
Reinforcement Learning Methods for Emulating Personality in a Game Environment †


Abstract
1. Introduction
- A scalable framework that supports both single-agent personality modeling and a multi-agent system for analyzing their performance in a gamified escape room environment.
- A new reward mechanism that enables deep reinforcement learning agents to emulate distinct human personality traits, grounded in the OCEAN model, through their behavior and decision-making.
- An analysis of how different combinations of personality traits impact team efficiency, coordination, and problem-solving effectiveness for assessment/debugging or NPC creation.
2. Literature Review
2.1. Background
2.1.1. Reinforcement Learning
2.1.2. Personality Traits
- Openness: Shows imagination, interest, and a readiness to try new things. People with high levels of openness make excellent team players who welcome creative approaches to problem-solving.
- Conscientiousness: Shows organization, focus, and dedication, all of which are necessary for reaching long-term objectives. Conscientious people are excellent at organized work and teamwork.
- Extraversion: Characterizes assertiveness and sociability. Group dynamics are frequently led by extroverts, but introverts may be reluctant to express their opinions, which can affect team performance.
- Agreeableness: Stands for empathy and collaboration. Through mutual respect and understanding, highly agreeable people promote smooth teamwork.
- Neuroticism: Consists of emotional instability and stress vulnerability. High levels of neuroticism can make it more difficult to adjust and work well with others.
2.2. Related Work
3. Materials and Methods
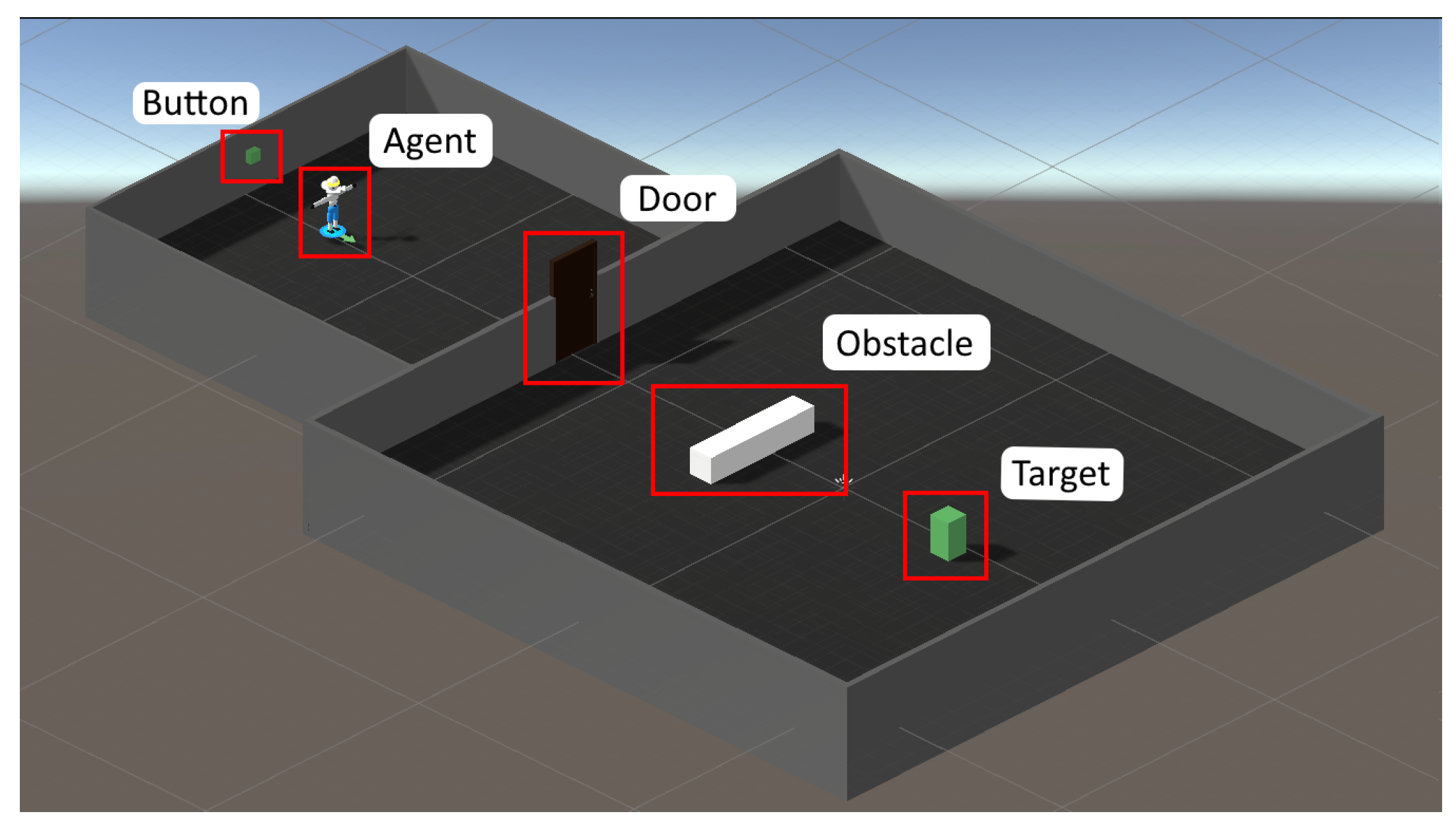
3.1. Game Mechanics and Environments
3.1.1. Action Space
3.1.2. State Space
- One-hot encoded categorical data, where each category is represented by a binary vector (e.g., detecting a “Door” from [Target, Door, Wall, Obstacle] results in [0, 1, 0, 0]);
- Normalized numerical values, scaled to ranges like [0, 1] or [−1, 1] to ensure consistent contribution to learning;
- Stacked temporal data, which aggregates past observations to simulate short-term memory, aiding in the detection of dynamics like motion and acceleration.
3.1.3. Rewards
- S is the set of states;
- A is the set of actions;
- is the transition function;
- is the discount factor;
- is the reward function for agent i;
- Trait-Dependent Reward Definitions:
- Openness
- Extraversion
- Agreeableness
- Final Reward
3.1.4. Training Methodology
- We choose the specific trait we want the agent to emulate (e.g., extroversion);
- We set the Gaussian of each trait to define the selected one ( = 0, = 0, = 1, = 0, = 0)
- During training at the end of each episode:
