
A Smart Housing Recommender for Students in Timișoara: Reinforcement Learning and Geospatial Analytics in a Modern Application


Abstract
1. Introduction
1.1. Related Work
1.1.1. Student Housing and AI in Recommendations
1.1.2. Anomaly Detection and Geospatial Analysis in Real-Estate Data
1.1.3. Research Gaps Addressed
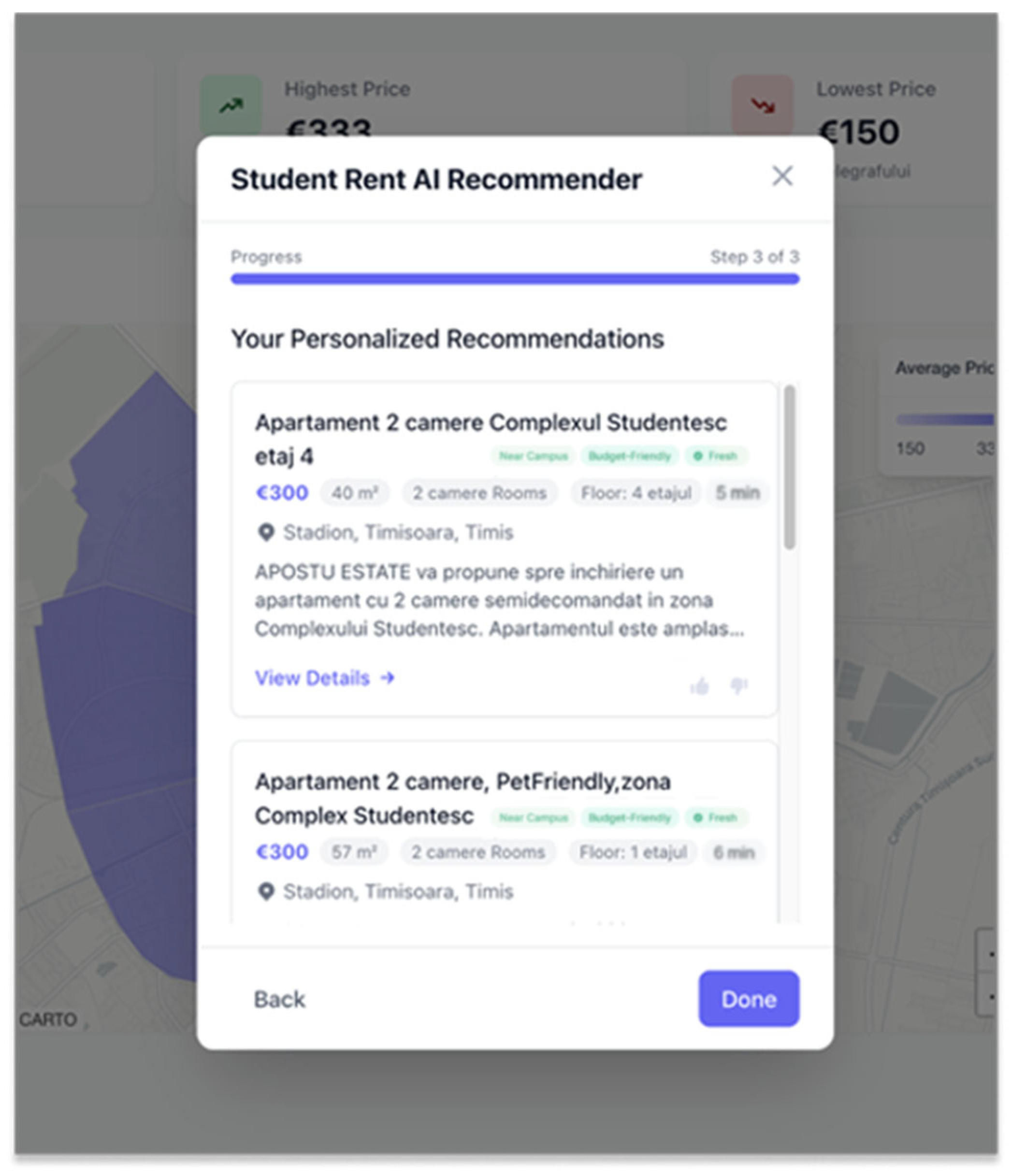
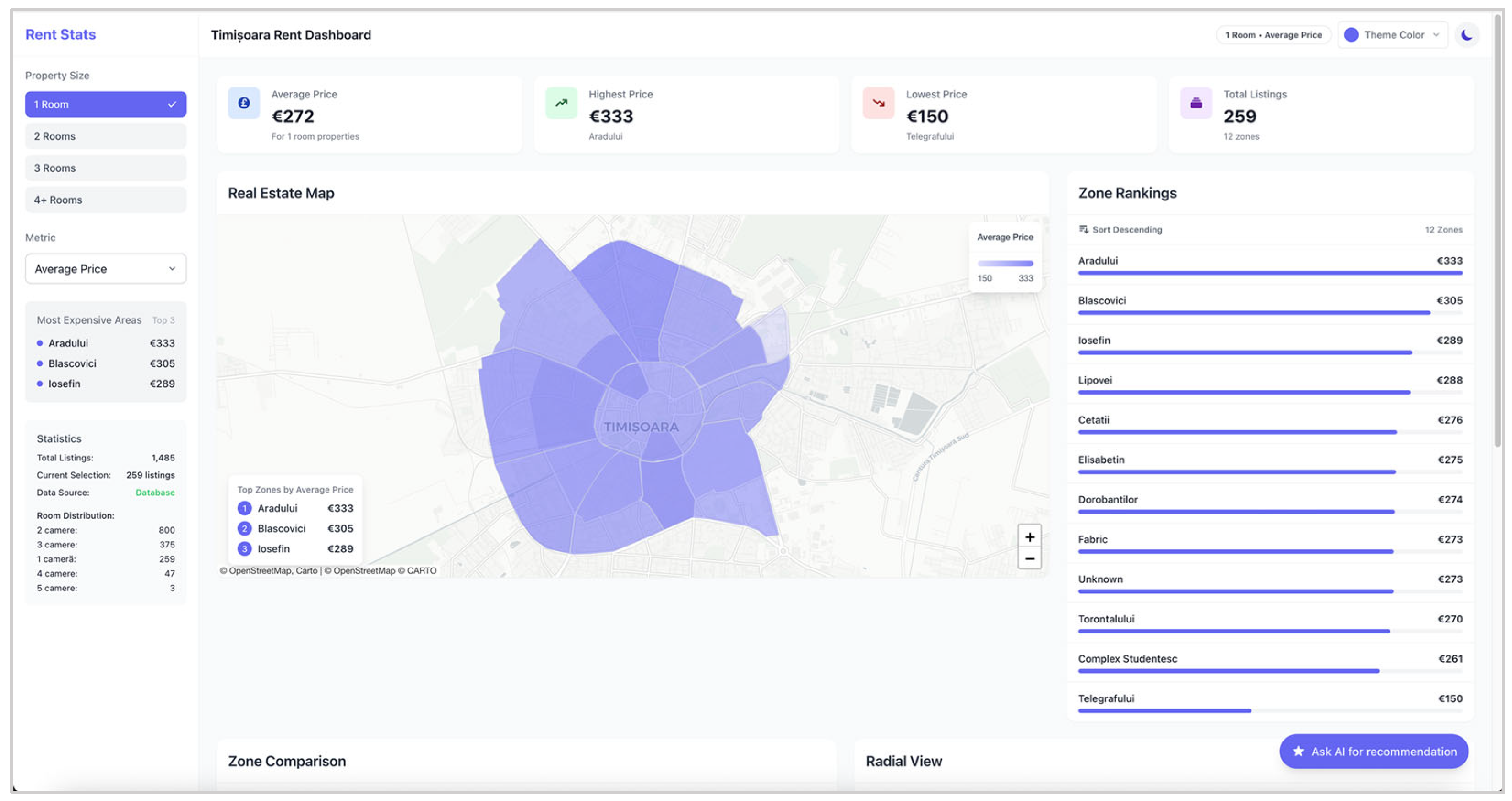
1.2. Application Showcased in This Paper
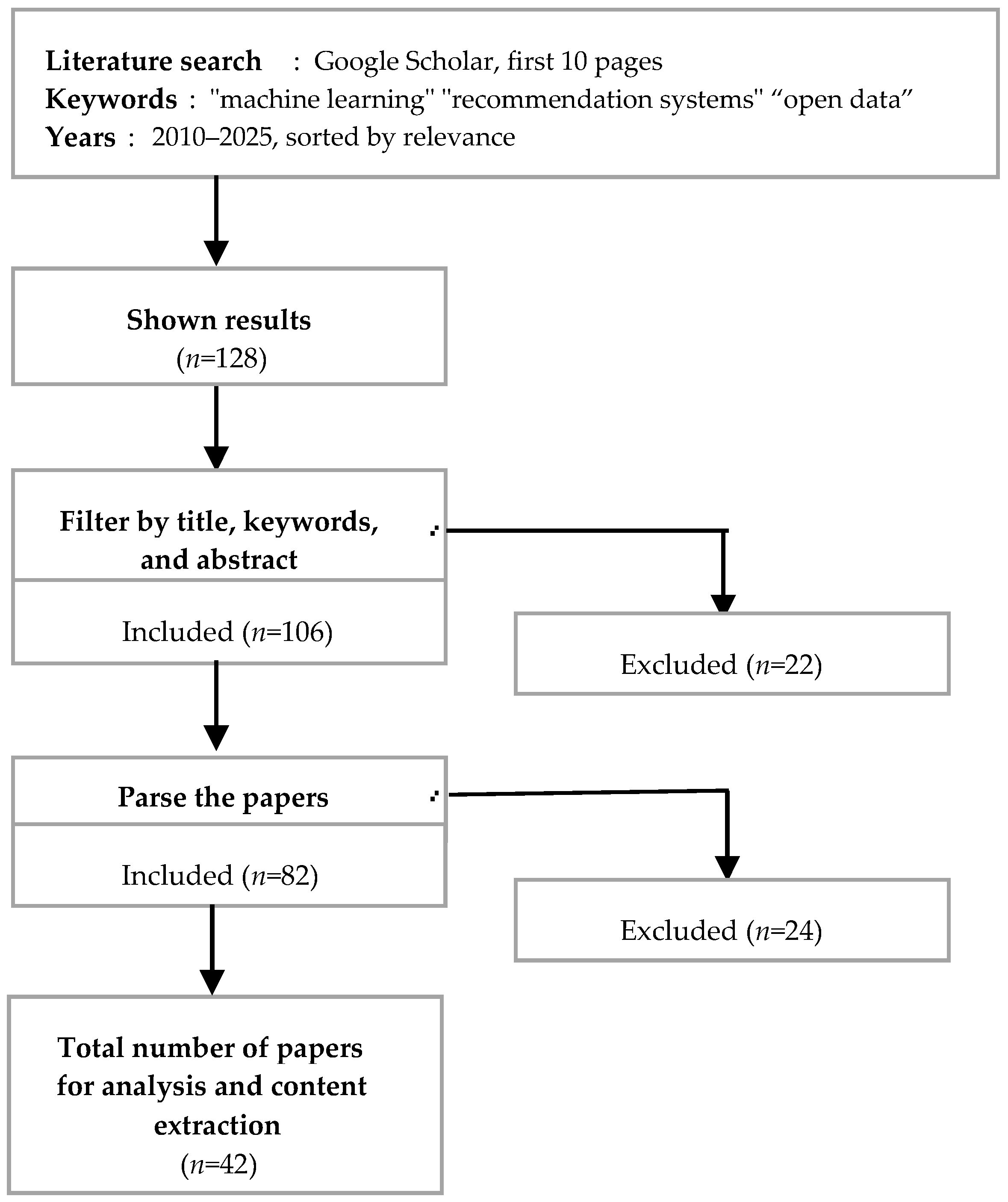
2. Research Questions and Methodology
2.1. Research Questions
2.2. Methodology
2.2.1. Initial Recommendation Phase and Sliding Window Weight Formula
2.2.2. Peak Load Stability and Dynamic Clustering Parameters
3. System Architecture
3.1. Data Layer
- Database Characteristics:
- Total database size: 2.3 GB across 47,583 documents
