
A Combined Approach of Heat Map Confusion and Local Differential Privacy for the Anonymization of Mobility Data


Abstract
1. Introduction
- It utilizes a combined approach using HMC and LDP to address vulnerabilities in mobility data anonymization, which has not been explored together before.
- It integrates LDP through LDPTrace to enhance HMC’s resistance against Aggregate Privacy (AP-Attacks), a novel improvement over using HMC alone.
- The approach emphasizes preserving both individual privacy and the utility of aggregate mobility data, achieving a balance not previously demonstrated in comparable methods.
2. Heat Map Confusion
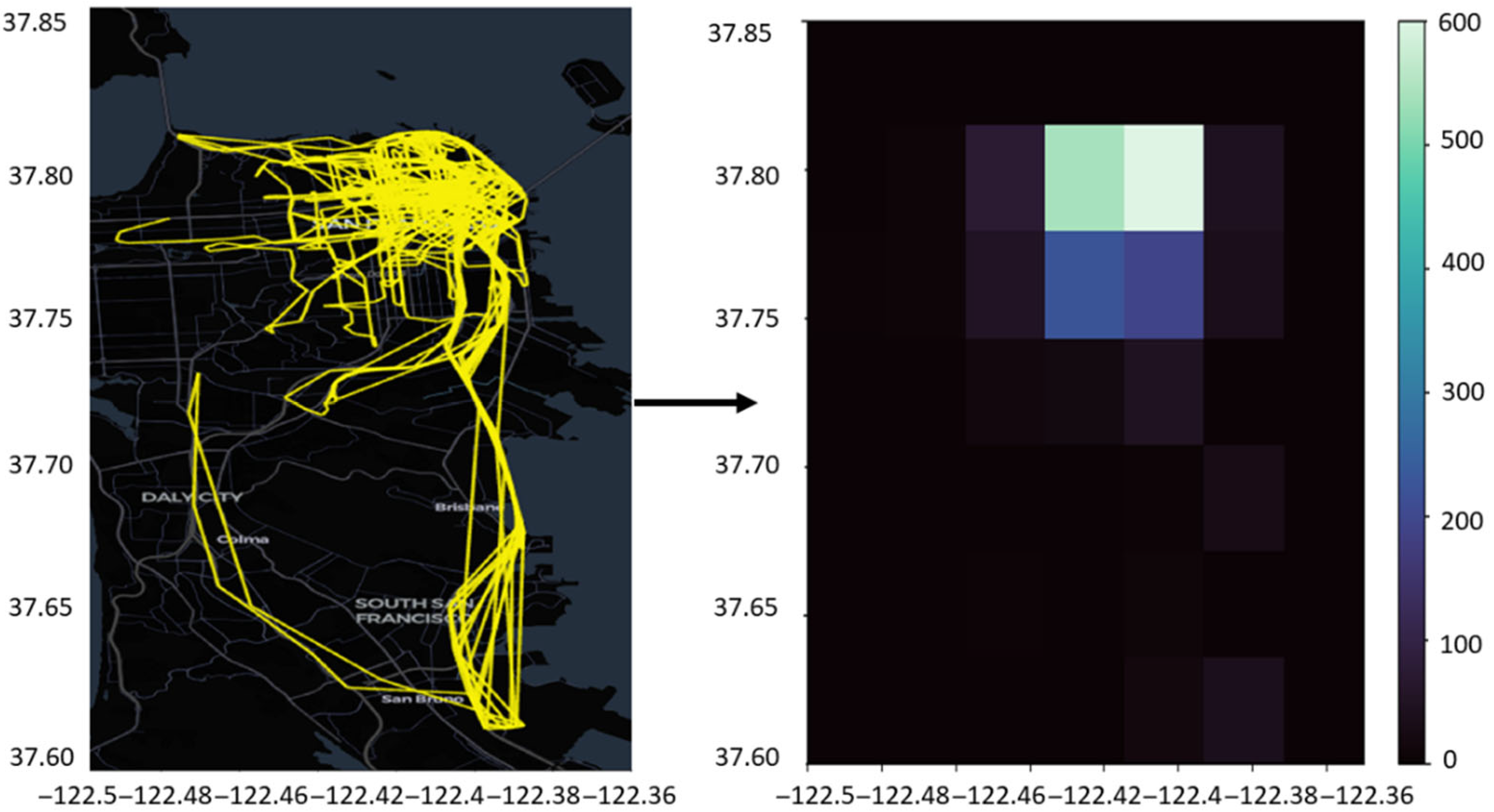
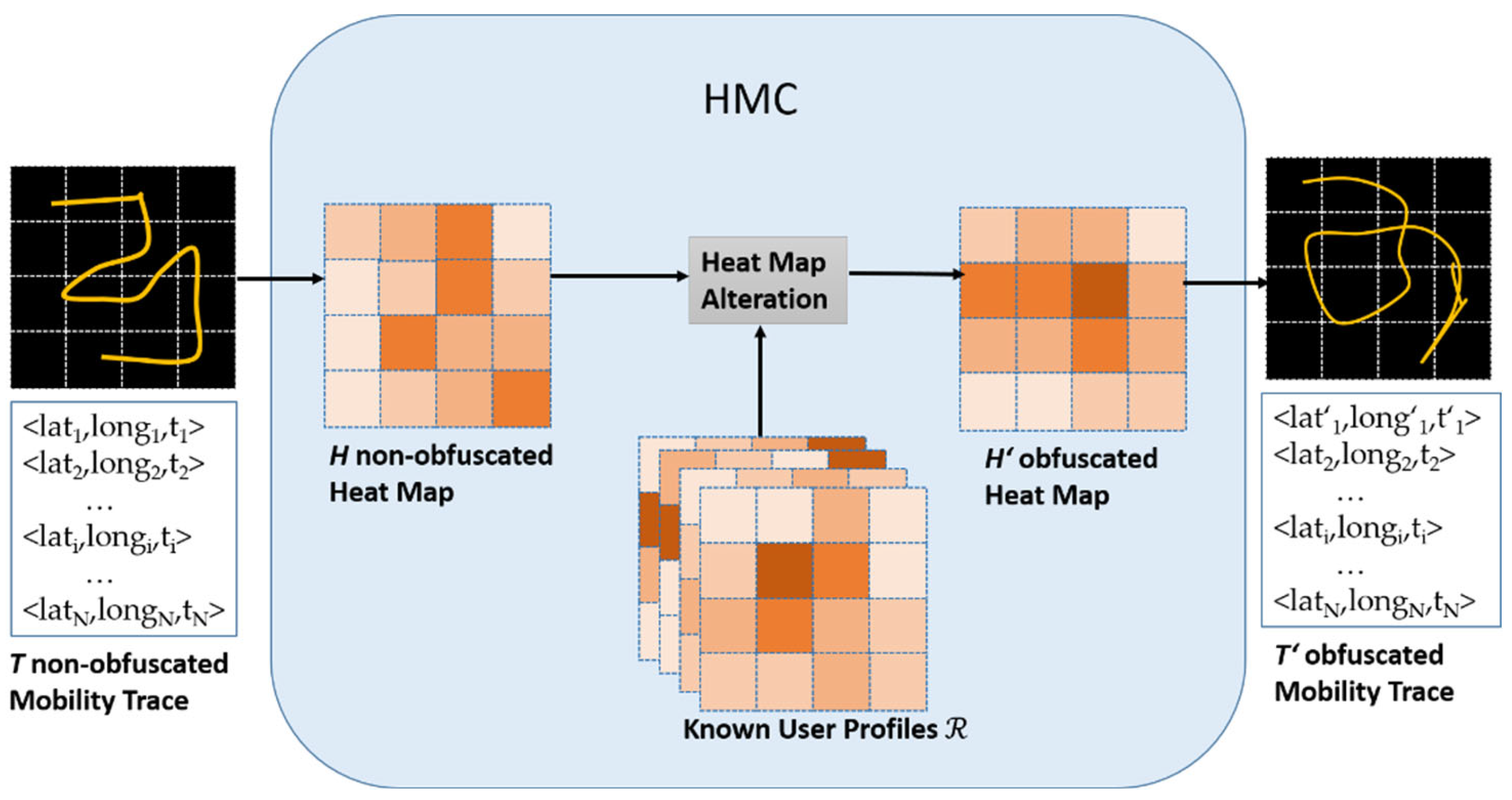
- Heat Map Creation: The first step in the HMC process is to turn a user’s mobility trace . A mobility trace of length is a sequence of latitude, longitude, and timestamp: into a heat map . The heat map creation step involves dividing a specific geographical area into a grid of squares, where each cell represents a location. The intensity of each cell shows how often a specific user has visited that spot (see Figure 1). This approach makes raw GPS data more general, creating a wider view of movement patterns and hiding precise location details.