- We collect behavior action metrics (push behavior = number of push actions)
- We reward the agent by multiplying behavior metric with the corresponding Gaussian (R = Pushing behavior * ( + ))
4. Results
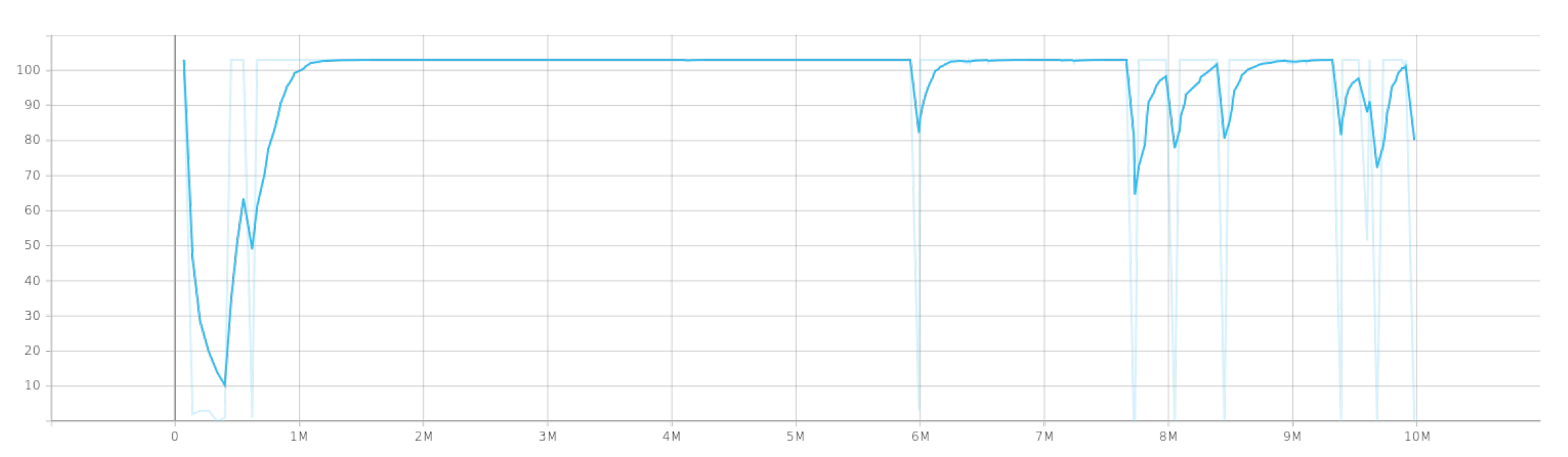
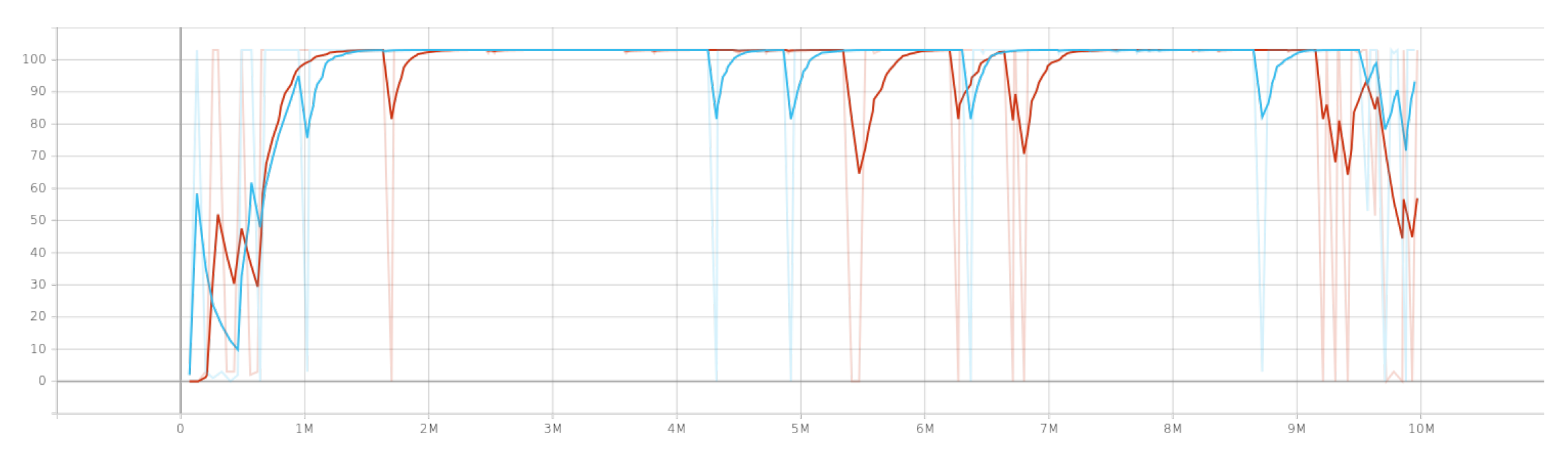
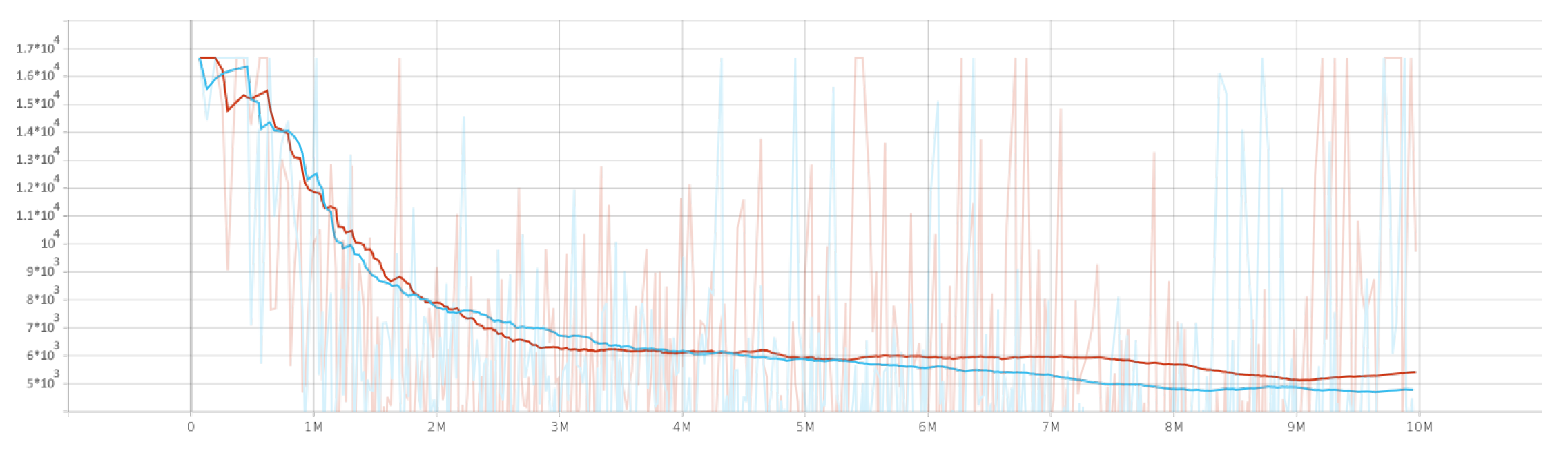
4.1. Singe Agent Results
- Lesson 1: Passed if the agent succeeds in over 90% of the last 100,000 steps.
- Lesson 2: Same as Lesson 1—over 90% success.
- Lesson 3: Passed if success rate is over 50% in the last 100,000 steps.
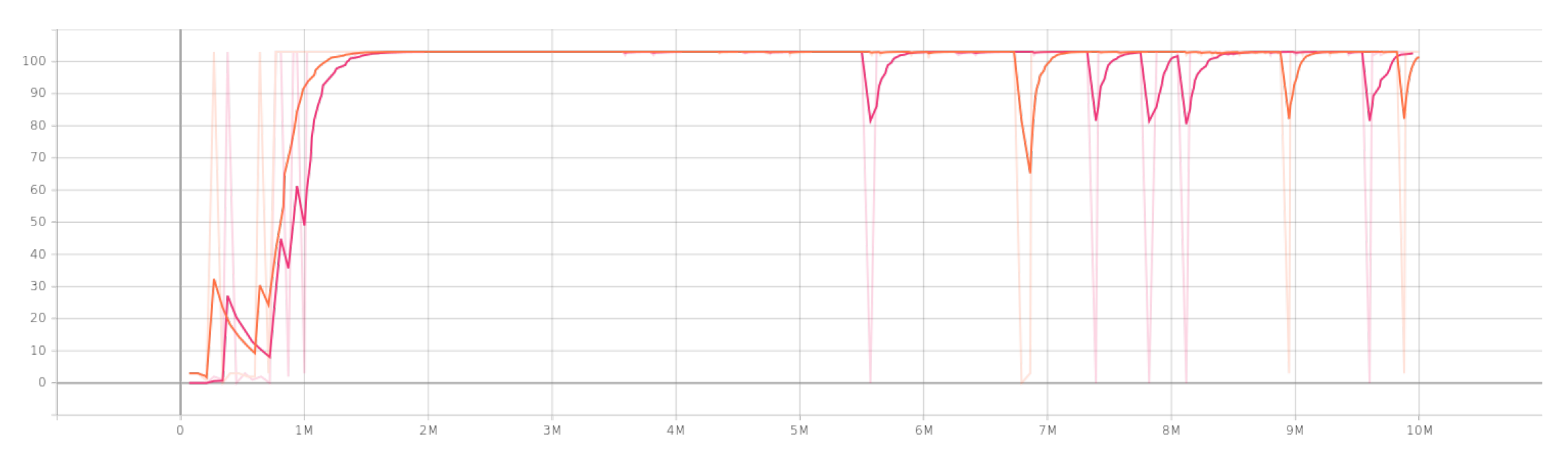
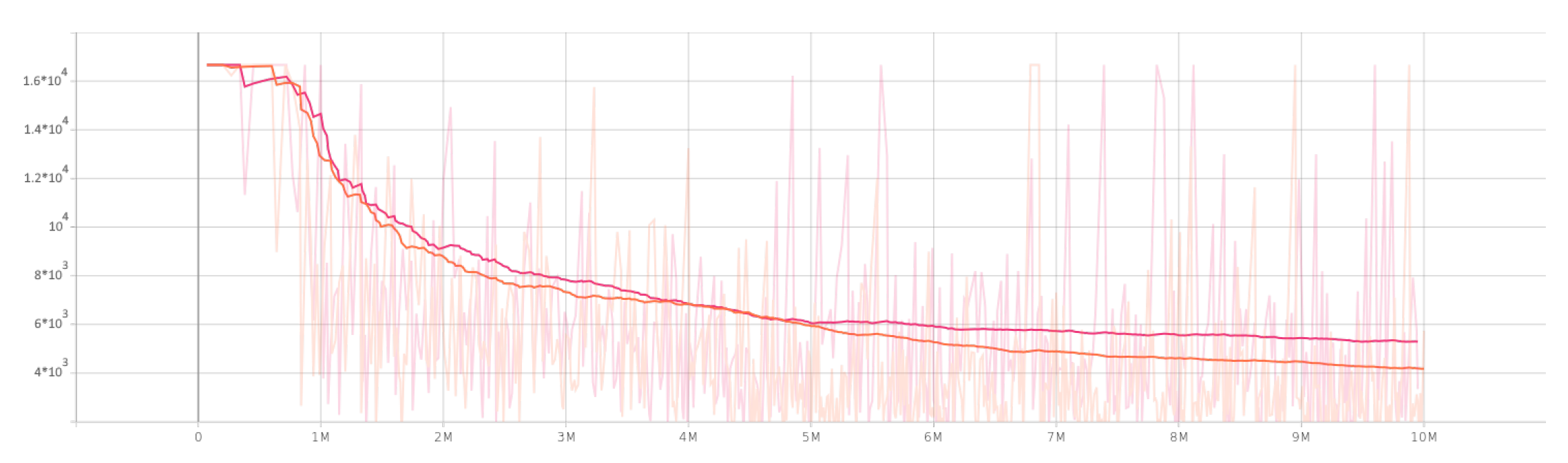
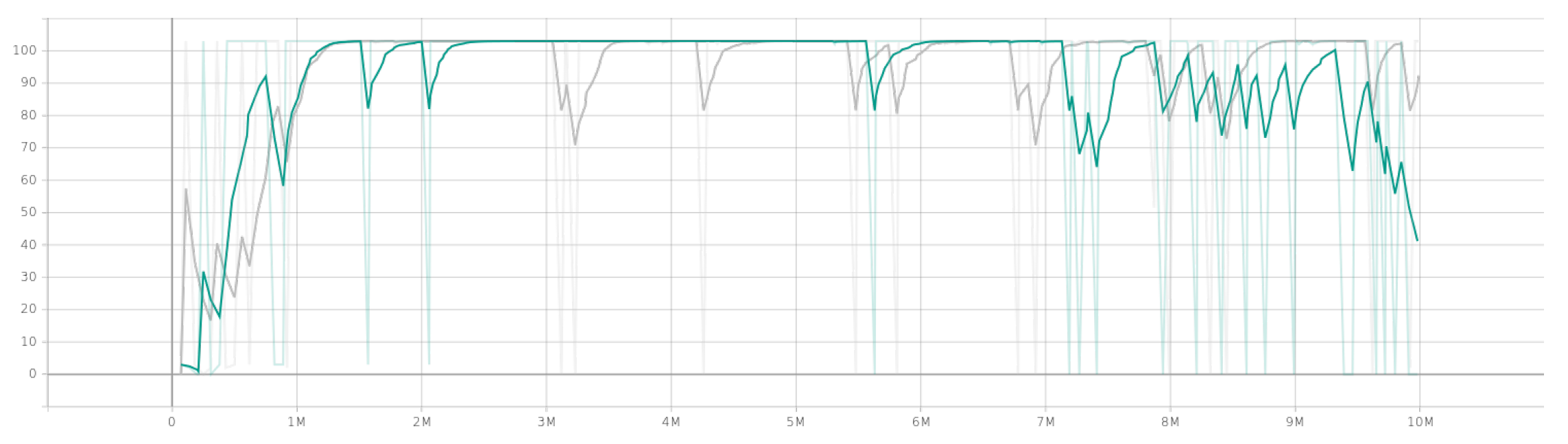
4.2. Multi-Agent Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ER | Escape Room |
| RL | Reinforcement Learning |
| MDP | Markovian Decision Process |
| MA-POCA | Multi-agent POsthumous Credit Assignment |
| OCEAN | Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism |
| MA-A2C | Multi-agent Advantage Actor–Critic |
References
- Dicheva, D.; Dichev, C.; Agre, G.; Angelova, G. Gamification in Education: A Systematic Mapping Study. Educ. Technol. Soc. 2015, 18, 75–88. [Google Scholar]
- Bakar, M.H.A.; McMahon, M. Collaborative problem solving and communication in virtual escape rooms: An experimental study. J. Interact. Learn. Res. 2021, 32, 135–152. [Google Scholar]
