [46] | CNN model | Majority vote | Sleep stages | SHHS | MF1 score 80.0% |
| SeqSleepNet [47] | CNN model and BiLSTM | C4-A1, EOG, EMG | Sleep stages | SHHS | MF1 score 78.5%, κ 0.81 |
| SSC-SleepNet [17] | CNN and ResNet | EEG | Sleep stages | SHHS | MF1 score 84.0%, κ 0.86 |
| XSleepNet1 [48] | CNN and RNN model | C4-A1, EOG, EMG | Sleep stages | SHHS | MF1 score 80.7%, κ 0.83 |
| Xie et al. [49] | An extreme gradient boosting classifier | Demographic features and features from overnight snore patterns | AHI estimation | Full-night audio signals from 172 subjects, cross-validation | Spearman’s correlation = 0.786 |
| Zarei and As [50] | Random forest classifier | Features using autoregressive modeling and spectral autocorrelation from ECG | Segment (60 s) based classification | ECG from 70 subjects (Apnea-ECG database) cross- validation | Accuracy = 0.94, sensitivity = 0.92, specificity = 0.95 |
| Olsen et al. [51] | RNN model | IBI and EDR | Event based detection | 9869 recordings from different datasets, 1051 for testing | Sensitivity = 0.709, specificity = 0.734, F1 = 0.721 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Tang, R.; Wang, Y.; Wang, Z. Multimodal Fusion Multi-Task Learning Network Based on Federated Averaging for SDB Severity Diagnosis. Appl. Sci. 2025, 15, 8077. https://doi.org/10.3390/app15148077
Lin S, Tang R, Wang Y, Wang Z. Multimodal Fusion Multi-Task Learning Network Based on Federated Averaging for SDB Severity Diagnosis. Applied Sciences. 2025; 15(14):8077. https://doi.org/10.3390/app15148077
Chicago/Turabian StyleLin, Songlu, Renzheng Tang, Yuzhe Wang, and Zhihong Wang. 2025. "Multimodal Fusion Multi-Task Learning Network Based on Federated Averaging for SDB Severity Diagnosis" Applied Sciences 15, no. 14: 8077. https://doi.org/10.3390/app15148077
APA StyleLin, S., Tang, R., Wang, Y., & Wang, Z. (2025). Multimodal Fusion Multi-Task Learning Network Based on Federated Averaging for SDB Severity Diagnosis. Applied Sciences, 15(14), 8077. https://doi.org/10.3390/app15148077