- Heat Map Alteration: To anonymize the data, HMC changes each user’s heat map by comparing and merging it with the heat map of a similar user from a reference set . This step ensures that the final heat map does not show unique patterns of the original user. To calculate the similarity of two different heat maps, the Topsøe Divergence is used.
- 3.
- Mobility Trace Reconstruction: After the heat map is modified into the obfuscated heat map , the next step reconstructs an anonymized mobility trace that corresponds to . In [2], this process is described in detail.
3. Local Differential Privacy
- 1.
- Feature Extraction: LDPTrace extracts three main features from individual user trajectories and obfuscates them with a privacy budget :
- Intra-trajectory Transitions: The movement between consecutive cells in a grid of a trajectory, capturing local movement behavior.
- Start and End Points: Virtual markers indicate where trajectories begin and end, which helps in preserving trajectory structures.
- Trajectory Length: A probability distribution is determined by a central data curator using the obfuscated trajectory lengths of each trajectory.
- 2.
- Frequency Estimation: To estimate frequencies for trajectory synthesis, Optimized Unary Encoding (OUE) is used for each of the features extracted. OUE represents each feature as a binary vector of length equaling the maximal value of the feature, where at the index, which equals the feature value and zero otherwise. OUE adds noise to binary data to protect privacy before combining the data [3]. As depicted in Equation (6), the probability of a perturbed vector at index i being 1 is defined as
- 3.
- Adaptive Synthesis Process: The framework builds a probabilistic model using these extracted features, allowing it to generate synthetic trajectories that mimic real movement patterns [17]. The synthesis process is adaptive, meaning it selects transitions and trajectory lengths based on learned distributions without needing exact user data, thus enhancing privacy.
- Enhanced Privacy Protection: By employing local differential privacy, LDPTrace reduces the risk associated with data aggregation and central storage, ensuring that users’ real mobility data is not exposed [4].
- Improved Utility: The framework maintains high data utility, as synthetic trajectories generated by LDPTrace closely match real-world movement patterns [4]. This is particularly beneficial for analyses that depend on aggregated mobility trends rather than specific individual behaviors.
- Low Computational Cost: Unlike older methods that rely on intensive computations, such as linear programming or external data integration, LDPTrace simplifies the synthesis process, making it feasible for use on devices with limited resources [4].
- Resistance to Attacks: The method is designed to withstand common location-based attacks, such as reidentification and outlier analysis. By generating trajectories that do not closely mirror any specific user data, LDPTrace effectively minimizes vulnerabilities [4].
4. Combination of HMC and LDPTrace
- Synthetic Trajectory Generation with LDPTrace: First, LDPTrace creates synthetic mobility traces based on real mobility data from the San Francisco taxi dataset. These synthetic trajectories simulate movement patterns without directly revealing actual user locations. By introducing randomness in location data, LDPTrace makes it difficult to link specific movements to real individuals while maintaining patterns that resemble real-world data.
- Heat Map Confusion on Synthetic Data: Once the synthetic trajectories are generated, HMC further anonymizes the data. HMC creates heat maps from these synthetic traces and then alters them by merging similar patterns. This step reduces the likelihood of reidentification based on movement patterns, as individual traces are grouped into less specific patterns. By transforming synthetic data into altered heat maps, this combined approach provides additional protection for individual locations and routes.