- Yannakakis, G.N.; Togelius, J. Artificial Intelligence and Games; Springer: New York, NY, USA, 2025. [Google Scholar]
- Kapadia, M.; Shoulson, A.; Durupinar, F.; Badler, N.I. Authoring Multi-actor Behaviors in Crowds with Diverse Personalities. In Modeling, Simulation and Visual Analysis of Crowds; Ali, S., Nishino, K., Manocha, D., Shah, M., Eds.; The International Series in Video Computing, Vol. 11; Springer: New York, NY, USA, 2013; pp. 113–132. [Google Scholar] [CrossRef]
- Ghasemi, M.; Ebrahimi, D. Introduction to Reinforcement Learning. arXiv 2024, arXiv:2408.07712. [Google Scholar] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson: Boston, MA, USA, 2020. [Google Scholar]
- Juliani, A.; Berges, V.-P.; Teng, E.; Cohen, A.; Harper, J.; Elion, C.; Goy, C.; Gao, Y.; Henry, H.; Mattar, M.; et al. Unity: A General Platform for Intelligent Agents. arXiv 2020, arXiv:1809.02627. [Google Scholar]
- Cohen, A.; Teng, E.; Berges, V.-P.; Dong, R.-P.; Henry, H.; Mattar, M.; Zook, A.; Ganguly, S. On the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning. In Proceedings of the Reinforcement Learning in Games Workshop at AAAI 2022, Vancouver, BC, Canada, 28 February–1 March 2022. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.V.; Lanctot, M.; de Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Jang, K.L.; Livesley, W.J.; Vernon, P.A. Heritability of the big five personality dimensions and their facets: A twin study. J. Personal. 1996, 64, 577–591. [Google Scholar] [CrossRef] [PubMed]