- Average document size: 48.3 KB, including embedded arrays
- Index composition:
- ○
- Compound geospatial index of location and price: 124 MB
- ○
- Text index of title and description fields: 89 MB
- ○
- Single-field indexes of scraped_at and rooms: 31 MB combined
- Working set size: 1.8 GB (fits entirely in RAM)
- Performance Benchmarking Methodology:
- Measured Performance Metrics:
- Geospatial queries (finding listings within radius):
- ○
- P50: 45 ms, P95: 89 ms, P99: 142 ms
- Aggregation pipelines (statistics generation):
- ○
- P50: 123 ms, P95: 289 ms, P99: 456 ms
3.2. Backend API Layer
- /search (or/listings), which accepts filters (location radius, price range, keywords) as query parameters and returns a JSON of matching listings (potentially already sorted by some criteria).
- /recommendations, which triggers the recommendation engine for a given user context, returning a curated list of listings.
- /stats, which provides aggregated data (for charts), such as counts per neighborhood or price distribution.
3.3. Frontend Layer
3.4. Detailed System Implementation
3.4.1. Data-Ingestion Pipeline Architecture
3.4.2. Reinforcement-Learning Implementation Details
- Spatial features: haversine distance to each university, zone one-hot encoding.
- Temporal features: days since listing, update frequency, day-of-week encoding.
- Textual features: TF-IDF vectors from descriptions, title–keyword similarity scores.
- Interaction features: cross-products of price–distance, area–zone relationships.
3.4.3. Geospatial Processing Implementation
3.4.4. Sparse Region Handling and Computational Analysis
- Initial DBSCAN with adaptive eps (5th percentile nearest neighbor distance).
- Sparse region detection (<5 listings/km2) using sliding window analysis.
- Hierarchical merging of adjacent sparse clusters within a 500 m radius.
- Spatial partitioning: a 4-partition grid for our city-scale dataset.
- Optimized processing: single-thread.
- R-tree indexing: O (log n) point-in-polygon checks vs. O (n) naïve.
- Boundary caching: recomputation only when density changes > 15%.
4. Discussion
https://www.storia.ro/api/offers?offer_type=rent&estate_type=apartment&city=timisoara&__pagination[offset]=0&__pagination[limit]=50
- 100 concurrent users: achieved a 98th percentile latency of 145 ms with a 0% error rate.
- 500 concurrent users: latency slightly increased to 312 ms at the 98th percentile, with a minimal error rate of 0.1%.