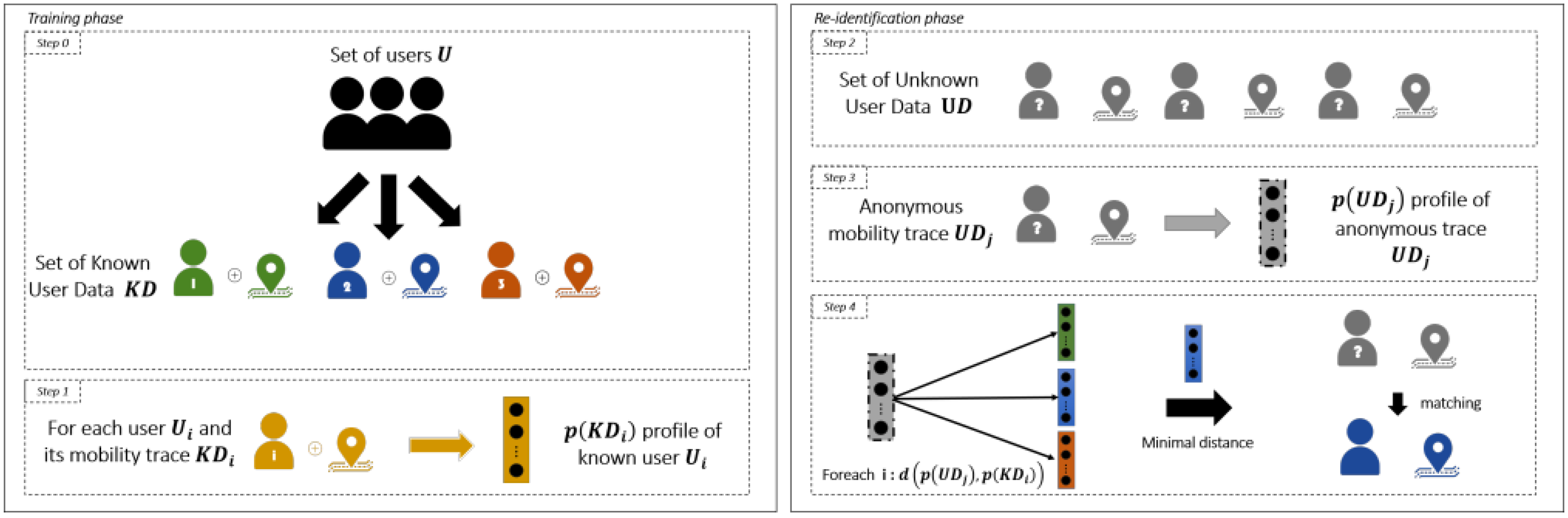
5. Aggregate Privacy Attack
6. Experimental Evaluation
6.1. Dataset
6.2. Evaluation with Aggregate Privacy Attack
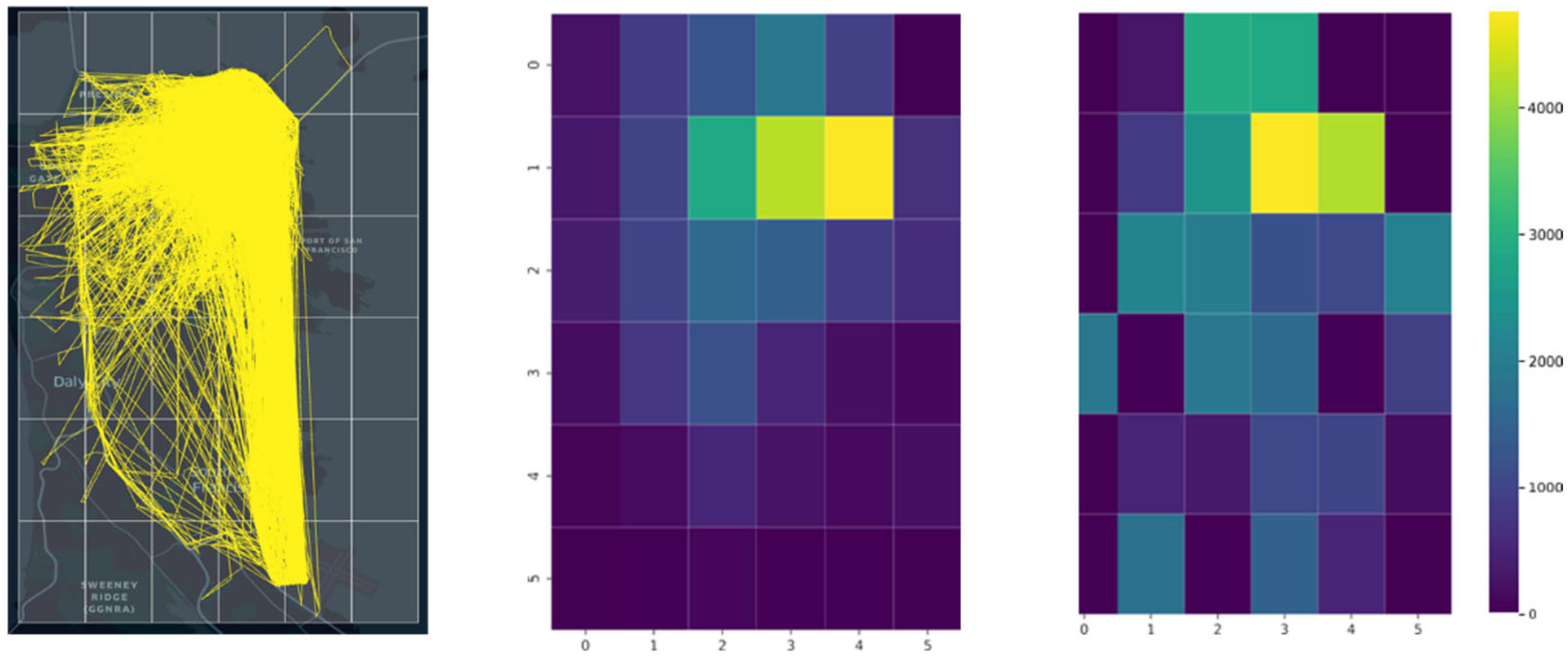
- AP-Attack on unaltered Heat Maps: The AP-Attack is first applied to the original heat maps, which have not been anonymized with HMC. This provides a baseline reidentification rate, showing how easily a taxi can be reidentified without any further anonymization.