- Lo, M.T.; Hinds, D.A.; Tung, J.Y.; Franz, C.; Fan, C.C.; Wang, Y.; Chen, C.H. Genome-wide analyses for personality traits identify novel loci and pathways. Nat. Commun. 2021, 12, 1–11. [Google Scholar]
- Uzieblo, K.; Verschuere, B.; Van den Bussche, E.; Crombez, G. The validity of the Psychopathic Personality Inventory-Revised in a community sample. Assessment 2010, 17, 334–346. [Google Scholar] [CrossRef] [PubMed]
- Jiang, N.; Shi, M.; Xiao, Y.; Shi, K.; Watson, B. Factors Affecting Pedestrian Crossing Behaviors at Signalized Crosswalks in Urban Areas in Beijing and Singapore. In Proceedings of the ICTIS 2011, Wuhan, China, 30 June–2 July 2011; p. 1097. [Google Scholar] [CrossRef]
- Hirschfeld, R.R.; Jordan, M.H.; Thomas, C.H.; Feild, H.S. Observed leadership potential of personnel in a team setting: Big five traits and proximal factors as predictors. Int. J. Sel. Assess. 2008, 16, 385–402. [Google Scholar] [CrossRef]
- Durupinar, F.; Allbeck, J.M.; Badler, N.I.; Guy, S.J. Navigating performance: Surfing on the OCEAN (Big Five) personality traits. J. Econ. Bus. Account. 2024, 7, 767–783. [Google Scholar]
- Durupinar, F.; Pelechano, N.; Allbeck, J.; Gudukbay, U.; Badler, N. How the Ocean Personality Model Affects the Perception of Crowds. IEEE Comput. Graph. Appl. 2011, 31, 22–31. [Google Scholar] [CrossRef] [PubMed]