- 1000 concurrent users: even under extreme stress, the platform maintained a 98th percentile latency of 890 ms and limited the error rate to just 0.8%.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| AR | Augmented Reality |
| AI | Artificial Intelligence |
| RL | Reinforcement Learning |
| UI | User Interface |
| JSON | JavaScript Object Notation |
| REST | Representational State Transfer (as in RESTful API) |
| GET | Hypertext Transfer Protocol GET request (used in the context of API calls) |
| NoSQL | Non-relational Database (Not Only SQL) |
| IoT | Internet of Things |
| URL | Uniform Resource Locator |
References
- Wang, J.; Gou, L.; Shen, H.-W.; Yang, H. DQNViz: A Visual Analytics Approach to Understand Deep Q-Networks. IEEE Trans. Vis. Comput. Graph. 2019, 25, 288–298. [Google Scholar] [CrossRef]
- Baldominos, A.; Blanco, I.; Moreno, A.J.; Iturrarte, R.; Bernárdez, Ó.; Afonso, C. Identifying Real Estate Opportunities Using Machine Learning. Appl. Sci. 2018, 8, 2321. [Google Scholar] [CrossRef]
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. Explainable Reinforcement Learning: A Survey and Comparative Review. ACM Comput. Surv. 2023, 56, 1–36. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar] [CrossRef]
- Bauder, R.A.; Khoshgoftaar, T.M. Medicare Fraud Detection Using Machine Learning Methods. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancún, Mexico, 18–21 December 2017; pp. 858–865. [Google Scholar] [CrossRef]
- Tu, X.; Fu, C.; Huang, A.; Chen, H.; Ding, X. DBSCAN Spatial Clustering Analysis of Urban “Production–Living–Ecological” Space Based on POI Data: A Case Study of Central Urban Wuhan, China. Int. J. Environ. Res. Public Health 2022, 19, 5153. [Google Scholar] [CrossRef]
- Mora-Garcia, R.-T.; Cespedes-Lopez, M.-F.; Perez-Sanchez, V.R. Housing Price Prediction Using Machine Learning Algorithms in COVID-19 Times. Land 2022, 11, 2100. [Google Scholar] [CrossRef]
- Dong, X.L.; Naumann, F. Data Fusion: Resolving Data Conflicts for Integration. Proc. VLDB Endow. 2009, 2, 1654–1655. [Google Scholar] [CrossRef]
- Choy, L.H.T.; Ho, W.K.O. The Use of Machine Learning in Real Estate Research. Land 2023, 12, 740. [Google Scholar] [CrossRef]
- Strong, E.; Kleynhans, B.; Kadıoğlu, S. MABWiser: Contextual Multi-Armed Bandits for Production Recommendation Systems. Int. J. Artif. Intell. Tools 2024, 33, 2450001. [Google Scholar] [CrossRef]
- Kmen, C.; Navratil, G.; Giannopoulos, I. Location, Location, Location: The Power of Neighborhoods for Apartment Price Predictions Based on Transaction Data. ISPRS Int. J. Geo-Inf. 2024, 13, 425. [Google Scholar] [CrossRef]
- Lv, Z.; Li, J.; Xu, Z.; Wang, Y.; Li, H. Parallel Computing of Spatio-Temporal Model Based on Deep Reinforcement Learning. Lect. Notes Comput. Sci. 2021, 12937, 391–403. Available online: https://www.researchgate.net/publication/354454406_Parallel_Computing_of_Spatio-Temporal_Model_Based_on_Deep_Reinforcement_Learning (accessed on 1 June 2025).
- Fang, C.; Zhou, L.; Gu, X.; Liu, X.; Werner, M. A Data-driven Approach to Urban Area Delineation Using Multi-source Geospatial Data. Sci. Rep. 2025, 15, 8708. [Google Scholar] [CrossRef]
- Luxen, D.; Vetter, C. Real-time Routing with OpenStreetMap Data: OSRM Performance at Continental Scale. ACM Trans. Spat. Algorithms Syst. 2023, 9, 513–516. [Google Scholar] [CrossRef]