- AP-Attack on obfuscated Heat Maps: The AP-Attack is applied to the heat maps after the HMC anonymization process. Comparing the reidentification rates from the original and altered maps shows whether the HMC process is effective. A lower reidentification rate indicates successful anonymization.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Mean | Standard Deviation |
|---|---|---|
| Reidentified Total | 103 | 32.784 |
| Non-Reidentified Total | 433 | |
| Reidentified (%) | 19.20 | 6.116 |
| Non-Reidentified (%) | 80.80 | |
| Average Distance (Topsøe Divergence) | 0.034 | 0.014 |
| Metrics | Mean | Standard Deviation |
|---|---|---|
| Reidentified Total | 9 | 3.035 |
| Non-Reidentified Total | 527 | |
| Reidentified (%) | 1.76 | 0.659 |
| Non-Reidentified (%) | 98.24 | |
| Average Distance (Topsøe Divergence) | 0.070 | 0.019 |
| Metrics | Mean | Standard Deviation | ||
|---|---|---|---|---|
| Reidentified Total | 1 | 1 | 0.5 | |
| 1.5 | 1.78 | 0.44 | ||
| 2 | 0.78 | 0.44 | ||
| Non-Reidentified Total | 1 | 535 | 0.5 | |
| 1.5 | 534.22 | 0.44 | ||
| 2 | 535.22 | 0.44 | ||
| Reidentified (%) | 1 | 0.19 | 0.09 | |
| 1.5 | 0.33 | 0.08 | ||
| 2 | 0.15 | 0.08 | ||
| Non-Reidentified (%) | 1 | 99.81 | 0.09 | |
| 1.5 | 99.67 | 0.08 | ||
| 2 | 99.85 | 0.08 | ||
| Average Distance (Topsøe Div.) | 1 | 0.162 | 0.016 | |
| 1.5 | 0.144 | 0.015 | ||
| 2 | 0.139 | 0.016 | ||
| Metrics | Mean | Standard Deviation | ||
|---|---|---|---|---|
| Reidentified Total | 1 | 1.67 | 0.71 | |
| 1.5 | 2.56 | 0.73 | ||
| 2 | 1.33 | 0.5 | ||
| Non-Reidentified Total | 1 | 534.33 | 0.71 | |
| 1.5 | 533.33 | 0.73 | ||
| 2 | 534.67 | 0.5 | ||
| Reidentified (%) | 1 | 0.31 | 0.13 | |
| 1.5 | 0.48 | 0.14 | ||
| 2 | 0.24 | 0.1 | ||
| Non-Reidentified (%) | 1 | 99.69 | 0.13 | |
| 1.5 | 99.52 | 0.14 | ||
| 2 | 99.75 | 0.1 | ||
| Average Distance (Topsøe Div.) | 1 | 0.161 | 0.016 | |
| 1.5 | 0.142 | 0.016 | ||
| 2 | 0.138 | 0.017 | ||
- (Non-)Reidentified Total: This refers to the total number of (un-)successful reidentifications.
- (Non-)Reidentified (%): This refers to the percentage of (un-)successful reidentifications.
- Seed: NumPy seed set with np.random. This influences how the datasets are partitioned into train and test datasets.
- Average Distance: The average minimum distance determined by calculating Topsøe Divergence—see Equation (1)—over all 536 datasets.
7. Conclusions
- HMC alone is effective at lowering Reidentified (%) rates, with average distances from 0.05 to 0.10, as shown in Table A2. This indicates that HMC can offer privacy protection while keeping data reasonably useful.
- HMC combined with LDPTrace provides stronger privacy, as shown by the lower Reidentified (%) rates between 0% and 0.37% in Table A3 and larger average distances up to 0.20. This demonstrates that the additional application of HMC further strengthens anonymization.