- Du, H.; Huhns, M.N. Determining the Effect of Personality Types on Human-Agent Interactions. In Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Atlanta, GA, USA; 2013; Volume 2, pp. 239–244. [Google Scholar] [CrossRef]
- Liu, S.; Rizzo, P. Personality-aware virtual agents: Advances and challenges. IEEE Trans. Affect. Comput. 2021, 12, 1012–1027. [Google Scholar]
- DeYoung, C.G.; Krueger, R.F. Understanding personality through biological and genetic bases. Annu. Rev. Psychol. 2021, 72, 555–580. [Google Scholar]
- Ashton, M.C.; Lee, K.; De Vries, R.E. The HEXACO Model of Personality Structure and the Importance of Agreeableness. Eur. J. Personal. 2020, 34, 3–19. [Google Scholar]
- Kumar, S.; Singh, V. Behavior modeling for personalized virtual coaching using contemporary personality theories. Int. J. Hum.-Comput. Stud. 2021, 146, 102557. [Google Scholar]
- Oulhaci, M.; Tranvouez, E.; Fournier, S.; Espinasse, B. A MultiAgent Architecture for Collaborative Serious Game applied to Crisis Management Training: Improving Adaptability of Non Played Characters. In Proceedings of the 7th European Conference on Games Based Learning (ECGBL 2013), Porto, Portugal, 3–4 October 2013. [Google Scholar]
- Hafner, D.; Pavsukonis, J.; Ba, J.; Lillicrap, T.P. Mastering Diverse Domains through World Models. arXiv 2023, arXiv:2301.04104. [Google Scholar]