- Bansal, M.; Dar, M.A.; Bhat, M.M. Data Ingestion and Processing Using Playwright. TechRxiv 2023. [Google Scholar] [CrossRef]
- Pu, P.; Li, C.; Rong, H. A User-Centric Evaluation Framework for Recommender Systems. In Proceedings of the 5th ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 157–164. [Google Scholar] [CrossRef]
- Bradley, J.V. Complete Counterbalancing of Immediate Sequential Effects in a Latin Square Design. J. Am. Stat. Assoc. 1958, 53, 525–528. [Google Scholar] [CrossRef]
- Hart, S.G. NASA-Task Load Index (NASA-TLX); 20 Years Later. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2006, 50, 904–908. [Google Scholar] [CrossRef]
- Jian, J.-Y.; Bisantz, A.M.; Drury, C.G. Foundations for an Empirically Determined Scale of Trust in Automated Systems. Int. J. Cogn. Ergon. 2000, 4, 53–71. [Google Scholar] [CrossRef]
- Xu, Z.; Lv, Z.; Chu, B.; Li, J. A Fast Spatial-Temporal Information Compression Algorithm for Online Real-Time Forecasting of Traffic Flow with Complex Nonlinear Patterns. Chaos Solitons Fractals 2024, 182, 114852. [Google Scholar] [CrossRef]
- Miljkovic, I.; Shlyakhetko, O.; Fedushko, S. Real Estate App Development Based on AI/VR Technologies. Electronics 2023, 12, 707. [Google Scholar] [CrossRef]
- Söderberg, I.-L.; Wester, M.; Jonsson, A.Z. Exploring Factors Promoting Recycling Behavior in Student Housing. Sustainability 2022, 14, 4264. [Google Scholar] [CrossRef]
- Gharahighehi, A.; Pliakos, K.; Vens, C. Recommender Systems in the Real Estate Market—A Survey. Appl. Sci. 2021, 11, 7502. [Google Scholar] [CrossRef]
- Ojokoh, B.; Olufunke, C.O.; Babalola, A.; Eyo, E. A User-Centric Housing Recommender System. Inf. Manag. Bus. Rev. 2018, 10, 17–24. [Google Scholar]
- Mubarak, M.; Tahir, A.; Waqar, F.; Haneef, I.; McArdle, G.; Bertolotto, M.; Saeed, M.T. A Map-Based Recommendation System and House Price Prediction Model for Real Estate. ISPRS Int. J. Geo-Inf. 2022, 11, 178. [Google Scholar] [CrossRef]
- Satapathy, S.M.; Jhaveri, R.; Khanna, U.; Dwivedi, A. Smart Rent Portal using Recommendation System Visualized by Augmented Reality. Procedia Comput. Sci. 2020, 171, 197–206. [Google Scholar] [CrossRef]
- Najib, N.U.M.; Yousof, N.A.; Tabassi, A.A. Living in On-Campus Student Housing: Students’ Behavioural Intentions and Students’ Personal Attainments. Procedia Soc. Behav. Sci. 2015, 170, 494–503. [Google Scholar] [CrossRef]
- Cheskis-Gold, R.; Danahy, A.D. Trends in Undergraduate Student Housing: Process and Product. Plan. High. Educ. 2012, 41, 1. Available online: https://demographicperspectives.com/wp-content/uploads/2019/09/Trends-in-Undergraduate-Housing-Process-and-Product.pdf (accessed on 9 May 2025).
- Minder, P.; Bernstein, A. The Role of te Web in Real Estate: Web Science and Housing Markets. In Proceedings of the ACM Web Science Conference 2012, Evanston, IL, USA, 22–24 June 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Henríquez-Miranda, C.; Ríos-Pérez, J.; Sanchez-Torres, G. Recommender Systems in Real Estate: A Systematic Review. Bull. Electr. Eng. Inform. 2025, 14, 2156–2170. [Google Scholar] [CrossRef]
- Tintarev, N.; Masthoff, J. Evaluating the Effectiveness of Explanations for Recommender Systems. User Model. User-Adapt. Interact. 2012, 22, 399–439. [Google Scholar] [CrossRef]