- While LDPTrace alone increases Topsøe Divergence nearly tenfold, reflecting its strong anonymization effect, adding HMC does not significantly increase this distance further. Instead, it provides a substantial additional drop in reidentification rates, implying that HMC complements LDPTrace effectively by improving anonymization without further distorting the data.
- Application-specific studies: Analyzing how different data modification levels impact specific applications or use cases, i.e., environmental pollution or traffic simulations.
- Including other utility metrics: Creating or utilizing other metrics beyond average distance, such as checking for time-based consistency and the accuracy of Points of Interest (POIs), can offer a clearer view of data usability.
- Experiments with other attacks: To strengthen the robustness of privacy protection methods and ensure comprehensive evaluation, future work should focus on testing additional attack scenarios and analyzing their impact on reidentification rates and data utility. This could include exploring attacks such as outlier detection, POI (Point of Interest)-based attacks, and PIT (Point-in-Time)-based attacks; see [2].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Metrics | Trial 1 | Trial 2 | Trial 3 | Trial 4 | Trial 5 | Trial 6 | Trial 7 | Trial 8 | Trial 9 |
|---|---|---|---|---|---|---|---|---|---|
| # Taxi ID | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 |
| Reidentified Total | 152 | 82 | 141 | 45 | 140 | 83 | 90 | 96 | 97 |
| Non-Reidentified Total | 384 | 454 | 395 | 491 | 396 | 453 | 446 | 440 | 439 |
| Reidentified (%) | 28.36 | 15.30 | 26.31 | 8.40 | 26.12 | 15.49 | 16.79 | 17.91 | 18.10 |
| Non-Reidentified (%) | 71.64 | 84.70 | 73.69 | 91.60 | 73.88 | 84.51 | 83.21 | 82.09 | 81.90 |
| Seed | 845 | 286 | 742 | 301 | 87 | 123 | 581 | 445 | 4 |
| ⌀ Topsøe Divergence | 0.02 | 0.03 | 0.03 | 0.07 | 0.03 | 0.03 | 0.04 | 0.03 | 0.03 |
| Metrics | Trial 1 | Trial 2 | Trial 3 | Trial 4 | Trial 5 | Trial 6 | Trial 7 | Trial 8 | Trial 9 |
|---|---|---|---|---|---|---|---|---|---|
| # Taxi ID | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 |
| Reidentified Total | 11 | 12 | 10 | 3 | 9 | 11 | 7 | 12 | 5 |
| Non-Reidentified Total | 525 | 524 | 526 | 533 | 527 | 525 | 529 | 524 | 531 |
| Reidentified (%) | 2.50 | 2.24 | 1.87 | 0.56 | 1.68 | 2.50 | 1.31 | 2.24 | 0.93 |
| Non-Reidentified (%) | 97.50 | 97.76 | 98.13 | 99.44 | 98.32 | 97.50 | 98.69 | 97.76 | 99.07 |
| Seed | 845 | 286 | 742 | 301 | 87 | 123 | 581 | 445 | 4 |
| ⌀ Topsøe Divergence | 0.08 | 0.05 | 0.10 | 0.09 | 0.08 | 0.06 | 0.07 | 0.05 | 0.05 |
| Metrics | Trial 1 | Trial 2 | Trial 3 | Trial 4 | Trial 5 | Trial 6 | Trial 7 | Trial 8 | Trial 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| # Taxi ID | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 | ||
| Reidentified Total | 1 | 1 | 1 | 1 | 2 | 1 | 0 | 1 | 1 | 1 | |
| 1.5 | 2 | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | ||
| 2 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| Non-Reidentified Total | 1 | 535 | 535 | 535 | 534 | 535 | 536 | 535 | 535 | 535 | |
| 1.5 | 534 | 534 | 535 | 535 | 534 | 534 | 534 | 534 | 534 | ||
| 2 | 535 | 536 | 536 | 535 | 535 | 535 | 535 | 535 | 535 | ||
| Reidentified (%) | 1 | 0.19 | 0.19 | 0.19 | 0.37 | 0.19 | 0 | 0.19 | 0.19 | 0.19 | |