- Alonso, E.; Peter, M.; Goumard, D.; Romoff, J. Deep Reinforcement Learning for Navigation in AAA Video Games. In Proceedings of the International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Sestini, A.; Kuhnle, A.; Bagdanov, A.D. DeepCrawl: Deep Reinforcement Learning for Turn-based Strategy Games. arXiv 2019, arXiv:2012.01914. [Google Scholar]
- Liapis, G.; Lazaridis, A.; Vlahavas, I. Escape Room Experience for Team Building Through Gamification Using Deep Reinforcement Learning. In Proceedings of the 15th European Conference of Games Based Learning, Online, 23–24 December 2021. [Google Scholar]
- Liapis, G.; Zacharia, K.; Rrasa, K.; Liapi, A.; Vlahavas, I. Modelling Core Personality Traits Behaviours in a Gamified Escape Room Environment. Eur. Conf. Games Based Learn. 2022, 16, 723–731. [Google Scholar] [CrossRef]
- Liapis, G.; Vordou, A.; Vlahavas, I. Machine Learning Methods for Emulating Personality Traits in a Gamified Environment. In Proceedings of the 13th Conference on Artificial Intelligence (SETN 2024), Piraeus, Greece, 11–13 September 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Unity Technologies. Unity Real-Time Development Platform | 3D, 2D VR & AR Engine. Unity, version 6000.1.11f1; Game Development Platform. 2025. Available online: https://unity.com/ (accessed on 18 December 2024).