- Koeva, M.; Gasuku, O.; Lengoiboni, M.; Asiama, K.; Bennett, R.M.; Potel, J.; Zevenbergen, J. Remote Sensing for Property Valuation: A Data Source Comparison in Support of Fair Land Taxation in Rwanda. Remote Sens. 2021, 13, 3563. [Google Scholar] [CrossRef]
- La Roche, C.R.; Flanigan, M.A.; Copeland, P.K., Jr. Student Housing: Trends, Preferences and Needs. Contemp. Issues Educ. Res. (CIER) 2010, 3, 45. [Google Scholar] [CrossRef]
- Lorenz, F.; Willwersch, J.; Cajias, M.; Fuerst, F. Interpretable Machine Learning for Real Estate Market Analysis. Real Estate Econ. 2022, 51, 5. [Google Scholar] [CrossRef]
- Droj, G.; Kwartnik-Pruc, A.; Droj, L. A Comprehensive Overview Regarding the Impact of GIS on Property Valuation. ISPRS Int. J. Geo-Inf. 2024, 13, 175. [Google Scholar] [CrossRef]
- Thomsen, J.; Eikemo, T.A. Aspects of Student Housing Satisfaction. J. Hous. Built Environ. 2010, 25, 273–293. [Google Scholar] [CrossRef]
- Simpeh, F.; Akinlolu, M. A Scientometric Review of Student Housing Research Trends. IOP Conf. Ser. Earth Environ. Sci. 2021, 654, 012015. [Google Scholar] [CrossRef]
- Pai, P.-F.; Wang, W.-C. Using Machine Learning Models and Actual Transaction Data for Predicting Real Estate Prices. Appl. Sci. 2020, 10, 5832. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, Y.; Lin, F.; Zou, L.; Wu, P.; Zeng, W.; Chen, H.; Miao, C. Reinforcement Learning for Recommender Systems: A Survey. ACM Comput. Surv. 2021, 54, 42. [Google Scholar] [CrossRef]
- Louzada, F.; de Lacerda, K.J.C.C.; Ferreira, P.H.; Gomes, N.D. Smart Renting: Harnessing Urban Data with Statistical and Machine Learning Methods for Predicting Property Rental Prices from a Tenant’s Perspective. Stats 2025, 8, 12. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | Avg. Time (min) | Listings Viewed | Relevance Score |
|---|---|---|---|
| Our System | 8.3 ± 2.1 | 5.2 ± 1.8 | 8.7 ± 0.9 |
| Imobiliare.ro | 24.6 ± 6.3 | 18.4 ± 5.2 | 6.2 ± 1.3 |
| Facebook Marketplace | 31.2 ± 8.7 | 25.3 ± 7.1 | 5.8 ± 1.6 |
| OLX | 28.4 ± 7.2 | 21.6 ± 6.3 | 5.5 ± 1.4 |
| Approach | Preprocessing | Query Time | Memory | Accuracy | Region Coverage |
|---|---|---|---|---|---|
| Fixed Boundaries | 0 ms | 2.3 ± 0.4 ms | 0.5 MB | 82% | 71% |
| Dynamic DBSCAN | 45 ± 8 ms | 4.7 ± 0.8 ms | 3.2 MB | 94% | 96% |
| Hybrid Cached | 45 ms initial | 2.8 ± 0.5 ms | 4.8 MB | 94% | 96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nicula, A.-S.; Ternauciuc, A.; Vasiu, R.-A. A Smart Housing Recommender for Students in Timișoara: Reinforcement Learning and Geospatial Analytics in a Modern Application. Appl. Sci. 2025, 15, 7869. https://doi.org/10.3390/app15147869
Nicula A-S, Ternauciuc A, Vasiu R-A. A Smart Housing Recommender for Students in Timișoara: Reinforcement Learning and Geospatial Analytics in a Modern Application. Applied Sciences. 2025; 15(14):7869. https://doi.org/10.3390/app15147869
Chicago/Turabian StyleNicula, Andrei-Sebastian, Andrei Ternauciuc, and Radu-Adrian Vasiu. 2025. "A Smart Housing Recommender for Students in Timișoara: Reinforcement Learning and Geospatial Analytics in a Modern Application" Applied Sciences 15, no. 14: 7869. https://doi.org/10.3390/app15147869
APA StyleNicula, A.-S., Ternauciuc, A., & Vasiu, R.-A. (2025). A Smart Housing Recommender for Students in Timișoara: Reinforcement Learning and Geospatial Analytics in a Modern Application. Applied Sciences, 15(14), 7869. https://doi.org/10.3390/app15147869