| 1.5 | 0.37 | 0.37 | 0.19 | 0.19 | 0.37 | 0.37 | 0.37 | 0.37 | 0.37 | ||
| 2 | 0.19 | 0 | 0 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | ||
| Non-Reidentified (%) | 1 | 99.81 | 99.81 | 99.81 | 99.63 | 99.81 | 100 | 99.81 | 99.81 | 99.81 | |
| 1.5 | 99.63 | 99.63 | 99.81 | 99.81 | 99.63 | 99.63 | 99.63 | 99.63 | 99.63 | ||
| 2 | 99.81 | 100 | 100 | 99.81 | 99.81 | 99.81 | 99.81 | 99.81 | 99.81 | ||
| Seed | 845 | 286 | 742 | 301 | 87 | 123 | 581 | 445 | 4 | ||
| ⌀ Topsoe Divergence | 1 | 0.15 | 0.15 | 0.16 | 0.2 | 0.16 | 0.15 | 0.17 | 0.16 | 0.16 | |
| 1.5 | 0.13 | 0.14 | 0.15 | 0.18 | 0.14 | 0.13 | 0.15 | 0.14 | 0.14 | ||
| 2 | 0.13 | 0.13 | 0.14 | 0.18 | 0.13 | 0.13 | 0.14 | 0.13 | 0.14 | ||
| Metrics | Trial 1 | Trial 2 | Trial 3 | Trial 4 | Trial 5 | Trial 6 | Trial 7 | Trial 8 | Trial 9 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| # Taxi ID | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 | 536 | ||
| Reidentified Total | 1 | 2 | 2 | 1 | 2 | 1 | 2 | 1 | 3 | 1 | |
| 1.5 | 2 | 3 | 2 | 2 | 2 | 3 | 3 | 4 | 2 | ||
| 2 | 1 | 1 | 2 | 1 | 2 | 2 | 1 | 1 | 1 | ||
| Non-Reidentified Total | 1 | 534 | 534 | 535 | 534 | 535 | 534 | 535 | 533 | 535 | |
| 1.5 | 534 | 533 | 534 | 534 | 534 | 533 | 533 | 532 | 534 | ||
| 2 | 535 | 535 | 534 | 535 | 534 | 534 | 535 | 535 | 535 | ||
| Reidentified (%) | 1 | 0.37 | 0.37 | 0.19 | 0.37 | 0.19 | 0.37 | 0.19 | 0.56 | 0.19 | |
| 1.5 | 0.37 | 0.56 | 0.37 | 0.37 | 0.37 | 0.56 | 0.56 | 0.75 | 0.37 | ||
| 2 | 0.19 | 0.19 | 0.37 | 0.19 | 0.37 | 0.37 | 0.19 | 0.19 | 0.1 | ||
| Non-Reidentified (%) | 1 | 99.63 | 99.63 | 99.81 | 99.63 | 99.81 | 99.63 | 99.81 | 99.44 | 99.81 | |
| 1.5 | 99.63 | 99.44 | 99.63 | 99.63 | 99.63 | 99.44 | 99.44 | 99.25 | 99.63 | ||
| 2 | 99.81 | 99.81 | 99.63 | 99.81 | 99.63 | 99.63 | 99.81 | 99.81 | 99.81 | ||
| Seed | 845 | 286 | 742 | 301 | 87 | 123 | 581 | 445 | 4 | ||
| ⌀ Topsoe Divergence | 1 | 0.15 | 0.15 | 0.16 | 0.2 | 0.16 | 0.15 | 0.17 | 0.15 | 0.16 | |
| 1.5 | 0.13 | 0.13 | 0.14 | 0.18 | 0.14 | 0.13 | 0.15 | 0.14 | 0.14 | ||
| 2 | 0.12 | 0.13 | 0.14 | 0.18 | 0.13 | 0.13 | 0.14 | 0.13 | 0.14 | ||
References
- Khalfoun, B.; Maouche, M.; Ben Mokhtar, S.; Bouchenak, S. MooD: MObility Data Privacy as Orphan Disease—Experimentation and Deployment Paper. In Proceedings of the 20th International Middleware Conference, Davis, CA, USA, 9–13 December 2019. [Google Scholar]
- Maouche, M.; Ben Mokhtar, S.; Bouchenak, S. HMC: Robust Privacy Protection of Mobility Data against Multiple Re-Identification Attacks. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–25. [Google Scholar] [CrossRef]
- Gatzert, N.; Knorre, S.; Müller-Peters, H.; Wagner, F.; Jost, T. Big Data in der Mobilität: Akteure, Geschäftsmodelle und Nutzenpotenziale für die Welt von Morgen; Springer Gabler: Wiesbaden, Germany, 2023. [Google Scholar]
- Du, Y.; Hu, Y.; Zhang, Z.; Fang, Z.; Chen, L.; Zheng, B.; Gao, Y. LDPTrace: Locally Differentially Private Trajectory Synthesis. Proc. VLDB Endow. 2023, 16, 1897–1909. [Google Scholar] [CrossRef]
- Xu, F.; Tu, Z.; Li, Y.; Zhang, P.; Fu, X.; Jin, D. Trajectory Recovery from Ash: User Privacy is NOT Preserved in Aggregated Mobility Data. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Maouche, M.; Ben Mokhtar, S.; Bouchenak, S. AP-Attack: A Novel User Re-identification Attack on Mobility Datasets. In Proceedings of the 14th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MobiQuitous 2017), Melbourne, Australia, 7–10 November 2017. [Google Scholar]