- RealMINT ai. 2024. RealEscape. Available online: https://store.steampowered.com/app/3301090/RealEscape/ (accessed on 10 December 2024).
- Delalleau, O.; Peter, M.; Alonso, E.; Logut, A. Discrete and Continuous Action Representation for Practical RL in Video Games. arXiv 2019, arXiv:1912.11077. [Google Scholar]
- Justesen, N.; Bontrager, P.; Togelius, J.; Risi, S. Deep learning for video game playing. IEEE Trans. Games 2019, 12, 1–20. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Behavior | Reward |
|---|---|
| Pressed button | 0.4 × time |
| Pick Up Key | 0.4 × time |
| Unlock door | 0.4 × time |
| Escaped | 1 × time |
| Escaped all | 10 × time |
| Collided (other agent or obstacle) | −0.01 × time |
| Hyperparameters | Single-Agent Values | Multi-Agent Values |
|---|---|---|
| batch size | 128 | 2048 |
| buffer size | 128,000 | 256,000 |
| learning rate | 0.004 | 0.005 |
| hidden units and | 512 | 512 |
| number layers | 2 | 3 |
| epochs | 3 | 5 |
| Map | Sensors | Optimal Steps 1 | Mean Escape Time | Success Rate |
|---|---|---|---|---|
| Simple | Raycast | 400 k | 410 | 53% |
| Raycast + Grid | 500 k | 280 | 90% | |
| Raycast + Camera | 600 k | 331 | 66% | |
| Raycast + Grid + Camera | 200 k | 309 | 73% | |
| Complex | Raycast + Grid | 900 k | 320 | 78% |
| id | Personality (+/−) | Mean Reward 1 | Mean Escape Time 2 | Success Rate (All Agents Escaped) |
|---|---|---|---|---|
| 1 | Default | 1970 | 410 | 27% |
| 2 | Openness | 1695/2154 | 505/411 | 37/20% |
| 3 | Extraversion | 1776/1891 | 428/409 | 29/30% |
| 4 | Agreeableness | 1819/2003 | 440/430 | 37/27% |
| 5 | 3 Extroverts and 1 Introvert | 1150 | 380 | 39% (+10%) |
| 6 | 3 Introverts + 1 Extrovert | 1318 | 403 | 48% (+18%) |
| 7 | 3 Agreeableness and 1 Non Agreeableness | 1740 | 435 | 35% (−2%) |
| 8 | 3 Non Agreeableness + 1 Agreeableness | 1991 | 445 | 30% (+2%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liapis, G.; Vordou, A.; Nikolaidis, S.; Vlahavas, I. Reinforcement Learning Methods for Emulating Personality in a Game Environment. Appl. Sci. 2025, 15, 7894. https://doi.org/10.3390/app15147894
Liapis G, Vordou A, Nikolaidis S, Vlahavas I. Reinforcement Learning Methods for Emulating Personality in a Game Environment. Applied Sciences. 2025; 15(14):7894. https://doi.org/10.3390/app15147894
Chicago/Turabian StyleLiapis, Georgios, Anna Vordou, Stavros Nikolaidis, and Ioannis Vlahavas. 2025. "Reinforcement Learning Methods for Emulating Personality in a Game Environment" Applied Sciences 15, no. 14: 7894. https://doi.org/10.3390/app15147894
APA StyleLiapis, G., Vordou, A., Nikolaidis, S., & Vlahavas, I. (2025). Reinforcement Learning Methods for Emulating Personality in a Game Environment. Applied Sciences, 15(14), 7894. https://doi.org/10.3390/app15147894