- Buchholz, E.; Abuadbba, A.; Wang, S.; Nepal, S.; Kanhere, S.S. SoK: Can Trajectory Generation Combine Privacy and Utility? Proc. Priv. Enhancing Technol. Symp. 2024, 3, 75–93. [Google Scholar] [CrossRef]
- Primault, V.; Ben Mokhtar, S.; Lauradoux, C.; Brunie, L. Differentially Private Location Privacy in Practice. arXiv 2014. [Google Scholar] [CrossRef]
- Walter, P.; Efremidis, A.; Gühring, G. Anonymization of Mobility Data and its Meta Information using Local Differential Privacy in Combination with Bidirectional Graphs. 2025; preprint. [Google Scholar]
- Netek, R.; Pour, T.; Slezakova, R. Implementation of Heat Maps in Geographical Information System—Exploratory Study on Traffic Accident Data. Open Geosci. 2018, 10, 367–384. [Google Scholar] [CrossRef]
- Jiang, D.; Wang, H.; Li, T.; Gouda, M.A.; Zhou, B. Real-time tracker of chicken for poultry based on attention mechanism-enhanced YOLO-Chicken algorithm. Comput. Electron. Agric. 2025, 237, 110640. [Google Scholar] [CrossRef]
- Kapp, A.; Nuñez von Voigt, S.; Mihaljević, H.; Tschorsch, F. Towards mobility reports with user-level privacy. J. Locat. Based Serv. 2023, 17, 95–121. [Google Scholar] [CrossRef]
- European Union. General Data Protection Regulation (GDPR), 2018, [Online]. Available online: https://gdpr-info.eu/ (accessed on 9 June 2025).
- Cunningham, T.; Cormode, G.; Ferhatosmanoglu, H.; Srivastava, D. Real-world trajectory sharing with local differential privacy. Proc. VLDB Endow. 2021, 14, 2283–2295. [Google Scholar] [CrossRef]
- Topsøe, F. Some inequalities for information divergence and related measures of discrimination. IEEE Trans. Inf. Theory 2000, 46, 1602–1609. [Google Scholar] [CrossRef]
- Dwork, C.; Kohli, N.; Mulligan, D. Differential Privacy in Practice Expose your Epsilons! J. Priv. Confidentiality 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Abul, O.; Bonchi, F.; Nanni, M. Anonymization of Moving Objects Databases by Clustering and Perturbation. Inf. Syst. 2010, 35, 884–910. [Google Scholar] [CrossRef]
- Piorkowski, M.; Sarafijanovic-Djukic, N.; Grossglauser, M. CRAWDAD Epfl/Mobility; IEEE Dataport: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Ghazi, B.; He, J.; Kohlhoff, K.; Kumar, R.; Manurangsi, P.; Navalpakkam, V.; Valliappan, N. Differentially Private Heatmaps. Proc. AAAI Conf. Artif. Intell. 2023, 37, 7696–7704. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dürr, C.; Gühring, G.S. A Combined Approach of Heat Map Confusion and Local Differential Privacy for the Anonymization of Mobility Data. Appl. Sci. 2025, 15, 8065. https://doi.org/10.3390/app15148065
Dürr C, Gühring GS. A Combined Approach of Heat Map Confusion and Local Differential Privacy for the Anonymization of Mobility Data. Applied Sciences. 2025; 15(14):8065. https://doi.org/10.3390/app15148065
Chicago/Turabian StyleDürr, Christian, and Gabriele S. Gühring. 2025. "A Combined Approach of Heat Map Confusion and Local Differential Privacy for the Anonymization of Mobility Data" Applied Sciences 15, no. 14: 8065. https://doi.org/10.3390/app15148065
APA StyleDürr, C., & Gühring, G. S. (2025). A Combined Approach of Heat Map Confusion and Local Differential Privacy for the Anonymization of Mobility Data. Applied Sciences, 15(14), 8065. https://doi.org/10.3390/app15148065